

SQL在MySQL数据库中是如何执行的

今天和mysql视频教程栏目一起看看一条更新语句又是怎么一个执行流程。

查询语句的一套执行流程,更新语句也会同样的走一步,下边我们在对照上次文章中的图来简单的看一下:
 " data- style="max-width:90%" data- style="max-width:90%">
" data- style="max-width:90%" data- style="max-width:90%">
首先,在执行语句前要先连接数据库,这是第一步中连接器的工作,前面我们也说过,当一个表有更新的时候,跟这个表有关的查询缓存都会失效,所以我们一般不建议十月查询缓存。
接下来,分析器会经过语法分析和词法分析,知道了这是一条更新语句后,优化器决定要使用哪一个索引,然后执行器负责具体的执行,先找到这一行,然后做更新。
与查询语句更新不同的是,更新流程还涉及两个重要的日志,这个我们在前边的文章中也有专门的介绍,有兴趣的可以找一下上周的文章《MySQL的两个日志系统》,这里就不多做介绍了。
下边通过一个简单的例子来分析一下更新操作的流程。
我们先创建一张表,这个表有主键ID和一个整型字段c:
mysql> create table demo T (ID int primarty ,c int);复制代码
然后将ID=2的这一行的值加1
mysql> update table demo set c = c + 1 where ID = 2;复制代码
接下来我们来看看update语句的执行流程,图中浅色框表示在存储引擎中执行的,神色框代表的是执行器中执行的。
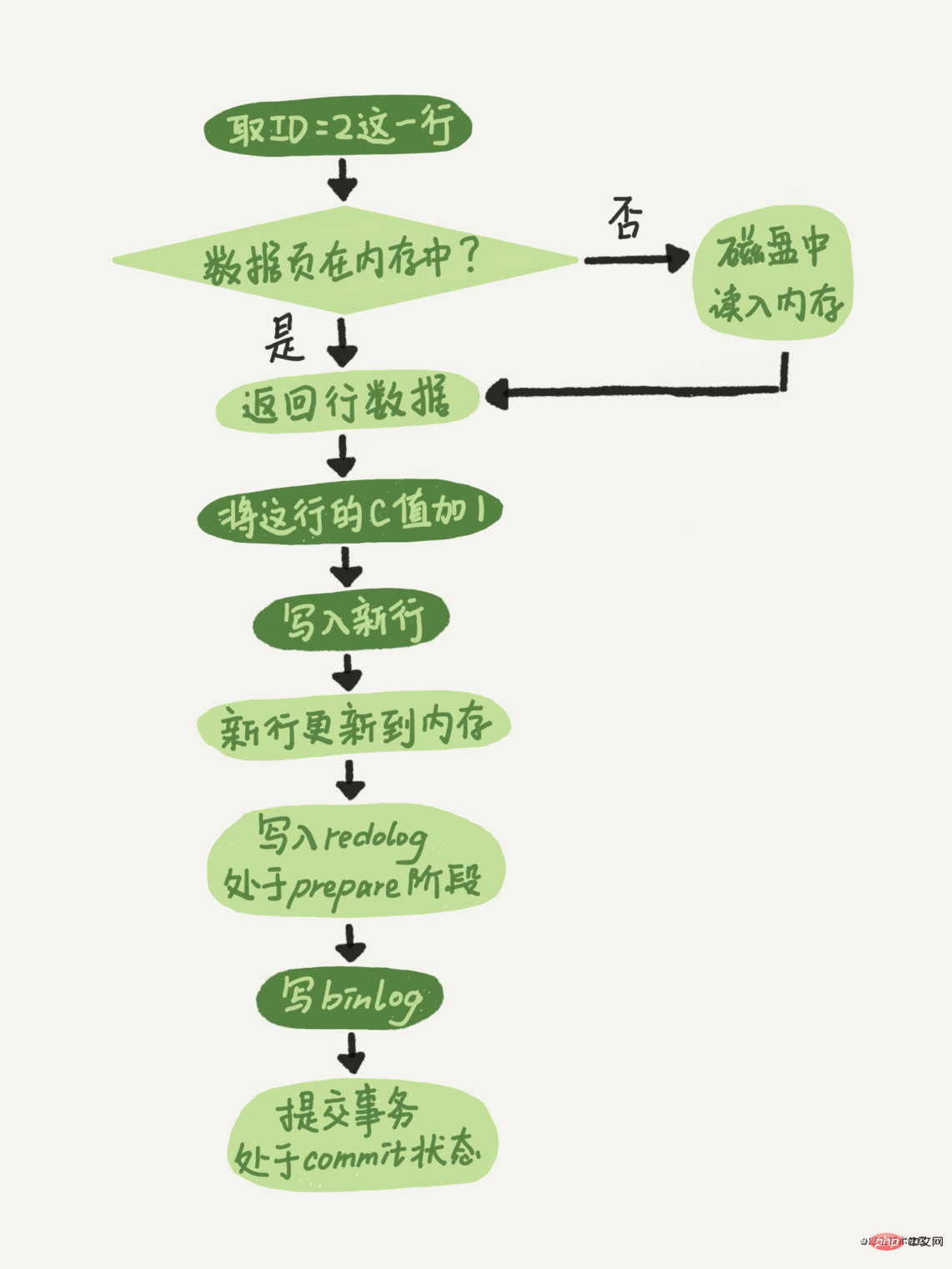
我们可以看到最后的时候,写redolog的时候分了两步,prepare和commit,这就是我们常说的“两阶段提交”。
为什么日志需要“两阶段提交”?
