

Ringkasan isu untuk menyatukan asas MySQL

Artikel ini membawakan anda pengetahuan yang berkaitan tentang mysql terutamanya meringkaskan beberapa masalah biasa dan menyelesaikannya, termasuk yang konvensional, serta kelas indeks, kelas prinsip dan kelas rangka kerja, saya harap akan membantu semua orang.

Pembelajaran yang disyorkan: tutorial video mysql
Artikel biasa
1. Beritahu kami tentang tiga paradigma utama pangkalan data?
Bentuk normal pertama: atomicity medan, bentuk normal kedua: baris unik, dengan lajur kunci primer, bentuk normal ketiga: setiap lajur berkaitan dengan lajur kunci primer.
Dalam aplikasi sebenar, sebilangan kecil medan berlebihan akan digunakan untuk mengurangkan bilangan jadual berkaitan dan meningkatkan kecekapan pertanyaan.
2. Hanya satu keping data ditanya, tetapi pelaksanaannya sangat perlahan.
- Pangkalan data MySQL itu sendiri disekat, contohnya: sistem atau sumber rangkaian tidak mencukupi
- Pernyataan SQL disekat, seperti: kunci meja, kunci baris, dsb., mengakibatkan Enjin storan tidak melaksanakan pernyataan SQL yang sepadan
- Ia sememangnya disebabkan oleh penggunaan indeks yang tidak betul dan tidak mengindeks
- disebabkan oleh ciri-ciri data dalam jadual digunakan, tetapi bilangan pulangan jadual adalah besar
3. Apakah perbezaan dalam kaedah pelaksanaan count(*), count(0) dan count(id)?
- Untuk fungsi kiraan dalam bentuk
count(*),count(常数)dancount(主键), pengoptimum boleh memilih indeks dengan kos imbasan terkecil untuk melaksanakan pertanyaan, dengan itu menambah baik kecekapan. Prosesnya adalah sama. - Untuk
count(非索引列), pengoptimum memilih imbasan jadual penuh, yang bermaksud ia hanya boleh mengimbas nod daun indeks berkelompok secara berurutan. -
count(二级索引列)Hanya indeks yang mengandungi lajur yang kami tentukan boleh dipilih untuk melaksanakan pertanyaan, yang boleh menyebabkan kos pelaksanaan indeks yang dipilih oleh pengoptimum bukan yang terkecil.

4.
1) Jika jumlah data agak besar, gunakan sandaran fizikal xtrabackup. Lakukan sandaran penuh pangkalan data secara kerap, serta sandaran tambahan.
2) Jika jumlah data adalah kecil, gunakan mysqldump atau mysqldumper, dan kemudian gunakan binlog untuk memulihkan atau menyediakan kaedah master-slave untuk memulihkan data Anda boleh memulihkan daripada perkara berikut:
- Pernyataan salah operasi DML: Anda boleh menggunakan kilas balik untuk menghuraikan acara binlog dahulu dan kemudian membalikkannya.
- Salah operasi penyataan DDL: Data hanya boleh dipulihkan melalui aplikasi sandaran penuh dan binlog. Apabila jumlah data agak besar, masa pemulihan akan menjadi sangat lama.
- pemadaman rm: Gunakan sandaran merentas bilik komputer atau lebih baik merentasi bandar.
5 Perbezaan antara lepas, potong dan padam
- Pernyataan DELETE memadamkan satu baris daripada jadual pada satu masa dan pada satu masa. masa yang sama Simpan pemadaman baris sebagai rekod transaksi dalam log untuk operasi rollback.
- TRUNCATE TABLE memadam semua data daripada jadual sekaligus dan tidak merekodkan rekod operasi pemadaman individu dalam log tidak boleh dipulihkan. Dan pencetus pemadaman yang berkaitan dengan jadual tidak akan diaktifkan semasa proses pemadaman, dan kelajuan pelaksanaan adalah pantas.
- Pernyataan drop melepaskan semua ruang yang diduduki oleh meja.
6 Mengapa pertanyaan jadual besar MySQL tidak memecahkan memori?
- MySQL ialah "menghantar semasa membaca", yang bermaksud jika pelanggan menerima perlahan, pelayan MySQL tidak akan dapat menghantar keputusan kerana masa pelaksanaan transaksi menjadi lebih lama.
- Pelayan tidak perlu menyimpan set hasil lengkap. Proses mendapatkan dan menghantar data semuanya dikendalikan melalui next_buffer.
- Halaman data memori diuruskan dalam Buffer Pool (BP).
- InnoDB menguruskan Buffer Pool menggunakan algoritma LRU yang dipertingkatkan, yang dilaksanakan menggunakan senarai terpaut. Dalam pelaksanaan InnoDB, keseluruhan senarai terpaut LRU dibahagikan kepada kawasan muda dan kawasan lama mengikut nisbah 5:3 untuk memastikan data panas tidak akan dihanyutkan apabila data sejuk dimuatkan dalam kelompok besar.
7. Bagaimana untuk menangani paging dalam (paging yang sangat besar)?
- Gunakan pengoptimuman ID: mula-mula cari ID maksimum yang terakhir paging, dan kemudian gunakan Pertanyaan menggunakan indeks pada id, sama seperti pilih * daripada pengguna di mana id>1000000 had 100.
- Optimumkan dengan indeks penutup: Apabila pertanyaan MySQL mencecah indeks sepenuhnya, ia dipanggil indeks penutup, yang sangat pantas kerana pertanyaan hanya perlu mencari pada indeks dan boleh dikembalikan terus tanpa kembali ke Jadual.
- Hadkan bilangan halaman jika perniagaan membenarkan
8. Bagaimanakah anda mengoptimumkan SQL dalam pembangunan harian?
- Tambah indeks yang sesuai: indeks medan yang digunakan sebagai syarat pertanyaan dan susunan mengikut, pertimbangkan berbilang medan pertanyaan untuk mewujudkan indeks gabungan, dan perhatikan susunan medan indeks gabungan, yang akan menjadi yang paling biasa digunakan Lajur yang digunakan sebagai syarat terhad diletakkan di sebelah kiri, dalam tertib menurun Indeks tidak boleh terlalu banyak, biasanya dalam lingkungan 5.
