

Koleksi Soal Jawab temu bual MySQL (perkongsian ringkasan)

Artikel ini membawakan anda pengetahuan yang berkaitan tentang mysql Terutamanya ia menyusun beberapa soalan lazim dalam temu bual, termasuk seni bina pangkalan data, pengindeksan dan pengoptimuman SQL, dsb. Semoga ia membantu semua orang.

Pembelajaran yang disyorkan: tutorial mysql
1.1 Gambar
Beritahu penemuduga tentang seni bina logik MySQL Jika anda mempunyai papan putih, anda boleh melukis gambar berikut.
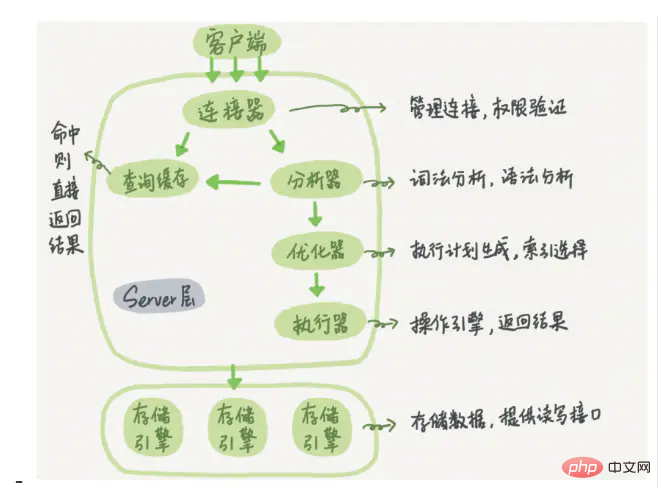 Rajah seni bina logik MySQL terbahagi terutamanya kepada tiga lapisan:
Rajah seni bina logik MySQL terbahagi terutamanya kepada tiga lapisan:
(1) Lapisan pertama bertanggungjawab untuk pemprosesan sambungan, pengesahan kebenaran, keselamatan, dsb. .
(2) Lapisan kedua bertanggungjawab untuk menyusun dan mengoptimumkan SQL
(3) Lapisan ketiga ialah enjin storan.
1.2. Bagaimanakah pernyataan pertanyaan SQL dilaksanakan dalam MySQL?
- Semak pernyataan
- terlebih dahulu Jika tiada kebenaran, mesej ralat akan dikembalikan secara langsung Jika ada kebenaran, cache akan ditanya terlebih dahulu (sebelum MySQL8.0 versi).
是否有权限Jika tiada cache, penganalisis akan melaksanakan - , ekstrak elemen utama seperti pilih dalam pernyataan sql, dan kemudian tentukan sama ada pernyataan sql mempunyai ralat sintaks, seperti sama ada kata kunci itu betul, dsb.
词法分析Akhir sekali, pengoptimum menentukan pelan pelaksanaan dan melakukan pengesahan kebenaran Jika tiada kebenaran, ia akan mengembalikan mesej ralat secara langsung. Jika ada kebenaran, ia akan - dan kembalikan hasil pelaksanaan.
调用数据库引擎接口2. Pengoptimuman SQL
2.1.
Anda boleh menjawab soalan ini dari dimensi ini:
2.1.1,
Optimumkan struktur jadual(1) Cuba gunakan medan angka
Jika medan yang hanya mengandungi maklumat berangka harus direka bentuk sebagai jenis aksara, ia akan mengurangkan pertanyaan dan prestasi sambungan serta meningkatkan overhed storan. Ini kerana enjin akan membandingkan setiap aksara dalam rentetan satu demi satu apabila memproses pertanyaan dan sambungan, dan hanya satu perbandingan yang mencukupi untuk jenis angka.
(2) Gunakan varchar dan bukannya char sebanyak mungkin
Medan panjang boleh ubah mempunyai ruang storan yang kecil dan boleh menjimatkan ruang storan.
(3) Apabila terdapat sejumlah besar data pendua dalam lajur indeks, indeks boleh dipadamkan
Sebagai contoh, jika terdapat lajur untuk jantina, hampir hanya lelaki, perempuan , dan tidak diketahui, indeks sedemikian adalah tidak sah.
