

Artikel ini akan memperkenalkan anda kepada algoritma pernyataan bergabung dalam MySQL, dan memperkenalkan cara untuk mengoptimumkan pernyataan bergabung.

Buat dua jadual t1 dan t2
CREATE TABLE `t2` (
`id` int(11) NOT NULL,
`a` int(11) DEFAULT NULL,
`b` int(11) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `a` (`a`)
) ENGINE=InnoDB;
CREATE DEFINER=`root`@`%` PROCEDURE `idata`()
BEGIN
declare i int;
set i=1;
while(i<=1000)do
insert into t2 values(i, i, i);
set i=i+1;
end while;
END
create table t1 like t2;
insert into t1 (select * from t2 where id<=100);Dua ini Setiap satu. jadual mempunyai id indeks kunci utama dan indeks a, dan tiada indeks pada medan b. Prosedur tersimpan idata() memasukkan 1000 baris data ke dalam jadual t2 dan memasukkan 100 baris data ke dalam jadual t1
select * from t1 straight_join t2 on (t1.a=t2.a);
Jika anda menggunakan kenyataan gabungan secara langsung, pengoptimum MySQL boleh memilih jadual t1 atau t2 sebagai jadual pemacu, dan biarkan MySQL menggunakan kaedah sambungan tetap untuk melaksanakan pertanyaan melalui straight_join Dalam pernyataan ini, t1 ialah jadual pemacu dan t2 ialah jadual terdorong. >
1. Daripada Baca satu baris data R daripada jadual t1 2. Dari baris data R, keluarkan medan dan cari
daripada jadual t1 2. Dari baris data R, keluarkan medan dan cari
Proses ini boleh menggunakan indeks jadual didorong, yang dipanggil Index Nested-Loop Join, dirujuk sebagai NLJ Dalam proses ini: 1 . Lakukan imbasan jadual penuh bagi jadual pemacu t1. Proses ini memerlukan pengimbasan 100 baris
 2. Untuk setiap baris R, cari jadual t2 berdasarkan medan, menggunakan proses carian pokok. Memandangkan data yang kami bina mempunyai surat-menyurat satu dengan satu, hanya satu baris diimbas dalam setiap proses carian, dan sejumlah 100 baris diimbas
2. Untuk setiap baris R, cari jadual t2 berdasarkan medan, menggunakan proses carian pokok. Memandangkan data yang kami bina mempunyai surat-menyurat satu dengan satu, hanya satu baris diimbas dalam setiap proses carian, dan sejumlah 100 baris diimbas
