

Artikel ini akan memperkenalkan kepada anda pengetahuan yang berkaitan tentang pengedaran Redis dan membantu anda memahami replikasi tuan-hamba, Sentinel dan pengelompokan, untuk membawa tahap Redis anda ke tahap yang lebih tinggi!

Replikasi tuan-hamba adalah asas pengedaran Redis dan juga tinggi. ketersediaan Redis Assure. Dalam Redis, pelayan yang direplikasi dipanggil pelayan induk (Master), dan pelayan yang mereplikasi pelayan induk dipanggil pelayan hamba (Slave). [Cadangan berkaitan: Tutorial video Redis]
Konfigurasi replikasi tuan-hamba sangat mudah dan terdapat tiga cara (termasuk IP-master alamat IP pelayan/PORT -Port perkhidmatan Redis pelayan utama):
fail konfigurasi - fail redis.conf, konfigurasikan port ip slaveof
arahan - masukkan Pelanggan Redis melaksanakan port ip slaveof
parameter permulaan—— ./redis-server --port ip slaveof
Mekanisme replikasi tuan-hamba Redis tidak sesempurna 6. Ia biasanya telah diulang melalui tiga versi:
2.8 yang lalu
2.8~4.0
Selepas 4.0
Apabila versi berkembang, mekanisme replikasi tuan-hamba Redis bertambah baik secara beransur-ansur tetapi intipatinya berkisar pada dua operasi penyegerakan (penyegerakan) dan penyebaran perintah (penyebaran perintah) Kembangkan; :
Penyegerakan (penyegerakan): merujuk kepada mengemas kini status data pelayan hamba kepada status data semasa pelayan utama, yang terutamanya berlaku semasa pemulaan atau penyegerakan penuh seterusnya.
Penyebaran perintah: Apabila status data pelayan induk diubah suai (tulis/padam, dsb.) dan status data antara induk dan hamba tidak konsisten, perkhidmatan induk akan berubah data Arahan disebarkan kepada pelayan hamba untuk mengembalikan status antara pelayan tuan dan hamba kepada konsistensi.
2.1.1 Penyegerakan
Dalam versi sebelum 2.8, penyegerakan daripada pelayan hamba kepada pelayan induk memerlukan pelayan hamba kepada pelayan induk Perintah penyegerakan berlaku untuk melengkapkan:
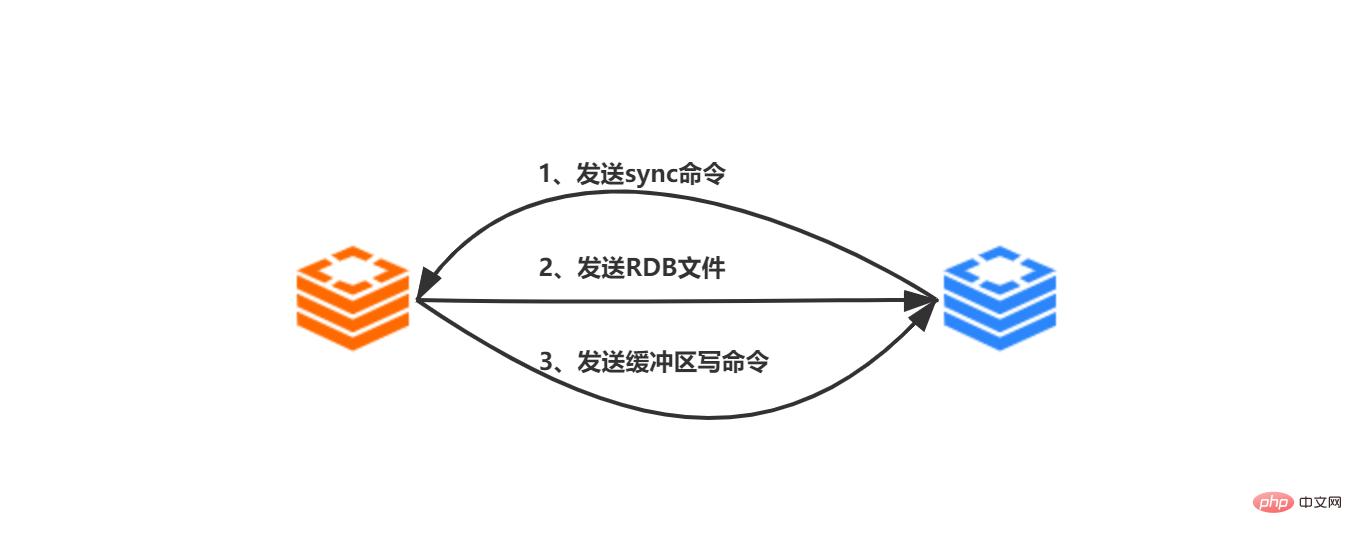
Pelayan hamba menerima perintah slaveof ip prot yang dihantar oleh klien dan pelayan hamba menciptanya ke pelayan induk berdasarkan sambungan Soket ip:port
Selepas soket berjaya disambungkan ke pelayan induk, pelayan hamba akan mengaitkan pengendali acara fail yang khusus digunakan untuk mengendalikan replikasi berfungsi dengan sambungan soket. Fail RDB seterusnya dan arahan disebarkan yang dihantar oleh pelayan induk
mula disalin, dan pelayan hamba menghantar arahan penyegerakan ke pelayan induk
pelayan induk Selepas menerima arahan penyegerakan, laksanakan arahan bgsave Sub-proses garpu proses utama pelayan utama akan menjana fail RDB dan merekodkan semua operasi tulis selepas syot kilat RDB dijana dalam penimbal.
Selepas arahan bgsave dilaksanakan, pelayan induk menghantar fail RDB yang dijana kepada pelayan hamba Selepas menerima fail RDB, pelayan hamba akan mengosongkan semua datanya sendiri, kemudian muatkan fail RDB, dan kemas kini status datanya kepada pelayan induk Status data fail RDB
Pelayan induk menghantar arahan tulis penimbal kepada pelayan hamba, dan pelayan hamba menerima arahan dan melaksanakannya.
Langkah penyegerakan replikasi tuan-hamba selesai
2.1.2 Penyebaran arahan
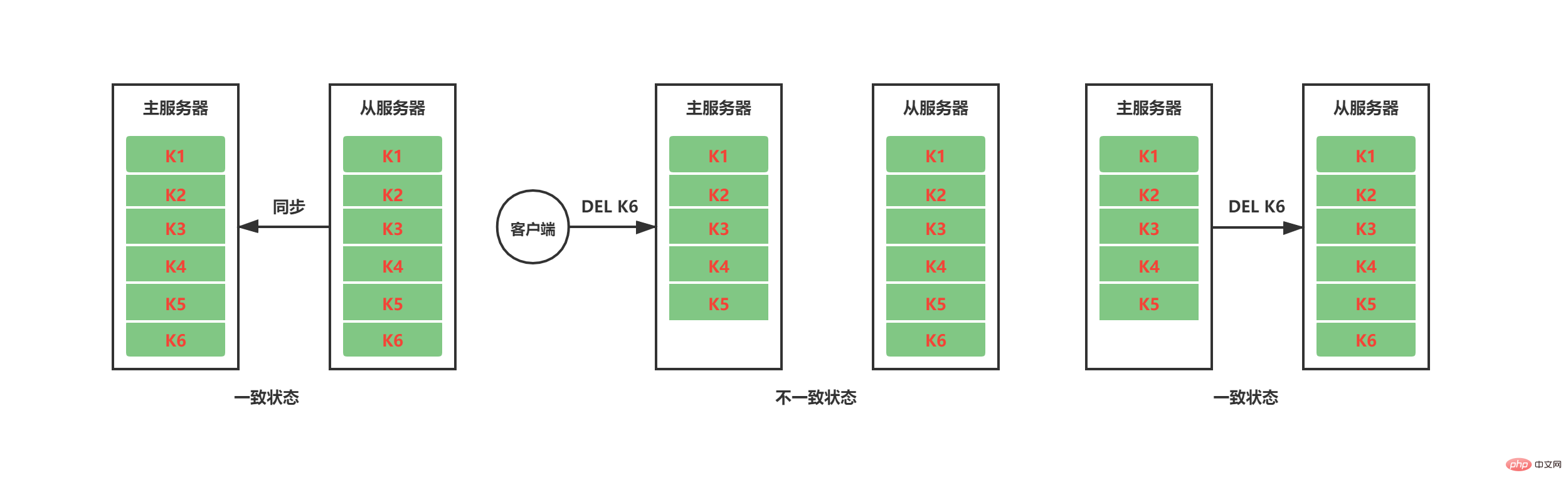
Selepas kerja penyegerakan selesai , replikasi tuan-hamba Ia adalah perlu untuk mengekalkan ketekalan status data melalui penyebaran arahan. Seperti yang ditunjukkan dalam rajah di bawah, selepas kerja penyegerakan antara pelayan induk dan pelayan semasa selesai, perkhidmatan induk memadamkan K6 selepas menerima arahan DEL K6 daripada klien Pada masa ini, K6 masih wujud pada pelayan hamba, dan status data tuan-hamba tidak konsisten. Untuk mengekalkan status pelayan induk dan hamba yang konsisten, pelayan induk akan menyebarkan arahan yang menyebabkan status datanya sendiri berubah kepada pelayan hamba untuk pelaksanaan Apabila pelayan hamba juga melaksanakan arahan yang sama, status data antara pelayan tuan dan hamba akan kekal konsisten.
2.1.3 Kecacatan
Daripada perkara di atas, kami tidak dapat melihat sebarang kelemahan dalam replikasi master-slave versi sebelum 2.8 Ini kerana kami tidak mempertimbangkan turun naik rangkaian. Saudara yang memahami pengedaran pasti pernah mendengar teori CAP adalah asas sistem storan teragih Dalam teori CAP, P (partition network partition) mesti wujud, dan Redis master-slave tidak terkecuali. Apabila kegagalan rangkaian berlaku antara pelayan induk dan hamba, mengakibatkan kegagalan komunikasi antara pelayan hamba dan pelayan induk untuk satu tempoh masa Apabila pelayan hamba menyambung semula ke pelayan induk, jika status data pelayan induk berubah dalam tempoh ini, maka pelayan tuan-hamba Ketidakkonsistenan dalam status data akan berlaku antara pelayan. Dalam versi replikasi induk-hamba sebelum Redis 2.8, cara untuk menyelesaikan ketidakkonsistenan keadaan data ini adalah dengan menghantar semula arahan penyegerakan. Walaupun penyegerakan boleh memastikan bahawa status data pelayan induk dan hamba adalah konsisten, adalah jelas bahawa penyegerakan adalah operasi yang sangat memakan sumber.
Apabila arahan penyegerakan dilaksanakan, sumber yang diperlukan oleh pelayan induk dan hamba ialah:
Pelayan induk melaksanakan BGSAVE untuk menjana fail RDB, yang akan menduduki banyak CPU, cakera I/O dan sumber memori
Pelayan induk menghantar fail RDB yang dijana ke pelayan hamba, yang akan menduduki banyak lebar jalur
Pelayan hamba menerima fail RDB dan memuatkannya, akan menyebabkan pelayan hamba disekat dan tidak dapat menyediakan perkhidmatan
Seperti yang dapat dilihat dari di atas tiga mata, arahan penyegerakan bukan sahaja akan menyebabkan keupayaan tindak balas pelayan induk berkurangan, tetapi juga menyebabkan pelayan hamba Enggan memberikan perkhidmatan kepada orang luar.
2.2.1 Mata penambahbaikan
Untuk versi sebelum 2.8, Redis akan menyambung semula ke pelayan hamba selepas 2.8 Status data penyegerakan telah dipertingkatkan. Arah penambahbaikan adalah untuk mengurangkan berlakunya penyegerakan semula penuh dan menggunakan penyegerakan semula separa sebanyak mungkin. Selepas versi 2.8, arahan psync digunakan dan bukannya perintah penyegerakan untuk melaksanakan operasi penyegerakan Perintah psync mempunyai kedua-dua fungsi penyegerakan penuh dan penyegerakan tambahan:
Penyegerakan penuh dengan versi sebelumnya (. penyegerakan) Konsisten
Dalam penyegerakan tambahan, langkah yang berbeza akan diambil mengikut situasi untuk replikasi selepas pemotongan dan penyambungan semula, jika keadaan membenarkan, hanya sebahagian daripada data yang hilang daripada perkhidmatan akan tetap dihantar.