2.1.2,
Optimumkan pertanyaan- Anda harus cuba mengelak daripada menggunakan != atau operator
- Anda harus cuba mengelak daripada menggunakan atau dalam klausa di mana untuk menyambung syarat
- Jangan muncul pilih *
Elakkan pertimbangan nilai nol pada medan dalam klausa where
-
2.1.3,
Pengoptimuman indeks
Buat indeks untuk medan yang berfungsi sebagai syarat pertanyaan dan tertib mengikut
Elakkan membuat terlalu banyak indeks dan gunakan indeks gabungan
2.2 untuk membaca rancangan pelaksanaan (menerangkan) dan memahami maksud setiap bidang di dalamnya?
Tambahkan kata kunci explain sebelum pernyataan pilih untuk mengembalikan maklumat pelan pelaksanaan.
 (2) lajur select_type: Menunjukkan sama ada baris yang sepadan ialah pertanyaan ringkas atau kompleks.
(2) lajur select_type: Menunjukkan sama ada baris yang sepadan ialah pertanyaan ringkas atau kompleks.
(3) lajur jadual: Menunjukkan jadual yang satu baris explain sedang diakses.
(4) jenis lajur: salah satu lajur yang paling penting. Mewakili jenis perkaitan atau jenis akses yang MySQL tentukan cara mencari baris dalam jadual. Dari yang terbaik kepada yang paling teruk: sistem > eq_ref > : Menunjukkan indeks mana yang boleh digunakan oleh pertanyaan untuk mencari.
(6) lajur kunci: Lajur ini menunjukkan indeks mysql yang sebenarnya digunakan untuk mengoptimumkan akses kepada jadual.
(7) lajur key_len: menunjukkan bilangan bait yang digunakan oleh mysql dalam indeks Nilai ini boleh digunakan untuk mengira lajur dalam indeks yang digunakan.
(8) lajur rujukan: Lajur ini menunjukkan lajur atau pemalar yang digunakan oleh jadual untuk mencari nilai dalam indeks rekod lajur utama ialah: const (constant), func, NULL , nama medan.
(9) lajur baris: Lajur ini ialah bilangan baris yang dianggarkan oleh mysql untuk dibaca dan dikesan. Ambil perhatian bahawa ini bukan bilangan baris dalam set hasil.
(10) Lajur tambahan: Paparkan maklumat tambahan. Sebagai contoh, terdapat indeks Menggunakan, Menggunakan di mana, Menggunakan sementara, dll.
2.3 Pernahkah anda mengambil berat tentang SQL yang memakan masa dalam sistem perniagaan? Adakah statistik pertanyaan terlalu perlahan? Bagaimanakah anda telah mengoptimumkan pertanyaan perlahan?
Apabila kita biasanya menulis Sql, kita mesti membangunkan tabiat menggunakan analisis explain. Statistik pertanyaan lambat, operasi dan penyelenggaraan akan sentiasa memberi kami statistik
Idea untuk mengoptimumkan pertanyaan perlahan:
-
Analisis penyataan untuk melihat sama ada medan/data yang tidak perlu dimuatkan
Analisis ayat pelaksanaan SQL, sama ada ia mencecah indeks, dsb.
Jika SQL kompleks, optimumkan struktur SQL
Jika jumlah data jadual terlalu besar, pertimbangkan untuk membahagikan jadual
3.1 dan indeks bukan berkelompok
Anda boleh menekan Jawapan daripada empat dimensi berikut:
(1) Jadual hanya boleh mempunyai satu indeks berkelompok, manakala jadual boleh mempunyai berbilang indeks bukan berkelompok.
(2) Indeks berkelompok, susunan logik nilai utama dalam indeks menentukan susunan fizikal baris yang sepadan dalam jadual, susunan logik indeks dalam indeks; adalah berbeza daripada susunan storan fizikal bagi baris pada cakera.
(3) Indeks diterangkan melalui struktur data pokok binari Kita boleh memahami indeks berkelompok dengan cara ini: nod daun indeks ialah nod data. Nod daun bagi indeks bukan berkelompok masih merupakan nod indeks, tetapi mempunyai penunjuk yang menunjuk ke blok data yang sepadan.
(4) Indeks berkelompok: storan fizikal diisih mengikut indeks; kenapa bukan pokok binari biasa?
Anda boleh melihat masalah ini dari beberapa dimensi, sama ada pertanyaan itu cukup pantas, sama ada kecekapannya stabil, berapa banyak data yang disimpan dan bilangan carian cakera Mengapa ia bukan pokok binari biasa , mengapa ia bukan pokok binari yang seimbang, mengapa ia bukan pokok B, dan Bagaimana pula dengan pokok B?