untuk mengetahui semua data dalam jadual t1 ialah 100 baris di sini
2 Gelung Lintas 100 baris data ini:
select * from t1Dapatkan nilai medan a dari setiap baris R $R.a
Laksanakan
select * from t2 where a=$R.a Proses pertanyaan ini juga mengimbas 200 baris, tetapi melaksanakan sejumlah 101 pernyataan, iaitu 100 lebih interaksi daripada penyertaan langsung. Pelanggan juga perlu menyambung penyataan dan keputusan SQL dengan sendirinya. Ini tidak sebaik menyertai secara langsung Dalam kes di mana indeks jadual dipandu boleh digunakan:
Menggunakan pernyataan gabungan , prestasi adalah lebih baik daripada paksaan Prestasi pemisahan kepada beberapa jadual tunggal untuk melaksanakan pernyataan SQL adalah lebih baik
Jika anda menggunakan pernyataan gabungan, anda perlu menjadikan jadual kecil sebagai jadual pemanduan
select * from t1 straight_join t2 on (t1.a=t2.b);
3 Block Nested-Loop Join
Tiada indeks yang tersedia pada jadual didorong Proses algoritma adalah seperti berikut: Dalam proses ini, imbasan jadual penuh dilakukan pada kedua-dua jadual t1 dan jadual t2, jadi jumlah bilangan baris yang diimbas ialah 1100. Memandangkan join_buffer disusun sebagai tatasusunan tidak tertib, 100 pertimbangan mesti dibuat untuk setiap baris dalam jadual t2 Jumlah bilangan pertimbangan yang perlu dibuat dalam ingatan ialah 100*1000=100,000 kali
Dalam proses ini, imbasan jadual penuh dilakukan pada kedua-dua jadual t1 dan jadual t2, jadi jumlah bilangan baris yang diimbas ialah 1100. Memandangkan join_buffer disusun sebagai tatasusunan tidak tertib, 100 pertimbangan mesti dibuat untuk setiap baris dalam jadual t2 Jumlah bilangan pertimbangan yang perlu dibuat dalam ingatan ialah 100*1000=100,000 kali
Gunakan Simple Nested. Algoritma -Loop Join untuk membuat pertanyaan, dan bilangan baris yang diimbas juga ialah 100,000. Oleh itu, dari segi kerumitan masa, kedua-dua algoritma ini adalah sama. Walau bagaimanapun, 100,000 pertimbangan algoritma Block Nested-Loop Join ini adalah operasi memori, yang akan menjadi lebih pantas dan berprestasi lebih baik