- Optimumkan struktur jadual: medan berangka lebih baik daripada jenis rentetan, jenis data yang lebih kecil biasanya lebih baik, cuba gunakan NOT NULL
- Optimumkan pernyataan pertanyaan: analisis pelan pelaksanaan SQl, sama ada ia mencapai indeks , dsb. , jika SQL sangat kompleks, optimumkan struktur SQL Jika jumlah data jadual terlalu besar, pertimbangkan sub-jadual
9. Apakah perbezaan antara serentak. sambungan dan pertanyaan serentak dalam MySQL?
- Dalam hasil melaksanakan senarai proses rancangan, saya melihat beribu-ribu sambungan, yang merujuk kepada sambungan serentak.
- Pernyataan "sedang melaksanakan" ialah pertanyaan serentak.
- Sebilangan besar sambungan serentak menjejaskan memori.
- Pertanyaan serentak yang terlalu tinggi adalah tidak baik untuk CPU. Mesin mempunyai bilangan teras CPU yang terhad dan jika semua utas tergesa-gesa masuk, kos penukaran konteks akan menjadi terlalu tinggi.
- Perlu diambil perhatian bahawa selepas benang memasuki kunci tunggu, kiraan benang serentak dikurangkan sebanyak satu, jadi benang menunggu kunci baris atau kunci celah tidak termasuk dalam julat kiraan. Maksudnya, benang yang menunggu kunci tidak memakan CPU, dengan itu menghalang keseluruhan sistem daripada terkunci.
10 Bagaimanakah MySQL beroperasi secara dalaman apabila mengemas kini nilai medan kepada nilai asalnya?
- Dengan data yang sama, tiada kemas kini akan dilakukan.
- Walau bagaimanapun, format binlog yang berbeza mempunyai kaedah pemprosesan log yang berbeza:
- 1) Apabila berdasarkan mod baris, lapisan pelayan sepadan dengan rekod yang akan dikemas kini dan mendapati bahawa nilai baharu adalah konsisten dengan nilai lama, kembali terus tanpa mengemas kini, dan tidak merekodkan binlog.
- 2) Apabila berdasarkan pernyataan atau format campuran, MySQL melaksanakan pernyataan kemas kini dan merekodkan pernyataan kemas kini ke binlog.
11. Apakah perbezaan antara tarikh dan cap waktu?
- Julat tarikh masa tarikh ialah 1001-9999; julat masa cap waktu ialah 1970-2038
- Masa storan tarikh tidak ada kaitan dengan zon waktu; masa storan cap waktu tiada kaitan dengan zon masa berkaitan zon waktu, nilai yang dipaparkan juga bergantung pada zon masa
- Ruang storan masa tarikh ialah 8 bait; ruang storan cap masa ialah 4 bait
- Nilai lalai datetime ialah nol; medan cap masa menjadi lalai, nilai lalai ialah masa semasa (current_timestamp)
Apakah tahap pengasingan urus niaga?
- "Read Uncommitted" adalah tahap paling rendah dan tidak boleh dijamin dalam apa jua keadaan
- "Read Committed" boleh mengelakkan berlakunya bacaan kotor
- "Baca Berulang" boleh mengelakkan bacaan kotor dan bacaan tidak boleh berulang
- "Boleh Bersiri" boleh mengelakkan bacaan kotor, bacaan tidak boleh berulang dan bacaan hantu
- Tahap pengasingan transaksi lalai Mysql ialah "Boleh Diulang Baca"
13. Terdapat dua perintah kill dalam MySQL
- kill query thread id, yang bermaksud untuk menamatkan pernyataan yang dilaksanakan dalam ini utas
- bunuh id utas sambungan, di sini sambungan boleh lalai, yang bermaksud memutuskan sambungan utas ini
Indeks
Apakah itu kategori indeks?
- Mengikut kandungan nod daun, jenis indeks dibahagikan kepada indeks kunci utama dan indeks kunci bukan utama.
- Nod daun indeks kunci utama menyimpan keseluruhan baris data. Dalam InnoDB, indeks kunci utama juga dipanggil indeks berkelompok.
- Kandungan nod daun dalam indeks bukan kunci utama ialah nilai kunci utama. Dalam InnoDB, indeks kunci bukan utama juga dipanggil indeks sekunder.
2. Apakah perbezaan antara indeks berkelompok dan indeks tidak berkelompok?
-
Indeks berkelompok: Indeks berkelompok ialah indeks yang dibuat dengan kunci utama Indeks berkelompok menyimpan data dalam jadual dalam nod daun.

-
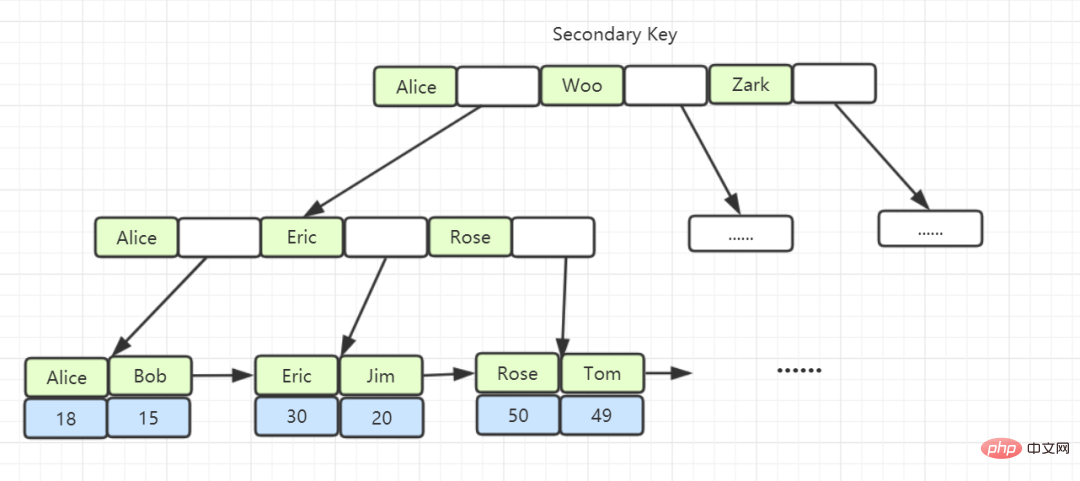
Indeks tidak berkelompok: Indeks yang dibuat oleh kunci bukan utama menyimpan kunci utama dan lajur indeks dalam nod daun menggunakan indeks tidak berkelompok , dapatkan kunci utama pada daun dan kemudian cari data yang ingin anda cari. (Proses mendapatkan kunci utama dan kemudian mencarinya dipanggil pulangan jadual).