3.2.1 Mengapa bukan pokok binari biasa?
Jika pepohon binari dikhususkan ke dalam senarai terpaut, ia bersamaan dengan imbasan jadual penuh. Berbanding dengan pokok carian binari, pokok binari seimbang mempunyai kecekapan carian yang lebih stabil dan kelajuan carian keseluruhan yang lebih pantas.
3.2.2 Mengapa bukan pokok binari yang seimbang?
Kami tahu bahawa menanyakan data dalam memori adalah lebih pantas daripada pada cakera. Jika struktur data seperti pokok digunakan sebagai indeks, maka setiap kali kita mencari data, kita perlu membaca nod dari cakera, iaitu apa yang kita panggil blok cakera, tetapi pokok binari yang seimbang hanya menyimpan satu nilai kunci. dan data bagi setiap nod. Jika ia adalah pokok B, lebih banyak data nod boleh disimpan, dan ketinggian pokok itu juga akan dikurangkan, jadi bilangan bacaan cakera akan dikurangkan, dan kecekapan pertanyaan akan menjadi lebih cepat.
3.2.3 Mengapa bukan B-tree tetapi B-tree?
B-tree nod bukan daun tidak menyimpan data, hanya nilai utama, manakala B-tree nod bukan sahaja menyimpan nilai utama, tetapi juga menyimpan data. Saiz lalai halaman dalam innodb ialah 16KB Jika tiada data disimpan, lebih banyak nilai kunci akan disimpan, susunan pokok yang sepadan (pokok nod anak nod) akan menjadi lebih besar, dan pokok itu akan menjadi. lebih pendek dan lebih gemuk Dengan cara ini, bilangan kali IO cakera yang kita perlukan untuk mencari data akan dikurangkan lagi, dan kecekapan pertanyaan data akan menjadi lebih cepat.
Semua data dalam indeks B-tree disimpan dalam nod daun dan data disusun mengikut susunan serta senarai terpaut. Kemudian B-tree menjadikan carian julat, carian isihan, carian kumpulan dan carian deduplikasi sangat mudah.
3.3. Apakah perbezaan antara indeks Hash dan indeks B-tree? Bagaimanakah anda memilih untuk mereka bentuk indeks?
B-tree boleh melakukan pertanyaan julat, indeks Hash tidak boleh.
B-tree menyokong prinsip paling kiri indeks kesatuan, tetapi indeks Hash tidak.
B-tree menyokong pesanan dengan mengisih, tetapi indeks Hash tidak menyokongnya.
Indeks cincang lebih cekap daripada B-tree untuk pertanyaan yang setara.
Apabila B-tree menggunakan suka untuk pertanyaan kabur, perkataan selepas suka (seperti bermula dengan %) boleh memainkan peranan pengoptimuman dan indeks Hash tidak boleh melakukan pertanyaan kabur sama sekali.
3.4. Apakah prinsip awalan paling kiri? Apakah prinsip padanan paling kiri?
Prinsip awalan paling kiri ialah keutamaan paling kiri Apabila membuat indeks berbilang lajur, mengikut keperluan perniagaan, lajur yang paling kerap digunakan dalam klausa tempat diletakkan di bahagian paling kiri.
Apabila kita mencipta indeks gabungan, seperti (a1, a2, a3), ia bersamaan dengan mencipta tiga indeks (a1), (a1, a2) dan (a1, a2, a3 This This). ialah prinsip padanan paling kiri.
3.5. Senario manakah yang tidak sesuai untuk pengindeksan
Ia tidak sesuai untuk pengindeksan jika jumlah data adalah kecil
-
Mengemas kini dengan kerap Tidak sesuai untuk pengindeksan = Medan dengan diskriminasi rendah tidak sesuai untuk pengindeksan (seperti jantina)
3.6 Apakah kelebihan dan kekurangan pengindeksan?
(1) Kelebihan:
Indeks unik boleh memastikan keunikan data dalam setiap baris dalam jadual pangkalan data
Indeks Ia boleh mempercepatkan pertanyaan data dan mengurangkan masa pertanyaan
(2) Kelemahan:
Memerlukan masa untuk mencipta dan mengekalkan indeks
Indeks perlu menduduki ruang fizikal Selain ruang data yang diduduki oleh jadual data, setiap indeks juga menduduki sejumlah ruang fizikal
- berdasarkan data dalam jadual Apabila menambah, memadam atau mengubah suai, indeks juga mesti dikekalkan secara dinamik.
