

集群的最主要瓶颈是什么?

集群的最主要瓶颈是:磁盘。当我们面临集群作战的时候,我们所希望的是即读即得。可是面对大数据,读取数据需要经过磁盘IO,这里可以把IO理解为水的管道。管道越大越强,我们对于T级的数据读取就越快。所以IO的好坏,直接影响了集群对于数据的处理。

集群的瓶颈提出多种看法,其中网络和磁盘io的争议比较大。这里需要说明的是网络是一种稀缺资源,而不是瓶颈。
对于磁盘IO:(磁盘IO:磁盘输出输出)
当我们面临集群作战的时候,我们所希望的是即读即得。可是面对大数据,读取数据需要经过IO,这里可以把IO理解为水的管道。管道越大越强,我们对于T级的数据读取就越快。所以IO的好坏,直接影响了集群对于数据的处理。
这里举几个例子,让大家来参考一下。
案例一
自从使用阿里云以来,我们遇到了三次故障(一、二、三),这三次故障都与磁盘IO高有关。
第一次故障发生在跑zzk.cnblogs.com索引服务的云 服务器上,当时的Avg.Disk Read Queue Length高达200多;
第二次故障发生在跑images.cnblogs.com静态文件的云服务器上,当时的Avg.Disk Read Queue Length在2左右(后来分析,对于图片站点这样的直接读文件进行响应的应用,Disk Read Queue Length达到这个值会明显影响响应速度);
第三次故障发生在跑数据库服务的云服务器上,当时的Avg. Disk Write Queue Length达到4~5,造成很多的数据库写入操作超时。
(这里既提到“硬盘”,又提到“磁盘”,我们这样界定的:在云服务器中看到的硬盘叫磁盘[虚拟出来的硬盘],在集群中的物理硬盘叫硬盘)
这三次的磁盘IO高都不是我们云服务器内的应用引起的,最直接的证据就是将云服务迁移至另一个集群之后,问题立即解决。也就是说云服务器的磁盘IO高是因 为它所在的集群的硬盘IO高。
集群的硬盘IO是集群内所有云服务器的磁盘IO的累加,集群的硬盘IO高是因为集群中某些云服务器的磁盘IO过高。而我们自 己的云服务器内的应用产生的磁盘IO在正常范围,问题出在其他用户的云服务器产生过多的磁盘IO,造成整个集群硬盘IO高,从而影响了我们。
为什么其他云服务器引起的硬盘IO问题会影响到我们?问题的根源就在于集群的硬盘IO被集群中的所有云服务器所共享,而且这种共享没有被有效的限制、没有 被有效的隔离,大家都在争抢这个资源,同时争抢的人太多,就会排长多。
而且对于每个云服务器来说,也不知道有多少台云服务器在争抢,从云服务器使用者的角 度根本无法躲开这个争抢;就像在世博会期间,你起再早去排队,也得排超长的队。
如果每个云服务器使用的硬盘IO资源是被限制或隔离的,其他云服务器产生再 多的磁盘IO也不会影响到我们的云服务器;就像在一个小区,你一个人租了一套房子,其他的一套房子即使住了100人,也不会影响到你。
你可以买到CPU、内存、带宽、硬盘空间,你却买不到一心一意为你服务的硬盘IO,这就是当前阿里云虚拟化平台设计时未考虑到的一个重要问题。
经过与阿里云技术人员的沟通,得知他们已经意识到这个问题,希望这个问题能早日得到解决。
---------------------------------------------------------------------------------------------------------------------------------------
案例2
云计算之路-迁入阿里云后:20130314云服务器故障经过
首先向大家致歉,这次云服务器故障发现于17:30左右,18:30左右恢复正常,给大家带来了麻烦,请大家谅解!
故障的原因是云服务器所在的集群负载过高,磁盘写入性能急剧下降,造成很多数据库写入操作超时。后来恢复正常的解决方法是将云服务器迁移至另一个集群。
下面是故障发生的主要经过:
今天上午9:15左右一位园友通过邮件反馈在访问园子时遇到502 Bad Gateway错误.
