

python学习requests爬取网页图片
Feb 18, 2021 am 09:37 AM
免费学习推荐:python视频教程
前言
最近想做一个练练的小游戏给家里的小朋友玩儿,但是苦于选取素材,然后在一个巨佬的博客里找了灵感,就借用一下粉丝的头像试试爬取网页里的图片吧!(感谢各位啦!)
完成总目标:
爬取粉丝头像作为素材,完成一个连连看的小游戏
故本文分为两部分内容:
1、爬取素材部分;
2、利用素材完成连连看小游戏部分(链接)
实现目标:
通过爬虫实现对粉丝头像的爬取并顺序排列存储,作为游戏设计的素材,其中爬取的头像一部分是使用了CSDN的默认头像,存在重复情况,所以还需要去重以得到完整且不重复的图像集
一、准备
1、python环境
2、涉及到的python库需要 pip install 包名 安装
二、代码编写
1.爬取内容
(1)所需要的库
import requestsimport json
(2)得到请求地址
url = 'https://blog.csdn.net//phoenix/web/v1/fans/list?page=1&pageSize=40&blogUsername=weixin_45386875' #关注我的部分请求地址#url = 'https://blog.csdn.net//phoenix/web/v1/follow/list?page=1&pageSize=40&blogUsername=weixin_45386875' #我关注的部分请求地址
请求地址获取方法:
右击所要爬取部分页面,点击 审查元素,找到图中文件
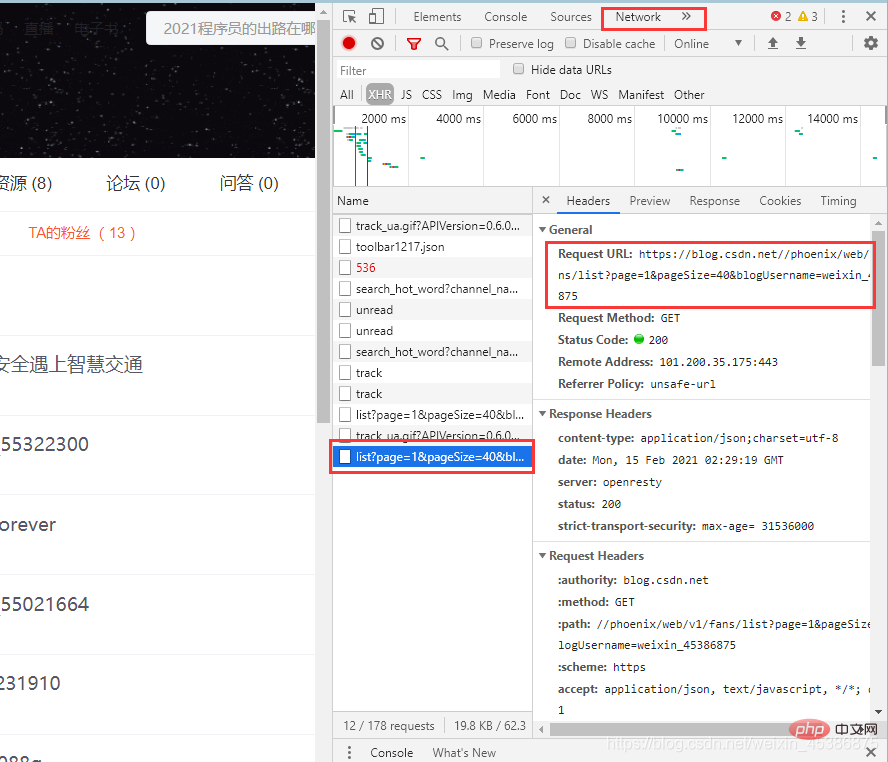
注: 页面选到“TA的粉丝(13)”部分才能出现,如果点击Network什么也没有,则需要刷新页面就会出现页面内容了)
(3)带上请求头发送请求,做一些简单伪装
header = {
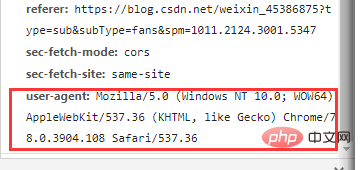
'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36',
'Cookie' : 'uuid_tt_dd=10_30826311340-1612520858912-361156; Hm_ct_6bcd52f51e9b3dce32bec4a3997715ac=6525*1*10_30826311340-1612520858912-361156!5744*1*weixin_45386875!1788*1*PC_VC; UN=weixin_45386875; p_uid=U010000; ssxmod_itna=Qui=DKiI3hkbG=DXDnD+r8h9eD53ecxPPit5bP1ODlOaYxA5D8D6DQeGTbcW1AoWGATqFYKmEWiH5/gbO4FpjQGcxLbbYx0aDbqGkqnU40rDzuQGuD0KGRDD4GEDCHHDIxGUBuDeKDR8qDg7gQcCM=DbSdDKqDHR+4FbG4oD8PdS0p=C7Gt3AuQ3DmtSije3r424rQ+iPqWzPDA3DK6jiD==; ssxmod_itna2=Qui=DKiI3hkbG=DXDnD+r8h9eD53ecxPPit5bP1D66Ii40vah303pFcXW0D6QALW==0tWLGtzKPUA76xoU10vpqD6AoOqs1R=Db=3olozYp0wVxUS0r/GeZCqzVezFQc8dZon7efYcr=1nhNr6nWKcTqqaDQYcwYSA+hNaqem=WWuDuDQ/+1PGEsN=atvS7WDp07vFuFDherg0AP0KFw0ea6kcTtK2rh/fy=/De0n1FNk+ONYxCXr=QrdTj6gxCuNNWXvp1IDdl2Ckjc=N/cqV6SmHZIZIuOEqml=dHMroMFDvdMVr8afnyQ+sbGPCbt3xdD07tAdRD7uDQ0gT=Bh7OYblbtYQFDDLxD2tGDD===; UserName=weixin_45386875; UserInfo=9863b829527c49a3ba1622396deaa7d9; UserToken=9863b829527c49a3ba1622396deaa7d9; UserNick=ryc875327878; AU=01F; BT=1612846374580; Hm_up_6bcd52f51e9b3dce32bec4a3997715ac=%7B%22uid_%22%3A%7B%22value%22%3A%22weixin_45386875%22%2C%22scope%22%3A1%7D%2C%22islogin%22%3A%7B%22value%22%3A%221%22%2C%22scope%22%3A1%7D%2C%22isonline%22%3A%7B%22value%22%3A%221%22%2C%22scope%22%3A1%7D%2C%22isvip%22%3A%7B%22value%22%3A%220%22%2C%22scope%22%3A1%7D%7D; __gads=ID=94978f740e79c9e5-22c918ed05c600ea:T=1613266189:RT=1613266189:S=ALNI_Mbwb8ad5kdYjogF7yImerVAzKaJuQ; dc_session_id=10_1613272