

Ringkaskan dan atur peruntukan memori dan penalaan pembelajaran oracle

Artikel ini membawakan anda pengetahuan yang berkaitan tentang Oracle, yang terutamanya memperkenalkan isu yang berkaitan dengan peruntukan memori dan penalaan memori Oracle boleh dibahagikan kepada sistem global dari perspektif kawasan global dan proses yang dikongsi , iaitu SGA dan PGA, mari kita lihat bersama-sama saya harap ia akan membantu semua orang.

Tutorial yang disyorkan: "Tutorial Pembelajaran Oracle"
1 Memori Oracle boleh dibahagikan kepada kawasan global sistem dan kawasan global proses dari perspektif perkongsian dan persendirian, iaitu SGA dan PGA (kawasan global proses atau kawasan global persendirian). Untuk memori dalam kawasan SGA, ia dikongsi secara global Pada UNIX, segmen memori yang dikongsi (boleh menjadi satu atau lebih) mesti ditetapkan untuk Oracle, kerana Oracle ialah berbilang proses pada UNIX manakala pada WINDOWS, Oracle adalah Tunggal proses (benang berbilang), jadi tidak perlu menyediakan segmen memori yang dikongsi. PGA ialah kawasan persendirian proses (benang). Apabila Oracle menggunakan mod pelayan kongsi (MTS), sebahagian daripada PGA, iaitu, UGA, akan diletakkan dalam memori kongsi large_pool_size.
Siarkan gambar seni bina memori Oracle Anda boleh melihat parameter utama dan nama parameter sepintas lalu mengikut paparan pada gambar:
.
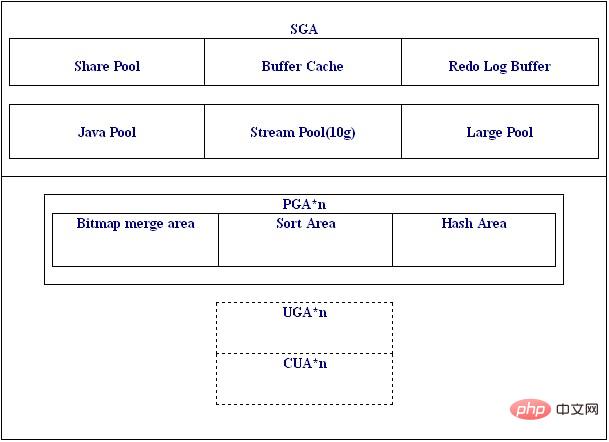 Untuk bahagian SGA, kita boleh lihat melalui pertanyaan dalam sqlplus:
Untuk bahagian SGA, kita boleh lihat melalui pertanyaan dalam sqlplus:
SQL> select * from v$sga; NAME VALUE ---------- -------------------- Fixed Size 454032 Variable Size 109051904 Database Buffers 385875968 Redo Buffers 667648
Oracle mungkin berbeza pada platform yang berbeza dan versi yang berbeza, tetapi ia adalah nilai tetap untuk persekitaran tertentu Ia menyimpan maklumat tentang setiap komponen SGA dan boleh dianggap sebagai kawasan untuk membimbing penubuhan daripada SGA.
Saiz Boleh Ubah:
Mengandungi shared_pool_size, java_pool_size, large_pool_size dan tetapan memori lain
Penimbal Pangkalan Data:
merujuk kepada penimbal data:
Dalam 8i, ia termasuk tiga bahagian memori: db_block_buffer*db_block_size, buffer_pool_keep dan buffer_pool_recycle.
Dalam 9i, ia termasuk db_cache_size, db_keep_cache_size, db_recycle_cache_size, db_nk_cache_size.