由于redo log和binlog分别是存储引擎和执行器的日志,是两个独立的逻辑,如果不用两阶段提交,无论先提交哪个后提交哪个都会存在一些问题。我们这里也借助上边的例子看一下,假设当前ID=2的这一行值为0 ,在update的过程中写完了第一个日志后,第二个日志还没写期间发生了crash,会怎么样?
- 先写redolog后写binlog。假设redolog写完,binlog还没写完,MySQL进程异常重启了。我们知道,redolog写完以后,系统即使崩溃了,也可以将数据恢复,所以在MySQL重启后,这一行回被恢复成1。由于binlog没写完就crash,这时候binlog里面是没有这个语句的,因此之后备份日志的的时候,存起来的binlog日志也没有这一条语句。当我们需要通过binlog来恢复数据的时候,由于binlog丢失了这条语句,恢复出来的这一行的值就是0,与原库的值不一样啦。
- 先写binlog后写redo log。如果写完buglog之后,redo log还没写完的时候发生 crash,如果这个时候数据库奔溃了,恢复以后这个事务无效,所以这一行的值还是0,但是binlog里已经记载了这条更新语句的日志,在以后需要用binlog来恢复数据的时候,就会多了一个事务出来,执行这条更新语句,将值从0更新成1,与原库中的0就不同了。
我们可以看到如果不使用“两阶段提交",那么数据库的状态就会和用日志恢复出来的库不一致。虽然平时用日志恢复数据的概率比较低,但是用日志最多的还是扩容的时候,用全量备份和binlog来实现的,这个时候就可能导致线上的主从数据库不一致的情况。
相关免费学习推荐:mysql视频教程
Atas ialah kandungan terperinci SQL在MySQL数据库中是如何执行的. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1378
1378
 52
52

 Apakah perbezaan antara HQL dan SQL dalam rangka kerja Hibernate?
Apr 17, 2024 pm 02:57 PM
Apakah perbezaan antara HQL dan SQL dalam rangka kerja Hibernate?
Apr 17, 2024 pm 02:57 PM
HQL dan SQL dibandingkan dalam rangka kerja Hibernate: HQL (1. Sintaks berorientasikan objek, 2. Pertanyaan bebas pangkalan data, 3. Keselamatan jenis), manakala SQL mengendalikan pangkalan data secara langsung (1. Piawaian bebas pangkalan data, 2. Boleh laku kompleks pertanyaan dan manipulasi data).
 Penggunaan operasi bahagian dalam Oracle SQL
Mar 10, 2024 pm 03:06 PM
Penggunaan operasi bahagian dalam Oracle SQL
Mar 10, 2024 pm 03:06 PM
"Penggunaan Operasi Bahagian dalam OracleSQL" Dalam OracleSQL, operasi bahagi ialah salah satu operasi matematik yang biasa. Semasa pertanyaan dan pemprosesan data, operasi pembahagian boleh membantu kami mengira nisbah antara medan atau memperoleh hubungan logik antara nilai tertentu. Artikel ini akan memperkenalkan penggunaan operasi pembahagian dalam OracleSQL dan memberikan contoh kod khusus. 1. Dua cara operasi bahagi dalam OracleSQL Dalam OracleSQL, operasi bahagi boleh dilakukan dalam dua cara berbeza.
 Perbandingan dan perbezaan sintaks SQL antara Oracle dan DB2
Mar 11, 2024 pm 12:09 PM
Perbandingan dan perbezaan sintaks SQL antara Oracle dan DB2
Mar 11, 2024 pm 12:09 PM
Oracle dan DB2 ialah dua sistem pengurusan pangkalan data hubungan yang biasa digunakan, setiap satunya mempunyai sintaks dan ciri SQL tersendiri. Artikel ini akan membandingkan dan membezakan antara sintaks SQL Oracle dan DB2, dan memberikan contoh kod khusus. Sambungan pangkalan data Dalam Oracle, gunakan pernyataan berikut untuk menyambung ke pangkalan data: CONNECTusername/password@database Dalam DB2, pernyataan untuk menyambung ke pangkalan data adalah seperti berikut: CONNECTTOdataba
 Penjelasan terperinci tentang fungsi Set tag dalam teg SQL dinamik MyBatis
Feb 26, 2024 pm 07:48 PM
Penjelasan terperinci tentang fungsi Set tag dalam teg SQL dinamik MyBatis
Feb 26, 2024 pm 07:48 PM
Tafsiran teg SQL dinamik MyBatis: Penjelasan terperinci tentang penggunaan teg Set MyBatis ialah rangka kerja lapisan kegigihan yang sangat baik Ia menyediakan banyak teg SQL dinamik dan boleh membina pernyataan operasi pangkalan data secara fleksibel. Antaranya, tag Set ialah tag yang digunakan untuk menjana klausa SET dalam kenyataan UPDATE, yang sangat biasa digunakan dalam operasi kemas kini. Artikel ini akan menerangkan secara terperinci penggunaan teg Set dalam MyBatis dan menunjukkan kefungsiannya melalui contoh kod tertentu. Apakah itu Set tag Set tag digunakan dalam MyBati
 Apakah yang dimaksudkan dengan atribut identiti dalam SQL?
