

Artikel ini membawa anda pengetahuan tentang penciptaan dan penggunaan indeks dalam Oracle, saya harap ia akan membantu anda.

Penciptaan indeks sistem OLTP
1 Dengan mencipta indeks yang unik, keunikan setiap baris data dalam jadual pangkalan data boleh dijamin.
2. Ia boleh mempercepatkan pengambilan data, yang juga merupakan sebab utama untuk mencipta indeks.
3. Ia boleh mempercepatkan sambungan antara jadual, yang amat bermakna dalam mencapai integriti rujukan data.
4 Apabila menggunakan klausa pengumpulan dan pengisihan untuk mendapatkan data, masa untuk mengumpulkan dan mengisih dalam pertanyaan juga boleh dikurangkan dengan ketara.
5. Dengan menggunakan indeks, anda boleh menggunakan penyembunyi pengoptimuman semasa proses pertanyaan untuk meningkatkan prestasi sistem
1) Pada lajur yang sering perlu dicari, ia boleh mempercepatkan carian; dalam struktur susunan jadual;
3) Dalam lajur yang sering digunakan dalam sambungan, lajur ini adalah kunci asing, yang boleh mempercepatkan sambungan; selalunya perlu untuk mencari berdasarkan julat Buat indeks pada lajur, kerana indeks telah diisih, dan julat yang ditentukan adalah berterusan; indeks telah diisih, supaya pertanyaan boleh mengambil kesempatan daripada pengisihan indeks, Mempercepatkan masa pertanyaan mengisih; daripada syarat.
2. Ciri-ciri lajur yang tidak boleh diindeks
1) Indeks tidak boleh dibuat untuk lajur yang jarang digunakan atau dirujuk dalam pertanyaan. Ini kerana, memandangkan lajur ini jarang digunakan, pengindeksan atau tidak pengindeksan tidak meningkatkan kelajuan pertanyaan. Sebaliknya, disebabkan penambahan indeks, kelajuan penyelenggaraan sistem dikurangkan dan keperluan ruang meningkat.
2) Indeks tidak boleh dinaikkan untuk lajur dengan sedikit nilai data. Ini kerana, memandangkan lajur ini mempunyai nilai yang sangat sedikit, seperti lajur jantina jadual kakitangan, dalam hasil pertanyaan, baris data dalam set hasil mengambil kira sebahagian besar baris data dalam jadual, iaitu, data yang perlu dicari dalam jadual Perkadaran baris adalah besar. Meningkatkan indeks tidak secara signifikan mempercepatkan pencarian semula.
3) Indeks tidak boleh ditambahkan pada lajur yang ditakrifkan sebagai jenis data gumpalan. Ini kerana volum data lajur ini sama ada agak besar atau mempunyai nilai yang sangat sedikit.
Sintaks penciptaan indeks
Arahan berkaitan1) UNIK: Tentukan UNIK sebagai a indeks nilai unik, BITMAP ialah indeks bitmap, jika ditinggalkan ia adalah indeks B-Tree. 2)CREATEUNIUQE | BITMAP INDEX <schema>.<index_name> ON <schema>.<table_name> (<column_name> | <expression> ASC | DESC, <column_name> | <expression> ASC | DESC,...) TABLESPACE <tablespace_name> STORAGE <storage_settings> LOGGING | NOLOGGING COMPUTE STATISTICS NOCOMPRESS | COMPRESS<nn> NOSORT | REVERSE PARTITION | GLOBAL PARTITION<partition_setting>
5) LOGGING |. NOLOGGING: Sama ada Hasilkan semula log untuk indeks (cuba gunakan NOLOGGING untuk jadual besar untuk mengurangkan ruang dan meningkatkan kecekapan)
6) KOMPUTESTATISTIK: kumpulkan maklumat statistik semasa membuat yang baharu indeks
7) NOCOMPRESS | : NOSORT bermaksud mencipta indeks dalam susunan yang sama seperti dalam jadual, REVERSE bermaksud bertentangan Simpan nilai indeks secara berurutan
9) NOPARTITION: Indeks yang dibuat boleh dibahagikan pada jadual partition dan jadual tidak partition
Salah faham dalam penggunaan indeks
Indeks terhad
Menyekat pengindeksan adalah salah satu kesilapan yang sering dilakukan oleh pembangun yang tidak berpengalaman. Terdapat banyak perangkap dalam SQL yang boleh menyebabkan beberapa indeks tidak dapat digunakan. Beberapa masalah biasa dibincangkan di bawah:
1 Gunakan operator ketaksamaan (<>, !=)Pertanyaan berikut juga mempunyai Indeks lajur penilaian_kust, pernyataan pertanyaan masih melakukan imbasan jadual penuh.
