

详解Python之urllib爬虫、request模块和parse模块


文章目录
- urllib
- request模块
- 访问URL
- Request类
- 其他类
- parse模块
- 解析URL
- 转义URL
- robots.txt文件
(免费学习推荐:python视频教程)
urllib
urllib是Python中用来处理URL的工具包,源码位于/Lib/下。它包含了几个模块:用于打开及读写的urls的request模块、由request模块引起异常的error模块、用于解析urls的parse模块、用于响应处理的response模块、分析robots.txt文件的robotparser模块。
注意版本差异。urllib有3个版本:Python2.X包含urllib、urllib2模块,Python3.X把urllib、urllib2以及urlparse合成到urllib包中,而urllib3是新增的第三方工具包。若遇到"No module named urllib2"等问题几乎都是Python版本不同导致的。
urllib3是一个功能强大、条例清晰、用于HTTP客户端的Python库。它提供了许多Python标准库里所没有的特性:压缩编码、连接池、线程安全、SSL/TLS验证、HTTP和SCOCKS代理等。可以通过pip进行安装:pip install urllib3
也可以通过GitHub下载最新代码:
git clone git://github.com/shazow/urllib3.git python setup.py install
urllib3参考文档:https://urllib3.readthedocs.io/en/latest/
request模块
urllib.request模块定义了身份认证、重定向、cookies等应用中打开url的函数和类。
再简单介绍下request包,该包用于高级的非底层的HTTP客户端接口,容错能力比request模块强大。request使用的是urllib3,它继承了urllib2的特性,支持HTTP连接保持和连接池,支持使用cookie保持会话、文件上传、自动解压缩、Unicode响应、HTTP(S)代理等。更多具体可参考文档http://requests.readthedocs.io。
下面将介绍urllib.request模块常用函数和类。
访问URL
一、urlopen()
urllib.request.urlopen(url,data=None,[timeout,]*,cafile=None,capath=None,cadefault=false,context=None)
该函数用于抓取URL数据,十分重要。带有如上所示的参数,除了URL参数外(字符串或Request对象)其余参数都有默认值。
①URL参数
from urllib import requestwith request.urlopen("http://www.baidu.com") as f:
print(f.status)
print(f.getheaders())#运行结果如下200[('Bdpagetype', '1'), ('Bdqid', '0x8583c98f0000787e'), ('Cache-Control', 'private'), ('Content-Type', 'text/html;charset=utf-8'), ('Date', 'Fri, 19 Mar 2021 08:26:03 GMT'), ('Expires', 'Fri, 19 Mar 2021 08:25:27 GMT'), ('P3p', 'CP=" OTI DSP COR IVA OUR IND COM "'), ('P3p', 'CP=" OTI DSP COR IVA OUR IND COM "'), ('Server', 'BWS/1.1'), ('Set-Cookie', 'BAIDUID=B050D0981EE3A706D726852655C9FA21:FG=1; expires=Thu, 31-Dec-37 23:55:55 GMT; max-age=2147483647; path=/; domain=.baidu.com'), ('Set-Cookie', 'BIDUPSID=B050D0981EE3A706D726852655C9FA21; expires=Thu, 31-Dec-37 23:55:55 GMT; max-age=2147483647; path=/; domain=.baidu.com'), ('Set-Cookie', 'PSTM=1616142363; expires=Thu, 31-Dec-37 23:55:55 GMT; max-age=2147483647; path=/; domain=.baidu.com'), ('Set-Cookie', 'BAIDUID=B050D0981EE3A706FA20DF440C89F27F:FG=1; max-age=31536000; expires=Sat, 19-Mar-22 08:26:03 GMT; domain=.baidu.com; path=/; version=1; comment=bd'), ('Set-Cookie', 'BDSVRTM=0; path=/'), ('Set-Cookie', 'BD_HOME=1; path=/'), ('Set-Cookie', 'H_PS_PSSID=33272_33710_33690_33594_33600_33624_33714_33265; path=/; domain=.baidu.com'), ('Traceid', '161614236308368819309620754845011048574'), ('Vary', 'Accept-Encoding'), ('Vary', 'Accept-Encoding'), ('X-Ua-Compatible', 'IE=Edge,chrome=1'), ('Connection', 'close'), ('Transfer-Encoding', 'chunked')]②data参数
