

PHP结合MySQL完成千万级数据处理

PHP MySQL栏目讲解如何实现千万级数据处理

推荐(免费):PHP MySQL
mysql分表思路
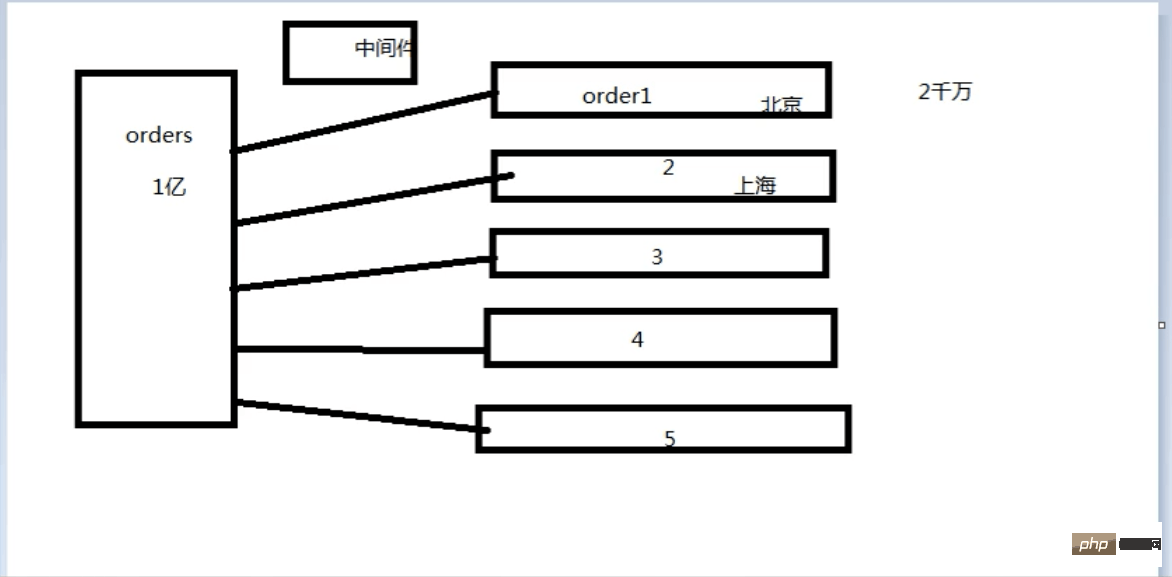
一张一亿的订单表,可以分成五张表,这样每张表就只有两千万数据,分担了原来一张表的压力,分表需要根据某个条件进行分,这里可以根据地区来分表,需要一个中间件来控制到底是去哪张表去找到自己想要的数据。
中间件:根据主表的自增id作为中间件(什么样的字段适合做中间件?要具备唯一性)
怎么分发?主表插入之后返回一个id,根据这个id和表的数量进行取模,余数是几就往哪张表中插入数据。
注意:子表中的id要与主表的id保持一致
以后只有插入操作会用到主表,修改,删除,读取,均不需要用到主表
redis消息队列
1,什么是消息队列?
