

单表查询是什么

单表查询指的是在一张表中进行数据的查询,它的执行顺序是“from->where->group by->having->distinct->order by->limit->select”。

在数据库操作中,单表查询就是在一张表中进行数据的查询,详细它的语法是:
select distinct 字段1,字段2... from 表名 where 分组之前的过滤条件 group by 分组字段 having 分组之后的过滤条件 order by 排序字段 limit 显示的条数;
语法是样的一个顺序,但是它的执行顺序就不是从语法的顺序来执行了,而是这样的一个顺序。
from--->where--->group by--->having-->distinct--->order by--->limit--->select
至于为什么这样的一个执行顺序,我就不说了,也没这个自信说清楚。如果小白只要记得是这个执行顺序就可以了,如果非要刨根问底,可以去google一下。
在了解单表查询前,我们首先来建一张雇员表:
emp表: 员工id id int 姓名 emp_name varchar 性别 sex enum 年龄 age int 入职日期 hire_date date 岗位 post varchar 职位描述 post_comment varchar 薪水 salary double 办公室 office int 部门编号 depart_id int
建表:
create table emp( id int not null unique auto_increment, name varchar(20) not null, sex enum('male','female') not null default 'male', age int(3) unsigned not null default 28, hire_date date not null, post varchar(50), post_comment varchar(100), salary double(15,2), office int, depart_id int );
插入数据:
insert into emp(name,sex,age,hire_date,post,salary,office,depart_id) values ('niange','male',23,'20170301','manager',15000,401,1), ('monicx','male',23,'20150302','teacher',16000,401,1), ('wupeiqi','male',25,'20130305','teacher',8300,401,1), ('yuanhao','male',34,'20140701','teacher',3500,401,1), ('anny','female',48,'20150311','sale',3000.13,402,2), ('monke','female',38,'20101101','sale',2000.35,402,2), ('sandy','female',18,'20110312','sale',1000.37,402,2), ('chermy','female',18,'20130311','operation',19000,403,3), ('bailes','male',18,'20150411','operation',18000,403,3), ('omg','female',18,'20140512','operation',17000,403,3);