如果向服务器发送数据,那么data参数必须是一个有数据的byes对象,否则为None。在Python3.2之后可以是一个iterable对象。若是,则headers中必须带有Content-Length参数。HTTP请求使用POST方法时,data必须有数据;使用GET方法时,data写None即可。
from urllib import parsefrom urllib import request
data = bytes(parse.urlencode({"pro":"value"}),encoding="utf8")response = request.urlopen("http://httpbin.org/post",data=data)print(response.read())#运行结果如下b'{\n "args": {}, \n "data": "", \n "files": {}, \n "form": {\n "pro": "value"\n }, \n "headers": {\n "Accept-Encoding": "identity", \n "Content-Length": "9", \n "Content-Type": "application/x-www-form-urlencoded", \n "Host": "httpbin.org", \n "User-Agent": "Python-urllib/3.9", \n "X-Amzn-Trace-Id": "Root=1-60545f5e-7428b29435ce744004d98afa"\n }, \n "json": null, \n "origin": "112.48.80.243", \n "url": "http://httpbin.org/post"\n}\n'对数据进行POST请求,需要转码bytes类型或者iterable类型。这里通过bytes()进行字节转换,考虑到第一个参数为字符串,所以需要利用parse模块(下面会讲)的urlencode()方法对上传的数据进行字符串转换,同时指定编码格式为utf8。测试网址httpbin.org可以提供HTTP测试,从返回的内容可以看出提交以表单form作为属性、以字典作为属性值。
③timeout参数
该参数是可选的,以秒为单位指定一个超时时间,若超过该时间则任何操作都会被阻止,如果没有指定,那么默认会取sock.GLOBAL_DEFAULT_TIMEOUT对应的值。该参数仅对http、https、ftp连接有效。
超时后会抛出urllib.error.URLError:
from urllib import request
response = request.urlopen("http://httpbin.org/get",timeout=1)print(response.read())#运行结果如下b'{\n "args": {}, \n "headers": {\n "Accept-Encoding": "identity", \n "Host": "httpbin.org", \n "User-Agent": "Python-urllib/3.9", \n "X-Amzn-Trace-Id": "Root=1-605469dd-76a6d963171127c213d9a9ab"\n }, \n "origin": "112.48.80.243", \n "url": "http://httpbin.org/get"\n}\n'④返回对象的常用方法和属性
除了前三个urlopen()常用参数外,该函数返回用作context manager(上下文管理器)的类文件对象,并包含如下方法:
- geturl():返回请求的URL,通常重定向后的URL照样能获取到
- info():返回httplib.HTTPMessage对象,表示远程服务器返回的头信息
- getcode():返回响应后的HTTP状态码
- status属性:返回响应后的HTTP状态码
- msg属性:请求结果
from urllib import request
response = request.urlopen("http://httpbin.org/get")print(response.geturl())print("===========")print(response.info())print("===========")print(response.getcode())print("===========")print(response.status)print("===========")print(response.msg)运行结果: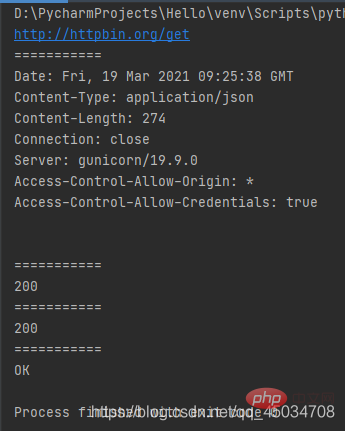
附:状态码对应状态
- 1xx(informational):请求已经收到,正在进行中。
- 2xx(successful):请求成功接收,解析,完成。
- 3xx(Redirection):需要重定向。
- 4xx(Client Error):客户端问题,请求存在语法错误,网址未找到。
- 5xx(Server Error):服务器问题。
二、build_opener()
urllib.request.build_opener([handler1 [handler2, ...]])