Indeks penutup: Dengan mengandaikan bahawa lajur yang ditanya adalah lajur yang sepadan dengan indeks, dan tidak perlu kembali ke jadual untuk melihat ke atas, maka lajur indeks ini dipanggil indeks Penutup.
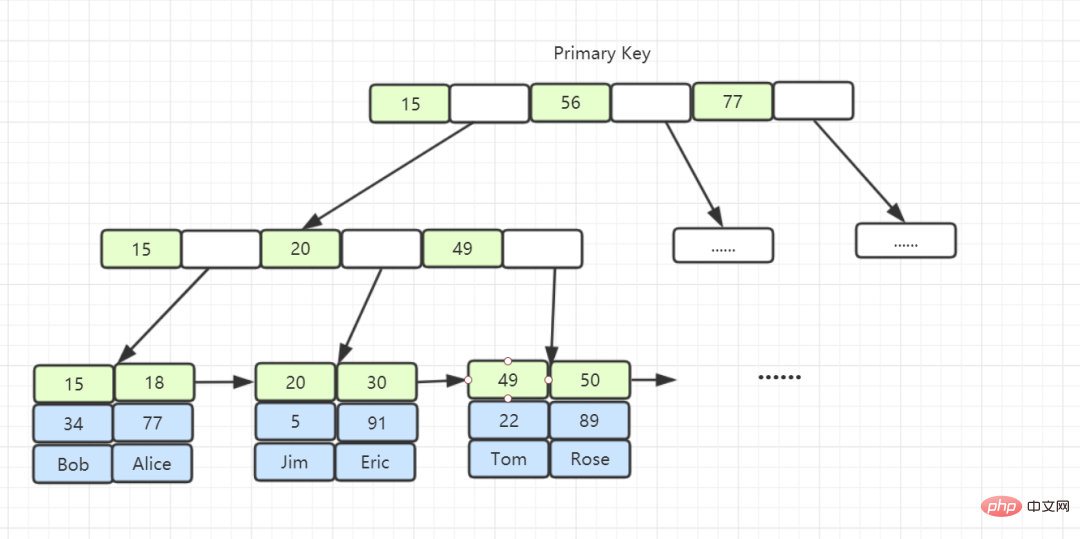
3. Mengapakah InnoDB mereka bentuk B-tree dan bukannya B-Tree, Hash, pokok binari dan pokok merah-hitam?
- Indeks cincang boleh mengendalikan penambahan, pemadaman, pengubahsuaian dan pertanyaan baris data tunggal pada kelajuan O(1), tetapi apabila berhadapan dengan pertanyaan julat atau pengisihan, ia akan membawa kepada hasil imbasan jadual penuh.
- B-tree boleh menyimpan data dalam nod bukan daun Memandangkan semua nod mungkin mengandungi data sasaran, kami sentiasa perlu merentasi subtree ke bawah dari nod akar untuk mencari baris data yang memenuhi syarat yang dibawa oleh ciri ini Sejumlah besar I/O rawak datang, menyebabkan kemerosotan prestasi.
- Semua baris data pokok B disimpan dalam nod daun, dan nod daun ini boleh disambungkan mengikut urutan melalui "penunjuk". mengakses berbilang subpokok secara terus Melompat antara nod boleh menjimatkan banyak masa I/O cakera.
Pokok binari: Ketinggian pokok tidak sekata dan tidak boleh mengimbangi sendiri Kecekapan carian berkaitan dengan data (ketinggian pokok), dan kos IO adalah tinggi.
Pokok merah-hitam: Ketinggian pokok meningkat apabila jumlah data meningkat, dan kos IO adalah tinggi.
4. Mari kita bincangkan tentang indeks berkelompok dan indeks tidak berkelompok?
- Dalam InnoDB, nod daun indeks B Tree menyimpan keseluruhan baris data ialah indeks kunci utama, juga dipanggil indeks berkelompok, yang meletakkan penyimpanan data dan indeks bersama-sama. Apabila anda mencari indeks, anda mencari data.
- Nod daun bagi Pepohon indeks B menyimpan nilai kunci primer dan merupakan indeks kunci bukan utama, juga dipanggil indeks bukan berkelompok dan indeks sekunder.
- Indeks pertama biasanya IO berjujukan, dan operasi kembali ke jadual ialah IO rawak. Lebih banyak kali kita perlu kembali ke jadual, iaitu, lebih banyak kali kita memerlukan IO rawak, lebih banyak kita cenderung menggunakan imbasan jadual penuh.
5 Adakah indeks tidak berkelompok pasti mengembalikan pertanyaan jadual?
- Tidak semestinya ini melibatkan sama ada semua medan yang diperlukan oleh pernyataan pertanyaan mengenai indeks Jika semua medan mencapai indeks, maka tidak perlu melakukan pertanyaan pemulangan jadual. Indeks mengandungi (meliputi) nilai semua medan yang perlu ditanya, dan dipanggil "indeks penutup".
6. Beritahu kami tentang prinsip awalan paling kiri MySQL?
- Prinsip awalan paling kiri ialah keutamaan paling kiri Apabila membuat indeks berbilang lajur, mengikut keperluan perniagaan, lajur yang paling kerap digunakan dalam klausa tempat diletakkan di sebelah kiri.
- MySQL akan terus memadankan ke kanan sehingga ia menemui pertanyaan julat (>, <, antara, suka), seperti a = 1 dan b = 2 dan c > Cipta indeks dalam susunan (a, b, c, d) Indeks d tidak digunakan , b, d boleh sewenang-wenangnya.
- = dan in boleh menjadi tidak teratur, seperti a = 1 dan b = 2 dan c = 3. Anda boleh mencipta indeks (a, b, c) dalam sebarang susunan Pengoptimum pertanyaan MySQL akan membantu anda mengoptimumkan indeks ke dalam bentuk pengenalan.
