
 pembangunan bahagian belakang
Tutorial Python
Pemahaman mendalam tentang pemprosesan dan visualisasi data Python
pembangunan bahagian belakang
Tutorial Python
Pemahaman mendalam tentang pemprosesan dan visualisasi data Python
Pemahaman mendalam tentang pemprosesan dan visualisasi data Python

Artikel ini membawa anda pengetahuan yang berkaitan tentang python, yang terutamanya memperkenalkan isu berkaitan pemprosesan dan visualisasi data, termasuk penggunaan awal NumPy, penggunaan pakej Matplotlib dan statistik data Paparan visual, dsb. I semoga ianya bermanfaat kepada semua.

Pembelajaran yang disyorkan: tutorial python
1. Penggunaan awal NumPy
Jadual ialah perwakilan umum data. bentuk, tetapi ia tidak dapat difahami oleh mesin, iaitu, ia adalah data yang tidak dapat dikenali, jadi kita perlu menyesuaikan bentuk jadual.
Perwakilan pembelajaran mesin yang biasa digunakan ialah matriks data. 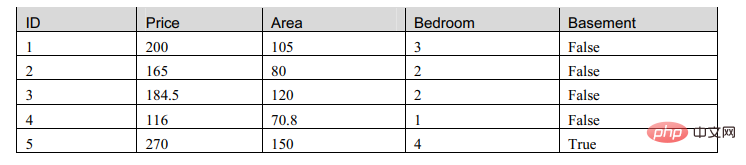
Kami memerhatikan jadual ini dan mendapati terdapat dua jenis atribut dalam matriks, satu jenis angka dan satu lagi jenis Boolean. Jadi kita kini akan membina model untuk menerangkan jadual ini:
# 数据的矩阵化import numpy as np data = np.mat([[1,200,105,3,False],[2,165,80,2,False],[3,184.5,120,2,False], [4,116,70.8,1,False],[5,270,150,4,True]])row = 0for line in data: row += 1print( row )print(data.size)print(data)
Barisan pertama kod di sini bermaksud memperkenalkan NumPy dan menamakan semula ia kepada np. Dalam baris kedua, kami menggunakan kaedah mat() dalam NumPy untuk mencipta matriks data, dan baris ialah pembolehubah yang diperkenalkan untuk mengira bilangan baris.
Saiz di sini bermaksud jadual 5*5 Anda boleh melihat data dengan mencetak data secara terus: 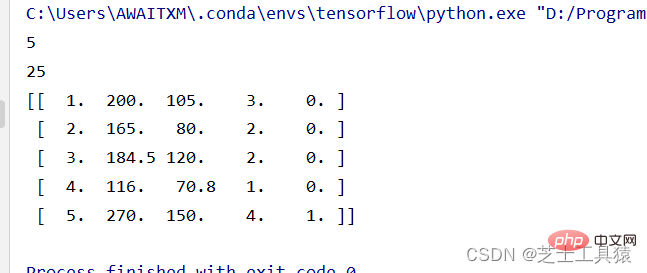
2. Penggunaan pakej Matplotlib – pemprosesan data grafik
Mari kita lihat pada jadual atas Lajur kedua adalah perbezaan harga perumahan Tidak mudah untuk melihat perbezaan secara intuitif (kerana hanya ada nombor), jadi kami berharap untuk menariknya (Kaedah Penyelidikan. perbezaan berangka dan anomali adalah untuk melukis darjah pengedaran data ):
import numpy as npimport scipy.stats as statsimport pylab data = np.mat([[1,200,105,3,False],[2,165,80,2,False],[3,184.5,120,2,False], [4,116,70.8,1,False],[5,270,150,4,True]])coll = []for row in data: coll.append(row[0,1])stats.probplot(coll,plot=pylab)pylab.show()
Hasil kod ini adalah untuk menjana graf: 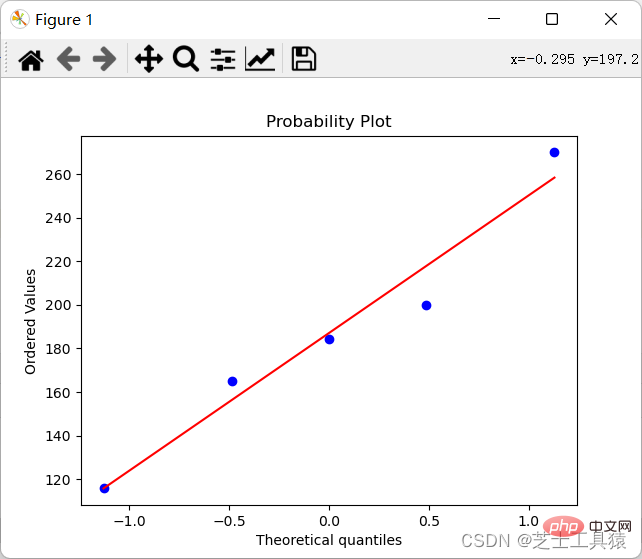
Dengan cara ini kita boleh nampak dengan jelas perbezaannya.