该函数不支持验证、cookie及其他HTTP高级功能。要支持这些功能必须使用build_opener()函数自定义OpenerDirector对象,称之为Opener。
build_opener()函数返回的是OpenerDirector实例,而且是按给定的顺序链接处理程序的。作为OpenerDirector实例,可以从OpenerDirector类的定义看出他具有addheaders、handlers、handle_open、add_handler()、open()、close()等属性或方法。open()方法与urlopen()函数的功能相同。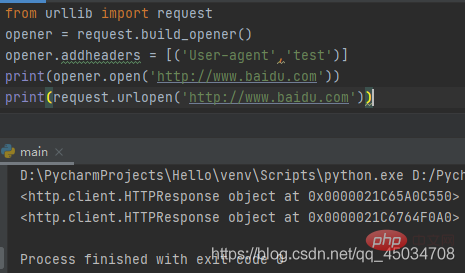
上述代码通过修改http报头进行HTTP高级功能操作,然后利用返回对象open()进行请求,返回结果与urlopen()一样,只是内存位置不同而已。
实际上urllib.request.urlopen()方法只是一个Opener,如果安装启动器没有使用urlopen启动,调用的就是OpenerDirector.open()方法。那么如何设置默认全局启动器呢?就涉及下面的install_opener函数。
三、install_opener()
urllib.request.install_opener(opener)
安装OpenerDirector实例作为默认全局启动器。
首先导入request模块,实例化一个HTTPBasicAuthHandler对象,然后通过利用add_password()添加用户名和密码来创建一个认证处理器,利用urllib.request.build_opener()方法来调用该处理器以构建Opener,并使其作为默认全局启动器,这样Opener在发生请求时具备了认证功能。通过Opener的open()方法打开链接完成认证。
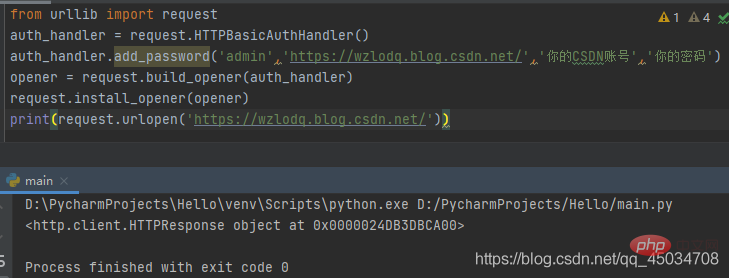
当然了,CSDN不需要账号密码也可以访问,读者还可以在其他网站上用自己的账号进行测试。
除了上述方法外,还有将路径转换为URL的pathname2url(path)、将URL转换为路径的url2pathname(path),以及返回方案至代理服务器URL映射字典的getproxies()等方法。
Request类
前面介绍的urlopen()方法可以满足一般基本URL请求,如果需要添加headers信息,就要考虑更为强大的Request类了。Request类是URL请求的抽象,包含了许多参数,并定义了一系列属性和方法。
一、定义
class urllib.request.Request(url,data=None,headers={},origin_req_host=None,unverifiable=False,method=None)- 参数url是有效网址的字符串,同
urlopen()方法中一样,data参数也是。 - headers是一个字典,可以通过
add_header()以键值进行调用。通常用于爬虫爬取数据时或者Web请求时更改User-Agent标头值参数来进行请求。 - origin_req_host是原始请求主机,比如请求的是针对HTML文档中的图像的,则该请求主机是包含图像页面所在的主机。
- Unverifiable指示请求是否是无法验证的。
- method指示使用的是HTTP请求方法。常用的有GET、POST、PUT、DELETE等,
代码示例:
from urllib import requestfrom urllib import parse
data = parse.urlencode({"name":"baidu"}).encode('utf-8')headers = {'User-Agent':'wzlodq'}req = request.Request(url="http://httpbin.org/post",data=data,headers=headers,method="POST")response = request.urlopen(req)print(response.read())#运行结果如下b'{\n "args": {}, \n "data": "", \n "files": {}, \n "form": {\n "name": "baidu"\n }, \n "headers": {\n "Accept-Encoding": "identity", \n "Content-Length": "10", \n "Content-Type": "application/x-www-form-urlencoded", \n "Host": "httpbin.org", \n "User-Agent": "wzlodq", \n "X-Amzn-Trace-Id": "Root=1-605491a4-1fcf3df01a8b3c3e22b5edce"\n }, \n "json": null, \n "origin": "112.48.80.34", \n "url": "http://httpbin.org/post"\n}\n'注意data参数和前面一样需是字节流类型的,不同的是调用Request类进行请求。
