

BP神经网络算法

BP(Back Propagation)网络是1986年由Rumelhart和McCelland为首的科学家小组提出,是一种按误差逆传播算法训练的多层前馈网络,是目前应用最广泛的神经网络模型之一。
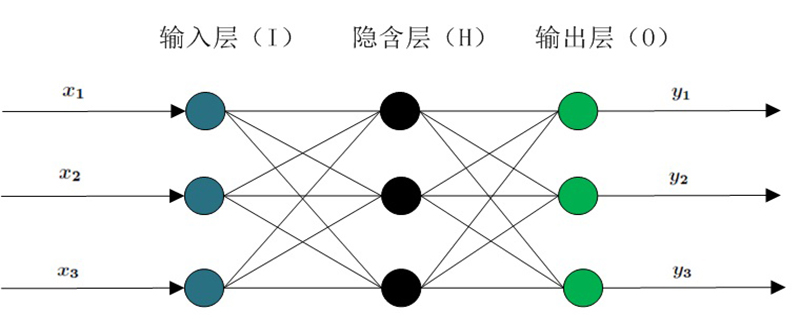
BP网络能学习和存贮大量的输入-输出模式映射关系,而无需事前揭示描述这种映射关系的数学方程。
它的学习规则是使用最速下降法,通过反向传播来不断调整网络的权值和阈值,使网络的误差平方和最小。BP神经网络模型拓扑结构包括输入层(input)、隐层(hide layer)和输出层(output layer)。 (推荐学习:web前端视频教程)
BP神经网络算法是在BP神经网络现有算法的基础上提出的,是通过任意选定一组权值,将给定的目标输出直接作为线性方程的代数和来建立线性方程组,解得待求权,不存在传统方法的局部极小及收敛速度慢的问题,且更易理解。
BP算法
人工神经网络(artificial neural networks, ANN)系统是20世纪40年代后出现的,它是由众多的神经元可调的连接权值连接而成,具有大规模并行处理、分布式信息存储、良好的自组织自学习能力等特点,在信息处理、模式识别、智能控制及系统建模等领域得到越来越广泛的应用。
尤其误差反向传播算法(Error Back-propagation Training,简称BP网络)可以逼近任意连续函数,具有很强的非线性映射能力,而且网络的中间层数、各层的处理单元数及网络的学习系数等参数可根据具体情况设定,灵活性很大,所以它在许多应用领域中起到重要作用。
为了解决BP神经网络收敛速度慢、不能保证收敛到全局最点,网络的中间层及它的单元数选取无理论指导及网络学习和记忆的不稳定性等缺陷,提出了许多改进算法。
Atas ialah kandungan terperinci BP神经网络算法. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1381
1381
 52
52

 YOLO adalah abadi! YOLOv9 dikeluarkan: prestasi dan kelajuan SOTA~
Feb 26, 2024 am 11:31 AM
YOLO adalah abadi! YOLOv9 dikeluarkan: prestasi dan kelajuan SOTA~
Feb 26, 2024 am 11:31 AM
Kaedah pembelajaran mendalam hari ini memberi tumpuan kepada mereka bentuk fungsi objektif yang paling sesuai supaya keputusan ramalan model paling hampir dengan situasi sebenar. Pada masa yang sama, seni bina yang sesuai mesti direka bentuk untuk mendapatkan maklumat yang mencukupi untuk ramalan. Kaedah sedia ada mengabaikan fakta bahawa apabila data input mengalami pengekstrakan ciri lapisan demi lapisan dan transformasi spatial, sejumlah besar maklumat akan hilang. Artikel ini akan menyelidiki isu penting apabila menghantar data melalui rangkaian dalam, iaitu kesesakan maklumat dan fungsi boleh balik. Berdasarkan ini, konsep maklumat kecerunan boleh atur cara (PGI) dicadangkan untuk menghadapi pelbagai perubahan yang diperlukan oleh rangkaian dalam untuk mencapai pelbagai objektif. PGI boleh menyediakan maklumat input lengkap untuk tugas sasaran untuk mengira fungsi objektif, dengan itu mendapatkan maklumat kecerunan yang boleh dipercayai untuk mengemas kini berat rangkaian. Di samping itu, rangka kerja rangkaian ringan baharu direka bentuk
 Asas, sempadan dan aplikasi GNN
Apr 11, 2023 pm 11:40 PM
Asas, sempadan dan aplikasi GNN
Apr 11, 2023 pm 11:40 PM
Rangkaian saraf graf (GNN) telah mencapai kemajuan yang pesat dan luar biasa dalam beberapa tahun kebelakangan ini. Rangkaian saraf graf, juga dikenali sebagai pembelajaran dalam graf, pembelajaran perwakilan graf (pembelajaran perwakilan graf) atau pembelajaran dalam geometri, ialah topik penyelidikan yang paling pesat berkembang dalam bidang pembelajaran mesin, terutamanya pembelajaran mendalam. Tajuk perkongsian ini ialah "Asas, Sempadan dan Aplikasi GNN", yang terutamanya memperkenalkan kandungan umum buku komprehensif "Asas, Sempadan dan Aplikasi Rangkaian Neural Graf" yang disusun oleh sarjana Wu Lingfei, Cui Peng, Pei Jian dan Zhao Liang. 1. Pengenalan kepada rangkaian neural graf 1. Mengapa mengkaji graf? Graf ialah bahasa universal untuk menerangkan dan memodelkan sistem yang kompleks. Graf itu sendiri tidak rumit, ia terutamanya terdiri daripada tepi dan nod. Kita boleh menggunakan nod untuk mewakili mana-mana objek yang ingin kita modelkan, dan tepi untuk mewakili dua
 Gambaran keseluruhan tiga seni bina cip arus perdana untuk pemanduan autonomi dalam satu artikel