where条件过滤
where字句中可以使用:
1. 比较运算符:>、<、>=、 <=、 <>、!=。
2. between 1 and 5 值在1到5之间。
3. in(1,3,8) 值是1或3或8。
4. like 'monicx%'
%表示任意多字符
_表示一个字符
5. 逻辑运算符:在多个条件直接可以使用逻辑运算符 and、or、not。
6、正则表达式
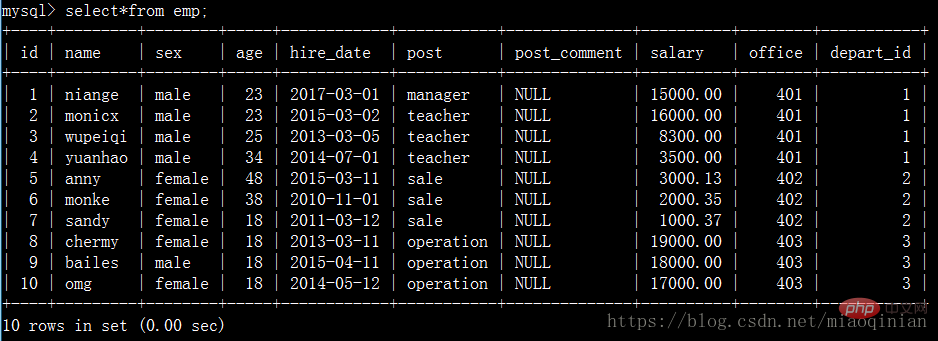
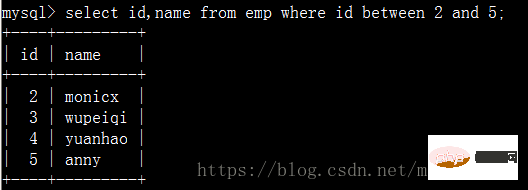
查找员工id在2到5之间的名字:
查询员工姓名中包含y字母的员工姓名与其薪资:
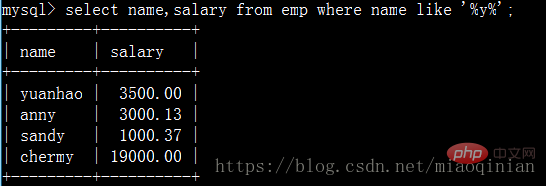
查询员工姓名是由四个字符组成的的员工姓名与其薪资:
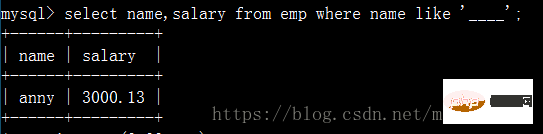
查询岗位描述为空的员工名与岗位名:
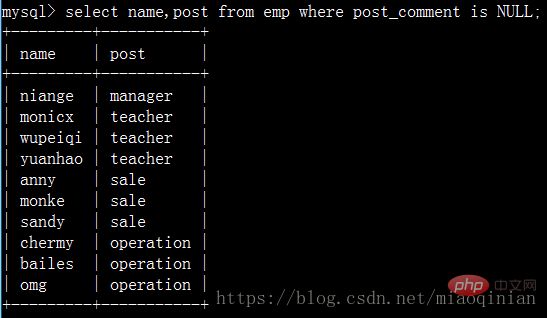
查询名字是字母m开头,以字母e或x结尾的员工!些时就可以用到正则表达示了,mysql里提供了regexp来现正则。

group by分组
先设置mysq的sql_mode为only_full_group_by,意味着以后但凡分组,只能取到分组的依据。
set global sql_mode="strict_trans_tables,only_full_group_by";
分组发生在where之后,即分组是基于where之后得到的记录而进行的。
分组指的是:将所有记录按照某个相同字段进行归类,比如针对员工信息表的职位分组,或者按照性别进行分组等
怎么要分组呢?
如:取每个部门的最高工资。
如:取每个部门的员工数。
每’这个字后面的字段,就是我们分组的依据。
注意:我们可以按照任意字段分组,但是分组完毕后,比如group by post,只能查看post字段。
但如果想查看组内信息,需要借助于聚合(聚在一起合成一个内容)函数
每个部门的最高工资 select post,max(salary) from emp group by post; 每个部门的最底工资 select post,min(salary) from emp group by post; 每个部门的平均工资 select post,avg(salary) from emp group by post; 每个部门的工资总合 select post,sum(salary) from emp group by post; 每个部门的总人数 select post,count(id) from emp group by post;
group_concat(分组之后用来用它获得组内字段的内容。)
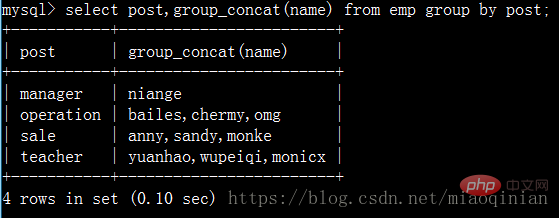
而且它还可以这样子使用:
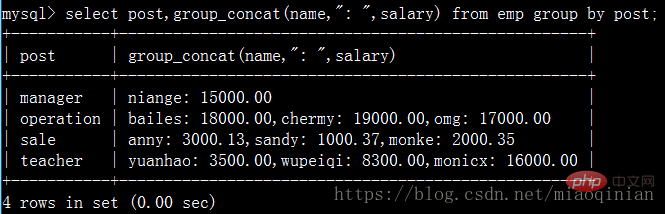
可以用下面的代码自己试一下吧:
select post,group_concat(name) from emp group by post; select post,group_concat(name,"_NB") from emp group by post; select post,group_concat(name,": ",salary) from emp group by post; select post,group_concat(salary) from emp group by post;
机智的同学会说那么不分组的情况下也能用它吗?不行!但是mysql提拱了另外的方式来操作。它就是concat。
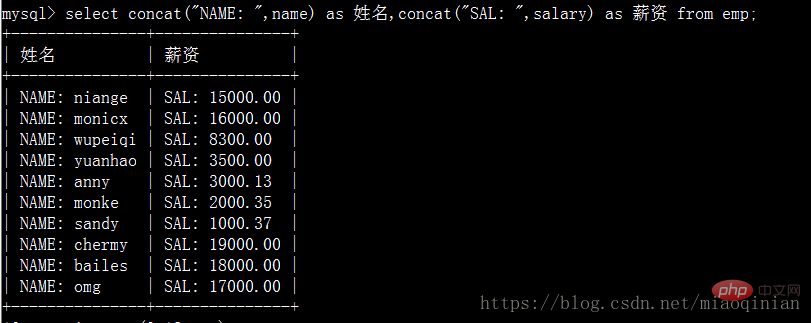
# 补充as语法
mysql> select emp.id,emp.name from emp as t1; # 报错
mysql> select t1.id,t1.name from emp as t1;group by 就说这些了,如果还不懂,可以作一下面的小练习。
1. 查询岗位名以及岗位包含的所有员工名字
select post,group_concat(name) from emp group by post;
2. 查询岗位名以及各岗位内包含的员工个数
select post,count(id) from emp group by post;
3. 查询公司内男员工和女员工的个数
select sex,count(id) from emp group by sex;
4. 查询岗位名以及各岗位的平均薪资
select post,avg(salary) from emp group by post;
5. 查询岗位名以及各岗位的最高薪资
select post,max(salary) from emp group by post;
6. 查询岗位名以及各岗位的最低薪资
select post,min(salary) from emp group by post;
7. 查询男员工与男员工的平均薪资,女员工与女员工的平均薪资
select sex,avg(salary) from emp group by sex;
8、统计各部门年龄在30岁以上的员工平均工资
select post,avg(salary) from emp where age >= 30 group by post;having过滤
having的语法格式与where一模一样,只不过having是在分组之后进行的进一步过滤。
where不能用聚合函数,但having是可以用聚合函数,这也是它们最大的区别。
统计各部门年龄在24岁以上的员工平均工资,并且保留平均工资大于4000的部门。
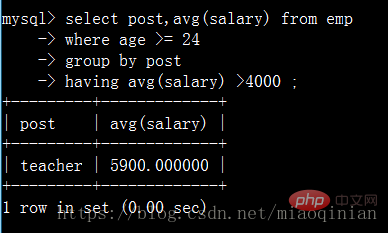
注意:having只能与 select 语句一起使用。
having通常在 group by 子句中使用。
如果不使用 group by子句,不会报错,但会出现以下的情况。

distinct去重
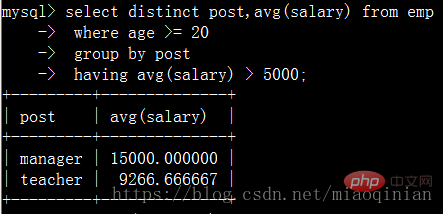
order by 排序
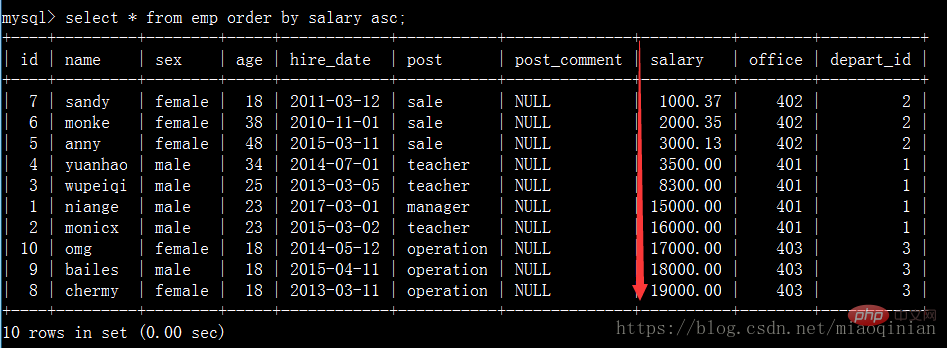
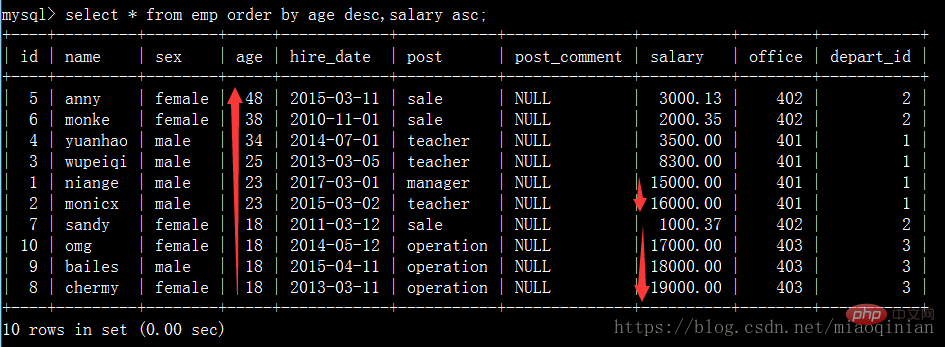
select * from emp order by salary asc; #默认升序排 select * from emp order by salary desc; #降序排 select * from emp order by age desc; #降序排 select * from emp order by age desc,salary asc; #先按照age降序排,再按照薪资升序排