- 4. Kunci4.1 Adakah MySQL pernah menghadapi masalah kebuntuan?
(1) Lihat log kebuntuan menunjukkan status enjin innodb;
(2) Ketahui kebuntuan Sql
(3) Analisis situasi kunci sql
( 4) Simulasikan kes kebuntuan
(5) Analisis log kebuntuan
(6) Analisis keputusan kebuntuan
4.2. Bercakap tentang kunci optimistik dan kunci pesimis dalam pangkalan data Apakah itu dan perbezaan mereka?
(1) Kunci pesimis:
Kunci pesimis berfikiran tunggal dan tidak selamat Hatinya hanya berkaitan dengan hal semasa, dan dia sentiasa bimbang data kesayangannya mungkin dicuri. Diubah suai oleh transaksi lain, jadi selepas transaksi memiliki (mendapat) kunci pesimis, tiada transaksi lain boleh mengubah suai data dan hanya boleh menunggu kunci dikeluarkan sebelum melaksanakannya.
(2) Kunci optimistik:
"optimisme" kunci optimistik ditunjukkan dalam fakta bahawa ia percaya bahawa data tidak akan berubah terlalu kerap. Oleh itu, ia membenarkan berbilang transaksi untuk membuat perubahan pada data secara serentak.
Kaedah pelaksanaan: Penguncian optimis secara amnya dilaksanakan menggunakan mekanisme nombor versi atau algoritma CAS.
4.3 Adakah anda biasa dengan MVCC dan mengetahui prinsip asasnya?
MVCC (Multiversion Concurrency Control), iaitu teknologi kawalan penukaran berbilang versi.
Pelaksanaan MVCC dalam MySQL InnoDB adalah terutamanya untuk meningkatkan prestasi konkurensi pangkalan data dan menggunakan cara yang lebih baik untuk mengendalikan konflik baca-tulis, supaya walaupun terdapat konflik baca-tulis, tiada penguncian boleh dicapai -menyekat bacaan serentak.
5. Transaksi
5.1 Empat ciri utama dan prinsip pelaksanaan transaksi MySQL
Atomicity: Transaksi dilaksanakan secara keseluruhan dan adalah. termasuk dalam Sama ada semua operasi pada pangkalan data dilaksanakan, atau tiada satu pun dilaksanakan.
Ketekalan: bermakna data tidak akan dimusnahkan sebelum transaksi bermula dan selepas transaksi tamat Jika akaun A memindahkan 10 yuan ke akaun B, tanpa mengira kejayaan atau kegagalan, A dan B Jumlah keseluruhan kekal tidak berubah.
Pengasingan: Apabila berbilang transaksi mengakses secara serentak, transaksi diasingkan antara satu sama lain, iaitu, satu transaksi tidak menjejaskan kesan berjalan transaksi lain. Ringkasnya, ia bermakna tidak ada konflik antara urusan.
Kegigihan: Menunjukkan bahawa selepas transaksi selesai, perubahan operasi yang dibuat oleh transaksi kepada pangkalan data akan disimpan secara kekal dalam pangkalan data.
5.2 Apakah tahap pengasingan urus niaga? Apakah tahap pengasingan lalai MySQL?
Baca Tanpa Komitmen
Baca Komited
Bacaan Boleh Diulang
Boleh Bersiri
Tahap pengasingan transaksi lalai MySQL ialah Bacaan Boleh Berulang )
5.3.3 Apakah bacaan hantu, bacaan kotor dan bacaan tidak boleh berulang?
Transaksi A dan B dilaksanakan secara bergilir-gilir Transaksi A diganggu oleh transaksi B kerana transaksi A membaca data transaksi B yang tidak dikomit.
Dalam skop transaksi, dua pertanyaan yang sama membaca rekod yang sama tetapi mengembalikan data yang berbeza Ini adalah bacaan yang tidak boleh diulang.
Transaksi A menanyakan set hasil julat, dan satu lagi transaksi serentak B memasukkan/memadamkan data ke dalam julat ini dan melakukannya secara senyap Kemudian transaksi A menanyakan julat yang sama sekali lagi dan membaca set hasil berbeza, iaitu bacaan hantu.
