
 pangkalan data
tutorial mysql
Ringkasan penyelesaian kepada kelewatan tuan-hamba MySQL dan pemisahan baca-tulis
pangkalan data
tutorial mysql
Ringkasan penyelesaian kepada kelewatan tuan-hamba MySQL dan pemisahan baca-tulis
Ringkasan penyelesaian kepada kelewatan tuan-hamba MySQL dan pemisahan baca-tulis

Artikel ini membawa anda pengetahuan yang berkaitan tentang mysql terutamanya penyelesaian kepada kelewatan master-slave dan pemisahan baca-tulis Mari kita lihat dan ringkaskan beberapa kaedah.

Pembelajaran yang disyorkan: tutorial video mysql
Kita semua tahu bahawa data Internet mempunyai ciri, kebanyakan senario adalah 读多写少 , seperti sebagai: Weibo, WeChat, Taobao e-dagang, mengikut 二八原则, nisbah trafik baca malah boleh mencapai 90%
Digabungkan dengan ciri ini, kami juga akan membuat pelarasan yang sepadan dengan seni bina pangkalan data asas. Menggunakan 读写分离
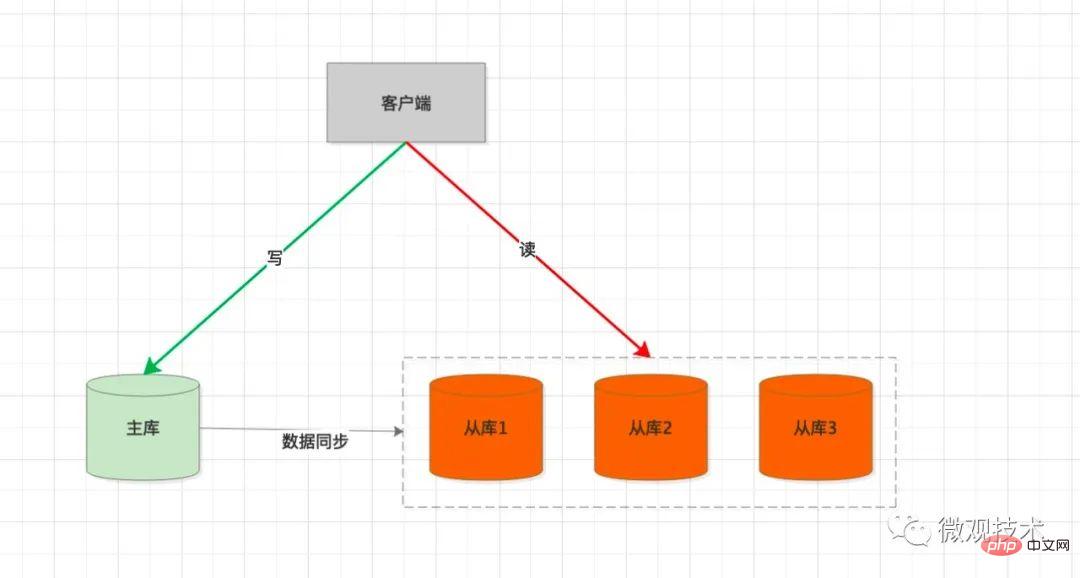
proses pemprosesan:
Pelanggan akan menyepadukan SDK dan melaksanakan SQL setiap masa Bila, ia akan dinilai sebagai operasi
写atau读Jika
写SQL, permintaan akan dihantar ke主库Pangkalan data induk melaksanakan SQL Selepas transaksi diserahkan,
binlogakan dijana dan disegerakkan ke从库从库melalui SQL. main balik benangbinlogdan dalam jadual pangkalan data hamba Jana data yang sepadan dalamJika ia
读SQL, permintaan akan melepasi strategi负载均衡dan pilih从库untuk mengendalikan permintaan pengguna
Nampaknya sangat munasabah, tetapi apabila anda memikirkannya, perkara itu tidak berlaku
主库 dan 从库 gunakan tak segerak. replikasi data Bagaimana jika data antara kedua-duanya belum disegerakkan?
Pangkalan data utama baru sahaja selesai menulis data, dan pangkalan data hamba belum sempat menarik data terkini 读 Permintaan datang, memberikan pengguna perasaan, 数据丢了???
Sebagai tindak balas kepada masalah ini, hari ini, mari kita bincangkan apakah penyelesaian yang ada?