7. Apakah itu index pushdown?
- Apabila prinsip awalan paling kiri dipenuhi, awalan paling kiri boleh digunakan untuk mencari rekod dalam indeks.
- Sebelum MySQL 5.6, anda hanya boleh mengembalikan jadual satu demi satu bermula dari ID. Cari baris data pada indeks kunci utama, dan kemudian bandingkan nilai medan.
- Pengoptimuman tekan bawah indeks (tekan ke bawah keadaan indeks) yang diperkenalkan dalam MySQL 5.6 boleh menilai terlebih dahulu medan yang disertakan dalam indeks semasa proses lintasan indeks, dan secara langsung menapis rekod yang tidak memenuhi syarat, mengurangkan bilangan jadual pulangan.
8 Mengapakah Innodb menggunakan id penambahan automatik sebagai kunci utama?
- Jika jadual menggunakan kunci utama kenaikan automatik, maka setiap kali rekod baharu dimasukkan, rekod itu akan ditambah secara berurutan ke kedudukan nod indeks semasa yang seterusnya Apabila a halaman penuh, ia akan dibuka secara automatik Halaman baharu. Jika anda menggunakan kunci utama yang tidak meningkat secara automatik (seperti nombor ID atau nombor pelajar, dsb.), memandangkan nilai kunci utama yang dimasukkan setiap kali adalah lebih kurang rawak, setiap rekod baharu mesti dimasukkan di suatu tempat di tengah-tengah halaman indeks yang sedia ada, dengan kerap operasi mengalihkan dan kelui menyebabkan sejumlah besar pemecahan dan mengakibatkan struktur indeks yang tidak cukup padat Selepas itu, OPTIMIZE TABLE (mengoptimumkan jadual) terpaksa digunakan untuk membina semula jadual dan mengoptimumkan halaman yang diisi.
9 Bagaimanakah ciri ACID transaksi dilaksanakan?
- "Atomicity": Ia dilaksanakan menggunakan log buat asal Jika ralat berlaku semasa pelaksanaan transaksi atau pengguna melaksanakan rollback, sistem mengembalikan status permulaan transaksi melalui log buat asal.
- "Kegigihan": Gunakan log buat semula untuk mencapainya selagi log buat semula berterusan, apabila sistem ranap, data boleh dipulihkan melalui log buat semula.
- "Pengasingan": Gunakan kunci dan MVCC untuk mengasingkan transaksi antara satu sama lain.
- "Ketekalan": Mencapai konsistensi melalui rollback, pemulihan dan pengasingan dalam situasi serentak.
10. Apakah perbezaan antara cara MyISAM dan InnoDB melaksanakan indeks B-tree?
Enjin storan InnoDB: nod daun indeks B-tree menyimpan data itu sendiri
Enjin storan MyISAM: daun indeks B-tree Alamat fizikal tempat nod menyimpan data
- InnoDB, fail datanya sendiri ialah fail indeks Berbanding dengan MyISAM, fail indeks dan fail datanya dipisahkan sendiri ialah struktur indeks yang diatur oleh B Tree, dan medan data nod pokok itu disimpan. Rekod data lengkap diperolehi Kunci indeks ini adalah kunci utama jadual data Oleh itu, fail data jadual InnoDB itu sendiri dipanggil "indeks berkelompok , dan indeks yang selebihnya digunakan sebagai indeks tambahan Medan data menyimpan nilai kunci utama rekod yang sepadan dan bukannya alamat.
11. Apakah kategori indeks?
- Mengikut kandungan nod daun, jenis indeks dibahagikan kepada indeks kunci primer dan indeks kunci bukan utama.
- Nod daun indeks kunci utama menyimpan keseluruhan baris data. Dalam InnoDB, indeks kunci utama juga dipanggil indeks berkelompok.
- Kandungan nod daun dalam indeks bukan kunci utama ialah nilai kunci utama. Dalam InnoDB, indeks kunci bukan utama juga dipanggil indeks sekunder.
12. Apakah senario yang akan menyebabkan kegagalan indeks?
Latar Belakang: Keupayaan penentududukan pantas yang disediakan oleh pokok B berasal daripada keteraturan nod adik-beradik pada lapisan yang sama Oleh itu, jika keteraturan ini dimusnahkan, kemungkinan besar ia akan gagal. Secara khusus Terdapat situasi berikut:
Gunakan padanan kabur kiri atau kiri pada indeks: iaitu, seperti %xx atau seperti %xx%. indeks untuk gagal. Sebabnya ialah hasil pertanyaan mungkin "Chen Lin, Zhang Lin, Zhou Lin" dan sebagainya, jadi kami tidak tahu nilai indeks mana yang hendak dibandingkan, jadi kami hanya boleh membuat pertanyaan melalui imbasan jadual penuh.
Gunakan fungsi untuk indeks/pengiraan Ungkapan untuk indeks: Kerana indeks menyimpan nilai asal medan indeks, bukan nilai yang dikira oleh fungsi, secara semula jadi tidak ada cara untuk menggunakan indeks .
Penukaran jenis tersirat untuk indeks: bersamaan dengan menggunakan fungsi baharu
ATAU dalam klausa WHERE: bermaksud dua asalkan Cukup memuaskan satu , jadi tidak masuk akal jika hanya satu lajur bersyarat menjadi lajur indeks Selagi lajur bersyarat bukan lajur indeks, imbasan jadual penuh akan dilakukan.
Cadangan
1. Terdapat sistem yang tidak dibahagikan kepada pangkalan data dan jadual dan meja?
- Hentikan pengembangan (tidak disyorkan)
- Pelan migrasi tulis dua kali: Reka pelan struktur jadual dikembangkan, dan kemudian laksanakan dwi-tulis untuk pangkalan data tunggal dan sub-pangkalan data , amati Selepas tiada masalah selama seminggu, matikan trafik baca pangkalan data tunggal dan amatinya untuk seketika Selepas ia terus stabil, matikan trafik tulis pangkalan data tunggal dan lancar beralih ke sub-pangkalan data dan sub-jadual.
2. Bagaimana untuk mereka bentuk sub-pangkalan data dan skema jadual yang boleh mengembangkan dan mengecilkan kapasiti secara dinamik?