Apr 12, 2023 pm 12:07 PM
Gambaran keseluruhan tiga seni bina cip arus perdana untuk pemanduan autonomi dalam satu artikel
Apr 12, 2023 pm 12:07 PM
Cip AI arus perdana semasa terutamanya dibahagikan kepada tiga kategori: GPU, FPGA dan ASIC. Kedua-dua GPU dan FPGA adalah seni bina cip yang agak matang pada peringkat awal dan merupakan cip kegunaan umum. ASIC ialah cip yang disesuaikan untuk senario AI tertentu. Industri telah mengesahkan bahawa CPU tidak sesuai untuk pengkomputeran AI, tetapi ia juga penting dalam aplikasi AI. Seni Bina Penyelesaian GPU Perbandingan antara GPU dan CPU CPU mengikut seni bina von Neumann, terasnya ialah penyimpanan atur cara/data dan pelaksanaan bersiri. Oleh itu, seni bina CPU memerlukan sejumlah besar ruang untuk meletakkan unit storan (Cache) dan unit kawalan (Control) Sebaliknya, unit pengkomputeran (ALU) hanya menduduki sebahagian kecil, jadi CPU berfungsi secara besar-besaran. pengkomputeran selari.
 'Pemilik Bilibili UP berjaya mencipta rangkaian neural berasaskan batu merah pertama di dunia, yang menyebabkan sensasi di media sosial dan dipuji oleh Yann LeCun.'
May 07, 2023 pm 10:58 PM
'Pemilik Bilibili UP berjaya mencipta rangkaian neural berasaskan batu merah pertama di dunia, yang menyebabkan sensasi di media sosial dan dipuji oleh Yann LeCun.'
May 07, 2023 pm 10:58 PM
Dalam Minecraft, batu merah adalah item yang sangat penting. Ia adalah bahan unik dalam permainan Suis, obor batu merah, dan blok batu merah boleh memberikan tenaga seperti elektrik kepada wayar atau objek. Litar Redstone boleh digunakan untuk membina struktur untuk anda mengawal atau mengaktifkan jentera lain Ia sendiri boleh direka bentuk untuk bertindak balas kepada pengaktifan manual oleh pemain, atau mereka boleh mengeluarkan isyarat berulang kali atau bertindak balas kepada perubahan yang disebabkan oleh bukan pemain, seperti pergerakan makhluk. dan item Jatuh, pertumbuhan tumbuhan, siang dan malam, dan banyak lagi. Oleh itu, dalam dunia saya, redstone boleh mengawal pelbagai jenis jentera, daripada jentera ringkas seperti pintu automatik, suis lampu dan bekalan kuasa strob, kepada lif besar, ladang automatik, platform permainan kecil dan juga komputer binaan dalam permainan . Baru-baru ini, stesen B UP utama @
 Drone yang boleh menahan angin kencang? Caltech menggunakan data penerbangan selama 12 minit untuk mengajar dron terbang mengikut angin
Apr 09, 2023 pm 11:51 PM
Drone yang boleh menahan angin kencang? Caltech menggunakan data penerbangan selama 12 minit untuk mengajar dron terbang mengikut angin
Apr 09, 2023 pm 11:51 PM
Apabila angin cukup kuat untuk meniup payung, drone itu stabil, seperti ini: Terbang dalam angin adalah sebahagian daripada terbang di udara Dari tahap yang besar, apabila juruterbang mendaratkan pesawat, kelajuan angin mungkin Membawa cabaran kepada mereka; pada tahap yang lebih kecil, angin kencang juga boleh menjejaskan penerbangan dron. Pada masa ini, dron sama ada diterbangkan dalam keadaan terkawal, tanpa angin, atau dikendalikan oleh manusia menggunakan alat kawalan jauh. Dron dikawal oleh penyelidik untuk terbang dalam formasi di langit terbuka, tetapi penerbangan ini biasanya dijalankan dalam keadaan dan persekitaran yang ideal. Walau bagaimanapun, agar dron melakukan tugasan yang perlu tetapi rutin secara autonomi, seperti menghantar pakej, ia mesti dapat menyesuaikan diri dengan keadaan angin dalam masa nyata. Untuk menjadikan dron lebih mudah dikendalikan apabila terbang mengikut angin, pasukan jurutera dari Caltech