二、属性方法
①Request.full_url
full_url属性包含setter、getter和deleter。如果原始请求URL片段存在,那么得到的full_url将返回原始请求的URL片段,通过添加修饰器@property将原始URL传递给构造函数。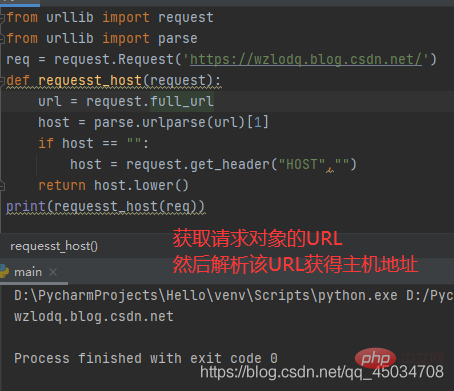
②Request.type:获取请求对象的协议类型。
③Request.host:获取URL主机,可能含有端口的主机。
④Request.origin_req_host:发出请求的原始主机,没有端口。
⑤Request.get_method():返回显示HTTP请求方法的字符串。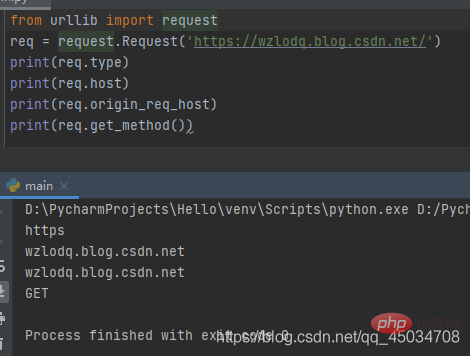
(插播反爬信息 )博主CSDN地址:https://wzlodq.blog.csdn.net/
⑥Request.add_header(key,val):向请求中添加标头。
from urllib import requestfrom urllib import parse
data = bytes(parse.urlencode({'name':'baidu'}),encoding='utf-8')req = request.Request('http://httpbin.org/post',data,method='POST')req.add_header('User-agent','test')response = request.urlopen(req)print(response.read().decode('utf-8'))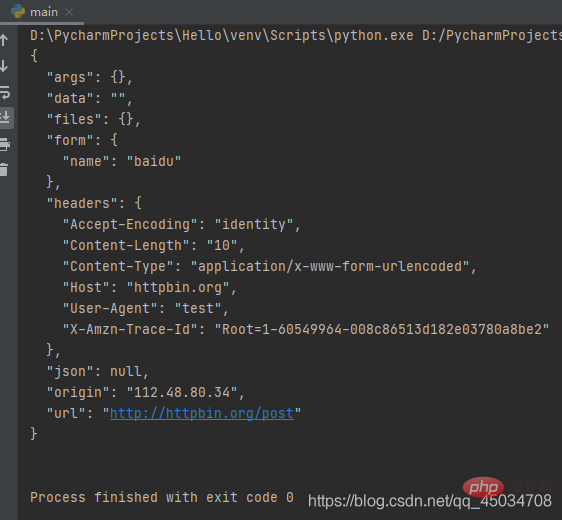
上述代码中,通过add_header()传入了User-Agent,在爬虫过程中,常常通过循环调用该方法来添加不同的User-Agent进行请求,避免服务器针对某一User-Agent的禁用。
其他类
BaseHandler为所有注册处理程序的基类,并且只处理注册的简单机制,从定义上看,BaseHandler提供了一个添加基类的add_parent()方法,后面介绍的类都是继承该类操作的。
- HTTPErrorProcessor:用于HTTP错误响应过程。
- HTTPDefaultErrorHandler:用于处理HTTP响应错误。
- ProxyHandler:用于设置代理。
- HTTPRedirectHandler:用于设置重定向。
- HTTPCookieProcessor:用于处理cookie。
- HEEPBasicAuthHandler:用于管理认证。
parse模块
parse模块用于分解URL字符串为各个组成部分,包括寻址方案、网络位置、路径等,也可将这些部分组成URL字符串,同时可以对“相对URL"进行转换等。
解析URL
一、urllib.parse.urlparse(urlstring,scheme=’’,allow_fragments=True)
解析URL为6个部分,即返回一个6元组(tuple子类的实例),tuple类具有下标所示的属性:
| 属性 | 说明 | 对应下标指数 | 不存在时的取值 |
|---|---|---|---|
| scheme | URL方案说明符 0 | scheme参数 | |
| netloc | 网络位置部分 | 1 | 空字符串 |
| path | 分层路径 | 2 | 空字符串 |
| params | 最后路径元素的参数 | 3 | 空字符串 |
| query | 查询组件 | 4 | 空字符串 |
| fragment | 片段标识符 | 5 | 空字符串 |
| username | 用户名 | None | |
| password | 密码 | None | |
| hostname | 主机名 | None | |
| port | 端口号 | None |
最后组成的URL结构为scheme://netloc/path;parameters?query#fragment
