

使用Node.js+Chrome+Puppeteer实现网站的爬取


视频教程推荐:nodejs 教程
我们将学到什么?
在本教程中,您将学习如何使用 JavaScript 自动化和清理 web 。要做到这一点,我们将使用 Puppeteer 。Puppeteer是一个允许我们控制无头Chrome 的 Node 库 API。Headless Chrome是一种在不真实运行 Chrome 的情况下运行 Chrome 浏览器的方法。
如果这一切都没有意义,您真正需要知道的是,我们将编写 JavaScript 代码,使 Google Chrome 实现自动化。
开始之前
开始之前,您需要在计算机上安装 Node 8+。您可以在此处进行安装。确保选择「当前」版本 8+ 版本。
如果您以前从未使用过 Node 并想学习,请查看:学习 Node JS 3 种最佳在线 Node JS 课程。
安装完 Node 后,创建一个新的项目文件夹并安装 Puppeteer。 Puppeteer 附带了 Chromium 的最新版本,该版本可以与 API 一起使用:
npm install --save puppeteer
例 #1 — 截图
安装完 Puppeteer 之后,我们将首先介绍一个简单的示例。此示例来自Puppeteer 文档(进行了少量更改)。我们将通过代码逐步介绍对您访问的网站如何截图。
首先,创建一个名为test.js的文件,然后复制以下代码:
const puppeteer = require('puppeteer');
async function getPic() {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://google.com');
await page.screenshot({path: 'google.png'});
await browser.close();
}
getPic();让我们逐行浏览这个例子。
- 第1行: 我们需要我们先前安装的 Puppeteer 依赖项
-
第3-10行:这是我们的主函数
getPic()。该函数将保存我们所有的自动化代码。 -
第12行:在第12行上,我们调用
getPic()函数。
需要注意的是,getPic()函数是一个异步函数,并利用了新的ES 2017async/await功能。由于这个函数是异步的,所以当调用时它返回一个Promise。当Async函数最终返回值时,Promise将被解析(如果存在错误,则Reject)。
由于我们使用的是async函数,因此我们可以使用await表达式,该表达式将暂停函数执行并等待Promise解析后再继续。 如果现在所有这些都没有意义,那也没关系。随着我们继续学习教程,它将变得更加清晰。
现在,我们概述了主函数,让我们深入了解其内部功能:
- 第4行:
const browser = await puppeteer.launch();
这是我们实际启动 puppeteer 的地方。实际上,我们正在启动 Chrome 实例,并将其设置为等于我们新创建的browser变量。由于我们使用了await关键字,因此该函数将在此处暂停,直到Promise解析(直到我们成功创建 Chrome 实例或出错)为止。
- 第5行:
const page = await browser.newPage();
在这里,我们在自动浏览器中创建一个新页面。我们等待新页面打开并将其保存到我们的page变量中。
- 第6行:
await page.goto('https://google.com');使用我们在代码的最后一行中创建的page,现在可以告诉page导航到URL。在此示例中,导航到 google。我们的代码将暂停,直到页面加载完毕。
- 第7行:
await page.screenshot({path: 'google.png'});现在,我们告诉 Puppeteer 截取当前页面的屏幕。screenshot()方法将自定义的.png屏幕截图的保存位置的对象作为参数。同样,我们使用了await关键字,因此在执行操作时我们的代码会暂停。
- 第9行:
await browser.close();
最后,我们到了getPic()函数的结尾,并且关闭了browser。
运行示例
您可以使用 Node 运行上面的示例代码:
node test.js
这是生成的屏幕截图:
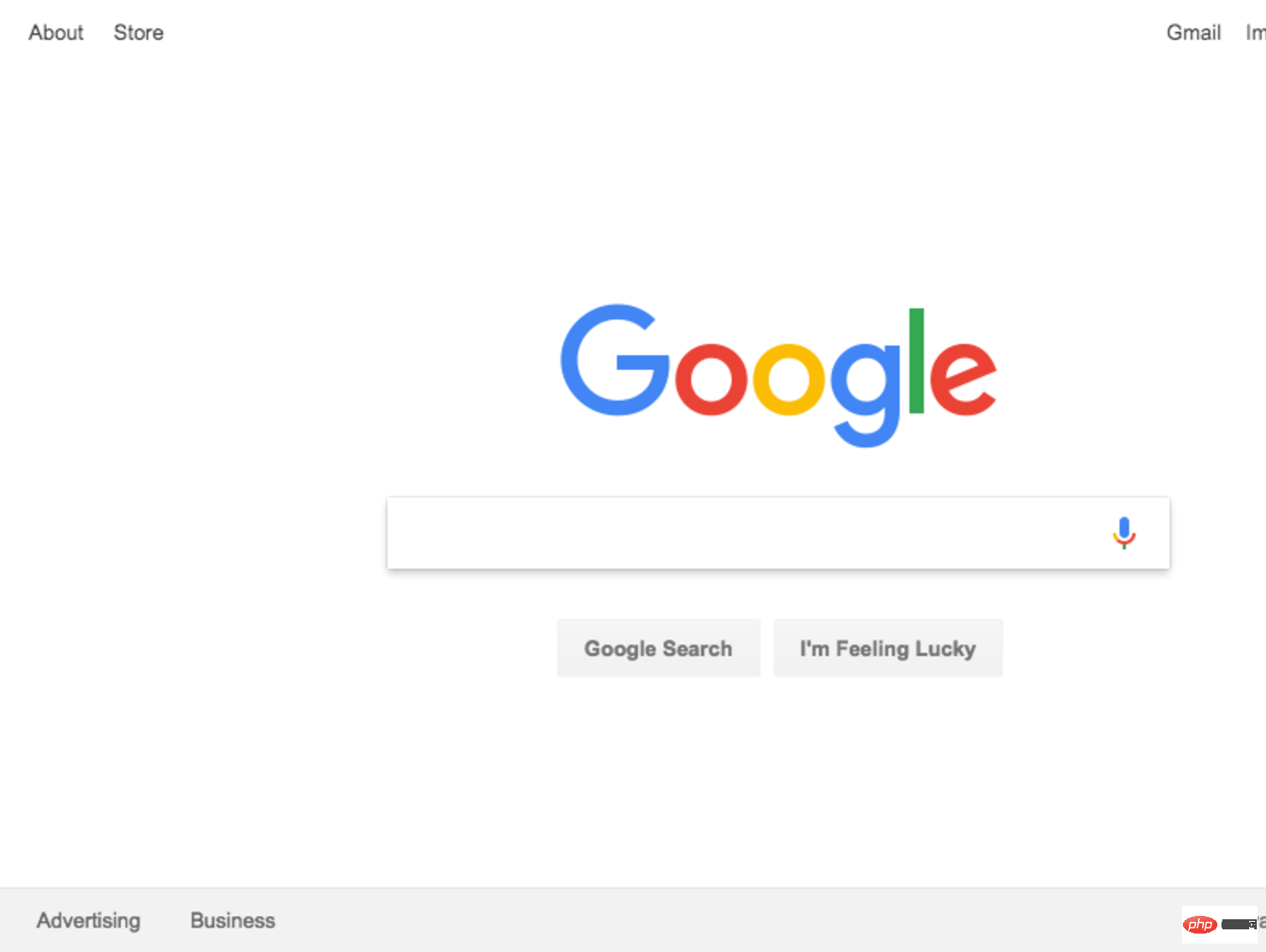
太棒了!为了增加乐趣(并简化调试),我们可以不以无头方式运行代码。
这到底是什么意思?自己尝试一下,看看吧。更改代码的第4行从:
const browser = await puppeteer.launch();
改为:
const browser = await puppeteer.launch({headless: false});然后使用 Node 再次运行:
node test.js
太酷了吧?当我们使用{headless:false}运行时,您可以真实看到 Google Chrome 按照您的代码工作。
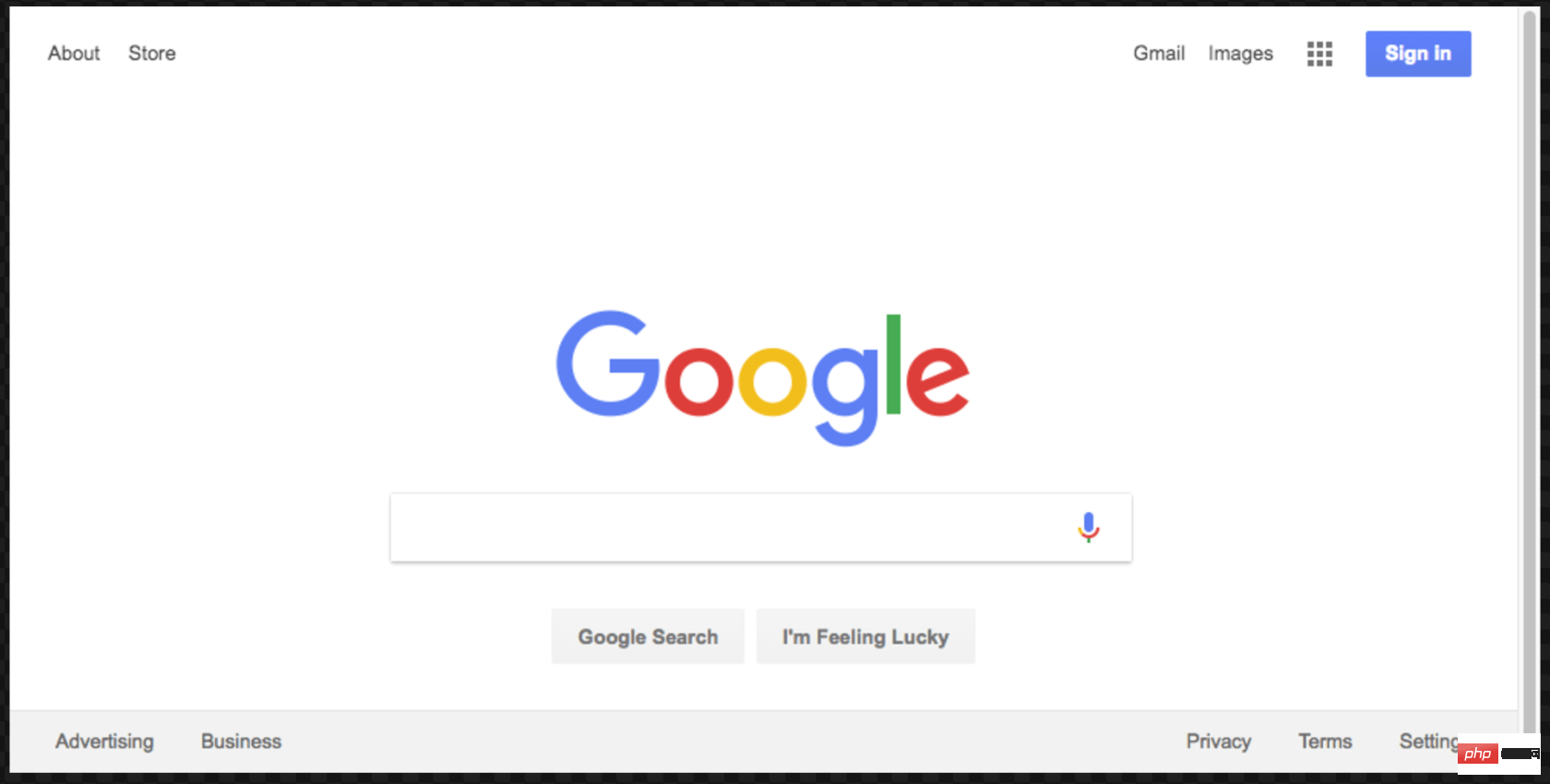
在继续之前,我们将对这段代码做最后一件事。还记得我们的屏幕截图有点偏离中心吗?那是因为我们的页面有点小。我们可以通过添加以下代码行来更改页面的大小:
await page.setViewport({width: 1000, height: 500})这个屏幕截图更好看点:
这是本示例的最终代码:
const puppeteer = require('puppeteer');
async function getPic() {
const browser = await puppeteer.launch({headless: false});
const page = await browser.newPage();
await page.goto('https://google.com');
await page.setViewport({width: 1000, height: 500})
await page.screenshot({path: 'google.png'});
await browser.close();
}
getPic();示例 #2-让我们抓取一些数据
既然您已经了解了 Headless Chrome 和 Puppeteer 的工作原理,那么让我们看一个更复杂的示例,在该示例中我们事实上可以抓取一些数据。
首先, 在此处查看 Puppeteer 的 API 文档。 如您所见,我们有很多方法可以使用, 不仅可以点击网站,还可以填写表格,输入内容和读取数据。
在本教程中,我们将抓取 Books To Scrape ,这是一家专门设置的假书店,旨在帮助人们练习抓取。
在同一目录中,创建一个名为scrape.js的文件,并插入以下样板代码:
const puppeteer = require('puppeteer');
let scrape = async () => {
// 实际的抓取从这里开始...
