

机器翻译属于哪个领域的应用

机器翻译属于“自然语言处理”领域的应用。“自然语言处理”研究能实现人与计算机之间用自然语言进行有效通信的各种理论和方法,主要应用于机器翻译、舆情监测、自动摘要、观点提取、文本分类、问题回答、文本语义对比、语音识别、中文OCR等方面。

本教程操作环境:windows7系统、Dell G3电脑。
机器翻译属于“自然语言处理”领域的应用。
自然语言处理( Natural Language Processing, NLP)是计算机科学领域与人工智能领域中的一个重要方向。它研究能实现人与计算机之间用自然语言进行有效通信的各种理论和方法。
自然语言处理是一门融语言学、计算机科学、数学于一体的科学。因此,这一领域的研究将涉及自然语言,即人们日常使用的语言,所以它与语言学的研究有着密切的联系,但又有重要的区别。
自然语言处理并不是一般地研究自然语言,而在于研制能有效地实现自然语言通信的计算机系统,特别是其中的软件系统。因而它是计算机科学的一部分。
自然语言处理主要应用于机器翻译、舆情监测、自动摘要、观点提取、文本分类、问题回答、文本语义对比、语音识别、中文OCR等方面。
机器翻译,又称为自动翻译,是利用计算机将一种自然语言(源语言)转换为另一种自然语言(目标语言)的过程。它是计算语言学的一个分支,是人工智能的终极目标之一,具有重要的科学研究价值。同时,机器翻译又具有重要的实用价值。随着经济全球化及互联网的飞速发展,机器翻译技术在促进政治、经济、文化交流等方面起到越来越重要的作用。
鉴于机器翻译仍具相当市场,中国涉足这一领域的厂商也不一而足。国内市场上的翻译软件产品可以划分为四大类:全文翻译(专业翻译)、在线翻译、汉化软件和电子词典。
-
全文翻译
全文翻译软件以中软“译星”以及“雅信CAT2.5”为代表;
-
在线翻译
随着全球化网络时代的到来,语言障碍已经成为二十一世纪社会发展的重要瓶颈,实现任意时间、任意地点、任意语言的无障碍自由沟通是人类追求的一个梦想。这仅是全球化背景下的一个小缩影。在社会快速发展的进程中,机器翻译扮演越来越重要的角色。
词典类软件如金山词霸,有道词典等,基于大数据的互联网机器翻译系统如百度翻译,谷歌翻译等。
-
汉化类翻译
汉化类翻译软件主要以“东方快车3000”为代表;
-
词典工具
词曲工具软件以“金山词霸.net2001”为主要代表。
更多相关知识,请访问常见问题栏目!
Atas ialah kandungan terperinci 机器翻译属于哪个领域的应用. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1382
1382
 52
52

 Panduan Pemula untuk Pemprosesan Bahasa Semulajadi dalam PHP
Jun 11, 2023 pm 06:30 PM
Panduan Pemula untuk Pemprosesan Bahasa Semulajadi dalam PHP
Jun 11, 2023 pm 06:30 PM
Dengan perkembangan teknologi kecerdasan buatan, Natural Language Processing (NLP) telah menjadi teknologi yang sangat penting. NLP boleh membantu kami lebih memahami dan menganalisis bahasa manusia untuk mencapai beberapa tugas automatik, seperti perkhidmatan pelanggan pintar, analisis sentimen, terjemahan mesin, dsb. Dalam artikel ini, kami akan membincangkan asas dan alatan untuk pemprosesan bahasa semula jadi menggunakan PHP. Apakah pemprosesan bahasa semulajadi adalah kaedah yang menggunakan teknologi kecerdasan buatan untuk memproses
 Pengiktirafan entiti yang dinamakan dan teknologi pengekstrakan perhubungan dan aplikasi dalam pemprosesan bahasa semula jadi berasaskan Java
Jun 18, 2023 am 09:43 AM
Pengiktirafan entiti yang dinamakan dan teknologi pengekstrakan perhubungan dan aplikasi dalam pemprosesan bahasa semula jadi berasaskan Java
Jun 18, 2023 am 09:43 AM
Dengan kemunculan era Internet, sejumlah besar maklumat teks telah membanjiri bidang penglihatan kita, diikuti oleh keperluan orang ramai untuk pemprosesan dan analisis maklumat yang semakin meningkat. Pada masa yang sama, era Internet juga telah membawa perkembangan pesat teknologi pemprosesan bahasa semula jadi, membolehkan orang ramai memperoleh maklumat berharga daripada teks dengan lebih baik. Antaranya, pengiktirafan entiti yang dinamakan dan teknologi pengekstrakan perhubungan merupakan salah satu hala tuju penyelidikan penting dalam bidang aplikasi pemprosesan bahasa semula jadi. 1. Teknologi pengecaman entiti bernama Entiti bernama merujuk kepada orang, tempat, organisasi, masa, mata wang, pengetahuan ensiklopedia, istilah pengukuran dan profesion.