Prinsip
1.
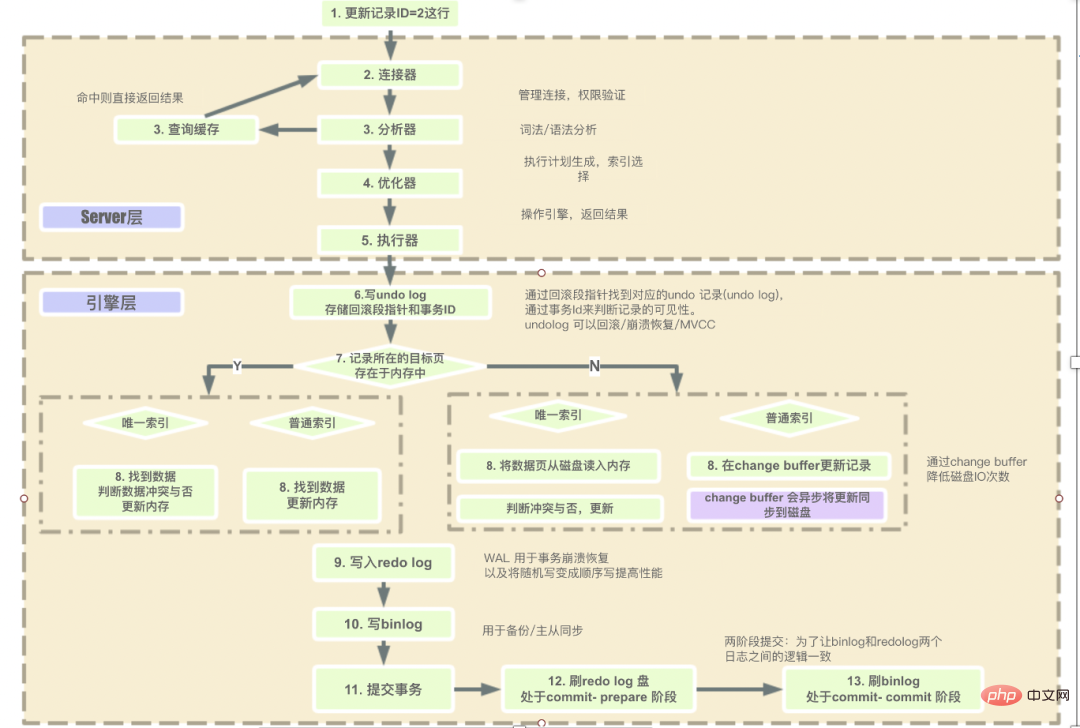
- Langkah-langkah untuk lapisan Pelayan untuk melaksanakan SQL mengikut turutan ialah:
- Permintaan pelanggan -> Penyambung (sahkan identiti pengguna, berikan kebenaran) -> Cache pertanyaan (kembali terus jika cache wujud, Jika ia tidak wujud, operasi seterusnya akan dilakukan) -> Penganalisis (analisis leksikal dan operasi analisis sintaks pada SQL) -> semak dahulu sama ada pengguna mempunyai kebenaran pelaksanaan sebelum menggunakan antara muka yang disediakan oleh enjin ini) -> Pergi ke lapisan enjin untuk mendapatkan pulangan data (jika cache pertanyaan dihidupkan, hasil pertanyaan akan dicache).
2. Apakah prinsip tertib dalaman?
- MySQL akan memperuntukkan memori (sort_buffer) untuk setiap thread untuk mengisih Saiz memori ialah sort_buffer_size.
- Jika jumlah data yang hendak diisih kurang daripada sort_buffer_size, pengisihan akan diselesaikan dalam ingatan.
- Jika jumlah data yang diisih adalah besar dan tidak boleh disimpan dalam memori, fail sementara pada cakera akan digunakan untuk membantu pengisihan, juga dikenali sebagai pengisihan luaran.
- Apabila menggunakan pengisihan luaran, MySQL akan membahagikannya kepada beberapa fail sementara yang berasingan untuk menyimpan data yang diisih, dan kemudian menggabungkan fail ini menjadi satu fail besar.
Prinsip pelaksanaan MVCC?
- MVCC (Kawalan penukaran berbilang versi) ialah cara untuk mengekalkan berbilang versi data yang sama, dengan itu mencapai kawalan serentak. Apabila membuat pertanyaan, cari data versi yang sepadan melalui paparan baca dan rantaian versi.
- Fungsi: Tingkatkan prestasi serentak. Untuk senario konkurensi tinggi, MVCC lebih murah daripada kunci peringkat baris.
- Pelaksanaan MVCC bergantung pada rantaian versi, yang dilaksanakan melalui tiga medan tersembunyi jadual.
- 1) DB_TRX_ID: Id transaksi semasa, urutan masa transaksi dinilai mengikut saiz id transaksi.
- 2) DB_ROLL_PRT: Penunjuk gulung balik menghala ke versi sebelumnya bagi rekod baris semasa Melalui penuding ini, berbilang versi data disambungkan bersama untuk membentuk rantaian versi log asal.
- 3) DB_ROLL_ID: kunci utama Jika jadual data tidak mempunyai kunci utama, InnoDB akan menjana kunci primer secara automatik.
4.
5 Bagaimanakah MySQL memastikan data tidak hilang?
- Selagi redolog dan binlog memastikan cakera berterusan, data boleh dipastikan selepas MySQL dimulakan semula secara tidak normal Pulihkan mekanisme penulisan binlog.
- Redolog memastikan data yang hilang boleh dibuat semula selepas pengecualian sistem dan binlog mengarkibkan data untuk memastikan data yang hilang boleh dipulihkan.
- Tulis redolog sebelum pelaksanaan urus niaga, log terlebih dahulu ditulis ke cache binlog Apabila urus niaga diserahkan, cache binlog ditulis ke fail binlog.
6. Mengapakah saiz fail jadual kekal tidak berubah walaupun selepas memadamkan jadual?
- Selepas item data dipadamkan, InnoDB menandakan halaman A dan ia akan ditandakan sebagai boleh diguna semula
- Bagaimana pula dengan arahan padam untuk memadamkan keseluruhan data jadual? Akibatnya, semua halaman data akan ditandakan sebagai boleh digunakan semula. Tetapi pada cakera, fail tidak menjadi lebih kecil.