这是由阿里云负载均衡器返回的错误,Tegine是由阿里巴巴开发的开源Web服务器。我们猜测阿里云提供的负载均衡服务可能是通过Tegine反向代理实现的。
这个错误页面表示负载均衡器检测到负载均衡中的云服务器返回了无效的响应,比如500系列错误。
我们将这个情况通过工单反馈给了阿里云,得到的处理反馈是继续观察,可能是这位用户的网络线路的临时问题导致。
由于我们在这个时间段没遇到这个问题,也没有其他用户反馈这个问题,我们也认可了继续观察的处理方式。
(根据我们后来的分析,出现502 Bad Gateway错误可能是集群出现了瞬时负载高的情况)
下午17:20左右,我们自己也遇到了502 Bad Gateway错误,持续了大约1-2分钟。见下图: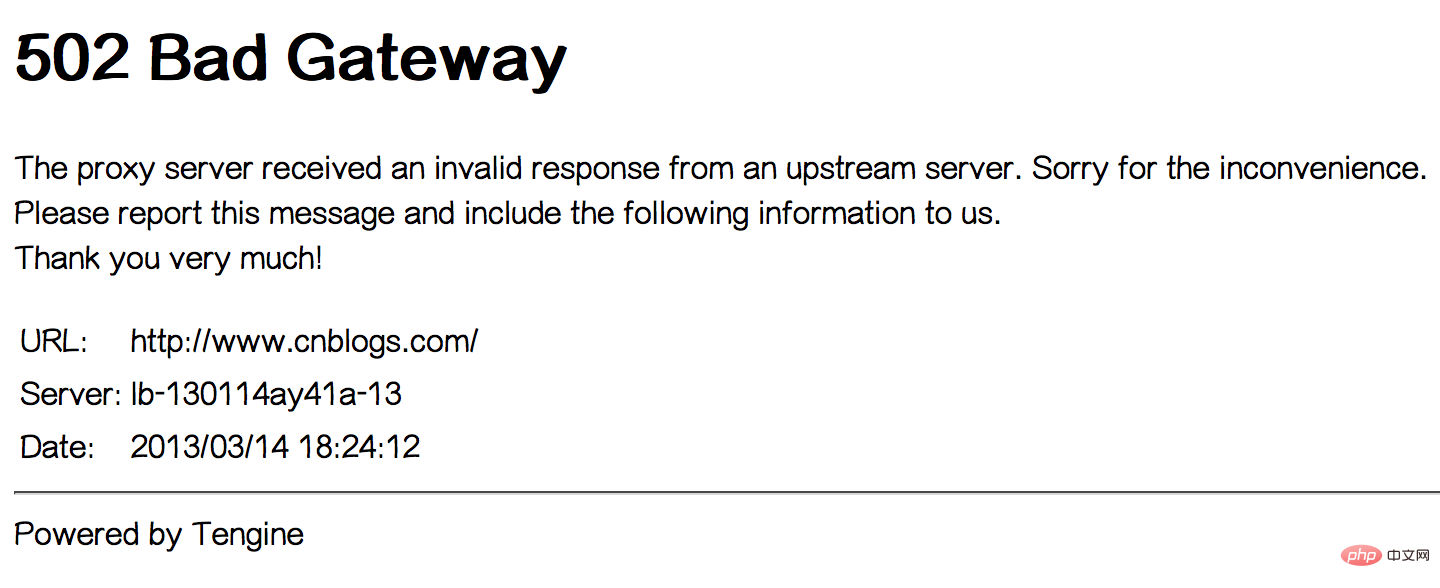
出问题期间,我们赶紧登录到两台云服务器查看情况,发现IIS并发连接数增长至原来的30多倍,而Bytes
Send/sec为0,而且两台云服务器都是同样的情况。我们当时推断,这两台云服务器本身应该没有问题,问题可能出在它们与数据库服务器之间的网络通
信。我们继续将这个情况通过工单反馈给阿里云。
刚把工单填好,我们就接到园友的电话反馈说博客后台不能发布文章,我们一测试,果然不能发布,报数据库超时错误,见下图:
但打开现有的文章速度很快,也就是说读正常,写有问题。赶紧登录数据库服务器通过性能监视器查看磁盘IO情况,果然磁盘写入性能有问题,见下图: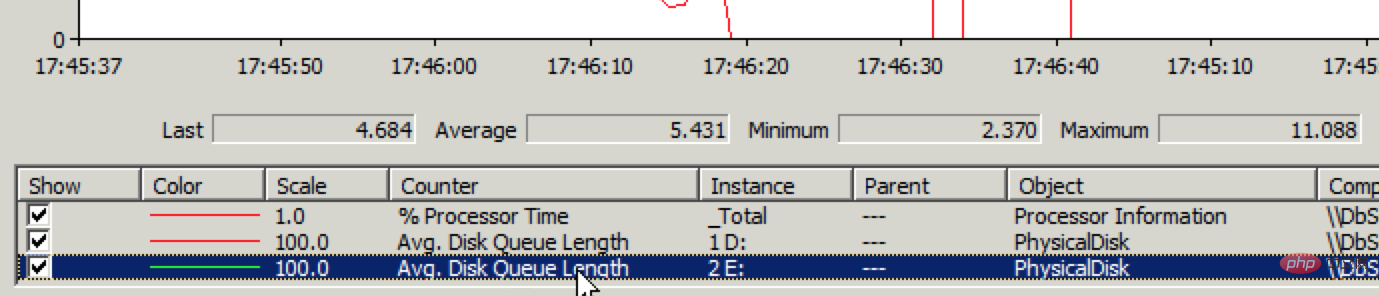

Avg. Disk Write Queue Length超过1就说明有问题了,现在平均已经到了4~5。进入阿里云网站上的管理控制台一看,磁盘IO问题就更明显了,见下图:
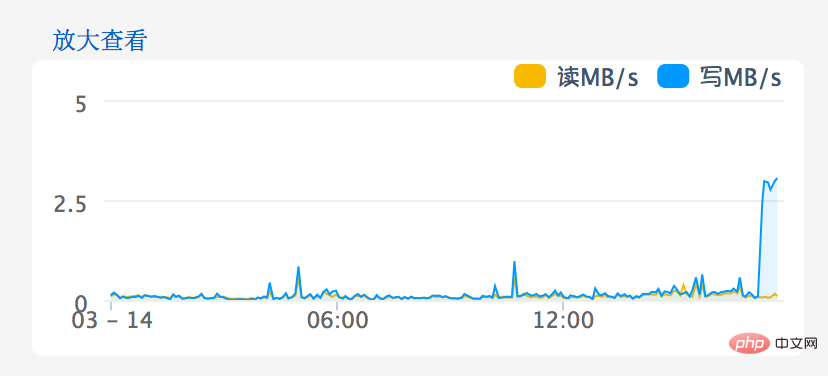
继续向阿里云反馈情况,得到的反馈是这台云服务器IOPS太高了,见下图:
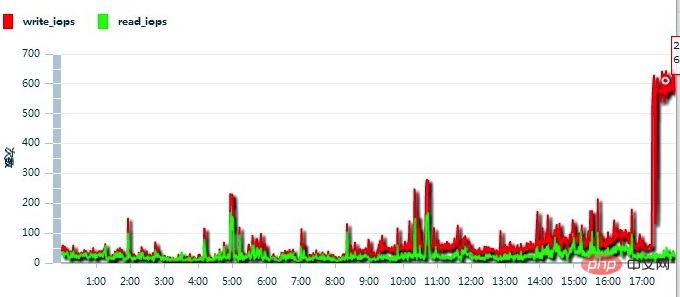
于是,阿里云工作人员将这台云服务器迁移至另一个集群,问题立刻解决。
----------------------------------------------------------------------------------------------------------------------------------------
案例三
14:17左右,我们看到了这条闪存。立即进入博客后台测试,发现提交时会出现如下的错误:

"Timeout expired. The timeout period elapsed prior to completion of the operation or the server is not responding."