889543.735028; announcement-new=%7B%22isLogin%22%3Atrue%2C%22announcementUrl%22%3A%22https%3A%2F%2Fblog.csdn.net%2Fblogdevteam%2Farticle%2Fdetails%2F112280974%3Futm_source%3Dgonggao_0107%22%2C%22announcementCount%22%3A0%2C%22announcementExpire%22%3A3600000%7D; dc_sid=3784575ebe1e9d08a29b0e3fc3621328; c_first_ref=default; c_first_page=https%3A//www.csdn.net/; c_segment=4; Hm_lvt_6bcd52f51e9b3dce32bec4a3997715ac=1613222907,1613266055,1613268241,1613273899; TY_SESSION_ID=82f0aa61-9b28-49b2-a854-b18414426735; c_pref=; c_ref=https%3A//www.csdn.net/; c_page_id=default; dc_tos=qoi2fq; log_Id_pv=925; Hm_lpvt_6bcd52f51e9b3dce32bec4a3997715ac=1613274327; log_Id_view=905; log_Id_click=658'
}获取请求头的方法: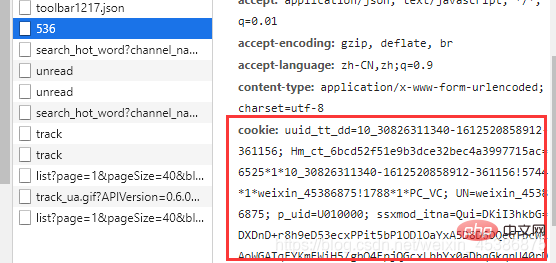
(4)向网页发送请求
try:
data = requests.get(url,headers = header).text
data_dist = json.loads(data)
except:
print('爬取失败')
exit ()2.保存所需图片并去重
定义一些函数备用
#保存文件def save_imag(file_name,img_url): request.urlretrieve(url=img_url,filename='D:\\ryc\python_learning\\10_linkup\\fan_avatar\\'+file_name)
#删除一个文件夹下的所有所有文件def del_file(path):
ls = os.listdir(path)
for i in ls:
c_path = os.path.join(path, i)
if os.path.isdir(c_path):#如果是文件夹那么递归调用一下
del_file(c_path)
else: #如果是一个文件那么直接删除
os.remove(c_path)
print ('文件已经清空完成')#图像去重def compare_images(pic1,pic2):
image1 = Image.open(pic1)
image2 = Image.open(pic2)
histogram1 = image1.histogram()
histogram2 = image2.histogram()
differ = math.sqrt(reduce(operator.add, list(map(lambda a,b: (a-b)**2,histogram1, histogram2)))/len(histogram1))
print('differ:',differ)
if differ == 0:
return 'same'
else:
return 'diff'#删除指定位置的图像def del_avatar(path):
if os.path.exists(path): # 如果文件存在
os.remove(path)
else:
print('no such file:%s'%(path)) # 则返回文件不存在#先清空一下文件夹
del_file('D:\\ryc\python_learning\\10_linkup\\fan_avatar')
index = 0
# i 是爬取列表的索引号; index 是保存的图片的索引号
for i in range(0,len(fan_list)):
fan_username = fan_list[i]['nickname']
#print('fans_user%s:'%(i+1),fan_username)
fan_avatar_url = fan_list[i]['userAvatar']
#print('fans_avatar_url%s:'%(i+1),fan_avatar_url)
save_imag('fans_avatar%s.jpg'%(index+1),fan_avatar_url)
#print('----------------save_image--fans_avatar%s.jpg'%(index+1))
#图片去重
for j in range(0,index):
if index != j :
comp_res = compare_images('./fan_avatar/fans_avatar%s.jpg'%(index+1),'./fan_avatar/fans_avatar%s.jpg'%(j+1))