2.2.2 Cara melaksanakan pync
Untuk mencapai penyegerakan tambahan selepas pemotongan dan penyambungan semula daripada pelayan, Redis menambah tiga parameter tambahan:
replikasi mengimbangi
replikasi tunggakan
server running id (run id)
2.2.2.1 Replikasi ofset
Satu ofset replikasi dikekalkan dalam kedua-dua pelayan induk dan pelayan hamba
Pelayan induk menghantar data kepada perkhidmatan hamba, menyebarkan N bait data, dan mengimbangi replikasi perkhidmatan induk meningkat sebanyak N
Pelayan hamba Terima data yang dihantar oleh pelayan induk, terima N bait daripada data, dan meningkatkan pengimbangan replikasi pelayan hamba oleh N
Situasi penyegerakan biasa adalah seperti berikut:
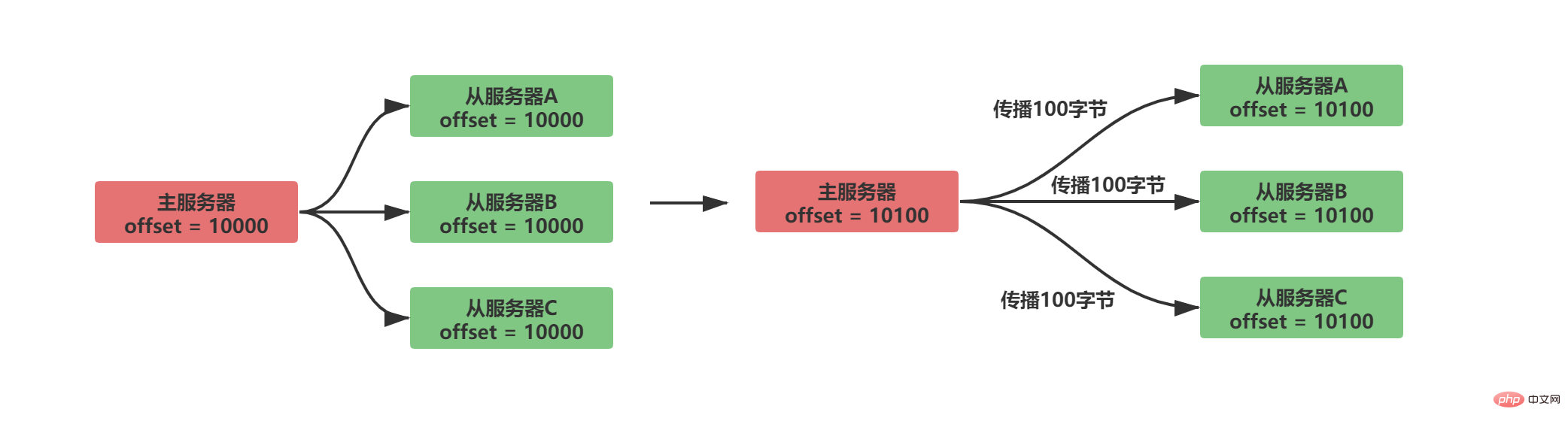
Dengan membandingkan sama ada pengimbangan replikasi antara pelayan induk dan hamba adalah sama, anda boleh mengetahui sama ada status data antara pelayan induk dan hamba adalah konsisten. Dengan mengandaikan bahawa A/B merambat secara normal dan C diputuskan sambungan daripada pelayan, situasi berikut akan berlaku:
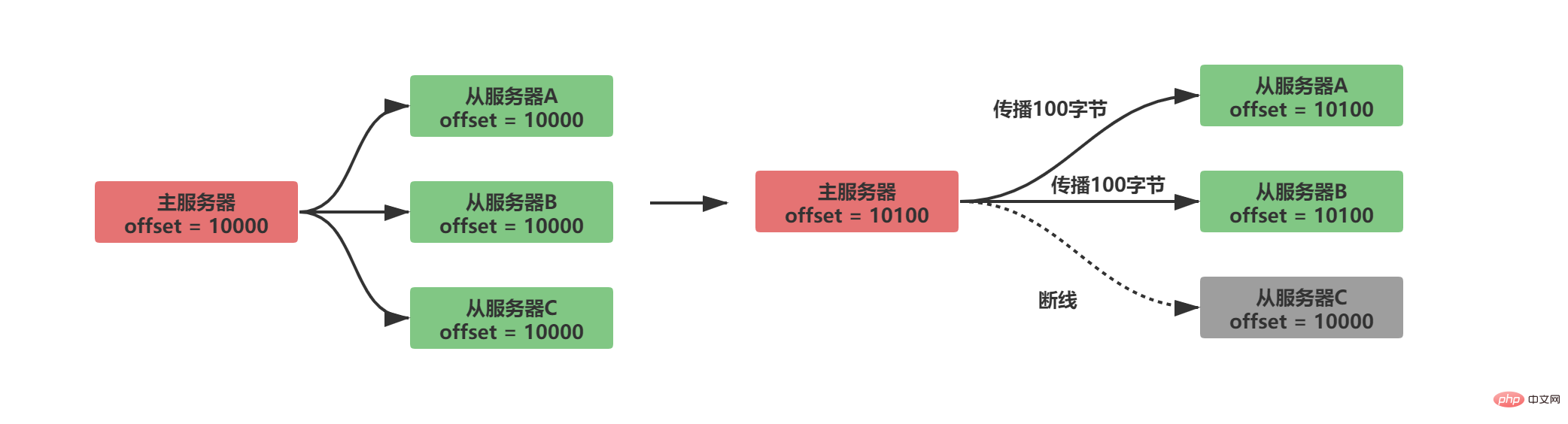
Jelas sekali terdapat salinan offset Kemudian, selepas pelayan hamba C diputuskan dan disambungkan semula, pelayan induk hanya perlu menghantar 100 bait data yang hilang daripada pelayan hamba. Tetapi bagaimanakah pelayan induk mengetahui data yang hilang daripada pelayan hamba?
2.2.2.2 Salin Backlog Buffer
Salin tunggakan penimbal ialah baris gilir tetap dengan saiz lalai 1MB. Apabila status data pelayan induk berubah, pelayan induk menyegerakkan data ke pelayan hamba dan menyimpan salinan ke penimbal tunggakan replikasi.
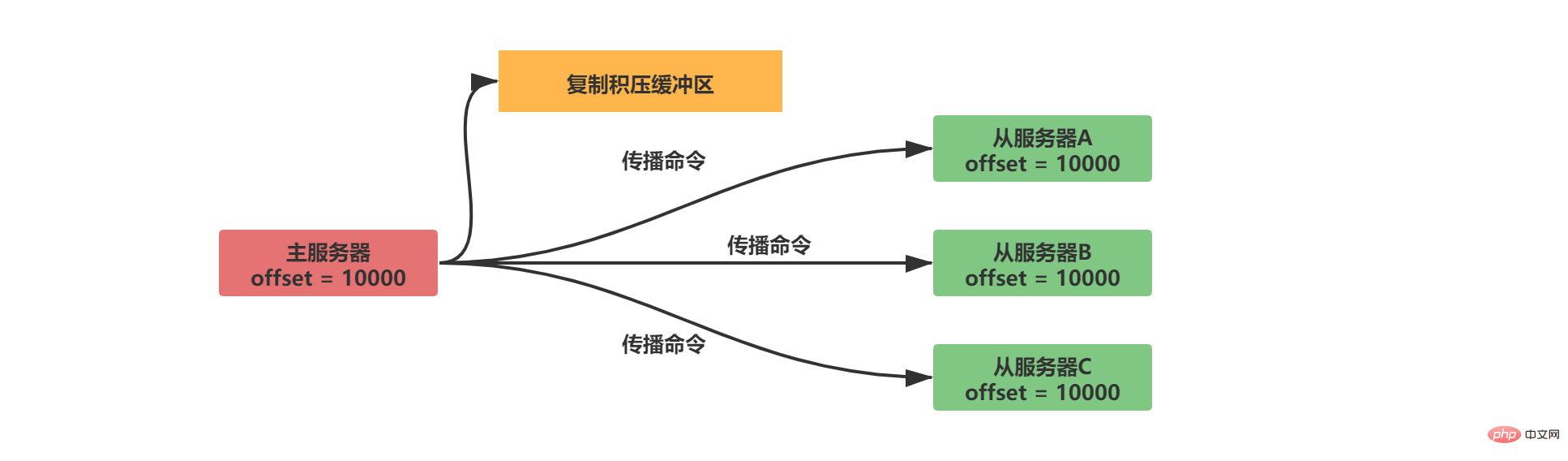
Untuk memadankan offset, penimbal tunggakan salinan bukan sahaja menyimpan kandungan data, tetapi juga merekodkan offset yang sepadan dengan setiap bait:

Apabila pelayan hamba diputuskan sambungan dan disambung semula, pelayan hamba menghantar offset replikasinya (offset) kepada pelayan induk melalui arahan pync, dan pelayan induk boleh menggunakan ofset ini Gunakan jumlah untuk menentukan sama ada untuk melakukan perambatan tambahan atau penyegerakan penuh.
Jika data pada offset 1 masih dalam penimbal tunggakan salinan, kemudian lakukan operasi penyegerakan tambahan
Jika tidak, lakukan Operasi penyegerakan penuh, konsisten dengan penyegerakan
Saiz penimbal tunggakan salinan lalai Redis ialah 1MB. Bagaimana untuk menetapkannya jika anda perlu menyesuaikannya? Jelas sekali, kami mahu menggunakan penyegerakan tambahan sebanyak mungkin, tetapi kami tidak mahu penimbal mengambil terlalu banyak ruang memori. Kemudian kita boleh menetapkan saiz penimbal tunggakan replikasi S dengan menganggarkan masa penyambungan semula T selepas perkhidmatan hamba Redis diputuskan dan saiz memori M bagi arahan tulis yang diterima oleh pelayan induk Redis sesaat.
S = 2 * M * T
Perhatikan bahawa pengembangan di sini digandakan untuk meninggalkan sejumlah bilik untuk memastikan kebanyakan rehat Penyegerakan tambahan boleh digunakan untuk penyambungan semula talian.
2.2.2.3 Server menjalankan ID
Melihat perkara ini, adakah anda fikir sekali lagi bahawa penyegerakan tambahan bagi pemotongan dan penyambungan semula boleh dicapai, dan anda perlu menjalankan ID kering Baik? Malah, terdapat satu lagi situasi yang belum dipertimbangkan, iaitu, apabila pelayan induk turun, pelayan hamba dipilih sebagai pelayan induk baru Dalam kes ini, kita boleh membezakannya dengan membandingkan ID yang sedang berjalan.