// 返回值
};
scrape().then((value) => {
console.log(value); // 成功!
});理想情况下,在看完第一个示例之后,上面的代码对您有意义。如果没有,那没关系!
我们上面所做的需要以前安装的puppeteer依赖关系。然后我们有scraping()函数,我们将在其中填入抓取代码。此函数将返回值。最后,我们调用scraping函数并处理返回值(将其记录到控制台)。
我们可以通过在scrape函数中添加一行代码来测试以上代码。试试看:
let scrape = async () => {
return 'test';
};现在,在控制台中运行node scrape.js。您应该返回test!完美,我们返回的值正在记录到控制台。现在我们可以开始补充我们的scrape函数。
步骤1:设置
我们需要做的第一件事是创建浏览器实例,打开一个新页面,然后导航到URL。我们的操作方法如下:
let scrape = async () => {
const browser = await puppeteer.launch({headless: false});
const page = await browser.newPage();
await page.goto('http://books.toscrape.com/');
await page.waitFor(1000); // Scrape browser.close();
return result;};太棒了!让我们逐行学习它:
首先,我们创建浏览器,并将headless模式设置为false。这使我们可以准确地观察发生了什么:
const browser = await puppeteer.launch({headless: false});然后,我们在浏览器中创建一个新页面:
const page = await browser.newPage();
接下来,我们转到books.toscrape.com URL:
await page.goto('http://books.toscrape.com/');我选择性地添加了1000毫秒的延迟。尽管通常没有必要,但这将确保页面上的所有内容都加载:
await page.waitFor(1000);
最后,完成所有操作后,我们将关闭浏览器并返回结果。
browser.close(); return result;
步骤2:抓取
正如您现在可能已经确定的那样,Books to Scrape 拥有大量的真实书籍和这些书籍的伪造数据。我们要做的是选择页面上的第一本书,然后返回该书的标题和价格。这是要抓取的图书的主页。我有兴趣点第一本书(下面红色标记)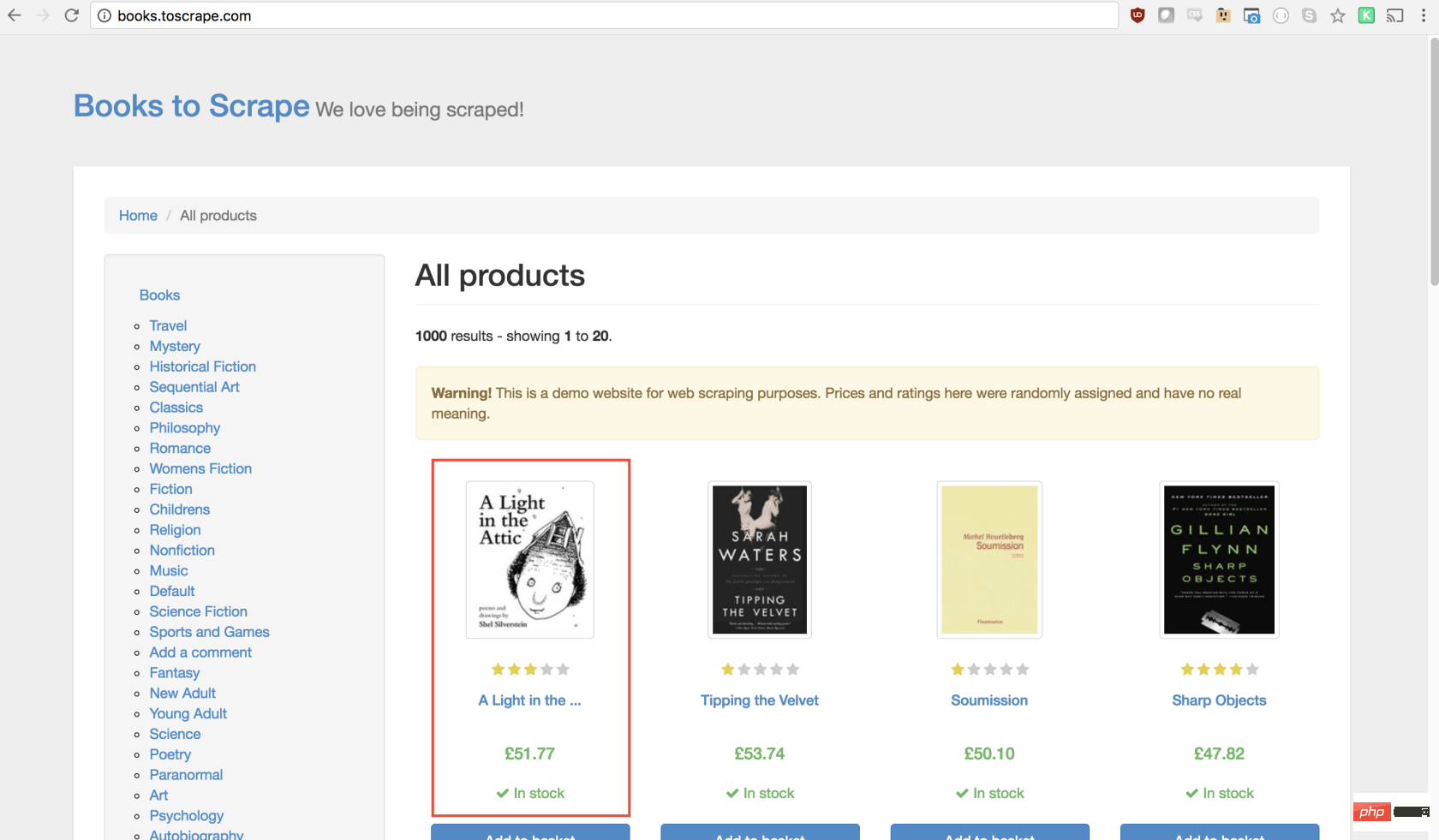
查看 Puppeteer API,我们可以找到单击页面的方法:
page.click(selector[, options])
-
selector用于选择要单击的元素的选择器,如果有多个满足选择器的元素,则将单击第一个。
幸运的是,使用 Google Chrome 开发者工具可以非常轻松地确定特定元素的选择器。只需右键单击图像并选择检查: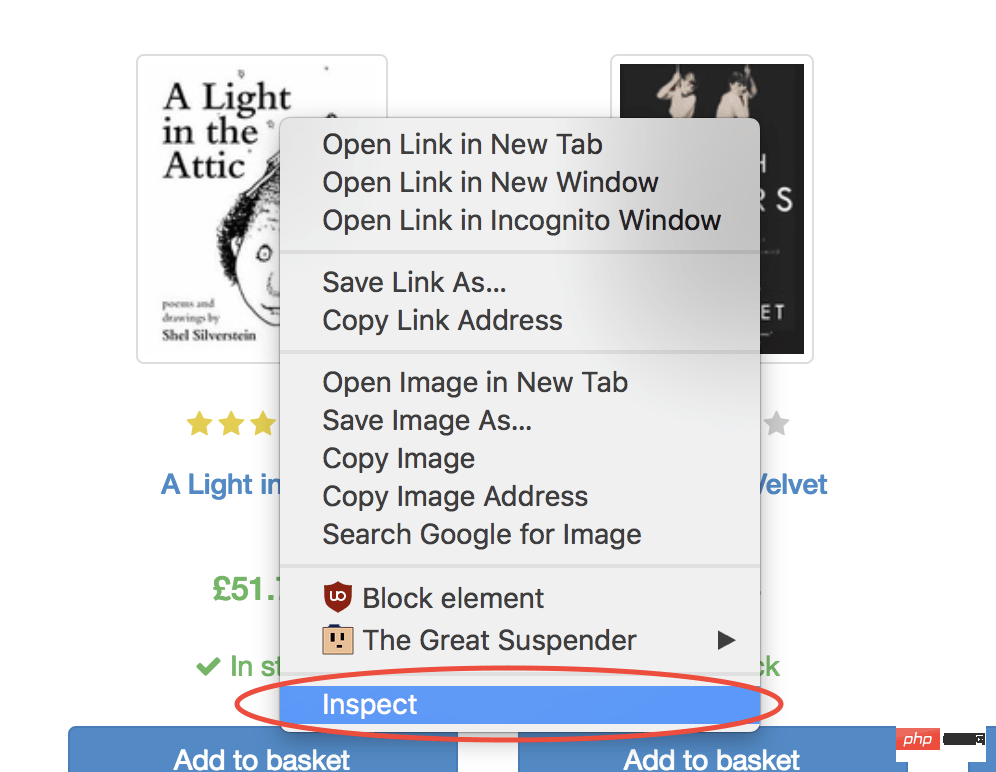
这将打开元素面板,突出显示该元素。现在,您可以单击左侧的三个点,选择复制,然后选择复制选择器:
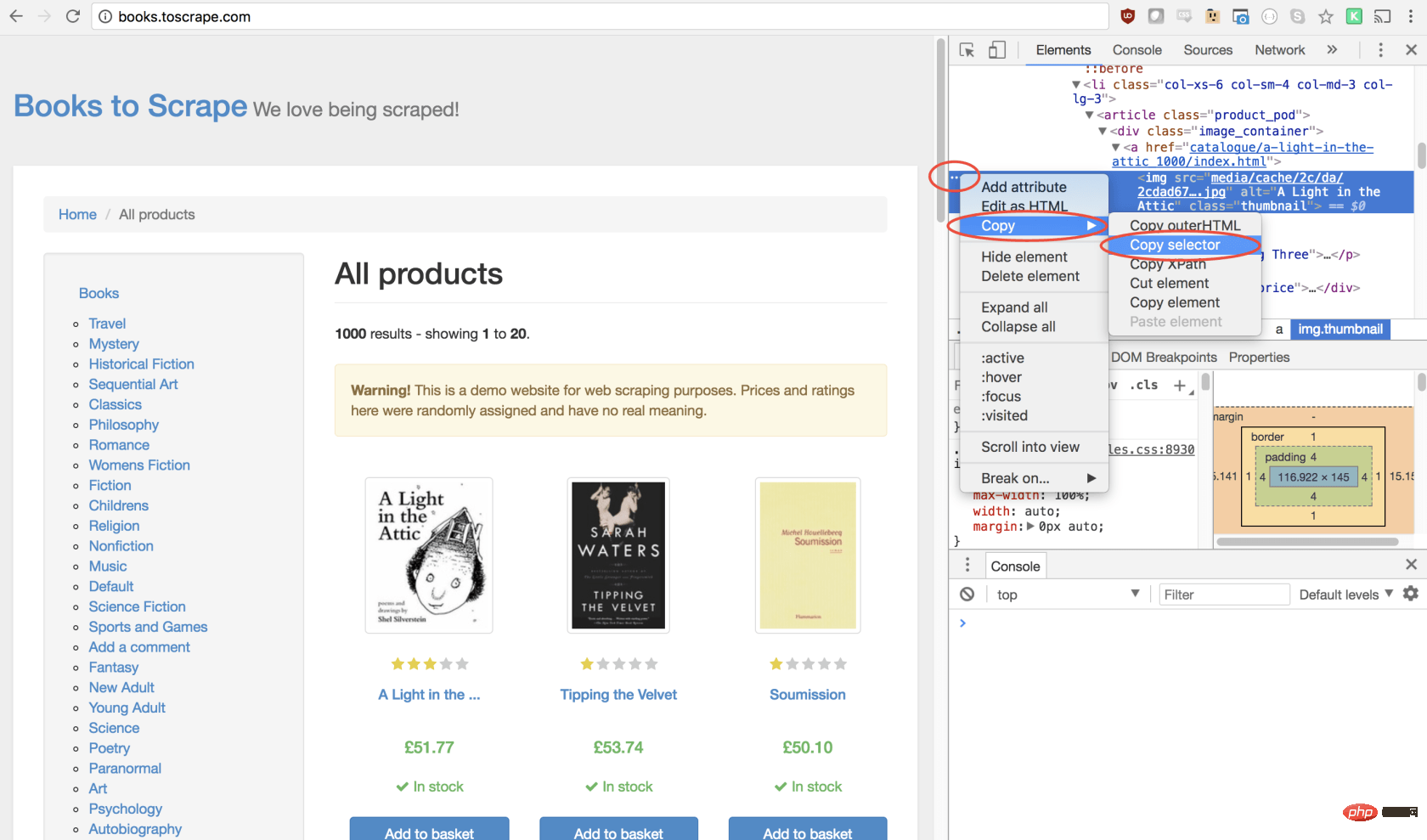
太棒了!现在,我们复制了选择器,并且可以将click方法插入程序。像这样:
await page.click('#default > p > p > p > p > section > p:nth-child(2) > ol > li:nth-child(1) > article > p.image_container > a > img');我们的窗口将单击第一个产品图像并导航到该产品页面!
在新页面上,我们对商品名称和商品价格均感兴趣(以下以红色概述)
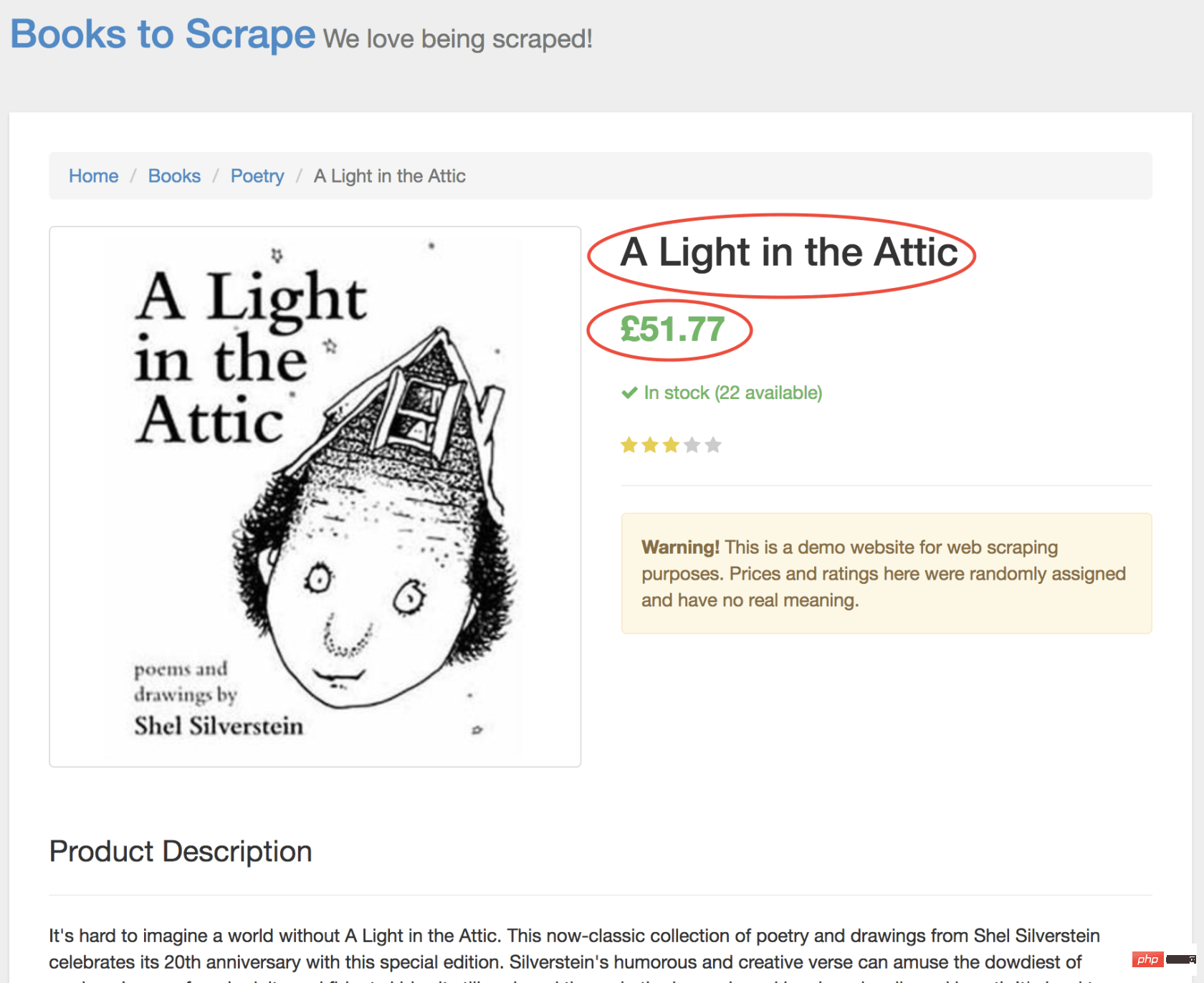
为了检索这些值,我们将使用page.evaluate()方法。此方法使我们可以使用内置的 DOM 选择器,例如querySelector()。
我们要做的第一件事是创建page.evaluate()函数,并将返回值保存到变量result中:
const result = await page.evaluate(() => {// return something});在函数里,我们可以选择所需的元素。我们将使用 Google Developers 工具再次解决这一问题。右键单击标题,然后选择检查:
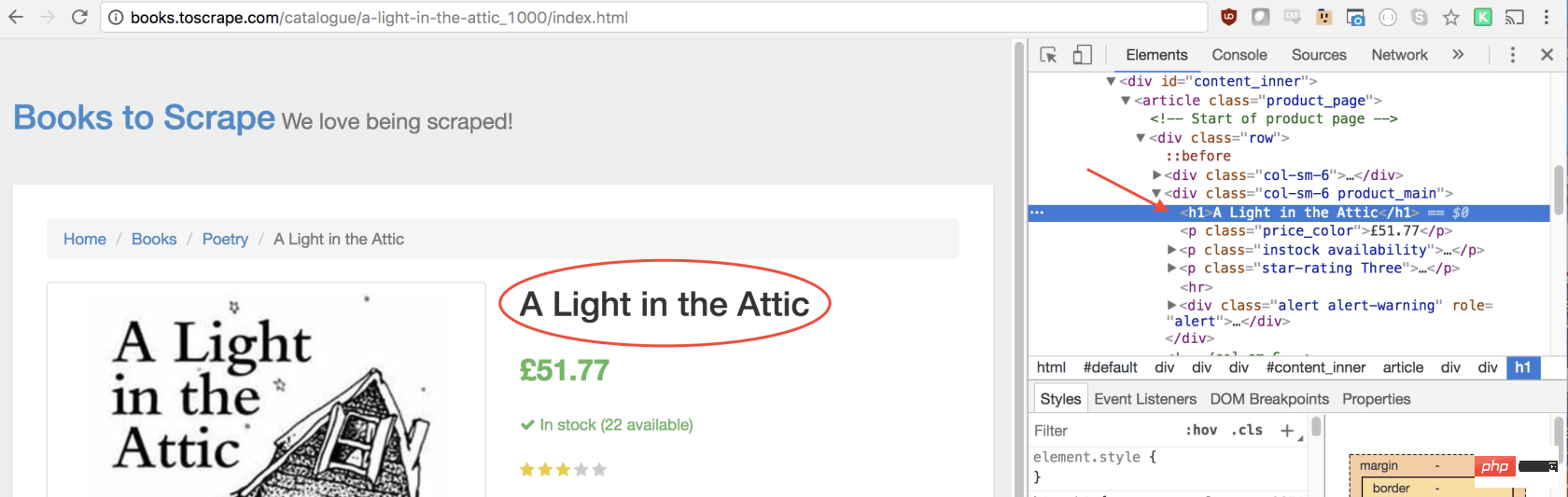
正如您将在 elements 面板中看到的那样,标题只是一个h1元素。我们可以使用以下代码选择此元素:
let title = document.querySelector('h1');由于我们希望文本包含在此元素中,因此我们需要添加.innerText-最终代码如下所示:
let title = document.querySelector('h1').innerText;同样,我们可以通过单击右键检查元素来选择价格:
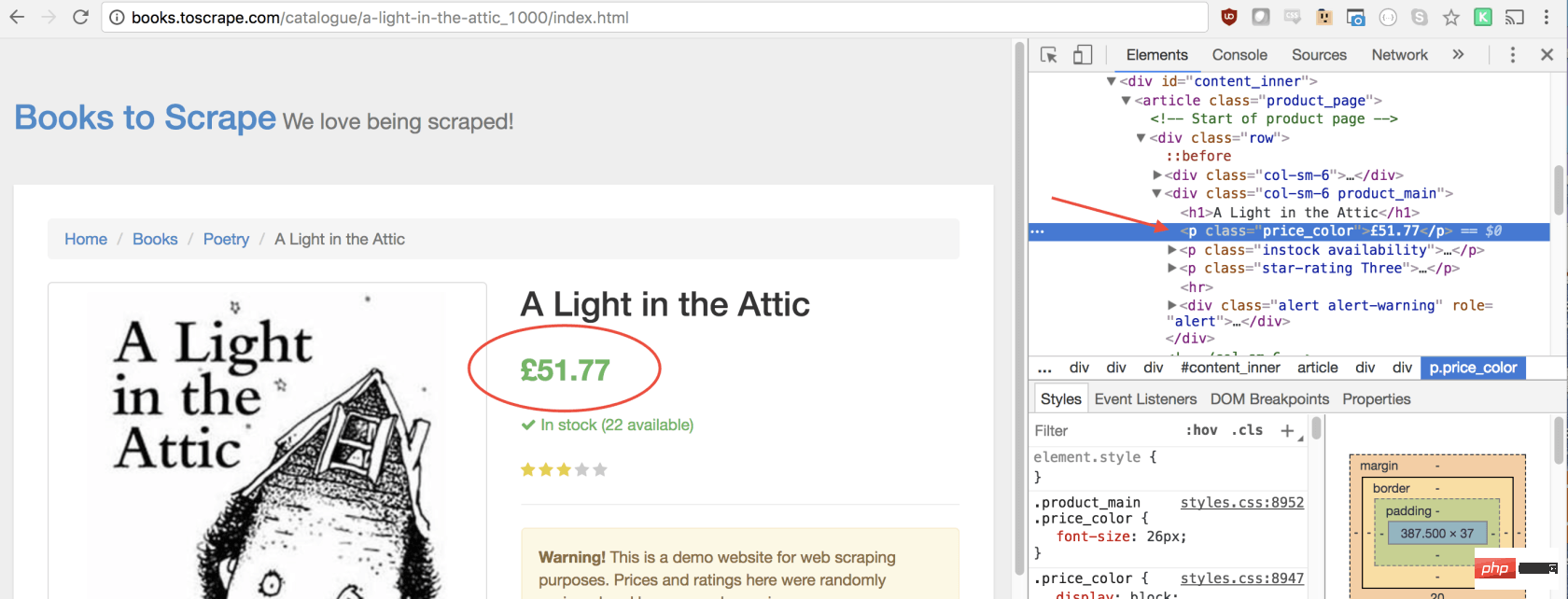
如您所见,我们的价格有price_color类,我们可以使用此类选择元素及其内部文本。这是代码:
let price = document.querySelector('.price_color').innerText;现在我们有了所需的文本,可以将其返回到一个对象中:
return {
title,
price
}太棒了!我们选择标题和价格,将其保存到一个对象中,然后将该对象的值返回给result变量。放在一起是这样的:
const result = await page.evaluate(() => {
let title = document.querySelector('h1').innerText;
let price = document.querySelector('.price_color').innerText;
return {
title,
price
}});剩下要做的唯一一件事就是返回result,以便可以将其记录到控制台:
return result;
您的最终代码应如下所示:
const puppeteer = require('puppeteer');
let scrape = async () => {
const browser = await puppeteer.launch({headless: false});
const page = await browser.newPage();
await page.goto('http://books.toscrape.com/');
await page.click('#default > p > p > p > p > section > p:nth-child(2) > ol > li:nth-child(1) > article > p.image_container > a > img');
await page.waitFor(1000);
const result = await page.evaluate(() => {
let title = document.querySelector('h1').innerText;
let price = document.querySelector('.price_color').innerText;
return {
title,
price
}
});
browser.close();
return result;
};
scrape().then((value) => {
console.log(value); // 成功!
});您可以通过在控制台中键入以下内容来运行 Node 文件:
node scrape.js // { 书名: 'A Light in the Attic', 价格: '£51.77' }您应该看到所选图书的标题和价格返回到屏幕上!您刚刚抓取了网页!
示例 #3 ——完善它
现在您可能会问自己,当标题和价格都显示在主页上时,为什么我们要点击书?为什么不从那里抓取呢?而在我们尝试时,为什么不抓紧所有书籍的标题和价格呢?
因为有很多方法可以抓取网站! (此外,如果我们留在首页上,我们的标题将被删掉)。但是,这为您提供了练习新的抓取技能的绝好机会!
