

Artikel ini membawakan anda pengetahuan yang berkaitan tentang python terutamanya isu yang berkaitan dengan aksara dan senarai, termasuk input dan output rentetan, lintasan gelung senarai, dan penambahan senarai , bersarang senarai, dll. Saya harap ia akan membantu semua orang.

Pembelajaran yang disyorkan: tutorial video python
1.1 Fungsi len mengembalikan panjang atau bilangan objek
a = "100"b = "hello world"c = 'hello world'd = '100'e = ‘18.20520'
1.2 Cara lain untuk membentuk rentetan:
In [1]: a="abcdefg"In [2]: len(a)Out[2]: 7In [3]: b = [1,2,3,4,5,66,77,8888]In [4]: len(b)Out[4]: 8
In [5]: a ="lao"In [6]: b="wang"In [7]: c=a+b In [8]: c Out[8]: 'laowang'In [9]: d= "===="+a+b+"===="In [10]: d Out[10]: '====laowang===='In [11]: f="===%s===="%(a+b)In [12]: f Out[12]: '===laowang===='
name = input(“ 请输入你的姓名:”)position = input(“ 请输入你的职业:”)address = input(“ 请输入你的地址:”)
2.2Formatkan sintaks penggunaan:
print("="*50)print(" 姓名:%s\n 职业:%s\n 地址:%s" % (name,position,address))print("="*50)print(“nama saya {0},umur {1}”.format('Liu Bei',20))
print(“my nama ialah {},umur ialah {}".format('Liu Bei',20))print("{1},{0},{1}".format('Liu Bei',20))#. Tentukan sama ada kata laluan itu betul2. Lulus parameter kata kunci
print(“{umur},{nama}”.format(umur=28,name="Cao Cao”))
print(“{nama},{nama} ,{umur }".format(age=28, name="Cao Cao"))
3. Dengan memetakan senarai
alist = ["Sun Quan", 20, "China"]
blist = ["Diao Chan", 18, "China"]
print("nama saya ialah {1[0]}, daripada {0[2]}, umur ialah {0[1]}".format(alist, blist))
Data yang diperoleh melalui input dalam python3 disimpan sebagai rentetan Walaupun input ialah nombor, ia disimpan sebagai rentetan
2.3 Pengenalan subskrip
user_name = input(“ 请输入用户名:”)password = input(“ 请输入密码:”)if user_name == “beijing” and password == “123” :print(“ 欢迎登录北京官网!")else :print(" 你的账户或者密码错误!")
Dalam [ 1] : len(nama)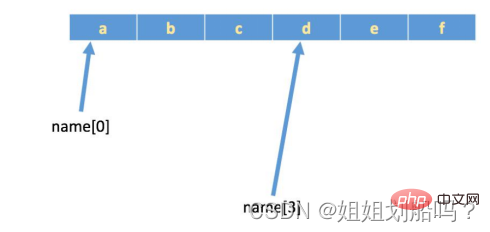 Keluar[1]: 7
Keluar[1]: 7
Keluar[2]: 'g'Dalam [3 ]: nama[-1]
Keluar[3]: 'g' Nombor positif pergi dari kiri ke kanan, nombor negatif pergi dari kanan ke kiri
2.4 keping
Ringkasan subskrip dan penghirisan
[:] Ekstrak keseluruhan rentetan dari awal (kedudukan lalai 0) hingga akhir
[mulakan. :] Extract dari mula hingga akhir
In [1]: name="abcdefABCDEF"In [2]: name[0:3]Out[2]: 'abc'In [3]: name[0:5:2]Out[3]: 'ace'In [4]: name[-1::-1] #逆序(倒叙)Out[4]: 'FEDCBAfedcba'
[startstep] Extract from start to end - 1, ekstrak satu aksara untuk setiap langkah
[::-1] Tertib terbalik
3. Fungsi rentetan biasa
find(), rfind (), index (), rindex (. ), ganti (), belah (), bahagian (), rparttion (), splitlines (), startswith (), endswith (), lower (), atas (),…………
In [1]: mystr="hello world yanzilu and yanziluPython"In [2]: mystr
Out[2]: 'hello world yanzilu and yanziluPython