Buffer Penampan:
merujuk kepada penimbal log, log_buffer. Perkara tambahan yang perlu diperhatikan di sini ialah nilai pertanyaan untuk v$parameter, v$sgastat dan v$sga mungkin berbeza. Nilai dalam v$parameter merujuk pada awalan pengguna
Nilai yang ditetapkan dalam fail parameter permulaan, v$sgastat ialah saiz penimbal log yang sebenarnya diperuntukkan oleh Oracle (kerana nilai peruntukan penimbal sebenarnya adalah diskret, dan unit minimum bukan blok. diperuntukkan),
Nilai yang ditanya dalam v$sga ialah selepas Oracle memperuntukkan penimbal log, untuk melindungi penimbal log, beberapa halaman perlindungan biasanya kita akan mendapati bahawa saiz perlindungan halaman adalah kira-kira 11k ( Mungkin berbeza dalam persekitaran yang berbeza). <<>
Er, parameter dan tetapan SGA:
2.1 log_buffer
Bagi penetapan saiz penampan log, saya biasanya tidak fikir terdapat terlalu banyak cadangan, kerana selepas merujuk kepada syarat pencetus yang ditulis oleh LGWR, kita akan mendapati bahawa biasanya melebihi 3M tidak begitu bermakna. . Sebagai sistem formal,
Anda boleh mempertimbangkan untuk menetapkan bahagian ini kepada saiz log_buffer=3-5M dahulu, dan kemudian laraskannya mengikut situasi tertentu.
log_buffer ialah penimbal bagi Redo log.
Jadi di sini anda mesti memahami peristiwa pencetus Redo Log (LGWR)
1 Apabila kapasiti penampan semula log mencapai 1/. 3
2. Set selang masa penulisan semula log dicapai, biasanya 3 saat.
3 Kapasiti log buat semula dalam penimbal log buat semula mencapai 1M
4 Sebelum fail
5. Setiap komit--serahkan transaksi.
Kesimpulan di atas boleh dinyatakan dengan kata lain
1 Apabila kandungan dalam log_buffer adalah 1/3 penuh, cache akan dimuat semula sekali.
2 Selang maksimum ialah 3 saat, cache dimuat semula sekali
3. Apabila data dalam log_buffer mencapai 1M, cache disegarkan sekali.
4. Setiap kali "urus niaga" diserahkan, cache dimuatkan semula
2.2 Saiz_pool_besar
Untuk penetapan kolam penampan yang besar, jika MTS tidak digunakan, disarankan 20-30M sudah memadai. Bahagian ini digunakan terutamanya untuk menyimpan beberapa maklumat semasa pertanyaan selari, dan mungkin digunakan oleh RMAN semasa sandaran.
Jika MTS ditetapkan, memandangkan bahagian UGA akan dialihkan ke sini, saiz bahagian ini perlu dipertimbangkan secara menyeluruh berdasarkan bilangan proses pelayan dan tetapan parameter memori sesi yang berkaitan.
2.3 Java_pool_size
Jika pangkalan data tidak menggunakan JAVA, biasanya kita fikir mengekalkan 10-20M sudah memadai. Malah, ia boleh kurang, walaupun sekurang-kurangnya 32k, tetapi ia bergantung kepada komponen semasa memasang pangkalan data (seperti pelayan http).
2.4 Shared_pool_size
Overhed Shared_pool_size biasanya perlu dikekalkan dalam 300M. Melainkan sistem menggunakan sejumlah besar prosedur, fungsi dan pakej yang disimpan,
Aplikasi seperti oracle erp mungkin mencapai 500M atau lebih tinggi. Jadi kami menganggap sistem dengan memori 1G, kami boleh mempertimbangkan
Tetapkan parameter ini kepada 100M Untuk sistem 2G, pertimbangkan untuk menetapkannya kepada 150M Untuk sistem 8G, pertimbangkan untuk menetapkannya kepada 200—300M
<🎜. >2.5SGA_MAX_SIZE
Kawasan SGA merangkumi pelbagai penimbal dan kumpulan memori, yang kebanyakannya boleh menentukan saiznya melalui parameter tertentu. Walau bagaimanapun, sebagai sumber yang mahal, saiz memori fizikal sistem adalah terhad.