Keperluan carta koordinat adalah untuk menunjukkan nilai khusus data melalui baris dan lajur yang berbeza.
Sudah tentu, kita juga boleh memaparkan gambar rajah koordinat: 
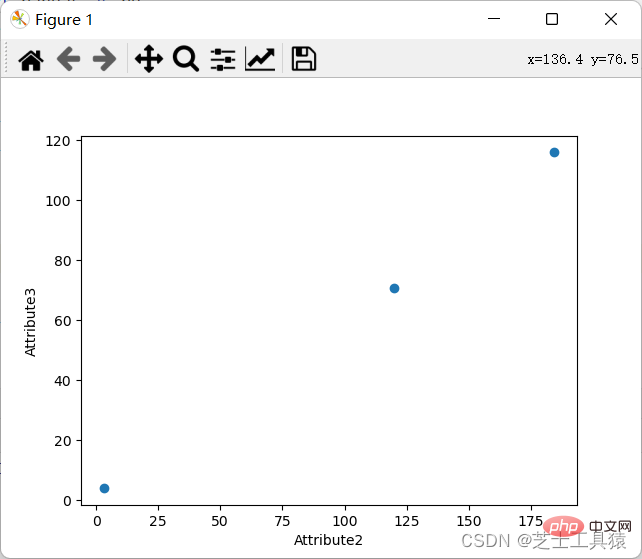
3 Kaedah teori pembelajaran mendalam – pengiraan persamaan (boleh dilangkau)
Persamaan. Terdapat banyak kaedah pengiraan, dan kami memilih dua yang paling biasa digunakan, iaitu persamaan Euclidean dan pengiraan persamaan kosinus.
1. Pengiraan persamaan berdasarkan jarak Euclidean
Jarak Euclidean digunakan untuk mewakili jarak sebenar antara dua titik dalam ruang tiga dimensi. Kita semua tahu formulanya, tetapi kita jarang mendengar nama: 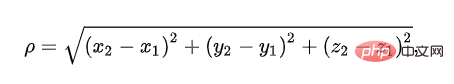
Kemudian mari kita lihat aplikasi praktikalnya:
Jadual ini menunjukkan penilaian item oleh tiga pengguna: 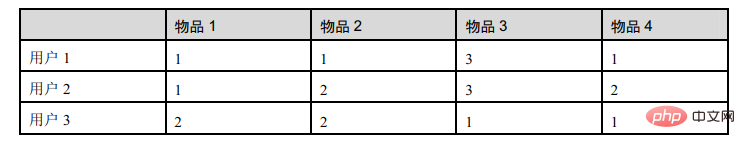
d12 mewakili persamaan antara pengguna 1 dan pengguna 2, maka terdapat: 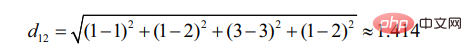
Begitu juga d13: 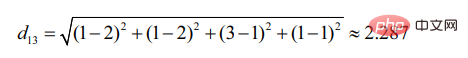
Dapat dilihat pengguna 2 adalah lebih serupa dengan Pengguna 1 (semakin kecil jarak, semakin besar persamaan).