print('--------compare_images:--------'+'./fan_avatar/fans_avatar%s.jpg'%(index+1) + '------with---' + './fan_avatar/fans_avatar%s.jpg'%(j+1))
print('comp_res:',comp_res)
if comp_res == 'same':
del_avatar('D:\\ryc\python_learning\\10_linkup\\fan_avatar\\fans_avatar%s.jpg'%(index+1))
print('D:\\ryc\python_learning\\10_linkup\\fan_avatar\\fans_avatar%s.jpg'%(index+1))
index = index - 1
break
index = index + 13、调用
if __name__ == "__main__": spider_fanavatar()
三、完整代码
# 爬取网页图片import requestsfrom urllib import requestimport jsonfrom PIL import Imageimport osimport mathimport operatorfrom functools import reduce#保存文件def save_imag(file_name,img_url):
request.urlretrieve(url=img_url,filename='D:\\ryc\python_learning\\10_linkup\\fan_avatar\\'+file_name)#爬取粉丝的头像def spider_fanavatar():
url = 'https://blog.csdn.net//phoenix/web/v1/fans/list?page=1&pageSize=40&blogUsername=weixin_45386875' #关注我的部分请求地址
#url = 'https://blog.csdn.net//phoenix/web/v1/follow/list?page=1&pageSize=40&blogUsername=weixin_45386875' #我关注的部分请求地址
header = {
'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36',
'Cookie' : 'uuid_tt_dd=10_30826311340-1612520858912-361156; Hm_ct_6bcd52f51e9b3dce32bec4a3997715ac=6525*1*10_30826311340-1612520858912-361156!5744*1*weixin_45386875!1788*1*PC_VC; UN=weixin_45386875; p_uid=U010000; ssxmod_itna=Qui=DKiI3hkbG=DXDnD+r8h9eD53ecxPPit5bP1ODlOaYxA5D8D6DQeGTbcW1AoWGATqFYKmEWiH5/gbO4FpjQGcxLbbYx0aDbqGkqnU40rDzuQGuD0KGRDD4GEDCHHDIxGUBuDeKDR8qDg7gQcCM=DbSdDKqDHR+4FbG4oD8PdS0p=C7Gt3AuQ3DmtSije3r424rQ+iPqWzPDA3DK6jiD==; ssxmod_itna2=Qui=DKiI3hkbG=DXDnD+r8h9eD53ecxPPit5bP1D66Ii40vah303pFcXW0D6QALW==0tWLGtzKPUA76xoU10vpqD6AoOqs1R=Db=3olozYp0wVxUS0r/GeZCqzVezFQc8dZon7efYcr=1nhNr6nWKcTqqaDQYcwYSA+hNaqem=WWuDuDQ/+1PGEsN=atvS7WDp07vFuFDherg0AP0KFw0ea6kcTtK2rh/fy=/De0n1FNk+ONYxCXr=QrdTj6gxCuNNWXvp1IDdl2Ckjc=N/cqV6SmHZIZIuOEqml=dHMroMFDvdMVr8afnyQ+sbGPCbt3xdD07tAdRD7uDQ0gT=Bh7OYblbtYQFDDLxD2tGDD===; UserName=weixin_45386875; UserInfo=9863b829527c49a3ba1622396deaa7d9; UserToken=9863b829527c49a3ba1622396deaa7d9; UserNick=ryc875327878; AU=01F; BT=1612846374580; Hm_up_6bcd52f51e9b3dce32bec4a3997715ac=%7B%22uid_%22%3A%7B%22value%22%3A%22weixin_45386875%22%2C%22scope%22%3A1%7D%2C%22islogin%22%3A%7B%22value%22%3A%221%22%2C%22scope%22%3A1%7D%2C%22isonline%22%3A%7B%22value%22%3A%221%22%2C%22scope%22%3A1%7D%2C%22isvip%22%3A%7B%22value%22%3A%220%22%2C%22scope%22%3A1%7D%7D; __gads=ID=94978