ID run (id run) ialah 40 rentetan perenambelasan rawak yang dijana secara automatik apabila pelayan dimulakan, kedua-dua perkhidmatan induk dan pelayan hamba akan menjana ID larian
Apabila pelayan hamba menyegerakkan data pelayan induk buat kali pertama, pelayan induk akan menghantar ID berjalannya ke pelayan hamba, dan pelayan hamba akan menyimpannya dalam fail RDB
Apabila pelayan hamba diputuskan sambungan dan disambungkan semula, pelayan hamba akan menghantar ID yang menjalankan pelayan induk yang disimpan sebelum ini ke pelayan induk Jika pelayan yang menjalankan ID sepadan, ia membuktikan bahawa pelayan induk tidak berubah, dan anda boleh mencuba penyegerakan tambahan
Jika pelayan yang menjalankan ID tidak sepadan, penyegerakan penuh akan dilakukan
2.2.3 Psync lengkap
Proses psync yang lengkap adalah sangat rumit. Ia telah menjadi sangat sempurna dalam replikasi tuan-hamba versi 2.8-4.0. Parameter yang dihantar oleh arahan psync adalah seperti berikut:
psync
Apabila pelayan hamba tidak mereplikasi mana-mana pelayan induk (ia bukan kali pertama tuan-hamba mereplikasi , kerana pelayan induk mungkin berubah, tetapi pelayan hamba disegerakkan sepenuhnya untuk kali pertama), pelayan hamba akan menghantar:
psync ? 1
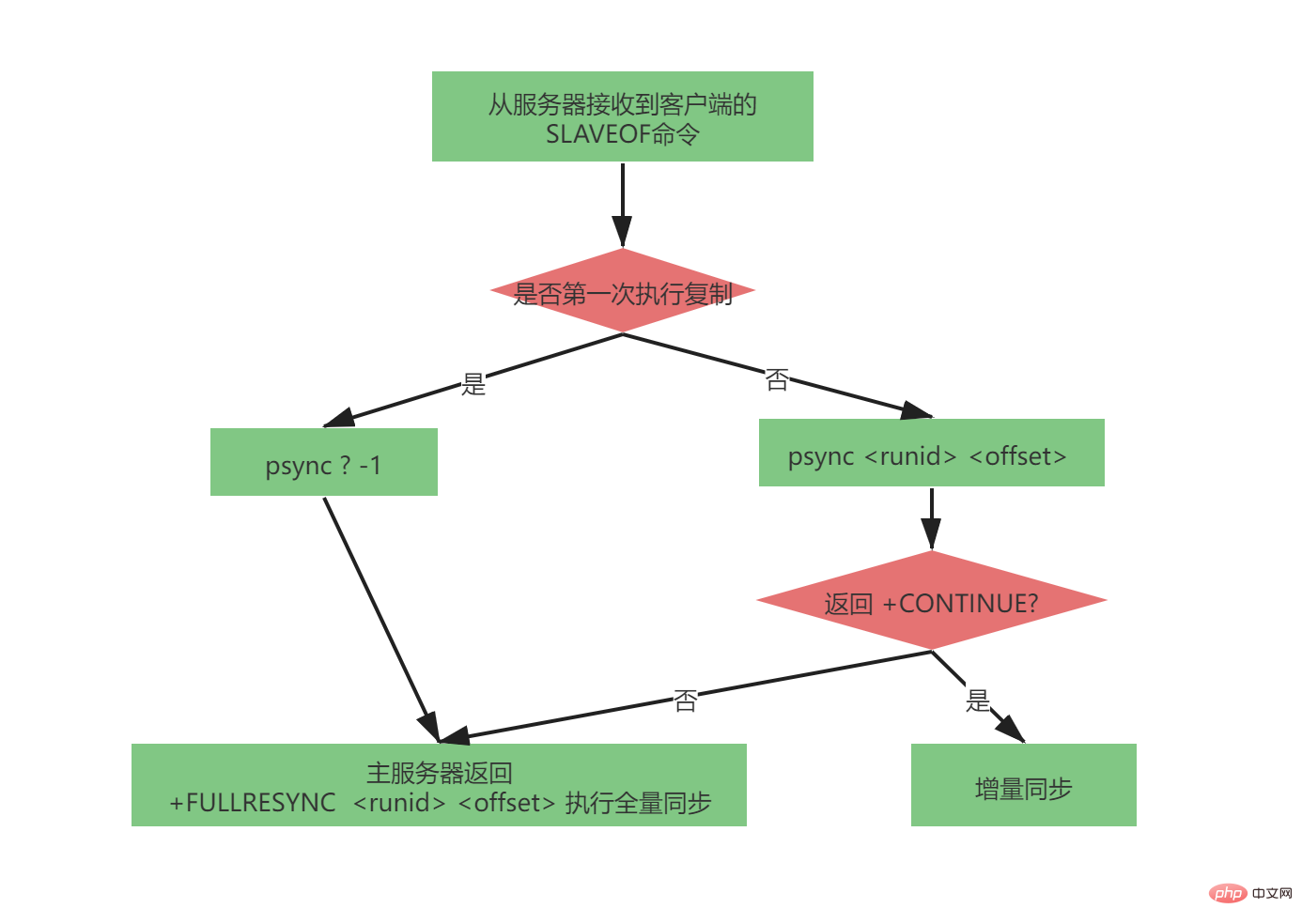
Proses psync yang lengkap adalah seperti berikut:
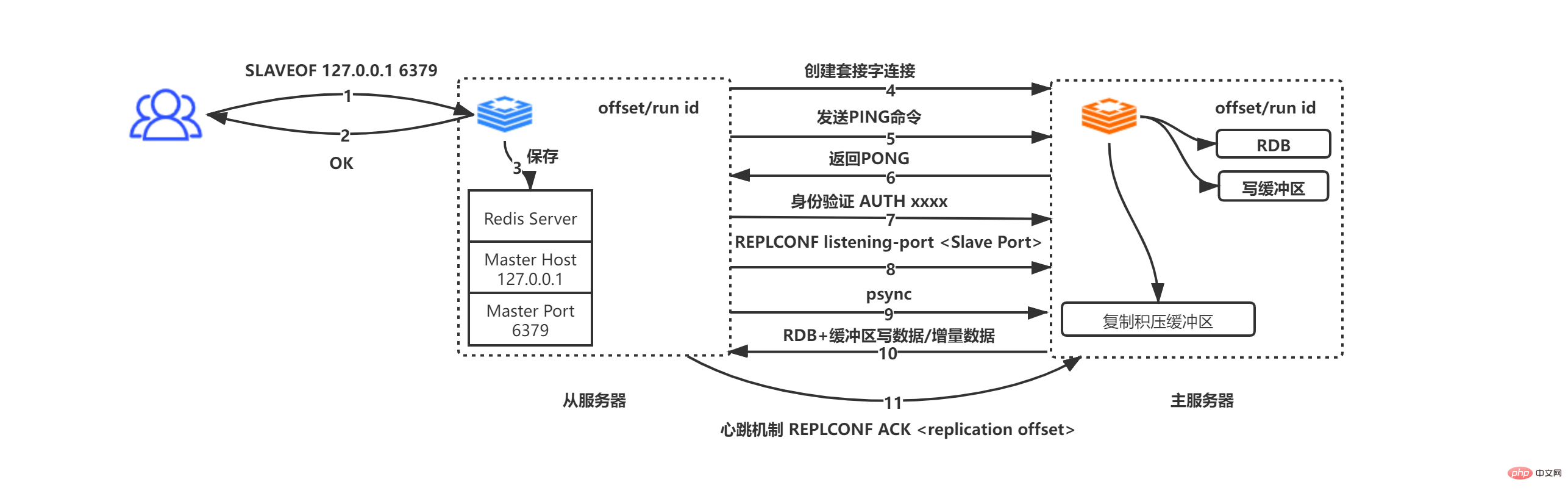
Diterima daripada pelayan Pergi ke SLAVEOF 127.0.0.1 6379 arahan
dan kembalikan OK daripada pelayan kepada pemula arahan (ini adalah operasi tak segerak, kembalikan OK pertama, dan kemudian simpan alamat dan maklumat port)
Pelayan hamba menyimpan alamat IP dan maklumat port ke Hos Induk dan Pelabuhan Induk
Pelayan hamba secara aktif memulakan soket ke pelayan induk berdasarkan sambungan Master Host dan Master Port, dan pada masa yang sama, perkhidmatan hamba akan mengaitkan pengendali acara fail yang khusus digunakan untuk penyalinan fail dengan sambungan soket ini, yang akan digunakan untuk penyalinan fail RDB berikutnya dan kerja lain
Pelayan induk Selepas menerima permintaan sambungan soket daripada pelayan hamba, buat sambungan soket yang sepadan untuk permintaan itu, dan lihat pelayan hamba sebagai pelanggan (dalam replikasi induk-hamba, pelayan induk dan pelayan hamba sebenarnya adalah pelanggan antara satu sama lain. hujung dan pelayan)
Sambungan soket diwujudkan, dan pelayan hamba secara aktif menghantar arahan PING kepada perkhidmatan utama Jika pelayan utama mengembalikan PONG dalam tempoh tamat masa yang ditentukan, soket terbukti Sambungan perkataan tersedia, jika tidak, putuskan sambungan dan sambung semula
Jika pelayan induk menetapkan kata laluan (masterauth), kemudian pelayan hamba menghantar arahan masterauth AUTH ke pelayan induk untuk pengesahan. Ambil perhatian bahawa jika pelayan hamba menghantar kata laluan tetapi perkhidmatan induk tidak menetapkan kata laluan, pelayan induk akan menghantar ralat tiada kata laluan ditetapkan jika pelayan induk memerlukan kata laluan tetapi pelayan hamba tidak menghantar kata laluan, induk pelayan akan menghantar ralat NOAUTH; Jika kata laluan tidak sepadan, pelayan induk menghantar ralat kata laluan yang tidak sah.
Pelayan hamba menghantar port pendengaran REPLCONF xxxx (xxxx mewakili port pelayan hamba) ke pelayan induk. Selepas menerima arahan, pelayan induk akan menyimpan data Apabila pelanggan menggunakan replikasi INFO untuk menanyakan maklumat induk-hamba, ia boleh mengembalikan data
Pelayan hamba menghantar psync. perintah. Sila lihat di atas untuk langkah ini
Pelayan induk dan pelayan hamba adalah pelanggan antara satu sama lain, melaksanakan permintaan/tindak balas data
Pelayan induk Mekanisme paket degupan jantung digunakan antara pelayan dan pelayan hamba untuk menentukan sama ada sambungan diputuskan. Pelayan hamba menghantar arahan kepada pelayan induk setiap 1 saat, mengimbangi REPLCONF ACL (mengimbangi replikasi pelayan hamba Mekanisme ini boleh memastikan penyegerakan data yang betul antara induk dan hamba Jika pengimbangan tidak sama, induk pelayan akan mengambil langkah-langkah penyegerakan Incremental/penuh untuk memastikan status data yang konsisten antara master dan slave (pilihan incremental/penuh bergantung pada sama ada data ofset 1 masih dalam penimbal backlog replikasi)
Redis versi 2.8-4.0 masih mempunyai sedikit ruang untuk penambahbaikan bolehkah penyegerakan tambahan dilakukan apabila pelayan utama ditukar? Oleh itu, versi Redis 4.0 telah dioptimumkan untuk menangani masalah ini, dan psync telah dinaik taraf kepada psync2.0. pync2.0 meninggalkan ID yang sedang berjalan dan menggunakan replid dan replid2 sebaliknya menyimpan ID yang sedang berjalan bagi pelayan utama semasa, dan replid2 menyimpan ID yang sedang berjalan bagi pelayan utama sebelumnya.
replikasi mengimbangi
replikasi tunggakan
Pelayan utama menjalankan id (replid)
Id menjalankan pelayan utama terakhir (replid2)
Melalui replid dan replid2 kita boleh menyelesaikan pelayan utama Apabila menukar, masalah penyegerakan tambahan:
Jika balasan adalah sama dengan id berjalan pelayan utama semasa, kemudian tentukan kaedah penyegerakan tambahan/penyegerakan penuh
Jika replika tidak sama, tentukan sama ada replika adalah sama (sama ada ia tergolong dalam pelayan hamba pelayan induk sebelumnya. Jika ia sama, anda masih boleh memilih penyegerakan tambahan/penuh Jika ia tidak sama, anda hanya boleh melakukan penyegerakan penuh.