In [3]: mystr.find("and")Out[3]: 20In [4]: mystr.find("world") #存在则返回该单词开始的下标Out[4]: 6In [5]: mystr.find("world1") #不存在则返回-1Out[5]: -1In [6]: mystr.find("yanzilu")Out[6]: 12In [7]: mystr.find("yanzilu",20,len(mystr)) #指定查找区域Out[7]: 24In [8]: mystr.rfind("yanzilu") #rfind,从右往左搜索Out[8]: 24In [9]: mystr.index("and") Out[9]: 20In [10]: mystr.index("yanzilu")Out[10]: 12In [11]: mystr.index("yanzilu",20,len(mystr)) #指定查找区域Out[11]: 24In [12]: mystr.rindex("yanzilu") #从右往左搜索Out[12]: 24In [13]: mystr.rindex("zhangsan") #搜索不存在的会报错---------------------------------------------------------------------------ValueError Traceback (most recent call last)<ipython-input-67-6aff7ee60ad5> in <module>----> 1 mystr.rindex("zhangsan")ValueError: substring not found</module></ipython-input-67-6aff7ee60ad5>In [14]: mystr
Out[14]: 'hello world yanzilu and yanziluPython'In [15]: mystr.replace("world","WORLD")Out[15]: 'hello WORLD yanzilu and yanziluPython'In [16]: mystr
Out[16]: 'hello world yanzilu and yanziluPython'In [17]: mystr.replace("yan","zhang")Out[17]: 'hello world zhangzilu and zhangziluPython'In [18]: mystr.replace("yan","zhang",1) #指定替换次数Out[18]: 'hello world zhangzilu and yanziluPython'In [19]: mystr.replace("yan","xxx",1)Out19]: 'hello world xxxzilu and yanziluPython'In [20]: mystr.replace("yan","xxx",2)Out[20]: 'hello world xxxzilu and xxxziluPython'In [21]: mystr.replace("yan","xxx",33) #替换次数可以超过最大值Out[21]: 'hello world xxxzilu and xxxziluPython'In [22]: mystr
Out[22]: 'hello world yanzilu and yanziluPython'In [23]: mystr.split(" ")Out[23]: ['hello', 'world', 'yanzilu', 'and', 'yanziluPython']In [24]: mystr.split("and")Out[24]: ['hello world yanzilu ', ' yanziluPython']In [25]: mystr.split(" ",3)Out[25]: ['hello', 'world', 'yanzilu', 'and yanziluPython']In [26]: mystr.split()Out[26]: ['hello', 'world', 'yanzilu', 'and', 'yanziluPython']In [27]: mystr
Out[27]: 'hello world yanzilu and yanziluPython'In [28]: mystr.partition("and")Out[28]: ('hello world yanzilu ', 'and', ' yanziluPython')In [29]: mystr.partition("yanzilu")Out[29]: ('hello world ', 'yanzilu', ' and yanziluPython')In [30]: mystr.rpartition("yanzilu")Out[30]: ('hello world yanzilu and ', 'yanzilu', 'Python')In [31]: mystr1 Out[31]: 'hello\nworld\nyanzilu\nand\nyanziluPython'In [32]: mystr1.splitlines()Out[32]: ['hello', 'world', 'yanzilu', 'and', 'yanziluPython']
In [33]: mystr
Out[33]: 'hello world yanzilu and yanziluPython'In [34]: mystr.startswith("hello")Out[34]: TrueIn [35]: mystr.startswith("Hello")Out[35]: FalseIn [36]: mystr.startswith("h")Out[36]: TrueIn [37]: mystr.endswith("Pthon")Out[37]: FalseIn [38]: mystr.endswith("Python")Out[38]: TrueIn [39]: mystr.upper()。 Out[39]: 'HELLO WORLD YANZILU AND YANZILUPYTHON'In [40]: mystr.lower() Out[40]: 'hello world yanzilu and yanzilupython'
In [44]: mystr.lstrip()Out[44]: '那一夜我伤害了你
In [45]: mystr.rstrip()Out[45]: ' 那一夜我伤害了你'
In [46]: mystr.strip()Out[46]: '那一夜我伤害了你'
In [47]: mystr.isspace()Out[47]: FalseIn [48]: mystr = " "In [49]: mystr.isspace()Out[49]: True
In [50]: mystr = "abc" In [51]: mystr.isalpha()Out[51]: TrueIn [52]: mystr = "abc1"In [53]: mystr.isalpha()Out[53]: False
In [54]: mystr = "123123"In [55]: mystr.isdigit()Out[55]: TrueIn [56]: mystr = "123123aa"In [57]: mystr.isdigit()Out[57]: False
In [58]: mystr.isalnum()Out[58]: TrueIn [59]: mystr = "123123 aa"In [60]: mystr.isalnum()Out[60]: False
In [61]: mystr = 'hello world yanzilu and yanziluPython'In [62]: mystr.title()Out[63]: 'Hello World Yanzilu And Yanzilupython'