 Berbilang laluan, berbilang domain, merangkumi semua! Google AI mengeluarkan model am pembelajaran berbilang domain MDL
May 28, 2023 pm 02:12 PM
Berbilang laluan, berbilang domain, merangkumi semua! Google AI mengeluarkan model am pembelajaran berbilang domain MDL
May 28, 2023 pm 02:12 PM
Model pembelajaran mendalam untuk tugas penglihatan (seperti klasifikasi imej) biasanya dilatih hujung ke hujung dengan data daripada domain visual tunggal (seperti imej semula jadi atau imej yang dijana komputer). Secara amnya, aplikasi yang menyelesaikan tugas penglihatan untuk berbilang domain perlu membina berbilang model untuk setiap domain yang berasingan dan melatihnya secara berasingan Data tidak dikongsi antara domain yang berbeza, setiap model akan mengendalikan data input tertentu. Walaupun ia berorientasikan kepada bidang yang berbeza, beberapa ciri lapisan awal antara model ini adalah serupa, jadi latihan bersama model ini adalah lebih cekap. Ini mengurangkan kependaman dan penggunaan kuasa, dan mengurangkan kos memori untuk menyimpan setiap parameter model Pendekatan ini dipanggil pembelajaran berbilang domain (MDL). Selain itu, model MDL juga boleh mengatasi prestasi tunggal
 1.3ms mengambil masa 1.3ms! Seni bina rangkaian neural mudah alih sumber terbuka terbaru Tsinghua RepViT
Mar 11, 2024 pm 12:07 PM
1.3ms mengambil masa 1.3ms! Seni bina rangkaian neural mudah alih sumber terbuka terbaru Tsinghua RepViT
Mar 11, 2024 pm 12:07 PM
Alamat kertas: https://arxiv.org/abs/2307.09283 Alamat kod: https://github.com/THU-MIG/RepViTRepViT berprestasi baik dalam seni bina ViT mudah alih dan menunjukkan kelebihan yang ketara. Seterusnya, kami meneroka sumbangan kajian ini. Disebutkan dalam artikel bahawa ViT ringan biasanya berprestasi lebih baik daripada CNN ringan pada tugas visual, terutamanya disebabkan oleh modul perhatian diri berbilang kepala (MSHA) mereka yang membolehkan model mempelajari perwakilan global. Walau bagaimanapun, perbezaan seni bina antara ViT ringan dan CNN ringan belum dikaji sepenuhnya. Dalam kajian ini, penulis menyepadukan ViT ringan ke dalam yang berkesan
 Meneroka rangkaian Siam menggunakan kehilangan kontrastif untuk perbandingan persamaan imej
Apr 02, 2024 am 11:37 AM
Meneroka rangkaian Siam menggunakan kehilangan kontrastif untuk perbandingan persamaan imej
Apr 02, 2024 am 11:37 AM
Pengenalan Dalam bidang penglihatan komputer, mengukur kesamaan imej dengan tepat adalah tugas kritikal dengan pelbagai aplikasi praktikal. Daripada enjin carian imej kepada sistem pengecaman muka dan sistem pengesyoran berasaskan kandungan, keupayaan untuk membandingkan dan mencari imej serupa dengan cekap adalah penting. Rangkaian Siam digabungkan dengan kehilangan kontras menyediakan rangka kerja yang kuat untuk mempelajari persamaan imej dalam cara yang dipacu data. Dalam catatan blog ini, kami akan menyelami butiran rangkaian Siam, meneroka konsep kehilangan kontras dan meneroka cara kedua-dua komponen ini berfungsi bersama untuk mencipta model persamaan imej yang berkesan. Pertama, rangkaian Siam terdiri daripada dua subrangkaian yang sama yang berkongsi berat dan parameter yang sama. Setiap sub-rangkaian mengekod imej input ke dalam vektor ciri, yang