

❝本文学习知识点 redis五大数据类型数据类型:string、hash、list、set、sorted_set 五大类型各自的应用场景
❞
❝咔咔整理了一个路线图,打造一份面试宝典,准备按照这样的路线图进行编写文章,后期发现没有补充到的知识点在进行添加。也期待各位伙伴一起来帮助补充一下。评论区见哦!
❞

添加 / 修改数据:set key value
获取数据:get key
删除数据:del key
添加 / 修改多个数据:mset key value key1 value1
获取多个数据:mget key key1
追加信息到原始数据后边(不存在时则添加):append key value
设置数值增加指定范围的值:incr key 默认每次加1 | incrby key value 每次新增value设置数据减少指定范围:decr key | decrby key value 跟新增是一回事
「应用场景」
控制数据库表主键id,为数据库表提供主键生成策略,保证数据表主键的一致性。
设置过期时间:setex key seconds value
「应用场景」
实现限制时间投票功能:例如一个微信一个小时可以投一次 实现热点信息:例如电商行业热门商品、新闻网站热门新闻
微博大V主页高频的访问,对于粉丝数、关注数、微博数都需要时时更新。这个就属于高频信息了,我们就可以使用redis的string类型来解决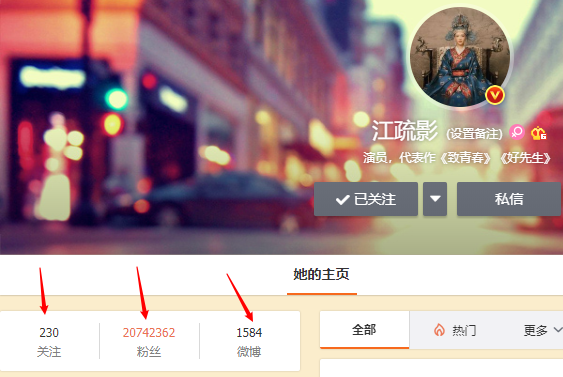 在redis中为大V设定用户信息,以用户主键和属性为键值,以下为实现案例。
在redis中为大V设定用户信息,以用户主键和属性为键值,以下为实现案例。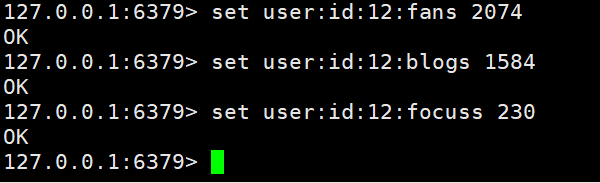 在这里需要简单的说一下key的命名规则:以表名+主键+主键值+字段 :字段值。以这样的规则来命名就可以很好的来管理我们的键值。
在这里需要简单的说一下key的命名规则:以表名+主键+主键值+字段 :字段值。以这样的规则来命名就可以很好的来管理我们的键值。
我们还可以使用另外一种方式来实现,就是键后边直接跟一个结构,例如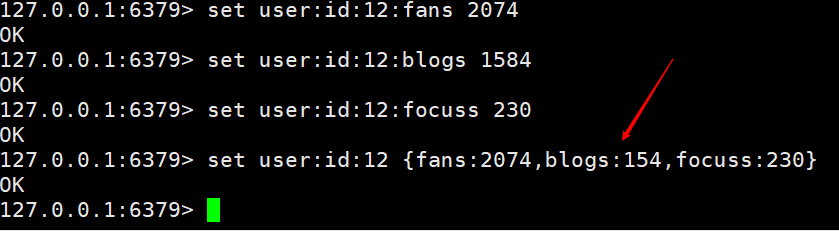 以上的俩种方式都是可以实现的,只是第一种可以很方便的对任意一个值进行管理,第二种是改一个都得改一次,看业务场景,定时刷新就行。
以上的俩种方式都是可以实现的,只是第一种可以很方便的对任意一个值进行管理,第二种是改一个都得改一次,看业务场景,定时刷新就行。
添加 / 修改数据:hset key field value
获取数据:hget key field | hgetall key
删除数据:hdel key field field1
添加 / 修改多个数据:hmset key field value field1 value1
获取多个数据:hmget key field field1
获取表中字段数量:hlen key
获取表中是否存在某个字段:hexists key field
获取hash表中所有的字段值:hkeys key
获取hash表中所有的字段值:hvals key
设置指定字段的数值增加指定范围的值:hincrby key field increment | hincrbyfloat key field increment