消息传播过程中保存消息的容器
2,消息队列产生的历史原因

消息队列的特点:先进先出
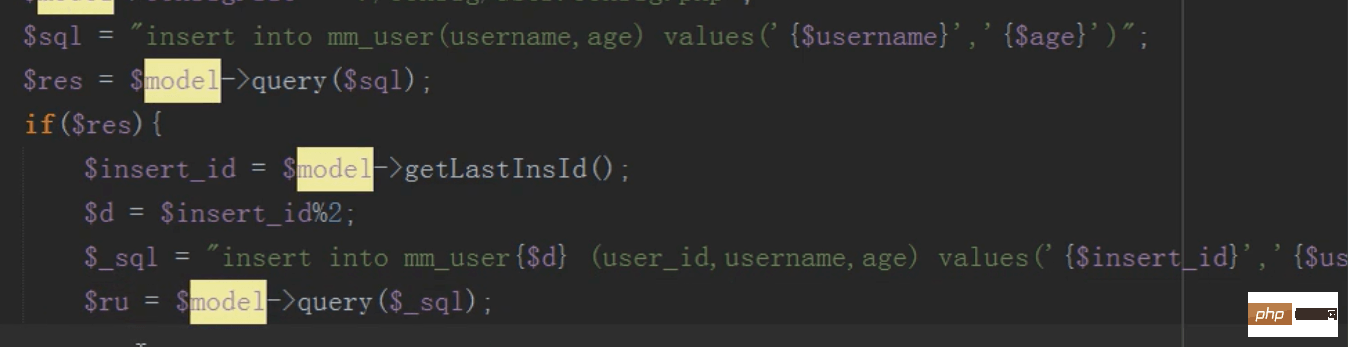
把要执行的sql语句先保存在消息队列中,然后依次按照顺利异步插入的数据库中
应用:新浪,把瞬间的评论先放入消息队列,然后通过定时任务把消息队列里面的sql语句依次插入到数据库中
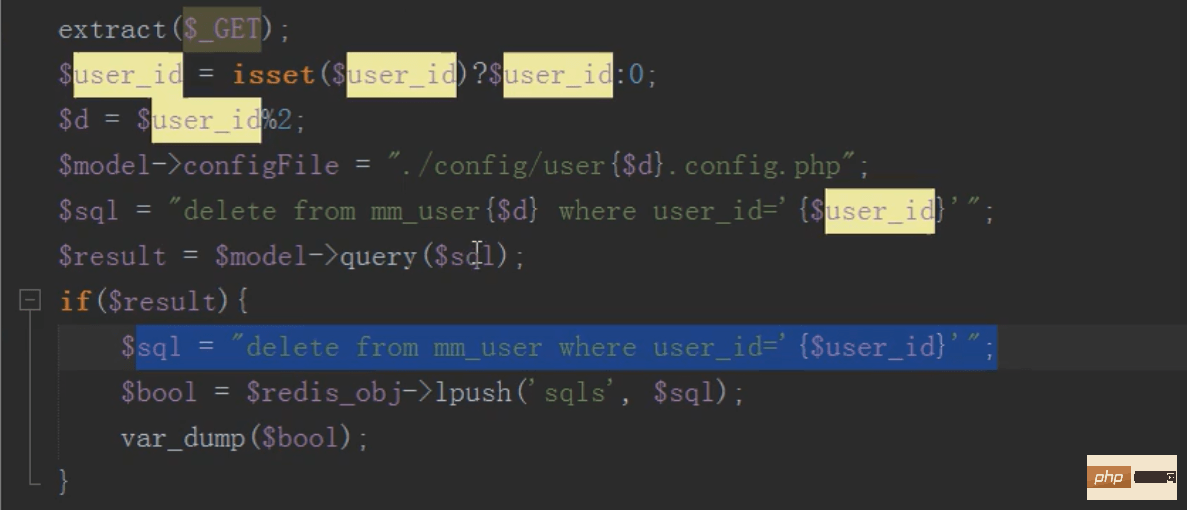
修改
操作子表进行修改
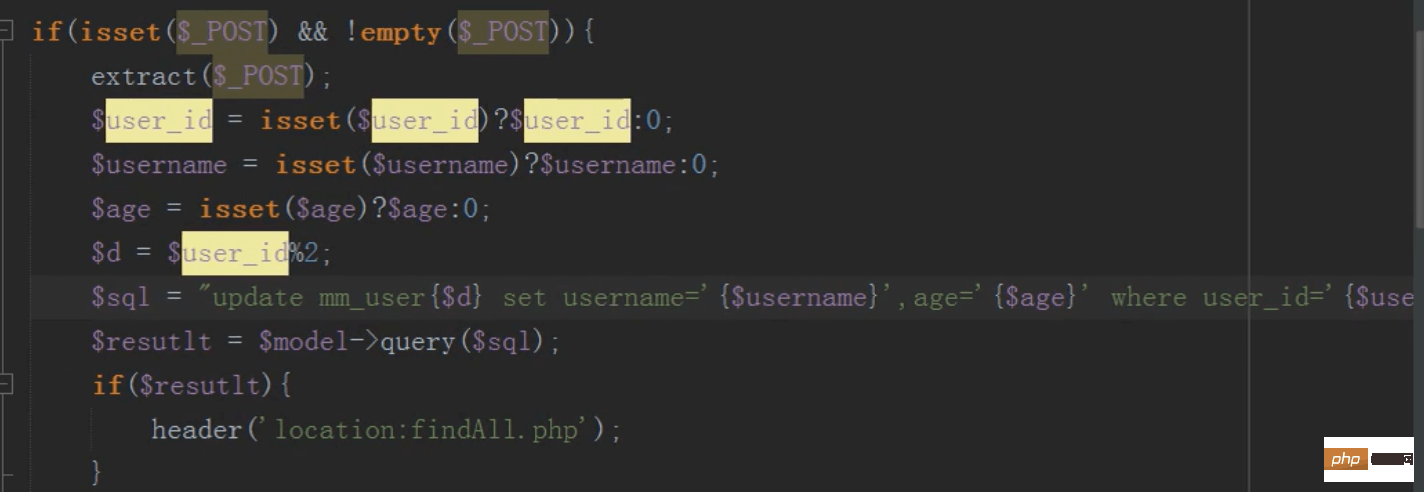
这样修改有一个问题,主表和子表的数据会出现不一致,如何让主表和字表数据一致?
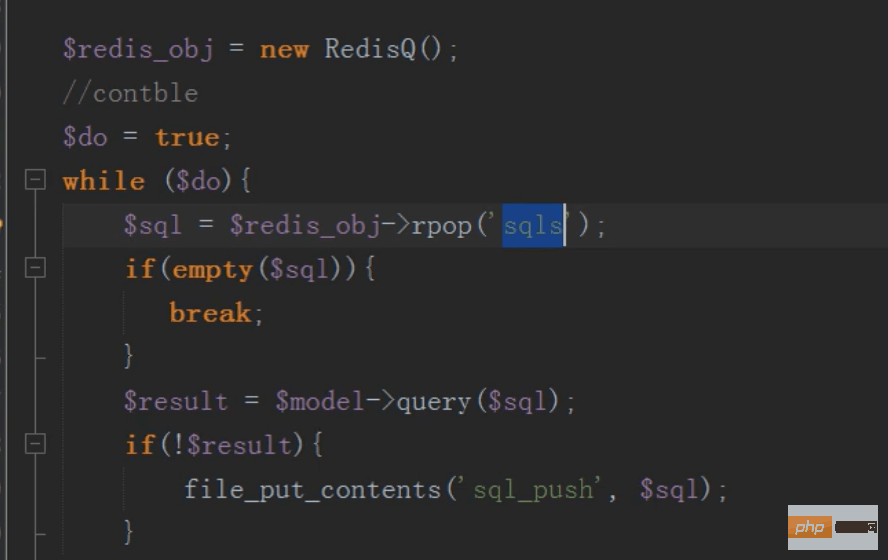
redis队列保持主表子表数据一致
修改完成后将要修改主表的数据,存入redis队列中
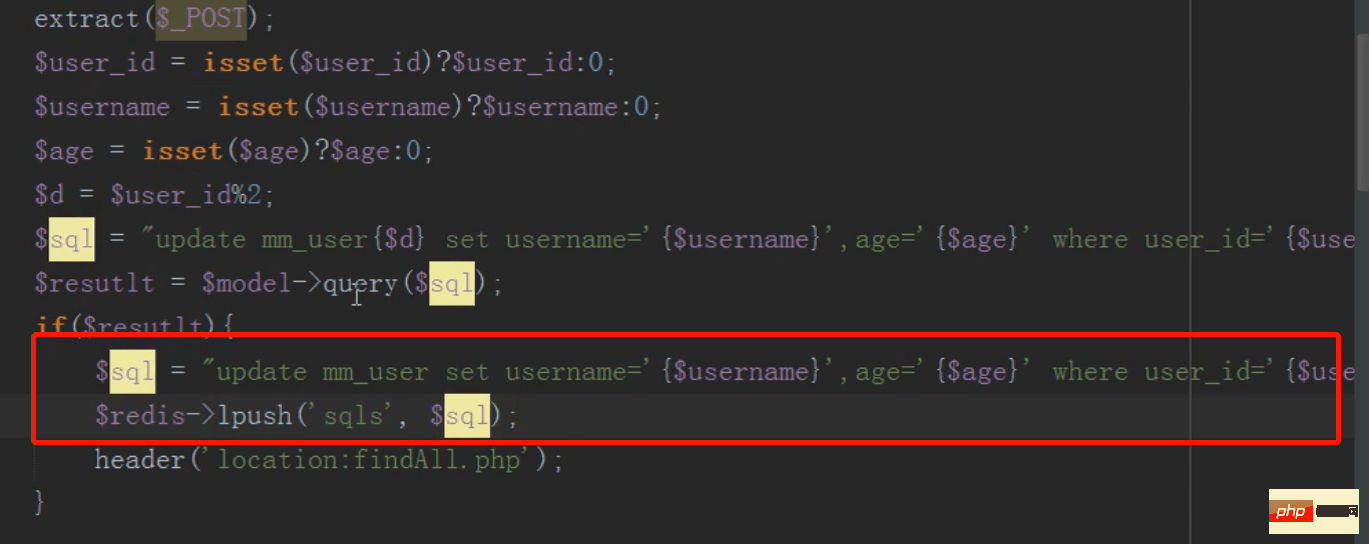
然后linux定时任务(contble)循环执行redis队列中的sql语句,同步更新主表的内容

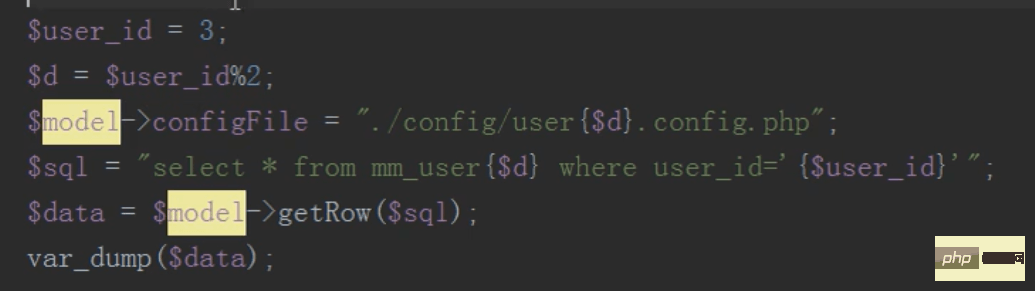
mysql分布式之分表(查,删)
查询只需要查询子表,不要查询总表
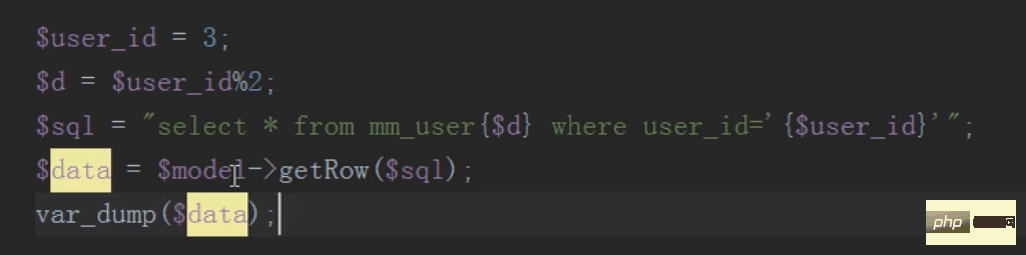
删除,先根据id找到要删除的子表,然后删除,然后往消息队列中压入一条删除总表数据的sql语句
然后执行定时任务删除总表数据

定时任务:
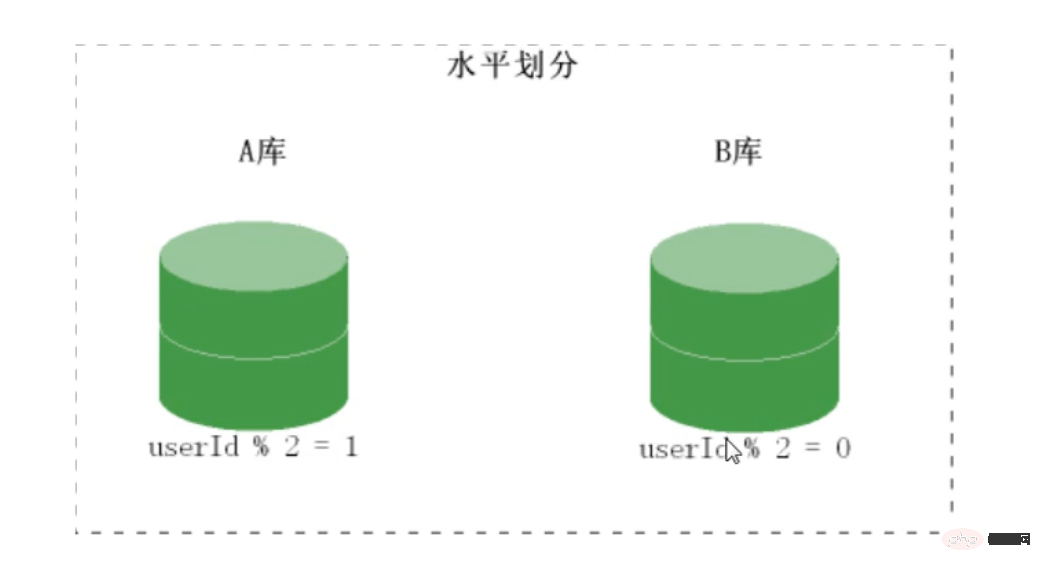
mysql分布式之分库
分库思路

分库原理图:

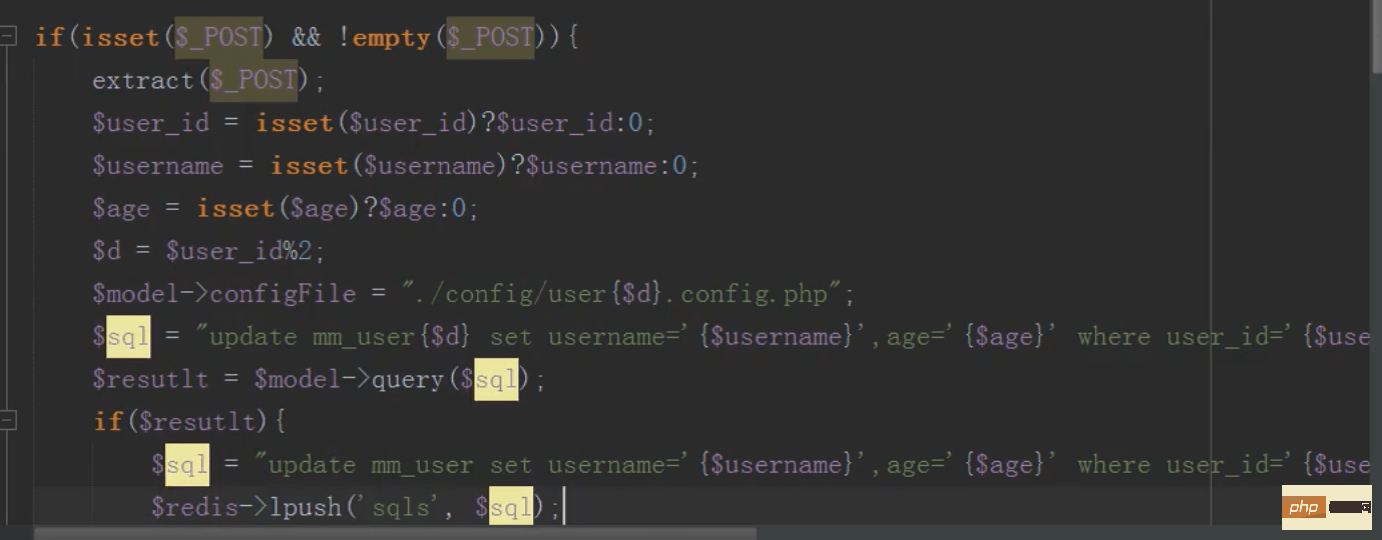
mysql分布式之分库(增)

注意:操作完一个数据库一定要把数据库连接关闭,不然mysql会以为一直连接的同一个数据库
还是取模确定加载哪个配置文件连接哪个数据库

mysql分布式之分库(改)
原理同新增
mysql分布式之分库(查,删)
原理类似
删除
执行队列
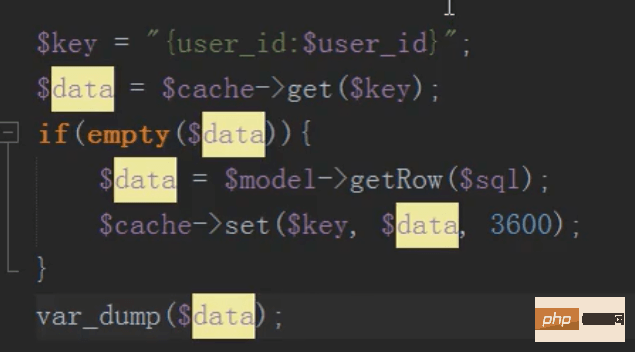
mysql分布式之缓存(memcache)的应用
将数据放入缓存中,节省数据库开销,先去缓存中查,如果有直接取出,如果没有,去数据库查,然后存入缓存中
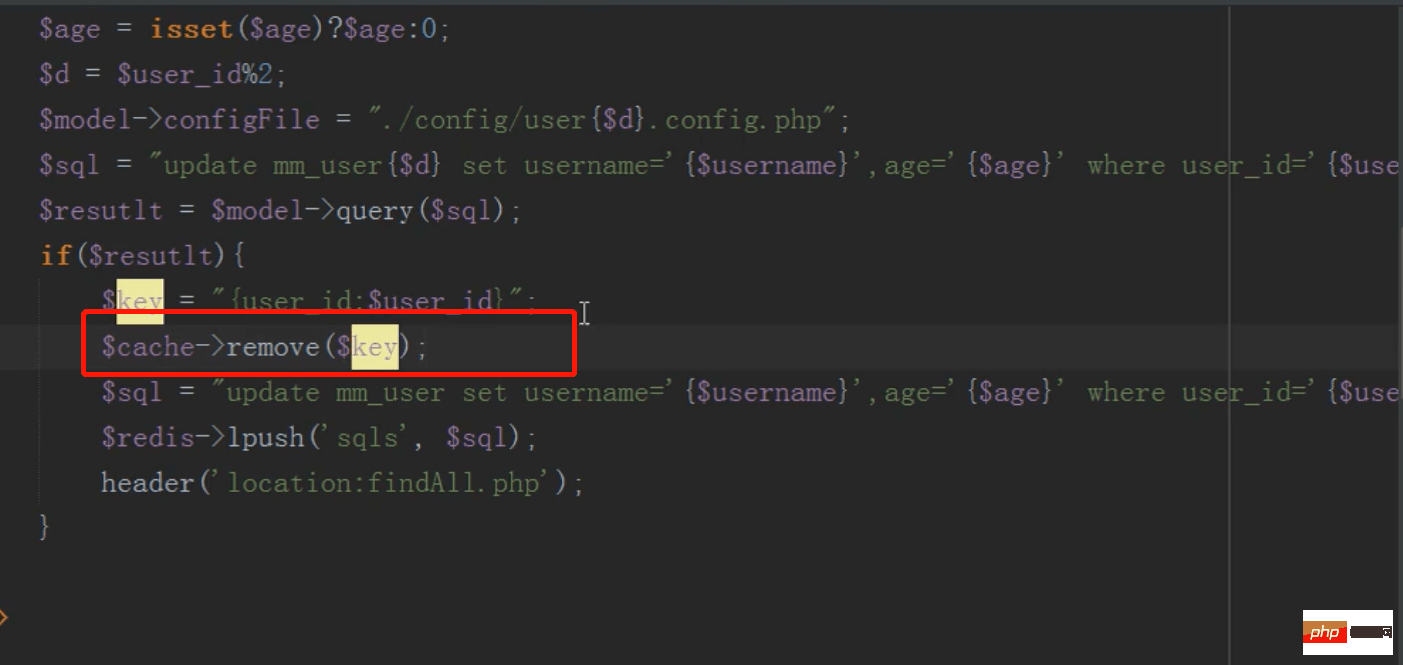
在编辑信息之后需要删除缓存,不然一直读取的是缓存的数据而不是修改过的数据
Atas ialah kandungan terperinci PHP结合MySQL完成千万级数据处理. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1378
1378
 52
52

 Cara menggunakan iterator dan algoritma rekursif untuk memproses data dalam C#
Oct 08, 2023 pm 07:21 PM
Cara menggunakan iterator dan algoritma rekursif untuk memproses data dalam C#
Oct 08, 2023 pm 07:21 PM
Cara menggunakan iterator dan algoritma rekursif untuk memproses data dalam C# memerlukan contoh kod khusus Dalam C#, iterator dan algoritma rekursif ialah dua kaedah pemprosesan data yang biasa digunakan. Iterator boleh membantu kami merentasi elemen dalam koleksi, dan algoritma rekursif boleh menangani masalah yang kompleks dengan cekap. Artikel ini memperincikan cara menggunakan iterator dan algoritma rekursif untuk memproses data dan menyediakan contoh kod khusus. Menggunakan Iterator untuk Memproses Data Dalam C#, kita boleh menggunakan iterator untuk mengulang elemen dalam koleksi tanpa mengetahui saiz koleksi terlebih dahulu. Melalui iterator, I
 Panda dengan mudah membaca data daripada pangkalan data SQL
Jan 09, 2024 pm 10:45 PM
Panda dengan mudah membaca data daripada pangkalan data SQL
Jan 09, 2024 pm 10:45 PM
Alat pemprosesan data: Pandas membaca data daripada pangkalan data SQL dan memerlukan contoh kod khusus Memandangkan jumlah data terus berkembang dan kerumitannya meningkat, pemprosesan data telah menjadi bahagian penting dalam masyarakat moden. Dalam proses pemprosesan data, Pandas telah menjadi salah satu alat pilihan untuk ramai penganalisis dan saintis data. Artikel ini akan memperkenalkan cara menggunakan pustaka Pandas untuk membaca data daripada pangkalan data SQL dan menyediakan beberapa contoh kod khusus. Pandas ialah alat pemprosesan dan analisis data yang berkuasa berdasarkan Python
 Bagaimana untuk melaksanakan fungsi tolak data masa nyata dalam MongoDB
Sep 21, 2023 am 10:42 AM
Bagaimana untuk melaksanakan fungsi tolak data masa nyata dalam MongoDB
Sep 21, 2023 am 10:42 AM
Cara melaksanakan fungsi tolak data masa nyata dalam MongoDB MongoDB ialah pangkalan data NoSQL berorientasikan dokumen, yang dicirikan oleh model data berskala tinggi dan fleksibel. Dalam sesetengah senario aplikasi, kami perlu menolak kemas kini data kepada klien dalam masa nyata untuk mengemas kini antara muka atau melaksanakan operasi yang sepadan tepat pada masanya. Artikel ini akan memperkenalkan cara melaksanakan fungsi tolak masa nyata data dalam MongoDB dan memberikan contoh kod khusus. Terdapat banyak cara untuk melaksanakan fungsi tolak masa nyata, seperti menggunakan tinjauan pendapat, tinjauan panjang, Web
 Bagaimanakah Golang meningkatkan kecekapan pemprosesan data?
May 08, 2024 pm 06:03 PM
Bagaimanakah Golang meningkatkan kecekapan pemprosesan data?
May 08, 2024 pm 06:03 PM
Golang meningkatkan kecekapan pemprosesan data melalui konkurensi, pengurusan memori yang cekap, struktur data asli dan perpustakaan pihak ketiga yang kaya. Kelebihan khusus termasuk: Pemprosesan selari: Coroutine menyokong pelaksanaan berbilang tugas pada masa yang sama. Pengurusan memori yang cekap: Mekanisme kutipan sampah secara automatik menguruskan memori. Struktur data yang cekap: Struktur data seperti kepingan, peta dan saluran mengakses dan memproses data dengan pantas. Perpustakaan pihak ketiga: meliputi pelbagai perpustakaan pemprosesan data seperti fasthttp dan x/text.
