
 pangkalan data
tutorial mysql
Kuasai sepenuhnya kemahiran pengindeksan mysql (perkongsian ringkasan)
pangkalan data
tutorial mysql
Kuasai sepenuhnya kemahiran pengindeksan mysql (perkongsian ringkasan)
Kuasai sepenuhnya kemahiran pengindeksan mysql (perkongsian ringkasan)

Artikel ini membawa anda pengetahuan yang berkaitan tentang indeks mysql, termasuk struktur logik pernyataan pelaksanaan mysql dan sql saya harap ia akan membantu anda.

1. Seni bina logik tiga peringkat MySQL
Seni bina enjin storan MySQL memisahkan pemprosesan pertanyaan daripada penyimpanan/pendapatan data. Berikut ialah gambar rajah seni bina logik MySQL:

1 Lapisan pertama bertanggungjawab untuk pengurusan sambungan, pengesahan kebenaran, keselamatan, dsb.
Setiap sambungan pelanggan sepadan dengan urutan pada pelayan. Kumpulan benang dikekalkan pada pelayan untuk mengelak daripada mencipta dan memusnahkan benang untuk setiap sambungan. Apabila pelanggan menyambung ke pelayan MySQL, pelayan mengesahkannya. Pengesahan boleh dilakukan melalui nama pengguna dan kata laluan, atau melalui sijil SSL. Selepas pengesahan log masuk diluluskan, pelayan juga akan mengesahkan sama ada klien mempunyai kuasa untuk melaksanakan pertanyaan tertentu.
2. Lapisan kedua bertanggungjawab untuk menghuraikan pertanyaan
menyusun SQL dan mengoptimumkannya (seperti melaraskan susunan bacaan jadual, memilih indeks yang sesuai, dsb. .). Untuk pernyataan SELECT, sebelum menghuraikan pertanyaan, pelayan akan menyemak cache pertanyaan terlebih dahulu Jika hasil pertanyaan yang sepadan boleh ditemui di dalamnya, hasil pertanyaan akan dikembalikan secara langsung tanpa memerlukan penghuraian pertanyaan, pengoptimuman, dsb. Prosedur tersimpan, pencetus, pandangan, dsb. semuanya dilaksanakan dalam lapisan ini.
3. Lapisan ketiga ialah enjin storan
Enjin storan bertanggungjawab untuk menyimpan data dalam MySQL, mengekstrak data, memulakan transaksi, dsb. Enjin storan berkomunikasi dengan lapisan atas melalui API ini melindungi perbezaan antara enjin storan yang berbeza, menjadikan perbezaan ini telus kepada proses pertanyaan lapisan atas. Enjin storan tidak akan menghuraikan SQL.
2. Perbandingan antara InnoDB dan MyISAM
1 Struktur storan
MyISAM: Setiap MyISAM disimpan sebagai tiga fail pada cakera. Ia adalah: fail definisi jadual, fail data dan fail indeks. Nama fail pertama bermula dengan nama jadual dan sambungan menunjukkan jenis fail. Fail .frm menyimpan takrif jadual. Sambungan fail data ialah .MYD (MYData). Sambungan fail indeks ialah .MYI (MYIndex).
InnoDB: Semua jadual disimpan dalam fail data yang sama (atau berbilang fail, atau fail ruang jadual bebas Saiz jadual InnoDB hanya dihadkan oleh saiz fail sistem pengendalian umumnya 2GB).
2. Ruang storan
MyISAM: MyISAM menyokong tiga format storan yang berbeza: jadual statik (lalai, tetapi ambil perhatian bahawa tidak boleh ada ruang di hujung data, ia akan dialih keluar ), jadual dinamik, jadual termampat. Selepas jadual dibuat dan data diimport, ia tidak akan diubah suai Anda boleh menggunakan jadual termampat untuk mengurangkan penggunaan ruang cakera.
InnoDB: Memerlukan lebih banyak memori dan storan, ia akan mewujudkan kumpulan penimbal khususnya sendiri dalam memori utama untuk menyimpan data dan indeks.
3. Kemudahalihan, sandaran dan pemulihan
MyISAM: Data disimpan dalam bentuk fail, jadi ia sangat mudah untuk pemindahan data merentas platform. Anda boleh melakukan operasi di atas meja secara individu semasa sandaran dan pemulihan.
InnoDB: Penyelesaian percuma termasuk menyalin fail data, menyandarkan binlog atau menggunakan mysqldump, yang agak menyakitkan apabila volum data mencapai berpuluh-puluh gigabait.
4. Sokongan Transaksi
MyISAM: Penekanan adalah pada prestasi, setiap pertanyaan adalah atom dan masa pelaksanaannya lebih cepat daripada jenis InnoDB, tetapi ia tidak menyediakan sokongan urus niaga.
InnoDB: Menyediakan sokongan transaksi, kunci asing dan fungsi pangkalan data lanjutan yang lain. Jadual selamat urus niaga (patuh ACID) dengan keupayaan transaksi (komit), gulung balik (balik semula) dan ranap sistem.
5. AUTO_INCREMENT
MyISAM: Anda boleh mencipta indeks bersama dengan medan lain. Lajur pertumbuhan automatik enjin mestilah indeks Jika ia adalah indeks gabungan, lajur pertumbuhan automatik tidak perlu menjadi lajur pertama Ia boleh diisih mengikut lajur sebelumnya dan kemudian ditambah.
InnoDB: InnoDB mesti mengandungi indeks dengan medan ini sahaja. Lajur pertumbuhan automatik enjin mestilah indeks, dan jika indeks komposit, lajur itu juga mesti menjadi lajur pertama indeks komposit.
6. Perbezaan kunci jadual
MyISAM: Hanya kunci peringkat jadual disokong Apabila pengguna mengendalikan jadual myisam, pilih, kemas kini, padam dan masukkan penyata akan semuanya ditugaskan secara automatik ke jadual Mengunci, jika jadual yang dikunci memenuhi konkurensi sisipan, data baharu boleh dimasukkan di hujung jadual.
InnoDB: Menyokong transaksi dan kunci peringkat baris ialah ciri terbesar innodb. Kunci baris meningkatkan prestasi operasi serentak berbilang pengguna. Walau bagaimanapun, kunci baris InnoDB hanya sah pada kunci utama WHERE Sebarang kunci bukan utama WHERE akan mengunci seluruh jadual.
7. Indeks teks penuh
MyISAM: menyokong indeks teks penuh jenis FULLTEXT
InnoDB: tidak menyokong indeks teks penuh jenis FULLTEXT , tetapi innodb boleh menggunakannya Pemalam sphinx menyokong pengindeksan teks penuh dan kesannya lebih baik.
8 Kunci utama jadual
MyISAM: Membenarkan jadual tanpa sebarang indeks dan kunci utama wujud.
InnoDB: Jika tiada kunci utama atau indeks unik bukan kosong ditetapkan, kunci utama 6 bait (tidak kelihatan kepada pengguna) akan dijana secara automatik Data adalah sebahagian daripada indeks utama, dan indeks tambahan menyimpannya nilai indeks utama.
9. Bilangan baris tertentu dalam jadual
MyISAM: Menyimpan jumlah baris dalam jadual Jika anda memilih count() daripada jadual; ia akan dibawa keluar terus nilai.
InnoDB: Jumlah bilangan baris dalam jadual tidak disimpan Jika anda menggunakan pilih count(*) daripada jadual, ia akan menggunakan banyak wang. selepas menambah syarat wehre, myisam dan innodb memprosesnya.
10. Operasi CRUD
MyISAM: Jika anda melakukan sejumlah besar PILIHAN, MyISAM ialah pilihan yang lebih baik.
InnoDB: Jika data anda melakukan banyak INSERT atau UPDATE, anda harus menggunakan jadual InnoDB atas sebab prestasi.
11 Kunci asing
MyISAM: Tidak disokong
InnoDB: Disokong
3
1. Dalam keadaan apakah pengoptimuman SQL harus dilakukan
Prestasi rendah, masa pelaksanaan terlalu lama, masa menunggu terlalu lama, pertanyaan sambungan dan kegagalan indeks.2. Proses pelaksanaan pernyataan SQL
(1) Proses penulisanselect distinct ... from ... join ... on ... where ... group by ... having ... order by ... limit ...
from ... on ... join ... where ... group by ... having ... select distinct ... order by ... limit ...
3. Pengoptimuman SQL adalah untuk mengoptimumkan indeks
Indeks adalah bersamaan dengan jadual kandungan buku. Struktur data indeks ialah pokok B. 4. Indeks1. Kelebihan indeks
(1) Meningkatkan kecekapan pertanyaan (mengurangkan penggunaan IO) ( 2) Kurangkan penggunaan CPUContohnya, susunan pertanyaan mengikut desc umur, kerana pokok indeks B itu sendiri diisih, jadi jika indeks dicetuskan oleh pertanyaan, tidak perlu bertanya lagi.2. Kelemahan indeks
(1) Indeks itu sendiri besar dan boleh disimpan dalam memori atau pada cakera keras, biasanya pada cakera keras. (2) Indeks tidak digunakan dalam semua situasi, seperti ① sejumlah kecil data ② medan yang kerap bertukar ③ medan yang jarang digunakan (3) Indeks akan mengurangkan kecekapan penambahan, pemadaman dan pengubahsuaian
3 Pengelasan indeks
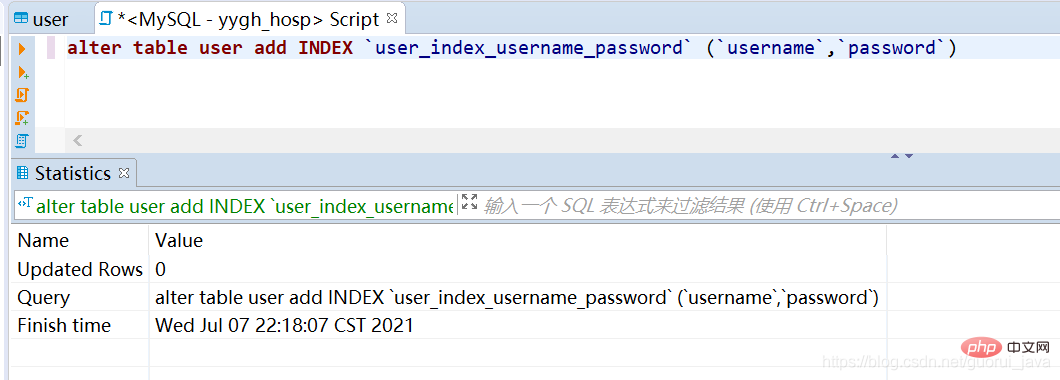
(1) Indeks nilai tunggal (2) Indeks unik (. 3) Indeks bersama (4) Indeks kunci utamaNota: Satu-satunya perbezaan antara indeks unik dan indeks kunci primer: indeks kunci primer tidak boleh batal4. Cipta indeks
alter table user add INDEX `user_index_username_password` (`username`,`password`)
Terdapat penuding pautan antara semua nod daun.
Rekod data disimpan dalam nod daun.
Optimumkan B-Tree dalam bahagian sebelumnya Memandangkan nod bukan daun bagi B Tree hanya menyimpan maklumat nilai utama, dengan mengandaikan bahawa setiap blok cakera boleh menyimpan 4 nilai utama dan maklumat penunjuk, ia akan menjadi struktur bagi. Pokok B. Seperti yang ditunjukkan dalam rajah di bawah:
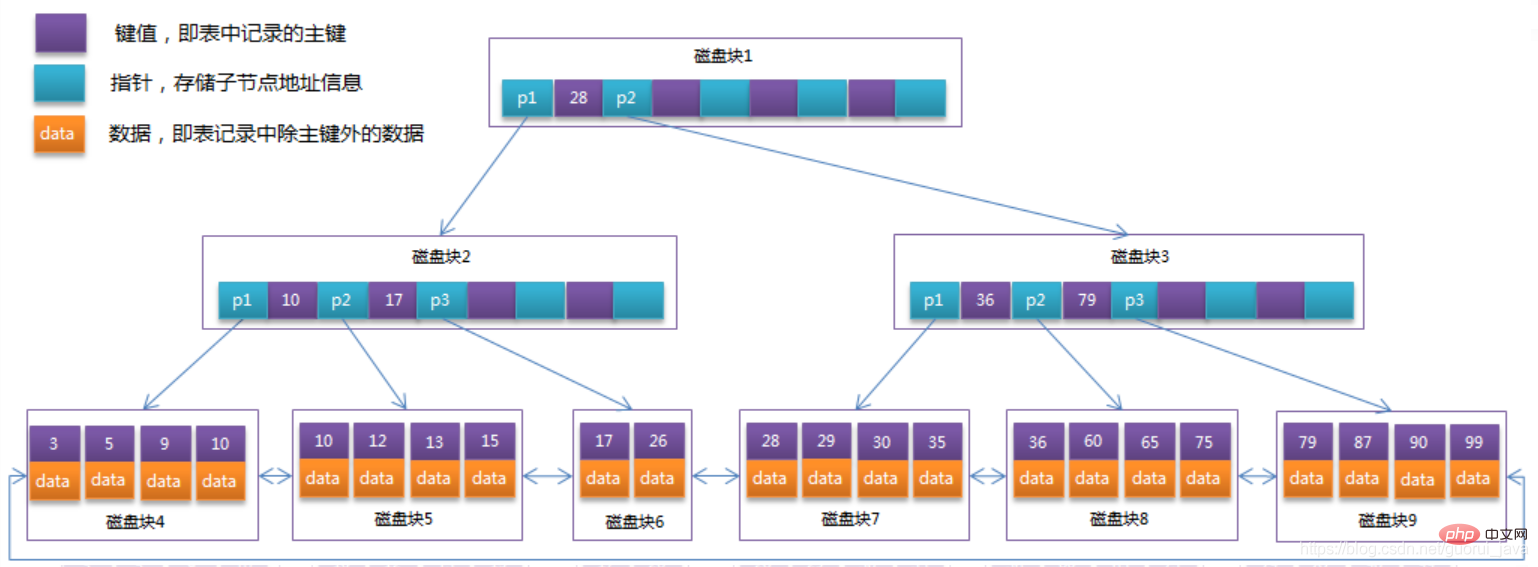
Indeks B Tree dalam pangkalan data boleh dibahagikan kepada indeks berkelompok dan indeks sekunder. Contoh rajah B Tree di atas dilaksanakan dalam pangkalan data sebagai indeks berkelompok Nod daun dalam B Tree indeks berkelompok menyimpan data rekod baris keseluruhan jadual. Perbezaan antara indeks tambahan dan indeks berkelompok ialah nod daun indeks tambahan tidak mengandungi semua data rekod baris, tetapi kunci indeks berkelompok yang menyimpan data baris yang sepadan, iaitu kunci utama. Apabila menanyakan data melalui indeks tambahan, enjin storan InnoDB akan merentasi indeks tambahan untuk mencari kunci utama, dan kemudian mencari data rekod baris lengkap dalam indeks berkelompok melalui kunci utama.
5. Cara mencetuskan indeks bersama
1 Buat indeks bersama pada nama pengguna jadual pengguna, kata laluan
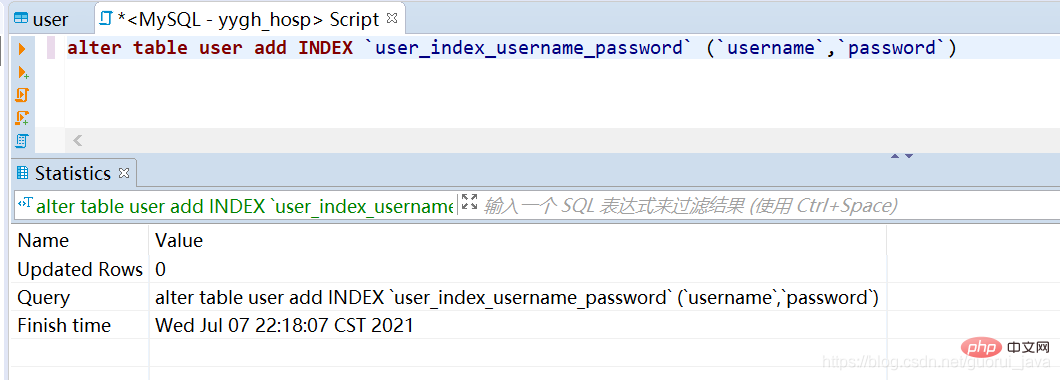
2. Cetuskan indeks bersama
(1) Menggunakan semua kekunci indeks indeks bersama boleh mencetuskan indeks bersama
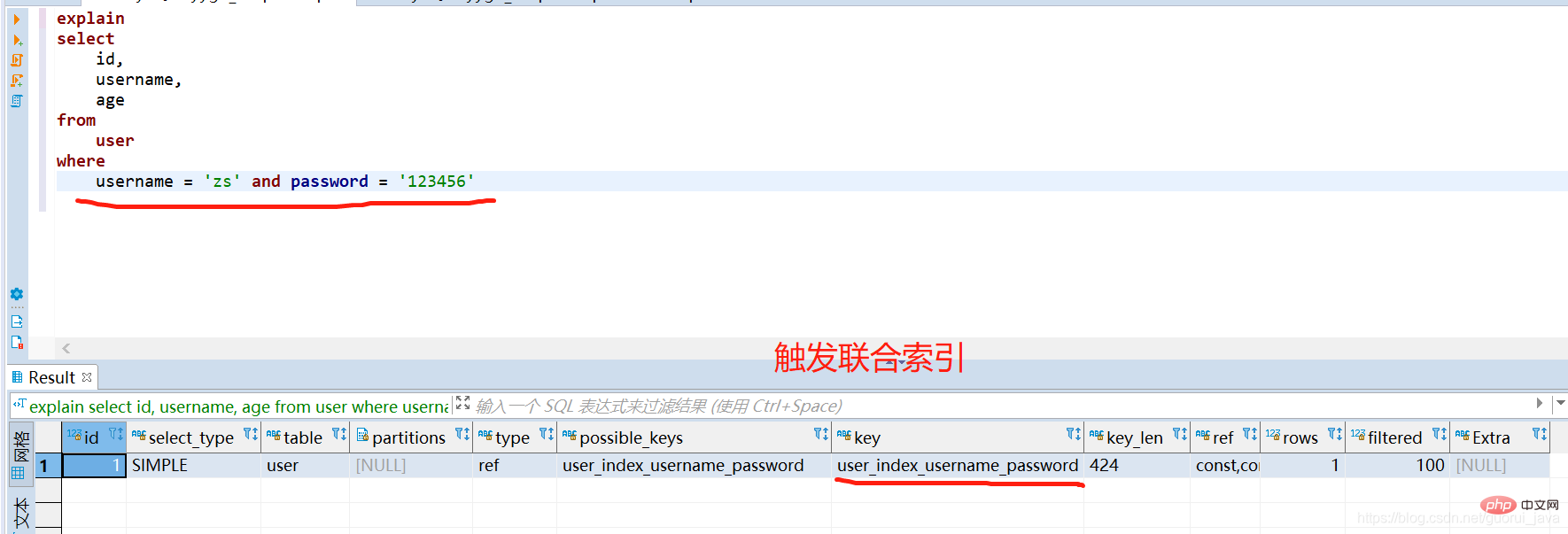
(2) Menggunakan semua kekunci indeks daripada indeks bersama, tetapi bersambung dengan atau , indeks sendi
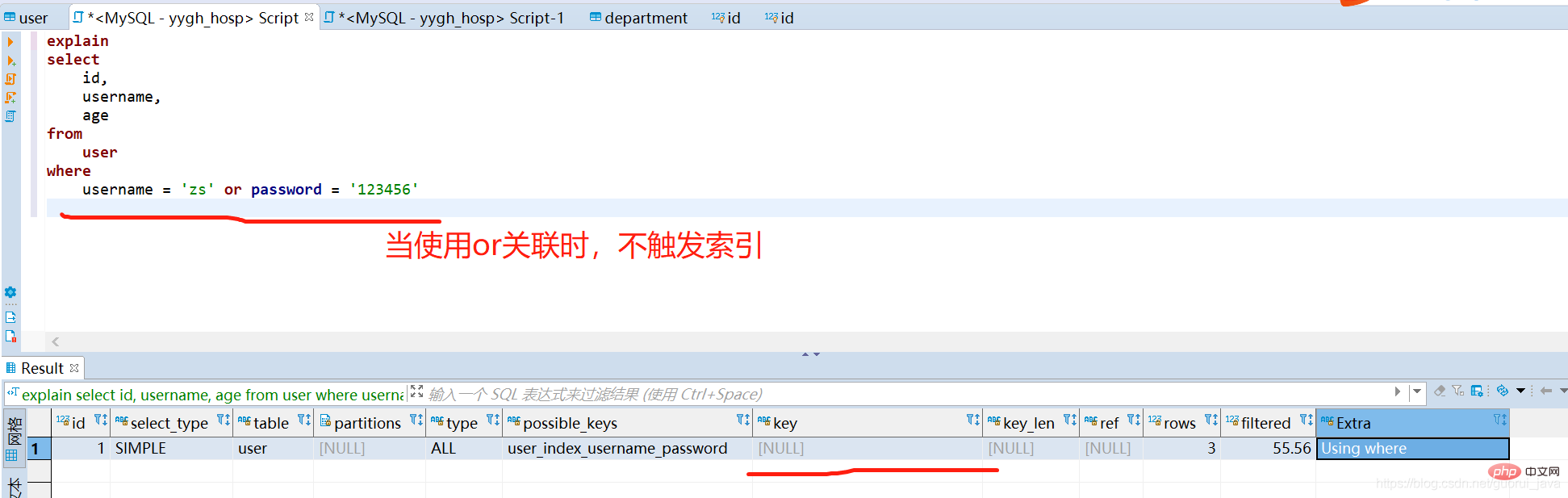
(3) Apabila medan pertama di sebelah kiri indeks sendi digunakan secara bersendirian, indeks sendi



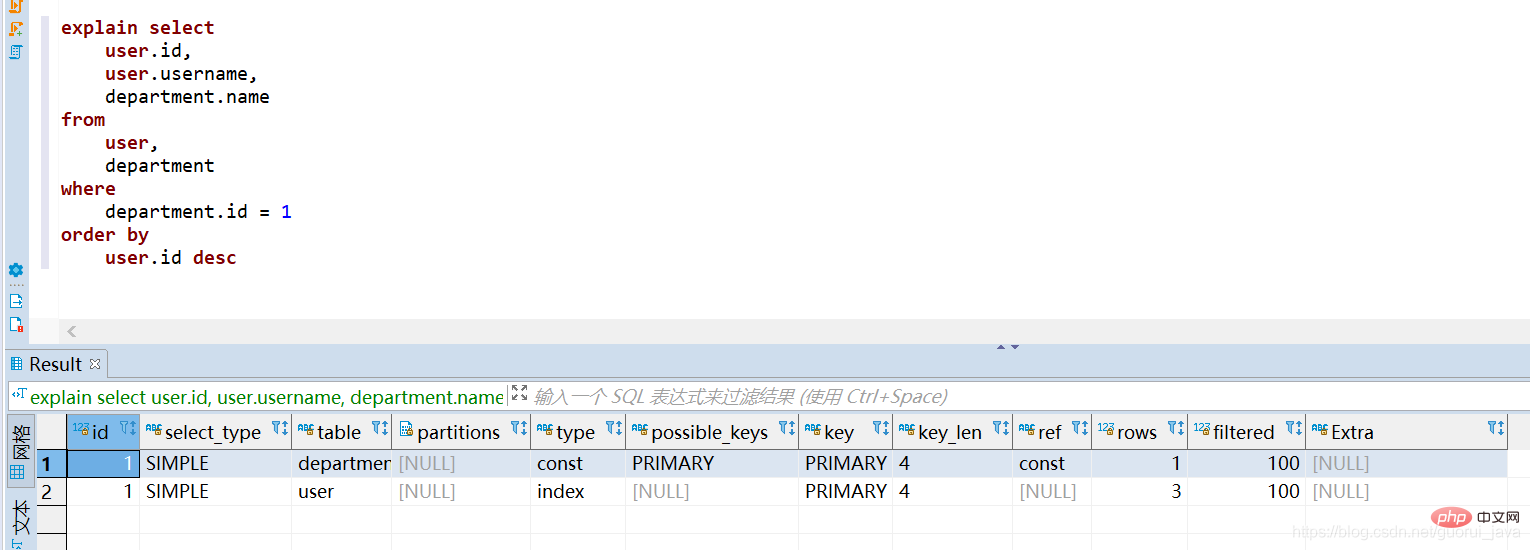
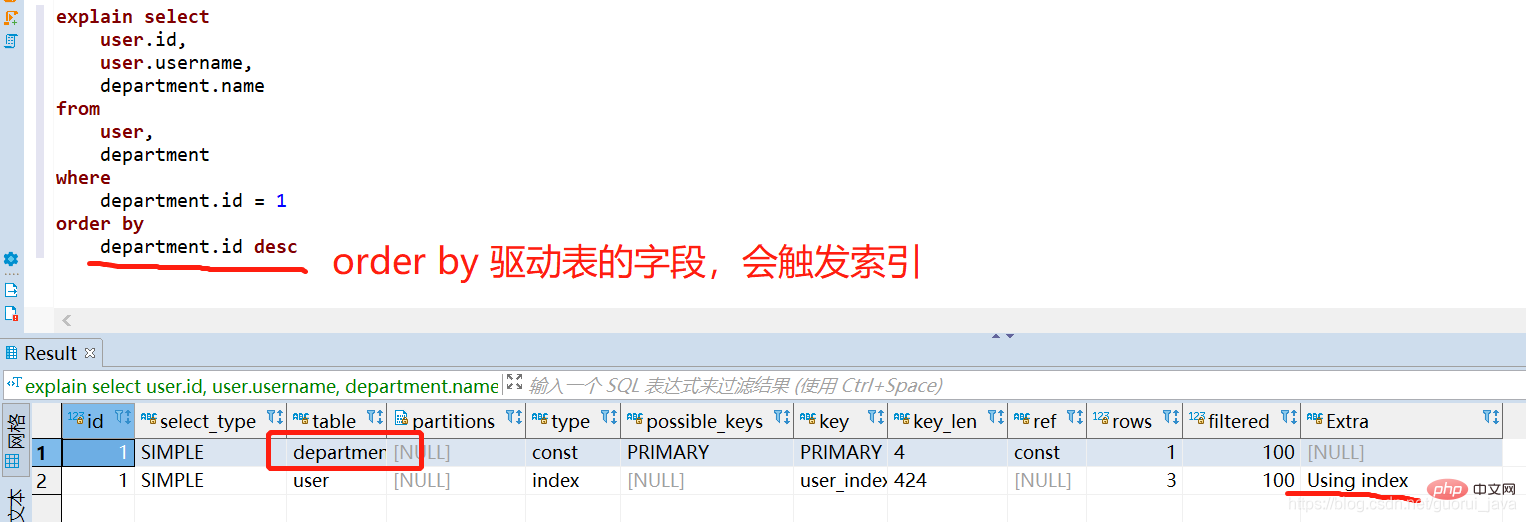
Jadual yang muncul dalam baris pertama explain ialah jadual pemacu.
- Apabila syarat cantuman ditentukan, jadual dengan bilangan baris rekod yang kecil yang memenuhi syarat pertanyaan ialah [jadual dipandu]
- Tidak dinyatakan Apabila menyertai syarat, jadual dengan bilangan baris yang kecil ialah [jadual terdorong]
- SIMPLE: Simple SELECT (tanpa UNION atau subquery)
- PRIMER: SELECT Terluar
- UNION: Pernyataan SELECT kedua atau seterusnya dalam UNION
- DEPENDENT UNION: Yang ketiga dalam UNION Pernyataan SELECT kedua atau seterusnya bergantung pada pertanyaan luar
- KEPUTUSAN KESATUAN: hasil daripada KESATUAN
- SUBQUERY: subkueri ketiga A SELECT
- SUBQUERY BERGANTUNG: PILIHAN pertama dalam subkueri, bergantung pada pertanyaan luar
- TERUSKAN: PILIH jadual terbitan (Subkueri daripada klausa FROM)
- sistem: Jadual hanya mempunyai satu baris (=jadual sistem ). Ini adalah kes khas jenis gabungan const.
- const: Jadual mempunyai paling banyak satu baris yang sepadan, yang akan dibaca pada permulaan pertanyaan. Oleh kerana hanya terdapat satu baris, nilai lajur dalam baris ini boleh dianggap sebagai pemalar oleh pengoptimum yang lain. const digunakan apabila membandingkan semua bahagian KUNCI UTAMA atau indeks UNIK dengan nilai malar.
- eq_ref: Untuk setiap gabungan baris daripada jadual sebelumnya, baca satu baris daripada jadual ini. Ini mungkin jenis gabungan terbaik, selain jenis const. Ia digunakan apabila semua bahagian indeks digunakan dalam gabungan dan indeks adalah UNIK atau KUNCI UTAMA. eq_ref boleh digunakan pada lajur diindeks berbanding menggunakan operator =. Nilai perbandingan boleh menjadi pemalar atau ungkapan menggunakan lajur daripada jadual yang dibaca sebelum jadual ini.
- ref: Untuk setiap gabungan baris daripada jadual sebelumnya, semua baris dengan nilai indeks yang sepadan akan dibaca daripada jadual ini. Gunakan ref jika gabungan hanya menggunakan awalan paling kiri kekunci, atau jika kunci itu bukan UNIK atau KUNCI UTAMA (dengan kata lain, jika gabungan tidak boleh memilih satu baris berdasarkan kekunci). Jenis cantuman ini bagus jika anda menggunakan kekunci yang sepadan dengan hanya sebilangan kecil baris. ref boleh digunakan pada lajur diindeks menggunakan operator = atau <=>
- ref_or_null: Jenis gabungan ini seperti ref, tetapi dengan penambahan MySQL yang secara khusus boleh mencari baris yang mengandungi nilai NULL. Jenis pengoptimuman gabungan ini sering digunakan dalam menyelesaikan subkueri.
index_merge: Jenis gabungan ini menunjukkan bahawa kaedah pengoptimuman gabungan indeks digunakan. Dalam kes ini, lajur kunci mengandungi senarai indeks yang digunakan dan key_len mengandungi elemen kunci terpanjang bagi indeks yang digunakan.
unique_subquery: Jenis ini menggantikan ref subquery IN dalam bentuk berikut: nilai IN (SELECT primary_key FROM single_table WHERE some_expr unique_subquery ialah fungsi carian indeks yang boleh menggantikan sepenuhnya subquery, Lebih cekap.
index_subquery: Jenis gabungan ini serupa dengan unique_subquery. IN subqueries boleh digantikan, tetapi hanya untuk indeks bukan unik dalam subqueries dalam bentuk berikut: nilai IN (SELECT key_column FROM single_table WHERE some_expr)
julat: hanya ambil julat yang diberikan Baris , gunakan indeks untuk memilih baris. Lajur utama menunjukkan indeks yang digunakan. key_len mengandungi elemen kunci terpanjang bagi indeks yang digunakan. Lajur rujukan ialah NULL dalam jenis ini. Apabila menggunakan operator =, <>, >, >=, <, <=, IS NULL, <=>, BETWEEN atau IN untuk membandingkan lajur utama dengan pemalar, anda boleh menggunakan julat
indeks: Jenis cantuman ini adalah sama seperti SEMUA, kecuali pepohon indeks sahaja yang diimbas. Ini biasanya lebih pantas daripada SEMUA kerana fail indeks biasanya lebih kecil daripada fail data.
semua: Lakukan imbasan jadual lengkap untuk setiap gabungan baris daripada jadual sebelumnya. Ini biasanya tidak baik jika jadual adalah yang pertama tidak ditanda const, dan biasanya buruk dalam kes itu. Ia biasanya mungkin untuk menambah lebih banyak indeks tanpa menggunakan SEMUA supaya baris boleh diambil berdasarkan nilai malar atau nilai lajur dalam jadual sebelumnya.
(5) possible_keys: Lajur possible_keys menunjukkan indeks yang MySQL boleh gunakan untuk mencari baris dalam jadual. Ambil perhatian bahawa lajur ini adalah bebas sepenuhnya daripada susunan jadual yang ditunjukkan dalam output EXPLAIN. Ini bermakna bahawa beberapa kunci dalam possible_keys sebenarnya tidak boleh digunakan dalam susunan jadual yang dijana.
(6) kunci: Lajur kunci memaparkan kunci (indeks) yang MySQL benar-benar memutuskan untuk digunakan. Jika tiada indeks dipilih, kuncinya adalah NULL. Untuk memaksa MySQL menggunakan atau mengabaikan indeks pada lajur possible_keys, gunakan FORCE INDEX, USE INDEX atau ABAIKAN INDEX dalam pertanyaan.
(7) key_len: Lajur key_len memaparkan panjang kunci yang MySQL memutuskan untuk digunakan. Jika kuncinya NULL, panjangnya ialah NULL. Ambil perhatian bahawa dengan menggunakan nilai key_len kita boleh menentukan bahagian mana kata kunci berbilang bahagian yang sebenarnya akan digunakan oleh MySQL.
(8) rujukan: Lajur rujukan menunjukkan lajur atau pemalar yang digunakan dengan kunci untuk memilih baris daripada jadual.
(9) baris: Lajur baris menunjukkan bilangan baris yang MySQL fikir ia mesti semak semasa melaksanakan pertanyaan.
(10) Tambahan: Lajur ini mengandungi butiran pertanyaan yang diselesaikan oleh MySQL.
Berbeza: Selepas MySQL menemui baris pertama yang sepadan, ia berhenti mencari lebih banyak baris untuk gabungan baris semasa.
Tidak wujud: MySQL boleh melakukan pengoptimuman LEFT JOIN pada pertanyaan Selepas mencari baris yang sepadan dengan standard LEFT JOIN, ia tidak akan menyemak lagi dalam jadual untuk gabungan baris sebelumnya. OK.
julat disemak untuk setiap rekod (peta indeks: #): MySQL tidak menemui indeks yang baik untuk digunakan, tetapi mendapati bahawa adalah mungkin untuk mengindeks sebahagiannya jika nilai lajur dari jadual sebelumnya diketahui Boleh digunakan. Untuk setiap gabungan baris daripada jadual sebelumnya, MySQL menyemak sama ada baris itu boleh diambil menggunakan kaedah capaian julat atau index_merge.
Menggunakan failsort: MySQL memerlukan pas tambahan untuk memikirkan cara mendapatkan semula baris dalam susunan yang disusun. Pengisihan dicapai dengan menyemak imbas semua baris berdasarkan jenis gabungan dan menyimpan kekunci isihan dan penuding ke baris untuk semua baris yang sepadan dengan klausa WHERE. Kekunci kemudian diisih dan baris diambil dalam susunan yang disusun.
Menggunakan indeks: Dapatkan maklumat lajur daripada jadual dengan membaca baris sebenar menggunakan hanya maklumat dalam pepohon indeks tanpa mencari lebih lanjut. Strategi ini boleh digunakan apabila pertanyaan hanya menggunakan lajur yang merupakan sebahagian daripada indeks tunggal.
Menggunakan sementara: Untuk menyelesaikan pertanyaan, MySQL perlu mencipta jadual sementara untuk menyimpan keputusan. Situasi biasa ialah apabila pertanyaan mengandungi klausa GROUP BY dan ORDER BY yang boleh menyenaraikan lajur mengikut situasi yang berbeza.
Menggunakan where: klausa WHERE digunakan untuk mengehadkan baris mana yang sepadan dengan jadual seterusnya atau dihantar kepada pelanggan. Melainkan anda secara khusus meminta atau menyemak semua baris daripada jadual, pertanyaan mungkin mempunyai beberapa ralat jika nilai Tambahan tidak Menggunakan tempat dan jenis gabungan jadual ialah SEMUA atau indeks.
Menggunakan sort_union(...), Menggunakan union(...), Menggunakan intersect(...): Fungsi ini menggambarkan cara untuk menggabungkan imbasan indeks untuk jenis gabungan index_merge.
Menggunakan indeks untuk kumpulan mengikut: Sama seperti Menggunakan kaedah indeks untuk mengakses jadual, Menggunakan indeks untuk kumpulan mengikut bermakna MySQL telah menemui indeks yang boleh digunakan untuk membuat pertanyaan GROUP BY atau DISTINCT pertanyaan semua lajur tanpa perlu mencari cakera keras tambahan untuk mengakses jadual sebenar. Juga, gunakan indeks dengan cara yang paling cekap supaya untuk setiap kumpulan, hanya beberapa entri indeks dibaca.
Dengan mendarab semua nilai dalam lajur baris keluaran EXPLAIN, anda boleh mendapat petunjuk tentang betapa bagusnya gabungan. Ini sepatutnya memberitahu anda berapa banyak baris yang perlu diperiksa oleh MySQL untuk melaksanakan pertanyaan. Produk ini juga digunakan untuk menentukan pernyataan SELECT berbilang jadual yang hendak dilaksanakan apabila anda menggunakan pembolehubah max_join_size untuk mengehadkan pertanyaan.
Pembelajaran yang disyorkan: tutorial video mysql
Atas ialah kandungan terperinci Kuasai sepenuhnya kemahiran pengindeksan mysql (perkongsian ringkasan). Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1382
1382
 52
52

 Beberapa situasi kegagalan indeks mysql
Feb 21, 2024 pm 04:23 PM
Beberapa situasi kegagalan indeks mysql
Feb 21, 2024 pm 04:23 PM
Situasi biasa: 1. Gunakan fungsi atau operasi; 2. Penukaran jenis tersirat 3. Gunakan tidak sama dengan (!= atau <>); Nilai; 7. Selektiviti indeks rendah 8. Prinsip awalan paling kiri bagi indeks komposit 9. Keputusan pengoptimum;
 Dalam keadaan apakah indeks mysql akan gagal?
Aug 09, 2023 pm 03:38 PM
Dalam keadaan apakah indeks mysql akan gagal?
Aug 09, 2023 pm 03:38 PM
Indeks MySQL akan gagal apabila membuat pertanyaan tanpa menggunakan lajur indeks, jenis data yang tidak sepadan, penggunaan indeks awalan yang tidak betul, menggunakan fungsi atau ungkapan untuk pertanyaan, susunan lajur indeks yang salah, kemas kini data yang kerap dan terlalu banyak atau terlalu sedikit indeks. 1. Jangan gunakan lajur indeks untuk pertanyaan Untuk mengelakkan situasi ini, anda harus menggunakan lajur indeks yang sesuai dalam pertanyaan 2. Jenis data tidak sepadan apabila mereka bentuk struktur jadual jenis data pertanyaan 3. , Penggunaan indeks awalan yang tidak betul, anda boleh menggunakan indeks awalan.
 Bilakah imbasan jadual penuh lebih cepat daripada menggunakan indeks di MySQL?
Apr 09, 2025 am 12:05 AM
Bilakah imbasan jadual penuh lebih cepat daripada menggunakan indeks di MySQL?
Apr 09, 2025 am 12:05 AM
Pengimbasan jadual penuh mungkin lebih cepat dalam MySQL daripada menggunakan indeks. Kes -kes tertentu termasuk: 1) jumlah data adalah kecil; 2) apabila pertanyaan mengembalikan sejumlah besar data; 3) Apabila lajur indeks tidak selektif; 4) Apabila pertanyaan kompleks. Dengan menganalisis rancangan pertanyaan, mengoptimumkan indeks, mengelakkan lebih banyak indeks dan tetap mengekalkan jadual, anda boleh membuat pilihan terbaik dalam aplikasi praktikal.
 Apakah klasifikasi indeks mysql?
Apr 22, 2024 pm 07:12 PM
Apakah klasifikasi indeks mysql?
Apr 22, 2024 pm 07:12 PM
Indeks MySQL dibahagikan kepada jenis berikut: 1. Indeks biasa: sepadan dengan nilai, julat atau awalan 2. Indeks unik: memastikan bahawa nilai adalah unik 3. Indeks kunci utama: indeks unik lajur kunci utama; indeks kunci: menunjuk ke kunci utama jadual lain ; 5. Indeks teks penuh: carian teks penuh; lajur.
 Indeks MySQL meninggalkan peraturan padanan awalan
Feb 24, 2024 am 10:42 AM
Indeks MySQL meninggalkan peraturan padanan awalan
Feb 24, 2024 am 10:42 AM
Contoh prinsip prinsip dan kod indeks MySQL paling kiri Dalam MySQL, pengindeksan adalah salah satu cara penting untuk meningkatkan kecekapan pertanyaan. Antaranya, prinsip paling kiri indeks adalah prinsip penting yang perlu kita ikuti apabila menggunakan indeks untuk mengoptimumkan pertanyaan. Artikel ini akan memperkenalkan prinsip prinsip paling kiri indeks MySQL dan memberikan beberapa contoh kod khusus. 1. Prinsip prinsip indeks paling kiri Prinsip paling kiri indeks bermaksud bahawa dalam indeks, jika keadaan pertanyaan terdiri daripada berbilang lajur, maka hanya pertanyaan berdasarkan lajur paling kiri dalam indeks dapat memenuhi syarat pertanyaan sepenuhnya.
 Terangkan pelbagai jenis indeks MySQL (B-Tree, Hash, Full-Text, Spatial).
Apr 02, 2025 pm 07:05 PM
Terangkan pelbagai jenis indeks MySQL (B-Tree, Hash, Full-Text, Spatial).
Apr 02, 2025 pm 07:05 PM
MySQL menyokong empat jenis indeks: B-Tree, Hash, Full-Text, dan Spatial. 1. B-Tree Index sesuai untuk carian nilai yang sama, pertanyaan dan penyortiran. 2. Indeks hash sesuai untuk carian nilai yang sama, tetapi tidak menyokong pertanyaan dan penyortiran pelbagai. 3. Indeks teks penuh digunakan untuk carian teks penuh dan sesuai untuk memproses sejumlah besar data teks. 4. Indeks spatial digunakan untuk pertanyaan data geospatial dan sesuai untuk aplikasi GIS.
 Bagaimana untuk menggunakan indeks MySQL secara rasional dan mengoptimumkan prestasi pangkalan data? Reka bentuk protokol yang perlu diketahui oleh pelajar teknikal!
Sep 10, 2023 pm 03:16 PM
Bagaimana untuk menggunakan indeks MySQL secara rasional dan mengoptimumkan prestasi pangkalan data? Reka bentuk protokol yang perlu diketahui oleh pelajar teknikal!
Sep 10, 2023 pm 03:16 PM
Bagaimana untuk menggunakan indeks MySQL secara rasional dan mengoptimumkan prestasi pangkalan data? Reka bentuk protokol yang perlu diketahui oleh pelajar teknikal! Pengenalan: Dalam era Internet hari ini, jumlah data terus berkembang, dan pengoptimuman prestasi pangkalan data telah menjadi topik yang sangat penting. Sebagai salah satu pangkalan data hubungan yang paling popular, penggunaan indeks rasional MySQL adalah penting untuk meningkatkan prestasi pangkalan data. Artikel ini akan memperkenalkan cara menggunakan indeks MySQL secara rasional, mengoptimumkan prestasi pangkalan data dan menyediakan beberapa peraturan reka bentuk untuk pelajar teknikal. 1. Mengapa menggunakan indeks? Indeks ialah struktur data yang menggunakan
 Strategi pengoptimuman prestasi untuk kemas kini data dan penyelenggaraan indeks indeks PHP dan MySQL serta kesannya terhadap prestasi
Oct 15, 2023 pm 12:15 PM
Strategi pengoptimuman prestasi untuk kemas kini data dan penyelenggaraan indeks indeks PHP dan MySQL serta kesannya terhadap prestasi
Oct 15, 2023 pm 12:15 PM
Strategi pengoptimuman prestasi untuk kemas kini data dan penyelenggaraan indeks indeks PHP dan MySQL serta kesannya terhadap prestasi Ringkasan: Dalam pembangunan PHP dan MySQL, indeks ialah alat penting untuk mengoptimumkan prestasi pertanyaan pangkalan data. Artikel ini akan memperkenalkan prinsip asas dan penggunaan indeks, serta meneroka kesan prestasi indeks pada kemas kini dan penyelenggaraan data. Pada masa yang sama, artikel ini juga menyediakan beberapa strategi pengoptimuman prestasi dan contoh kod khusus untuk membantu pembangun lebih memahami dan menggunakan indeks. Prinsip asas dan penggunaan indeks Dalam MySQL, indeks ialah nombor khas