Tukar pernyataan di atas kepada pernyataan pertanyaan berikut, supaya indeks akan digunakan apabila menggunakan pengoptimum berasaskan peraturan dan bukannya pengoptimum berasaskan kos (lebih pintar).Nota khas: Dengan menukar operator ketaksamaan kepada keadaan OR, anda boleh menggunakan indeks untuk mengelakkan imbasan jadual penuh.
2. Penggunaan IS NULL atau IS NOT NULLMenggunakan ISNULL atau ISNOT NULL juga akan mengehadkan penggunaan indeks. Kerana nilai NULL tidak ditakrifkan.
在 SQL语句中使用NULL会有很多的麻烦。因此建议开发人员在建表时,把需要索引的列设成NOT NULL。如果被索引的列在某些行中存在NULL值,就不会使用这个索引(除非索引是一个位图索引,关于位图索引在稍后在详细讨论)。
3、使用函数
如果不使用基于函数的索引,那么在 SQL语句的 WHERE子句中对存在索引的列使用函数时,会使优化器忽略掉这些索引。 下面的查询不会使用索引(只要它不是基于函数的索引)
select empno,ename,deptno from emp where trunc(hiredate)='01-MAY-81';
把上面的语句改成下面的语句,这样就可以通过索引进行查找。
select empno,ename,deptno from emp where hiredate<(to_date('01-MAY-81')+0.9999);
4、比较不匹配的数据类型
也是比较难于发现的性能问题之一。 注意下面查询的例子,account_number是一个VARCHAR2类型,在 account_number字段上有索引。
下面的语句将执行全表扫描:
select bank_name,address,city,state,zip from banks whereaccount_number = 990354;
Oracle 可以自动把 where子句变成to_number(account_number)=990354,这样就限
制了索引的使用,改成下面的查询就可以使用索引:
select bank_name,address,city,state,zip from banks where account_number='990354';
特别注意: 不匹配的数据类型之间比较会让Oracle自动限制索引的使用,即便对这个查询执行ExplainPlan也不能让您明白为什么做了一次―全表扫描。
5、查询索引
查 询 DBA_INDEXES视 图 可 得 到 表 中 所 有 索 引 的 列表 , 注 意 只 能 通 过USER_INDEXES的方法来检索模式(schema)的索引。访问 USER_IND_COLUMNS视图可得到一个给定表中被索引的特定列。
6、 组合索引
当某个索引包含有多个已索引的列时,称这个索引为组合(concatented)索引。在Oracle9i引入跳跃式扫描的索引访问方法之前,查询只能在有限条件下使用该索引。比如:表 emp 有一个组合索引键,该索引包含了 empno、 ename和 deptno。在Oracle9i之前除非在 where之句中对第一列(empno)指定一个值,否则就不能使用这个索引键进行一次范围扫描。
特别注意:在Oracle9i之前,只有在使用到索引的前导索引时才可以使用组合索引
