

解决php字符串长度不等的方法:首先通过“mb_detect_encoding()”函数查看两个字符串的编码方式;然后查看具体字符长度;最后剔除非中文字符即可。

问题:
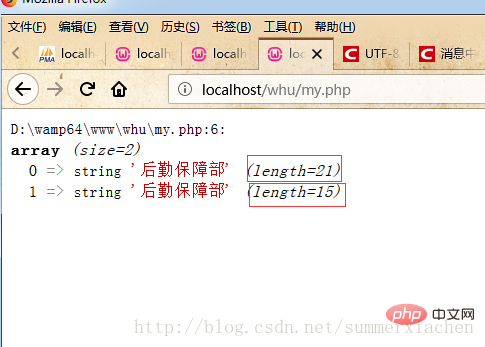
如图所示 咋眼看去两个一样的中文字符串“后勤保障部”,但一个长度为21 一个为15。
首先直觉可能会认为是编码方式不一样导致的,
通过mb_detect_encoding()函数查看两个字符串的编码方式 代码如下
<?phpheader("Content-Type: text/html;charset=utf-8");
$data[0]=$str1="后勤保障部";$data[1]=$str2="后勤保障部";
var_dump($data);//查看编码方式$encode1 = mb_detect_encoding($str1, array("ASCII","UTF-8","GB2312","GBK","BIG5"));$encode2 = mb_detect_encoding($str2, array("ASCII","UTF-8","GB2312","GBK","BIG5"));echo "str1='".$str1."'"." 编码:".$encode1."</br>";echo "str2='".$str2."'"." 编码:".$encode2."</br>";?>但输出结果都是UTF-8
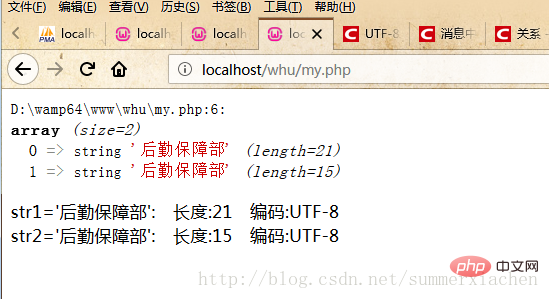
那么是什么原因呢 ,我们在输出看下具体字符长度
<?phpheader("Content-Type: text/html;charset=utf-8");
$data[0]=$str1="后勤保障部";$data[1]=$str2="后勤保障部";
var_dump($data);//查看编码方式$encode1 = mb_detect_encoding($str1, array("ASCII","UTF-8","GB2312","GBK","BIG5"));$encode2 = mb_detect_encoding($str2, array("ASCII","UTF-8","GB2312","GBK","BIG5"));//当mb_strlen的内码选择为UTF-8的时候,则会将中文字符当成一个字符//strlen,得到的是字符串所占的字节数echo "str1='".$str1."'".": 字符长度:".mb_strlen($str1).": 字节长度:".strlen($str1)." 编码:".$encode1."</br>";echo "str2='".$str2."'".": 字符长度:".mb_strlen($str2).": 字节长度:".strlen($str2)." 编码:".$encode2."</br>";?>输出结果如下:
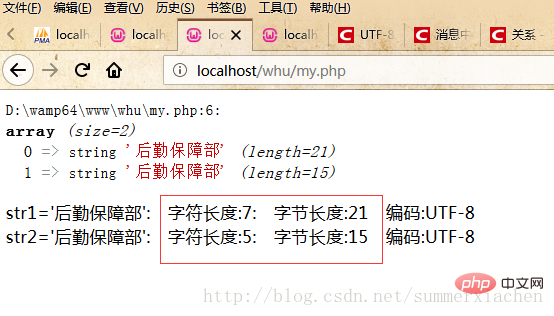
发现字符串str1有7个中文字符,但实际只显示了5个,也就是“后勤保障部”
通过截取str1最后两个字符查看
//截取str1后面两个未显示字符$res=mb_substr($str1, 5,2);echo "最后两字符:".$res."</br>";echo mb_strlen($res);
无法echo显示,但确实占有两个字符
如果实际要求这看上去一样的字符串就相等的话,需要进行处理,处理就是剔除非中文字符:
//剔除str1字串中未显示的字符(非中文字符)preg_match_all('/[\x{4e00}-\x{9fff}]+/u', $str1, $matches);$str1 = join('', $matches[0]);最终代码如下
<?phpheader("Content-Type: text/html;charset=utf-8");
$data[0]=$str1="后勤保障部";$data[1]=$str2="后勤保障部";
var_dump($data);//查看编码方式$encode1 = mb_detect_encoding($str1, array("ASCII","UTF-8","GB2312","GBK","BIG5"));$encode2 = mb_detect_encoding($str2, array("ASCII","UTF-8","GB2312","GBK","BIG5"));//当mb_strlen的内码选择为UTF-8的时候,则会将中文字符当成一个字符//strlen,得到的是字符串所占的字节数echo "str1='".$str1."'".": 字符长度:".mb_strlen($str1).": 字节长度:".strlen($str1)." 编码:".$encode1."</br>";echo "str2='".$str2."'".": 字符长度:".mb_strlen($str2).": 字节长度:".strlen($str2)." 编码:".$encode2."</br>";//截取str1后面两个未显示字符echo "</br>------------------截取str1后面两个未显示字符---------------------</br>";$res=mb_substr($str1, 5,2);echo "str1最后两字符: ".$res."</br>";echo "str1长度: ".mb_strlen($res)."</br>";//比较echo "</br>--------------------------相等比较----------------------------------</br>";echo "str1 与 str2比较: ";echo strcomp($str1,$str2)."</br>";echo "str2 与 str2比较: ";echo strcomp($str2,$str2)."</br>";//剔除str1字串中非中文preg_match_all('/[\x{4e00}-\x{9fff}]+/u', $str1, $matches);$str1 = join('', $matches[0]);echo "</br>---------------------剔除str1字串中非中文后----------------------</br>";echo "str1='".$str1."'".": 字符长度:".mb_strlen($str1).": 字节长度:".strlen($str1)." 编码:".$encode1."</br>";echo "str1 与 str2比较: ";echo strcomp($str1,$str2)."</br>";function strcomp($str1,$str2){
if($str1 == $str2){
return "相等";
}else{
return "不等";
}
}
?>运行结果 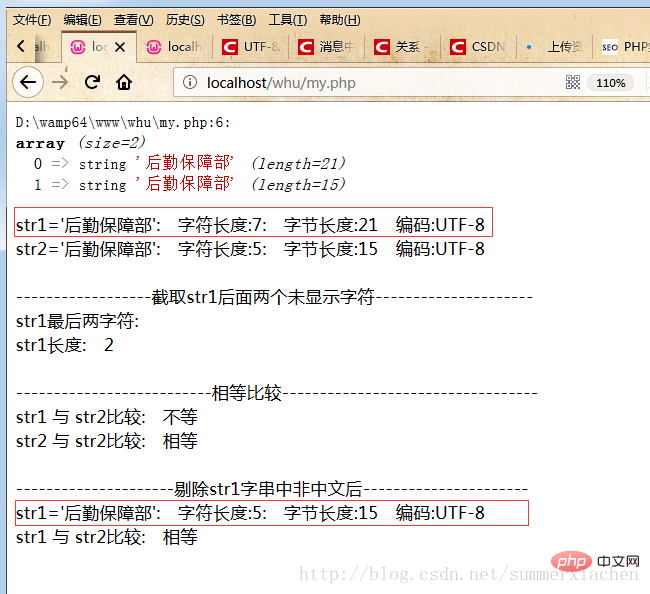
注:
将21字节的str1复制到phpmyadmin的sql输入框,显示如下
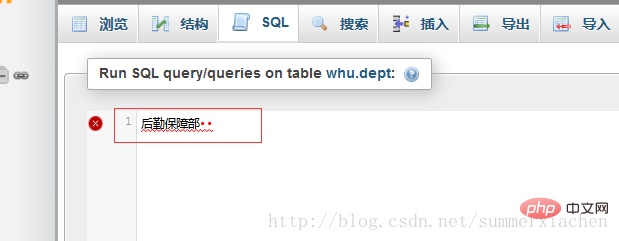
嗯 就是多的那两个字符
更多相关知识,请访问PHP中文网!
Atas ialah kandungan terperinci 解决php字符串一样但长度不等的问题. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 Bagaimana untuk membuka fail php
Bagaimana untuk membuka fail php
 Bagaimana untuk mengalih keluar beberapa elemen pertama tatasusunan dalam php
Bagaimana untuk mengalih keluar beberapa elemen pertama tatasusunan dalam php
 Apa yang perlu dilakukan jika penyahserialisasian php gagal
Apa yang perlu dilakukan jika penyahserialisasian php gagal
 Bagaimana untuk menyambungkan php ke pangkalan data mssql
Bagaimana untuk menyambungkan php ke pangkalan data mssql
 Bagaimana untuk menyambung php ke pangkalan data mssql
Bagaimana untuk menyambung php ke pangkalan data mssql
 Bagaimana untuk memuat naik html
Bagaimana untuk memuat naik html
 Bagaimana untuk menyelesaikan aksara bercelaru dalam PHP
Bagaimana untuk menyelesaikan aksara bercelaru dalam PHP
 Bagaimana untuk membuka fail php pada telefon bimbit
Bagaimana untuk membuka fail php pada telefon bimbit








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