Pada masa ini, pilih jadual besar atau jadual kecil Jadual digunakan sebagai jadual pemacu, dan masa pelaksanaan adalah sama
Saiz join_buffer ditetapkan oleh parameter join_buffer_size, dan nilai lalai ialah 256k. Jika semua data dalam jadual t1 tidak boleh diletakkan, strateginya sangat mudah, iaitu meletakkannya dalam segmen
2)扫描表t2,把t2中的每一行取出来,跟join_buffer中的数据做对比,满足join条件的,作为结果集的一部分返回
3)清空join_buffer
4)继续扫描表t1,顺序读取最后的12行放入join_buffer中,继续执行第2步
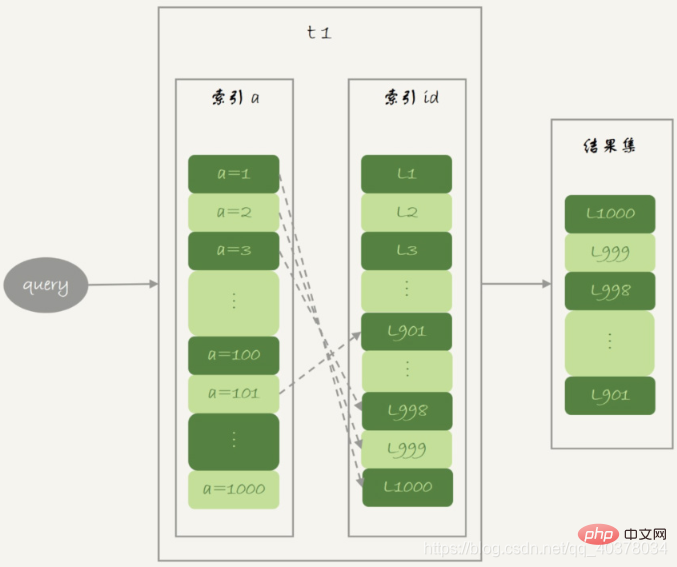
由于表t1被分成了两次放入join_buffer中,导致表t2会被扫描两次。虽然分成两次放入join_buffer,但是判断等值条件的此时还是不变的
1.如果可以使用Index Nested-Loop Join算法,也就是说可以用上被驱动表上的索引,其实是没问题的
2.如果使用Block Nested-Loop Join算法,扫描行数就会过多。尤其是在大表上的join操作,这样可能要扫描被驱动表很多次,会占用大量的系统资源。所以这种join尽量不要用
1.如果是Index Nested-Loop Join算法,应该选择小表做驱动表
2.如果是Block Nested-Loop Join算法:
在决定哪个表做驱动表的时候,应该是两个表按照各自的条件过滤,过滤完成以后,计算参数join的各个字段的总数据量,数据量小的那个表,就是小表,应该作为驱动表
创建两个表t1、t2
create table t1(id int primary key, a int, b int, index(a));create table t2 like t1;CREATE DEFINER = CURRENT_USER PROCEDURE `idata`()BEGIN
declare i int;
set i=1;
while(i<=1000)do
insert into t1 values(i, 1001-i, i);
set i=i+1;
end while;
set i=1;
while(i<=1000000)do
insert into t2 values(i, i, i);
set i=i+1;
end while;END;在表t1中,插入了1000行数据,每一行的a=1001-id的值。也就是说,表t1中字段a是逆序的。同时,在表t2中插入了100万行数据
Multi-Range Read(MRR)优化主要的目的是尽量使用顺序读盘
select * from t1 where a>=1 and a<=100;
主键索引是一棵B+树,在这棵树上,每次只能根据一个主键id查到一行数据。因此,回表是一行行搜索主键索引的
如果随着a的值递增顺序查找的话,id的值就变成随机的,那么就会出现随机访问,性能相对较差
因为大多数的数据都是按照主键递增顺序插入得到的,所以如果按照主键的递增顺序查询,对磁盘的读比较接近顺序读,能够提升读性能
这就是MRR优化的设计思路,语句的执行流程如下:
1.根据索引a,定位到满足条件的记录,将id值放入read_rnd_buffer中
2.将read_rnd_buffer中的id进行递增排序
3.排序后的id数组,依次到主键id索引中查记录,并作为结果返回
read_rnd_buffer的大小是由read_rnd_buffer_size参数控制的。如果步骤1中,read_rnd_buffer放满了,就会先执行完步骤2和3,然后清空read_rnd_buffer。之后继续找索引a的下个记录,并继续循环
如果想要稳定地使用MRR优化的话,需要设置set optimizer_switch="mrr_cost_based=off"
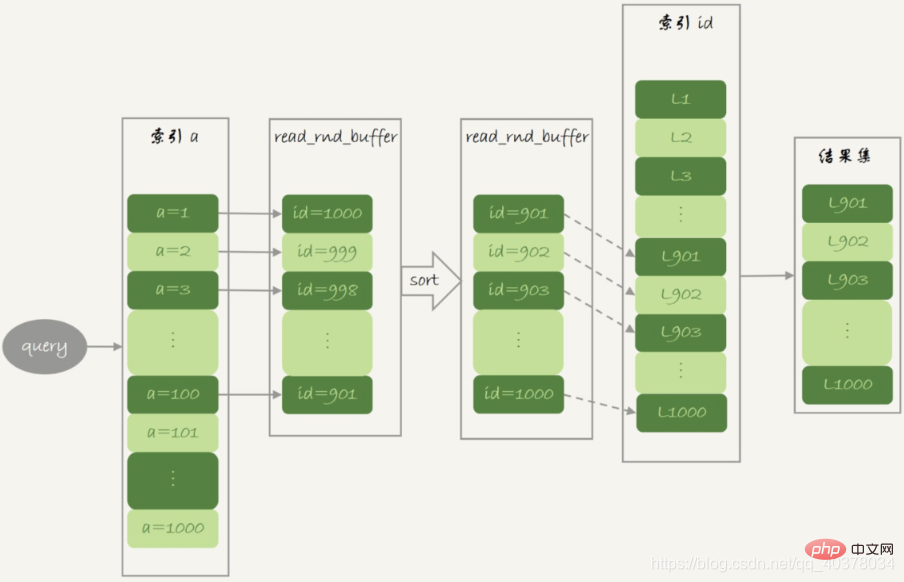