- Jadual yang telah mengalami banyak penambahan, pemadaman dan pengubahsuaian mungkin mempunyai lubang. Lubang-lubang ini juga mengambil ruang, jadi jika lubang ini boleh dikeluarkan, tujuan mengecilkan ruang meja boleh dicapai.
- Membina semula jadual boleh mencapai tujuan ini. Anda boleh menggunakan perintah alter table A engine=InnoDB untuk membina semula jadual.
7 Perbandingan tiga format binlog
- Id kunci utama baris operasi yang direkodkan dalam binlog format baris dan nilai sebenar. bagi setiap medan, Oleh itu, tidak akan ada ketidakkonsistenan dalam data operasi primer dan sekunder.
- penyataan: pernyataan SQL sumber yang direkodkan
- bercampur: dua yang pertama bercampur, mengapa anda memerlukan fail dalam format bercampur kerana sesetengah binlog dalam format pernyataan mungkin menyebabkan ketidakkonsistenan antara yang utama dan pelayan sekunder, jadi perlu Gunakan format baris. Tetapi kelemahan format baris ialah ia mengambil banyak ruang. MySQL telah mengambil kompromi MySQL sendiri akan menentukan sama ada pernyataan SQL ini boleh menyebabkan ketidakkonsistenan antara pelayan utama dan sekunder Jika boleh, ia akan menggunakan format baris, jika tidak ia akan menggunakan format pernyataan.
8 Peraturan penguncian MySQL
- Prinsip 1: Unit asas penguncian ialah kunci kekunci seterusnya, dan kunci kekunci seterusnya ialah sebelum Buka dan kemudian tutup selang.
- Prinsip 2: Hanya objek yang diakses semasa proses carian akan dikunci
- Pengoptimuman 1: Pertanyaan setara pada indeks, apabila mengunci indeks unik, kunci kekunci seterusnya merosot menjadi kunci Baris.
- Pengoptimuman 2: Untuk pertanyaan setara pada indeks, apabila merentasi ke kanan dan nilai terakhir tidak memenuhi syarat kesetaraan, kunci kekunci seterusnya merosot menjadi kunci celah
- Pepijat: Pertanyaan julat pada indeks unik akan mengakses nilai pertama yang tidak memenuhi syarat.
9 Apakah bacaan kotor, bacaan tidak boleh diulang dan bacaan hantu?
- "Bacaan Kotor": Bacaan kotor merujuk kepada membaca data tidak komited daripada urus niaga lain bermakna data itu boleh ditarik balik, yang bermaksud ia mungkin tidak disimpan pada akhirnya. Dalam pangkalan data, iaitu data yang tidak wujud. Membaca data yang mungkin akhirnya tidak wujud dipanggil bacaan kotor.
- "Bacaan tidak boleh berulang": Bacaan tidak boleh berulang bermaksud bahawa dalam transaksi, data yang dibaca pada mulanya tidak konsisten dengan kumpulan data yang sama dibaca pada bila-bila masa sebelum tamat transaksi.
- "Bacaan hantu": Bacaan hantu tidak bermakna set hasil yang diperoleh oleh dua bacaan adalah berbeza Fokus bacaan hantu ialah status data hasil yang diperoleh oleh operasi pilihan tertentu tidak dapat menyokong perniagaan berikutnya operasi. Untuk lebih spesifik: pilih sama ada rekod tertentu wujud Jika ia tidak wujud, sediakan untuk memasukkan rekod Walau bagaimanapun, apabila melaksanakan sisipan, didapati rekod itu sudah wujud dan tidak boleh dimasukkan pada masa ini berlaku.
10 Apakah jenis kunci yang ada pada MySQL? daripada kategori, terdapat kunci kongsi dan kunci eksklusif.
1) Kunci kongsi: Juga dipanggil kunci baca Apabila pengguna ingin membaca data, kunci kongsi ditambahkan pada data berbilang kunci.- 2) Kunci eksklusif: Juga dipanggil kunci tulis Apabila pengguna ingin menulis data, kunci eksklusif ditambahkan pada data Hanya satu kunci eksklusif boleh ditambah dan kunci eksklusif lain serta kunci kongsi sedang menolak antara satu sama lain.
- Kebutiran kunci bergantung pada enjin storan tertentu InnoDB melaksanakan kunci peringkat baris, kunci peringkat halaman dan kunci peringkat jadual.
Overhed pengunciannya meningkat daripada besar kepada kecil, dan keupayaan serentak mereka juga meningkat daripada besar kepada kecil. Kerangka
Acara kemas kini Guru (kemas kini, sisip, padam) akan ditulis kepada 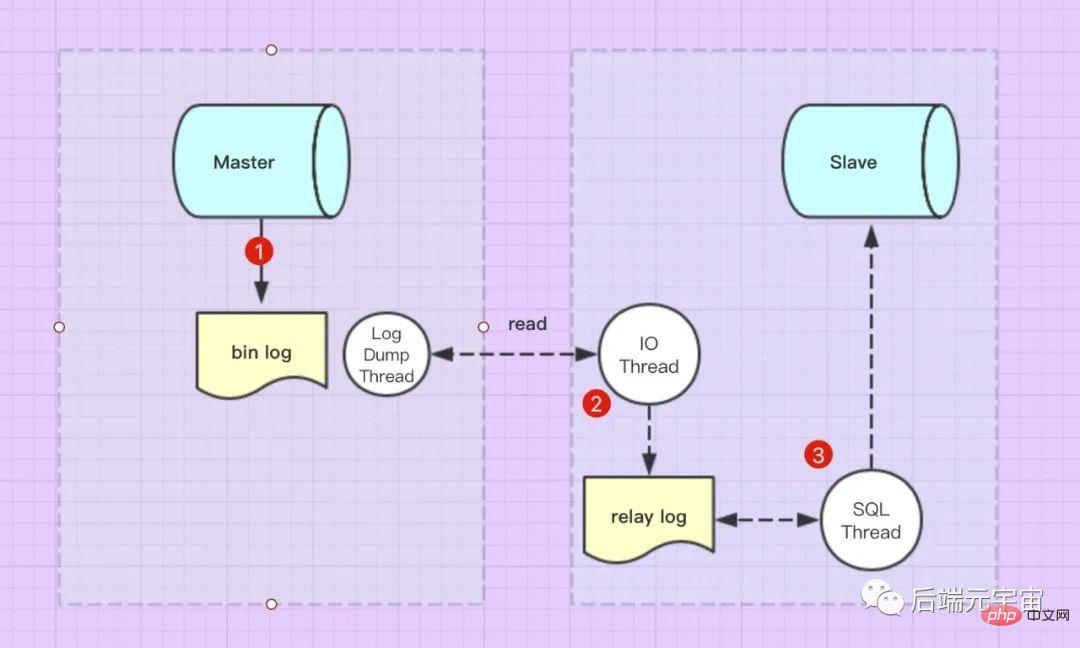 mengikut urutan. Apabila hamba disambungkan kepada tuan, mesin tuan akan membuka benang
mengikut urutan. Apabila hamba disambungkan kepada tuan, mesin tuan akan membuka benang
- Selepas Slave disambungkan kepada Master, perpustakaan Slave mempunyai
bin-logyang membaca log bin-log dengan meminta benang dump binlog, dan kemudian menulisnya kebinlog dumplog hamba perpustakaan. - Slave juga mempunyai
I/O线程, yang memantau kandungan log relay dalam masa nyata untuk kemas kini, menghuraikan pernyataan SQL dalam fail dan melaksanakannya dalam pangkalan data Slave.relay log -
SQL线程2. Apakah kaedah penyegerakan master-slave Mysql?