Walaupun saiz memori fizikal sebenar tidak perlu dikaitkan dengan pengalamatan memori CPU (ini akan diperkenalkan secara terperinci kemudian), penggunaan memori maya yang berlebihan membawa kepada halaman masuk/keluar,
akan sangat mempengaruhi prestasi sistem malah boleh menyebabkan sistem ranap. Oleh itu, parameter diperlukan untuk mengawal saiz maksimum memori maya yang digunakan oleh SGA Parameter ini ialah SGA_MAX_SIZE. Apabila contoh dimulakan,
Setiap kawasan memori hanya diperuntukkan saiz minimum yang diperlukan oleh contoh Semasa operasi berikutnya, saiznya dibesarkan mengikut keperluan, dan jumlah saiznya dihadkan oleh SGA_MAX_SIZE.
Untuk sistem OLTP, rujuk:
| <🎜>Nilai SGA_MAX_SIZE<🎜><🎜><🎜> | ||||||||||
<🎜>1G<🎜> < 🎜><🎜> | <🎜>400-500J<🎜><🎜><🎜> | ||||||||||
<🎜>2G<🎜><🎜><🎜> | <🎜>1G<🎜><🎜><🎜> | <🎜>4G< 🎜 ><🎜><🎜> | <🎜>2500J<🎜><🎜><🎜> | ||||||||
<🎜>8G<🎜><🎜><🎜> | <🎜>5G<🎜><🎜><🎜> |
2.6 PRE_PAGE_SGA
Apabila kejadian oracle bermula, hanya saiz terkecil bagi setiap kawasan memori akan dimuatkan. Manakala memori SGA yang lain hanya diperuntukkan sebagai memori maya,
Hanya apabila proses menyentuh halaman yang sepadan, ia akan digantikan dalam ingatan fizikal. Tetapi kami mungkin berharap sebaik sahaja contoh dimulakan, semua SGA
semuanya diperuntukkan kepada ingatan fizikal. Pada masa ini, tujuan boleh dicapai dengan menetapkan parameter PRE_PAGE_SGA. Nilai lalai parameter ini
adalah PALSU, iaitu tidak semua SGA akan diletakkan dalam ingatan fizikal. Apabila ditetapkan kepada TRUE, pelancaran instance akan meletakkan semua SGA ke dalam fizikal
dalam ingatan. Ia membenarkan contoh bermula sehingga keadaan prestasi maksimumnya, walau bagaimanapun, masa permulaan juga akan menjadi lebih lama (kerana untuk menjadikan semua SGA
semuanya diletakkan dalam ingatan fizikal, dan proses oracle perlu menyentuh semua halaman SGA).
2.7 LOCK_SGA
Untuk memastikan SGA dikunci dalam memori fizikal tanpa perlu masuk/keluar halaman , boleh dikawal melalui parameter LOCK_SGA.
Nilai lalai parameter ini adalah FALSE. Apabila dinyatakan sebagai TRUE, semua SGA boleh dikunci dalam memori fizikal. Sudah tentu,
Sesetengah sistem tidak menyokong penguncian memori, jadi parameter ini tidak sah.
2.8 SGA_TARGET
Apa yang ingin kami perkenalkan di sini ialah parameter yang sangat penting yang diperkenalkan dalam Oracle10g. Sebelum 10g, pelbagai kawasan ingatan SGA Saiz
perlu ditentukan melalui parameter masing-masing dan tidak boleh melebihi nilai saiz yang ditentukan oleh parameter, walaupun jumlahnya mungkin bukan
Had maksimum SGA belum dicapai. Di samping itu, setelah diperuntukkan, memori di setiap kawasan hanya boleh digunakan oleh kawasan ini dan tidak boleh dikongsi antara satu sama lain.