挑战
目标 ——从首页抓取所有书名和价格,并以数组形式返回。这是我最终的输出结果:

开始!看看您是否可以自己完成此任务。与我们刚创建的上述程序非常相似,如果卡住,请向下滚动…
GO! See if you can accomplish this on your own. It’s very similar to the above program we just created. Scroll down if you get stuck…
提示:
此挑战与上一个示例之间的主要区别是需要遍历大量结果。您可以按照以下方法设置代码来做到这一点:
const result = await page.evaluate(() => {
let data = []; // 创建一个空数组
let elements = document.querySelectorAll('xxx'); // 选择全部
// 遍历每一个产品
// 选择标题
// 选择价格
data.push({title, price}); // 将数据放到数组里, 返回数据;
// 返回数据数组
});如果您不明白,没事!这是一个棘手的问题…… 这是一种可能的解决方案。在以后的文章中,我将深入研究此代码及其工作方式,我们还将介绍更高级的抓取技术。如果您想收到通知,请务必 在此处输入您的电子邮件 。
方案:
const puppeteer = require('puppeteer');
let scrape = async () => {
const browser = await puppeteer.launch({headless: false});
const page = await browser.newPage();
await page.goto('http://books.toscrape.com/');
const result = await page.evaluate(() => {
let data = []; // 创建一个空数组, 用来存储数据
let elements = document.querySelectorAll('.product_pod'); // 选择所有产品
for (var element of elements){ // 遍历每个产品
let title = element.childNodes[5].innerText; // 选择标题
let price = element.childNodes[7].children[0].innerText; // 选择价格
data.push({title, price}); // 将对象放进数组 data
}
return data; // 返回数组 data
});
browser.close();