limit 限制显示条数

如查要获取工资最高的员工的信息,我们可以用order by和limit也可以做到。

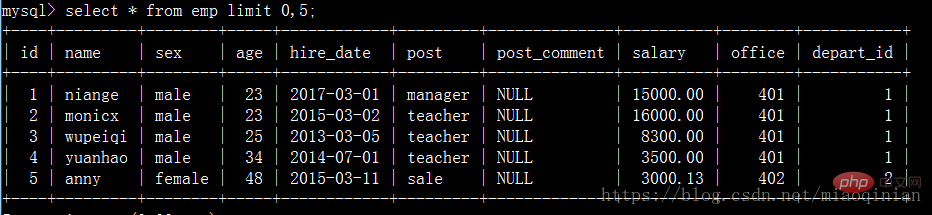
如果查一个表数据量大的话可以用limit分页显示。
select * from emp limit 0,5;
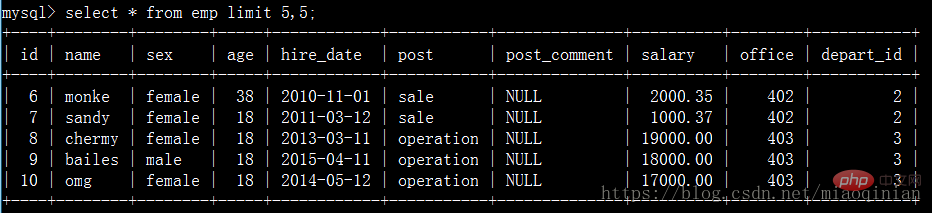
select * from emp limit 5,5;
ps:看到这里如果上面的东西你都明白的话,单表查询你基本上已经熟悉它了。
Atas ialah kandungan terperinci 单表查询是什么. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1383
1383
 52
52

 Terangkan keupayaan carian teks penuh InnoDB.
Apr 02, 2025 pm 06:09 PM
Terangkan keupayaan carian teks penuh InnoDB.
Apr 02, 2025 pm 06:09 PM
Keupayaan carian teks penuh InnoDB sangat kuat, yang dapat meningkatkan kecekapan pertanyaan pangkalan data dan keupayaan untuk memproses sejumlah besar data teks. 1) InnoDB melaksanakan carian teks penuh melalui pengindeksan terbalik, menyokong pertanyaan carian asas dan maju. 2) Gunakan perlawanan dan terhadap kata kunci untuk mencari, menyokong mod boolean dan carian frasa. 3) Kaedah pengoptimuman termasuk menggunakan teknologi segmentasi perkataan, membina semula indeks dan menyesuaikan saiz cache untuk meningkatkan prestasi dan ketepatan.
 Bagaimana anda mengubah jadual di MySQL menggunakan pernyataan Alter Table?
Mar 19, 2025 pm 03:51 PM
Bagaimana anda mengubah jadual di MySQL menggunakan pernyataan Alter Table?
Mar 19, 2025 pm 03:51 PM
Artikel ini membincangkan menggunakan pernyataan jadual Alter MySQL untuk mengubah suai jadual, termasuk menambah/menjatuhkan lajur, menamakan semula jadual/lajur, dan menukar jenis data lajur.
