

InnoDB的数据存储文件和MyISAM的不同

MySQL教程栏目介绍的索引为什么用B+Tree

前言
这篇文章的题目,是我真实在面试过程中遇到的问题,某互联网众筹公司在考察面试者MySQL相关知识的第一个问题,我当时还是比较懵的,没想到这年轻人不讲武德,不按套路出牌,一般的问MySQL的相关知识的时候,不都是问索引优化以及索引失效等相关问题吗?怎么还出来了,存储文件的不同?哪怕考察个MVCC机制也行啊。所以这次我就好好总结总结这部分知识点。
为什么需要建立索引
首先,我们都知道建立索引的目的是为了提高查询速度,那么为什么有了索引就能提高查询速度呢?
我们来看一下,一个索引的示意图。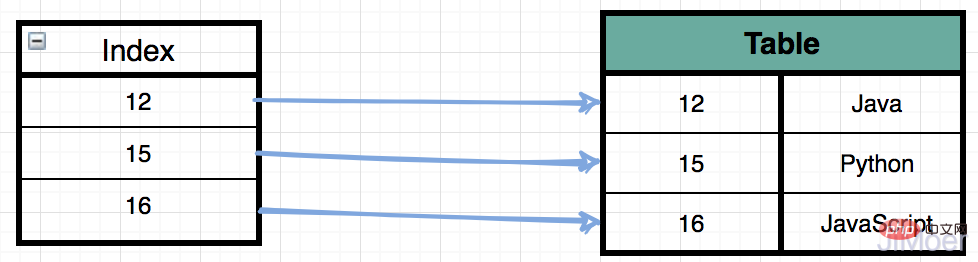
如果我有一个SQL语句是:select * from Table where id = 15 那么在没有索引的情况下其实是会进行全表扫描的,就是挨个去找,直到找到id=15的这条记录,时间复杂度是O(n);
如果在有索引的情况下去进行查询呢。首先会根据id=15,在索引值里面进行二分查找,二分查找的效率是很高的,它的时间复杂度是O(logn);
这就是索引为什么能提高查询效率了,但是索引数据的量也是比较大的,所以一般并不是存储在内存中的,都是直接存储在磁盘中的,所以对磁盘中的文件内容进行读取,免不了要进行磁盘IO。
MySQL的索引为什么使用B+Tree
上面我们也说了,索引数据一般是存储在磁盘中的,但是计算数据都是要在内存中进行的,如果索引文件很大的话,并不能一次都加载进内存,所以在使用索引进行数据查找的时候是会进行多次磁盘IO,将索引数据分批的加载到内存中,<strong>因此一个好的索引的数据结构,在得到正确的结果前提下,一定是磁盘IO次数最少的。</strong>
Hash类型
目前MySQL其实是有两种索引数据类型可以选择的,一个是BTree(实际是B+Tree)、一个Hash。
但是为什么在实际的使用过程中,基本上大部分都是选择BTree呢?
因为如果使用Hash类型的索引,MySQL在创建索引的时候,会对索引数据进行一次Hash运算,这样根据Hash值就能快速的定位到磁盘指针了,就算数据量很大,也能快速精准的定位到数据。
- 但是像
select * from Table where id > 15这种范围查询,Hash类型的索引就搞不定了,对这种范围查询,会直接全表扫描,另外Hash类型的索引也搞不定排序。 - 还有就是虽然MySQL底层做了一系列的处理,但还是不能完全的保证,不产生Hash碰撞。
二叉树
那MySQL为什么没有二叉树作为它的索引数据结构呢?我们都知道,二叉树是通过二分查找来进行定位数据的,所以效果还是不错的,时间复杂度是O(logn);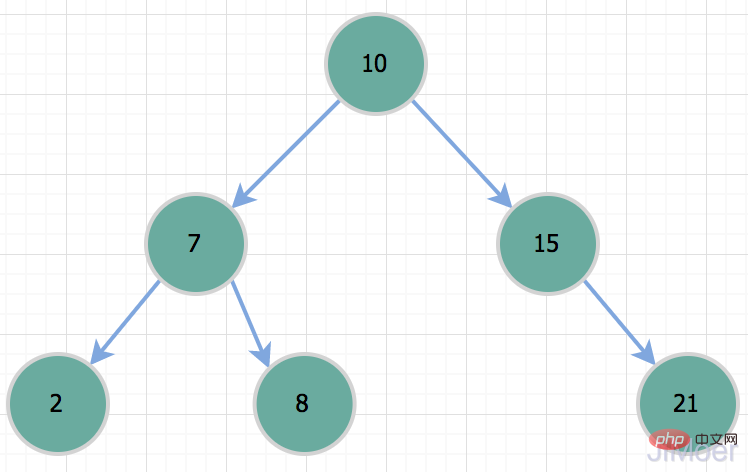
但是二叉树有个问题,就是在特殊情况下,它会退化成一根棍子,也就是一个单向链表。这个时候,它的时间复杂度就会退化成O(n);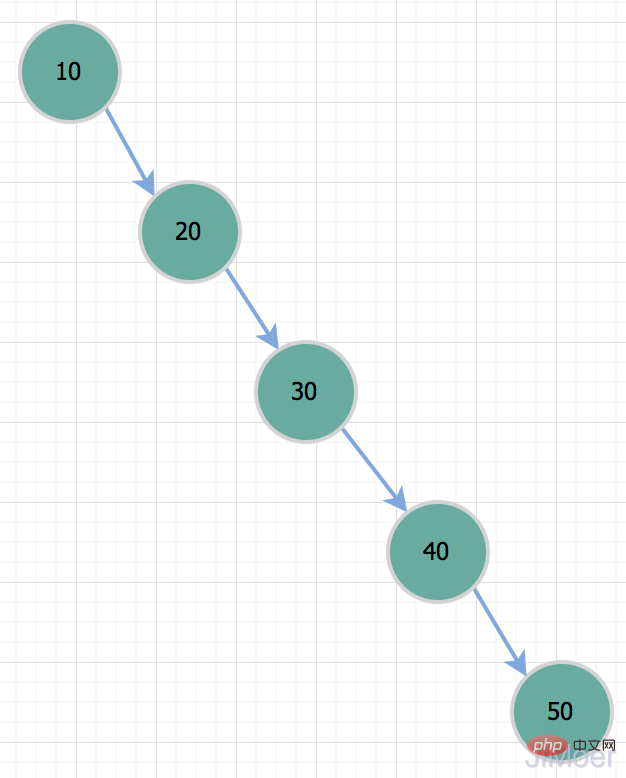
所以当我们要查询id=50的记录时,其实和全表扫描是一样的了。所以因为存在这种情况,二叉树不适合作为索引的数据结构。
平衡二叉树
那么既然二叉树,在特殊情况下会退化成链表,那么平衡二叉树为什么不可以呢?