这是数据库写入超时的错误,对这个错误信息我们记忆犹新。之前遇到过两次(3月14日、4月2日),都是数据库服务器所在的云服务器磁盘IO问题引起的。
登上云服务器,查看Windows性能监视器,发现日志文件所在的磁盘的IO监测数据Avg.Disk Write Queue Length平均值在5以上。性能监视器中这个值的纵坐标最高值是1,可想而知5是多么高的一个值。性能监视器中的走势图几乎是一条直线。见下图(最高值 竟然达到了20,真恐怖):
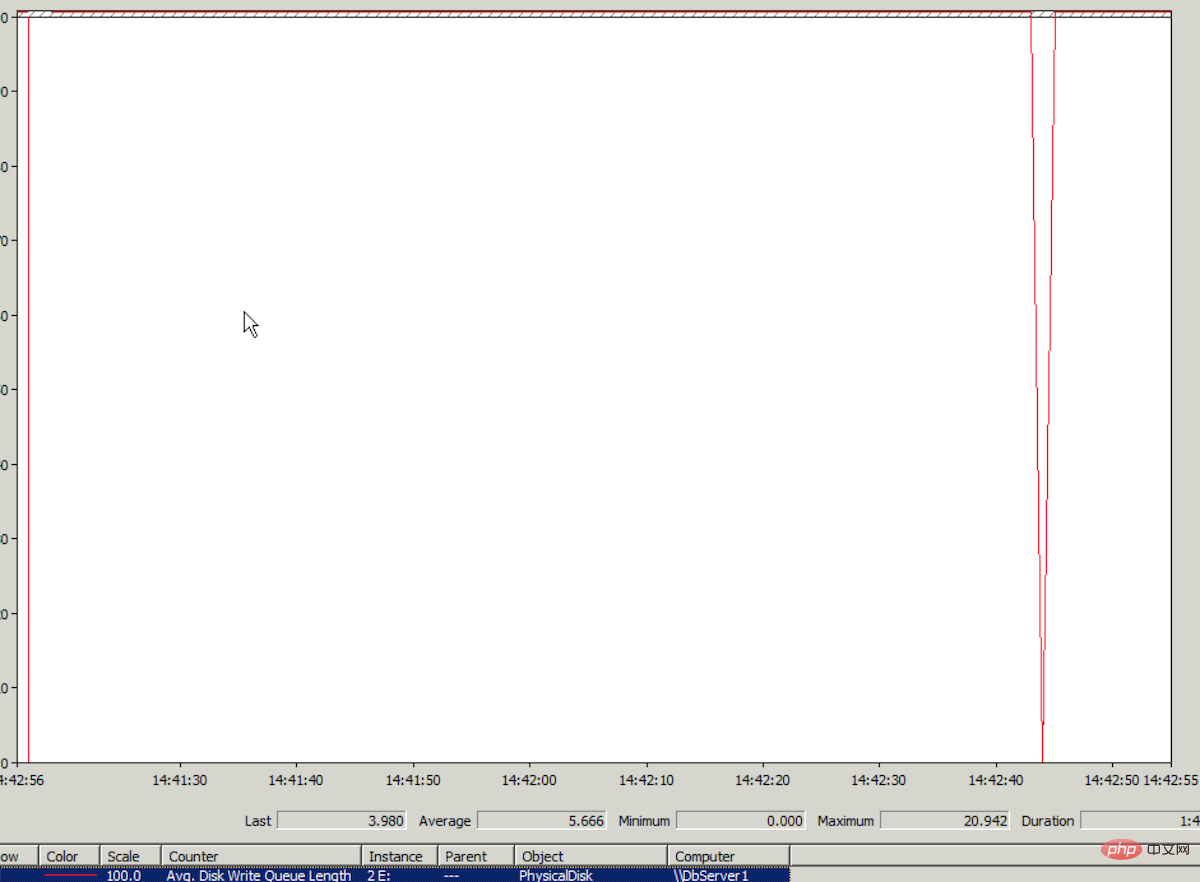
(为什么数据库写入超时会表现于日志文件所在的磁盘IO高?因为数据库恢复模式用的是Full,对数据库的数据写入,会先在日志中进行写入操作。)
这次问题与3月14日磁盘IO问题的表现是一样的,所以我们断定这次也是同样的原因,是云服务器所在集群的磁盘IO负载高引起的。
14:19,我们向阿里云提交了工单,特地在标题中加了“紧急”;
14:23,阿里云客服回复说正在核实我们提交的问题;
14:31,阿里云客服回复说已反馈给相关部门检查;
14:42,没有阿里云客服的进一步消息,我们就回复说“如果短时间内解决不了,希望尽快进行集群迁移”(3月14日就是通过集群迁移解决这个问题的,阿里云的技术人员也说过对于集群负载高引起的磁盘IO问题,目前唯一的解决办法就是集群迁移);
14:47,阿里云客服只回复说正在处理;
14:59,还是没消息,我们心急如焚(40分钟过去了,连个说法都没有),在工单中说:“能不能先做集群迁移?”;
然后,接到阿里云客服的电话,说集群中其他云服务器占用的磁盘IO高影响了我们,他们正在处理。。。
过了会,阿里云客服又打电话过来说可能是我们云服务器中的系统或应用导致服务器磁盘写入卡死,让我们重启一下云服务器。(这样的考虑可能是因为这时集群的负载已经降下来,但我们的云服务器磁盘IO还是高。)
15:23左右,我们重启了数据库服务器,但问题依旧。
15:30,阿里云客服终于决定进行集群迁移(从提交工单到决定集群迁移耗时1小10分钟)
15:45,完成集群迁移(上次迁移5分钟不到,这次用了15分钟,这也是阿里云客服所说的进行集群迁移所需的最长时间)
迁移之后,傻眼了,磁盘IO(Avg.Disk Write Queue Length)还是那么高!
为什么这次集群迁移不能像上次那样立即解决问题?我们猜测有两个可能的原因:
1、迁移后所在的集群磁盘IO负载依然高;
2、 云服务器上出现磁盘IO很高的这个分区放的都是数据库日志文件,可能这个时间段日志写入操作比平时频繁(但暴增几乎没有可能)而且所有日志文件在同一个分 区,超过了云服务器磁盘IO的某个极限,造成磁盘IO性能骤降(可能性比较大,依据是云计算之路-入阿里云后:解决images.cnblogs.com 响应速度慢的诡异问题)。虽然之前使用物理服务器时,日志文件也是放在同一个分区,从未出现过这个问题,但现在云服务器的磁盘IO能力无法与物理服务器相 比,而且磁盘IO会被集群上其他云服务器争抢(详见云计算之路-迁入阿里云后:问题的根源——买到她的“人”,却买不到她的“心”)。
不管是哪一个原因,要解决问题只有一招也是最后一招——减轻日志文件所在的磁盘分区的IO压力。
怎么减压呢?根据“迁入阿里云后的一些心得”一文中的“提高整体磁盘IO性能的小偏方”,另外购买一块磁盘空间,然后将存放博文内容的数据库CNBlogsText(大文本数据写入,对磁盘IO产生的压力很大)的日志文件移至独立的磁盘分区。
在SQL Server中,无法在线完成将数据库日志文件从一个磁盘分区移至另一个磁盘分区。需要先detach数据库,然后将日志文件复制至目标分区,然后再attach这个数据库;在attach时,将日志文件的位置修改为新的路径。
于是,在别无选择的情况下,我们CNBlogsText数据库进行detach操作,并且选择了drop connections,哪知在detach的过程中悲剧发生了,detach失败了,错误是:
Transaction (Process ID 124) was deadlocked on lock resources with another process and has been chosen as the deadlock victim. Rerun the transaction.
在 detach的过程中竟然发生了死锁,然后“被牺牲”了。让人困惑的是,不是drop connections吗,怎么还会发生死锁?可能drop connections是在detach操作正式开始前,在detach的过程中,还会发生数据库写入操作,这时的写入操作引发了deadlock。为什 么偏偏要让detach牺牲?不合情理。
detach失败后,CNBlogsText数据库就处于Single User状态。继续detach,同样的错误,同样的“被牺牲”。
于是,重启了一下SQL Server服务。重启之后,CNBlogsText数据库的状态变为了In Recovery。
这时时间已经到了16:45。
这样的In Recovery状态以前没遇到过,不知如何处理,也不敢轻举妄动。
过了一段时间,刷新了一下SQL Server的Databases列表,CNBlogsText数据库又显示为之前的Single User状态。(原来重启SQL Server之后,会自动先进入In Recovery状态,再进入到Single User状态)
针对Single User状态问题,在工单中咨询了阿里云客服,阿里云客服联系了数据库工程师,得到的建议是进行这样的操作:alter database $db_name SET multi_user
于是,执行了这样的SQL:
exec sp_dboption 'CNBlogsText', N'single', N'false'
出现错误提示:
Database 'CNBlogsText' is already open and can only have one user at a time.