举个栗子:
from urllib.parse import *res = urlparse('https://wzlodq.blog.csdn.net/article/details/113597816')print(res)print(res.scheme)print(res.netloc)print(res.path)print(res.params)print(res.query)print(res.username)print(res.password)print(res.hostname)print(res.port)print(res.geturl())print(tuple(res))print(res[0])print(res[1])print(res[2])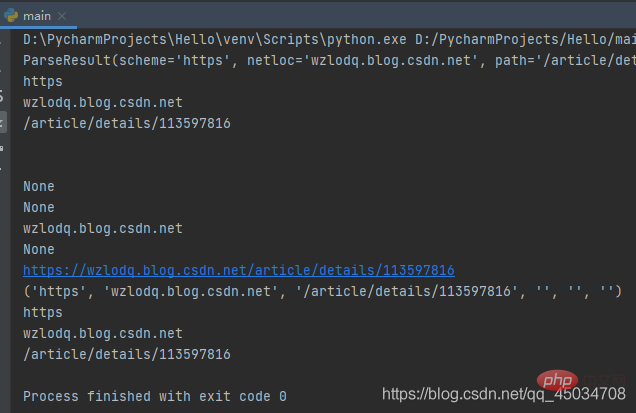
需要注意的是urlparse有时并不能很好地识别netloc,它会假定相对URL以路径分量开始,将其取值放在path中。
二、urllib.parse.urlunparse(parts)
是urlparse()的逆操作,即将urlparse()返回的原则构建一个URL。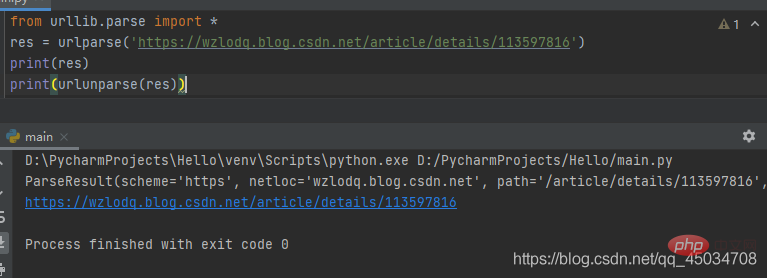
三、urllib.parse.urlsplit(urlstring,scheme=’’.allow_fragments=True)
类似urlparse(),但不会分离参数,即返回的元组对象没有params元素,是一个五元组,对应下标指数也发生了改变。
from urllib.parse import *sp = urlsplit('https://wzlodq.blog.csdn.net/article/details/113597816')print(sp)#运行结果如下SplitResult(scheme='https', netloc='wzlodq.blog.csdn.net', path='/article/details/113597816', query='', fragment='')四、urllib.parse.urlunsplit(parts)
类似urlunparse(),是urlsplit()的逆操作,不再赘述。
五、urllib.parse.urljoin(base,url,allow_fragments=True)
该函数主要组合基本网址(base)与另一个网址(url)以构建新的完整网址。
相对路径和绝对路径的url组合是不同的,而且相对路径是以最后部分路径进行替换处理的: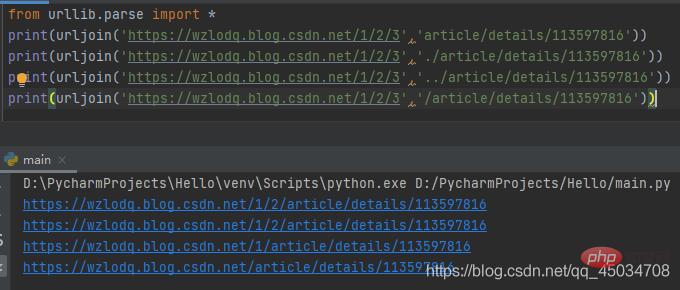
六、urllib.parse.urldefrag(url)
根据url进行分割,如果url包含片段标识符,就返回url对应片段标识符前的网址,fragment取片段标识符后的值。如果url没有片段标识符,那么fragment为空字符串。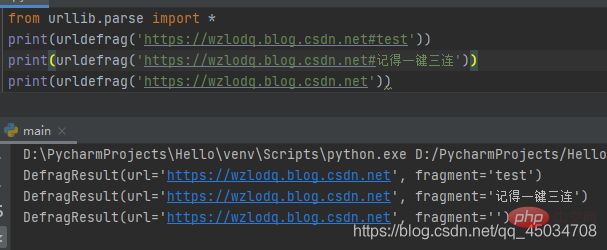
转义URL
URL转义可以避免某些字符引起歧义,通过引用特殊字符并适当编排非ASCII文本使其作为URL组件安全使用。同时也支持反转这些操作,以便从URL组件内容重新创建原始数据。
一、urllib.parse.quote(string,safe=’/’,encoding=None,errors=None)
使用%xx转义替换string中的特殊字符,其中字母、数字和字符’_.-‘不会进行转义。默认情况下,此函数用于转义URL的路径部分,可选的safe参数指定不应转义的其他ASCII字符——其默认值为’/’。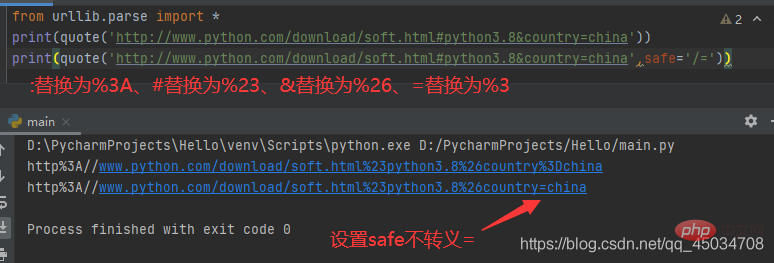
特别注意的是若string是bytes,encoding和errors就无法指定,否则报错TypeError。
二、urllib.parse.unquote(string,encoding=‘utf-8’,errors=‘replace’)
该函数时quote()的逆操作,即将%xx转义为等效的单字符。参数encoding和errors用来指定%xx编码序列解码为Unicode字符,同bytes.decode()方法。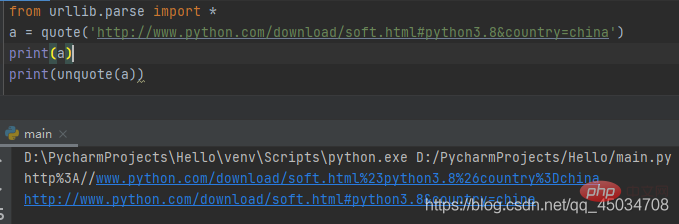
三、urllib.parse.quote_plus(string,safe=’’,encoding=None,errors=None)