f740e79c9e5-22c918ed05c600ea:T=1613266189:RT=1613266189:S=ALNI_Mbwb8ad5kdYjogF7yImerVAzKaJuQ; dc_session_id=10_1613272889543.735028; announcement-new=%7B%22isLogin%22%3Atrue%2C%22announcementUrl%22%3A%22https%3A%2F%2Fblog.csdn.net%2Fblogdevteam%2Farticle%2Fdetails%2F112280974%3Futm_source%3Dgonggao_0107%22%2C%22announcementCount%22%3A0%2C%22announcementExpire%22%3A3600000%7D; dc_sid=3784575ebe1e9d08a29b0e3fc3621328; c_first_ref=default; c_first_page=https%3A//www.csdn.net/; c_segment=4; Hm_lvt_6bcd52f51e9b3dce32bec4a3997715ac=1613222907,1613266055,1613268241,1613273899; TY_SESSION_ID=82f0aa61-9b28-49b2-a854-b18414426735; c_pref=; c_ref=https%3A//www.csdn.net/; c_page_id=default; dc_tos=qoi2fq; log_Id_pv=925; Hm_lpvt_6bcd52f51e9b3dce32bec4a3997715ac=1613274327; log_Id_view=905; log_Id_click=658'
}
try:
data = requests.get(url,headers = header).text #得到返回的字符串
data_dist = json.loads(data) #将字符串转为字典格式
except:
print('爬取失败')
exit ()
fan_list = data_dist['data']['list'] #提取所需内容
#先清空一下文件夹
del_file('D:\\ryc\python_learning\\10_linkup\\fan_avatar')
index = 0
# i 是爬取列表的索引号; index 是保存的图片的索引号
for i in range(0,len(fan_list)):
fan_username = fan_list[i]['nickname']
#print('fans_user%s:'%(i+1),fan_username)
fan_avatar_url = fan_list[i]['userAvatar']
#print('fans_avatar_url%s:'%(i+1),fan_avatar_url)
save_imag('fans_avatar%s.jpg'%(index+1),fan_avatar_url)
#print('----------------save_image--fans_avatar%s.jpg'%(index+1))
#图片去重
for j in range(0,index):
if index != j :
comp_res = compare_images('./fan_avatar/fans_avatar%s.jpg'%(index+1),'./fan_avatar/fans_avatar%s.jpg'%(j+1))
print('--------compare_images:--------'+'./fan_avatar/fans_avatar%s.jpg'%(index+1) + '------with---' + './fan_avatar/fans_avatar%s.jpg'%(j+1))
print('comp_res:',comp_res)
if comp_res == 'same':
del_avatar('D:\\ryc\python_learning\\10_linkup\\fan_avatar\\fans_avatar%s.jpg'%(index+1))
print('D:\\ryc\python_learning\\10_linkup\\fan_avatar\\fans_avatar%s.jpg'%(index+1))
index = index - 1
break
index = index + 1
#图像去重def compare_images(pic1,pic2):
image1 = Image.open(pic1)
image2 = Image.open(pic2)
histogram1 = image1.histogram()
histogram2 = image2.histogram()
differ = math.sqrt(reduce(operator.add, list(map(lambda a,b: (a-b)**2,histogram1, histogram2)))/len(histogram1))
print('differ:',differ)
if differ == 0:
return 'same'
else:
return 'diff'
#删除指定位置的图像def del_avatar(path):
if os.path.exists(path): # 如果文件存在
os.remove(path)
else:
print('no such file:%s'%(path)) # 则返回文件不存在#删除一个文件夹下的所有所有文件def del_file(path):
ls = os.listdir(path)
for i in ls:
c_path = os.path.join(path, i)
if os.path.isdir(c_path):#如果是文件夹那么递归调用一下
del_file(c_path)
else: #如果是一个文件那么直接删除
os.remove(c_path)
print ('文件已经清空完成')if __name__ == "__main__":
spider_fanavatar()最后
第一部分内容就到这里,第二部分内容将在下一篇文章完成,感兴趣的小伙伴可以关注我,然后去看下一片文章哦!
都读到这里了,各位亲爱的读者留下你们宝贵的赞和评论吧,这将是我继续前进的坚定动力!!!
大量免费学习推荐,敬请访问python教程(视频)
Atas ialah kandungan terperinci python学习requests爬取网页图片. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Artikel Panas

Alat panas Tag

Artikel Panas

Tag artikel panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas




 Apakah kelebihan dan kekurangan templat?
May 08, 2024 pm 03:51 PM
Apakah kelebihan dan kekurangan templat?
May 08, 2024 pm 03:51 PM
Apakah kelebihan dan kekurangan templat?
 Google AI mengumumkan Gemini 1.5 Pro dan Gemma 2 untuk pembangun
Jul 01, 2024 am 07:22 AM
Google AI mengumumkan Gemini 1.5 Pro dan Gemma 2 untuk pembangun
Jul 01, 2024 am 07:22 AM
Google AI mengumumkan Gemini 1.5 Pro dan Gemma 2 untuk pembangun
 Dengan hanya $250, pengarah teknikal Hugging Face mengajar anda cara memperhalusi Llama 3
May 06, 2024 pm 03:52 PM
Dengan hanya $250, pengarah teknikal Hugging Face mengajar anda cara memperhalusi Llama 3
May 06, 2024 pm 03:52 PM
Dengan hanya $250, pengarah teknikal Hugging Face mengajar anda cara memperhalusi Llama 3
 Kongsi beberapa rangka kerja projek berkaitan AI dan LLM sumber terbuka .NET
May 06, 2024 pm 04:43 PM
Kongsi beberapa rangka kerja projek berkaitan AI dan LLM sumber terbuka .NET
May 06, 2024 pm 04:43 PM
Kongsi beberapa rangka kerja projek berkaitan AI dan LLM sumber terbuka .NET
 Panduan lengkap untuk penyahpepijatan dan analisis fungsi golang
May 06, 2024 pm 02:00 PM
Panduan lengkap untuk penyahpepijatan dan analisis fungsi golang
May 06, 2024 pm 02:00 PM
Panduan lengkap untuk penyahpepijatan dan analisis fungsi golang
 Bagaimana anda bertanya kepadanya Deepseek
Feb 19, 2025 pm 04:42 PM
Bagaimana anda bertanya kepadanya Deepseek
Feb 19, 2025 pm 04:42 PM
Bagaimana anda bertanya kepadanya Deepseek
 Bagaimana untuk menyimpan fungsi menilai
May 07, 2024 am 01:09 AM
Bagaimana untuk menyimpan fungsi menilai
May 07, 2024 am 01:09 AM
Bagaimana untuk menyimpan fungsi menilai