平衡二叉树的子节点高度差不能超过1,像下图中的二叉树,关键字为15的节点,它的左子节点高度为0,右子节点高度为1,高度差不超过1,所以下面这棵树是一棵平衡二叉树。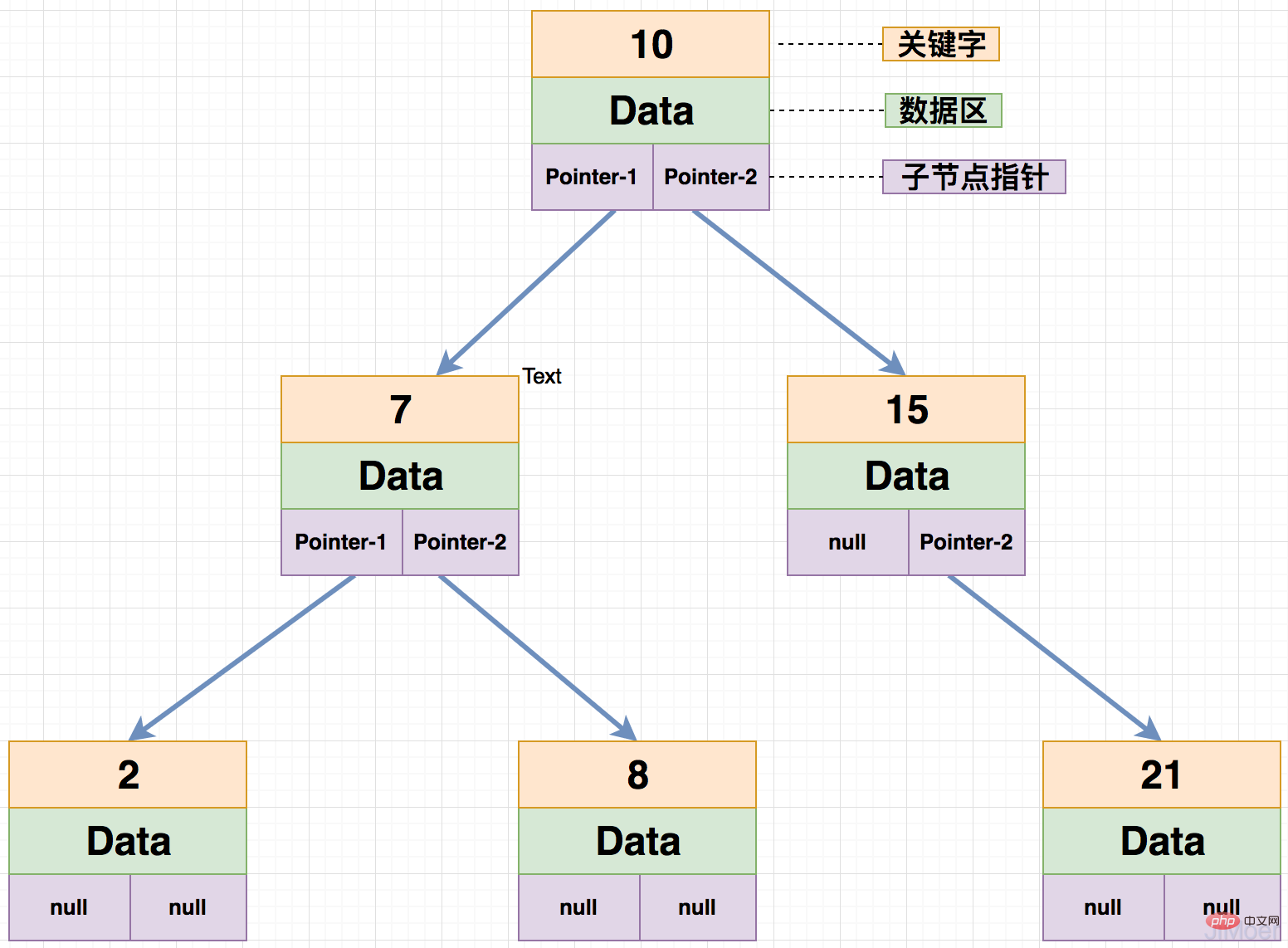
因为能保持平衡,所以它的查询时间复杂度为O(logN),至于怎么保持平衡的,主要是做一些左旋,右旋等,具体保持平衡的细节不是本文主要内容,想了解的可自行搜索。
用这个数据结构来做MySQL的索引会有 什么问题呢?
