

优化技巧!!前端菜鸟让接口提速60%

javascript栏目介绍前端菜鸟让接口提速60%的技巧。

背景
好久没写文章了,沉寂了大半年
持续性萎靡不振,间歇性癫痫发作
天天来大姨爹,在迷茫、焦虑中度过每一天
不得不承认,其实自己就是个废物
作为一名低级前端工程师
最近处理了一个十几年的祖传老接口
它继承了一切至尊级复杂度逻辑
传说中调用一次就能让cpu负载飙升90%的日天服务
专治各种不服与老年痴呆
我们欣赏一下这个接口的耗时
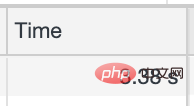
平均调用时间在3s以上
导致页面出现严重的转菊花
经过各种深度剖析与专业人士答疑
最后得出结论是:放弃医疗
鲁迅在《狂人日记》里曾说过:“能打败我的,只有女人和酒精,而不是bug”
每当身处黑暗之时
这句话总能让我看到光
所以这次要硬起来
我决定做一个node代理层
用下面三个方法进行优化:
按需加载 -> graphQL数据缓存 -> redis轮询更新 -> schedule
代码地址:github
按需加载 -> graphQL
天秀老接口存在一个问题,我们每次请求1000条数据,返回的数组中,每一条数据都有上百个字段,其实我们前端只用到其中的10个字段而已。
如何从一百多个字段中,抽取任意n个字段,这就用到graphQL。
graphQL按需加载数据只需要三步:
- 定义数据池 root
- 描述数据池中数据结构 schema
- 自定义查询数据 query
定义数据池
我们针对屌丝追求女神的场景,定义一个数据池,如下:
// 数据池var root = { girls: [{ id: 1, name: '女神一', iphone: 12345678910, weixin: 'xixixixi', height: 175, school: '剑桥大学', wheel: [{ name: '备胎1号', money: '24万元' }, { name: '备胎2号', money: '26万元' }]
},
{ id: 2, name: '女神二', iphone: 12345678910, weixin: 'hahahahah', height: 168, school: '哈佛大学', wheel: [{ name: '备胎3号', money: '80万元' }, { name: '备胎4号', money: '200万元' }]
}]
}复制代码里面有两个女神的所有信息,包括女神的名字、手机、微信、身高、学校、备胎集合等信息。
接下来我们就要对这些数据结构进行描述。
描述数据池中数据结构
const { buildSchema } = require('graphql');// 描述数据结构 schemavar schema = buildSchema(`
type Wheel {
name: String,
money: String
}
type Info {
id: Int
name: String
iphone: Int
weixin: String
height: Int
school: String
wheel: [Wheel]
}
type Query {
girls: [Info]
}
`);复制代码上面这段代码就是女神信息的schema。
首先我们用type Query定义了一个对女神信息的查询,里面包含了很多女孩girls的信息Info,这些信息是一堆数组,所以是[Info]
我们在type Info中描述了一个女孩的所有信息的维度,包括了名字(name)、手机(iphone)、微信(weixin)、身高(height)、学校(school)、备胎集合(wheel)
定义查询规则
得到女神的信息描述(schema)后,就可以自定义获取女神的各种信息组合了。
比如我想和女神认识,只需要拿到她的名字(name)和微信号(weixin)。查询规则代码如下:
const { graphql } = require('graphql');// 定义查询内容const query = `
{
girls {
name
weixin
}
}
`;// 查询数据const result = await graphql(schema, query, root)复制代码筛选结果如下:

又比如我想进一步和女神发展,我需要拿到她备胎信息,查询一下她备胎们(wheel)的家产(money)分别是多少,分析一下自己能不能获取优先择偶权。查询规则代码如下:
const { graphql } = require('graphql');// 定义查询内容const query = `
{
girls {
name
wheel {
money
}
}
}
`;// 查询数据const result = await graphql(schema, query, root)复制代码筛选结果如下:

我们通过女神的例子,展现了如何通过graphQL按需加载数据。
映射到我们业务具体场景中,天秀接口返回的每条数据都包含100个字段,我们配置schema,获取其中的10个字段,这样就避免了剩下90个不必要字段的传输。
graphQL还有另一个好处就是可以灵活配置,这个接口需要10个字段,另一个接口要5个字段,第n个接口需要另外x个字段
按照传统的做法我们要做出n个接口才能满足,现在只需要一个接口配置不同schema就能满足所有情况了。
感悟
在生活中,咱们舔狗真的很缺少graphQL按需加载的思维
渣男渣女,各取所需
你的真情在名媛面前不值一提
我们要学会投其所好
上来就亮车钥匙,没有车就秀才艺
今晚我有一条祖传的染色体想与您分享一下
行就行,不行就换下一个
直奔主题,简单粗暴
缓存 -> redis
第二个优化手段,使用redis缓存
天秀老接口内部调用了另外三个老接口,而且是串行调用,极其耗时耗资源,秀到你头皮发麻
我们用redis来缓存天秀接口的聚合数据,下次再调用天秀接口,直接从缓存中获取数据即可,避免高耗时的复杂调用,简化后代码如下:
const redis = require("redis");const { promisify } = require("util");// 链接redis服务const client = redis.createClient(6379, '127.0.0.1');// promise化redis方法,以便用async/awaitconst getAsync = promisify(client.get).bind(client);const setAsync = promisify(client.set).bind(client);async function list() { // 先获取缓存中数据,没有缓存就去拉取天秀接口
let result = await getAsync("缓存"); if (!result) { // 拉接口
const data = await 天秀接口();
result = data; // 设置缓存数据
await setAsync("缓存", data)
} return result;
}
list();
复制代码先通过getAsync来读取redis缓存中的数据,如果有数据,直接返回,绕过接口调用,如果没有数据,就会调用天秀接口,然后setAsync更新到缓存中,以便下次调用。因为redis存储的是字符串,所以在设置缓存的时候,需要加上JSON.stringify(data),为了便于大家理解,我就不加了,会把具体细节代码放在github中。
将数据放在redis缓存里有几个好处
可以实现多接口复用、多机共享缓存
这就是传说中的云备胎
追求一个女神的成功率是1%
同时追求100个女神,那你获取到一个女神的概率就是100%
鲁迅《狂人日记》里曾说过:“舔一个是舔狗,舔一百个你就是战狼”
你是想当舔狗还是当战狼?
来吧,缓存用起来,redis用起来
轮询更新 -> schedule
最后一个优化手段:轮询更新 -> schedule
女神的备胎用久了,会定时换一批备胎,让新鲜血液进来,发现新的快乐
缓存也一样,需要定时更新,保持与数据源的一致性,代码如下:
const schedule = require('node-schedule');// 每个小时更新一次缓存schedule.scheduleJob('* * 0 * * *', async () => { const data = await 天秀接口(); // 设置redis缓存数据
await setAsync("缓存", data)
});复制代码天秀接口不是一个强实时性接口,数据源一周可能才会变一次
所以我们根据实际情况用轮询来设置更新缓存频率
我们用node-schedule这个库来轮询更新缓存,* * 0 * * *这个的意思就是设置每个小时的第0分钟就开始执行缓存更新逻辑,将获取到的数据更新到缓存中,这样其他接口和机器在调用缓存的时候,就能获取到最新数据,这就是共享缓存和轮询更新的好处。
早年我在当舔狗的时候,就将轮询机制发挥到淋漓尽致
每天向白名单里的女神,定时轮询发消息
无限循环云跪舔三件套:
- “啊宝贝,最近有没有想我”
- “啊宝贝早安安”
- “宝贝晚安,么么哒”
虽然女神依然看不上我
但仍然时刻准备着为女神服务
结尾
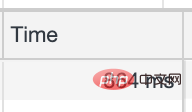
经过以上三个方法优化后
接口请求耗时从3s降到了860ms
这些代码都是从业务中简化后的逻辑
真实的业务场景远比这要复杂:分段式数据存储、主从同步 读写分离、高并发同步策略等等
每一个模块都晦涩难懂
就好像每一个女神都高不可攀
屌丝战胜了所有bug,唯独战胜不了她的心
受伤了只能在深夜里独自买醉
但每当梦到女神打开我做的页面
被极致流畅的体验惊艳到
在精神高潮中享受灵魂升华
那一刻
我觉得我又行了
(完)
相关免费学习推荐:JavaScript(视频)
Atas ialah kandungan terperinci 优化技巧!!前端菜鸟让接口提速60%. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

Video Face Swap
Tukar muka dalam mana-mana video dengan mudah menggunakan alat tukar muka AI percuma kami!