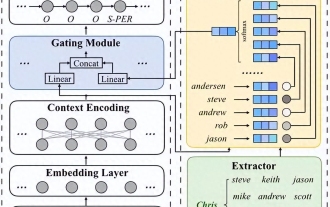 Pemprosesan bahasa semula jadi: membolehkan komputer memahami dan memproses bahasa manusia
Sep 21, 2023 pm 03:53 PM
Pemprosesan bahasa semula jadi: membolehkan komputer memahami dan memproses bahasa manusia
Sep 21, 2023 pm 03:53 PM
Natural Language Processing (NLP) ialah teknologi penting dan menarik dalam bidang kecerdasan buatan Matlamatnya adalah untuk membolehkan komputer memahami, menghuraikan dan menjana bahasa manusia. Pembangunan NLP telah mencapai kemajuan yang luar biasa, membolehkan komputer berinteraksi dengan lebih baik dengan manusia dan mencapai rangkaian aplikasi yang lebih luas. Artikel ini akan meneroka konsep, teknologi, aplikasi dan prospek pemprosesan bahasa semula jadi pada masa hadapan Konsep pemprosesan bahasa semula jadi ialah satu disiplin yang mengkaji bagaimana untuk membolehkan komputer memahami dan memproses bahasa manusia. Kerumitan dan kekaburan bahasa manusia menjadikan komputer menghadapi cabaran besar dalam memahami dan memproses. Matlamat NLP adalah untuk membangunkan algoritma dan model yang membolehkan komputer mengekstrak maklumat daripada teks
 Bagaimanakah penggunaan fungsi Java dalam pemprosesan bahasa semula jadi memudahkan interaksi perbualan?
Apr 30, 2024 am 08:03 AM
Bagaimanakah penggunaan fungsi Java dalam pemprosesan bahasa semula jadi memudahkan interaksi perbualan?
Apr 30, 2024 am 08:03 AM
Fungsi Java digunakan secara meluas dalam NLP untuk mencipta penyelesaian tersuai yang meningkatkan pengalaman interaksi perbualan. Fungsi ini boleh digunakan untuk prapemprosesan teks, analisis sentimen, pengecaman niat dan pengekstrakan entiti. Contohnya, dengan menggunakan fungsi Java untuk analisis sentimen, aplikasi boleh memahami nada pengguna dan bertindak balas dengan sewajarnya, meningkatkan pengalaman perbualan.