Feb 19, 2024 am 11:24 AM
Apakah yang dimaksudkan dengan atribut identiti dalam SQL?
Feb 19, 2024 am 11:24 AM
Apakah Identity dalam SQL? Contoh kod khusus diperlukan Dalam SQL, Identity ialah jenis data khas yang digunakan untuk menjana nombor penambahan automatik. Ia sering digunakan untuk mengenal pasti setiap baris data dalam jadual. Lajur Identiti sering digunakan bersama dengan lajur kunci utama untuk memastikan setiap rekod mempunyai pengecam unik. Artikel ini akan memperincikan cara menggunakan Identiti dan beberapa contoh kod praktikal. Cara asas untuk menggunakan Identity ialah menggunakan Identit semasa membuat jadual.
 Amalan pembangunan PHP: Gunakan PHPMailer untuk menghantar e-mel kepada pengguna dalam pangkalan data MySQL
Aug 05, 2023 pm 06:21 PM
Amalan pembangunan PHP: Gunakan PHPMailer untuk menghantar e-mel kepada pengguna dalam pangkalan data MySQL
Aug 05, 2023 pm 06:21 PM
Amalan pembangunan PHP: Gunakan PHPMailer untuk menghantar e-mel kepada pengguna dalam pangkalan data MySQL Pengenalan: Dalam pembinaan Internet moden, e-mel ialah alat komunikasi yang penting. Sama ada pendaftaran pengguna, tetapan semula kata laluan atau pengesahan pesanan dalam e-dagang, menghantar e-mel adalah fungsi penting. Artikel ini akan memperkenalkan cara menggunakan PHPMailer untuk menghantar e-mel dan menyimpan maklumat e-mel ke jadual maklumat pengguna dalam pangkalan data MySQL. 1. Pasang pustaka PHPMailer PHPMailer ialah
 Bagaimana untuk menyelesaikan ralat 5120 dalam SQL
Mar 06, 2024 pm 04:33 PM
Bagaimana untuk menyelesaikan ralat 5120 dalam SQL
Mar 06, 2024 pm 04:33 PM
Penyelesaian: 1. Semak sama ada pengguna log masuk mempunyai kebenaran yang mencukupi untuk mengakses atau mengendalikan pangkalan data, dan pastikan pengguna mempunyai kebenaran yang betul 2. Semak sama ada akaun perkhidmatan SQL Server mempunyai kebenaran untuk mengakses fail yang ditentukan atau folder, dan pastikan akaun Mempunyai kebenaran yang mencukupi untuk membaca dan menulis fail atau folder 3. Semak sama ada fail pangkalan data yang ditentukan telah dibuka atau dikunci oleh proses lain, cuba tutup atau lepaskan fail, dan jalankan semula pertanyaan 4 . Cuba sebagai pentadbir Jalankan Studio Pengurusan seperti dsb.
 Bagaimana untuk menggunakan pernyataan SQL untuk pengagregatan data dan statistik dalam MySQL?
Dec 17, 2023 am 08:41 AM
Bagaimana untuk menggunakan pernyataan SQL untuk pengagregatan data dan statistik dalam MySQL?
Dec 17, 2023 am 08:41 AM
Bagaimana untuk menggunakan pernyataan SQL untuk pengagregatan data dan statistik dalam MySQL? Pengumpulan data dan statistik merupakan langkah yang sangat penting semasa melakukan analisis dan statistik data. Sebagai sistem pengurusan pangkalan data perhubungan yang berkuasa, MySQL menyediakan pelbagai fungsi pengagregatan dan statistik, yang boleh melaksanakan pengagregatan data dan operasi statistik dengan mudah. Artikel ini akan memperkenalkan kaedah menggunakan pernyataan SQL untuk melaksanakan pengagregatan data dan statistik dalam MySQL, dan menyediakan contoh kod khusus. 1. Gunakan fungsi COUNT untuk mengira Fungsi COUNT adalah yang paling biasa digunakan