Contoh berikut: Apabila Master lama berada di luar talian lebih lama daripada had atas masa luar talian yang ditetapkan oleh pengguna, sistem Sentinel akan melakukan operasi failover pada Master lama Operasi failover merangkumi tiga langkah :
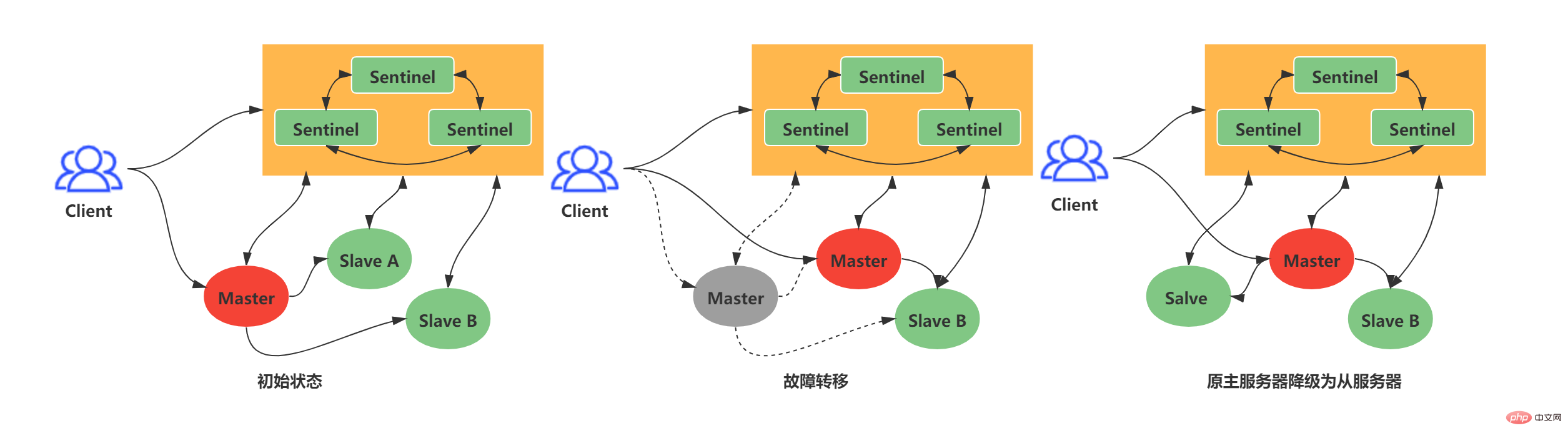
Sentinel adalah pelayan Redis yang lebih mudah, ia akan memuatkan jadual perintah dan fail konfigurasi Perkhidmatan Redis dengan lebih sedikit arahan dan beberapa fungsi khas. Apabila Sentinel bermula, ia perlu melalui langkah berikut: Memulakan pelayan Sentinel Ganti kod Redis biasa dengan Sentinel- kod khusus Mulakan status Sentinel Mulakan senarai pelayan utama yang dipantau oleh Sentinel mengikut fail konfigurasi Sentinel yang diberikan oleh pengguna Buat sambungan rangkaian ke pelayan induk Dapatkan maklumat pelayan hamba berdasarkan perkhidmatan induk dan buat sambungan rangkaian ke pelayan hamba Menurut keluaran /Langgan untuk mendapatkan maklumat Sentinel dan mewujudkan sambungan rangkaian antara Sentinel Sentinel pada dasarnya adalah pelayan Redis, jadi memulakan Sentinel memerlukan memulakan pelayan Redis, tetapi Sentinel tidak perlu membaca fail RDB/AOF untuk memulihkan keadaan data. Sentinel digunakan untuk perintah Redis yang lebih sedikit Kebanyakan arahan tidak disokong oleh klien Sentinel dan Sentinel mempunyai beberapa fungsi khas untuk menggantikan kod yang digunakan oleh pelayan Redis dengan kod khusus Sentinel semasa permulaan. Dalam tempoh ini, Sentinel akan memuatkan jadual arahan yang berbeza daripada pelayan Redis biasa. Sentinel tidak menyokong perintah seperti SET dan DBSIZE; ia mengekalkan sokongan untuk PING, PSUBSCRIBE, SUBSCRIBE, UNSUBSCRIBE, INFO dan arahan lain ini memberikan jaminan untuk kerja Sentinel. Selepas memuatkan kod unik Sentinel, Sentinel akan memulakan struktur sentinelState, yang digunakan untuk menyimpan maklumat status berkaitan Sentinel, yang paling penting ialah kamus induk. Senarai pelayan induk yang dipantau oleh Sentinel disimpan dalam kamus induk sentinelState Apabila sentinelState dicipta, senarai pelayan induk yang dipantau oleh Sentinel bermula. Kunci tuan ialah nama perkhidmatan utama Nilai tuan adalah penunjuk kepada sentinelRedisInstance Nama pelayan utama ditentukan oleh fail konfigurasi sentinel.conf kami Nama pelayan utama berikut ialah redis-master (saya mempunyai konfigurasi satu induk dan dua hamba di sini): Instance sentinelRedisInstance menyimpan maklumat pelayan Redis (pelayan induk, pelayan hamba dan maklumat Sentinel semuanya disimpan dalam kejadian ini). Mengikut konfigurasi satu tuan dan dua hamba di atas, anda akan mendapat struktur contoh berikut: Apabila struktur instance dimulakan, Sentinel akan mula membuat sambungan rangkaian kepada Master Dalam langkah ini, Sentinel akan menjadi pelanggan Master. Sambungan arahan dan sambungan langganan akan dibuat antara Sentinel dan Master: Sambungan perintah digunakan untuk mendapatkan maklumat tuan-hamba Langganan sambungan digunakan Maklumat siaran antara Sentinel dan pelayan tuan-hamba yang dipantaunya akan melanggan saluran _sentinel_:hello (perhatikan bahawa tiada sambungan langganan dibuat antara Sentinel. Mereka memperoleh Sentinel lain dengan melanggan saluran _sentinel_:hello. Maklumat awal) Selepas sambungan arahan dibuat, Sentinel menghantar arahan INFO kepada Guru setiap 10 saat, dan menggunakan maklumat balasan Guru Dua aspek pengetahuan boleh diperolehi: Maklumat Guru sendiri Maklumat hamba di bawah Tuan Dapatkan maklumat pelayan hamba mengikut perkhidmatan utama Sentinel boleh membuat sambungan rangkaian kepada Hamba, dan juga mencipta rangkaian sambungan antara Sentinel dan Slave sambungan dan sambungan langganan. 当Sentinel和Slave之间创建网络连接之后,Sentinel成为了Slave的客户端,Sentinel也会每隔10秒钟通过INFO指令请求Slave获取服务器信息。 到这一步Sentinel获取到了Master和Slave的相关服务器数据。这其中比较重要的信息如下: 服务器ip和port 服务器运行id run id 服务器角色role 服务器连接状态mater_link_status Slave复制偏移量slave_repl_offset(故障转移中选举新的Master需要使用) Slave优先级slave_priority 此时实例结构信息如下所示: 此时是不是还有疑问,Sentinel之间是怎么互相发现对方并且相互通信的,这个就和上面Sentinel与自己监视的主从之间订阅_sentinel_:hello频道有关了。 Sentinel会与自己监视的所有Master和Slave之间订阅_sentinel_:hello频道,并且Sentinel每隔2秒钟向_sentinel_:hello频道发送一条消息,消息内容如下: PUBLISH sentinel:hello " 其中s代码Sentinel,m代表Master;ip表示IP地址,port表示端口、runid表示运行id、epoch表示配置纪元。 多个Sentinel在配置文件中会配置相同的主服务器ip和端口信息,因此多个Sentinel均会订阅_sentinel_:hello频道,通过频道接收到的信息就可获取到其他Sentinel的ip和port,其中有如下两点需要注意: 如果获取到的runid与Sentinel自己的runid相同,说明消息是自己发布的,直接丢弃 如果不相同,则说明接收到的消息是其他Sentinel发布的,此时需要根据ip和port去更新或新增Sentinel实例数据 Sentinel之间不会创建订阅连接,它们只会创建命令连接: 此时实例结构信息如下所示: Sentinel最主要的工作就是监视Redis服务器,当Master实例超出预设的时限后切换新的Master实例。这其中有很多细节工作,大致分为检测Master是否主观下线、检测Master是否客观下线、选举领头Sentinel、故障转移四个步骤。 Sentinel每隔1秒钟,向sentinelRedisInstance实例中的所有Master、Slave、Sentinel发送PING命令,通过其他服务器的回复来判断其是否仍然在线。 在Sentinel的配置文件中,当Sentinel PING的实例在连续down-after-milliseconds配置的时间内返回无效命令,则当前Sentinel认为其主观下线。Sentinel的配置文件中配置的down-after-milliseconds将会对其sentinelRedisInstance实例中的所有Master、Slave、Sentinel都适应。 无效指令指的是+PONG、-LOADING、-MASTERDOWN之外的其他指令,包括无响应 如果当前Sentinel检测到Master处于主观下线状态,那么它将会修改其sentinelRedisInstance的flags为SRI_S_DOWN 当前Sentinel认为其下线只能处于主观下线状态,要想判断当前Master是否客观下线,还需要询问其他Sentinel,并且所有认为Master主观下线或者客观下线的总和需要达到quorum配置的值,当前Sentinel才会将Master标志为客观下线。 当前Sentinel向sentinelRedisInstance实例中的其他Sentinel发送如下命令: ip:被判断为主观下线的Master的IP地址 port:被判断为主观下线的Master的端口 current_epoch:当前sentinel的配置纪元 runid:当前sentinel的运行id,runid current_epoch和runid均用于Sentinel的选举,Master下线之后,需要选举一个领头Sentinel来选举一个新的Master,current_epoch和runid在其中发挥着重要作用,这个后续讲解。 接收到命令的Sentinel,会根据命令中的参数检查主服务器是否下线,检查完成后会返回如下三个参数: down_state:检查结果1代表已下线、0代表未下线 leader_runid:返回*代表判断是否下线,返回runid代表选举领头Sentinel leader_epoch:当leader_runid返回runid时,配置纪元会有值,否则一直返回0 当Sentinel检测到Master处于主观下线时,询问其他Sentinel时会发送current_epoch和runid,此时current_epoch=0,runid=* 接收到命令的Sentinel返回其判断Master是否下线时down_state = 1/0,leader_runid = *,leader_epoch=0 down_state返回1,证明接收is-master-down-by-addr命令的Sentinel认为该Master也主观下线了,如果down_state返回1的数量(包括本身)大于等于quorum(配置文件中配置的值),那么Master正式被当前Sentinel标记为客观下线。 此时,Sentinel会再次发送如下指令: 此时的runid将不再是0,而是Sentinel自己的运行id(runid)的值,表示当前Sentinel希望接收到is-master-down-by-addr命令的其他Sentinel将其设置为领头Sentinel。这个设置是先到先得的,Sentinel先接收到谁的设置请求,就将谁设置为领头Sentinel。 发送命令的Sentinel会根据其他Sentinel回复的结果来判断自己是否被该Sentinel设置为领头Sentinel,如果Sentinel被其他Sentinel设置为领头Sentinel的数量超过半数Sentinel(这个数量在sentinelRedisInstance的sentinel字典中可以获取),那么Sentinel会认为自己已经成为领头Sentinel,并开始后续故障转移工作(由于需要半数,且每个Sentinel只会设置一个领头Sentinel,那么只会出现一个领头Sentinel,如果没有一个达到领头Sentinel的要求,Sentinel将会重新选举直到领头Sentinel产生为止)。 故障转移将会交给领头sentinel全权负责,领头sentinel需要做如下事情: 从原先master的slave中,选择最佳的slave作为新的master 让其他slave成为新的master的slave 继续监听旧master,如果其上线,则将其设置为新的master的slave 这其中最难的一步是如果选择最佳的新Master,领头Sentinel会做如下清洗和排序工作: 判断slave是否有下线的,如果有从slave列表中移除 删除5秒内未响应sentinel的INFO命令的slave 删除与下线主服务器断线时间超过down_after_milliseconds * 10 的所有从服务器 根据slave优先级slave_priority,选择优先级最高的slave作为新master 如果优先级相同,根据slave复制偏移量slave_repl_offset,选择偏移量最大的slave作为新master 如果偏移量相同,根据slave服务器运行id run id排序,选择run id最小的slave作为新master 新的Master产生后,领头sentinel会向已下线主服务器的其他从服务器(不包括新Master)发送SLAVEOF ip port命令,使其成为新master的slave。 到这里Sentinel的的工作流程就算是结束了,如果新master下线,则循环流程即可! Redis集群是Redis提供的分布式数据库方案,集群通过分片(sharding)进行数据共享,Redis集群主要实现了以下目标: 在1000个节点的时候仍能表现得很好并且可扩展性是线性的。 没有合并操作(多个节点不存在相同的键),这样在 Redis 的数据模型中最典型的大数据值中也能有很好的表现。 Tulis selamat, sistem cuba menyimpan semua operasi tulis yang dilakukan oleh pelanggan yang disambungkan kepada majoriti nod. Walau bagaimanapun, Redis tidak dapat menjamin bahawa data tidak akan hilang sama sekali. Replikasi induk-hamba segerak akan menyebabkan kehilangan data. Ketersediaan, jika nod induk tidak tersedia, nod hamba boleh menggantikan nod induk. Berkenaan pembelajaran kluster Redis, jika anda tiada pengalaman, digalakkan membaca ketiga-tiga artikel ini (siri Cina) dahulu: Kluster Redis tutorial Tutorial kelompok REDIS -- Stesen Maklumat Cina Redis -- Kumpulan Pengguna Redis China (CRUG) Spesifikasi kelompok Redis Spesifikasi kluster REDIS -- Stesen Maklumat Cina Redis -- Kumpulan Pengguna Redis China (CRUG) Pengerahan kluster pseudo hamba Redis3 master 3 Pemasangan bersendirian CentOS 7 Kluster Redis (3 induk 3 Daripada kluster pseudo), hanya lima langkah mudah diperlukan_Blog-CSDN blog Li Zipin Kandungan berikut bergantung pada struktur tiga induk dan tiga hamba dalam rajah di bawah: Senarai sumber: Membawa anda melalui replikasi tuan-hamba, Sentinel dan pengelompokan dalam Redis Redis 集群没有使用一致性hash, 而是引入了 哈希槽的概念。Redis 集群有16384个哈希槽,每个key通过CRC16校验后对16384取模来决定放置哪个槽,这种结构很容易添加或者删除节点。集群的每个节点负责一部分hash槽,比如上面资源清单的集群有3个节点,其槽分配如下所示: 节点 Master[0] 包含 0 到 5460 号哈希槽 节点 Master[1] 包含5461 到 10922 号哈希槽 节点 Master[2] 包含10923到 16383 号哈希槽 深入学习Redis集群之前,需要了解集群中Redis实例的内部结构。当某个Redis服务节点通过cluster_enabled配置为yes开启集群模式之后,Redis服务节点不仅会继续使用单机模式下的服务器组件,还会增加custerState、clusterNode、custerLink等结构用于存储集群模式下的特殊数据。 如下三个数据承载对象一定要认真看,尤其是结构中的注释,看完之后集群大体上怎么工作的,心里就有数了,嘿嘿嘿; clsuterNode用于存储节点信息,比如节点的名字、IP地址、端口信息和配置纪元等等,以下代码列出部分非常重要的属性: 上述代码中可能不太好理解的是slots[16384/8],其实可以简单的理解为一个16384大小的数组,数组索引下标处如果为1表示当前槽属于当前clusterNode处理,如果为0表示不属于当前clusterNode处理。clusterNode能够通过slots来识别,当前节点处理负责处理哪些槽。 