Oracle提供了大量索引选项。知道在给定条件下使用哪个选项对于一个应用程序的性能来说非常重要。一个错误的选择可能会引发死锁,并导致数据库性能急剧下降或进程终止。而如果做出正确的选择,则可以合理使用资源,使那些已经运行了几个小时甚至几天的进程在几分钟得以完成,下面就将简单的讨论每个索引选项。
在这里讨论如下的索引类型:
B树索引(默认类型)
位图索引
HASH索引
索引组织表索引
反转键(reverse key)索引
基于函数的索引
分区索引(本地和全局索引)
位图连接索引
B树索引在Oracle中是一个通用索引。在创建索引时它就是默认的索引类型。B树索引可以是一个列的(简单)索引,也可以是组合/复合(多个列)的索引。B树索引最多可以包括32列。
在下图的例子中,B树索引位于雇员表的last_name列上。这个索引的二元高度为3;接下来,Oracle会穿过两个树枝块(branch block),到达包含有ROWID的树叶块。在每个树枝块中,树枝行包含链中下一个块的ID号。
树叶块包含了索引值、ROWID,以及指向前一个和后一个树叶块的指针。Oracle可以从两个方向遍历这个二叉树。B树索引保存了在索引列上有值的每个数据行的ROWID值。Oracle不会对索引列上包含NULL值的行进行索引。如果索引是多个列的组合索引,而其中列上包含NULL值,这一行就会处于包含NULL值的索引列中,且将被处理为空(视为NULL)
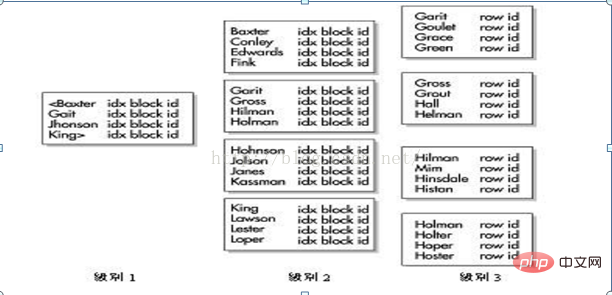
技巧:索引列的值都存储在索引中。因此,可以建立一个组合(复合)索引,这些索引可以直接满足查询,而不用访问表。这就不用从中检索数据,从而减少了I/O量。
B-tree特点:
适合与大量的增、删、改(OLTP)
不能用包含OR操作符的查询;
适合高基数的列(唯一值多)
典型的树状结构;
每个结点都是数据块;
大多都是物理上一层、两层或三层不定,逻辑上三层;
叶子块数据是排序的,从左向右递增;
在分支块和根块中放的是索引的范围;
位图索引
位图索引非常适合于决策支持系统(Decision Support System,DSS)和数据仓库,它们不应该用于通过事务处理应用程序访问的表。它们可以使用较少到中等基数(不同值的数量)的列访问非常大的表。
尽管位图索引最多可达30个列,但通常它们都只用于少量的列。
例如,您的表可能包含一个称为Sex的列,它有两个可能值:男和女。这个基数只为2,如果用户频繁地根据Sex列的值查询该表,这就是位图索引的基列。当一个表内包含了多个位图索引时,您可以体会到位图索引的真正威力。如果有多个可用的位图索引,Oracle就可以合并从每个位图索引得到的结果集,快速删除不必要的数据。
Bitmapt特点:
适合与决策支持系统;做 UPDATE代价非常高
非常适合 OR操作符的查询;基数比较少的时候才能建位图索引;
技巧:对于有较低基数的列需要使用位图索引。性别列就是这样一个例子,它有两个可能值:男或女(基数仅为2)。位图对于低基数(少量的不同值)列来说非常快,这是因为索引的尺寸相对于B树索引来说小了很多。因为这些索引是低基数的 B 树索引,所以非常小,因此您可以经常检索表中超过半数的行,并且仍使用位图索引。
当大多数条目不会向位图添加新的值时,位图索引在批处理(单用户)操作中加载表(插入操作)方面通常要比B树做得好。当多个会话同时向表中插入行时不应该使用位图索引,在大多数事务处理应用程序中都会发生这种情况。
示例
下面来看一个示例表PARTICIPANT,该表包含了来自个人的调查数据。列Age_Code、Income_Level、Education_Level和Marital_Status都包括了各自的位图索引。 下图显示了每个直方图中的数据平衡情况,以及对访问每个位图索引的查询的执行路径。图中的执行路径显示了有多少个位图索引被合并,可以看出性能得到了显著的提高。

如上图图所示,优化器依次使用4个单独的位图索引,这些索引的列在WHERE子句中被引用。每个位图记录指针(例如0或1),用于示表中的哪些行包含位图中的已知值。有了这些信息后,Oracle就执行BITMAP AND操作以查找将从所有4个位图中返回哪些行。该值然后被转换为ROWID值,并且查询继续完成剩余的处理工作。注意,所有4个列都有非常低的基数,使用索引可以非常快速地返回匹配的行。