此图来源于网络非自制,只是模拟购物车场景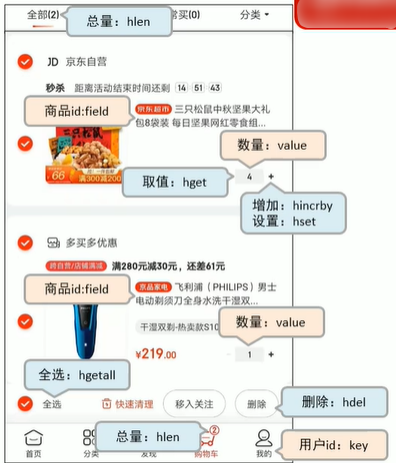 在上图中,我们可以看到购物车里的信息,下来咱们使用redis来对这个购物车的实现。
在上图中,我们可以看到购物车里的信息,下来咱们使用redis来对这个购物车的实现。
这里实现了一个添加购物车和获取购物车,keys的命名为 表名+主键+主键值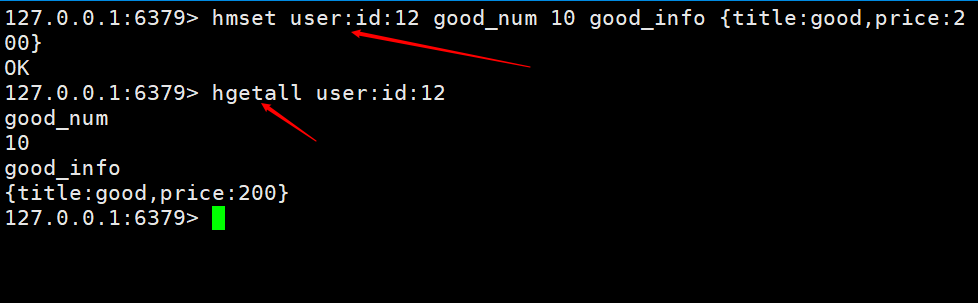 在上图中,我们会有一个问题就是商品信息存储会大量重复,所有我们也需要将商品单独给一直hash。如下图,只存储商品id
在上图中,我们会有一个问题就是商品信息存储会大量重复,所有我们也需要将商品单独给一直hash。如下图,只存储商品id 这里提供了俩种设置方式,一种是设置多个字段,一种是直接存储为json。信息不经常变动的话可以使用json
这里提供了俩种设置方式,一种是设置多个字段,一种是直接存储为json。信息不经常变动的话可以使用json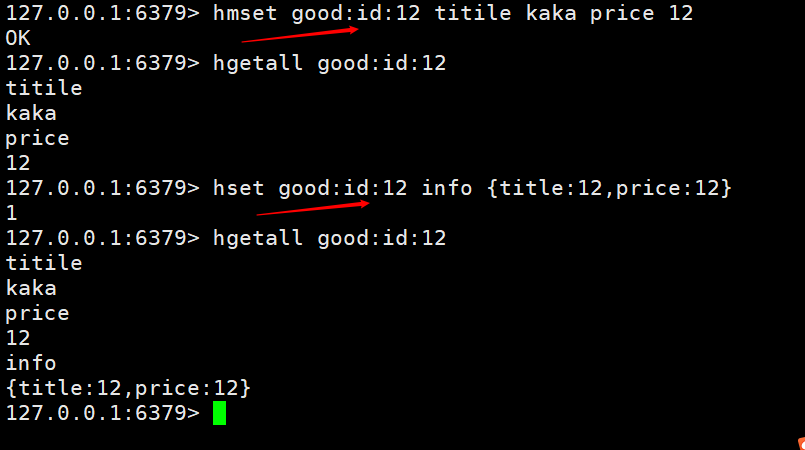 给大家在提供一个方法
给大家在提供一个方法hsetnx key field value,如果有则不进行添加,没有则添加。这个功能就使用在不同的用户添加同样的商品时不会执行覆盖和无用操作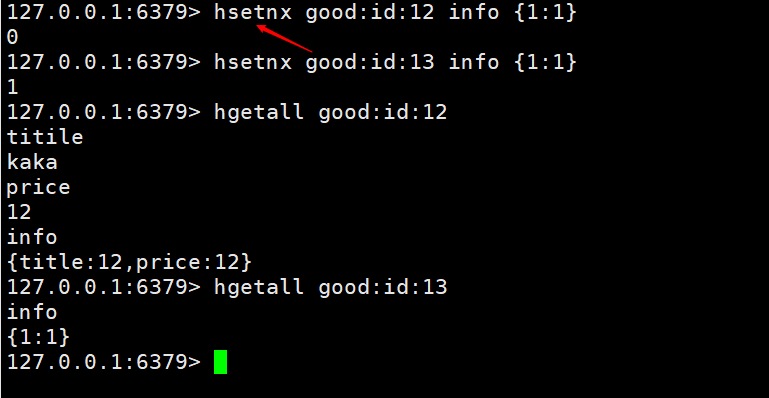
数据存储需求:存储多个数据,并对数据进行存储空间的顺序进行区分 需要的数据结构:一个存储空间保存多个数据,且通过数据可以体现进入顺序 list类型:保存多个数据,底层使用双向链表存储结构实现
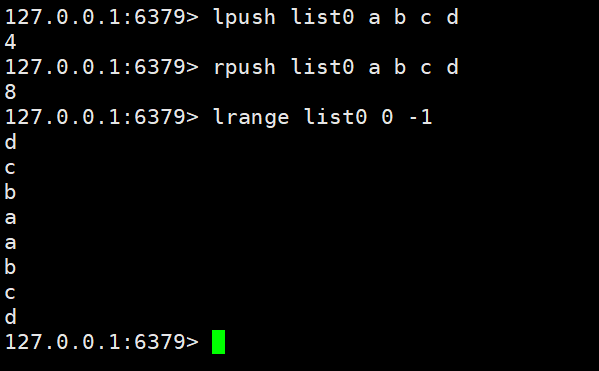
添加 / 修改数据:lpush key value value1 | rpush key value value1
获取数据:lrange key start end | lindex key index | llen key
删除数据:rpop key | lpop key
在规定时间内获取并移除数据:blpop key1 key2 timeout | brpop key1 key2 timeout
这个功能简单的写一个案例,容易理解
左边这个终端指令执行后会等待30秒的时间返回删除的数据
当右边的添加指令执行后左边会直接返回返回删除的数据
在上边我们知道了list的基础操作 执行 lpop key 或者 rpop key可以从做或者从右进行删除,但是现在有个场景是朋友圈点赞业务,然后从中间取消数据。案例如下图
我们先往list5里边添加 a b c d
然后移除c
在查看就剩下a b d了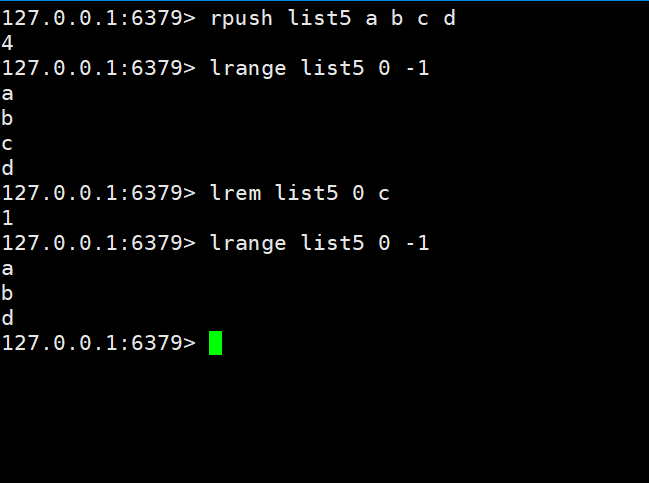
新的存储需求:存储大量的数据,在查询方便提供更高的效率 需要的存储结构:能够保存大量的数据,高效的内部存储机制,便于查询 set类型:与hash存储结构完全相同,仅存储键,不存储值(nil),并且值是不允许重复的
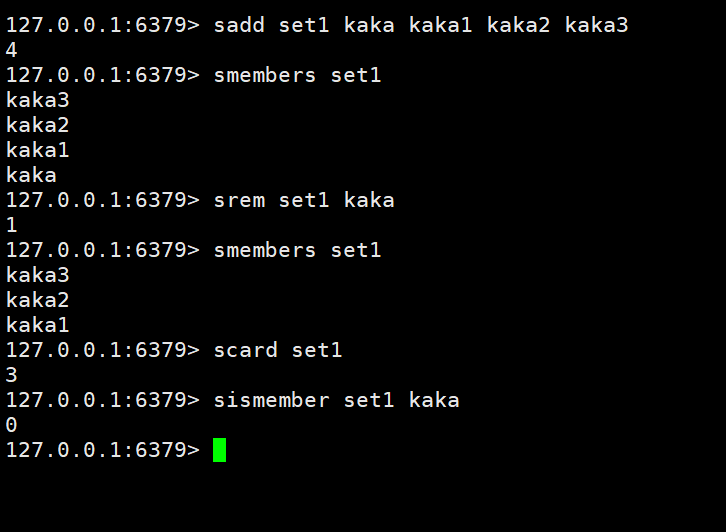
添加 / 修改数据:sadd key member member1
获取数据:smembers key
删除数据:srem key member1
获取集合数据总量:scard key
判断集合中是否包含指定数据:sismember key member
随机获取集合中指定数量的数据:srandmember key count