6. Pertempuran praktikal
6.1.
Proses penyelesaian masalah:
(1) Gunakan arahan atas untuk memerhati dan menentukan sama ada ia disebabkan oleh mysqld atau sebab lain.
(2) Jika ia disebabkan oleh mysqld, tunjukkan senarai proses, semak status sesi, dan tentukan sama ada terdapat sebarang SQL yang memakan sumber berjalan.
(3) Ketahui SQL dengan penggunaan tinggi dan lihat sama ada pelan pelaksanaan adalah tepat, sama ada indeks hilang dan sama ada jumlah data terlalu besar.
Pemprosesan:
(1) Matikan benang ini (dan perhatikan sama ada penggunaan CPU berkurangan)
(2) Buat pelarasan yang sepadan (seperti menambah indeks, menukar sql, tukar parameter memori)
(3) Jalankan semula SQL ini.
Situasi lain:
Mungkin juga setiap pernyataan SQL tidak menggunakan banyak sumber, tetapi tiba-tiba, sejumlah besar sesi disambungkan, menyebabkan CPU melonjak. anda perlu berbincang dengan aplikasi Mari analisa mengapa bilangan sambungan meningkat, dan kemudian buat pelarasan yang sepadan, seperti mengehadkan bilangan sambungan, dsb.
6.2 Bagaimana anda menyelesaikan kelewatan tuan-hamba masuk MYSQL?
Replikasi tuan-hamba terbahagi kepada lima langkah: (gambar dari Internet)
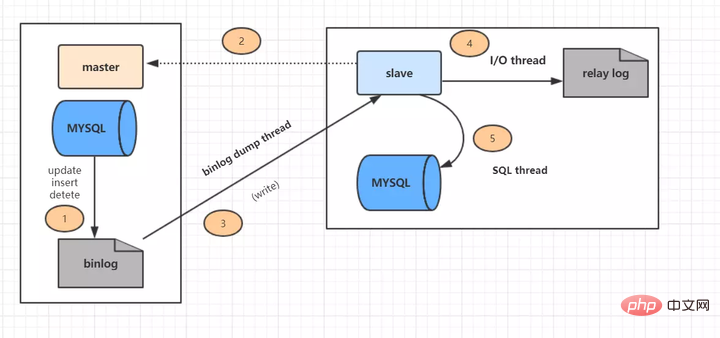
langkah 1: Peristiwa kemas kini (kemas kini, masukkan, padam) perpustakaan utama ditulis ke binlog
Langkah 2: Mulakan sambungan daripada perpustakaan untuk menyambung ke perpustakaan utama.
Langkah 3: Pada masa ini, perpustakaan utama mencipta benang pembuangan binlog dan menghantar kandungan binlog ke perpustakaan hamba.
Langkah 4: Selepas bermula dari perpustakaan, cipta utas I/O, baca kandungan binlog dari perpustakaan utama dan tulis pada log geganti
Langkah 5: Urutan SQL juga akan dibuat untuk membaca kandungan daripada log geganti, melaksanakan acara kemas kini baca bermula dari kedudukan Exec_Master_Log_Pos dan menulis kandungan yang dikemas kini ke db hamba
Punca kelewatan penyegerakan tuan-hamba
Pelayan membuka N pautan untuk disambungkan oleh pelanggan, jadi akan terdapat operasi kemas kini serentak yang besar, tetapi hanya terdapat satu urutan untuk membaca binlog daripada pelayan Apabila SQL tertentu dilaksanakan pada pelayan hamba Jika ia memerlukan a sedikit lebih lama atau kerana SQL tertentu perlu mengunci jadual, akan terdapat banyak tunggakan SQL pada pelayan induk dan ia tidak akan disegerakkan ke pelayan hamba. Ini membawa kepada ketidakkonsistenan tuan-hamba, iaitu kelewatan tuan-hamba.
Penyelesaian kepada kelewatan penyegerakan induk-hamba
Pelayan induk bertanggungjawab untuk operasi kemas kini dan mempunyai keperluan keselamatan yang lebih tinggi daripada pelayan hamba, jadi Beberapa parameter tetapan boleh diubah suai, seperti sync_binlog=1, innodb_flush_log_at_trx_commit = 1 dan tetapan lain.
Pilih peranti perkakasan yang lebih baik sebagai hamba.
Gunakan pelayan hamba sebagai sandaran tanpa memberikan pertanyaan Beban pada bahagian itu dikurangkan, dan kecekapan melaksanakan SQL dalam log geganti secara semula jadi lebih tinggi.
Tujuan menambah pelayan hamba adalah untuk menyebarkan tekanan bacaan dan dengan itu mengurangkan beban pelayan.
6.3 Jika anda diminta untuk mereka bentuk sub-pangkalan data dan sub-jadual, beritahu saya secara ringkas apa yang anda akan lakukan?
Skim pangkalan data dan jadual:
Sub-pangkalan data mendatar: Berdasarkan medan, mengikut strategi tertentu (cincang, julat, dsb. .), Data dalam satu perpustakaan dibahagikan kepada beberapa perpustakaan.
Pecahan jadual mendatar: Pisahkan data dalam satu jadual kepada berbilang jadual berdasarkan medan dan mengikut strategi tertentu (cincang, julat, dll.).
Pembahagian pangkalan data menegak: Berdasarkan jadual, jadual berbeza dibahagikan kepada pangkalan data berbeza mengikut pemilikan perniagaan yang berbeza.
Pemisahan jadual menegak: Berdasarkan medan dan mengikut aktiviti medan, medan dalam jadual dibahagikan kepada jadual yang berbeza (jadual utama dan jadual lanjutan).
Sharding-jdbc middleware yang biasa digunakan:
sharding-jdbc
Mycat
Masalah yang mungkin dihadapi dalam sub-pangkalan data dan sub-jadual
Isu transaksi: Pengedaran diperlukan Jenis transaksi
Masalah Gabungan nod silang: Untuk menyelesaikan masalah ini, ia boleh dilaksanakan dalam dua pertanyaan
Kiraan nod silang , susunan mengikut , kumpulan mengikut dan isu fungsi pengagregatan: keputusan diperoleh pada setiap nod dan kemudian digabungkan pada bahagian aplikasi.
Penghijrahan data, perancangan kapasiti, pengembangan dan isu lain
Masalah ID: Selepas pangkalan data dipecahkan, ia tidak lagi boleh bergantung pada Mekanisme penjanaan kunci utama pangkalan data sendiri, yang paling mudah boleh mempertimbangkan UUID
Isu pengisihan dan halaman halaman
Pembelajaran yang disyorkan: tutorial pembelajaran mysql
Atas ialah kandungan terperinci Koleksi Soal Jawab temu bual MySQL (perkongsian ringkasan). Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1377
1377
 52
52

 MySQL: Kemudahan Pengurusan Data untuk Pemula
Apr 09, 2025 am 12:07 AM
MySQL: Kemudahan Pengurusan Data untuk Pemula
Apr 09, 2025 am 12:07 AM
MySQL sesuai untuk pemula kerana mudah dipasang, kuat dan mudah untuk menguruskan data. 1. Pemasangan dan konfigurasi mudah, sesuai untuk pelbagai sistem operasi. 2. Menyokong operasi asas seperti membuat pangkalan data dan jadual, memasukkan, menanyakan, mengemas kini dan memadam data. 3. Menyediakan fungsi lanjutan seperti menyertai operasi dan subqueries. 4. Prestasi boleh ditingkatkan melalui pengindeksan, pengoptimuman pertanyaan dan pembahagian jadual. 5. Sokongan sokongan, pemulihan dan langkah keselamatan untuk memastikan keselamatan data dan konsistensi.
 Bolehkah saya mengambil kata laluan pangkalan data di Navicat?
Apr 08, 2025 pm 09:51 PM
Bolehkah saya mengambil kata laluan pangkalan data di Navicat?
Apr 08, 2025 pm 09:51 PM
Navicat sendiri tidak menyimpan kata laluan pangkalan data, dan hanya boleh mengambil kata laluan yang disulitkan. Penyelesaian: 1. Periksa Pengurus Kata Laluan; 2. Semak fungsi "Ingat Kata Laluan" Navicat; 3. Tetapkan semula kata laluan pangkalan data; 4. Hubungi pentadbir pangkalan data.
 Mysql: Konsep mudah untuk pembelajaran mudah
Apr 10, 2025 am 09:29 AM
Mysql: Konsep mudah untuk pembelajaran mudah
Apr 10, 2025 am 09:29 AM
MySQL adalah sistem pengurusan pangkalan data sumber terbuka. 1) Buat Pangkalan Data dan Jadual: Gunakan perintah Createdatabase dan Createtable. 2) Operasi Asas: Masukkan, Kemas kini, Padam dan Pilih. 3) Operasi lanjutan: Sertai, subquery dan pemprosesan transaksi. 4) Kemahiran Debugging: Semak sintaks, jenis data dan keizinan. 5) Cadangan Pengoptimuman: Gunakan indeks, elakkan pilih* dan gunakan transaksi.
 Cara Membuat Premium Navicat
Apr 09, 2025 am 07:09 AM
Cara Membuat Premium Navicat
Apr 09, 2025 am 07:09 AM
Buat pangkalan data menggunakan Navicat Premium: Sambungkan ke pelayan pangkalan data dan masukkan parameter sambungan. Klik kanan pada pelayan dan pilih Buat Pangkalan Data. Masukkan nama pangkalan data baru dan set aksara yang ditentukan dan pengumpulan. Sambung ke pangkalan data baru dan buat jadual dalam penyemak imbas objek. Klik kanan di atas meja dan pilih masukkan data untuk memasukkan data.
 Bagaimana untuk melihat kata laluan pangkalan data di Navicat untuk MariaDB?
Apr 08, 2025 pm 09:18 PM
Bagaimana untuk melihat kata laluan pangkalan data di Navicat untuk MariaDB?
Apr 08, 2025 pm 09:18 PM
Navicat untuk MariaDB tidak dapat melihat kata laluan pangkalan data secara langsung kerana kata laluan disimpan dalam bentuk yang disulitkan. Untuk memastikan keselamatan pangkalan data, terdapat tiga cara untuk menetapkan semula kata laluan anda: Tetapkan semula kata laluan anda melalui Navicat dan tetapkan kata laluan yang kompleks. Lihat fail konfigurasi (tidak disyorkan, risiko tinggi). Gunakan alat baris perintah sistem (tidak disyorkan, anda perlu mahir dalam alat baris arahan).
 MySQL dan SQL: Kemahiran Penting untuk Pemaju
Apr 10, 2025 am 09:30 AM
MySQL dan SQL: Kemahiran Penting untuk Pemaju
Apr 10, 2025 am 09:30 AM
MySQL dan SQL adalah kemahiran penting untuk pemaju. 1.MYSQL adalah sistem pengurusan pangkalan data sumber terbuka, dan SQL adalah bahasa standard yang digunakan untuk mengurus dan mengendalikan pangkalan data. 2.MYSQL menyokong pelbagai enjin penyimpanan melalui penyimpanan data yang cekap dan fungsi pengambilan semula, dan SQL melengkapkan operasi data yang kompleks melalui pernyataan mudah. 3. Contoh penggunaan termasuk pertanyaan asas dan pertanyaan lanjutan, seperti penapisan dan penyortiran mengikut keadaan. 4. Kesilapan umum termasuk kesilapan sintaks dan isu -isu prestasi, yang boleh dioptimumkan dengan memeriksa penyataan SQL dan menggunakan perintah menjelaskan. 5. Teknik pengoptimuman prestasi termasuk menggunakan indeks, mengelakkan pengimbasan jadual penuh, mengoptimumkan operasi menyertai dan meningkatkan kebolehbacaan kod.
 Cara Membuat Sambungan Baru ke MySQL di Navicat
Apr 09, 2025 am 07:21 AM
Cara Membuat Sambungan Baru ke MySQL di Navicat
Apr 09, 2025 am 07:21 AM
Anda boleh membuat sambungan MySQL baru di Navicat dengan mengikuti langkah -langkah: Buka aplikasi dan pilih Sambungan Baru (Ctrl N). Pilih "MySQL" sebagai jenis sambungan. Masukkan nama host/alamat IP, port, nama pengguna, dan kata laluan. (Pilihan) Konfigurasikan pilihan lanjutan. Simpan sambungan dan masukkan nama sambungan.
 Cara Melaksanakan SQL di Navicat
Apr 08, 2025 pm 11:42 PM
Cara Melaksanakan SQL di Navicat
Apr 08, 2025 pm 11:42 PM
Langkah -langkah untuk melaksanakan SQL di Navicat: Sambungkan ke pangkalan data. Buat tetingkap editor SQL. Tulis pertanyaan SQL atau skrip. Klik butang Run untuk melaksanakan pertanyaan atau skrip. Lihat hasilnya (jika pertanyaan dilaksanakan).