技巧:在一个查询中合并多个位图索引后,可以使性能显著提高。位图索引使用固定长度的数据类型要比可变长度的数据类型好。较大尺寸的块也会提高对位图索引的存储和读取性能。
下面的查询可显示索引类型。
SQL> select index_name, index_type from user_indexes; INDEX_NAME INDEX_TYPE ------------------------------ ---------------------- TT_INDEX NORMAL IX_CUSTADDR_TP NORMAL
B 树索引作为NORMAL列出;而位图索引的类型值为BITMAP。
技巧:如果要查询位图索引列表,可以在USER_INDEXES视图中查询index_type列。
建议不要在一些联机事务处理(OLTP)应用程序中使用位图索引。B树索引的索引值中包含ROWID,这样Oracle就可以在行级别上锁定索引。位图索引存储为压缩的索引值,其中包含了一定范围的ROWID,因此Oracle必须针对一个给定值锁定所有范围内的ROWID
这种锁定类型可能在某些DML语句中造成死锁。SELECT语句不会受到这种锁定问题的影响。
位图索引的使用限制:
基于规则的优化器不会考虑位图索引。
当执行 ALTER TABLE语句并修改包含有位图索引的列时,会使位图索引失效。位图索引不包含任何列数据,并且不能用于任何类型的完整性检查。位图索引不能被声明为唯一索引。位图索引的最大长度为30。
Petua: Jangan gunakan indeks bitmap dalam persekitaran OLTP berat
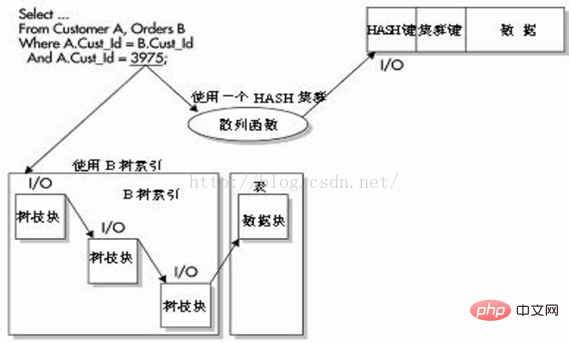
Menggunakan indeks HASH memerlukan penggunaan gugusan HASH. Apabila kluster atau kluster HASH ditubuhkan, kunci kluster juga ditakrifkan. Kunci ini memberitahu Oracle cara menyimpan jadual dalam kelompok. Apabila menyimpan data, semua baris yang berkaitan dengan kunci kluster ini disimpan pada blok pangkalan data.
Jika data semua disimpan pada blok pangkalan data yang sama, dan indeks HASH digunakan sebagai padanan tepat dalam klausa WHERE, Oracle boleh mengakses data dengan melaksanakan fungsi HASH dan I/O - bukannya menggunakan indeks B-tree dengan ketinggian binari 4 untuk mengakses data memerlukan 4 I/Os apabila mendapatkan semula data.
Seperti yang ditunjukkan dalam rajah di bawah, pertanyaan ialah pertanyaan yang setara untuk memadankan lajur HASH dan nilai yang tepat.
Oracle boleh menggunakan nilai ini dengan pantas untuk menentukan lokasi storan fizikal baris berdasarkan fungsi HASH.