初始clsuterNode或者未分配槽的集群中的clsuterNode的slots如下所示: 假设集群如上面我给出的资源清单,此时代表Master[0]的clusterNode的slots如下所示: clusterLink是clsuterNode中的一个属性,用于存储连接节点所需的相关信息,比如套接字描述符、输入输出缓冲区等待,以下代码列出部分非常重要的属性: 每个节点都会有一个custerState结构,这个结构中存储了当前集群的全部数据,比如集群状态、集群中的所有节点信息(主节点、从节点)等等,以下代码列出部分非常重要的属性: 在custerState有三个结构需要认真了解的,第一个是slots数组,clusterState中的slots数组与clsuterNode中的slots数组是不一样的,在clusterNode中slots数组记录的是当前clusterNode所负责的槽,而clusterState中的slots数组记录的是整个集群的每个槽由哪个clsuterNode负责,因此集群正常工作的时候clusterState的slots数组每个索引指向负责该槽的clusterNode,集群槽未分配之前指向null。 如图展示资源清单中的集群clusterState中的slots数组与clsuterNode中的slots数组: Redis集群中使用两个slots数组的原因是出于性能的考虑: 当我们需要获取整个集群中clusterNode分别负责什么槽时,只需要查询clusterState中的slots数组即可。如果没有clusterState的slots数组,则需要遍历所有的clusterNode结构,这样显然要慢一些 此外clusterNode中的slots数组也有存在的必要,因为集群中任意一个节点之间需要知道彼此负责的槽,此时节点之间只需要互相传输clusterNode中的slots数组结构就行。 第二个需要认真了解的结构是node字典,该结构虽然简单,但是node字典中存储了所有的clusterNode,这也是Redis集群中的单个节点获取其他主节点、从节点信息的主要位置,因此我们也需要注意一下。 第三个需要认真了解的结构是importing_slots_from[16384]数组和migrating_slots_to[16384],这两个数组在集群重新分片时需要使用,需要重点了解,后面再说吧,这里说的话顺序不太对。 Kluster Redis mempunyai sejumlah 16384 slot Seperti yang ditunjukkan dalam senarai sumber di atas, kami berada dalam kelompok tiga induk dan tiga hamba bertanggungjawab untuk slotnya sendiri. dalam proses penempatan tiga-tuan dan tiga-hamba di atas, tidak ada Anda melihat bahawa saya menetapkan slot kepada nod induk yang sepadan Ini kerana kelompok Redis sendiri telah membahagikan slot untuk kita secara dalaman tetapkan slot itu sendiri? Kami boleh menghantar arahan berikut kepada nod untuk menetapkan satu atau lebih slot kepada nod semasa: TAMBAHAN KLUSTERLOT Sebagai contoh, kami mahu Slot 0 dan 1 diberikan kepada Master[0]. Kami hanya perlu menghantar arahan berikut kepada nod Master[0]: TAMBAHAN KLUSTER 0 1< . melalui mesej nod lain akan menerima mesej selepas Kemas kini tatasusunan slot yang sepadan dengan clusterNode dan tatasusunan solts clusterState. HASH_SLOT = CRC16(kunci) mod 16384 Pada masa ini, apabila sambungan klien menghantar permintaan ke nod tertentu , Nod yang sedang menerima arahan akan terlebih dahulu mengira slot i yang dimiliki oleh kunci semasa melalui algoritma Selepas pengiraan, nod semasa akan menentukan sama ada slot i clusterState adalah tanggungjawabnya sendiri tanggungjawab sendiri, nod semasa akan bertindak balas kepada permintaan pelanggan Jika permintaan tidak dikendalikan oleh nod semasa, ia akan melalui langkah-langkah berikut: CLUSTER 用于槽分配的指令主要有如上这些,ADDSLOTS 和DELSLOTS主要用于槽的快速指派和快速删除,通常我们在集群刚刚建立的时候进行快速分配的时候才使用。CLUSTER SETSLOT slot NODE node也用于直接给指定的节点指派槽。如果集群已经建立我们通常使用最后两个来重分配,其代表的含义如下所示: 当一个槽被设置为 MIGRATING,原来持有该哈希槽的节点仍会接受所有跟这个哈希槽有关的请求,但只有当查询的键还存在原节点时,原节点会处理该请求,否则这个查询会通过一个 -ASK 重定向(-ASK redirection)转发到迁移的目标节点。 当一个槽被设置为 IMPORTING,只有在接受到 ASKING 命令之后节点才会接受所有查询这个哈希槽的请求。如果客户端一直没有发送 ASKING 命令,那么查询都会通过 -MOVED 重定向错误转发到真正处理这个哈希槽的节点那里。 上面这两句话是不是感觉不太看的懂,这是官方的描述,不太懂的话我来给你通俗的描述,整个流程大致如下步骤: redis-trib(集群管理软件redis-trib会负责Redis集群的槽分配工作),向目标节点(槽导入节点)发送CLUSTER SETSLOT slot IMPORTING node命令,目标节点会做好从源节点(槽导出节点)导入槽的准备工作。 redis-trib随即向源节点发送CLUSTER SETSLOT slot MIGRATING node命令,源节点会做好槽导出准备工作 redis-trib随即向源节点发送CLUSTER GETKEYSINSLOT slot count命令,源节点接收命令后会返回属于槽slot的键,最多返回count个键 redis-trib会根据源节点返回的键向源节点依次发送MIGRATE ip port key 0 timeout命令,如果key在源节点中,将会迁移至目标节点。 迁移完成之后,redis-trib会向集群中的某个节点发送CLUSTER SETSLOT slot NODE node命令,节点接收到命令后会更新clusterNode和clusterState结构,然后节点通过消息传播槽的指派信息,至此集群槽迁移工作完成,且集群中的其他节点也更新了新的槽分配信息。 优秀的你总会想到这种并发情况,牛皮呀!大佬们! 这个问题官方也考虑了,还记得我们在聊clusterState结构的时候么?importing_slots_from和migrating_slots_to就是用来处理这个问题的。 当节点正在导出某个槽,则会在clusterState中的migrating_slots_to数组对应的下标处设置其指向对应的clusterNode,这个clusterNode会指向导入的节点。 当节点正在导入某个槽,则会在clusterState中的importing_slots_from数组对应的下标处设置其指向对应的clusterNode,这个clusterNode会指向导出的节点。 有了上述两个相互数组,就能判断当前槽是否在迁移了,而且从哪里迁移来,要迁移到哪里去?搞笑不就是这么简单…… 此时,回到问题中,如果客户端请求的key刚好属于正在迁移的槽。那么接收到命令的节点首先会尝试在自己的数据库中查找键key,如果这个槽还没迁移完成,且当前key刚好也还没迁移完成,那就直接响应客户端的请求就行。如果该key已经不在了,此时节点会去查询migrating_slots_to数组对应的索引槽,如果索引处的值不为null,而是指向了某个clusterNode结构,那说明这个key已经被迁移到这个clusterNode了。这个时候节点不会继续在处理指令,而是返回ASKING命令,这个命令也会携带导入槽clusterNode对应的ip和port。客户端在接收到ASKING命令之后就需要将请求转向正确的节点了,不过这里有一点需要注意的地方**(因此我放个表情包在这里,方便读者注意)。** Seperti yang dinyatakan sebelum ini, apabila nod mendapati bahawa slot semasa bukan milik pemprosesannya sendiri, ia akan mengembalikan arahan MOVED Jadi bagaimana ia mengendalikan slot yang dipindahkan? Inilah gunanya kluster Redis ini. Apabila nod mendapati bahawa slot sedang berhijrah, ia mengembalikan perintah ASKING kepada klien. Pelanggan akan menerima arahan ASKING, yang mengandungi IP nod dan port clusterNode yang mana slot sedang dipindahkan. Kemudian pelanggan akan mula-mula menghantar arahan ASKING kepada clusterNode yang berpindah Tujuan arahan ini mestilah untuk memberitahu nod semasa bahawa anda perlu membuat pengecualian untuk mengendalikan permintaan ini, kerana slot ini telah dipindahkan kepada anda, dan anda tidak boleh. menolak saya secara langsung ( Oleh itu, jika Redis tidak menerima arahan ASKING, ia akan menanyakan secara langsung kepada clusterState nod, dan slot yang dipindahkan belum dikemas kini ke clusterState, jadi ia hanya boleh mengembalikan MOVED secara langsung, yang akan terus bergelung berkali-kali...), diterima Nod dengan arahan ASKING akan secara paksa melaksanakan permintaan ini sekali (hanya sekali, dan anda perlu menghantar arahan ASKING semula terlebih dahulu pada masa akan datang). Kegagalan kelompok Redis agak mudah Ini berkaitan dengan nod induk dalam sentinel yang turun atau tidak bertindak balas dalam masa maksimum yang ditentukan, dan memilih semula induk baharu. nod daripada nod hamba Kaedah ini sebenarnya serupa. Sudah tentu, premisnya ialah untuk setiap nod induk dalam kelompok Redis, kami telah menyediakan nod hamba terlebih dahulu, jika tidak, ia akan menjadi sia-sia... Langkah-langkah umum adalah seperti berikut: Dalam kluster yang biasa berfungsi, setiap nod akan kerap menghantar arahan PING ke nod lain Jika nod yang menerima arahan tidak mengembalikan mesej PONG dalam masa yang ditentukan, Nod semasa akan menetapkan bendera nod kluster nod yang menerima arahan kepada REDIS_NODE_PFAIL tidak di luar talian, tetapi disyaki berada di luar talian. Nod kluster akan memaklumkan nod lain dengan menghantar mesej maklumat status setiap nod dalam kluster Jika lebih separuh daripada kluster bertanggungjawab Nod induk slot pemprosesan semuanya menetapkan nod induk tertentu seperti yang disyaki berada di luar talian, kemudian nod ini akan ditandakan sebagai luar talian, dan nod akan menetapkan bendera klusterNod nod yang menerima arahan kepada REDIS_NODE_FAIL, FAIL bermakna ia di luar talian Nod kluster menghantar mesej untuk memaklumkan nod lain tentang maklumat status setiap nod dalam kluster Pada masa ini, nod hamba nod luar talian menemui bahawa nod induknya telah ditandakan sebagai status luar talian, maka sudah tiba masanya untuk melangkah ke hadapan Nod hamba nod induk luar talian akan memilih nod hamba sebagai nod induk yang terkini, dan laksanakan nod yang dipilih untuk menunjuk SLAVEOF tiada siapa yang menjadi nod induk baharu Nod induk baharu akan membatalkan penetapan slot nod induk asal dan mengubah suai tugasan slot ini kepada dirinya sendiri, iaitu , ubah suai struktur clusterNode dan struktur clusterState Nod induk baharu menyiarkan arahan PONG kepada gugusan Nod lain akan mengetahui bahawa nod induk baharu telah dijana dan mengemas kini struktur clusterNode Struktur clusterState Jika nod induk baharu akan menghantar arahan SLAVEOF baharu kepada nod hamba yang tinggal bagi nod induk asal, menjadikannya nod hambanya sendiri Nod induk baharu yang terakhir akan bertanggungjawab ke atas nod induk asal Kerja tindak balas slot Saya menulis dengan sangat samar-samar di sini Jika anda perlu menggali secara terperinci, anda mesti baca artikel ini: REDIS cluster-spec - - Redis Chinese Information Station - Redis China User Group (CRUG) http://redis.cn/topics/cluster- spec.html Atau anda boleh lihat Teacher Huang Jianhong Buku "Redis Design and Implementation" ditulis dengan sangat baik, dan saya juga merujuk kepada banyak kandungan. Untuk lebih banyak pengetahuan berkaitan pengaturcaraan, sila lawati: Video Pengaturcaraan! ! Atas ialah kandungan terperinci Membawa anda melalui replikasi tuan-hamba, Sentinel dan pengelompokan dalam Redis. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Alamat IP
Peranan nod
IP地址
节点角色
端口
192.168.211.104
Redis Master/ Sentinel
6379/26379
192.168.211.105
Redis Slave/ Sentinel
6379/26379
192.168.211.106
Redis Slave/ Sentinel
6379/26379
Port
192.168.211.104
Redis Master/ Sentinel
6379/26379 tr>
192.168.211.105
Redis Budak/ Sentinel
6379/26379
192.168.211.106
Redis Slave/ Sentinel
6379/26379 2. Inisialisasi Sentinel dan sambungan rangkaian
2.1 Mulakan pelayan Sentinel
2.2 Gantikan kod Redis biasa dengan kod khusus Sentinel
2.3 Memulakan keadaan Sentinel
struct sentinelState {
//当前纪元,故障转移使用
uint64_t current_epoch;
// Sentinel监视的主服务器信息
// key -> 主服务器名称
// value -> 指向sentinelRedisInstance指针
dict *masters;
// ...
} sentinel;2.4 Mulakan senarai pelayan induk yang dipantau oleh Sentinel
daemonize yes
port 26379
protected-mode no
dir "/usr/local/soft/redis-6.2.4/sentinel-tmp"
sentinel monitor redis-master 192.168.211.104 6379 2
sentinel down-after-milliseconds redis-master 30000
sentinel failover-timeout redis-master 180000
sentinel parallel-syncs redis-master 1
typedef struct sentinelRedisInstance {
// 标识值,标识当前实例的类型和状态。如SRI_MASTER、SRI_SLVAE、SRI_SENTINEL
int flags;
// 实例名称 主服务器为用户配置实例名称、从服务器和Sentinel为ip:port
char *name;
// 服务器运行ID
char *runid;
//配置纪元,故障转移使用
uint64_t config_epoch;
// 实例地址
sentinelAddr *addr;
// 实例判断为主观下线的时长 sentinel down-after-milliseconds redis-master 30000
mstime_t down_after_period;
// 实例判断为客观下线所需支持的投票数 sentinel monitor redis-master 192.168.211.104 6379 2
int quorum;
// 执行故障转移操作时,可以同时对新的主服务器进行同步的从服务器数量 sentinel parallel-syncs redis-master 1
int parallel-syncs;
// 刷新故障迁移状态的最大时限 sentinel failover-timeout redis-master 180000
mstime_t failover_timeout;
// ...
} sentinelRedisInstance;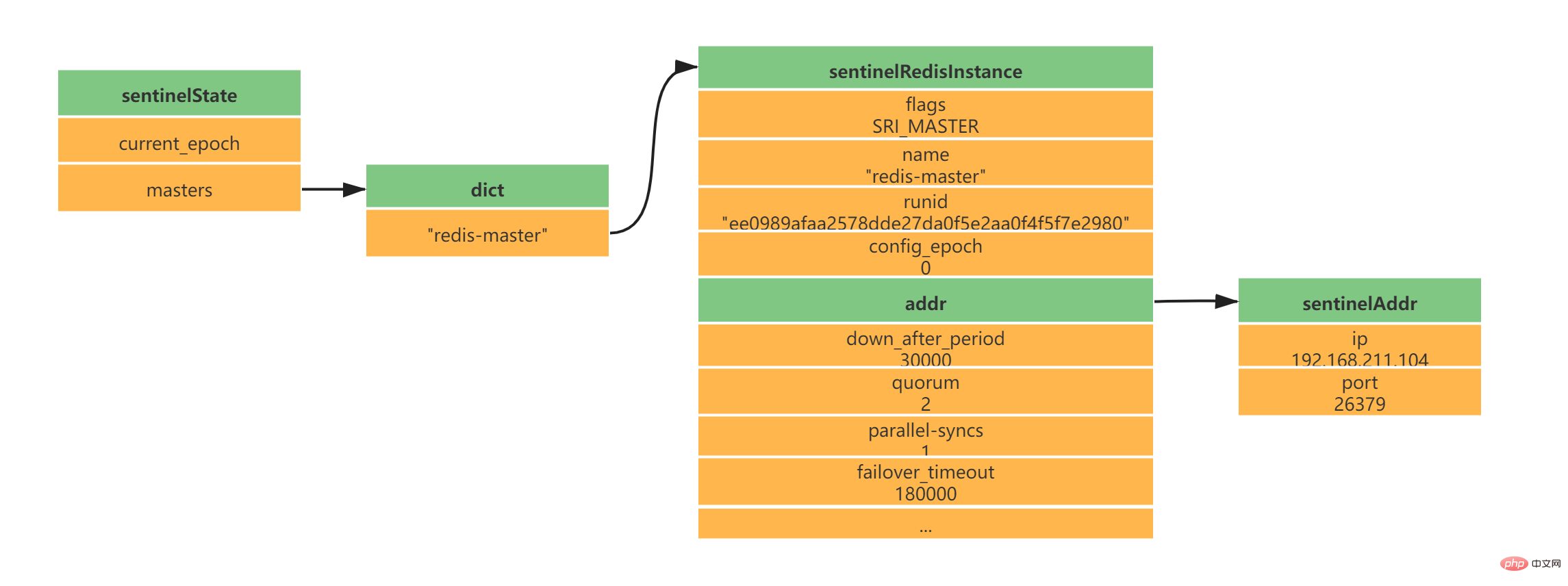
2.5 Buat sambungan rangkaian ke pelayan induk
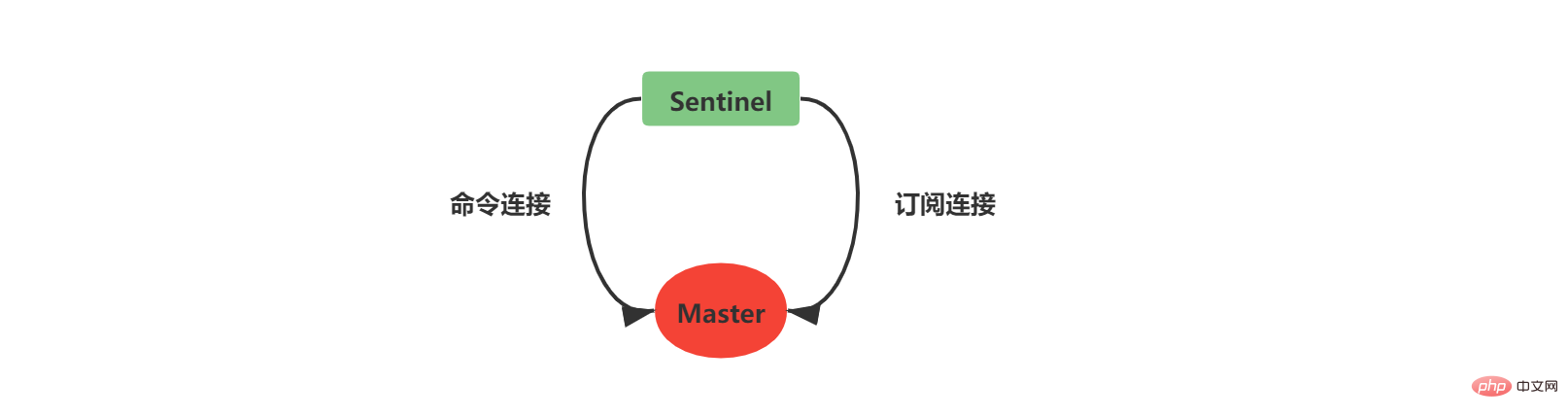
2.6 Buat sambungan rangkaian ke pelayan hamba
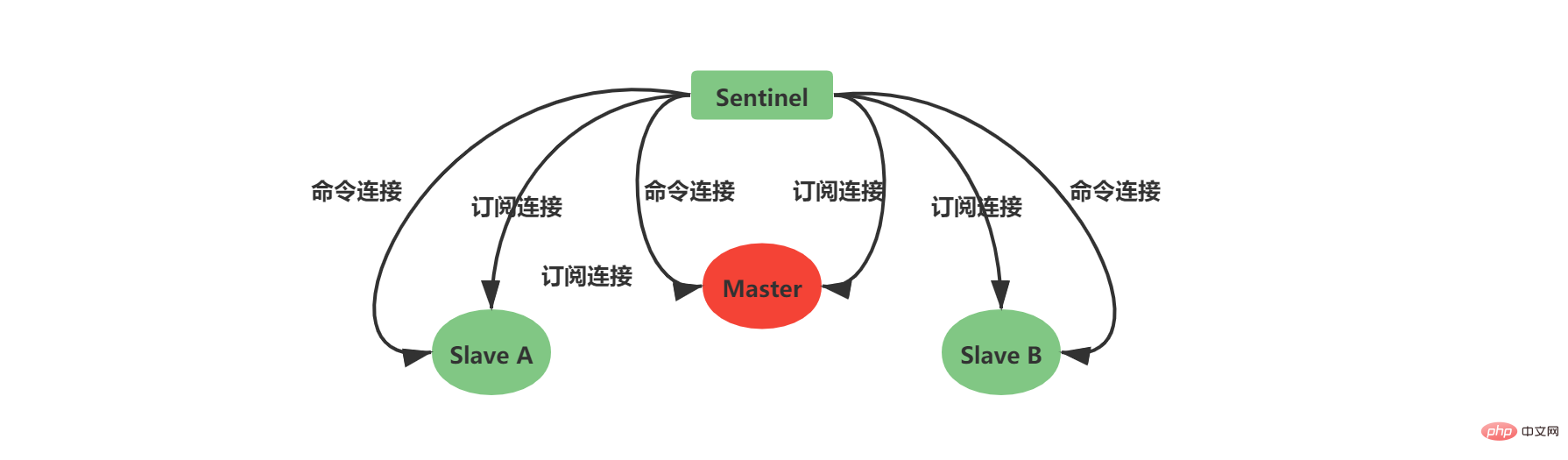
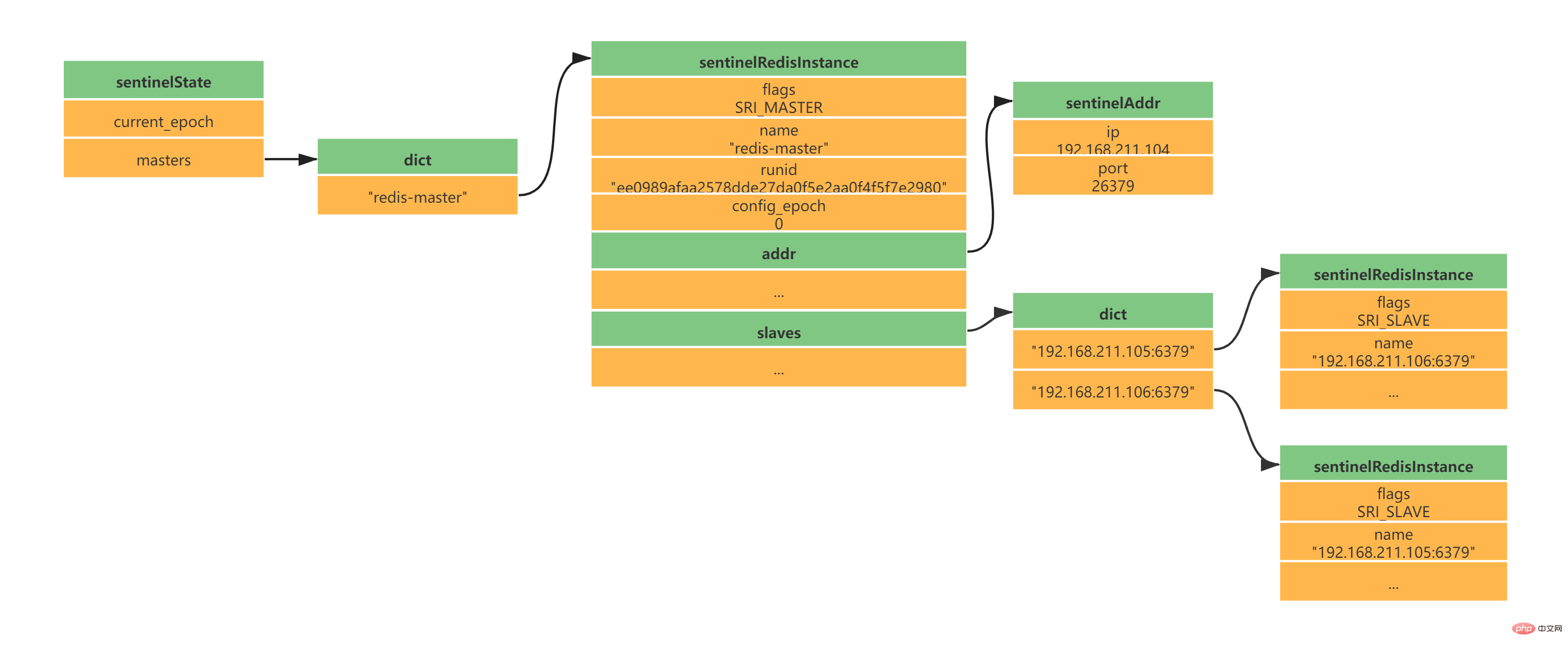
2.7 创建Sentinel之间的网络连接

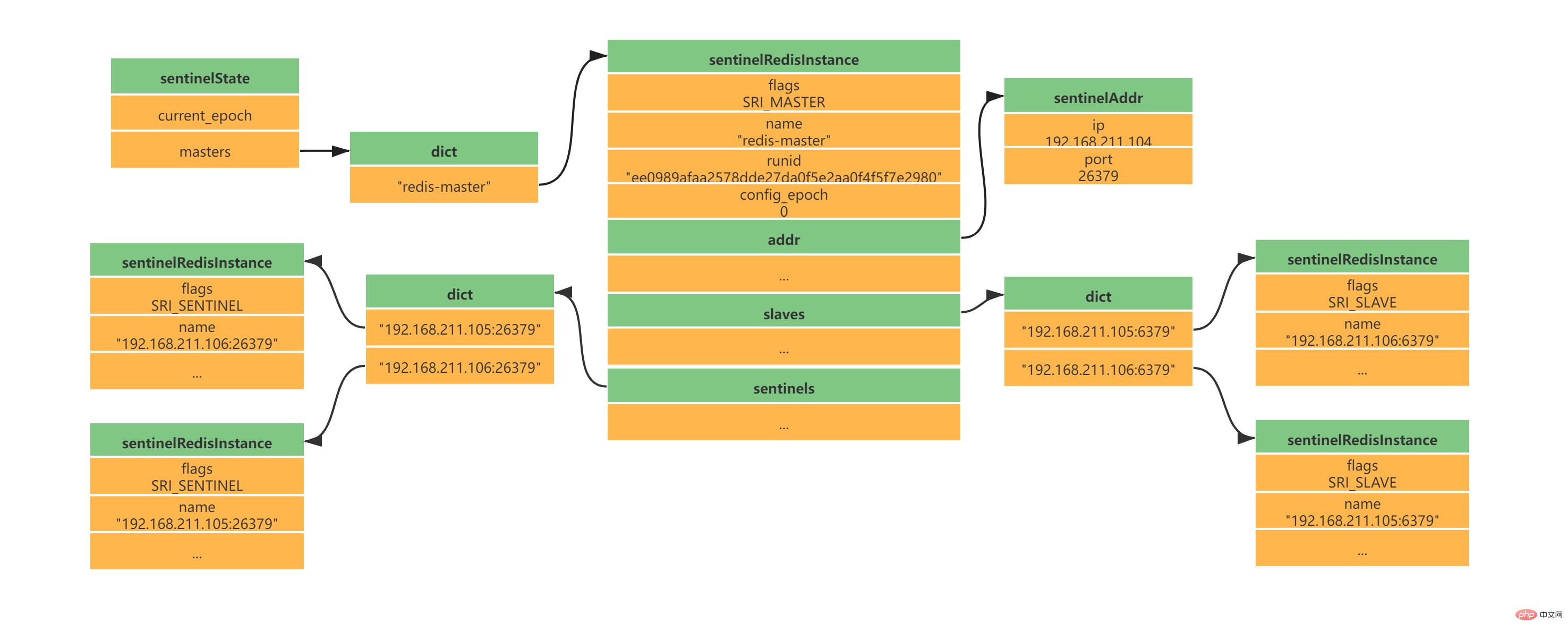
3、Sentinel工作
3.1 检测Master是否主观下线
sentinel down-after-milliseconds redis-master 30000

3.2 检测Master是否客观下线

SENTINEL is-master-down-by-addr <ip> <port> <current_epoch> <runid>
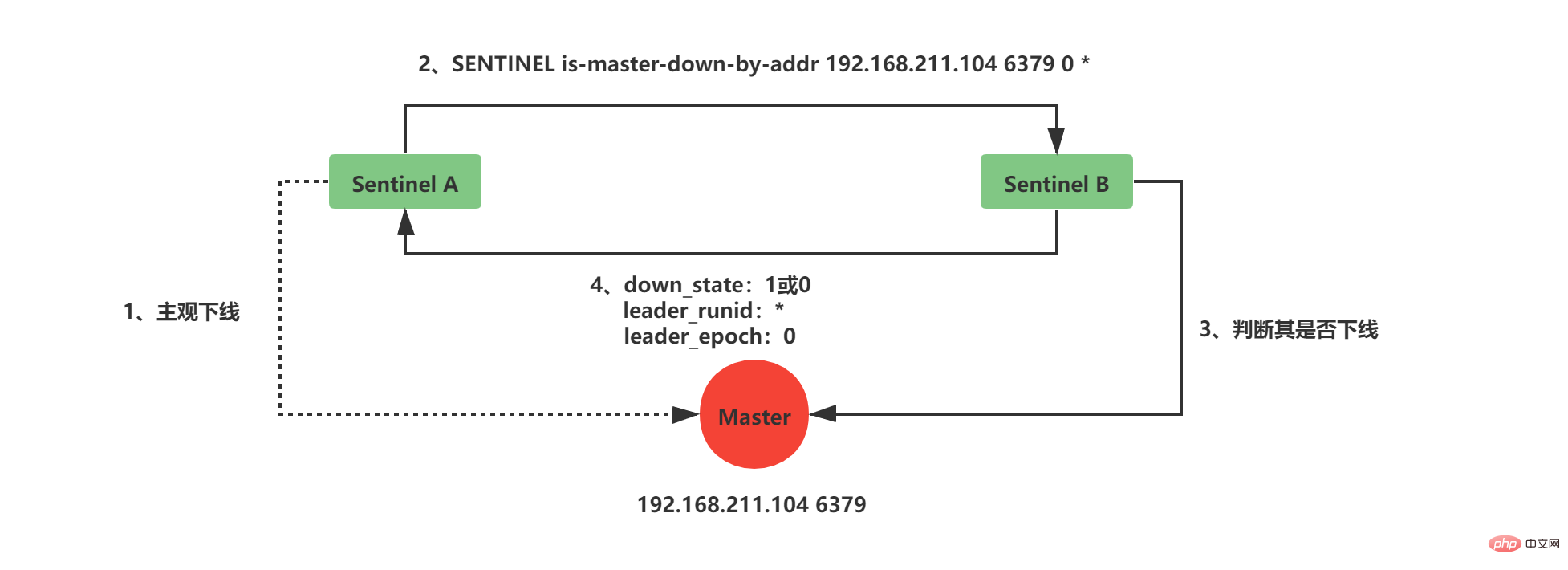
3.3 选举领头Sentinel
SENTINEL is-master-down-by-addr <ip> <port> <current_epoch> <runid>
3.4 故障转移
三、集群
1、简介
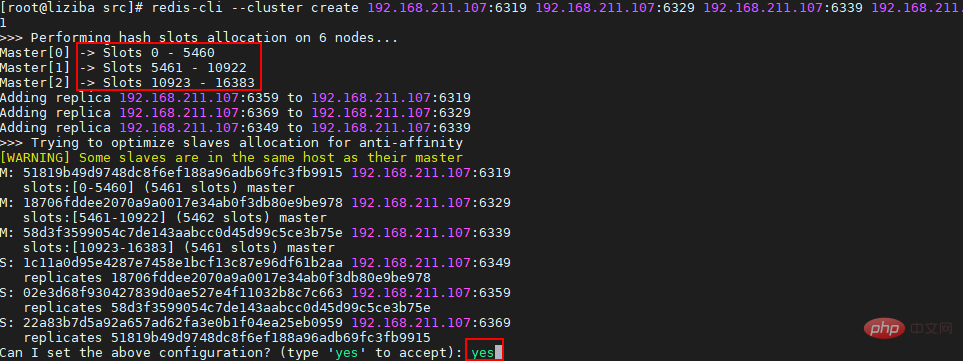
Nod<🎜>节点 IP 槽(slot)范围 Master[0] 192.168.211.107:6319 Slots 0 - 5460 Master[1] 192.168.211.107:6329 Slots 5461 - 10922 Master[2] 192.168.211.107:6339 Slots 10923 - 16383 Slave[0] 192.168.211.107:6369 Slave[1] 192.168.211.107:6349 Slave[2] 192.168.211.107:6359 <🎜>IP<🎜> <🎜>Julat slot<🎜> Guru [0] 192.168.211.107:6319 Slot 0 - 5460 Guru[ 1 192.168.211.107:6329 Slot 5461 - 10922 Master[2] 192.168.211.107:6339 Slot 10923 - 16383 Hamba[0] 192.168.211.107:6369
< /td>Hamba[1] 192.168.211.107:6349 Hamba[2] 192.168.211.107:6359 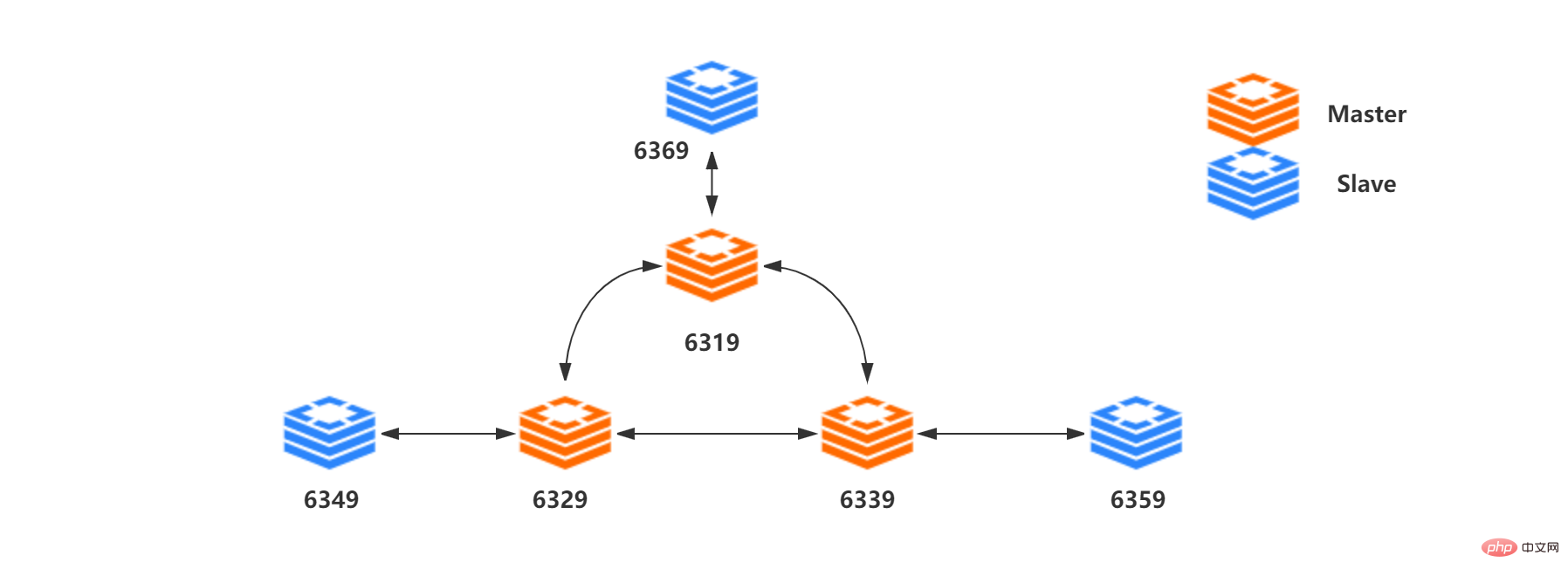
2、集群内部
2.1 clsuterNode
typedef struct clsuterNode {
// 创建时间