Ambil dua kawasan ingatan paling penting dalam SGA, Cache Penimbal dan Kolam Dikongsi, sebagai contoh
Tetapi terdapat percanggahan sedemikian: apabila sumber memori terhad, kadangkala permintaan untuk data dicache adalah sangat besar,
Untuk meningkatkan pukulan penimbal, perlu meningkatkan Cache Penampan Namun, disebabkan SGA yang terhad, ia hanya boleh "dirompak" dari kawasan lain - seperti mengurangkan Kongsi. Kolam,
Tingkatkan Cache Penampan; kadangkala sebahagian besar kod PLSQL dihuraikan dan disimpan dalam ingatan, menyebabkan Kolam Dikongsi tidak mencukupi,
Malah ralat 4031 berlaku dan Kumpulan Kongsi perlu dikembangkan Pada masa ini, campur tangan manusia mungkin diperlukan untuk mendapatkan semula ingatan daripada Cache Penampan.
Dengan ciri baharu ini, percanggahan ingatan dalam SGA ini mudah diselesaikan. Ciri ini dipanggil pengurusan memori kongsi automatik
(Pengurusan Memori Dikongsi Automatik ASMM). Satu-satunya parameter yang mengawal ciri ini ialah SGA_TARGE.
Selepas menetapkan parameter ini, anda tidak perlu menentukan saiz untuk setiap kawasan memori. SGA_TARGET menentukan saiz memori maksimum yang boleh digunakan oleh SGA,
Saiz setiap memori dalam SGA dikawal oleh Oracle sendiri dan tidak perlu dinyatakan secara manual. Oracle boleh melaraskan saiz setiap kawasan pada bila-bila masa untuk mencapai sistem
Saiz paling munasabah untuk prestasi sistem yang optimum, dan mengawal jumlahnya supaya berada dalam nilai yang ditentukan oleh SGA_TARGET. Sebaik sahaja anda menentukan nilai untuk SGA_TARGET
(lalai ialah 0, iaitu ASMM tidak dimulakan), ciri ASMM didayakan secara automatik.
三、oracle 内存调优办法
当项目的生产环境出现性能问题,我们如何通过判断那些参数需要调整呢?
3.1 检查ORACLE实例的Library Cache命中率:
标准:一般是大于99% 检查方式:
select 1-(sum(reloads)/sum(pins)) "Library cache Hit Ratio" from v$librarycache;
处理措施: 如果Library cache Hit Ratio的值低于99%,应调高shared_pool_size的大小。通过sqlplus连接数据库执行如下命令,调整shared_pool_size的大小:
SQL>alter system flush shared_pool;
SQL>alter system set shared_pool_size=设定值 scope=spfile;3.2 检查ORACLE实例的Data Buffer(数据缓冲区)命中率:
标准:一般是大于90% 检查方式:
select 1 - (phy.value / (cur.value + con.value)) "HIT RATIO"
from v$sysstat cur, v$sysstat con, v$sysstat phy
where cur.name = 'db block gets'
and con.name = 'consistent gets'
and phy.name = 'physical reads';处理措施:
如果HIT RATIO的值低于90%,应调高db_cache_size的大小。通过sqlplus连接数据库执行如下命令,
调整db_cache_size的大小
SQL>alter system set db_cache_size=设定值 scope=spfile
3.3 检查ORACLE实例的Dictionary Cache命中率:
标准:一般是大于95%
检查方式:
select 1 - (sum(getmisses) / sum(gets)) "Data Dictionary Hit Ratio" from v$rowcache;
处理措施:
如果Data Dictionary Hit Ratio的值低于95%,应调高shared_pool_size的大小。通过sqlplus连接数据库执行如下命令,调整shared_pool_size的大小:
SQL>alter system flush shared_pool; SQL>alter system set shared_pool_size=设定值 scope=spfile;
3.4 检查ORACLE实例的Log Buffer命中率:
标准:一般是小于1%
检查方式:
select (req.value * 5000) / entries.value "Ratio" from v$sysstat req, v$sysstat entries where req.name = 'redo log space requests' and entries.name = 'redo entries';
处理措施:
如果Ratio高于1%,应调高log_buffer的大小。通过sqlplus连接数据库执行如下命令,调整log_buffer的大小:
SQL>alter system set log_buffer=设定值 scope=spfile;
3.5 检查undo_retention:
标准:undo_retention 的值必须大于max(maxquerylen)的值