 Gunakan Redis untuk meningkatkan kecekapan pemprosesan data aplikasi Laravel
Mar 06, 2024 pm 03:45 PM
Gunakan Redis untuk meningkatkan kecekapan pemprosesan data aplikasi Laravel
Mar 06, 2024 pm 03:45 PM
Gunakan Redis untuk meningkatkan kecekapan pemprosesan data aplikasi Laravel Dengan pembangunan berterusan aplikasi Internet, kecekapan pemprosesan data telah menjadi salah satu fokus pembangun. Apabila membangunkan aplikasi berdasarkan rangka kerja Laravel, kami boleh menggunakan Redis untuk meningkatkan kecekapan pemprosesan data dan mencapai capaian pantas dan caching data. Artikel ini akan memperkenalkan cara menggunakan Redis untuk pemprosesan data dalam aplikasi Laravel dan memberikan contoh kod khusus. 1. Pengenalan kepada Redis Redis ialah data dalam memori berprestasi tinggi
 Bagaimanakah keupayaan pemprosesan data dalam Laravel dan CodeIgniter dibandingkan?
Jun 01, 2024 pm 01:34 PM
Bagaimanakah keupayaan pemprosesan data dalam Laravel dan CodeIgniter dibandingkan?
Jun 01, 2024 pm 01:34 PM
Bandingkan keupayaan pemprosesan data Laravel dan CodeIgniter: ORM: Laravel menggunakan EloquentORM, yang menyediakan pemetaan hubungan kelas-objek, manakala CodeIgniter menggunakan ActiveRecord untuk mewakili model pangkalan data sebagai subkelas kelas PHP. Pembina pertanyaan: Laravel mempunyai API pertanyaan berantai yang fleksibel, manakala pembina pertanyaan CodeIgniter lebih ringkas dan berasaskan tatasusunan. Pengesahan data: Laravel menyediakan kelas Pengesah yang menyokong peraturan pengesahan tersuai, manakala CodeIgniter mempunyai kurang fungsi pengesahan terbina dalam dan memerlukan pengekodan manual peraturan tersuai. Kes praktikal: Contoh pendaftaran pengguna menunjukkan Lar
 Alat pemprosesan data: teknik yang cekap untuk membaca fail Excel dengan panda
Jan 19, 2024 am 08:58 AM
Alat pemprosesan data: teknik yang cekap untuk membaca fail Excel dengan panda
Jan 19, 2024 am 08:58 AM
Dengan peningkatan populariti pemprosesan data, semakin ramai orang memberi perhatian kepada cara menggunakan data dengan cekap dan menjadikan data berfungsi untuk diri mereka sendiri. Dalam pemprosesan data harian, jadual Excel sudah pasti format data yang paling biasa. Walau bagaimanapun, apabila sejumlah besar data perlu diproses, pengendalian Excel secara manual jelas akan menjadi sangat memakan masa dan susah payah. Oleh itu, artikel ini akan memperkenalkan alat pemprosesan data yang cekap - panda, dan cara menggunakan alat ini untuk membaca fail Excel dengan cepat dan melaksanakan pemprosesan data. 1. Pengenalan kepada panda panda
 Menggunakan Panda untuk menamakan semula nama lajur untuk pemprosesan data yang cekap
Jan 11, 2024 pm 05:14 PM
Menggunakan Panda untuk menamakan semula nama lajur untuk pemprosesan data yang cekap
Jan 11, 2024 pm 05:14 PM
Pemprosesan data yang cekap: Menggunakan Panda untuk mengubah suai nama lajur memerlukan contoh kod khusus Pemprosesan data merupakan bahagian yang sangat penting dalam analisis data, dan semasa proses pemprosesan data, selalunya perlu mengubah suai nama lajur data. Pandas ialah perpustakaan pemprosesan data yang berkuasa yang menyediakan pelbagai kaedah dan fungsi untuk membantu kami memproses data dengan cepat dan cekap. Artikel ini akan memperkenalkan cara menggunakan Panda untuk mengubah suai nama lajur dan memberikan contoh kod khusus. Dalam analisis data sebenar, nama lajur data asal mungkin mempunyai piawaian penamaan yang tidak konsisten dan sukar untuk difahami.
