

介绍python60行代码写一个简单的笔趣阁爬虫


推荐(免费):Python视频教程
文章目录
- 系列文章目录
- 前言
- 一、网页解析
- 二、代码填写
- 1.获取Html及写入方法
- 2.其余代码
- 总结
前言
利用python写一个简单的笔趣阁爬虫,根据输入的小说网址爬取整个小说并保存到txt文件。爬虫用到了BeautifulSoup库的select方法
结果如图所示: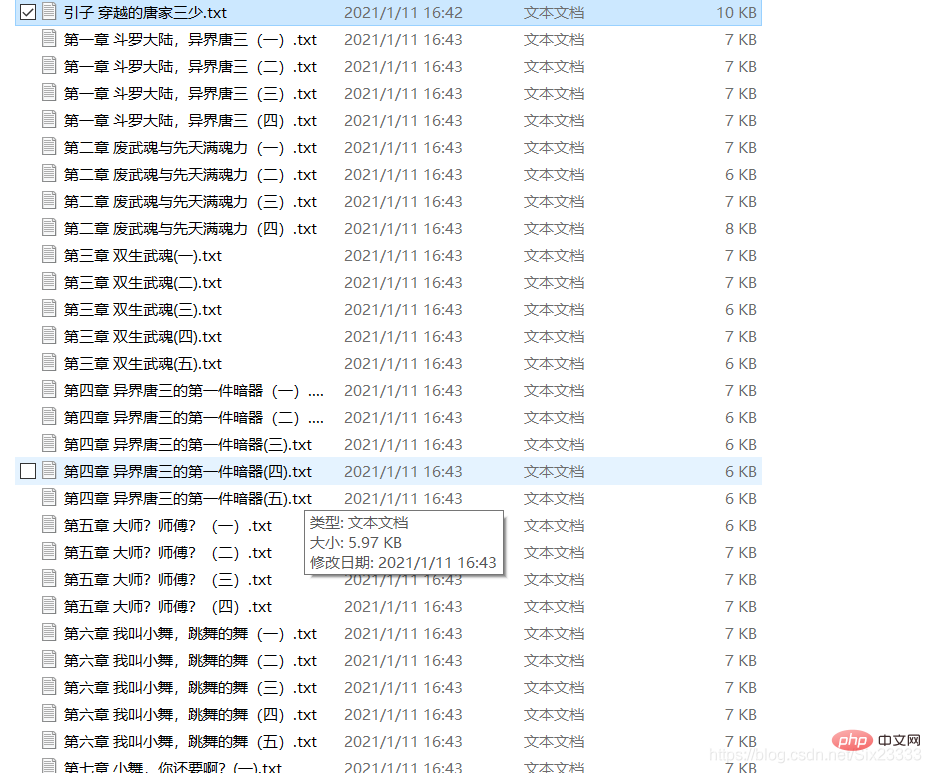
本文只用于学习爬虫
一、网页解析
这里以斗罗大陆小说为例 网址:
http://www.biquge001.com/Book/2/2486/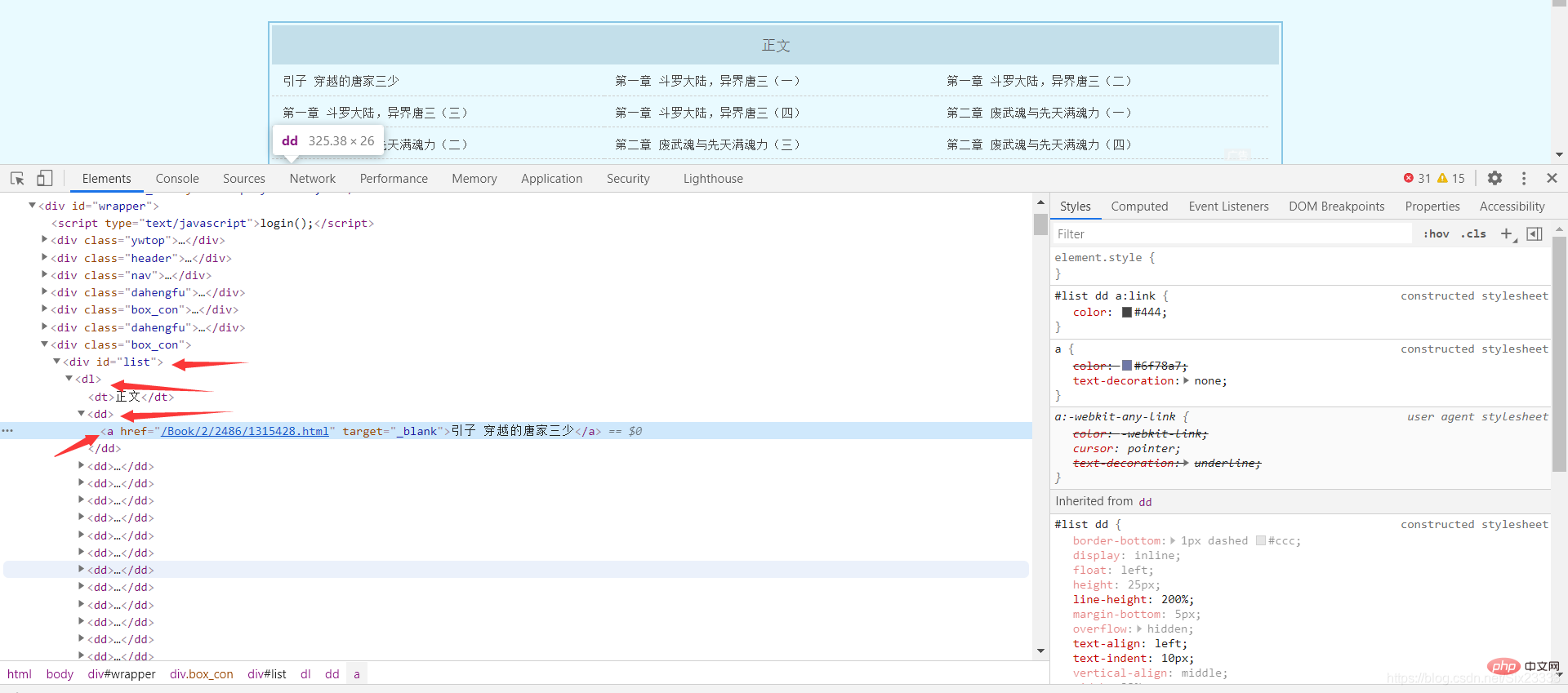
可以发现每章的网页地址和章节名都放在了 <"p id=list dl dd a>中的a标签中,所以利用BeautfulSoup中的select方法可以得到网址和章节名
Tag = BeautifulSoup(getHtmlText(url), "html.parser") #这里的getHtmlText是自己写的获取html的方法urls = Tag.select("p #list dl dd a")然后遍历列表
for url in urls: href = "http://www.biquge001.com/" + url['href'] # 字符串的拼接 拼接成正确的网址 pageName = url.text # 每章的章名
然后每章小说的内容都存放在
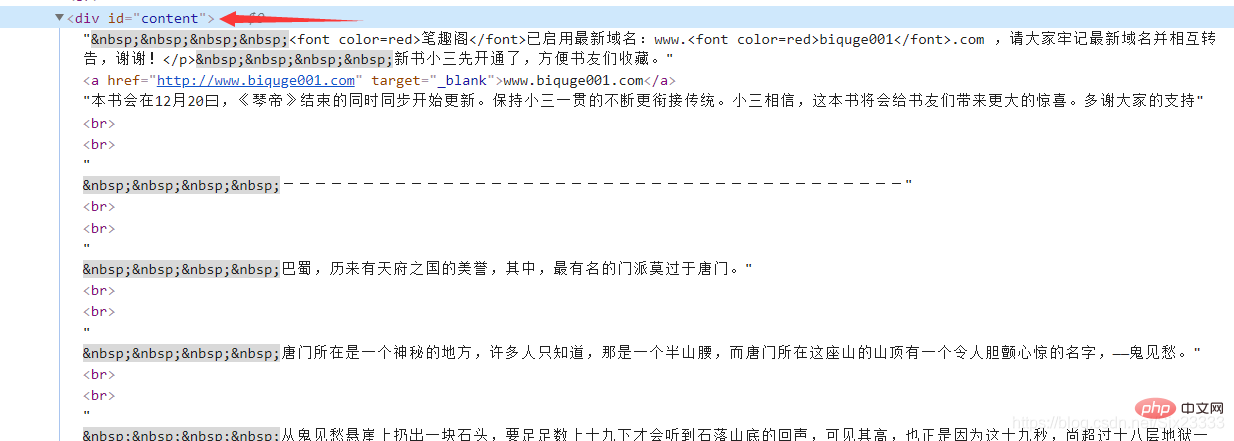
substance = Tag.select("p #content") # 文章的内容最后同理在首页获取小说的名称
<"p id = info h1>
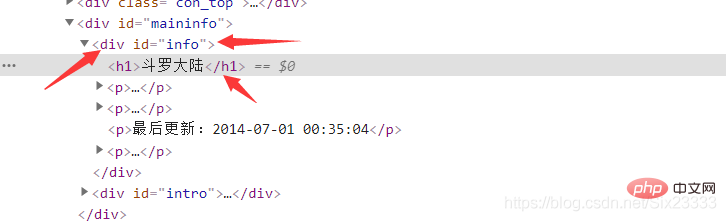