检查方式:
col undo_retention format a30
select value "undo_retention" from v$parameter where name='undo_retention';
select max(maxquerylen) From v$undostat Where begin_time>sysdate-(1/4);处理措施:
如果不满足要求,需要调高undo_retention 的值。通过sqlplus 连接数据库执行如下命令,调整undo_retention 的大小:
SQL>alter system set undo_retention= 设定值 scope=spfile;
注:
32bit 和 64bit 的问题
对于 oracle 来说,存在着 32bit 与 64bit 的问题。这个问题影响到的主要是 SGA 的大小。在 32bit 的数据库下,通常 oracle 只能使用不超过 1.7G 的内存,即使我们拥有 12G 的内存,但是我们却只能使用 1.7G,这是一个莫大的遗憾。假如我们安装 64bit 的数据库,我们就可以使用很大的内存,我们几乎不可能达到上限。但是 64bit 的数据库必须安装在 64bit 的操作系统上,可惜目前 windows 上只能安装 32bit 的数据库,我们通过下面的方式可以查看数据库是 32bit 还是 64bit
Tetapi di bawah sistem pengendalian tertentu, cara tertentu mungkin disediakan, membolehkan kami menggunakan lebih daripada 1.7G memori, mencapai lebih daripada 2G atau lebih.
Tutorial yang disyorkan: "Tutorial Oracle"
Atas ialah kandungan terperinci Ringkaskan dan atur peruntukan memori dan penalaan pembelajaran oracle. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1378
1378
 52
52

 Cara memeriksa saiz meja oracle
Apr 11, 2025 pm 08:15 PM
Cara memeriksa saiz meja oracle
Apr 11, 2025 pm 08:15 PM
Untuk menanyakan saiz ruang meja oracle, ikuti langkah -langkah berikut: Tentukan nama meja dengan menjalankan pertanyaan: pilih Tablespace_Name dari DBA_TableSpaces; Tanya saiz meja dengan menjalankan pertanyaan: pilih jumlah (bait) sebagai total_size, jumlah (bytes_free) sebagai tersedia_space, jumlah (bytes) - jumlah (bytes_free) sebagai digunakan_space dari dba_data_files di mana tablespace_
 Cara menyulitkan pandangan oracle
Apr 11, 2025 pm 08:30 PM
Cara menyulitkan pandangan oracle
Apr 11, 2025 pm 08:30 PM
Penyulitan Oracle View membolehkan anda menyulitkan data dalam pandangan, dengan itu meningkatkan keselamatan maklumat sensitif. Langkah -langkah termasuk: 1) mewujudkan kunci penyulitan induk (MEK); 2) mencipta pandangan yang disulitkan, menyatakan pandangan dan MEK untuk disulitkan; 3) Memberi kuasa pengguna untuk mengakses pandangan yang disulitkan. Bagaimana pandangan yang disulitkan berfungsi: Apabila permintaan pengguna untuk paparan yang disulitkan, Oracle menggunakan MEK untuk menyahsulit data, memastikan bahawa hanya pengguna yang diberi kuasa dapat mengakses data yang boleh dibaca.
 Cara membuat jadual di oracle
Apr 11, 2025 pm 08:00 PM
Cara membuat jadual di oracle
Apr 11, 2025 pm 08:00 PM
Mewujudkan Jadual Oracle melibatkan langkah -langkah berikut: Gunakan sintaks Create Table untuk menentukan nama jadual, nama lajur, jenis data, kekangan, dan nilai lalai. Nama jadual harus ringkas dan deskriptif, dan tidak boleh melebihi 30 aksara. Nama lajur hendaklah menjadi deskriptif, dan jenis data menentukan jenis data yang disimpan dalam lajur. Kekangan tidak null memastikan bahawa nilai null tidak dibenarkan dalam lajur, dan klausa lalai menentukan nilai lalai untuk lajur. Kekangan utama utama untuk mengenal pasti rekod unik jadual. Kekangan utama asing menentukan bahawa lajur dalam jadual merujuk kepada kunci utama dalam jadual lain. Lihat penciptaan pelajar jadual sampel, yang mengandungi kunci utama, kekangan unik, dan nilai lalai.