Indeks HASH mungkin cara terpantas untuk mengakses data dalam pangkalan data, tetapi ia juga mempunyai kelemahannya sendiri. Bilangan nilai yang berbeza pada kunci kluster mesti diketahui sebelum membuat kluster HASH. Nilai ini perlu dinyatakan semasa membuat kluster HASH. Meremehkan bilangan nilai kunci kelompok yang berbeza boleh menyebabkan konflik kelompok (dua kunci kelompok dengan nilai cincang yang sama). Konflik seperti ini sangat intensif sumber. Konflik boleh menyebabkan penimbal yang digunakan untuk menyimpan baris tambahan melimpah, yang seterusnya menyebabkan I/O tambahan. Jika bilangan nilai cincang yang berbeza telah dipandang remeh, anda mesti menukar nilai ini selepas membina semula kluster.
Arahan ALTER CLUSTER tidak boleh menukar bilangan kekunci HASH. Kelompok HASH juga boleh membazir ruang. Jika anda tidak dapat menentukan jumlah ruang yang diperlukan untuk mengekalkan semua baris pada kunci kluster, anda mungkin membuang ruang. Jika ruang tambahan tidak boleh diperuntukkan untuk pertumbuhan kluster pada masa hadapan, kluster HASH mungkin bukan pilihan terbaik.
Penghimpunan HASH mungkin bukan pilihan terbaik jika aplikasi kerap melakukan imbasan jadual penuh pada jadual berkelompok. Imbasan jadual penuh boleh menjadi sangat intensif sumber kerana keperluan untuk memperuntukkan ruang yang tinggal dalam kelompok untuk pertumbuhan masa hadapan.
Berhati-hati sebelum melaksanakan kluster HASH. Anda perlu melihat aplikasi dengan teliti untuk memastikan anda memahami banyak tentang jadual dan data sebelum melaksanakan pilihan ini. Secara amnya, HASH sangat berkesan untuk beberapa data statik yang mengandungi nilai tersusun.
Petua: Indeks HASH sangat berguna apabila terdapat sekatan (perlu menentukan nilai tertentu dan bukannya julat nilai)
Organisasi indeks Jadual akan menukar struktur storan jadual kepada struktur B-tree dan mengisih mengikut kunci utama jadual. Jadual khas ini, seperti jenis jadual lain, boleh melaksanakan semua pernyataan DML dan DDL pada jadual. Disebabkan oleh struktur khas jadual, ROWID tidak dikaitkan dengan baris jadual.
Untuk beberapa kenyataan yang melibatkan padanan tepat dan carian julat, jadual tersusun indeks menyediakan mekanisme capaian data berasaskan kunci yang pantas. Prestasi penyataan KEMASKINI dan PADAM berdasarkan nilai kunci utama juga dipertingkatkan kerana baris disusun secara fizikal.
Memandangkan nilai lajur utama tidak diulang dalam jadual dan indeks, ruang yang diperlukan untuk penyimpanan juga dikurangkan. Jika data tidak akan ditanya dengan kerap terhadap lajur kunci utama, anda perlu membuat indeks sekunder pada lajur lain dalam jadual tersusun indeks. Aplikasi yang tidak kerap menanyakan jadual berdasarkan kunci utamanya tidak akan melihat faedah penuh menggunakan indeks untuk menyusun jadual. Untuk jadual yang sentiasa diakses melalui padanan tepat kunci utama atau imbasan julat, pertimbangkan untuk menggunakan indeks untuk menyusun jadual.
Petua: Anda boleh mencipta indeks sekunder pada jadual tersusun indeks.
Apabila memuatkan beberapa data yang diisih, indeks pasti akan mengalami beberapa kesesakan yang berkaitan dengan I/O. Semasa pemuatan data, beberapa bahagian indeks dan cakera pasti akan digunakan dengan lebih kerap daripada yang lain. Untuk menyelesaikan masalah ini, ruang jadual indeks boleh disimpan pada seni bina cakera yang boleh memisahkan fail secara fizikal merentas berbilang cakera.