该函数时quote()的增强版,与之不同的是用+替换空格,而且如果原始URL有字符,那么+将被转义。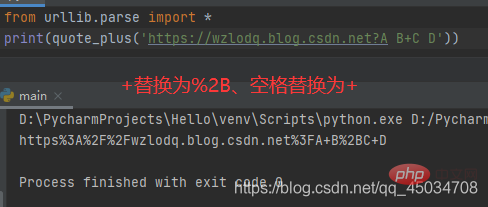
四、urllib.parse.unquote_plus(string,encoding=‘utf-8’,errors=‘replace’)
类似unquote(),不再赘述。
五、urllib.parse.urlencode(query,doseq=False,safe=’’,encoding=None,errors=None,quote_via=quote_plus)
该函数前面提到过,通常在使用HTTP进行POST请求传递的数据进行编码时使用。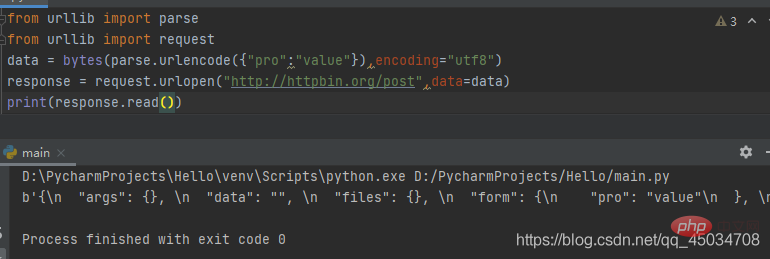
robots.txt文件
robotparser模块很简单,仅定义了3个类(RobotFileParser、RuleLine、Entry)。从__all__属性来看也就RobotFileParser一个类(用于处理有关特定用户代理是否可以发布robots.txt文件的网站上提前网址内容)。
robots文件类似一个协议文件,搜索引擎访问网站时查看的第一个文件,会告诉爬虫或者蜘蛛程序在服务器上可以查看什么文件。
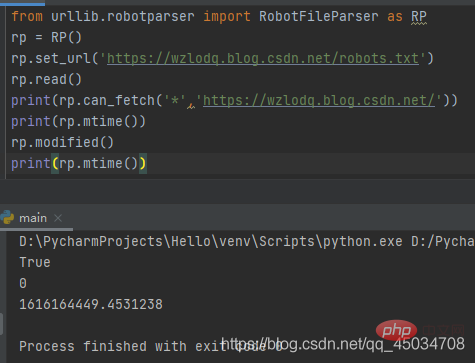
RobotFileParser类有一个url参数,常用以下方法:
- set_url():用来设置指向robots.txt文件的网址。
- read():读取robots.txt网址,并将其提供给解析器。
- parse():用来解析robots.txt文件。
- can_fetch():用来判断是否可提前url。
- mtime():返回上次抓取robots.txt文件的时间。
- modified():将上次抓取robots.txt文件的时间设置为当前时间。
大量免费学习推荐,敬请访问python教程(视频)
Atas ialah kandungan terperinci 详解Python之urllib爬虫、request模块和parse模块. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1376
1376
 52
52

 Cara Menggunakan MySQL Selepas Pemasangan
Apr 08, 2025 am 11:48 AM
Cara Menggunakan MySQL Selepas Pemasangan
Apr 08, 2025 am 11:48 AM
Artikel ini memperkenalkan operasi pangkalan data MySQL. Pertama, anda perlu memasang klien MySQL, seperti MySqlworkbench atau Command Line Client. 1. Gunakan perintah MySQL-Uroot-P untuk menyambung ke pelayan dan log masuk dengan kata laluan akaun root; 2. Gunakan CreateTatabase untuk membuat pangkalan data, dan gunakan Pilih pangkalan data; 3. Gunakan createtable untuk membuat jadual, menentukan medan dan jenis data; 4. Gunakan InsertInto untuk memasukkan data, data pertanyaan, kemas kini data dengan kemas kini, dan padam data dengan padam. Hanya dengan menguasai langkah -langkah ini, belajar menangani masalah biasa dan mengoptimumkan prestasi pangkalan data anda boleh menggunakan MySQL dengan cekap.
 Bagaimanakah Feathering PS mengawal kelembutan peralihan?
Apr 06, 2025 pm 07:33 PM
Bagaimanakah Feathering PS mengawal kelembutan peralihan?
Apr 06, 2025 pm 07:33 PM