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1390
1390
 52
52

 Apakah antara muka dalaman papan induk komputer yang disyorkan pengenalan kepada antara muka dalaman papan induk komputer
Mar 12, 2024 pm 04:34 PM
Apakah antara muka dalaman papan induk komputer yang disyorkan pengenalan kepada antara muka dalaman papan induk komputer
Mar 12, 2024 pm 04:34 PM
Apabila kami memasang komputer, walaupun proses pemasangannya mudah, kami sering menghadapi masalah dalam pendawaian Selalunya, pengguna tersilap memasangkan talian bekalan kuasa radiator CPU ke SYS_FAN Walaupun kipas boleh berputar, ia mungkin tidak berfungsi apabila komputer dihidupkan. Akan terdapat ralat F1 "CPUFanError", yang juga menyebabkan penyejuk CPU tidak dapat melaraskan kelajuan secara bijak. Mari kita berkongsi pengetahuan bersama tentang antara muka CPU_FAN, SYS_FAN, CHA_FAN dan CPU_OPT pada papan induk komputer. Sains popular pada antara muka CPU_FAN, SYS_FAN, CHA_FAN dan CPU_OPT pada papan induk komputer 1. CPU_FANCPU_FAN ialah antara muka khusus untuk radiator CPU dan berfungsi pada 12V
 Paradigma pengaturcaraan biasa dan corak reka bentuk dalam bahasa Go
Mar 04, 2024 pm 06:06 PM
Paradigma pengaturcaraan biasa dan corak reka bentuk dalam bahasa Go
Mar 04, 2024 pm 06:06 PM
Sebagai bahasa pengaturcaraan yang moden dan cekap, bahasa Go mempunyai paradigma pengaturcaraan yang kaya dan corak reka bentuk yang boleh membantu pembangun menulis kod yang berkualiti tinggi dan boleh diselenggara. Artikel ini akan memperkenalkan paradigma pengaturcaraan biasa dan corak reka bentuk dalam bahasa Go dan memberikan contoh kod khusus. 1. Pengaturcaraan berorientasikan objek Dalam bahasa Go, anda boleh menggunakan struktur dan kaedah untuk melaksanakan pengaturcaraan berorientasikan objek. Dengan mentakrifkan struktur dan kaedah mengikat kepada struktur, ciri berorientasikan objek bagi pengkapsulan data dan pengikatan tingkah laku boleh dicapai. packagemaini
 Pengenalan kepada antara muka PHP dan cara mentakrifkannya
Mar 23, 2024 am 09:00 AM
Pengenalan kepada antara muka PHP dan cara mentakrifkannya
Mar 23, 2024 am 09:00 AM
Pengenalan kepada antara muka PHP dan bagaimana ia ditakrifkan PHP ialah bahasa skrip sumber terbuka yang digunakan secara meluas dalam pembangunan Web Ia fleksibel, mudah dan berkuasa. Dalam PHP, antara muka ialah alat yang mentakrifkan kaedah biasa antara pelbagai kelas, mencapai polimorfisme dan menjadikan kod lebih fleksibel dan boleh digunakan semula. Artikel ini akan memperkenalkan konsep antara muka PHP dan cara mentakrifkannya, dan menyediakan contoh kod khusus untuk menunjukkan penggunaannya. 1. Konsep antara muka PHP Antara muka memainkan peranan penting dalam pengaturcaraan berorientasikan objek, mentakrifkan aplikasi kelas
 Penyelesaian kepada NotImplementedError()
Mar 01, 2024 pm 03:10 PM
Penyelesaian kepada NotImplementedError()
Mar 01, 2024 pm 03:10 PM
Sebab ralat adalah dalam python Sebab mengapa NotImplementedError() dilemparkan dalam Tornado mungkin kerana kaedah atau antara muka abstrak tidak dilaksanakan. Kaedah atau antara muka ini diisytiharkan dalam kelas induk tetapi tidak dilaksanakan dalam kelas anak. Subkelas perlu melaksanakan kaedah atau antara muka ini untuk berfungsi dengan baik. Cara menyelesaikan masalah ini adalah dengan melaksanakan kaedah abstrak atau antara muka yang diisytiharkan oleh kelas induk dalam kelas kanak-kanak. Jika anda menggunakan kelas untuk mewarisi daripada kelas lain dan anda melihat ralat ini, anda harus melaksanakan semua kaedah abstrak yang diisytiharkan dalam kelas induk dalam kelas anak. Jika anda menggunakan antara muka dan anda melihat ralat ini, anda harus melaksanakan semua kaedah yang diisytiharkan dalam antara muka dalam kelas yang melaksanakan antara muka. Jika anda tidak pasti yang mana