 Cara mengimport pangkalan data oracle
Apr 11, 2025 pm 08:06 PM
Cara mengimport pangkalan data oracle
Apr 11, 2025 pm 08:06 PM
Kaedah Import Data: 1. Gunakan utiliti SQLLoader: Sediakan fail data, buat fail kawalan, dan jalankan SQLLoader; 2. Gunakan alat IMP/EXP: data eksport, data import. Petua: 1. Disyorkan SQL*loader untuk set data besar; 2. Jadual sasaran harus wujud dan perlawanan definisi lajur; 3. Selepas mengimport, integriti data perlu disahkan.
 Cara menyahpasang pemasangan Oracle gagal
Apr 11, 2025 pm 08:24 PM
Cara menyahpasang pemasangan Oracle gagal
Apr 11, 2025 pm 08:24 PM
Nyahpasang Kaedah untuk kegagalan pemasangan Oracle: Tutup Perkhidmatan Oracle, Padam Fail Program Oracle dan Kekunci Pendaftaran, Nyahpasang pembolehubah persekitaran Oracle, dan mulakan semula komputer. Jika penyahpasang gagal, anda boleh menyahpasang secara manual menggunakan alat penyahpasang Oracle Universal.
 Cara melihat contoh nama oracle
Apr 11, 2025 pm 08:18 PM
Cara melihat contoh nama oracle
Apr 11, 2025 pm 08:18 PM
Terdapat tiga cara untuk melihat nama contoh di Oracle: Gunakan "sqlplus" dan "pilih instance_name dari v $ instance;" Perintah pada baris arahan. Gunakan "pertunjukan instance_name;" Perintah dalam SQL*Plus. Semak Pembolehubah Alam Sekitar (ORACLE_SID pada Linux) melalui Pengurus Tugas Sistem Operasi, Pengurus Oracle Enterprise, atau melalui sistem operasi.
 Cara Mendapatkan Masa di Oracle
Apr 11, 2025 pm 08:09 PM
Cara Mendapatkan Masa di Oracle
Apr 11, 2025 pm 08:09 PM
Terdapat kaedah berikut untuk mendapatkan masa di Oracle: Current_TimeStamp: Mengembalikan masa sistem semasa, tepat untuk beberapa saat. SystimeStamp: Lebih tepat daripada Current_TimeStamp, kepada nanodekonda. SYSDATE: Mengembalikan tarikh sistem semasa, tidak termasuk bahagian masa. To_char (sysdate, 'yyy-mm-dd hh24: mi: ss'): Menukar tarikh dan masa sistem semasa ke format tertentu. Ekstrak: Ekstrak bahagian tertentu dari nilai masa, seperti tahun, bulan, atau jam.
 Cara Membaca Laporan Oracle AWR
Apr 11, 2025 pm 09:45 PM
Cara Membaca Laporan Oracle AWR
Apr 11, 2025 pm 09:45 PM
Laporan AWR adalah laporan yang memaparkan prestasi pangkalan data dan snapshot aktiviti. Langkah -langkah tafsiran termasuk: mengenal pasti tarikh dan masa snapshot aktiviti. Lihat gambaran keseluruhan aktiviti dan penggunaan sumber. Menganalisis aktiviti sesi untuk mencari jenis sesi, penggunaan sumber, dan acara menunggu. Cari kemunculan prestasi yang berpotensi seperti pernyataan SQL yang perlahan, perbalahan sumber, dan isu I/O. Lihat acara menunggu, mengenal pasti dan menyelesaikannya untuk prestasi. Menganalisis corak penggunaan selak dan memori untuk mengenal pasti isu memori yang menyebabkan masalah prestasi.