Untuk menyelesaikan masalah ini, Oracle turut menyediakan kaedah untuk membalikkan indeks kunci. Jika data disimpan dengan indeks kunci terbalik, nilai data akan bertentangan dengan nilai yang disimpan pada asalnya. Dengan cara ini, data 1234, 1235 dan 1236 disimpan sebagai 4321, 5321 dan 6321. Hasilnya ialah indeks mengemas kini blok indeks yang berbeza untuk setiap baris yang baru dimasukkan.
Petua: Jika anda mempunyai kapasiti cakera yang terhad dan melakukan sejumlah besar beban tertib, anda boleh menggunakan pengindeksan kunci terbalik.
Anda tidak boleh menggunakan indeks kunci terbalik dengan indeks peta bit atau jadual tersusun indeks. Kerana indeks bitmap dan jadual tersusun indeks tidak boleh diterbalikkan dikunci.
Indeks berasaskan fungsi boleh dibuat pada jadual. Tanpa indeks berasaskan fungsi, sebarang pertanyaan yang melaksanakan fungsi pada lajur tidak boleh menggunakan indeks pada lajur tersebut. Sebagai contoh, pertanyaan berikut tidak boleh menggunakan indeks pada lajur JOB melainkan ia adalah indeks berasaskan fungsi:
select * from emp where UPPER(job) = 'MGR';
下面的查询使用 JOB列上的索引,但是它将不会返回JOB列具有Mgr或mgr值的行:
select * from emp where job = 'MGR';
可以创建这样的索引,允许索引访问支持基于函数的列或数据。可以对列表达式 UPPER(job)创建索引,而不是直接在JOB列上建立索引,如:
create index EMP$UPPER_JOB on emp(UPPER(job));尽管基于函数的索引非常有用,但在建立它们之前必须先考虑下面一些问题:
能限制在这个列上使用的函数吗?如果能,能限制所有在这个列上执行的所有函数吗?是否有足够应付额外索引的存储空间?在每列上增加的索引数量会对针对该表执行的DML语句的性能带来何种影响?
基于函数的索引非常有用,但在实现时必须小心。在表上创建的索引越多,INSERT、UPDATE和DELETE语句的执行就会花费越多的时间。
注意:对于优化器所使用的基于函数的索引来说,必须把初始参数QUERY_REWRITE _ ENABLED 设定为 TRUE。
示例:
select count(*) from sample where ratio(balance,limit) >.5; Elapsed time: 20.1 minutes create index ratio_idx1 on sample (ratio(balance, limit)); select count(*) from sample where ratio(balance,limit) >.5; Elapsed time: 7 seconds!!!
分区索引就是简单地把一个索引分成多个片断。通过把一个索引分成多个片断,可以访问更小的片断(也更快),并且可以把这些片断分别存放在不同的磁盘驱动器上(避免I/O问题)。
B树和位图索引都可以被分区,而HASH索引不可以被分区。可以有好几种分区方法:表被分区而索引未被分区;表未被分区而索引被分区;表和索引都被分区。
不管采用哪种方法,都必须使用基于成本的优化器。分区能够提供更多可以提高性能和可维护性的可能性有两种类型的分区索引:本地分区索引和全局分区索引。
每个类型都有两个子类型,有前缀索引和无前缀索引。表各列上的索引可以有各种类型索引的组合。如果使用了位图索引,就必须是本地索引。
把索引分区最主要的原因是可以减少所需读取的索引的大小,另外把分区放在不同的表空间中可以提高分区的可用性和可靠性。在使用分区后的表和索引时,Oracle还支持并行查询和并行DML。这样就可以同时执行多个进程,从而加快处理这条语句。