1. Penggunaan paksa pangkalan data utama
Mengikut permintaan perniagaan yang tidak digunakan, layan mereka secara berbeza
Senario 1:
Jika ia 实时性 Keperluan untuk data tidak begitu tinggi Contohnya, jika V besar mempunyai berpuluh juta peminat dan menyiarkan mesej Weibo, ia tidak akan memberi impak yang besar jika peminat menerima mesej itu. beberapa saat kemudian. Pada masa ini, anda boleh pergi 从库.
Senario 2:
Jika keperluan data 实时性 sangat tinggi, seperti perniagaan kewangan. Kita boleh memaksa pertanyaan untuk pergi ke pangkalan data utama di bawah teg kod klien.
2. Pertanyaan tertunda daripada pangkalan data hamba
Memandangkan penyegerakan data antara pangkalan data induk dan hamba memerlukan selang masa tertentu, terdapat strategi untuk menangguhkan pertanyaan data daripada pangkalan data hamba.
Contohnya:
select sleep(1) select * from order where order_id=11111;
Dalam pertanyaan perniagaan formal, mula-mula laksanakan pernyataan tidur untuk menempah tempoh penimbal penyegerakan data tertentu untuk pangkalan data hamba.
Oleh kerana ia adalah penyelesaian yang sesuai untuk semua, apabila berhadapan dengan senario perniagaan yang sepadan tinggi, prestasi akan menurun secara mendadak Penyelesaian ini biasanya tidak disyorkan.
3. Tentukan sama ada tuan dan hamba ditangguhkan? Tentukan sama ada untuk memilih perpustakaan utama atau perpustakaan hamba
Pilihan 1:
Laksanakan arahan dalam perpustakaan hamba show slave status
Lihat nilai seconds_behind_master dalam unit ialah saat Jika 0, ini bermakna tiada kelewatan antara perpustakaan induk dan hamba
Pilihan 2:
Bandingkan titik fail pustaka induk dan hamba
Atau jalankan show slave status, hasil tindak balas mengandungi parameter utama
Fail_Log_Induk membaca fail terkini pustaka utama
Read_Master_Log_Pos read Kedudukan koordinat fail terkini dalam pustaka utama
Relay_Master_Log_File Kedudukan koordinat fail terkini yang dilaksanakan daripada pustaka hamba
Exec_Master_Log_Pos Kedudukan koordinat fail terkini yang dilaksanakan daripada pustaka hamba
Bandingkan antara satu sama lain untuk melihat sama ada parameter di atas adalah sama
Pilihan 3:
Banding set GTID
Auto_Position=1 Gunakan protokol GTID antara tuan dan hamba
Retrieved_Gtid_Set Set GTID bagi semua log binlog yang diterima daripada perpustakaan
-
Executed_Gtid_Set Set GTID yang telah dilaksanakan daripada pustaka
Retrieved_Gtid_Set adalah sama Executed_Gtid_SetApabila melaksanakan operasi SQL perniagaan, pertama Tentukan sama ada pangkalan data hamba telah menyegerakkan data terkini. Ini menentukan sama ada untuk mengendalikan pangkalan data induk atau pangkalan data hamba.
Kelemahan:
Tidak kira mana penyelesaian di atas diterima pakai, jika perpustakaan utama mempunyai operasi tulis yang kerap, nilai perpustakaan hamba tidak akan setanding dengan nilai perpustakaan utama , maka trafik baca akan sentiasa mencecah pangkalan data utama.针对这个问题,有什么解决方案?