2. Pengiraan persamaan berdasarkan sudut kosinus
Titik permulaan untuk pengiraan sudut kosinus ialah perbezaan sudut yang disertakan. 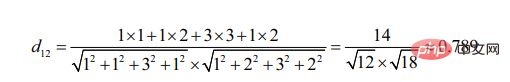
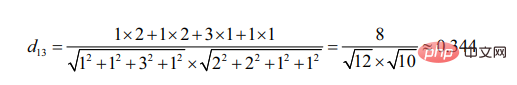
Dapat dilihat berbanding pengguna 3, pengguna 2 lebih serupa dengan pengguna 1 (semakin serupa kedua-dua sasaran, semakin kecil sudut yang terbentuk mengikut segmen garisan mereka)
4 Paparan visual statistik data (mengambil kerpasan kami di Bandar Bozhou sebagai contoh)
Kuartil data
The. kuartil ialah titik median statistik Sejenis digit, iaitu, data disusun dari kecil ke besar, dan kemudian dibahagikan kepada empat bahagian yang sama Data pada tiga titik pembahagi ialah kuartil.
Kuartil pertama (Q1), juga dikenali sebagai Kuartil bawah;
Kuartil kedua (Q1), juga dipanggil median;
kuartil ketiga (Q1) , juga dipanggil kuartil bawah; juga dipanggil jurang empat mata (IQR).
若n为项数,则: 四分位示例: 以下是plot运行结果: 那么每月的降水增减程度如何比较? 结果如图: 那么每月降水是否相关? 结果如图: 今天就记录到这里了,我们下次再见!希望本文章对你也有所帮助。 推荐学习:python学习教程
Q1的位置 = (n+1)*0.25
Q2的位置 = (n+1)*0.50
Q3的位置 = (n+1)*0.75
关于这个rain.csv,有需要的可以私我要文件,我使用的是亳州市2010-2019年的月份降水情况。from pylab import *import pandas as pdimport matplotlib.pyplot as plot
filepath = ("C:\\Users\\AWAITXM\\Desktop\\rain.csv")# "C:\Users\AWAITXM\Desktop\rain.csv"dataFile = pd.read_csv(filepath)summary = dataFile.describe()print(summary)array = dataFile.iloc[:,:].values