- 磁盘IO过多:在MySQL当中,一次IO操作只读取一个节点,那么一个节点若是最多就两个子节点的话,那么就只有这两个子节点的查询范围,所以要精确到具体的数据时,就需要进行多次读取,如果树非常深的话,那么将会进行大量的磁盘IO。性能自然下降了。
- 空间利用率低:对于平衡二叉树来说,每个节点值保存一个关键字,一个数据区,两个子节点的指针。这样导致了,一次辛辛苦苦的IO操作就只加载这么点数据,实在是有点杀鸡用牛刀了。
- 查询效果不稳定:如果在一个高度很深的平衡二叉树中,若是查询的数据正好是根节点,那么就会很快的查到,若是查询的数据正好是叶子节点,那么会进行多次磁盘IO后才能返回,响应时间有可能和根节点的不在一个数量级上。
虽然说二叉树解决的平衡的问题,但是也带来了新的问题,那就是由于它本身树的深度的,会造成一系列的效率问题。
那么为了解决平衡二叉树的这类问题,平衡多叉树(Balance Tree)就成为了更好的选择。
平衡多叉树(Balance Tree–B-Tree)
B-Tree的意思是平衡多叉树,一般B-Tree中的一个节点有多少个子节点,我们就称为多少阶的B-Tree。通常用m表示阶数,当m为2的时候,就是平衡二叉树。
一棵B-Tree的每个节点上最多能有m-1个关键字,最少要存放Math.ceil(m/2)-1个关键字,所有的叶子节点都在同一层。如下图就是一个4阶的B-Tree。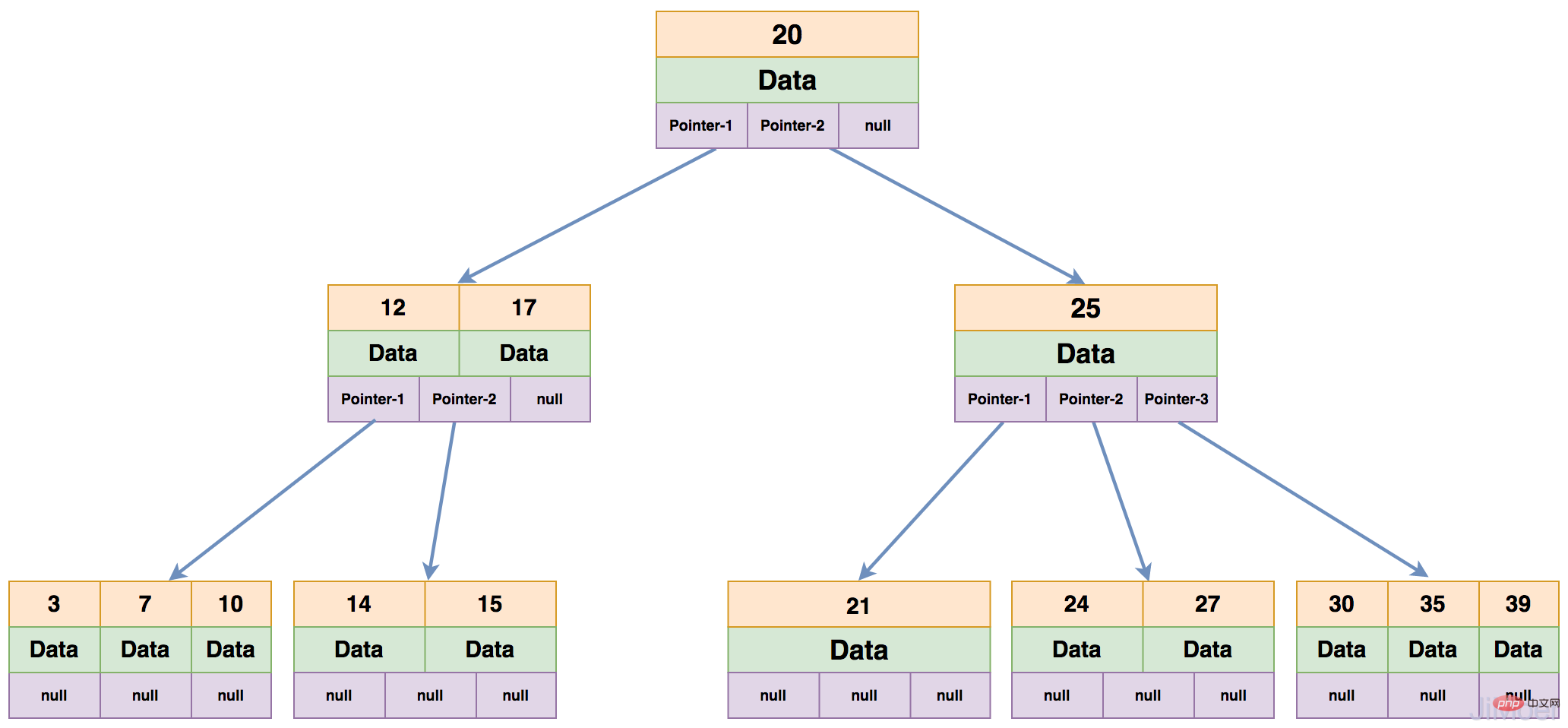
那么我们看一下B-Tree是如何进行查找数据的:
- 若是查询id=7的数据,先将关键字20的节点加载进内存,判断出7比20小;
- 那么加载第一个子节点,若查询的数据等于12或17则直接返回,不等于就继续向下找,发现7小于12;
- 那么继续加载第一个子节点中去,找到7之后,直接将7下面的data数据返回。
这样整个操作其实进行了3次IO操作,但实际上一般的B-Tree每层都是有很多分支(通常都大于100)。
MySQL为了能更好的利用磁盘的IO能力,将操作页的大小设置为了16K,即每个节点的大小为16K。如果每个节点中的关键字都是int类型的,那么就是4个字节,若数据区的大小为8个字节,节点指针再占4个字节,那么B-Tree的每个节点中可以保存的关键字个数为:(16*1000) / (4+8+4)=1000,每个节点最多可存储1000个关键字,每一个节点最多可以有1001个分支节点。
这样在查询索引数据的时候,一次磁盘IO操作可以将1000个关键字,读取到内存中进行计算,B-Tree的一次磁盘IO的操作,顶上平衡二叉数据的N次磁盘IO操作了。
要注意的是:B-Tree为了保证数据的平衡,会做一系列的操作,这个保持平衡的过程比较耗时间,所以在创建索引的时候,要选择合适的字段,并且不要过多的创建索引,创建索引过多的话,在更新数据的时候,更新索引的过程也比较耗时。
还有就是不要选择低区分度字段值作为索引,例如性别字段,总共就两个值,那么就有可能会造成B-Tree的深度过大,索引效率降低。
B+Tree
B-Tree已经很好的解决平衡二叉树的问题了,并且也能保证查询效率了,那么为什么会有B+Tree呢?
我们先来B+Tree是什么样子的。
B+Tree是B-Tree的变种,B+Tree的每个节点关键字和m阶的公式关系和B-Tree的不一样了。
首先每个节点的子节点数量和每个节点可存储的关键字比例是1:1,其次就是查询数据的时候采用的是左闭合区间进行查询,还有就是分支节点中没有数据了只保存关键字和子节点指向,数据都存储在叶子节点。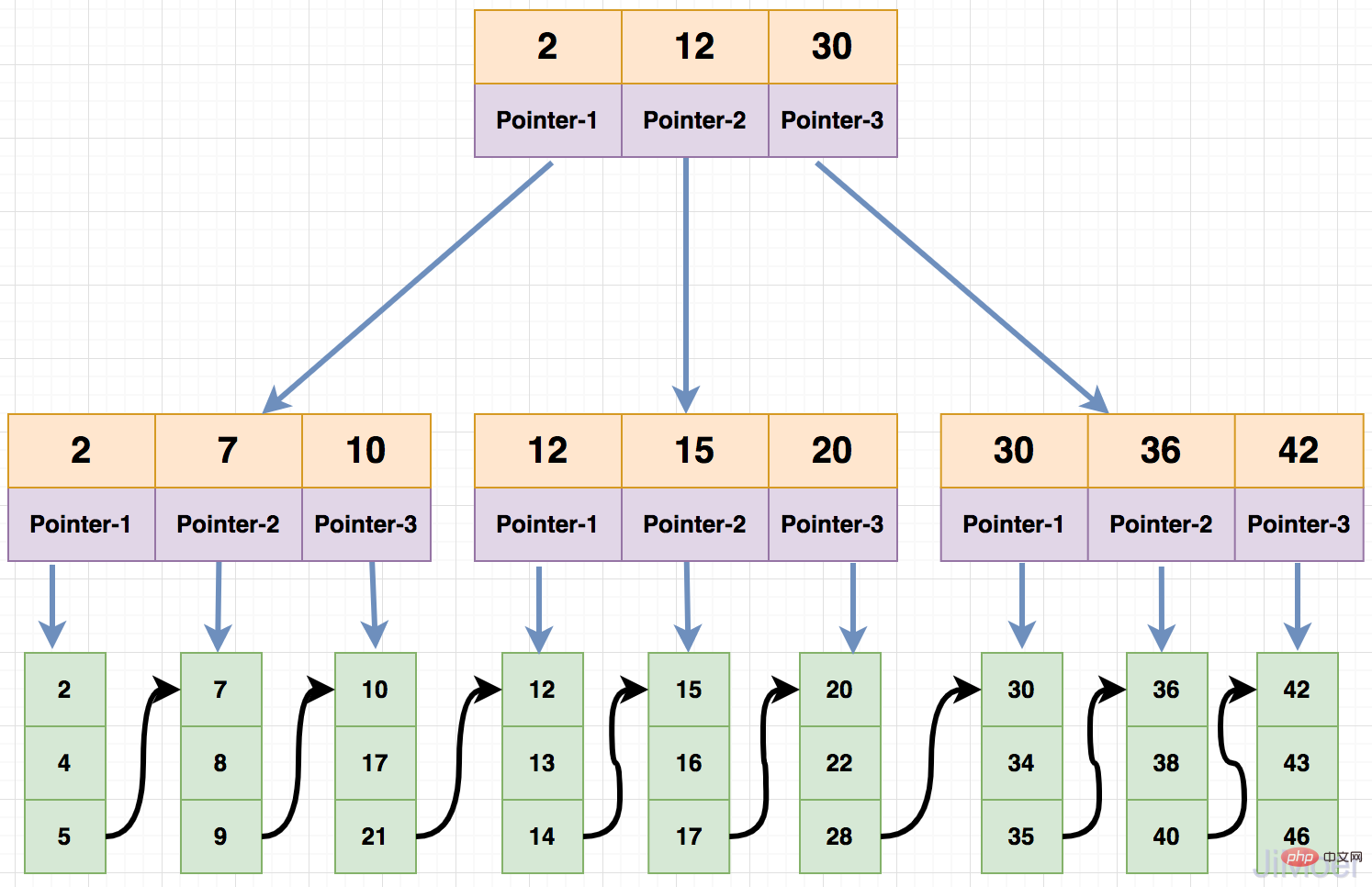
那么来看一下在B+Tree中是如何进行数据查询的。
例如:
- 现在要查询id=2的数据,那么会先将根节点取出,加载到内存中,发现
id=2存在于根节点,因为是左闭合区间存储数据,所以id<=2的都在根节点的第一个子节点上; - 那么取出第一个子节点,加载到内存中,发现当前节点存在
id=2的关键字,并且已经到了叶子节点了,那么直接取出叶子节点中的数据返回。
现在来看一下B-Tree和B+Tree的区别
- B+Tree的查询采用的左闭合区间,这样能更好的支持了自增索引的查询效果,所以一般在创建主键的时候通常都是自增的。这一点和B-Tree是不一样的。
- B+Tree中的根节点和分支节点上是不保存数据的,关键字相关的数据只保存在叶子节点上,这样保证了查询效果的稳定,任何查询都要走到叶子节点才能获取数据。而B-Tree在分支节点中保存了数据,若是命中关键字则直接返回数据。
- B+Tree的叶子节点是顺序排列的,并且相邻的两个叶子节点中具有顺序引用的关系,这样能更好的支持了范围查询。而B-Tree是没有这个顺序关系的。
MySQL的索引为什么选择了B+Tree
经过上面的层层分析,现在我们可以总结一下MySQL为什么选择了B+Tree作为它索引的数据结构呢。
首先和平衡二叉树相比,B+Tree的深度更低,节点保存关键字更多,磁盘IO次数更少,查询计算效率更好。
B+Tree的全局扫描能力更强,若是想根据索引数据对数据表进行全局扫描,B-Tree会将整棵树进行扫描,然后逐层遍历。而B+Tree呢,只需要遍历叶子节点即可,因为叶子节点之间存在顺序引用的关系。
B+Tree的磁盘IO读写能力更强,因为B+Tree的每个分支节点上只保存了关键字,这样每次磁盘IO在读写的时候,一页16K数据量可以存储更多的关键字了,每个节点上保存的关键字也比B-Tree更多了。这样B+Tree的一次磁盘IO加载的数据比B-Tree的多很多了。
B+Tree数据结构中有天然的排序能力,比其他数据结构排序能力更强而且排序时,是通过分支节点来进行的,若是需要将分支节点加载到内存中排序,一次加载的数据更多。
B+Tree的查询效果更稳定,因为所有的查询都是需要扫描到叶子节点才将数据返回的。效果只是稳定而不一定是最优,若是直接查询B-Tree的根节点数据,那么B-Tree只需要一次磁盘IO就可以直接将数据返回,反而是效果最优。
经过以上几点的分析,MySQL最终选择了B+Tree作为了它的索引的数据结构。
InnDB的数据存储文件和MyISAM的有何不同?