return result; // 返回数据
};
scrape().then((value) => {
console.log(value); // 成功!
});结束语:
感谢您的阅读!
英文原文地址:https://codeburst.io/a-guide-to-automating-scraping-the-web-with-javascript-chrome-puppeteer-node-js-b18efb9e9921
更多编程相关知识,请访问:编程入门!!
Atas ialah kandungan terperinci 使用Node.js+Chrome+Puppeteer实现网站的爬取. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas



 Apakah Updater.exe dalam Windows 11/10? Adakah ini proses Chrome?
Mar 21, 2024 pm 05:36 PM
Apakah Updater.exe dalam Windows 11/10? Adakah ini proses Chrome?
Mar 21, 2024 pm 05:36 PM
Setiap aplikasi yang anda jalankan pada Windows mempunyai program komponen untuk mengemas kininya. Jadi jika anda menggunakan Google Chrome atau Google Earth, ia akan menjalankan aplikasi GoogleUpdate.exe, menyemak sama ada kemas kini tersedia, dan kemudian mengemas kininya berdasarkan tetapan. Walau bagaimanapun, jika anda tidak lagi melihatnya dan sebaliknya melihat proses updater.exe dalam Pengurus Tugas Windows 11/10, ada sebab untuk ini. Apakah Updater.exe dalam Windows 11/10? Google telah melancarkan kemas kini untuk semua aplnya seperti Google Earth, Google Drive, Chrome, dsb. Kemas kini ini membawa
 Apakah fail crdownload?
Mar 08, 2023 am 11:38 AM
Apakah fail crdownload?
Mar 08, 2023 am 11:38 AM
crdownload ialah fail cache muat turun pelayar chrome, iaitu fail yang belum dimuat turun fail crdownload ialah format fail sementara yang digunakan untuk menyimpan fail yang dimuat turun dari cakera keras Ia boleh membantu pengguna melindungi integriti fail semasa memuat turun fail dan mengelakkan daripada rosak . Gangguan atau pemberhentian yang tidak dijangka. Fail CRDownload juga boleh digunakan untuk membuat sandaran fail, membenarkan pengguna menyimpan salinan sementara fail jika ralat yang tidak dijangka berlaku semasa memuat turun, fail CRDownload boleh digunakan untuk memulihkan fail yang dimuat turun.
 Perkara yang perlu dilakukan jika chrome tidak dapat memuatkan pemalam
Nov 06, 2023 pm 02:22 PM
Perkara yang perlu dilakukan jika chrome tidak dapat memuatkan pemalam
Nov 06, 2023 pm 02:22 PM
Ketidakupayaan Chrome untuk memuatkan pemalam boleh diselesaikan dengan menyemak sama ada pemalam dipasang dengan betul, melumpuhkan dan mendayakan pemalam, mengosongkan cache pemalam, mengemas kini penyemak imbas dan pemalam, menyemak sambungan rangkaian dan cuba memuatkan pemalam dalam mod inkognito. Penyelesaiannya adalah seperti berikut: 1. Periksa sama ada pemalam telah dipasang dengan betul dan pasangkannya semula 2. Lumpuhkan dan dayakan pemalam, klik butang Lumpuhkan, dan kemudian klik butang Dayakan semula; -dalam cache, pilih Pilihan Lanjutan > Kosongkan Data Penyemakan Imbas, semak imej dan fail cache dan kosongkan semua kuki, klik Kosongkan Data.
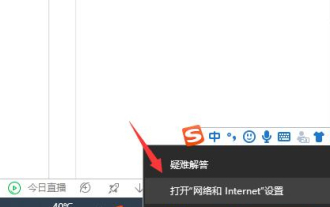 Bagaimana untuk menyelesaikan masalah bahawa Google Chrome tidak boleh membuka halaman web
Jan 04, 2024 pm 10:18 PM
Bagaimana untuk menyelesaikan masalah bahawa Google Chrome tidak boleh membuka halaman web
Jan 04, 2024 pm 10:18 PM
Apakah yang perlu saya lakukan jika halaman web Google Chrome tidak boleh dibuka? Ramai rakan suka menggunakan Google Chrome Sudah tentu, sesetengah rakan mendapati bahawa mereka tidak boleh membuka halaman web secara normal atau halaman web dibuka dengan sangat perlahan semasa digunakan. Jadi apa yang perlu anda lakukan jika anda menghadapi situasi ini? Mari kita lihat penyelesaian kepada masalah bahawa halaman web Google Chrome tidak boleh dibuka dengan editor. Penyelesaian kepada masalah bahawa halaman web Google Chrome tidak boleh dibuka Kaedah 1. Untuk membantu pemain yang belum melepasi tahap itu, mari kita belajar tentang kaedah khusus untuk menyelesaikan teka-teki. Mula-mula, klik kanan ikon rangkaian di penjuru kanan sebelah bawah dan pilih "Tetapan Rangkaian dan Internet." 2. Klik "Ethernet" dan kemudian klik "Tukar Pilihan Penyesuai". 3. Klik butang "Properties". 4. Klik dua kali untuk membuka i
 Apakah direktori pemasangan sambungan pemalam Chrome?
Mar 08, 2024 am 08:55 AM
Apakah direktori pemasangan sambungan pemalam Chrome?
Mar 08, 2024 am 08:55 AM
Apakah direktori pemasangan sambungan pemalam Chrome? Dalam keadaan biasa, direktori pemasangan lalai pelanjutan pemalam Chrome adalah seperti berikut: 1. Lokasi direktori pemasangan lalai pemalam chrome dalam windowsxp: C:\DocumentsandSettings\username\LocalSettings\ApplicationData\Google\Chrome\UserData\ Default\Extensions2 chrome dalam windows7 Lokasi direktori pemasangan lalai pemalam: C:\Users\username\AppData\Local\Google\Chrome\User.
 Bagaimana untuk memadam nod dalam nvm
Dec 29, 2022 am 10:07 AM
Bagaimana untuk memadam nod dalam nvm
Dec 29, 2022 am 10:07 AM
Cara memadam nod dengan nvm: 1. Muat turun "nvm-setup.zip" dan pasangkannya pada pemacu C 2. Konfigurasikan pembolehubah persekitaran dan semak nombor versi melalui arahan "nvm -v" 3. Gunakan "nvm arahan install" Pasang nod; 4. Padamkan nod yang dipasang melalui arahan "nvm uninstall".
 Cara menggunakan ekspres untuk mengendalikan muat naik fail dalam projek nod
Mar 28, 2023 pm 07:28 PM
Cara menggunakan ekspres untuk mengendalikan muat naik fail dalam projek nod
Mar 28, 2023 pm 07:28 PM
Bagaimana untuk mengendalikan muat naik fail? Artikel berikut akan memperkenalkan kepada anda cara menggunakan ekspres untuk mengendalikan muat naik fail dalam projek nod saya harap ia akan membantu anda!
 apakah maksud chrome
Aug 07, 2023 pm 01:18 PM
apakah maksud chrome
Aug 07, 2023 pm 01:18 PM
Chrome bermaksud penyemak imbas, pelayar web yang dibangunkan oleh Google Ia pertama kali dikeluarkan pada tahun 2008 dan dengan cepat menjadi salah satu penyemak imbas paling popular di dunia Namanya berasal dari reka bentuk antara muka pelayar kerana cirinya yang ikonik bahagian atas tetingkap, dan penampilan bar tab ini sangat serupa dengan logam krom.
