
java基础教程栏目介绍万亿级数据应该迁移的方法。

在星爷的《大话西游》中有一句非常出名的台词:“曾经有一份真挚的感情摆在我的面前我没有珍惜,等我失去的时候才追悔莫及,人间最痛苦的事莫过于此,如果上天能给我一次再来一次的机会,我会对哪个女孩说三个字:我爱你,如果非要在这份爱上加一个期限,我希望是一万年!”在我们开发人员的眼中,这个感情就和我们数据库中的数据一样,我们多希望他一万年都不改变,但是往往事与愿违,随着公司的不断发展,业务的不断变更,我们对数据的要求也在不断的变化,大概有下面的几种情况:
在实际业务开发中,我们会根据不同的情况来做出不同的迁移方案,接下来我们来讨论一下到底应该怎么迁移数据。
数据迁移其实不是一蹴而就的,每一次数据迁移都需要一段漫长的时间,有可能是一周,有可能是几个月,通常来说我们迁移数据的过程基本都和下图差不多: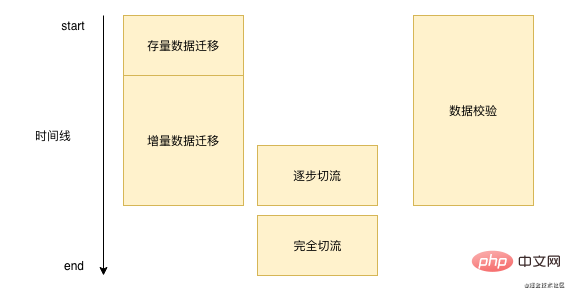 ‘
首先我们需要将我们数据库已经存在的数据进行批量的迁移,然后需要处理新增的这部分数据,需要实时的把这部分数据在写完原本的数据库之后然后写到我们的新的存储,在这一过程中我们需要不断的进行数据校验。当我们校验基本问题不大的时候,然后进行切流操作,直到完全切流之后,我们就可以不用再进行数据校验和增量数据迁移。
‘
首先我们需要将我们数据库已经存在的数据进行批量的迁移,然后需要处理新增的这部分数据,需要实时的把这部分数据在写完原本的数据库之后然后写到我们的新的存储,在这一过程中我们需要不断的进行数据校验。当我们校验基本问题不大的时候,然后进行切流操作,直到完全切流之后,我们就可以不用再进行数据校验和增量数据迁移。
首先我们来说一下存量数据迁移应该怎么做,存量数据迁移在开源社区中搜索了一圈发现没有太好用的工具,目前来说阿里云的DTS提供了存量数据迁移,DTS支持同构和异构不同数据源之间的迁移,基本支持业界常见的数据库比如Mysql,Orcale,SQL Server等等。DTS比较适合我们之前说的前两个场景,一个是分库的场景,如果使用的是阿里云的DRDS那么就可以直接将数据通过DTS迁移到DRDS,另外一个是数据异构的场景,无论是Redis还是ES,DTS都支持直接进行迁移。
那么DTS的存量迁移怎么做的呢?其实比较简单大概就是下面几个步骤:
select * from table_name where id > curId and id < curId + 10000;复制代码
3.当id大于等于maxId之后,存量数据迁移任务结束
当然我们在实际的迁移过程中可能不会去使用阿里云,或者说在我们的第三个场景下,我们的数据库字段之间需要做很多转换,DTS不支持,那么我们就可以模仿DTS的做法,通过分段批量读取数据的方式来迁移数据,这里需要注意的是我们批量迁移数据的时候需要控制分段的大小,以及频率,防止影响我们线上的正常运行。
存量数据的迁移方案比较有限,但是增量的数据迁移方法就是百花齐放了,一般来说我们有下面的几种方法:
这么多种方式我们应该使用哪种呢?我个人来说是比较推荐监听binlog的做法的,监听binlog减少开发成本,我们只需要实现consumer逻辑即可,数据能保证一致性,因为是监听的binlog这里不需要担心之前双写的时候不是一个事务的问题。
前面所说的所有方案,虽然有很多是成熟的云服务(dts)或者中间件(canal),但是他们都有可能出现一些数据丢失,出现数据丢失的情况整体来说还是比较少,但是非常难排查,有可能是dts或者canal不小心抖了一下,又或者是接收数据的时候不小心导致的丢失。既然我们没有办法避免我们的数据在迁移的过程中丢失,那么我们应该通过其他手段来进行校正。
通常来说我们迁移数据的时候都会有数据校验这一个步骤,但是在不同团队可能会选取不同的数据校验方案:
当然在实际开发过程中我们也需要注意下面几点:
当我们数据校验基本没有报错了之后,说明我们的迁移程序是比较稳定的了,那么我们就可以直接使用我们新的数据了吗?当然是不可以的,如果我们一把切换了,顺利的话当然是很好的,如果出现问题了,那么就会影响所有的用户。