mstime_t ctime;
// 节点名字,由40位随机16进制的字符组成(与sentinel中讲的服务器运行id相同)
char name[REDIS_CLUSTER_NAMELEN];
// 节点标识,可以标识节点的角色和状态
// 角色 -> 主节点或从节点 例如:REDIS_NODE_MASTER(主节点) REDIS_NODE_SLAVE(从节点)
// 状态 -> 在线或下线 例如:REDIS_NODE_PFAIL(疑似下线) REDIS_NODE_FAIL(下线)
int flags;
// 节点配置纪元,用于故障转移,与sentinel中用法类似
// clusterState中的代表集群的配置纪元
unit64_t configEpoch;
// 节点IP地址
char ip[REDIS_IP_STR_LEN];
// 节点端口
int port;
// 连接节点的信息
clusterLink *link;
// 一个2048字节的二进制位数组
// 位数组索引值可能为0或1
// 数组索引i位置值为0,代表节点不负责处理槽i
// 数组索引i位置值为1,代表节点负责处理槽i
unsigned char slots[16384/8];
// 记录当前节点处理槽的数量总和
int numslots;
// 如果当前节点是从节点
// 指向当前从节点的主节点
struct clusterNode *slaveof;
// 如果当前节点是主节点
// 正在复制当前主节点的从节点数量
int numslaves;
// 数组——记录正在复制当前主节点的所有从节点
struct clusterNode **slaves;
} clsuterNode;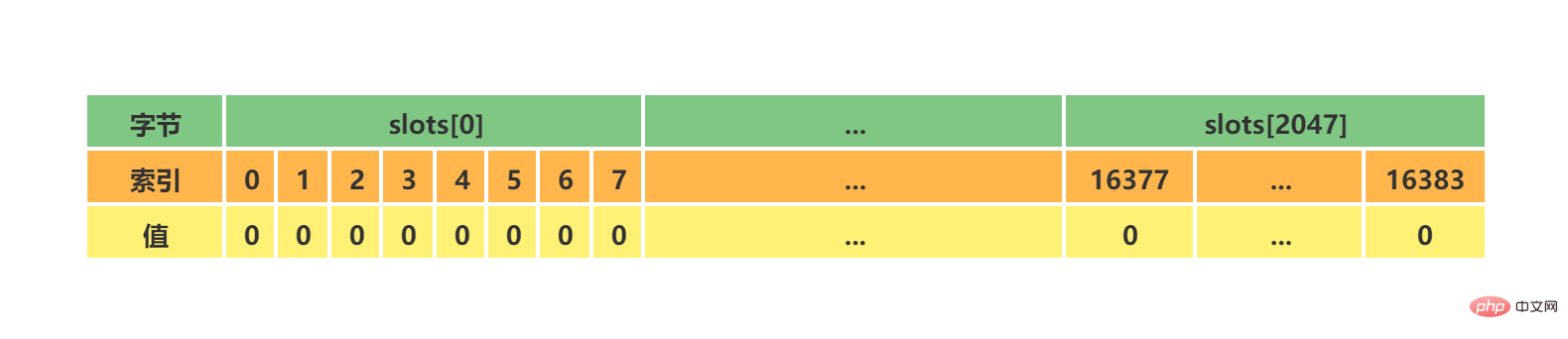

2.2 clusterLink
typedef struct clusterState {
// 连接创建时间
mstime_t ctime;
// TCP 套接字描述符
int fd;
// 输出缓冲区,需要发送给其他节点的消息缓存在这里
sds sndbuf;
// 输入缓冲区,接收打其他节点的消息缓存在这里
sds rcvbuf;
// 与当前clsuterNode节点代表的节点建立连接的其他节点保存在这里
struct clusterNode *node;
} clusterState;2.3 custerState
typedef struct clusterState {
// 当前节点指针,指向一个clusterNode
clusterNode *myself;
// 集群当前配置纪元,用于故障转移,与sentinel中用法类似
unit64_t currentEpoch;
// 集群状态 在线/下线
int state;
// 集群中处理着槽的节点数量总和
int size;
// 集群节点字典,所有clusterNode包括自己
dict *node;
// 集群中所有槽的指派信息
clsuterNode *slots[16384];
// 用于槽的重新分配——记录当前节点正在从其他节点导入的槽
clusterNode *importing_slots_from[16384];
// 用于槽的重新分配——记录当前节点正在迁移至其他节点的槽
clusterNode *migrating_slots_to[16384];
// ...
} clusterState;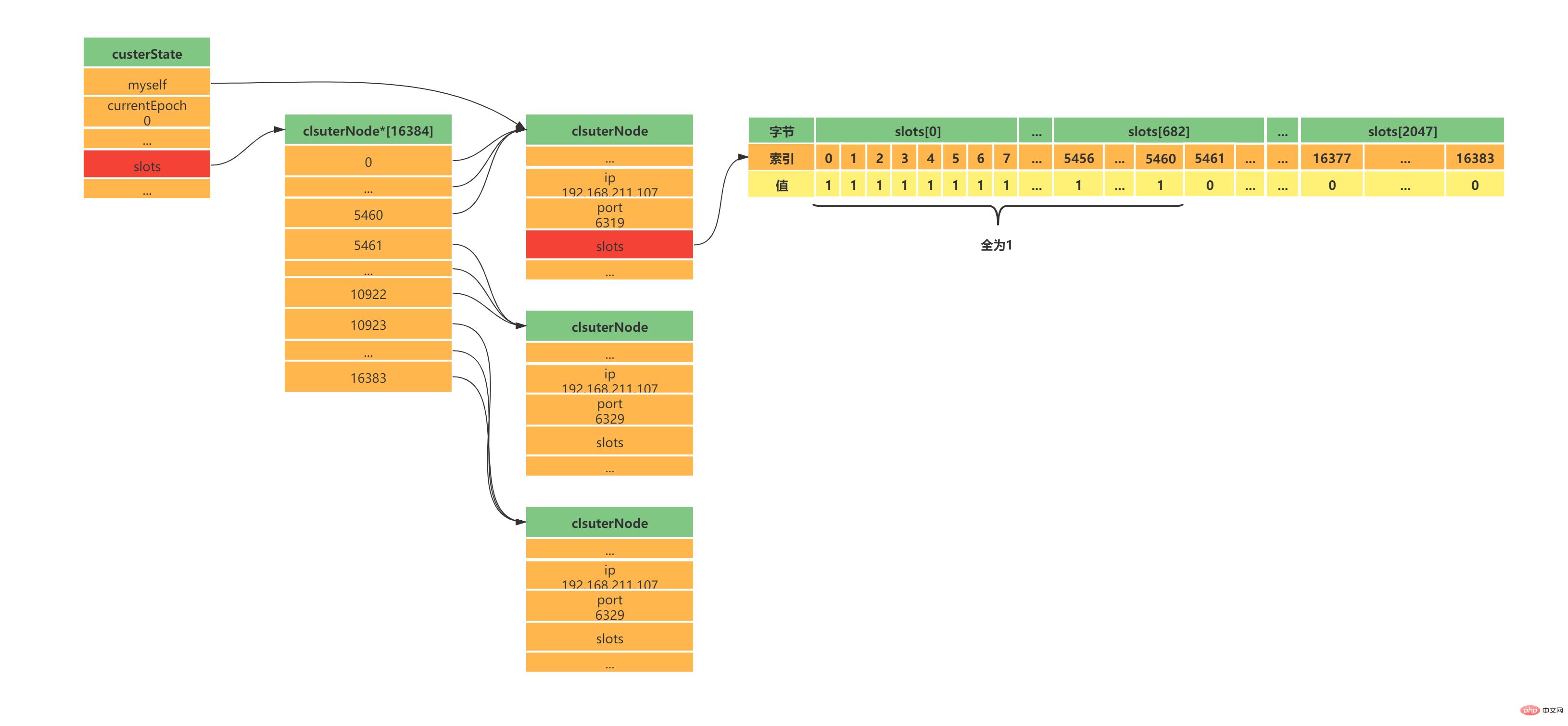
3. Kerja kelompok
3.1 Bagaimana untuk menetapkan slot?
3.2 Bagaimanakah ADDSLOTS dilaksanakan dalam kelompok Redis? Ini sebenarnya agak mudah Apabila kami menghantar arahan CLUSTER ADDSLOTS ke nod dalam kelompok Redis, nod semasa akan mula-mula mengesahkan melalui tatasusunan slot dalam clusterNyatakan sama ada slot yang diberikan kepada nod semasa belum. diberikan kepada Jika nod lain telah ditetapkan, pengecualian akan dilemparkan terus dan ralat akan dikembalikan kepada klien yang diberikan. Jika semua slot yang diberikan kepada nod semasa tidak diberikan kepada nod lain, nod semasa memperuntukkan slot tersebut kepada dirinya sendiri. Terdapat tiga langkah utama untuk tugasan: Kemas kini tatasusunan slot bagi clusterState, halakan slot yang ditentukan[i] ke clusterNode semasa