可以使用与表相同的分区键和范围界限来对本地索引分区。每个本地索引的分区只包含了它所关联的表分区的键和ROWID。本地索引可以是B树或位图索引。如果是 B树索引,它可以是唯一或不唯一的索引。
这种类型的索引支持分区独立性,这就意味着对于单独的分区,可以进行增加、截取、删除、分割、脱机等处理,而不用同时删除或重建索引。Oracle自动维护这些本地索引。本地索引分区还可以被单独重建,而其他分区不会受到影响。
(1) 有前缀的索引
有前缀的索引包含了来自分区键的键,并把它们作为索引的前导。例如,让我们再次回顾 participant表。在创建该表后,使用survey_id和survey_date这两个列进行范围分区,然后在survey_id列上建立一个有前缀的本地索引,如下图所示。这个索引的所有分区都被等价划分,就是说索引的分区都使用表的相同范围界限来创建。
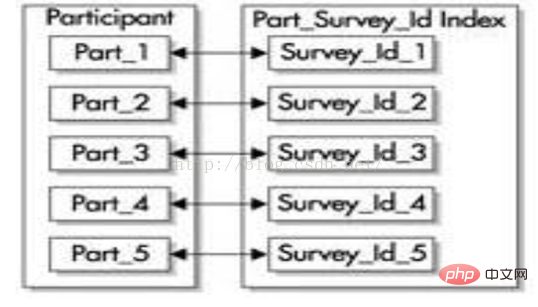
技巧:本地的有前缀索引可以让Oracle快速剔除一些不必要的分区。也就是说
没有包含 WHERE条件子句中任何值的分区将不会被访问,这样也提高了语句
的性能。
(2) Indeks tanpa awalan
Indeks tanpa awalan tidak menggunakan lajur utama kekunci partition sebagai lajur utama indeks. Jika anda menggunakan jadual partition yang sama dengan kunci partition yang sama (survey_id and survey_date), indeks yang dibina pada lajur survey_date ialah indeks tidak tetap tempatan, seperti yang ditunjukkan dalam rajah di bawah. Indeks
setempat tidak tetap boleh dibuat pada mana-mana lajur jadual, tetapi setiap partition indeks hanya mengandungi nilai kunci untuk partition jadual yang sepadan.
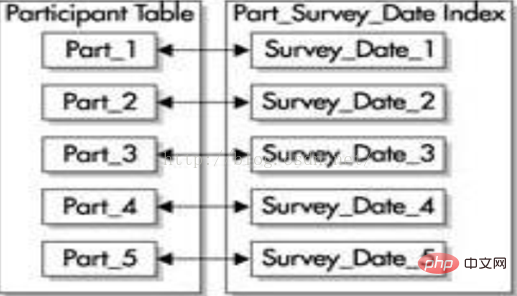
Jika anda ingin menetapkan indeks tidak tetap sebagai indeks unik, indeks ini mesti mengandungi subset kunci partition.
Dalam contoh ini, kita perlu menggabungkan tinjauan dan ( atau ) survey_id >Asalkan survey_id
bukan lajur pertama indeks, ia ialah indeks awalan ).
Untuk indeks tidak tetap yang unik, ia Mesti mengandungi subset kunci partition.
Indeks Pembahagian Global
(2) Indeks awalan Secara amnya, indeks awalan global tidak dipisahkan setara dalam jadual asas. Tiada apa-apa yang mengehadkan pembahagian rakan sebaya indeks, tetapi Oracle tidak memanfaatkan sepenuhnya pembahagian rakan sebaya apabila menjana pelan pertanyaan atau melaksanakan operasi penyelenggaraan partition. Jika indeks dipisahkan rakan sebaya, ia mesti dicipta sebagai indeks setempat supaya Oracle boleh mengekalkan indeks dan menggunakannya untuk mengalih keluar partition yang tidak perlu, seperti yang ditunjukkan dalam rajah di bawah. Dalam rajah ini, setiap satu daripada 3 partition indeks mengandungi entri indeks yang menghala ke baris dalam berbilang partition jadual.