bookName = Tag.select("p #info h1")
二、代码填写
1.获取Html及写入方法
def getHtmlText(url): r = requests.get(url, headers=headers) r.encoding = r.apparent_encoding # 编码转换 r.raise_for_status() return r.textdef writeIntoTxt(filename, content): with open(filename, "w", encoding="utf-8") as f: f.write(content) f.close() print(filename + "已完成")
2.其余代码
代码如下(示例):
url = "http://www.biquge001.com/Book/2/2486/"substanceStr = ""bookName1 = ""html = getHtmlText(url)# 判断是否存在这个文件Tag = BeautifulSoup(getHtmlText(url), "html.parser")urls = Tag.select("p #list dl dd a")bookName = Tag.select("p #info h1")for i in bookName:
bookName1 = i.textif not os.path.exists(bookName1):
os.mkdir(bookName1)
print(bookName1 + "创建完成")else:
print("文件已创建")for url in urls:
href = "http://www.biquge001.com/" + url['href'] # 字符串的拼接 拼接成正确的网址
pageName = url.text # 每章的章名
path = bookName1 + "\\" # 路径
fileName = path + url.text + ".txt" # 文件名 = 路径 + 章节名 + ".txt"
Tag = BeautifulSoup(getHtmlText(href), "html.parser") # 解析每张的网页
substance = Tag.select("p #content") # 文章的内容
for i in substance:
substanceStr = i.text
writeIntoTxt(fileName, substanceStr)
time.sleep(1)
总结
简单利用了BeautfulSoup的select方法对笔趣阁的网页进行了爬取
更多相关学习敬请关注Python教程栏目!
Atas ialah kandungan terperinci 介绍python60行代码写一个简单的笔趣阁爬虫. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1377
1377
 52
52

 Bagaimana untuk menyelesaikan masalah kebenaran yang dihadapi semasa melihat versi Python di Terminal Linux?
Apr 01, 2025 pm 05:09 PM
Bagaimana untuk menyelesaikan masalah kebenaran yang dihadapi semasa melihat versi Python di Terminal Linux?
Apr 01, 2025 pm 05:09 PM
Penyelesaian kepada Isu Kebenaran Semasa Melihat Versi Python di Terminal Linux Apabila anda cuba melihat versi Python di Terminal Linux, masukkan Python ...
