
 Operasi dan penyelenggaraan
operasi dan penyelenggaraan linux
Bagaimana untuk memasang hadoop dalam linux
Operasi dan penyelenggaraan
operasi dan penyelenggaraan linux
Bagaimana untuk memasang hadoop dalam linux
Bagaimana untuk memasang hadoop dalam linux

Cara memasang Hadoop pada Linux: 1. Pasang perkhidmatan ssh; 2. Gunakan ssh untuk log masuk tanpa pengesahan kata laluan; 4. Buka zip pakej pemasangan Hadoop; fail Hadoop Just yang sepadan.

Persekitaran pengendalian artikel ini: sistem ubuntu 16.04, Hadoop versi 2.7.1, komputer Dell G3.
Bagaimana untuk memasang hadoop dalam linux?
[Data Besar] Penjelasan terperinci tentang memasang Hadoop (2.7.1) dan menjalankan WordCount di bawah Linux
1 Selepas mengkonfigurasi persekitaran Storm, saya ingin memikirkan pemasangan Hadoop Terdapat banyak tutorial di Internet, tetapi tiada satu pun yang sesuai, jadi saya masih menghadapi banyak masalah semasa proses pemasangan , saya akhirnya menyelesaikannya. Soalan itu masih terasa baik.
Persekitaran konfigurasi mesin ini adalah seperti berikut: Hadoop (2.7.1) Ubuntu Linux (sistem 64-bit) Yang berikut terbahagi kepada beberapa langkah Mari jelaskan proses konfigurasi secara terperinci.2. Pasang perkhidmatan ssh
Masukkan arahan shell dan masukkan arahan berikut untuk menyemak sama ada perkhidmatan ssh telah dipasang, gunakan arahan berikut untuk memasangnya:
Proses pemasangan agak mudah dan menyeronokkan. sudo apt-get install ssh openssh-server
3. Gunakan ssh untuk log masuk pengesahan tanpa kata laluan
1. Cipta ssh-key Di sini kita menggunakan kaedah rsa dan gunakan arahan berikut:
2. Grafik yang dipaparkan ialah kata laluannya ssh-keygen -t rsa -P ""
3. Kemudian anda boleh. log masuk tanpa pengesahan kata laluan. Seperti berikut: cat ~/.ssh/id_rsa.pub >> authorized_keys(好像是可以省略的)
Tangkapan skrin yang berjaya adalah seperti berikut: ssh localhost
 4 . Muat turun pakej pemasangan Hadoop
4 . Muat turun pakej pemasangan Hadoop
Terdapat dua cara untuk memuat turun dan memasang Hadoop
1. Pergi terus ke tapak web rasmi untuk memuat turun, http://mirrors.hust.edu .cn/apache/hadoop/core/stable/hadoop-2.7.1 .tar.gz 2. Gunakan shell untuk memuat turun, arahannya adalah seperti berikut: Akhirnya muat turun selesai .5. Nyahmampat pakej pemasangan Hadoop wget http://mirrors.hust.edu.cn/apache/hadoop/core/stable/hadoop-2.7.1.tar.gz
Gunakan arahan berikut untuk menyahmampat pakej pemasangan Hadoop
tar -zxvf hadoop-2.7.1. tar. gz Selepas penyahmampatan selesai, folder hadoop2.7.1 muncul
6. Konfigurasikan fail yang sepadan dalam HadoopFail yang memerlukan yang akan dikonfigurasikan adalah seperti berikut, hadoop-env.sh, core-site.xml, mapred-site.xml.template, hdfs-site.xml, semua fail terletak di bawah hadoop2.7.1/etc/hadoop adalah seperti berikut:
1.core-site.xml dikonfigurasikan seperti berikut:
Laluan hadoop.tmp.dir boleh ditetapkan mengikut tabiat anda sendiri. 2.mapred-site.xml.template dikonfigurasikan seperti berikut:<configuration> <property> <name>hadoop.tmp.dir</name> <value>file:/home/leesf/program/hadoop/tmp</value> <description>Abase for other temporary directories.</description> </property> <property> <name>fs.defaultFS</name> <value>hdfs://localhost:9000</value> </property> </configuration>
Di mana dfs.namenode Laluan .name.dir dan dfs.datanode.data.dir boleh ditetapkan secara bebas, sebaik-baiknya di bawah direktori hadoop.tmp.dir.
<configuration> <property> <name>mapred.job.tracker</name> <value>localhost:9001</value> </property> </configuration>
<configuration> <property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>file:/home/leesf/program/hadoop/tmp/dfs/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:/home/leesf/program/hadoop/tmp/dfs/data</value> </property> </configuration>
Selepas konfigurasi selesai, jalankan hadoop.
1. Mulakan sistem HDFS Gunakan arahan berikut dalam direktori hadop2.7.1:
Tangkapan skrin adalah seperti berikut:bin/hdfs namenode -format