分区的、全局有前缀索引 ( 2) 无前缀的索引 位图连接索引是基于两个表的连接的位图索引,在数据仓库环境中使用这种索引改进连接维度表和事实表的查询的性能。创建位图连接索引时,标准方法是 连接索引中常用的维度表和事实表。当用户在一次查询中结合查询事实表和维度表时,就不需要执行连接,因为在位图连接索引中已经有可用的连接结果。通过压缩位图连接索引中的ROWID进一步改进性能,并且减少访问数据所需的I/O数量。 创建位图连接索引时,指定涉及的两个表。相应的语法应该遵循如下模式: 位图连接的语法比较特别,其中包含 FROM子句和WHERE子句,并且引用两个单独的表。索引列通常是维度表中的描述列——就是说,如果维度是 CUSTOMER,并且它的主键是CUSTOMER_ID,则通常索引Customer_Name 这样的列。如果事实表名为 SALES,可以使用如下的命令创建索引: 如果用户接下来使用指定 Customer_Name列值的WHERE子句查询 SALES和CUSTOMER表,优化器就可以使用位图连接索引快速返回匹配连接 条件和 Customer_Name条件的行。 位图连接索引的使用一般会受到限制: 1) 只可以索引维度表中的列。 2) 用于连接的列必须是维度表中的主键或唯一约束;如果是复合主键,则 必须使用连接中的每一列。 3) 不可以对索引组织表创建位图连接索引,并且适用于常规位图索引的限 制也适用于位图连接索引。
注意:以上总结是对oracle数据库中索引创建的一些知识的介绍和关键点。需要读懂理解之后结合系统业务情况合理创建索引,以求达到预期性能。 本文部分内容摘自《Oracle超详细讲解.pdf》 推荐教程:《Oracle教程》 Atas ialah kandungan terperinci Penciptaan dan penggunaan indeks dalam Oracle (perkongsian ringkasan). Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!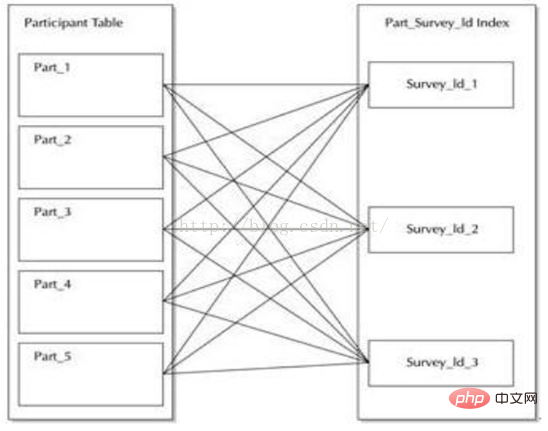
技巧:如果一个全局索引将被对等分区,就必须把它创建为一个本地索引,
这样 Oracle可以维护这个索引,并使用它来删除不必要的分区。
Oracle不支持无前缀的全局索引。位图连接索引
create bitmap index FACT_DIM_COL_IDX on FACT(DIM.Descr_Col) from
FACT, DIM where FACT.JoinCol = DIM.JoinCol;
create bitmap index SALES_CUST_NAME_IDX
on SALES(CUSTOMER.Customer_Name) from SALES, CUSTOMER
where SALES.Customer_ID=CUSTOMER.Customer_ID;
 Cara menghidupkan mod selamat Word
Cara menghidupkan mod selamat Word
 Pengenalan kepada penggunaan fungsi MySQL ELT
Pengenalan kepada penggunaan fungsi MySQL ELT
 Apa yang perlu dilakukan jika sambungan win8wifi tidak tersedia
Apa yang perlu dilakukan jika sambungan win8wifi tidak tersedia
 Cara menggunakan fungsi baris
Cara menggunakan fungsi baris
 Apakah yang termasuk platform e-dagang?
Apakah yang termasuk platform e-dagang?
 Cara mendaftar e-mel perniagaan
Cara mendaftar e-mel perniagaan
 Bagaimana untuk menyediakan memori maya
Bagaimana untuk menyediakan memori maya
 Bagaimana untuk membulatkan dalam Matlab
Bagaimana untuk membulatkan dalam Matlab
 penggunaan fungsi mul
penggunaan fungsi mul











![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