In [64]: mystr.capitalize()Out[64]: 'Hello world yanzilu and yanzilupython'
In [65]: mystr.count("hello")Out[65]: 1In [66]: mystr.count("yan")Out[66]: 2In [67]: mystr = " "In [68]: name Out[68]: ['hello', 'world', 'yanzilu', 'and', 'yanziluPython']In [69]: mystr.join(name)Out[69]: 'hello world yanzilu and yanziluPython'In [70]: mystr = "_"In [71]: mystr.join(name)Out[71]: 'hello_world_yanzilu_and_yanziluPython'
#变量names_list的类型为列表names_list = [' 刘备',' 曹操',' 孙权']
#打印多个姓名names_list = [' 刘备',' 曹操',' 孙权']print(names_list[0])print(names_list[1])print(names_list[2]) names = [' 刘备',' 曹操',' 孙权'] for x in names print(x)i=1while i<len><h2>5.列表的增删改查:</h2>
<p>列表中存放的数据是可以进行修改的,比如"增"、“删”、“改”</p>
<h3><strong>5.1列表的添加元素("增"append, extend, insert)</strong></h3>
<p>append可以向列表添加元素<br> extend将另一个集合中的元素逐一添加到列表中<br> insert在指定位置index前插入元素</p>
<pre class="brush:php;toolbar:false">name=[“刘备” , ”曹操” , ”孙权”]print(“增加之前:”,name)info=[“黄忠” , ”魏延”]append追加
names.append("吕布")names.append("貂蝉")names.append(info)
#append把中括号也增加上了print("增加之后:",names)这里是引用
使用extend合并列表
info = ["黄忠","魏延"]names.extend(info)print("增加之后:",names)这里是引用
insert在指定位置前插入元素
names.insert(0,"刘禅")print("增加之后:",names)del根据下标进行删除
pop删除最后一个元素
remove根据元素的值进行删除
names = ['刘备', '曹操', '孙权', '吕布', '貂蝉', '黄忠', '魏延']print("删除前:",names)del names[1]print("del删除后:",names)names.pop()names.pop()print("pop删除后:",names)name = input("请输入您要删除的历史人物:")names.remove(name)print("remove删除后:",names)通过下标修改元素 (" 改 ")
names = ["刘备","曹操","孙权"]names[0] = "刘禅"print(names)
python中查找的常用方法为:
in (存在), 如果存在那么结果为True ,否则为False
not in (不存在),如果不存在那么结果为True ,否则False
index和count与字符串中的用法相同
names = ['刘备', '曹操', '孙权', '吕布', '貂蝉', '黄忠', '魏延',"曹操"]findName = input("请输入您要查找的姓名:")if findName in names:
print("已经找到:%s"%findName)else:
print("没有找到:%s"%findName)In [1]: names = ['刘备', '曹操', '孙权', '吕布', '貂蝉', '黄忠', '魏延',’曹操’]In [2]: name.index(“曹操”)Out[2]:1In [3]: name.index(“曹操”,2,leb(names))Out[3]:7In [4]: name.count(“曹操”)Out[4]:2
sort方法是将list按特定顺序重新排列,默认为由小到大(True:从小到大;False从大到小)
reverse=True可改为倒序,由大到小。
reverse方法是将list逆置。需要先排序再降序
类似while循环的嵌套,列表也是支持嵌套的一个列表中的元素又是一个列表,那么这就是列表的嵌套
示例:
school_names = [[' 北京大学',' 清华大学'],[' 南开大学',' 天津大学'],[' 贵州大学',' 青海大学']]print(school_names)
#print(school_names)#print(len(school_names))#print(school_names[2][1])for school in school_names:
print("="*30)
print(school)
for name in school:
print(name)一个学校,有3个办公室,现在有8位老师等待工位的分配,请编写程序,完成随机的分配
import random
offices = [[ ],[ ],[ ]]names = ['刘备', '曹操', '孙权', '吕布', '貂蝉', '黄忠', '魏延','大乔']for office in offices:
#得到一个教师的下标
index = random.randint(0,len(names)-1)
#分配老师
name = names[index]
office.append(name)
#要移除已经完成分配的老师
names.remove(name)for name in names:
#得到办公室编号
index = random.randint(0,2)
offices[index].append(name)#print(offices)#打印出来哪些办公室有哪些老师i= 1for office in offices:
#office = ["刘备","曹操"]
print("办公室%s : 共%s人"%(i,len(office)))
i+=1
for name in office:
print("%s"%name,end="\t\t")
print()
print("="*30)推荐学习:python视频教程
Atas ialah kandungan terperinci Pelajari aksara dan senarai Python secara ringkas (contoh terperinci). Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!


















![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