dan  daemon
daemon
Gunakan arahan berikut untuk membuka:
NameNode 3. Lihat maklumat proses DataNode
sbin/start-dfs.sh,成功的截图如下:
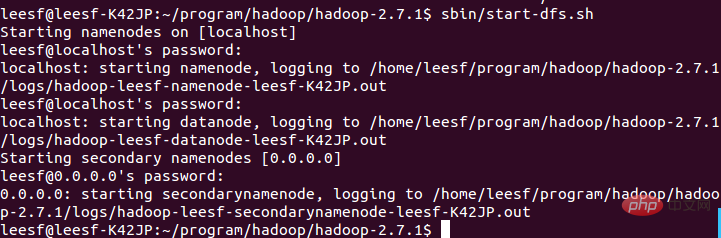 Mewakili data DataNode dan NameNode telah dimulakan
Mewakili data DataNode dan NameNode telah dimulakan
4. Lihat UI Web
Masukkan http://localhost:50070 dalam penyemak imbas untuk melihat maklumat yang berkaitan adalah seperti berikut:
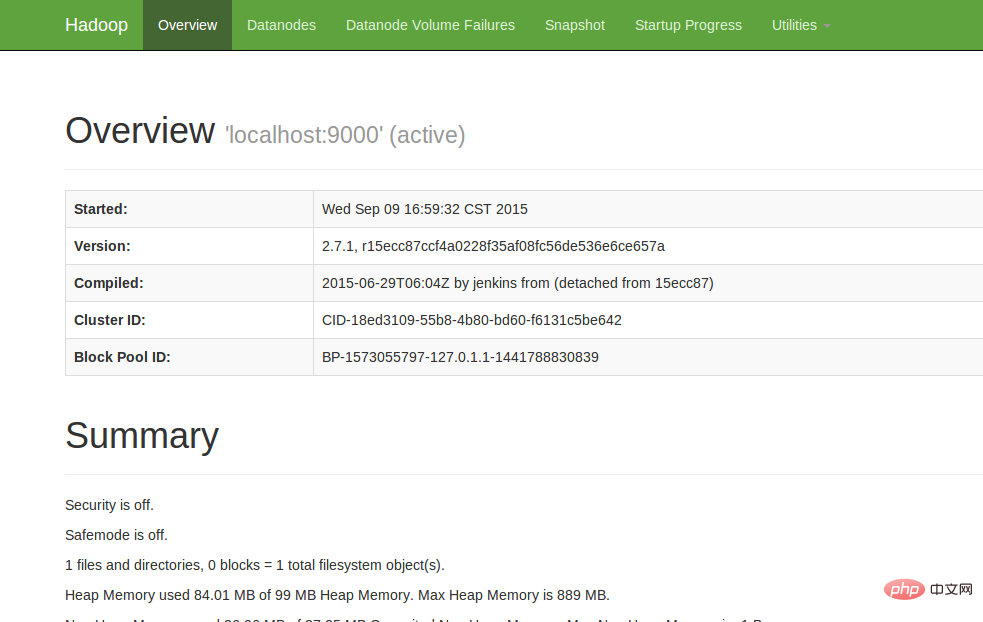
Pada ketika ini, persekitaran hadoop telah disediakan. Mari mulakan menggunakan hadoop untuk menjalankan contoh WordCount.
8. Jalankan WordCount Demo
1. Buat fail baharu secara setempat Pengarang mencipta dokumen perkataan baharu dalam direktori home/leesf kandungan yang anda suka.
2. Cipta folder baharu dalam HDFS untuk memuat naik dokumen perkataan tempatan Masukkan arahan berikut dalam direktori hadoop2.7.1:
bin/hdfs dfs -mkdir /test, bermaksud Direktori ujian. telah dicipta dalam direktori root hdfs
Gunakan arahan berikut untuk melihat struktur direktori dalam direktori root HDFS
bin/hdfs dfs -ls /
Tangkapan skrin khusus Seperti berikut:

Ini bermakna direktori ujian telah dibuat dalam direktori akar HDFS
3. Muat naik dokumen perkataan tempatan ke direktori ujian
Gunakan arahan berikut untuk memuat naik:
bin/hdfs dfs -put /home/leesf/words /test/
Gunakan arahan berikut untuk melihat
bin/ hdfs dfs -ls /test/
Tangkapan skrin keputusan adalah seperti berikut:

 Tangkapan skrin adalah seperti berikut:
Tangkapan skrin adalah seperti berikut:
Sudah ada direktori fail bernama Out di bawah
Masukkan arahan berikut untuk melihat fail dalam direktori out:
bin/hdfs dfs -ls /test/out, tangkapan skrin keputusan adalah seperti berikut:

Menunjukkan bahawa ia telah berjaya dijalankan dan hasilnya disimpan dalam bahagian-r-00000.
5. Semak hasil yang sedang dijalankan
Gunakan arahan berikut untuk menyemak hasil yang sedang dijalankan:
bin/hadoop fs -cat /test/out/part-r-00000 
Pada ketika ini, proses berjalan telah selesai.
9. Ringkasan Saya menghadapi banyak masalah semasa proses konfigurasi hadoop ini masih menyelesaikan masalah satu demi satu, konfigurasi berjaya, dan saya mendapat banyak saya ingin berkongsi pengalaman konfigurasi ini untuk kemudahan semua tukang kebun yang ingin mengkonfigurasi persekitaran Hadoop proses konfigurasi, sila berasa bebas untuk membincangkannya , terima kasih kerana menonton~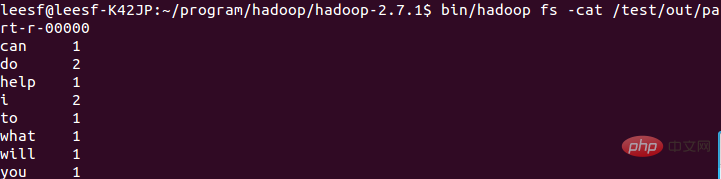
tutorial video linux
"Atas ialah kandungan terperinci Bagaimana untuk memasang hadoop dalam linux. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1381
1381
 52
52