Sebelum memahami masalah ini, anda mesti terlebih dahulu mengetahui satu perkara Bagaimana kluster Redis mengira slot mana yang dimiliki oleh kunci semasa? Menurut pengenalan di tapak web rasmi, Redis sebenarnya tidak menggunakan algoritma cincang yang konsisten Sebaliknya, setiap kunci yang diminta disemak oleh CRC16 dan kemudian modulo 16384 diambil untuk menentukan slot mana untuk meletakkannya.
Nod mengembalikan pengalihan MOVED. ralat kepada klien. Kunci yang dikira akan diproses dengan betul dalam ralat pengalihan MOVED Ip dan port clusterNode dikembalikan kepada klien
Soalan ini sebenarnya merangkumi banyak masalah, seperti mengalih keluar nod tertentu dalam gugusan Redis, menambah nod, dsb. Ia boleh diringkaskan sebagai mengalihkan slot cincang dari satu nod ke nod lain. Dan perkara yang sangat menarik tentang gugusan Redis ialah ia menyokong peruntukan dalam talian (tanpa henti), yang secara rasminya dikatakan sebagai konfigurasi semula dalam talian berkelompok (konfigurasi semula secara langsung). Sebelum melaksanakannya, mari kita lihat arahan KLUSTER Sebaik sahaja anda mengetahui arahannya, anda akan dapat mengendalikannya: SLOT TAMBAHAN KLUSTER slot1 [slot2. ] … [slotN]3.5 如果客户端访问的key所属的槽正在迁移怎么办?

typedef struct clusterState {
// ...
// 用于槽的重新分配——记录当前节点正在从其他节点导入的槽
clusterNode *importing_slots_from[16384];
// 用于槽的重新分配——记录当前节点正在迁移至其他节点的槽
clusterNode *migrating_slots_to[16384];
// ...
} clusterState;

4. Kegagalan kelompok
 Apa yang diedarkan
Apa yang diedarkan
 Perbezaan antara perkhidmatan teragih dan mikro
Perbezaan antara perkhidmatan teragih dan mikro
 Perisian pangkalan data yang biasa digunakan
Perisian pangkalan data yang biasa digunakan
 Apakah pangkalan data dalam memori?
Apakah pangkalan data dalam memori?
 Yang manakah mempunyai kelajuan bacaan yang lebih pantas, mongodb atau redis?
Yang manakah mempunyai kelajuan bacaan yang lebih pantas, mongodb atau redis?
 Cara menggunakan redis sebagai pelayan cache
Cara menggunakan redis sebagai pelayan cache
 Bagaimana redis menyelesaikan ketekalan data
Bagaimana redis menyelesaikan ketekalan data
 Bagaimanakah mysql dan redis memastikan konsistensi penulisan dua kali?
Bagaimanakah mysql dan redis memastikan konsistensi penulisan dua kali?










![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