所以我们接下来就需要进行灰度,也就是切流。 对于不同的业务切流的的维度会不一样,对于用户维度的切流,我们通常会以userId的取模的方式去进行切流,对于租户或者商家维度的业务,就需要按照租户id取模的方式去切流。这个切流需要制定好一个切流计划,在什么时间段,放出多少的流量,并且切流的时候一定要选择流量比较少的时候进行切流,每一次切流都需要对日志做详细的观察,出现问题尽早修复,流量的一个放出过程是一个由慢到快的过程,比如最开始是以1%的量去不断叠加的,到后面的时候我们直接以10%,20%的量去快速放量。因为如果出现问题的话往往在小流量的时候就会发现,如果小流量没有问题那么后续就可以快速放量。
在迁移数据的过程中特别要注意的是主键ID,在上面双写的方案中也提到过主键ID需要双写的时候手动的去指定,防止ID生成顺序错误。
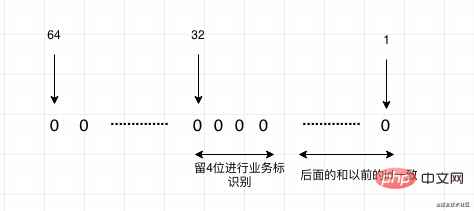
如果我们是因为分库分表而进行迁移,就需要考虑我们以后的主键Id就不能是自增id,需要使用分布式id,这里比较推荐的是美团开源的leaf,他支持两种模式一种是雪花算法趋势递增,但是所有的id都是Long型,适合于一些支持Long为id的应用。还有一种是号段模式,这种会根据你设置的一个基础id,从这个上面不断的增加。并且基本都走的是内存生成,性能也是非常的快。
当然我们还有种情况是我们需要迁移系统,之前系统的主键id在新系统中已经有了,那么我们的id就需要做一些映射。如果我们在迁移系统的时候已经知道未来大概有哪些系统会迁移进来,我们就可以采用预留的方式,比如A系统现在的数据是1到1亿,B系统的数据也是1到1亿,我们现在需要将A,B两个系统合并成新系统,那么我们可以稍微预估一些Buffer,比如给A系统留1到1.5亿,这样A就不需要进行映射,B系统是1.5亿到3亿,那么我们转换成老系统Id的时候就需要减去1.5亿,最后我们新系统的新的Id就从3亿开始递增。 但是如果系统中没有做规划的预留段怎么办呢?可以通过下面两种方式:
最后简单来总结下这个套路,其实就是四个步骤,一个注意:存量,增量,校验,切流,最后再注意一下id。不管是多大量级的数据,基本上按照这个套路来迁移就不会出现大的问题。希望能在大家的后续迁移数据工作中,这篇文章能帮助到你。
如果大家觉得这篇文章对你有帮助,你的关注和转发是对我最大的支持,O(∩_∩)O:
相关免费学习推荐:java基础教程
Atas ialah kandungan terperinci 万亿级数据应该迁移的方法. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 Alat carian yang biasa digunakan
Alat carian yang biasa digunakan
 Perbezaan antara flutter dan uniapp
Perbezaan antara flutter dan uniapp
 Apakah kaedah penukaran data dalam golang?
Apakah kaedah penukaran data dalam golang?
 Bagaimana untuk memasukkan keistimewaan root dalam linux
Bagaimana untuk memasukkan keistimewaan root dalam linux
 Perbezaan antara executeupdate dan execute
Perbezaan antara executeupdate dan execute
 kaedah tampalan naik taraf win10
kaedah tampalan naik taraf win10
 Alat muat turun dan pemasangan Linux biasa
Alat muat turun dan pemasangan Linux biasa
 Bagaimana untuk mematikan kemas kini automatik dalam win10
Bagaimana untuk mematikan kemas kini automatik dalam win10











![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