上面总结了MySQL的索引的数据结构,这次就可以说第二个问题了,因为这个问题其实和MySQL的索引还是有一定的关系的。
下面来看一下,先找到服务器桑MySQL存储数据的目录:
登录MySQL,打开MySQL的命令行界面:输入show variables like '%datadir%';,就能看到存储数据的目录了。
我的服务器中MySQL的存储数据的目录是在:
/var/lib/mysql/
进入到这个目录里后,能看到所有数据库的目录,新建一个study_test的数据库。
然后就进入
/var/lib/mysql/study_test
这个目录下,目前就只有一个文件,这个文件是用来记录创建数据库时配置的字符集的内容。
-rw-r----- 1 mysql mysql 60 1月 31 10:28 db.opt
现在新建两个表,第一个表的引擎类型选择InnoDB,第二个表的引擎类型选择MyISAM。
student_innodb:
CREATE TABLE `student_innodb` ( `id` bigint(20) NOT NULL AUTO_INCREMENT, `name` varchar(50) COLLATE utf8mb4_bin DEFAULT NULL, `age` int(11) DEFAULT NULL, `address` varchar(100) COLLATE utf8mb4_bin DEFAULT NULL, PRIMARY KEY (`id`), KEY `idx_name` (`name`) USING BTREE COMMENT 'name索引') ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin COMMENT='innodb引擎表';
student_myisam:
CREATE TABLE `student_myisam` ( `id` bigint(20) NOT NULL AUTO_INCREMENT, `name` varchar(50) COLLATE utf8mb4_bin DEFAULT NULL, `age` int(11) DEFAULT NULL, `address` varchar(100) COLLATE utf8mb4_bin DEFAULT NULL, PRIMARY KEY (`id`), KEY `idx_name` (`name`) USING BTREE COMMENT 'name索引') ENGINE=MyISAM DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin COMMENT='myISAM引擎类型表';
将两个表创建完成后,我们再进入到/var/lib/mysql/study_test看一下:
-rw-r----- 1 mysql mysql 60 1月 31 10:28 db.opt-rw-r----- 1 mysql mysql 8650 1月 31 10:41 student_innodb.frm-rw-r----- 1 mysql mysql 114688 1月 31 10:41 student_innodb.ibd-rw-r----- 1 mysql mysql 8650 1月 31 10:58 student_myisam.frm-rw-r----- 1 mysql mysql 0 1月 31 10:58 student_myisam.MYD-rw-r----- 1 mysql mysql 1024 1月 31 10:58 student_myisam.MYI
通过目录中的文件可看到创建表之后多了几个文件,这样也看出来了,InnoDB引擎类型的表和MyISAM引擎类型的表的文件差异。
这几个文件每个都是有自己的作用:
- InnoDB引擎的表文件,一共有两个:
- *.frm 这类文件是表的定义文件。
- *.ibd 这类文件是数据和索引存储文件。表数据和索引聚集存储,通过索引能直接查询到数据。
- MyIASM引擎的表文件,一共有三个:
- *.frm 这类文件是表的定义文件。
- *.MYD 这类文件是表数据文件,表中的所有数据都保存在此文件中。
- *.MYI 这类文件是表的索引文件,MyISAM存储引擎的索引数据单独存储。
MyISAM数据存储引擎,索引与数据的存储结构
MyISAM存储引擎在存储索引的时候,是将索引数据单独存储,并且索引的B+Tree最终指向的是数据存在的物理地址,而不是具体的数据。然后再根据物理地址去数据文件(*.MYD)中找到具体的数据。
如下图所示: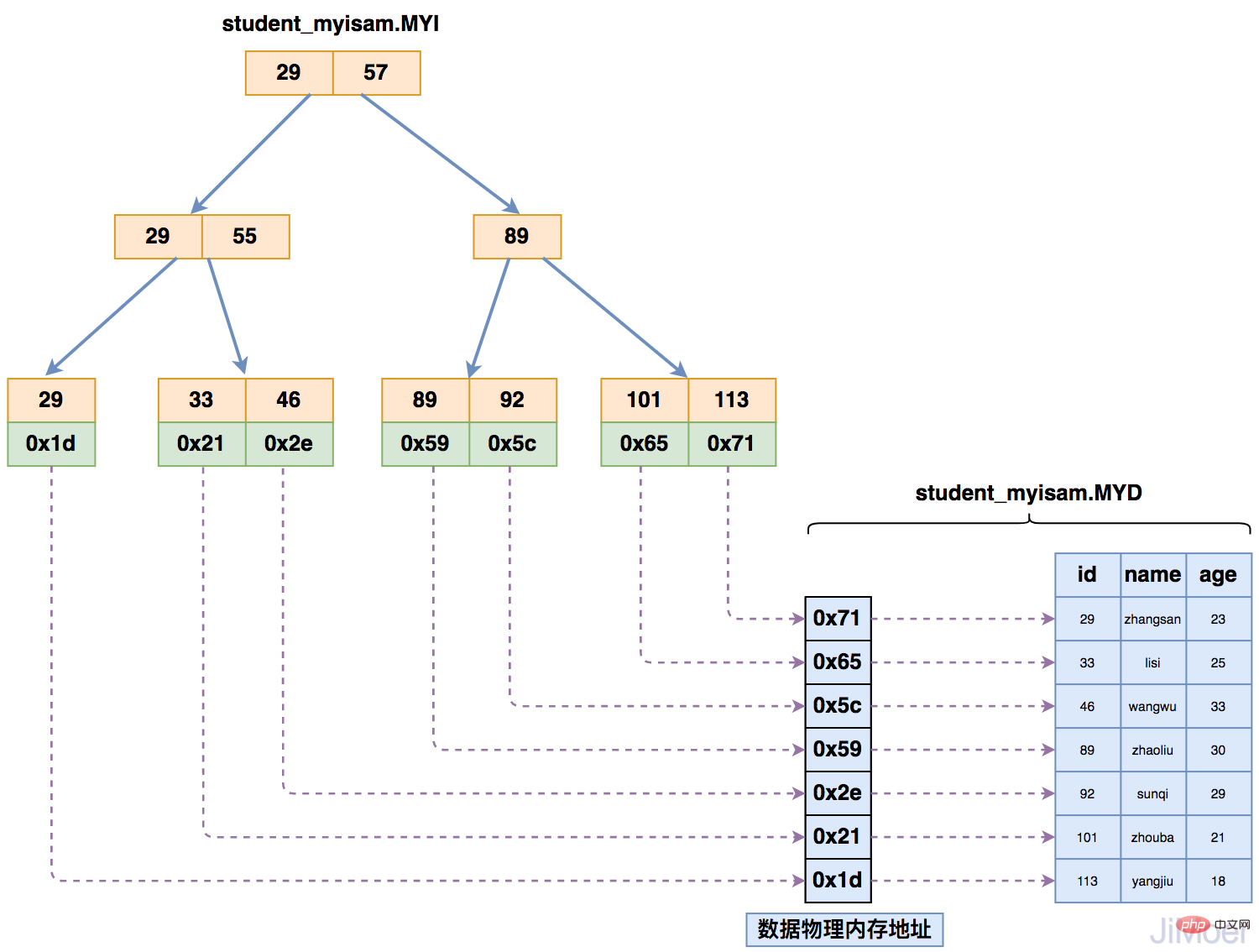
那么当存在多个索引时,多个索引都指向相同的物理地址。
如下图所示: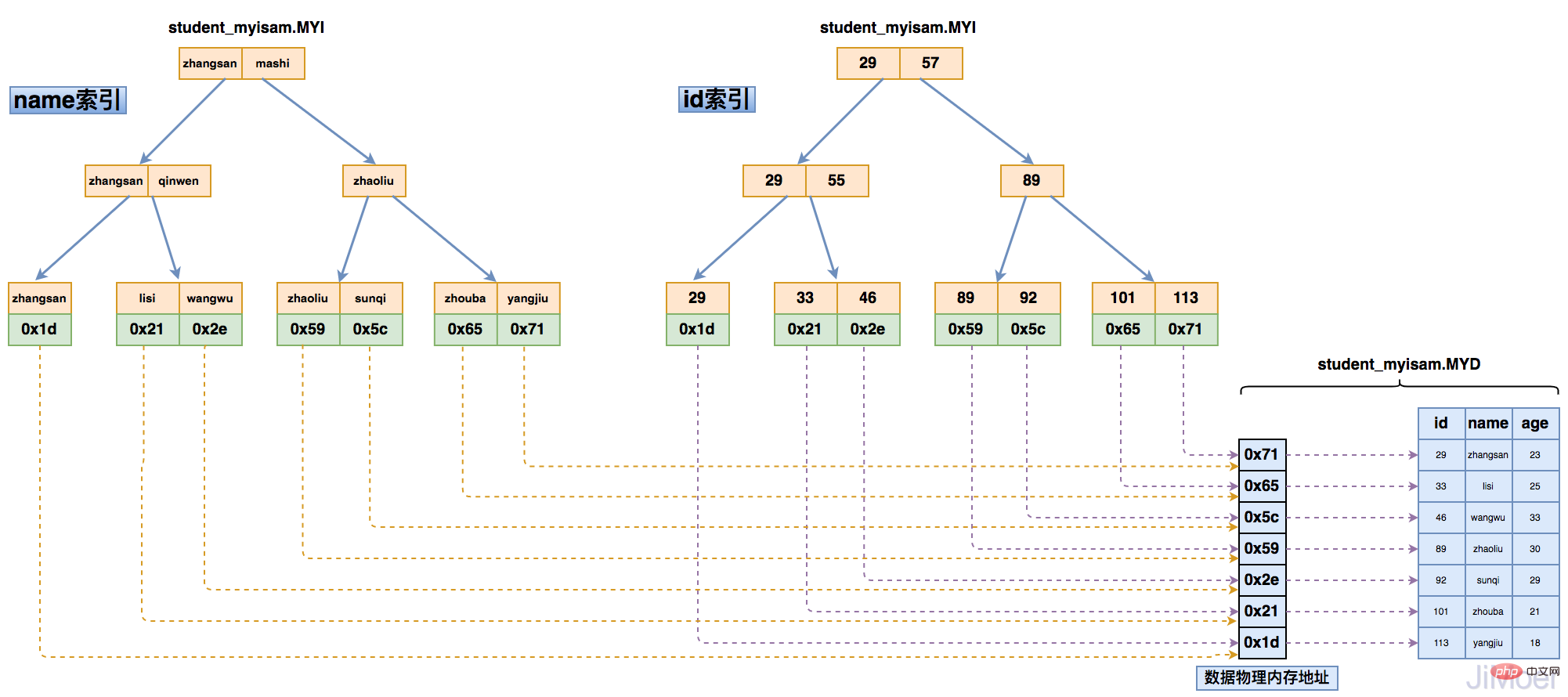
通过这个结构,我们可以看出来,MyISAM的存储引擎的索引都是同级别的,主键和非主键索引结构和查询方式完全一样。
InnoDB数据存储引擎,索引与数据的存储结构
首先InnoDB的索引分为聚簇索引和非聚簇索引,聚簇索引即保存关键字又保存数据,在B+Tree的每个分支节点上保存关键字,叶子节点上保存数据。