![[Python NLTK] Tutorial: Bermula dengan mudah dan berseronok dengan pemprosesan bahasa semula jadi](https://img.php.cn/upload/article/000/465/014/170882721469561.jpg?x-oss-process=image/resize,m_fill,h_207,w_330) [Python NLTK] Tutorial: Bermula dengan mudah dan berseronok dengan pemprosesan bahasa semula jadi
Feb 25, 2024 am 10:13 AM
[Python NLTK] Tutorial: Bermula dengan mudah dan berseronok dengan pemprosesan bahasa semula jadi
Feb 25, 2024 am 10:13 AM
1. Pengenalan kepada NLTK NLTK ialah kit pemprosesan bahasa semula jadi untuk bahasa pengaturcaraan Python, yang dicipta pada tahun 2001 oleh Steven Bird dan Edward Loper. NLTK menyediakan pelbagai alat pemprosesan teks, termasuk prapemprosesan teks, pembahagian perkataan, pengetegan sebahagian daripada pertuturan, analisis sintaksis, analisis semantik, dsb., yang boleh membantu pembangun memproses data bahasa semula jadi dengan mudah. 2.Pemasangan NLTK NLTK boleh dipasang melalui arahan berikut: fromnltk.tokenizeimportWord_tokenizetext="Hello, world!Thisisasampletext."tokens=word_tokenize(te
 Bagaimana untuk mengkonfigurasi pemprosesan bahasa semula jadi menggunakan IntelliJ IDEA pada sistem Linux
Jul 05, 2023 pm 10:45 PM
Bagaimana untuk mengkonfigurasi pemprosesan bahasa semula jadi menggunakan IntelliJ IDEA pada sistem Linux
Jul 05, 2023 pm 10:45 PM
Kaedah konfigurasi untuk menggunakan IntelliJIDEA untuk pemprosesan bahasa semula jadi pada sistem Linux IntelliJIDEA ialah persekitaran pembangunan bersepadu (IDE) yang berkuasa yang sesuai untuk berbilang bahasa pengaturcaraan. Artikel ini akan memperkenalkan cara mengkonfigurasi IntelliJIDEA pada sistem Linux untuk memudahkan pembangunan pemprosesan bahasa semula jadi (NLP). Langkah 1: Muat turun dan pasang IntelliJIDEA Mula-mula, kita perlu pergi ke laman web rasmi https://www.
 Pelajari pemprosesan bahasa semula jadi dan analisis teks dalam JavaScript
Nov 03, 2023 pm 04:32 PM
Pelajari pemprosesan bahasa semula jadi dan analisis teks dalam JavaScript
Nov 03, 2023 pm 04:32 PM
Mempelajari pemprosesan bahasa semula jadi dan analisis teks dalam JavaScript memerlukan contoh kod khusus Pemprosesan Bahasa Semulajadi (NLP) ialah disiplin yang melibatkan kecerdasan buatan dan sains komputer. Ia mengkaji interaksi antara komputer dan bahasa semula jadi manusia. Dalam konteks perkembangan pesat teknologi maklumat hari ini, NLP digunakan secara meluas dalam pelbagai bidang, seperti perkhidmatan pelanggan pintar, terjemahan mesin, perlombongan teks, dll. JavaScript sebagai pembangunan bahagian hadapan
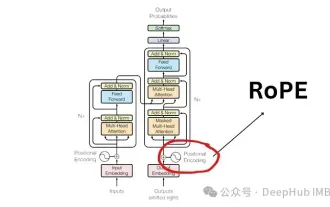 Penjelasan terperinci tentang pengekodan kedudukan putaran RoPE yang biasa digunakan dalam model bahasa besar: mengapa ia lebih baik daripada pengekodan kedudukan mutlak atau relatif?
Apr 01, 2024 pm 08:19 PM
Penjelasan terperinci tentang pengekodan kedudukan putaran RoPE yang biasa digunakan dalam model bahasa besar: mengapa ia lebih baik daripada pengekodan kedudukan mutlak atau relatif?
Apr 01, 2024 pm 08:19 PM
Sejak kertas "AttentionIsAllYouNeed" diterbitkan pada 2017, seni bina Transformer telah menjadi asas kepada bidang pemprosesan bahasa semula jadi (NLP). Reka bentuknya sebahagian besarnya kekal tidak berubah selama bertahun-tahun, dengan 2022 menandakan perkembangan besar dalam bidang dengan pengenalan Pengekodan Kedudukan Putar (RoPE). Benam kedudukan diputar ialah teknik benam kedudukan NLP terkini. Model bahasa berskala besar yang paling popular (seperti Llama, Llama2, PaLM dan CodeGen) sudah menggunakannya. Dalam artikel ini, kami akan menyelami lebih mendalam tentang pengekodan kedudukan putaran dan cara pengekodan ini menggabungkan dengan kemas manfaat daripada benam kedudukan mutlak dan relatif. Keperluan untuk pengekodan kedudukan untuk memahami Ro