Replikasi tak segerak:
Penyegerakan induk-hamba MySQL ialah replikasi tak segerak secara lalai. Iaitu, antara tiga langkah di atas, hanya langkah pertama adalah segerak (iaitu, Mater menulis log log bin), iaitu, perpustakaan induk boleh berjaya kembali kepada klien selepas menulis log binlog, tanpa menunggu binlog log untuk dipindahkan ke perpustakaan hamba.- Replikasi segerak: Untuk replikasi segerak, selepas hos Master menghantar acara kepada hos Hamba, ia akan mencetuskan penantian sehingga semua nod Hamba (jika terdapat berbilang Hamba) mengembalikan bahawa replikasi data adalah maklumat yang berjaya kepada Master.
- Replikasi separa segerak: Untuk replikasi separa segerak, penantian akan dicetuskan selepas hos Master menghantar acara kepada hos Hamba, sehingga salah satu nod Hamba
- (jika (Terdapat berbilang Hamba) mengembalikan maklumat tentang replikasi data yang berjaya kepada Master. 3. Apakah yang menyebabkan kelewatan penyegerakan tuan-hamba Mysql?
Jika nod induk melaksanakan transaksi yang besar, ia akan memberi kesan yang lebih besar pada kelewatan induk-hamba
Kelewatan Rangkaian , log besar, terlalu ramai hamba
Tulisan berbilang benang pada induk, hanya penyegerakan satu benang pada nod hamba
Prestasi mesin isu , sama ada nod hamba menggunakan "mesin buruk"
Isu konflik kunci juga boleh menyebabkan benang SQL mesin hamba dilaksanakan dengan perlahan
4. Apakah yang menyebabkan kelewatan penyegerakan tuan-hamba Mysql?
- Urus niaga besar: Bahagikan urus niaga besar kepada urus niaga kecil dan kemas kini data dalam kelompok
- Kurangkan bilangan Hamba kepada tidak lebih daripada 5 dan kurangkan saiz satu transaksi
- Selepas Mysql 5.7, anda boleh menggunakan replikasi berbilang benang dan menggunakan seni bina replikasi MGR
- Dalam kes masalah dengan cakera, kad serbuan dan strategi penjadualan, kependaman IO tunggal yang tinggi mungkin berlaku . Anda boleh menggunakan Gunakan perintah iostat untuk menyemak situasi IO cakera data DB, dan kemudian menilai lebih lanjut
- Untuk masalah kunci, anda boleh menyemak senarai proses dan menyemak jadual yang berkaitan dengan kunci dan transaksi di bawah information_schema.
6. Apakah itu log bin/log semula/buat asal
- log bin ialah fail di peringkat pangkalan data Mysql. Ia merekodkan semua operasi yang mengubah suai pangkalan data Mysql tidak akan direkodkan.
- Data yang akan dikemas kini direkodkan dalam log buat semula Sebagai contoh, jika sekeping data berjaya diserahkan, ia tidak akan disegerakkan dengan segera, sebaliknya, ia akan direkodkan dalam log buat semula mula-mula, dan kemudian tunggu masa yang sesuai untuk mengepam cakera Untuk Melaksanakan ketahanan transaksi.
- log asal digunakan untuk operasi panggil balik data Ia mengekalkan kandungan sebelum rekod diubah suai. Balik semula urus niaga boleh dicapai melalui log buat asal, dan MVCC boleh dilaksanakan dengan menjejak kembali ke versi data tertentu berdasarkan log buat asal.
Pembelajaran yang disyorkan: tutorial video mysql
Atas ialah kandungan terperinci Ringkasan isu untuk menyatukan asas MySQL. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1386
1386
 52
52

 Mysql: Konsep mudah untuk pembelajaran mudah
Apr 10, 2025 am 09:29 AM
Mysql: Konsep mudah untuk pembelajaran mudah
Apr 10, 2025 am 09:29 AM
MySQL adalah sistem pengurusan pangkalan data sumber terbuka. 1) Buat Pangkalan Data dan Jadual: Gunakan perintah Createdatabase dan Createtable. 2) Operasi Asas: Masukkan, Kemas kini, Padam dan Pilih. 3) Operasi lanjutan: Sertai, subquery dan pemprosesan transaksi. 4) Kemahiran Debugging: Semak sintaks, jenis data dan keizinan. 5) Cadangan Pengoptimuman: Gunakan indeks, elakkan pilih* dan gunakan transaksi.