Single User状态依旧,出现这个错误可能是因为这个数据库不断地有写入操作,抢占着Single User状态下只允许唯一的数据库连接。
(更新:后来从阿里云DBA那学习到解决这个问题的方法:
select spid from sys.sysprocesses where dbid=DB_ID('dbname'); --得到当前占用数据库的进程id kill [spid] go alter login [username] disable --禁用新的访问 go use cnblogstext go alter database cnblogstext set multi_user with rollback immediate go
)
当时的情形下,我们不够冷静,急着想完成detach操作。觉得屏蔽CNBlogsText数据库的所有写入操作可能需要禁止这台服务器的所有数据库连接,这样会影响整站的正常访问,所以没从这个角度下手。
这时时间已经到了17:08。
我们也准备了最最后一招,假如实在detach不了,假如日志文件也出了问题,我们可以通过数据文件恢复这个数据库。这个场景我们遇到过,也实际成功操作过,详见:SQL Server 2005数据库日志文件损坏的情况下如何恢复数据库。所需的SQL语句如下:
use master alter database dbname set emergency declare @databasename varchar(255) set @databasename='dbname' exec sp_dboption @databasename, N'single', N'true' --将目标数据库置为单用户状态 dbcc checkdb(@databasename,REPAIR_ALLOW_DATA_LOSS) dbcc checkdb(@databasename,REPAIR_REBUILD) exec sp_dboption @databasename, N'single', N'false'--将目标数据库置为多用户状态
即使最最后一招也失败了,我们在另外一台云服务器上有备份,在异地也有备份,都有办法恢复,只不过需要的恢复时间更长一些。
想到这些,内心平静了一些,认识到当前最重要的是抛开内疚、紧张、着急,冷静面对。
我们在工单中继续咨询阿里云客服,阿里云客服联系了数据库工程师,让我们加一下这位工程师的阿里旺旺。
我们的电脑上没装阿里旺旺,于是打算自己再试试,如果还是解决不了,再求助阿里云的数据库工程师。
在网上找了一个方法:SET DEADLOCK_PRIORITY NORMAL(来源),没有效果。
时间已经到了17:38。
这时,我们冷静地分析一下:detach时,因为死锁“被牺牲”;从单用户改为多用户时,提示“Database 'CNBlogsText' is already open and can only have one user at a time.”。可能都是因为程序中不断地对这个数据库有写入操作。试试修改一下程序,看看能不能屏蔽所有对这个数据库的写入操作,然后再将数据库恢复为多 用户状态。
修改好程序,18:00之后进行了更新。没想到更新之后,将单用户改为多用户的SQL就能执行了:
exec sp_dboption 'CNBlogsText', N'single', N'false'
于是,Single User状态消失,CNBlogsText数据库恢复了正常状态,然后尝试detach,一次成功。
接着将日志文件复制到新购的磁盘分区中,以新的日志路径attach数据库。attach成功之后,CNBlogsText数据库恢复正常,博客后台可以正常发布博文,CNBlogsText数据库日志文件所在分区的磁盘IO(单独的磁盘分区)也正常。问题就这么解决了。
当全部恢复正常,如释重负的时候,时间已经到了18:35。
原以为可以用更多的内存弥补云服务器磁盘IO性能低的不足。但万万没想到,云服务器的硬伤不是在磁盘IO性能低,而是在磁盘IO不稳定。
更多相关知识,请访问:PHP中文网!
Atas ialah kandungan terperinci 集群的最主要瓶颈是什么?. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1378
1378
 52
52

 Node berpindah sepenuhnya daripada Proxmox VE dan menyertai semula kluster
Feb 21, 2024 pm 12:40 PM
Node berpindah sepenuhnya daripada Proxmox VE dan menyertai semula kluster
Feb 21, 2024 pm 12:40 PM
Perihalan senario untuk nod mengosongkan sepenuhnya daripada ProxmoxVE dan menyertai semula kluster Apabila nod dalam kluster ProxmoxVE rosak dan tidak boleh dibaiki dengan cepat, nod yang rosak perlu ditendang keluar dari kluster dengan bersih dan maklumat baki mesti dibersihkan. Jika tidak, nod baharu yang menggunakan alamat IP yang digunakan oleh nod yang rosak tidak akan dapat menyertai kluster secara normal, selepas nod rosak yang telah dipisahkan daripada kluster dibaiki, walaupun ia tidak ada kaitan dengan kluster, ia akan; tidak dapat mengakses pengurusan web nod tunggal ini Di latar belakang, maklumat tentang nod lain dalam kelompok ProxmoxVE asal akan muncul, yang sangat menjengkelkan. Usir nod daripada kluster Jika ProxmoxVE ialah kluster hiper-tumpu Ceph, anda perlu log masuk ke mana-mana nod dalam kluster (kecuali nod yang anda mahu padamkan) pada sistem hos Debian, dan jalankan arahan
 Cara menggunakan Docker untuk mengurus dan mengembangkan kluster berbilang nod
Nov 07, 2023 am 10:06 AM
Cara menggunakan Docker untuk mengurus dan mengembangkan kluster berbilang nod
Nov 07, 2023 am 10:06 AM
Dalam era pengkomputeran awan hari ini, teknologi kontena telah menjadi salah satu teknologi paling popular di dunia sumber terbuka. Kemunculan Docker telah menjadikan pengkomputeran awan lebih mudah dan cekap, dan telah menjadi alat yang sangat diperlukan untuk pembangun dan kakitangan operasi dan penyelenggaraan. Aplikasi teknologi kluster berbilang nod digunakan secara meluas berdasarkan Docker. Melalui penggunaan kluster berbilang nod, kami boleh menggunakan sumber dengan lebih berkesan, meningkatkan kebolehpercayaan dan kebolehskalaan, dan juga menjadi lebih fleksibel dalam penggunaan dan pengurusan. Seterusnya, kami akan memperkenalkan cara menggunakan Docker untuk
 Kaedah pengoptimuman pangkalan data dalam persekitaran konkurensi tinggi PHP
Aug 11, 2023 pm 03:55 PM
Kaedah pengoptimuman pangkalan data dalam persekitaran konkurensi tinggi PHP
Aug 11, 2023 pm 03:55 PM
Kaedah pengoptimuman pangkalan data PHP dalam persekitaran konkurensi tinggi Dengan perkembangan pesat Internet, semakin banyak laman web dan aplikasi perlu menghadapi cabaran serentak yang tinggi. Dalam kes ini, pengoptimuman prestasi pangkalan data menjadi sangat penting, terutamanya untuk sistem yang menggunakan PHP sebagai bahasa pembangunan bahagian belakang. Artikel ini akan memperkenalkan beberapa kaedah pengoptimuman pangkalan data dalam persekitaran konkurensi tinggi PHP dan memberikan contoh kod yang sepadan. Menggunakan pengumpulan sambungan Dalam persekitaran konkurensi tinggi, penciptaan dan pemusnahan sambungan pangkalan data yang kerap boleh menyebabkan kesesakan prestasi. Oleh itu, menggunakan penyatuan sambungan boleh
 Apakah kluster biasa dalam php?
Aug 31, 2023 pm 05:45 PM
Apakah kluster biasa dalam php?
Aug 31, 2023 pm 05:45 PM
Kluster biasa dalam PHP termasuk kluster LAMP, kluster Nginx, kluster Memcached, kluster Redis dan kluster Hadoop. Pengenalan terperinci: 1. Kluster LAMP merujuk kepada gabungan Linux, Apache, MySQL dan PHP diedarkan kepada pelayan yang berbeza 2. Kelompok Nginx, Nginx ialah pelayan web berprestasi tinggi dan sebagainya.
 Cara menggunakan MongoDB untuk melaksanakan fungsi pengelompokan data dan pengimbangan beban
Sep 19, 2023 pm 01:22 PM
Cara menggunakan MongoDB untuk melaksanakan fungsi pengelompokan data dan pengimbangan beban
Sep 19, 2023 pm 01:22 PM
Cara menggunakan MongoDB untuk melaksanakan fungsi pengelompokan data dan pengimbangan beban Pengenalan: Dalam era data besar hari ini, pertumbuhan pesat volum data telah mengemukakan keperluan yang lebih tinggi untuk prestasi pangkalan data. Untuk memenuhi keperluan ini, pengelompokan data dan pengimbangan beban telah menjadi cara teknikal yang sangat diperlukan. Sebagai pangkalan data NoSQL yang matang, MongoDB menyediakan fungsi dan alatan yang kaya untuk menyokong pengelompokan data dan pengimbangan beban. Artikel ini akan memperkenalkan cara menggunakan MongoDB untuk melaksanakan fungsi pengelompokan data dan pengimbangan beban serta menyediakan kod khusus.
 Kaedah pelaksanaan kluster pelayan dalam dokumentasi Workerman
Nov 08, 2023 pm 08:09 PM
Kaedah pelaksanaan kluster pelayan dalam dokumentasi Workerman
Nov 08, 2023 pm 08:09 PM
Workerman ialah rangka kerja PHPSocket berprestasi tinggi yang membolehkan PHP mengendalikan komunikasi rangkaian tak segerak dengan lebih cekap. Dalam dokumentasi Workerman, terdapat arahan terperinci dan contoh kod tentang cara melaksanakan kluster pelayan. Untuk melaksanakan kluster pelayan, kita perlu menjelaskan konsep kluster pelayan terlebih dahulu. Kelompok pelayan menghubungkan berbilang pelayan ke rangkaian untuk meningkatkan prestasi sistem, kebolehpercayaan dan kebolehskalaan dengan berkongsi beban dan sumber. Dalam Workerman, anda boleh menggunakan dua kaedah berikut
 Apakah sistem kluster pelayan Linux? Apakah komponen yang disertakan?
Feb 22, 2024 pm 07:55 PM
Apakah sistem kluster pelayan Linux? Apakah komponen yang disertakan?
Feb 22, 2024 pm 07:55 PM
Linux, nama penuh GNU/Linux, ialah sistem pengendalian seperti Unix yang boleh digunakan dan disebarkan secara bebas. Ia ialah sistem pengendalian berbilang pengguna, berbilang tugas, berbilang benang dan berbilang CPU berdasarkan POSIX. Jadi apakah sistem kluster pelayan Linux Apakah komponen utamanya. Berikut adalah pengenalan kepada kandungan tertentu? Sistem kluster pelayan Linux ialah persekitaran pengkomputeran teragih berdasarkan sistem pengendalian Linux Ia terdiri daripada berbilang nod pelayan bebas disambungkan antara satu sama lain melalui rangkaian berkelajuan tinggi untuk menyelesaikan pelbagai tugas pengkomputeran secara kolaboratif. Sistem kluster mempunyai kebolehpercayaan yang tinggi, prestasi tinggi dan kebolehskalaan, dan boleh menyediakan pengguna dengan sokongan perkhidmatan yang stabil dan berkuasa. Melalui sistem kluster, pelayan boleh dibahagikan dengan berkesan kepada
 Bagaimana untuk mengkonfigurasi persekitaran kluster pangkalan data MySQL?
Jul 12, 2023 pm 02:52 PM
Bagaimana untuk mengkonfigurasi persekitaran kluster pangkalan data MySQL?
Jul 12, 2023 pm 02:52 PM
Bagaimana untuk mengkonfigurasi persekitaran kluster pangkalan data MySQL? Pengenalan: Dengan pembangunan Internet dan pertumbuhan berterusan volum data, pangkalan data telah menjadi salah satu sistem teras yang diperlukan untuk setiap perusahaan. Pada masa yang sama, untuk memastikan ketersediaan data yang tinggi dan keperluan prestasi membaca dan menulis, persekitaran kluster pangkalan data secara beransur-ansur menjadi pilihan perusahaan. Artikel ini akan memperkenalkan cara mengkonfigurasi persekitaran kluster pangkalan data MySQL dan menyediakan contoh kod yang sepadan. 1. Penyediaan persekitaran Sebelum mengkonfigurasi persekitaran kluster pangkalan data MySQL, kita perlu memastikan bahawa persediaan persekitaran berikut telah selesai: Pasang M