 Aplikasi antara muka dan kelas abstrak dalam corak reka bentuk di Jawa
May 01, 2024 pm 06:33 PM
Aplikasi antara muka dan kelas abstrak dalam corak reka bentuk di Jawa
May 01, 2024 pm 06:33 PM
Antara muka dan kelas abstrak digunakan dalam corak reka bentuk untuk penyahgandingan dan kebolehlanjutan. Antara muka mentakrifkan tandatangan kaedah, kelas abstrak menyediakan pelaksanaan separa, dan subkelas mesti melaksanakan kaedah yang tidak dilaksanakan. Dalam corak strategi, antara muka digunakan untuk menentukan algoritma, dan kelas abstrak atau kelas konkrit menyediakan pelaksanaan, membenarkan penukaran dinamik algoritma. Dalam corak pemerhati, antara muka digunakan untuk menentukan tingkah laku pemerhati, dan kelas abstrak atau konkrit digunakan untuk melanggan dan menerbitkan pemberitahuan. Dalam corak penyesuai, antara muka digunakan untuk menyesuaikan kelas yang sedia ada atau kelas konkrit boleh melaksanakan antara muka yang serasi, membenarkan interaksi dengan kod asal.
 Wawasan ke dalam sistem Hongmeng: pengukuran fungsi sebenar dan pengalaman penggunaan
Mar 23, 2024 am 10:45 AM
Wawasan ke dalam sistem Hongmeng: pengukuran fungsi sebenar dan pengalaman penggunaan
Mar 23, 2024 am 10:45 AM
Sebagai sistem pengendalian baharu yang dilancarkan oleh Huawei, sistem Hongmeng telah menimbulkan kekecohan dalam industri. Sebagai percubaan baharu Huawei selepas larangan AS, sistem Hongmeng mempunyai harapan dan harapan yang tinggi. Baru-baru ini, saya cukup bernasib baik untuk mendapatkan telefon mudah alih Huawei yang dilengkapi dengan sistem Hongmeng Selepas tempoh penggunaan dan ujian sebenar, saya akan berkongsi beberapa ujian berfungsi dan pengalaman penggunaan sistem Hongmeng. Mula-mula, mari kita lihat antara muka dan fungsi sistem Hongmeng. Sistem Hongmeng mengguna pakai gaya reka bentuk Huawei sendiri secara keseluruhan, yang mudah, jelas dan lancar dalam operasi. Di desktop, pelbagai
 Pelaksanaan kelas dalaman antara muka dan kelas abstrak dalam Java
Apr 30, 2024 pm 02:03 PM
Pelaksanaan kelas dalaman antara muka dan kelas abstrak dalam Java
Apr 30, 2024 pm 02:03 PM
Java membenarkan kelas dalaman ditakrifkan dalam antara muka dan kelas abstrak, memberikan fleksibiliti untuk penggunaan semula kod dan modularisasi. Kelas dalaman dalam antara muka boleh melaksanakan fungsi tertentu, manakala kelas dalaman dalam kelas abstrak boleh mentakrifkan fungsi umum, dan subkelas menyediakan pelaksanaan konkrit.
 Antara Muka Java dan Kelas Abstrak: Jalan Menuju Syurga Pengaturcaraan
Mar 04, 2024 am 09:13 AM
Antara Muka Java dan Kelas Abstrak: Jalan Menuju Syurga Pengaturcaraan
Mar 04, 2024 am 09:13 AM
Antara Muka: Antara muka kontrak tanpa pelaksanaan mentakrifkan satu set tandatangan kaedah dalam Java tetapi tidak menyediakan sebarang pelaksanaan konkrit. Ia bertindak sebagai kontrak yang memaksa kelas yang melaksanakan antara muka untuk melaksanakan kaedah yang ditentukan. Kaedah dalam antara muka adalah kaedah abstrak dan tidak mempunyai badan kaedah. Contoh kod: publicinterfaceAnimal{voideat();voidsleep();} Kelas Abstrak: Pelan Tindakan Separa Kelas abstrak ialah kelas induk yang menyediakan pelaksanaan separa yang boleh diwarisi oleh subkelasnya. Tidak seperti antara muka, kelas abstrak boleh mengandungi pelaksanaan konkrit dan kaedah abstrak. Kaedah abstrak diisytiharkan dengan kata kunci abstrak dan mesti ditindih oleh subkelas. Contoh kod: publicabstractcla