 Bilakah imbasan jadual penuh lebih cepat daripada menggunakan indeks di MySQL?
Apr 09, 2025 am 12:05 AM
Bilakah imbasan jadual penuh lebih cepat daripada menggunakan indeks di MySQL?
Apr 09, 2025 am 12:05 AM
Pengimbasan jadual penuh mungkin lebih cepat dalam MySQL daripada menggunakan indeks. Kes -kes tertentu termasuk: 1) jumlah data adalah kecil; 2) apabila pertanyaan mengembalikan sejumlah besar data; 3) Apabila lajur indeks tidak selektif; 4) Apabila pertanyaan kompleks. Dengan menganalisis rancangan pertanyaan, mengoptimumkan indeks, mengelakkan lebih banyak indeks dan tetap mengekalkan jadual, anda boleh membuat pilihan terbaik dalam aplikasi praktikal.
 Bolehkah saya memasang mysql pada windows 7
Apr 08, 2025 pm 03:21 PM
Bolehkah saya memasang mysql pada windows 7
Apr 08, 2025 pm 03:21 PM
Ya, MySQL boleh dipasang pada Windows 7, dan walaupun Microsoft telah berhenti menyokong Windows 7, MySQL masih serasi dengannya. Walau bagaimanapun, perkara berikut harus diperhatikan semasa proses pemasangan: Muat turun pemasang MySQL untuk Windows. Pilih versi MySQL yang sesuai (komuniti atau perusahaan). Pilih direktori pemasangan yang sesuai dan set aksara semasa proses pemasangan. Tetapkan kata laluan pengguna root dan simpan dengan betul. Sambung ke pangkalan data untuk ujian. Perhatikan isu keserasian dan keselamatan pada Windows 7, dan disyorkan untuk menaik taraf ke sistem operasi yang disokong.
 Bagaimana saya mengkonfigurasi penyulitan SSL/TLS untuk sambungan MySQL?
Mar 18, 2025 pm 12:01 PM
Bagaimana saya mengkonfigurasi penyulitan SSL/TLS untuk sambungan MySQL?
Mar 18, 2025 pm 12:01 PM
Artikel membincangkan mengkonfigurasi penyulitan SSL/TLS untuk MySQL, termasuk penjanaan sijil dan pengesahan. Isu utama menggunakan implikasi keselamatan sijil yang ditandatangani sendiri. [Kira-kira aksara: 159]
 Apakah beberapa alat GUI MySQL yang popular (mis., MySQL Workbench, phpmyadmin)?
Mar 21, 2025 pm 06:28 PM
Apakah beberapa alat GUI MySQL yang popular (mis., MySQL Workbench, phpmyadmin)?
Mar 21, 2025 pm 06:28 PM
Artikel membincangkan alat MySQL GUI yang popular seperti MySQL Workbench dan PHPMyAdmin, membandingkan ciri dan kesesuaian mereka untuk pemula dan pengguna maju. [159 aksara]
 Perbezaan antara indeks kluster dan indeks bukan clustered (indeks sekunder) di InnoDB.
Apr 02, 2025 pm 06:25 PM
Perbezaan antara indeks kluster dan indeks bukan clustered (indeks sekunder) di InnoDB.
Apr 02, 2025 pm 06:25 PM
Perbezaan antara indeks clustered dan indeks bukan cluster adalah: 1. Klustered Index menyimpan baris data dalam struktur indeks, yang sesuai untuk pertanyaan oleh kunci dan julat utama. 2. Indeks Indeks yang tidak berkumpul indeks nilai utama dan penunjuk kepada baris data, dan sesuai untuk pertanyaan lajur utama bukan utama.
 Bagaimana anda mengendalikan dataset besar di MySQL?
Mar 21, 2025 pm 12:15 PM
Bagaimana anda mengendalikan dataset besar di MySQL?
Mar 21, 2025 pm 12:15 PM
Artikel membincangkan strategi untuk mengendalikan dataset besar di MySQL, termasuk pembahagian, sharding, pengindeksan, dan pengoptimuman pertanyaan.