Kunci kawalan bulu adalah memahami sifatnya secara beransur -ansur. PS sendiri tidak menyediakan pilihan untuk mengawal lengkung kecerunan secara langsung, tetapi anda boleh melaraskan radius dan kelembutan kecerunan dengan pelbagai bulu, topeng yang sepadan, dan pilihan halus untuk mencapai kesan peralihan semula jadi.
 Adakah Mysql perlu membayar
Apr 08, 2025 pm 05:36 PM
Adakah Mysql perlu membayar
Apr 08, 2025 pm 05:36 PM
MySQL mempunyai versi komuniti percuma dan versi perusahaan berbayar. Versi komuniti boleh digunakan dan diubahsuai secara percuma, tetapi sokongannya terhad dan sesuai untuk aplikasi dengan keperluan kestabilan yang rendah dan keupayaan teknikal yang kuat. Edisi Enterprise menyediakan sokongan komersil yang komprehensif untuk aplikasi yang memerlukan pangkalan data yang stabil, boleh dipercayai, berprestasi tinggi dan bersedia membayar sokongan. Faktor yang dipertimbangkan apabila memilih versi termasuk kritikal aplikasi, belanjawan, dan kemahiran teknikal. Tidak ada pilihan yang sempurna, hanya pilihan yang paling sesuai, dan anda perlu memilih dengan teliti mengikut keadaan tertentu.
 Bagaimana cara menyediakan bulu ps?
Apr 06, 2025 pm 07:36 PM
Bagaimana cara menyediakan bulu ps?
Apr 06, 2025 pm 07:36 PM
PS Feathering adalah kesan kabur tepi imej, yang dicapai dengan purata piksel berwajaran di kawasan tepi. Menetapkan jejari bulu dapat mengawal tahap kabur, dan semakin besar nilai, semakin kaburnya. Pelarasan fleksibel radius dapat mengoptimumkan kesan mengikut imej dan keperluan. Sebagai contoh, menggunakan jejari yang lebih kecil untuk mengekalkan butiran apabila memproses foto watak, dan menggunakan radius yang lebih besar untuk mewujudkan perasaan kabur ketika memproses karya seni. Walau bagaimanapun, perlu diperhatikan bahawa terlalu besar jejari boleh dengan mudah kehilangan butiran kelebihan, dan terlalu kecil kesannya tidak akan jelas. Kesan bulu dipengaruhi oleh resolusi imej dan perlu diselaraskan mengikut pemahaman imej dan kesan genggaman.