 Bagaimana cara menyalin seluruh lajur satu data ke dalam data data lain dengan struktur yang berbeza di Python?
Apr 01, 2025 pm 11:15 PM
Bagaimana cara menyalin seluruh lajur satu data ke dalam data data lain dengan struktur yang berbeza di Python?
Apr 01, 2025 pm 11:15 PM
Apabila menggunakan Perpustakaan Pandas Python, bagaimana untuk menyalin seluruh lajur antara dua data data dengan struktur yang berbeza adalah masalah biasa. Katakan kita mempunyai dua DAT ...
 Bagaimana Mengajar Asas Pengaturcaraan Pemula Komputer Dalam Kaedah Projek dan Masalah Dikemukakan Dalam masa 10 Jam?
Apr 02, 2025 am 07:18 AM
Bagaimana Mengajar Asas Pengaturcaraan Pemula Komputer Dalam Kaedah Projek dan Masalah Dikemukakan Dalam masa 10 Jam?
Apr 02, 2025 am 07:18 AM
Bagaimana Mengajar Asas Pengaturcaraan Pemula Komputer Dalam masa 10 jam? Sekiranya anda hanya mempunyai 10 jam untuk mengajar pemula komputer beberapa pengetahuan pengaturcaraan, apa yang akan anda pilih untuk mengajar ...
 Bagaimanakah uvicorn terus mendengar permintaan http tanpa serving_forever ()?
Apr 01, 2025 pm 10:51 PM
Bagaimanakah uvicorn terus mendengar permintaan http tanpa serving_forever ()?
Apr 01, 2025 pm 10:51 PM
Bagaimanakah Uvicorn terus mendengar permintaan HTTP? Uvicorn adalah pelayan web ringan berdasarkan ASGI. Salah satu fungsi terasnya ialah mendengar permintaan HTTP dan teruskan ...
 Bagaimana secara dinamik membuat objek melalui rentetan dan panggil kaedahnya dalam Python?
Apr 01, 2025 pm 11:18 PM
Bagaimana secara dinamik membuat objek melalui rentetan dan panggil kaedahnya dalam Python?
Apr 01, 2025 pm 11:18 PM
Di Python, bagaimana untuk membuat objek secara dinamik melalui rentetan dan panggil kaedahnya? Ini adalah keperluan pengaturcaraan yang biasa, terutamanya jika perlu dikonfigurasikan atau dijalankan ...
 Bagaimana untuk mengelakkan dikesan oleh penyemak imbas apabila menggunakan fiddler di mana-mana untuk membaca lelaki-dalam-tengah?
Apr 02, 2025 am 07:15 AM
Bagaimana untuk mengelakkan dikesan oleh penyemak imbas apabila menggunakan fiddler di mana-mana untuk membaca lelaki-dalam-tengah?
Apr 02, 2025 am 07:15 AM
Cara mengelakkan dikesan semasa menggunakan fiddlerevery di mana untuk bacaan lelaki-dalam-pertengahan apabila anda menggunakan fiddlerevery di mana ...
 Apakah beberapa perpustakaan Python yang popular dan kegunaan mereka?
Mar 21, 2025 pm 06:46 PM
Apakah beberapa perpustakaan Python yang popular dan kegunaan mereka?
Mar 21, 2025 pm 06:46 PM
Artikel ini membincangkan perpustakaan Python yang popular seperti Numpy, Pandas, Matplotlib, Scikit-Learn, Tensorflow, Django, Flask, dan Permintaan, memperincikan kegunaan mereka dalam pengkomputeran saintifik, analisis data, visualisasi, pembelajaran mesin, pembangunan web, dan h
 Apakah ungkapan biasa?
Mar 20, 2025 pm 06:25 PM
Apakah ungkapan biasa?
Mar 20, 2025 pm 06:25 PM
Ekspresi biasa adalah alat yang berkuasa untuk memadankan corak dan manipulasi teks dalam pengaturcaraan, meningkatkan kecekapan dalam pemprosesan teks merentasi pelbagai aplikasi.