 Perbezaan antara centos dan ubuntu
Apr 14, 2025 pm 09:09 PM
Perbezaan antara centos dan ubuntu
Apr 14, 2025 pm 09:09 PM
Perbezaan utama antara CentOS dan Ubuntu adalah: asal (CentOS berasal dari Red Hat, untuk perusahaan; Ubuntu berasal dari Debian, untuk individu), pengurusan pakej (CentOS menggunakan yum, yang memberi tumpuan kepada kestabilan; Ubuntu menggunakan APT, untuk kekerapan yang tinggi) Pelbagai tutorial dan dokumen), kegunaan (CentOS berat sebelah ke arah pelayan, Ubuntu sesuai untuk pelayan dan desktop), perbezaan lain termasuk kesederhanaan pemasangan (CentOS adalah nipis)
 Cara memasang centos
Apr 14, 2025 pm 09:03 PM
Cara memasang centos
Apr 14, 2025 pm 09:03 PM
Langkah Pemasangan CentOS: Muat turun Imej ISO dan Burn Bootable Media; boot dan pilih sumber pemasangan; Pilih susun atur bahasa dan papan kekunci; Konfigurasikan rangkaian; memisahkan cakera keras; Tetapkan jam sistem; Buat pengguna root; pilih pakej perisian; Mulakan pemasangan; Mulakan semula dan boot dari cakera keras selepas pemasangan selesai.
 CentOS berhenti penyelenggaraan 2024
Apr 14, 2025 pm 08:39 PM
CentOS berhenti penyelenggaraan 2024
Apr 14, 2025 pm 08:39 PM
CentOS akan ditutup pada tahun 2024 kerana pengedaran hulu, RHEL 8, telah ditutup. Penutupan ini akan menjejaskan sistem CentOS 8, menghalangnya daripada terus menerima kemas kini. Pengguna harus merancang untuk penghijrahan, dan pilihan yang disyorkan termasuk CentOS Stream, Almalinux, dan Rocky Linux untuk memastikan sistem selamat dan stabil.
 Penjelasan terperinci mengenai Prinsip Docker
Apr 14, 2025 pm 11:57 PM
Penjelasan terperinci mengenai Prinsip Docker
Apr 14, 2025 pm 11:57 PM
Docker menggunakan ciri -ciri kernel Linux untuk menyediakan persekitaran berjalan yang cekap dan terpencil. Prinsip kerjanya adalah seperti berikut: 1. Cermin digunakan sebagai templat baca sahaja, yang mengandungi semua yang anda perlukan untuk menjalankan aplikasi; 2. Sistem Fail Kesatuan (Unionfs) menyusun pelbagai sistem fail, hanya menyimpan perbezaan, menjimatkan ruang dan mempercepatkan; 3. Daemon menguruskan cermin dan bekas, dan pelanggan menggunakannya untuk interaksi; 4. Ruang nama dan cgroups melaksanakan pengasingan kontena dan batasan sumber; 5. Pelbagai mod rangkaian menyokong interkoneksi kontena. Hanya dengan memahami konsep -konsep teras ini, anda boleh menggunakan Docker dengan lebih baik.
 Pilihan Centos setelah menghentikan penyelenggaraan
Apr 14, 2025 pm 08:51 PM
Pilihan Centos setelah menghentikan penyelenggaraan
Apr 14, 2025 pm 08:51 PM
CentOS telah dihentikan, alternatif termasuk: 1. Rocky Linux (keserasian terbaik); 2. Almalinux (serasi dengan CentOS); 3. Ubuntu Server (Konfigurasi diperlukan); 4. Red Hat Enterprise Linux (versi komersial, lesen berbayar); 5. Oracle Linux (serasi dengan CentOS dan RHEL). Apabila berhijrah, pertimbangan adalah: keserasian, ketersediaan, sokongan, kos, dan sokongan komuniti.
 Apa yang Harus Dilakukan Setelah CentOs Berhenti Penyelenggaraan
Apr 14, 2025 pm 08:48 PM
Apa yang Harus Dilakukan Setelah CentOs Berhenti Penyelenggaraan
Apr 14, 2025 pm 08:48 PM
Selepas CentOS dihentikan, pengguna boleh mengambil langkah -langkah berikut untuk menanganinya: Pilih pengedaran yang serasi: seperti Almalinux, Rocky Linux, dan CentOS Stream. Berhijrah ke pengagihan komersial: seperti Red Hat Enterprise Linux, Oracle Linux. Menaik taraf ke CentOS 9 Stream: Pengagihan Rolling, menyediakan teknologi terkini. Pilih pengagihan Linux yang lain: seperti Ubuntu, Debian. Menilai pilihan lain seperti bekas, mesin maya, atau platform awan.
 Cara menggunakan desktop docker
Apr 15, 2025 am 11:45 AM
Cara menggunakan desktop docker
Apr 15, 2025 am 11:45 AM
Bagaimana cara menggunakan desktop Docker? Docktop Docktop adalah alat untuk menjalankan bekas Docker pada mesin tempatan. Langkah -langkah untuk digunakan termasuk: 1. Pasang desktop Docker; 2. Mulakan desktop Docker; 3. Buat imej Docker (menggunakan Dockerfile); 4. Membina imej Docker (menggunakan Docker Build); 5. Jalankan bekas Docker (menggunakan Docker Run).
 Konfigurasi komputer apa yang diperlukan untuk vscode
Apr 15, 2025 pm 09:48 PM
Konfigurasi komputer apa yang diperlukan untuk vscode
Apr 15, 2025 pm 09:48 PM
Keperluan Sistem Kod Vs: Sistem Operasi: Windows 10 dan ke atas, MACOS 10.12 dan ke atas, pemproses pengedaran Linux: minimum 1.6 GHz, disyorkan 2.0 GHz dan ke atas memori: minimum 512 MB, disyorkan 4 GB dan ke atas ruang penyimpanan: minimum 250 mb, disyorkan 1 GB dan di atas keperluan lain:
