

Ringkaskan 10 petua untuk meningkatkan prestasi Redis

Artikel ini membawakan anda pengetahuan yang berkaitan tentang Redis Terutamanya ia memperkenalkan beberapa petua untuk meningkatkan prestasi redis, termasuk saluran paip, membolehkan IO berbilang benang, mengelakkan kunci besar, dll. , harap ia membantu semua orang.

Pembelajaran yang disyorkan: Tutorial Redis
01 Menggunakan saluran paip
Redis ialah TCP berdasarkan permintaan-tindak balas pelayan model. Bermaksud RTT permintaan tunggal (masa pergi balik), bergantung pada keadaan rangkaian semasa . Ini menyebabkan satu permintaan Redis berpotensi menjadi sangat pantas, mis. Mungkin sangat perlahan, seperti dalam persekitaran rangkaian yang lemah.
Sebaliknya, setiap permintaan-tindak balas Redis melibatkan panggilan sistem baca dan tulis. Ia juga boleh mencetuskan berbilang panggilan sistem epoll_wait (platform Linux). Ini menyebabkan Redis sentiasa bertukar antara mod pengguna dan mod kernel.
static int connSocketRead(connection *conn, void *buf, size_t buf_len) {
// read 系统调用
int ret = read(conn->fd, buf, buf_len);}static int connSocketWrite(connection *conn, const void *data, size_t data_len) {
// write 系统调用
int ret = write(conn->fd, data, data_len);}int aeProcessEvents(aeEventLoop *eventLoop, int flags) {
// 事件触发,Linux 下为 epoll_wait 系统调用
numevents = aeApiPoll(eventLoop, tvp);}Jadi, bagaimana untuk menjimatkan masa perjalanan pergi dan balik dan panggilan sistem? Pemprosesan kelompok adalah idea yang baik.
Untuk tujuan ini, Redis menyediakan "talian paip" . Prinsip saluran paip adalah sangat mudah Berbilang arahan dibungkus ke dalam "satu arahan" dan dihantar. Selepas Redis menerimanya, ia menghuraikannya kepada berbilang arahan untuk dilaksanakan. Akhirnya, berbilang hasil dibungkus dan dikembalikan.
"Paip boleh meningkatkan prestasi Redis dengan berkesan".
Walau bagaimanapun, terdapat beberapa perkara yang anda perlu beri perhatian apabila menggunakan saluran paip
"Saluran paip tidak dapat menjamin atomicity". Semasa pelaksanaan arahan saluran paip, arahan yang dimulakan oleh pelanggan lain boleh dilaksanakan. Ingat, saluran paip hanya menyusun arahan. Untuk memastikan atomicity, gunakan skrip MULTI atau Lua.
"Anda tidak seharusnya menggunakan terlalu banyak arahan saluran paip pada satu masa". Apabila menggunakan saluran paip, Redis akan menyimpan sementara hasil tindak balas arahan saluran paip dalam memori Balas penimbal dan menunggu semua arahan dilaksanakan sebelum kembali. Jika terdapat terlalu banyak arahan saluran paip, ia mungkin menduduki lebih banyak memori. Satu saluran paip boleh dibahagikan kepada beberapa saluran paip.
02 Dayakan IO multi-threading
Sebelum versi "Redis 6", Redis telah "single-threading" membaca dan menghuraikan, melaksanakan perintah. Bermula dari Redis 6, IO multi-threading diperkenalkan.
Benang IO bertanggungjawab untuk membaca arahan, menghurai arahan dan mengembalikan hasil. Apabila dihidupkan, ia boleh meningkatkan prestasi IO dengan berkesan.
Saya melukis gambarajah skematik untuk rujukan anda
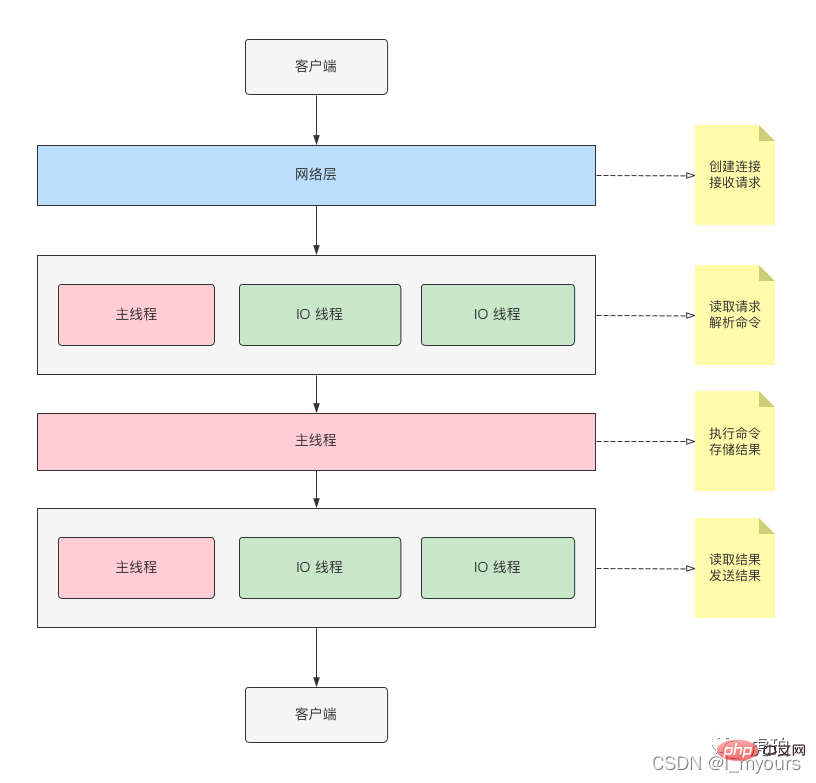
Seperti yang ditunjukkan dalam rajah di atas, utas utama dan utas IO akan bersama-sama mengambil bahagian dalam bacaan, penghuraian dan respons hasil daripada perintah.
Tetapi yang melaksanakan arahan ialah "benang utama".
Benang IO dimatikan secara lalai Anda boleh mengubah suai konfigurasi berikut dalam redis.conf untuk menghidupkannya.
io-threads 4 io-threads-do-reads yes
"io-threads" ialah bilangan IO thread (termasuk thread utama saya cadangkan anda menetapkan nilai yang berbeza mengikut mesin untuk ujian tekanan dan dapatkan nilai optimum).
03 Elakkan kunci besar
Perintah pelaksanaan Redis adalah satu benang, yang bermaksud terdapat risiko disekat apabila Redis mengendalikan "kunci besar".
Kunci besar biasanya merujuk kepada nilai yang disimpan dalam Redis yang terlalu besar. Termasuk:
- Satu nilai terlalu besar. Seperti String saiz 200M.
- Terlalu banyak elemen koleksi. Contohnya, terdapat ratusan atau puluhan juta data dalam Senarai, Hash, Set dan ZSet.
Sebagai contoh, katakan kita mempunyai kunci Rentetan 200M bernama "foo".
Laksanakan arahan berikut
127.0.0.1:6379> GET foo
Apabila keputusan dikembalikan, Redis akan memperuntukkan 200m memori dan melakukan salinan memcpy.
void _addReplyProtoToList(client *c, const char *s, size_t len) {
...
if (len) {
/* Create a new node, make sure it is allocated to at
* least PROTO_REPLY_CHUNK_BYTES */
size_t size = len size = zmalloc_usable_size(tail) - sizeof(clientReplyBlock);
tail->used = len;
// 内存拷贝
memcpy(tail->buf, s, len);
listAddNodeTail(c->reply, tail);
c->reply_bytes += tail->size;
closeClientOnOutputBufferLimitReached(c, 1);
}}Dan buf keluaran Redis ialah 16k
// server.h#define PROTO_REPLY_CHUNK_BYTES (16*1024) /* 16k output buffer */typedef struct client {
...
char buf[PROTO_REPLY_CHUNK_BYTES];} client;Ini bermakna Redis tidak boleh mengembalikan data respons dalam satu masa dan perlu mendaftarkan "peristiwa boleh ditulis", dengan itu mencetuskan berbilang tulis panggilan sistem.
Terdapat dua perkara yang memakan masa di sini:
- Peruntukkan memori yang besar (mungkin juga melepaskan memori, seperti arahan DEL)
- Cetuskan berbilang peristiwa boleh tulis (kerap Laksanakan panggilan sistem, seperti tulis, epoll_wait)
Jadi, bagaimana untuk mencari kunci besar?
Jika arahan mudah muncul dalam log perlahan, seperti GET, SET dan DEL, terdapat kebarangkalian tinggi bahawa kunci besar muncul.
127.0.0.1:6379> SLOWLOG GET 3) (integer) 201323 // 单位微妙 4) 1) "GET" 2) "foo"
Kedua, anda boleh menggunakan alat analisis Redis untuk mencari kunci besar.
$ redis-cli --bigkeys -i 0.1 ... [00.00%] Biggest string found so far '"foo"' with 209715200 bytes -------- summary ------- Sampled 1 keys in the keyspace! Total key length in bytes is 3 (avg len 3.00) Biggest string found '"foo"' has 209715200 bytes 1 strings with 209715200 bytes (100.00% of keys, avg size 209715200.00) 0 lists with 0 items (00.00% of keys, avg size 0.00) 0 hashs with 0 fields (00.00% of keys, avg size 0.00) 0 streams with 0 entries (00.00% of keys, avg size 0.00) 0 sets with 0 members (00.00% of keys, avg size 0.00) 0 zsets with 0 members (00.00% of keys, avg size 0.00)
Untuk kunci besar, terdapat beberapa cadangan:
1 Cuba elakkan kunci besar dalam perniagaan. Apabila kunci besar muncul, anda perlu menilai sama ada reka bentuk itu munasabah atau sama ada pepijat telah berlaku.
2. Pisahkan kunci besar kepada berbilang kunci kecil.
3. Gunakan arahan alternatif.
Jika versi Redis lebih besar daripada 4.0, anda boleh menggunakan perintah UNLINK dan bukannya DEL. Jika versi Redis lebih besar daripada 6.0, mekanisme bebas malas boleh dihidupkan. Operasi pelepasan memori akan dilaksanakan pada benang latar belakang.
LRANGE, HGETALL, dll. digantikan dengan LSCAN, HSCAN dan diperoleh secara berkelompok.
Tetapi saya masih mengesyorkan untuk mengelakkan kunci besar dalam perniagaan.
04 Elakkan daripada melaksanakan arahan dengan kerumitan masa yang tinggi
Kami tahu bahawa Redis melaksanakan arahan dalam "benang tunggal". Melaksanakan arahan dengan kerumitan masa yang tinggi berkemungkinan menyekat permintaan lain.
复杂度高的命令和元素数量有关。通常有以下两种场景。
元素太多,消耗 IO 资源。如 HGETALL、LRANGE,时间复杂度为 O(N)。
计算过于复杂,消费 CPU 资源。如 ZUNIONSTORE,时间复杂度为 O(N)+O(M log(M))
Redis 官方手册,标记了命令执行的时间复杂度。建议你在使用不熟悉的命令前,先查看手册,留意时间复杂度。
实际业务中,你应该尽量避免时间复杂度高的命令。如果必须要用,有两点建议
保证操作的元素数量,尽可能少。
读写分离。复杂命令通常是读请求,可以放到「slave」结点执行。
05 使用惰性删除 Lazy free
key 过期或是使用 DEL 删除命令时,Redis 除了从全局 hash 表移除对象外,还会将对象分配的内存释放。当遇到 big key 时,释放内存会造成主线程阻塞。
为此,Redis 4.0 引入了 UNLINK 命令,将释放对象内存操作放入 bio 后台线程执行。从而有效减少主线程阻塞。
Redis 6.0 更进一步,引入了 Lazy-free 相关配置。当开启配置后,key 过期和 DEL 命令内部,会将「释放对象」操作「异步执行」。
void delCommand(client *c) {
delGenericCommand(c,server.lazyfree_lazy_user_del);}void delGenericCommand(client *c, int lazy) {
int numdel = 0, j;
for (j = 1; j argc; j++) {
expireIfNeeded(c->db,c->argv[j]);
// 开启 lazy free 则使用异步删除
int deleted = lazy ? dbAsyncDelete(c->db,c->argv[j]) :
dbSyncDelete(c->db,c->argv[j]);
...
}}建议至少升级到 Redis 6,并开启 Lazy-free。
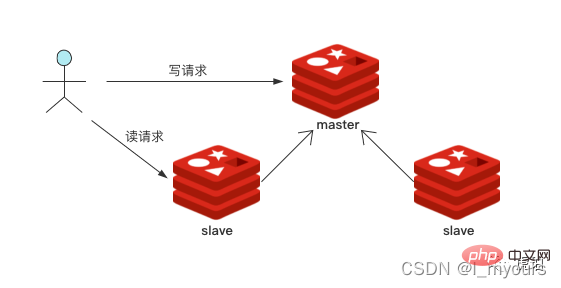
06 读写分离
Redis 通过副本,实现「主-从」运行模式,是故障切换的基石,用来提高系统运行可靠性。也支持读写分离,提高读性能。
你可以部署一个主结点,多个从结点。将读命令分散到从结点中,从而减轻主结点压力,提升性能。
07 绑定 CPU
Redis 6.0 开始支持绑定 CPU,可以有效减少线程上下文切换。
CPU 亲和性(CPU Affinity)是一种调度属性,它将一个进程或线程,「绑定」到一个或一组 CPU 上。也称为 CPU 绑定。
设置 CPU 亲和性可以一定程度避免 CPU 上下文切换,提高 CPU L1、L2 Cache 命中率。
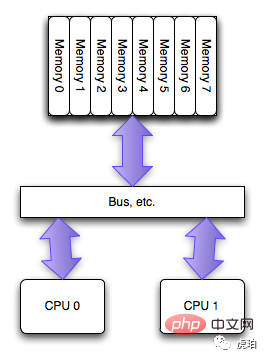
早期「SMP」架构下,每个 CPU 通过 BUS 总线共享资源。CPU 绑定意义不大。
而在当前主流的「NUMA」架构下,每个 CPU 有自己的本地内存。访问本地内存有更快的速度。而访问其他 CPU 内存会导致较大的延迟。这时,CPU 绑定对系统运行速度的提升有较大的意义。
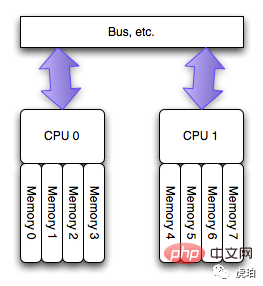
现实中的 NUMA 架构比上图更复杂,通常会将 CPU 分组,若干个 CPU 分配一组内存,称为 「node」。
你可以通过 「numactl -H 」 命令来查看 NUMA 硬件信息。
$ numactl -H available: 2 nodes (0-1)node 0 cpus: 0 2 4 6 8 10 12 14 16 18 20 22 24 26 28 30 32 34 36 38 node 0 size: 32143 MB node 0 free: 26681 MB node 1 cpus: 1 3 5 7 9 11 13 15 17 19 21 23 25 27 29 31 33 35 37 39 node 1 size: 32309 MB node 1 free: 24958 MB node distances: node 0 1 0: 10 21 1: 21 10
上图中可以得知该机器有 40 个 CPU,分组为 2 个 node。
node distances 是一个二维矩阵,表示 node 之间 「访问距离」,10 为基准值。上述命令中可以得知,node 自身访问,距离是 10。跨 node 访问,如 node 0 访问 node 1 距离为 21。说明该机器「跨 node 访问速度」比「node 自身访问速度」慢 2.1 倍。
其实,早在 2015 年,有人提出 Redis 需要支持设置 CPU 亲和性,而当时的 Redis 还没有支持 IO 多线程,该提议搁置。
而 Redis 6.0 引入 IO 多线程。同时,也支持了设置 CPU 亲和性。
我画了一张 Redis 6.0 线程家族供你参考。

上图可分为 3 个模块
- 主线程和 IO 线程:负责命令读取、解析、结果返回。命令执行由主线程完成。
- bio 线程:负责执行耗时的异步任务,如 close fd。
- 后台进程:fork 子进程来执行耗时的命令。
Redis 支持分别配置上述模块的 CPU 亲和度。你可以在 redis.conf 找到以下配置(该配置需手动开启)。
# IO 线程(包含主线程)绑定到 CPU 0、2、4、6 server_cpulist 0-7:2 # bio 线程绑定到 CPU 1、3 bio_cpulist 1,3 # aof rewrite 后台进程绑定到 CPU 8、9、10、11 aof_rewrite_cpulist 8-11 # bgsave 后台进程绑定到 CPU 1、10、11 bgsave_cpulist 1,10-11
我在上述机器,针对 IO 线程和主线程,进行如下测试:
首先,开启 IO 线程配置。
io-threads 4 # 主线程 + 3 个 IO 线程io-threads-do-reads yes # IO 线程开启读和解析命令功能
测试如下三种场景:
不开启 CPU 绑定配置。
绑定到不同 node。
「server_cpulist 0,1,2,3」绑定到相同 node。
「server_cpulist 0,2,4,6」
通过 redis-benchmark 对 get 命令进行基准测试,每种场景执行 3 次。
$ redis-benchmark -n 5000000 -c 50 -t get --threads 4
结果如下:
1.不开启 CPU 绑定配置
throughput summary: 248818.11 requests per second throughput summary: 248694.36 requests per second throughput summary: 249004.00 requests per second
2.绑定不同 node
throughput summary: 248880.03 requests per second throughput summary: 248447.20 requests per second throughput summary: 248818.11 requests per second
3.绑定相同 node
throughput summary: 284414.09 requests per second throughput summary: 284333.25 requests per second throughput summary: 265252.00 requests per second
根据测试结果,绑定到同一个 node,qps 大约提升 15%
使用绑定 CPU,你需要注意以下几点:
Linux 下,你可以使用 「numactl --hardware」 查看硬件布局,确保支持并开启 NUMA。
线程要尽可能分布在 「不同的 CPU,相同的 node」,设置 CPU 亲和度才有效。否则会造成频繁上下文切换和远距离内存访问。
你要熟悉 CPU 架构,做好充分的测试。否则可能适得其反,导致 Redis 性能下降。
08 合理配置持久化策略
Redis 支持两种持久化策略,RDB 和 AOF。
RDB 通过 fork 子进程,生成数据快照,二进制格式。
AOF 是增量日志,文本格式,通常较大。会通过 AOF rewrite 重写日志,节省空间。
除了手动执行「BGREWRITEAOF」命令外,以下 4 点也会触发 AOF 重写
执行「config set appendonly yes」命令
AOF 文件大小比例超出阈值,「auto-aof-rewrite-percentage」
AOF 文件大小绝对值超出阈值,「auto-aof-rewrite-min-size」
主从复制完成 RDB 加载
RDB 和 AOF,都是在主线程中触发执行。虽然具体执行,会通过 fork 交给后台子进程。但 fork 操作,会拷贝进程数据结构、页表等,当实例内存较大时,会影响性能。
AOF 支持以下三种策略。
appendfsync no:由操作系统决定执行 fsync 时机。 对 Linux 来说,通常每 30 秒执行一次 fsync,将缓冲区中的数据刷到磁盘上。如果 Redis qps 过高或写 big key,可能导致 buffer 写满,从而频繁触发 fsync。
appendfsync everysec: 每秒执行一次 fsync。
appendfsync always: 每次「写」会调用一次 fsync,性能影响较大。
AOF 和 RDB 都会对磁盘 IO 造成较高的压力。其中,AOF rewrite 会将 Redis hash 表所有数据进行遍历并写磁盘。对性能会产生一定的影响。
线上业务 Redis 通常是高可用的。如果对缓存数据丢失不敏感。考虑关闭 RDB 和 AOF 以提升性能。
如果无法关闭,有以下几点建议:
RDB 选择业务低峰期做,通常为凌晨。保持单个实例内存不超过 32 G。太大的内存会导致 fork 耗时增加。
AOF 选择 appendfsync no 或者 appendfsync everysec。
AOF auto-aof-rewrite-min-size 配置大一些,如 2G。避免频繁触发 rewrite。
AOF 可以仅在从节点开启,减轻主节点压力。
根据本地测试,不开启 AOF,写性能大约能提升 20% 左右。
09 使用长连接
Redis 是基于 TCP 协议,请求-响应式服务器。使用短连接会导致频繁的创建连接。
短连接有以下几个慢速操作:
创建连接时,TCP 会执行三次握手、慢启动等策略。
Redis 会触发新建/断开连接事件,执行分配/销毁客户端等耗时操作。
如果你使用的是 Redis Cluster,新建连接时,客户端会拉取 slots 信息初始化。建立连接速度更慢。
所以,相对于性能快速的 Redis,创建连接是十分慢速的操作。
「建议使用连接池,并合理设置连接池大小」。
但使用长连接时,需要留意一点,要有「自动重连」策略。避免因网络异常,导致连接失效,影响正常业务。
10 关闭 SWAP
SWAP 是内存交换技术。将内存按页,复制到预先设定的磁盘空间上。
内存是快速的,昂贵的。而磁盘是低速的,廉价的。
通常使用 SWAP 越多,系统性能越低。
Redis 是内存数据库,使用 SWAP 会导致性能快速下降。
建议留有足够内存,并关闭 SWAP。
总结
以上就是今天为大家分享的 「提升 Redis 性能的 10 个手段」。
我绘制了思维导图,方便大家记忆。
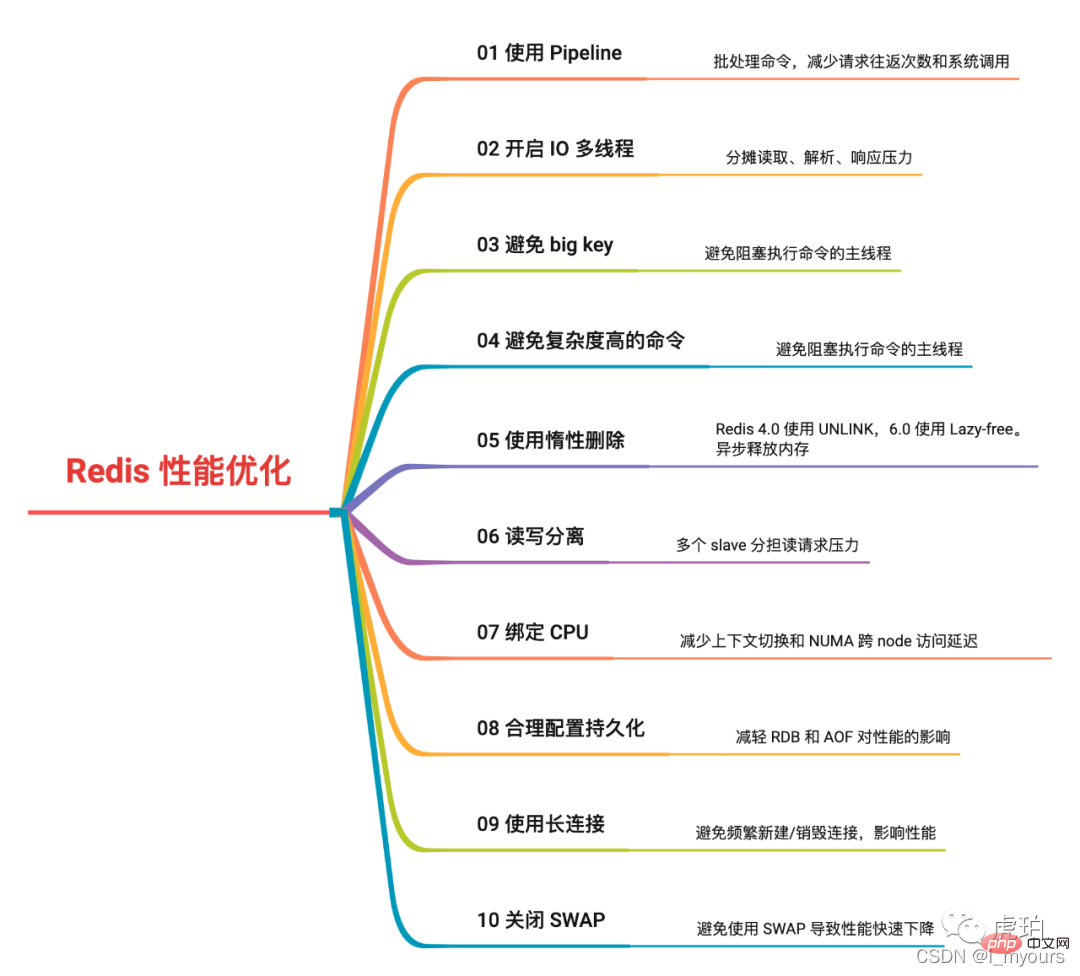
可以看到,性能优化并不容易,需要我们了解很多底层知识,并做出充分测试。在不同机器、不同系统、不同配置下,Redis 都会有不同的性能表现。
推荐学习:Redis学习教程
Atas ialah kandungan terperinci Ringkaskan 10 petua untuk meningkatkan prestasi Redis. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

Video Face Swap
Tukar muka dalam mana-mana video dengan mudah menggunakan alat tukar muka AI percuma kami!

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1392
1392
 52
52

 Cara Membina Mod Kluster Redis
Apr 10, 2025 pm 10:15 PM
Cara Membina Mod Kluster Redis
Apr 10, 2025 pm 10:15 PM
Mod Redis cluster menyebarkan contoh Redis ke pelbagai pelayan melalui sharding, meningkatkan skalabilitas dan ketersediaan. Langkah -langkah pembinaan adalah seperti berikut: Buat contoh Redis ganjil dengan pelabuhan yang berbeza; Buat 3 contoh sentinel, memantau contoh redis dan failover; Konfigurasi fail konfigurasi sentinel, tambahkan pemantauan maklumat contoh dan tetapan failover; Konfigurasi fail konfigurasi contoh Redis, aktifkan mod kluster dan tentukan laluan fail maklumat kluster; Buat fail nodes.conf, yang mengandungi maklumat setiap contoh Redis; Mulakan kluster, laksanakan perintah Buat untuk membuat kluster dan tentukan bilangan replika; Log masuk ke kluster untuk melaksanakan perintah maklumat kluster untuk mengesahkan status kluster; buat
 Cara membersihkan data redis
Apr 10, 2025 pm 10:06 PM
Cara membersihkan data redis
Apr 10, 2025 pm 10:06 PM
Cara Mengosongkan Data Redis: Gunakan perintah Flushall untuk membersihkan semua nilai utama. Gunakan perintah flushdb untuk membersihkan nilai utama pangkalan data yang dipilih sekarang. Gunakan Pilih untuk menukar pangkalan data, dan kemudian gunakan FlushDB untuk membersihkan pelbagai pangkalan data. Gunakan perintah DEL untuk memadam kunci tertentu. Gunakan alat REDIS-CLI untuk membersihkan data.
 Cara Membaca Gilir Redis
Apr 10, 2025 pm 10:12 PM
Cara Membaca Gilir Redis
Apr 10, 2025 pm 10:12 PM
Untuk membaca giliran dari Redis, anda perlu mendapatkan nama giliran, membaca unsur -unsur menggunakan arahan LPOP, dan memproses barisan kosong. Langkah-langkah khusus adalah seperti berikut: Dapatkan nama giliran: Namakannya dengan awalan "giliran:" seperti "giliran: my-queue". Gunakan arahan LPOP: Keluarkan elemen dari kepala barisan dan kembalikan nilainya, seperti LPOP Queue: My-Queue. Memproses Baris kosong: Jika barisan kosong, LPOP mengembalikan nihil, dan anda boleh menyemak sama ada barisan wujud sebelum membaca elemen.
 Cara menggunakan perintah redis
Apr 10, 2025 pm 08:45 PM
Cara menggunakan perintah redis
Apr 10, 2025 pm 08:45 PM
Menggunakan Arahan Redis memerlukan langkah -langkah berikut: Buka klien Redis. Masukkan arahan (nilai kunci kata kerja). Menyediakan parameter yang diperlukan (berbeza dari arahan ke arahan). Tekan Enter untuk melaksanakan arahan. Redis mengembalikan tindak balas yang menunjukkan hasil operasi (biasanya OK atau -r).
 Cara menggunakan kunci redis
Apr 10, 2025 pm 08:39 PM
Cara menggunakan kunci redis
Apr 10, 2025 pm 08:39 PM
Menggunakan REDIS untuk mengunci operasi memerlukan mendapatkan kunci melalui arahan SETNX, dan kemudian menggunakan perintah luput untuk menetapkan masa tamat tempoh. Langkah-langkah khusus adalah: (1) Gunakan arahan SETNX untuk cuba menetapkan pasangan nilai utama; (2) Gunakan perintah luput untuk menetapkan masa tamat tempoh untuk kunci; (3) Gunakan perintah DEL untuk memadam kunci apabila kunci tidak lagi diperlukan.
 Cara membaca kod sumber redis
Apr 10, 2025 pm 08:27 PM
Cara membaca kod sumber redis
Apr 10, 2025 pm 08:27 PM
Cara terbaik untuk memahami kod sumber REDIS adalah dengan langkah demi langkah: Dapatkan akrab dengan asas -asas Redis. Pilih modul atau fungsi tertentu sebagai titik permulaan. Mulakan dengan titik masuk modul atau fungsi dan lihat baris kod mengikut baris. Lihat kod melalui rantaian panggilan fungsi. Berhati -hati dengan struktur data asas yang digunakan oleh REDIS. Kenal pasti algoritma yang digunakan oleh Redis.
 Cara menyelesaikan kehilangan data dengan redis
Apr 10, 2025 pm 08:24 PM
Cara menyelesaikan kehilangan data dengan redis
Apr 10, 2025 pm 08:24 PM
Kerugian data REDIS termasuk kegagalan memori, gangguan kuasa, kesilapan manusia, dan kegagalan perkakasan. Penyelesaiannya adalah: 1. 2. Salin ke beberapa pelayan untuk ketersediaan tinggi; 3. Ha dengan redis sentinel atau cluster redis; 4. Buat gambar untuk membuat sandaran data; 5. Melaksanakan amalan terbaik seperti kegigihan, replikasi, gambar, pemantauan, dan langkah -langkah keselamatan.
 Cara menggunakan baris arahan redis
Apr 10, 2025 pm 10:18 PM
Cara menggunakan baris arahan redis
Apr 10, 2025 pm 10:18 PM
Gunakan alat baris perintah redis (redis-cli) untuk mengurus dan mengendalikan redis melalui langkah-langkah berikut: Sambungkan ke pelayan, tentukan alamat dan port. Hantar arahan ke pelayan menggunakan nama arahan dan parameter. Gunakan arahan bantuan untuk melihat maklumat bantuan untuk arahan tertentu. Gunakan perintah berhenti untuk keluar dari alat baris arahan.