 Cara mengoptimumkan prestasi pangkalan data selepas pemasangan MySQL
Apr 08, 2025 am 11:36 AM
Cara mengoptimumkan prestasi pangkalan data selepas pemasangan MySQL
Apr 08, 2025 am 11:36 AM
Pengoptimuman prestasi MySQL perlu bermula dari tiga aspek: konfigurasi pemasangan, pengindeksan dan pengoptimuman pertanyaan, pemantauan dan penalaan. 1. Selepas pemasangan, anda perlu menyesuaikan fail my.cnf mengikut konfigurasi pelayan, seperti parameter innodb_buffer_pool_size, dan tutup query_cache_size; 2. Buat indeks yang sesuai untuk mengelakkan indeks yang berlebihan, dan mengoptimumkan pernyataan pertanyaan, seperti menggunakan perintah menjelaskan untuk menganalisis pelan pelaksanaan; 3. Gunakan alat pemantauan MySQL sendiri (ShowProcessList, ShowStatus) untuk memantau kesihatan pangkalan data, dan kerap membuat semula dan mengatur pangkalan data. Hanya dengan terus mengoptimumkan langkah -langkah ini, prestasi pangkalan data MySQL diperbaiki.
 Apakah kesan PS Feathering pada kualiti imej?
Apr 06, 2025 pm 07:21 PM
Apakah kesan PS Feathering pada kualiti imej?
Apr 06, 2025 pm 07:21 PM
PS Feathering boleh menyebabkan kehilangan butiran imej, ketepuan warna yang dikurangkan dan peningkatan bunyi. Untuk mengurangkan kesan, disarankan untuk menggunakan radius bulu yang lebih kecil, menyalin lapisan dan kemudian bulu, dan berhati -hati membandingkan kualiti imej sebelum dan selepas bulu. Di samping itu, bulu tidak sesuai untuk semua kes, dan kadang -kadang alat seperti topeng lebih sesuai untuk mengendalikan tepi imej.
 Bagaimana untuk mengoptimumkan prestasi MySQL untuk aplikasi beban tinggi?
Apr 08, 2025 pm 06:03 PM
Bagaimana untuk mengoptimumkan prestasi MySQL untuk aplikasi beban tinggi?
Apr 08, 2025 pm 06:03 PM
Panduan Pengoptimuman Prestasi Pangkalan Data MySQL Dalam aplikasi yang berintensifkan sumber, pangkalan data MySQL memainkan peranan penting dan bertanggungjawab untuk menguruskan urus niaga besar-besaran. Walau bagaimanapun, apabila skala aplikasi berkembang, kemunculan prestasi pangkalan data sering menjadi kekangan. Artikel ini akan meneroka satu siri strategi pengoptimuman prestasi MySQL yang berkesan untuk memastikan aplikasi anda tetap cekap dan responsif di bawah beban tinggi. Kami akan menggabungkan kes-kes sebenar untuk menerangkan teknologi utama yang mendalam seperti pengindeksan, pengoptimuman pertanyaan, reka bentuk pangkalan data dan caching. 1. Reka bentuk seni bina pangkalan data dan seni bina pangkalan data yang dioptimumkan adalah asas pengoptimuman prestasi MySQL. Berikut adalah beberapa prinsip teras: Memilih jenis data yang betul dan memilih jenis data terkecil yang memenuhi keperluan bukan sahaja dapat menjimatkan ruang penyimpanan, tetapi juga meningkatkan kelajuan pemprosesan data.
 Kaedah Navicat untuk melihat kata laluan pangkalan data MongoDB
Apr 08, 2025 pm 09:39 PM
Kaedah Navicat untuk melihat kata laluan pangkalan data MongoDB
Apr 08, 2025 pm 09:39 PM
Tidak mustahil untuk melihat kata laluan MongoDB secara langsung melalui Navicat kerana ia disimpan sebagai nilai hash. Cara mendapatkan kata laluan yang hilang: 1. Tetapkan semula kata laluan; 2. Periksa fail konfigurasi (mungkin mengandungi nilai hash); 3. Semak Kod (boleh kata laluan Hardcode).