随机获取集合中某个数据并将改数据集移除集合:spop key
随机推送热点信息、热点新闻、热卖旅游、应用app推荐、关注推荐等
由于最近咔咔在写discuz,这个案例就以实现关注推荐。
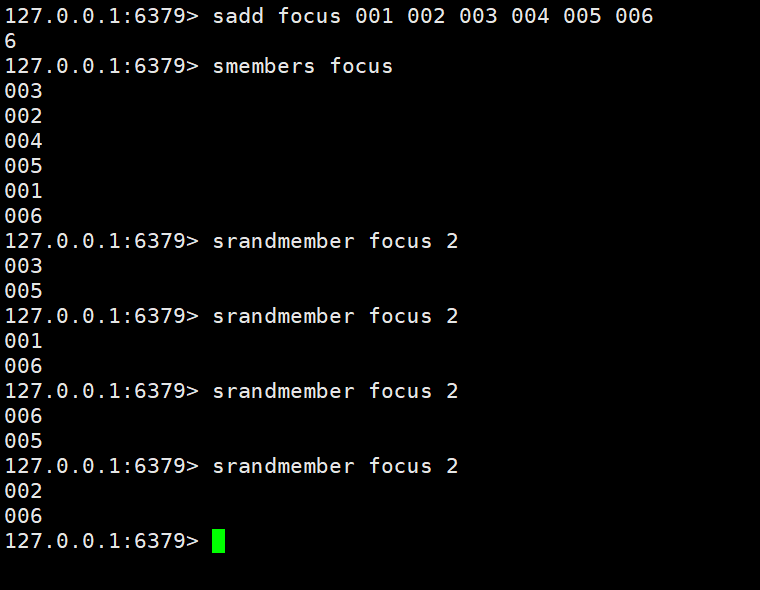
案例一:根据一定的推荐机制往set里边存放对应的用户,然后每次进行随机获取2位需要推荐的用户
案例二:根据一定的推荐机制往set里边存放对应的用户,然后根据日期每天推荐的用户都不能重复

俩个集合的交、并、差集
<span style="display: block; background: url(https://my-wechat.mdnice.com/point.png); height: 30px; width: 100%; background-size: 40px; background-repeat: no-repeat; background-color: #272822; margin-bottom: -7px; border-radius: 5px; background-position: 10px 10px;"></span><code class="hljs" style="overflow-x: auto; padding: 16px; color: #ddd; display: -webkit-box; font-family: Operator Mono, Consolas, Monaco, Menlo, monospace; font-size: 12px; -webkit-overflow-scrolling: touch; letter-spacing: 0px; padding-top: 15px; background: #272822; border-radius: 5px;"><span class="hljs-selector-tag" style="color: #f92672; font-weight: bold; line-height: 26px;">sinter</span> <span class="hljs-selector-tag" style="color: #f92672; font-weight: bold; line-height: 26px;">key</span> <span class="hljs-selector-tag" style="color: #f92672; font-weight: bold; line-height: 26px;">key1</span><br/><span class="hljs-selector-tag" style="color: #f92672; font-weight: bold; line-height: 26px;">sunion</span> <span class="hljs-selector-tag" style="color: #f92672; font-weight: bold; line-height: 26px;">key</span> <span class="hljs-selector-tag" style="color: #f92672; font-weight: bold; line-height: 26px;">key1</span><br/><span class="hljs-selector-tag" style="color: #f92672; font-weight: bold; line-height: 26px;">sdiff</span> <span class="hljs-selector-tag" style="color: #f92672; font-weight: bold; line-height: 26px;">key</span> <span class="hljs-selector-tag" style="color: #f92672; font-weight: bold; line-height: 26px;">key1</span><br/></code>
俩个集合的交、并、差集并存储到指定集合中
<span style="display: block; background: url(https://my-wechat.mdnice.com/point.png); height: 30px; width: 100%; background-size: 40px; background-repeat: no-repeat; background-color: #272822; margin-bottom: -7px; border-radius: 5px; background-position: 10px 10px;"></span><code class="hljs" style="overflow-x: auto; padding: 16px; color: #ddd; display: -webkit-box; font-family: Operator Mono, Consolas, Monaco, Menlo, monospace; font-size: 12px; -webkit-overflow-scrolling: touch; letter-spacing: 0px; padding-top: 15px; background: #272822; border-radius: 5px;"><span class="hljs-selector-tag" style="color: #f92672; font-weight: bold; line-height: 26px;">sinterstore</span> <span class="hljs-selector-tag" style="color: #f92672; font-weight: bold; line-height: 26px;">destination</span> <span class="hljs-selector-tag" style="color: #f92672; font-weight: bold; line-height: 26px;">key1</span> <span class="hljs-selector-tag" style="color: #f92672; font-weight: bold; line-height: 26px;">key2</span><br/><span class="hljs-selector-tag" style="color: #f92672; font-weight: bold; line-height: 26px;">sunionstore</span> <span class="hljs-selector-tag" style="color: #f92672; font-weight: bold; line-height: 26px;">destination</span> <span class="hljs-selector-tag" style="color: #f92672; font-weight: bold; line-height: 26px;">key1</span> <span class="hljs-selector-tag" style="color: #f92672; font-weight: bold; line-height: 26px;">key2</span><br/><span class="hljs-selector-tag" style="color: #f92672; font-weight: bold; line-height: 26px;">sdiffstore</span> <span class="hljs-selector-tag" style="color: #f92672; font-weight: bold; line-height: 26px;">destination</span> <span class="hljs-selector-tag" style="color: #f92672; font-weight: bold; line-height: 26px;">key1</span> <span class="hljs-selector-tag" style="color: #f92672; font-weight: bold; line-height: 26px;">key2</span><br/></code>
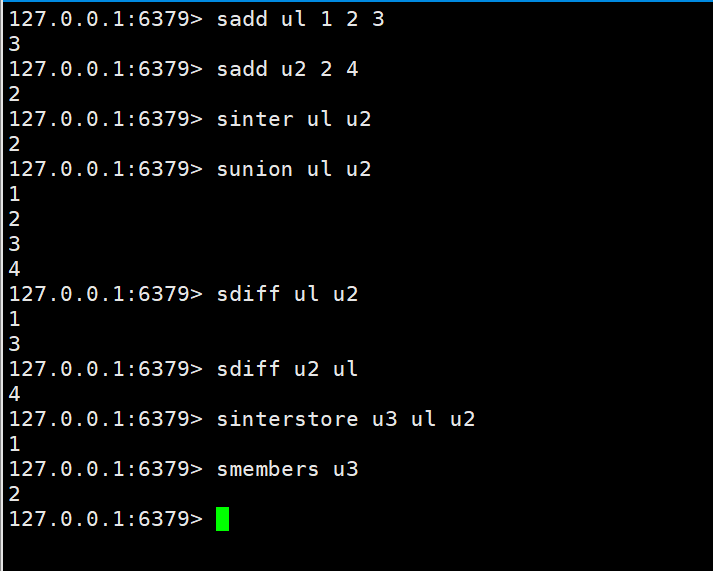 案例:我们需要挖掘一个信息的共同好友。例如微信公众号的共同关注好友数量、QQ添加新好友的推荐机制、深度挖掘用户直接的联系
案例:我们需要挖掘一个信息的共同好友。例如微信公众号的共同关注好友数量、QQ添加新好友的推荐机制、深度挖掘用户直接的联系
就根据上述案例,我们可以使用差集来实现qq的有可能认识的好友。
PV直接使用string类型的incr统计即可
UV和IP都是独立不重复的,使用set来操作。
在上边我们知道set有一个特性就是不能重复,我们就可以根据这一点来轻松实现这个功能。然后使用scard key 来统计数量。
至于UV是独立访客,使用本地的cookie来实现就可以,方法一样把cookie传给redis做记录即可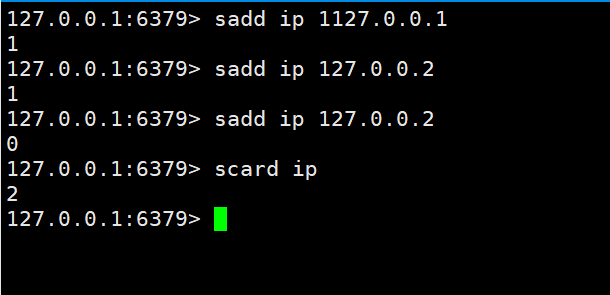
在之前的四个类型中都不支持排序的,下来咱们看的sorted_set类型是既支持存储大数据,也支持排序功能
添加数据:zadd key score member
获取数据:zrange key start stop | zrevrange key start stop
删除数据:zrem key member
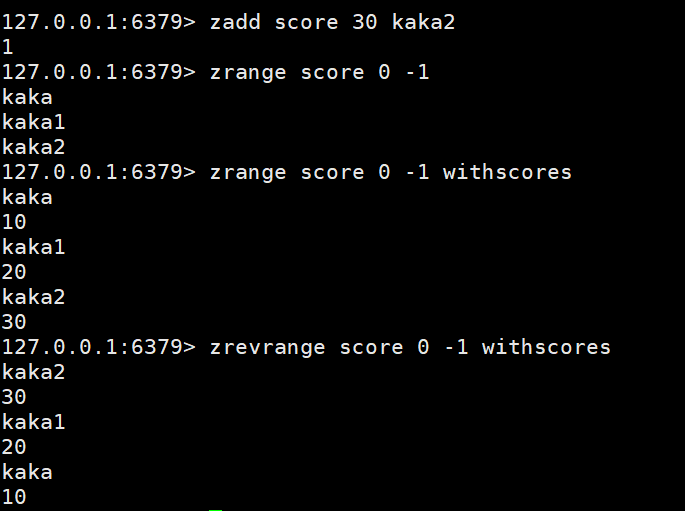 按条件获取数据:
按条件获取数据:zrangebyscore key min max limit | zrevrangescore key max min
条件删除数据:zremrangebyrank key start stop | zremrangebyscore key min max