 Cara membuka phpmyadmin
Apr 10, 2025 pm 10:51 PM
Cara membuka phpmyadmin
Apr 10, 2025 pm 10:51 PM
Anda boleh membuka phpmyadmin melalui langkah -langkah berikut: 1. Log masuk ke panel kawalan laman web; 2. Cari dan klik ikon phpmyadmin; 3. Masukkan kelayakan MySQL; 4. Klik "Login".
 MySQL: Pengenalan kepada pangkalan data paling popular di dunia
Apr 12, 2025 am 12:18 AM
MySQL: Pengenalan kepada pangkalan data paling popular di dunia
Apr 12, 2025 am 12:18 AM
MySQL adalah sistem pengurusan pangkalan data relasi sumber terbuka, terutamanya digunakan untuk menyimpan dan mengambil data dengan cepat dan boleh dipercayai. Prinsip kerjanya termasuk permintaan pelanggan, resolusi pertanyaan, pelaksanaan pertanyaan dan hasil pulangan. Contoh penggunaan termasuk membuat jadual, memasukkan dan menanyakan data, dan ciri -ciri canggih seperti Operasi Join. Kesalahan umum melibatkan sintaks SQL, jenis data, dan keizinan, dan cadangan pengoptimuman termasuk penggunaan indeks, pertanyaan yang dioptimumkan, dan pembahagian jadual.
 Mengapa menggunakan mysql? Faedah dan kelebihan
Apr 12, 2025 am 12:17 AM
Mengapa menggunakan mysql? Faedah dan kelebihan
Apr 12, 2025 am 12:17 AM
MySQL dipilih untuk prestasi, kebolehpercayaan, kemudahan penggunaan, dan sokongan komuniti. 1.MYSQL Menyediakan fungsi penyimpanan dan pengambilan data yang cekap, menyokong pelbagai jenis data dan operasi pertanyaan lanjutan. 2. Mengamalkan seni bina pelanggan-pelayan dan enjin penyimpanan berganda untuk menyokong urus niaga dan pengoptimuman pertanyaan. 3. Mudah digunakan, menyokong pelbagai sistem operasi dan bahasa pengaturcaraan. 4. Mempunyai sokongan komuniti yang kuat dan menyediakan sumber dan penyelesaian yang kaya.
 Cara menggunakan redis berulir tunggal
Apr 10, 2025 pm 07:12 PM
Cara menggunakan redis berulir tunggal
Apr 10, 2025 pm 07:12 PM
Redis menggunakan satu seni bina berulir untuk memberikan prestasi tinggi, kesederhanaan, dan konsistensi. Ia menggunakan I/O multiplexing, gelung acara, I/O yang tidak menyekat, dan memori bersama untuk meningkatkan keserasian, tetapi dengan batasan batasan konkurensi, satu titik kegagalan, dan tidak sesuai untuk beban kerja yang berintensifkan.
 MySQL dan SQL: Kemahiran Penting untuk Pemaju
Apr 10, 2025 am 09:30 AM
MySQL dan SQL: Kemahiran Penting untuk Pemaju
Apr 10, 2025 am 09:30 AM
MySQL dan SQL adalah kemahiran penting untuk pemaju. 1.MYSQL adalah sistem pengurusan pangkalan data sumber terbuka, dan SQL adalah bahasa standard yang digunakan untuk mengurus dan mengendalikan pangkalan data. 2.MYSQL menyokong pelbagai enjin penyimpanan melalui penyimpanan data yang cekap dan fungsi pengambilan semula, dan SQL melengkapkan operasi data yang kompleks melalui pernyataan mudah. 3. Contoh penggunaan termasuk pertanyaan asas dan pertanyaan lanjutan, seperti penapisan dan penyortiran mengikut keadaan. 4. Kesilapan umum termasuk kesilapan sintaks dan isu -isu prestasi, yang boleh dioptimumkan dengan memeriksa penyataan SQL dan menggunakan perintah menjelaskan. 5. Teknik pengoptimuman prestasi termasuk menggunakan indeks, mengelakkan pengimbasan jadual penuh, mengoptimumkan operasi menyertai dan meningkatkan kebolehbacaan kod.
 Tempat Mysql: Pangkalan Data dan Pengaturcaraan
Apr 13, 2025 am 12:18 AM
Tempat Mysql: Pangkalan Data dan Pengaturcaraan
Apr 13, 2025 am 12:18 AM
Kedudukan MySQL dalam pangkalan data dan pengaturcaraan sangat penting. Ia adalah sistem pengurusan pangkalan data sumber terbuka yang digunakan secara meluas dalam pelbagai senario aplikasi. 1) MySQL menyediakan fungsi penyimpanan data, organisasi dan pengambilan data yang cekap, sistem sokongan web, mudah alih dan perusahaan. 2) Ia menggunakan seni bina pelanggan-pelayan, menyokong pelbagai enjin penyimpanan dan pengoptimuman indeks. 3) Penggunaan asas termasuk membuat jadual dan memasukkan data, dan penggunaan lanjutan melibatkan pelbagai meja dan pertanyaan kompleks. 4) Soalan -soalan yang sering ditanya seperti kesilapan sintaks SQL dan isu -isu prestasi boleh disahpepijat melalui arahan jelas dan log pertanyaan perlahan. 5) Kaedah pengoptimuman prestasi termasuk penggunaan indeks rasional, pertanyaan yang dioptimumkan dan penggunaan cache. Amalan terbaik termasuk menggunakan urus niaga dan preparedStatemen
 Pantau titisan redis dengan perkhidmatan pengeksport redis
Apr 10, 2025 pm 01:36 PM
Pantau titisan redis dengan perkhidmatan pengeksport redis
Apr 10, 2025 pm 01:36 PM
Pemantauan yang berkesan terhadap pangkalan data REDIS adalah penting untuk mengekalkan prestasi yang optimum, mengenal pasti kemungkinan kesesakan, dan memastikan kebolehpercayaan sistem keseluruhan. Perkhidmatan Pengeksport Redis adalah utiliti yang kuat yang direka untuk memantau pangkalan data REDIS menggunakan Prometheus. Tutorial ini akan membimbing anda melalui persediaan lengkap dan konfigurasi perkhidmatan pengeksport REDIS, memastikan anda membina penyelesaian pemantauan dengan lancar. Dengan mengkaji tutorial ini, anda akan mencapai tetapan pemantauan operasi sepenuhnya