“聚簇”的意思是数据行被按照一定顺序一个个紧密地排列在一起存储。一个表只能有一个聚簇索引,因为在一个表中数据的存放方式只有一种,一般是主键作为聚簇索引,如果没有主键,InnoDB会默认生成一个隐藏的列作为主键。
如下图所示: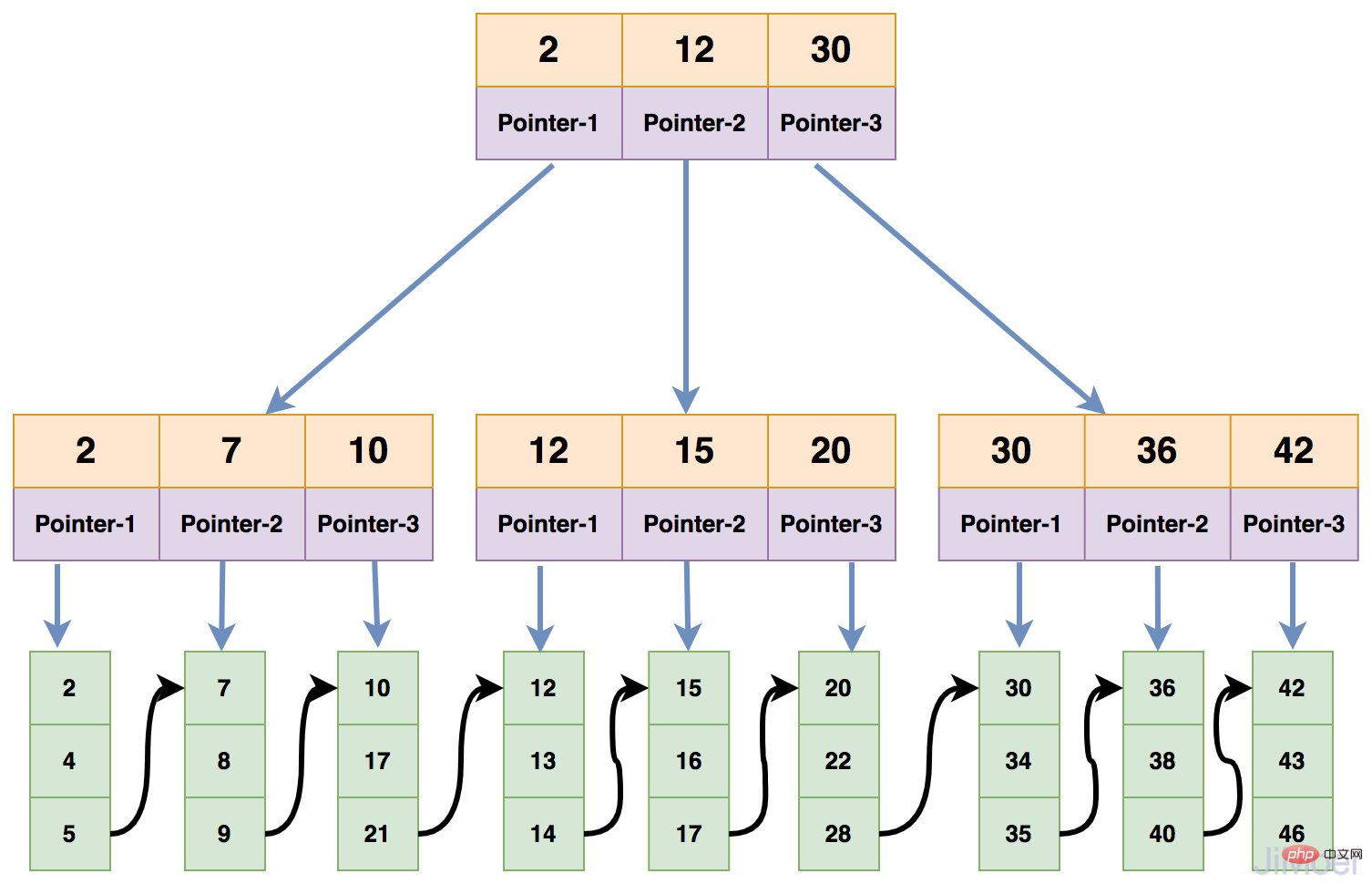
非聚簇索引,又称为二级索引,虽然也是在B+Tree的每个分支节点上保存关键字,但是叶子节点不是保存的数据,而是保存的主键值。通过二级索引去查询数据会先查询到数据对应的主键,然后再根据主键查询到具体的数据行。
如下图所示: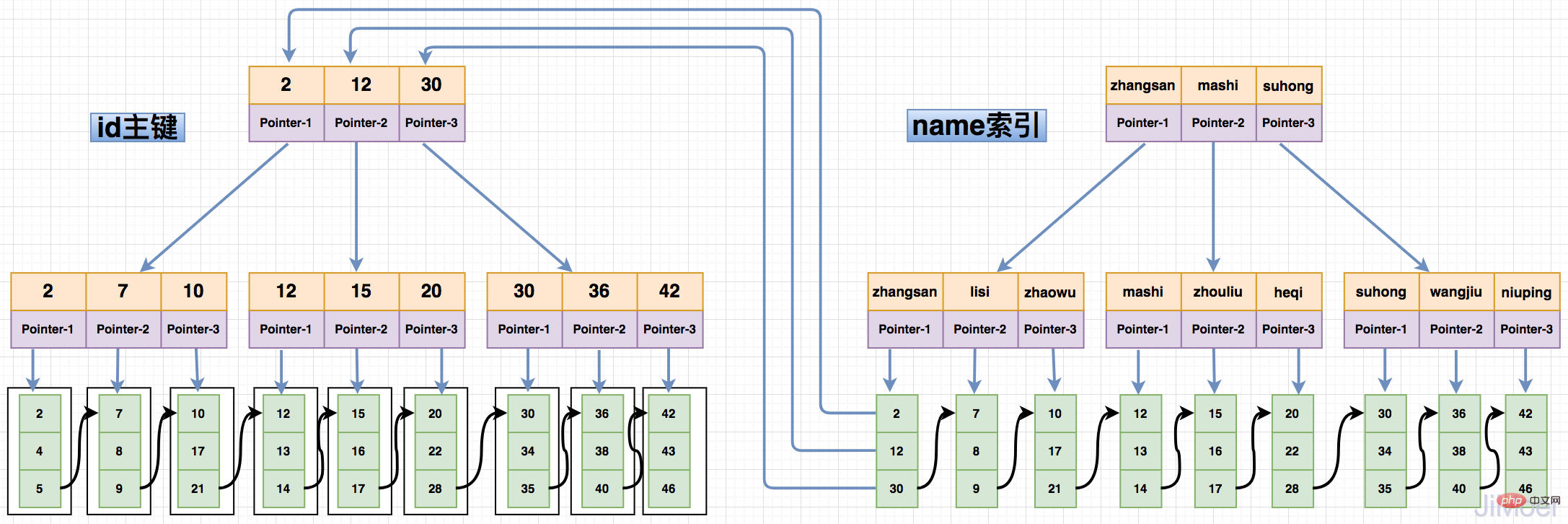
由于非聚簇索引的设计结构,导致了,非聚簇索引在查询的时候要进行两次索引检索,这样设计的好处,可以保证了一旦发生数据迁移的时候,只需要更新主键索引即可,非聚簇索引并不用动,而且也规避了像MyISAM的索引那样存储物理地址,在数据迁移的时候的需要重新维护所有索引的问题。
总结
这次把MySQL的索引的数据结构,以及文件存储结构,总结清楚了,后面在实际的工作过程中,设计索引的时候能够考虑的更全了,通过了解了索引的数据结构,也能让自己在实际写SQL的时候,能考虑到哪些情况走索引哪些不走索引了。
- MySQL使用B+Tree作为索引的数据结构,因为B+Tree的深度低,节点保存的关键字多,磁盘IO次数少,从而保证了查询效率更高。
- B+Tree能够保证MySQL无论是主键索引还是非主键索引的查询效果都是稳定的,每次都要查询到叶子节点才能返回数据,B+Tree的叶子节点的深度是一样的,而且为了更好的支持自增主键,B+Tree的查询节点范围是左闭合右开放。
- MySQL的MyISAM存储引擎,表数据和索引数据是分别放到两个文件中进行存储的,由于它本身的索引的B+Tree的叶子节点指向的表数据所在的磁盘地址,而且索引没有主键和非主键之分,所以分开存储,能够更好的统一管理索引;
- MySQL的InnoDB存储引擎,表数据和索引数据是存储在一个文件中的,因为InnoDB的聚簇索引的叶子节点指向的具体的数据行,而且为了保证查询效果的稳定,InnoDB表中必须要有一个聚簇索引,二级索引在进行索引检索时,会先通过二级索引检索到数据的主键值,再根据主键去聚簇索引中检索到具体的数据。
相关免费学习推荐:mysql视频教程
Atas ialah kandungan terperinci InnoDB的数据存储文件和MyISAM的不同. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1386
1386
 52
52

 Terangkan keupayaan carian teks penuh InnoDB.