explain结果中,Extra字段多了Using MRR,表示的是用上了MRR优化。由于在read_rnd_buffer中按照id做了排序,所以最后得到的结果也是按照主键id递增顺序的
MRR能够提升性能的核心在于,这条查询语句在索引a上做的是一个范围查询,可以得到足够多的主键id。这样通过排序以后,再去主键索引查数据,才能体现出顺序性的优势
MySQL5.6引入了Batched Key Access(BKA)算法。这个BKA算法是对NLJ算法的优化
NLJ算法流程图:
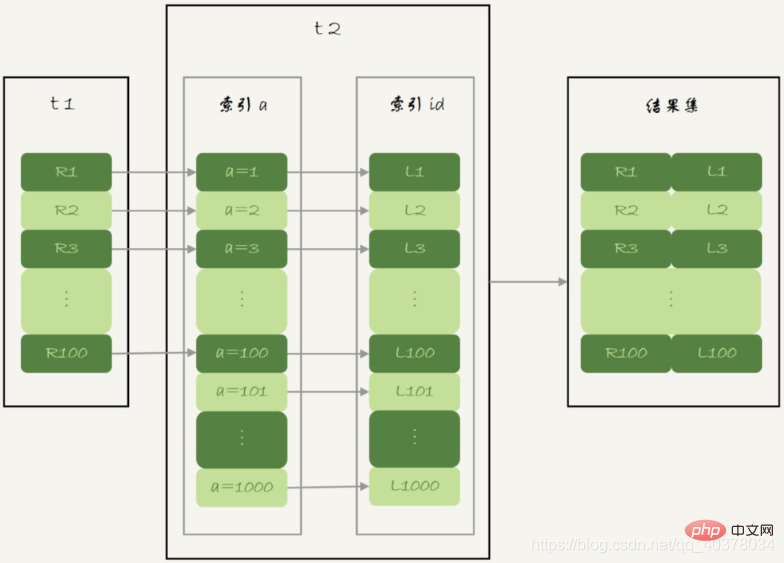
NLJ算法执行的逻辑是从驱动表t1,一行行地取出a的值,再到被驱动表t2去做join
BKA算法流程图:
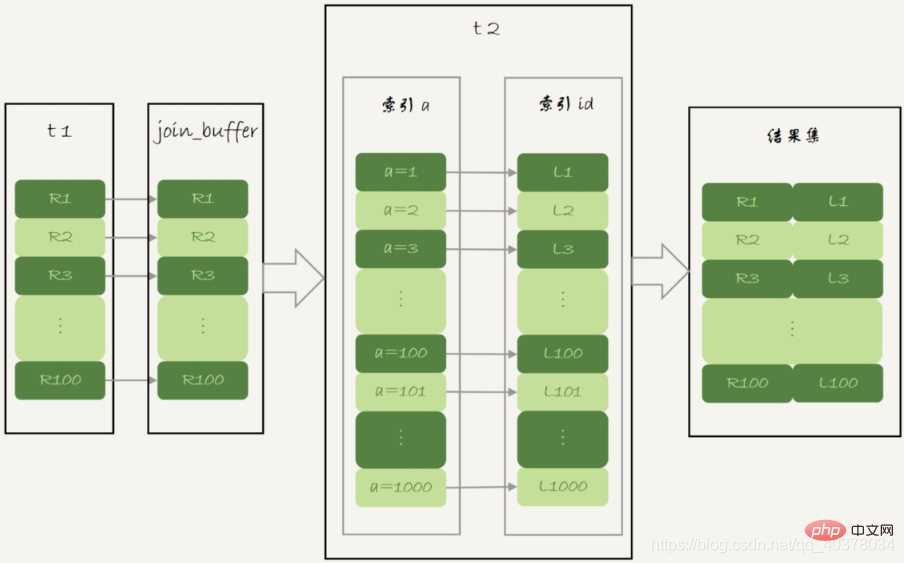
BKA算法执行的逻辑是把表t1的数据取出来一部分,先放到一个join_buffer,一起传给表t2。在join_buffer中只会放入查询需要的字段,如果join_buffer放不下所有数据,就会将数据分成多段执行上图的流程
如果想要使用BKA优化算法的话,执行SQL语句之前,先设置
set optimizer_switch='mrr=on,mrr_cost_based=off,batched_key_access=on';
其中前两个参数的作用是启用MRR,原因是BKA算法的优化要依赖与MRR
InnoDB对Buffer Pool的LRU算法做了优化,即:第一次从磁盘读入内存的数据页,会先放在old区域。如果1秒之后这个数据页不再被访问了,就不会被移动到LRU链表头部,这样对Buffer Pool的命中率影响就不大
如果一个使用BNL算法的join语句,多次扫描一个冷表,而且这个语句执行时间超过1秒,就会在再次扫描冷表的时候,把冷表的数据页移到LRU链表头部。这种情况对应的,是冷表的数据量小于整个Buffer Pool的3/8,能够完全放入old区域的情况
如果这个冷表很大,就会出现另外一种情况:业务正常访问的数据页,没有机会进入young区域。
由于优化机制的存在,一个正常访问的数据页,要进入young区域,需要隔1秒后再次被访问到。但是,由于join语句在循环读磁盘和淘汰内存页,进入old区域的数据页,很可能在1秒之内就被淘汰了。这样就会导致MySQL实例的Buffer Pool在这段时间内,young区域的数据页没有被合理地淘汰

一些情况下,我们可以直接在被驱动表上建索引,这时就可以直接转成BKA算法了
如果碰到一些不适合在被驱动表上建索引的情况,可以考虑使用临时表。大致思路如下:
select * from t1 join t2 on (t1.b=t2.b) where t2.b>=1 and t2.b<=2000;
1)把表t2中满足条件的数据放在临时表tmp_t中
2)为了让join使用BKA算法,给临时表tmp_t的字段b加上索引
3)让表t1和tmp_t做join操作
SQL语句写法如下:
create temporary table temp_t(id int primary key, a int, b int, index(b))engine=innodb; insert into temp_t select * from t2 where b>=1 and b<=2000; select * from t1 join temp_t on (t1.b=temp_t.b);
MySQL的优化器和执行器不支持哈希join,可以自己实现在业务端,实现流程大致如下:
1.select * from t1;取得表t1的全部1000行数据,在业务端存入一个hash结构
2.select * from t2 where b>=1 and b获取表t2中满足条件的2000行数据
3.把这2000行数据,一行一行地取到业务端,到hash结构的数据表中寻找匹配的数据。满足匹配的条件的这行数据,就作为结果集的一行
相关学习推荐:mysql教程(视频)
Atas ialah kandungan terperinci Pemahaman mendalam tentang algoritma pernyataan gabungan dan kaedah pengoptimuman dalam MySQL. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
















![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