boxplot(array)plot.xlabel("year")plot.ylabel("rain")show()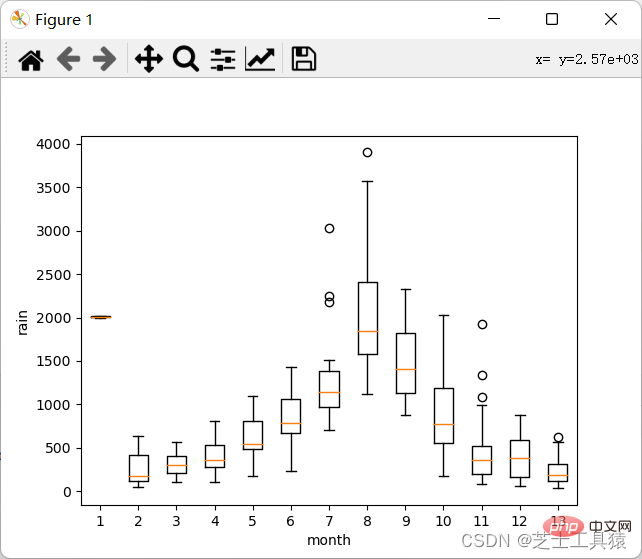
这个是pandas的运行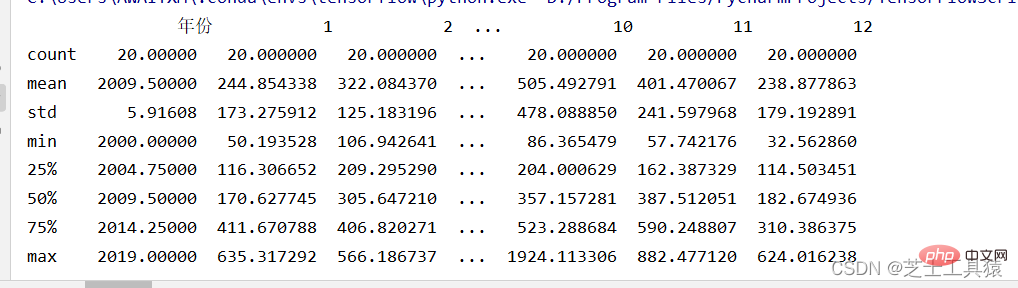
这里就可以很清晰的看出来数据的波动范围。
可以看出,不同月份的降水量有很大差距,8月最多,1-4月和10-12月最少。from pylab import *import pandas as pdimport matplotlib.pyplot as plot
filepath = ("C:\\Users\\AWAITXM\\Desktop\\rain.csv")# "C:\Users\AWAITXM\Desktop\rain.csv"dataFile = pd.read_csv(filepath)summary = dataFile.describe()minRings = -1maxRings = 99nrows = 11for i in range(nrows):
dataRow = dataFile.iloc[i,1:13]
labelColor = ( (dataFile.iloc[i,12] - minRings ) / (maxRings - minRings) )
dataRow.plot(color = plot.cm.RdYlBu(labelColor),alpha = 0.5)plot.xlabel("Attribute")plot.ylabel(("Score"))show()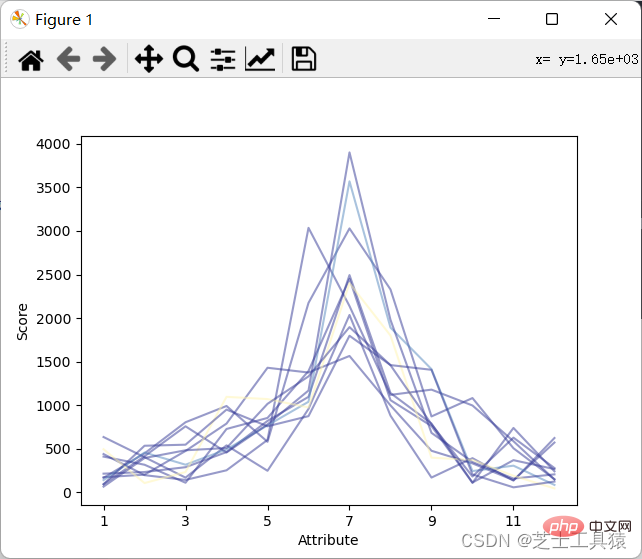
可以看出来降水月份并不规律的上涨或下跌。from pylab import *import pandas as pdimport matplotlib.pyplot as plot
filepath = ("C:\\Users\\AWAITXM\\Desktop\\rain.csv")# "C:\Users\AWAITXM\Desktop\rain.csv"dataFile = pd.read_csv(filepath)summary = dataFile.describe()corMat = pd.DataFrame(dataFile.iloc[1:20,1:20].corr())plot.pcolor(corMat)plot.show()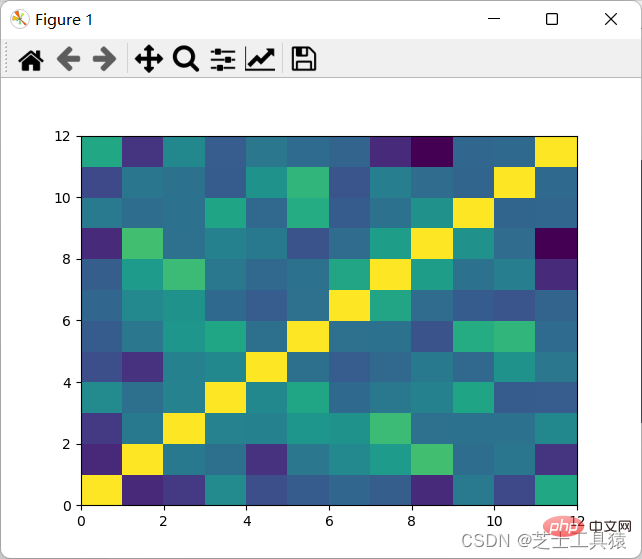
可以看出,颜色分布十分均匀,表示没有多大的相关性,因此可以认为每月的降水是独立行为。
Atas ialah kandungan terperinci Pemahaman mendalam tentang pemprosesan dan visualisasi data Python. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas



 Bagaimana untuk menyelesaikan masalah kebenaran yang dihadapi semasa melihat versi Python di Terminal Linux?
Apr 01, 2025 pm 05:09 PM
Bagaimana untuk menyelesaikan masalah kebenaran yang dihadapi semasa melihat versi Python di Terminal Linux?
Apr 01, 2025 pm 05:09 PM
Penyelesaian kepada Isu Kebenaran Semasa Melihat Versi Python di Terminal Linux Apabila anda cuba melihat versi Python di Terminal Linux, masukkan Python ...
 Bagaimana cara menyalin seluruh lajur satu data ke dalam data data lain dengan struktur yang berbeza di Python?
Apr 01, 2025 pm 11:15 PM
Bagaimana cara menyalin seluruh lajur satu data ke dalam data data lain dengan struktur yang berbeza di Python?
Apr 01, 2025 pm 11:15 PM
Apabila menggunakan Perpustakaan Pandas Python, bagaimana untuk menyalin seluruh lajur antara dua data data dengan struktur yang berbeza adalah masalah biasa. Katakan kita mempunyai dua DAT ...
 Python Hourglass Graph Lukisan: Bagaimana untuk mengelakkan kesilapan yang tidak ditentukan?
Apr 01, 2025 pm 06:27 PM
Python Hourglass Graph Lukisan: Bagaimana untuk mengelakkan kesilapan yang tidak ditentukan?
Apr 01, 2025 pm 06:27 PM
Bermula dengan Python: Lukisan Grafik Hourglass dan Pengesahan Input Artikel ini akan menyelesaikan masalah definisi berubah -ubah yang dihadapi oleh pemula python dalam program lukisan grafik Hourglass. Kod ...
 Bagaimanakah skrip Python jelas output ke kedudukan kursor di lokasi tertentu?
Apr 01, 2025 pm 11:30 PM
Bagaimanakah skrip Python jelas output ke kedudukan kursor di lokasi tertentu?
Apr 01, 2025 pm 11:30 PM
Bagaimanakah skrip Python jelas output ke kedudukan kursor di lokasi tertentu? Semasa menulis skrip python, adalah perkara biasa untuk membersihkan output sebelumnya ke kedudukan kursor ...
 Pembangunan Aplikasi Desktop Cross-Platform Python: Perpustakaan GUI mana yang terbaik untuk anda?
Apr 01, 2025 pm 05:24 PM
Pembangunan Aplikasi Desktop Cross-Platform Python: Perpustakaan GUI mana yang terbaik untuk anda?
Apr 01, 2025 pm 05:24 PM
Pilihan Perpustakaan Pembangunan Aplikasi Desktop Python Python Banyak pemaju Python ingin membangunkan aplikasi desktop yang boleh dijalankan pada kedua-dua sistem Windows dan Linux ...
 Bolehkah anotasi parameter Python menggunakan rentetan?
Apr 01, 2025 pm 08:39 PM
Bolehkah anotasi parameter Python menggunakan rentetan?
Apr 01, 2025 pm 08:39 PM
Penggunaan alternatif anotasi parameter python Dalam pengaturcaraan Python, anotasi parameter adalah fungsi yang sangat berguna yang dapat membantu pemaju memahami dan menggunakan fungsi ...
 Bagaimana secara dinamik membuat objek melalui rentetan dan panggil kaedahnya dalam Python?
Apr 01, 2025 pm 11:18 PM
Bagaimana secara dinamik membuat objek melalui rentetan dan panggil kaedahnya dalam Python?
Apr 01, 2025 pm 11:18 PM
Di Python, bagaimana untuk membuat objek secara dinamik melalui rentetan dan panggil kaedahnya? Ini adalah keperluan pengaturcaraan yang biasa, terutamanya jika perlu dikonfigurasikan atau dijalankan ...
 Adakah Google dan AWS menyediakan sumber imej Pypi awam?
Apr 01, 2025 pm 05:15 PM
Adakah Google dan AWS menyediakan sumber imej Pypi awam?
Apr 01, 2025 pm 05:15 PM
Ramai pemaju bergantung kepada PYPI (PythonPackageIndex) ...