获取集合数据总量:zcard key | zcount key min max
集合交、并操作:zinterstore destination numkeys key | zunionstore destination numkeys key(这个指令就不做演示了,可以自己查看文档。跟set有点类似,只不过会把所有交集的和给加起来。然后这里边有个numkeys这个参数是一共几个key进行计算 后边的key就需要几个)
获取数据对应的索引:zrank key member | zrevrank key member
socre值获取与修改:zscore key member | zincrby key increment member
相关推荐:《<a href="https://www.php.cn/redis/" target="_blank">redis教程</a>》
以上就是redis数据类型的简单介绍和具体应用,在后文中会针对具体需求在进行实战。
❝坚持学习、坚持写博、坚持分享是咔咔从业以来一直所秉持的信念。希望在偌大互联网中咔咔的文章能带给你一丝丝帮助。我们下期再见。
❞
Atas ialah kandungan terperinci 一文搞定Redis五大数据类型及应用场景. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 Perisian pangkalan data yang biasa digunakan
Perisian pangkalan data yang biasa digunakan
 Apakah pangkalan data dalam memori?
Apakah pangkalan data dalam memori?
 Yang manakah mempunyai kelajuan bacaan yang lebih pantas, mongodb atau redis?
Yang manakah mempunyai kelajuan bacaan yang lebih pantas, mongodb atau redis?
 Cara menggunakan redis sebagai pelayan cache
Cara menggunakan redis sebagai pelayan cache
 Bagaimana redis menyelesaikan ketekalan data
Bagaimana redis menyelesaikan ketekalan data
 Bagaimanakah mysql dan redis memastikan konsistensi penulisan dua kali?
Bagaimanakah mysql dan redis memastikan konsistensi penulisan dua kali?
 Apakah data yang biasanya disimpan oleh redis cache?
Apakah data yang biasanya disimpan oleh redis cache?
 Apakah 8 jenis data redis
Apakah 8 jenis data redis








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