Apr 02, 2025 pm 06:09 PM
Terangkan keupayaan carian teks penuh InnoDB.
Apr 02, 2025 pm 06:09 PM
Keupayaan carian teks penuh InnoDB sangat kuat, yang dapat meningkatkan kecekapan pertanyaan pangkalan data dan keupayaan untuk memproses sejumlah besar data teks. 1) InnoDB melaksanakan carian teks penuh melalui pengindeksan terbalik, menyokong pertanyaan carian asas dan maju. 2) Gunakan perlawanan dan terhadap kata kunci untuk mencari, menyokong mod boolean dan carian frasa. 3) Kaedah pengoptimuman termasuk menggunakan teknologi segmentasi perkataan, membina semula indeks dan menyesuaikan saiz cache untuk meningkatkan prestasi dan ketepatan.
 Bagaimana anda mengubah jadual di MySQL menggunakan pernyataan Alter Table?
Mar 19, 2025 pm 03:51 PM
Bagaimana anda mengubah jadual di MySQL menggunakan pernyataan Alter Table?
Mar 19, 2025 pm 03:51 PM
Artikel ini membincangkan menggunakan pernyataan jadual Alter MySQL untuk mengubah suai jadual, termasuk menambah/menjatuhkan lajur, menamakan semula jadual/lajur, dan menukar jenis data lajur.
 Bilakah imbasan jadual penuh lebih cepat daripada menggunakan indeks di MySQL?
Apr 09, 2025 am 12:05 AM
Bilakah imbasan jadual penuh lebih cepat daripada menggunakan indeks di MySQL?
Apr 09, 2025 am 12:05 AM
Pengimbasan jadual penuh mungkin lebih cepat dalam MySQL daripada menggunakan indeks. Kes -kes tertentu termasuk: 1) jumlah data adalah kecil; 2) apabila pertanyaan mengembalikan sejumlah besar data; 3) Apabila lajur indeks tidak selektif; 4) Apabila pertanyaan kompleks. Dengan menganalisis rancangan pertanyaan, mengoptimumkan indeks, mengelakkan lebih banyak indeks dan tetap mengekalkan jadual, anda boleh membuat pilihan terbaik dalam aplikasi praktikal.
 Bolehkah saya memasang mysql pada windows 7
Apr 08, 2025 pm 03:21 PM
Bolehkah saya memasang mysql pada windows 7
Apr 08, 2025 pm 03:21 PM
Ya, MySQL boleh dipasang pada Windows 7, dan walaupun Microsoft telah berhenti menyokong Windows 7, MySQL masih serasi dengannya. Walau bagaimanapun, perkara berikut harus diperhatikan semasa proses pemasangan: Muat turun pemasang MySQL untuk Windows. Pilih versi MySQL yang sesuai (komuniti atau perusahaan). Pilih direktori pemasangan yang sesuai dan set aksara semasa proses pemasangan. Tetapkan kata laluan pengguna root dan simpan dengan betul. Sambung ke pangkalan data untuk ujian. Perhatikan isu keserasian dan keselamatan pada Windows 7, dan disyorkan untuk menaik taraf ke sistem operasi yang disokong.
 Perbezaan antara indeks kluster dan indeks bukan clustered (indeks sekunder) di InnoDB.
Apr 02, 2025 pm 06:25 PM
Perbezaan antara indeks kluster dan indeks bukan clustered (indeks sekunder) di InnoDB.
Apr 02, 2025 pm 06:25 PM
Perbezaan antara indeks clustered dan indeks bukan cluster adalah: 1. Klustered Index menyimpan baris data dalam struktur indeks, yang sesuai untuk pertanyaan oleh kunci dan julat utama. 2. Indeks Indeks yang tidak berkumpul indeks nilai utama dan penunjuk kepada baris data, dan sesuai untuk pertanyaan lajur utama bukan utama.
 Apakah beberapa alat GUI MySQL yang popular (mis., MySQL Workbench, phpmyadmin)?
Mar 21, 2025 pm 06:28 PM
Apakah beberapa alat GUI MySQL yang popular (mis., MySQL Workbench, phpmyadmin)?
Mar 21, 2025 pm 06:28 PM
Artikel membincangkan alat MySQL GUI yang popular seperti MySQL Workbench dan PHPMyAdmin, membandingkan ciri dan kesesuaian mereka untuk pemula dan pengguna maju. [159 aksara]
 Bagaimana anda mengendalikan dataset besar di MySQL?
Mar 21, 2025 pm 12:15 PM
Bagaimana anda mengendalikan dataset besar di MySQL?
Mar 21, 2025 pm 12:15 PM
Artikel membincangkan strategi untuk mengendalikan dataset besar di MySQL, termasuk pembahagian, sharding, pengindeksan, dan pengoptimuman pertanyaan.
 Bagaimana anda menjatuhkan jadual di MySQL menggunakan pernyataan jadual drop?
Mar 19, 2025 pm 03:52 PM
Bagaimana anda menjatuhkan jadual di MySQL menggunakan pernyataan jadual drop?
Mar 19, 2025 pm 03:52 PM
Artikel ini membincangkan jadual menjatuhkan di MySQL menggunakan pernyataan Jadual Drop, menekankan langkah berjaga -jaga dan risiko. Ia menyoroti bahawa tindakan itu tidak dapat dipulihkan tanpa sandaran, memperincikan kaedah pemulihan dan bahaya persekitaran pengeluaran yang berpotensi.