这个问题跟 MQ消息队列 既要求高吞吐量又要保证顺序是一样的,从全局来看确实无解,但是缩小范围就容易多了,我们可以保证一个分区内的消息有序。
回到 主从库 之间的数据同步问题,从库查询哪条记录,我们只要保证之前对应的写binglog已经同步完数据即可,可以不用管主从库的所有的事务binlog 是否同步。
问题是不是一下简单多了
四、从库节点判断主库位点
在从库执行下面命令,返回是一个正整数 M,表示从库从参数节点开始执行了多少个事务
select master_pos_wait(file, pos[, timeout]);
file 和 pos 表示主库上的文件名和位置
timeout 可选, 表示这个函数最多等待 N 秒
缺点:
master_pos_wait 返回结果无法与具体操作的数据行做关联,所以每次接收读请求时,从库还是无法确认是否已经同步数据,方案实用性不高。
五、比较 GTID
执行下面查询命令
阻塞等待,直到从库执行的事务中包含 gtid_set,返回 0
超时,返回 1
select wait_for_executed_gtid_set(gtid_set, 1);
MySQL 5.7.6 版本开始,允许在执行完更新类事务后,把这个事务的 GTID 返回给客户端。具体操作,将参数
session_track_gtids设置为OWN_GTID,调用 API 接口mysql_session_track_get_first返回结果解析出 GTID
处理流程:
发起
写SQL 操作,在主库成功执行后,返回这个事务的 GTID发起
读SQL 操作时,先在从库执行select wait_for_executed_gtid_set (gtid_set, 1)如果返回 0,表示已经从库已经同步了数据,可以在从库执行
查询操作否则,在主库执行
查询操作
缺点:
跟上面的 master_pos_wait 类似,如果 写操作 与 读操作 没有上下文关联,那么 GTID 无法传递 。方案实用性不高。
六、引入缓存中间件
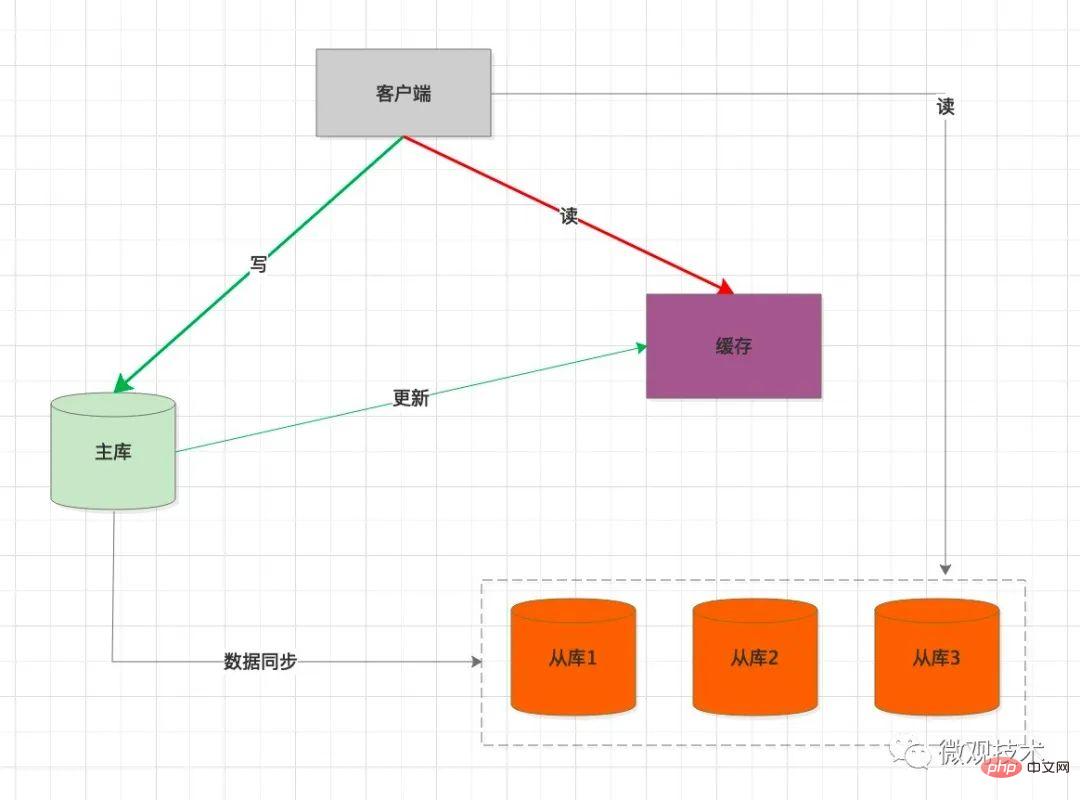
高并发系统,缓存作为性能优化利器,应用广泛。我们可以考虑引入缓存作为缓冲介质
处理过程:
客户端
写SQL ,操作主库同步将缓存中的数据删除
当客户端读数据时,优先从缓存加载
如果 缓存中没有,会强制查询主库预热数据
缺点:
K-V 存储,适用一些简单的查询条件场景。如果复杂的查询,还是要查询从库。
七、数据分片
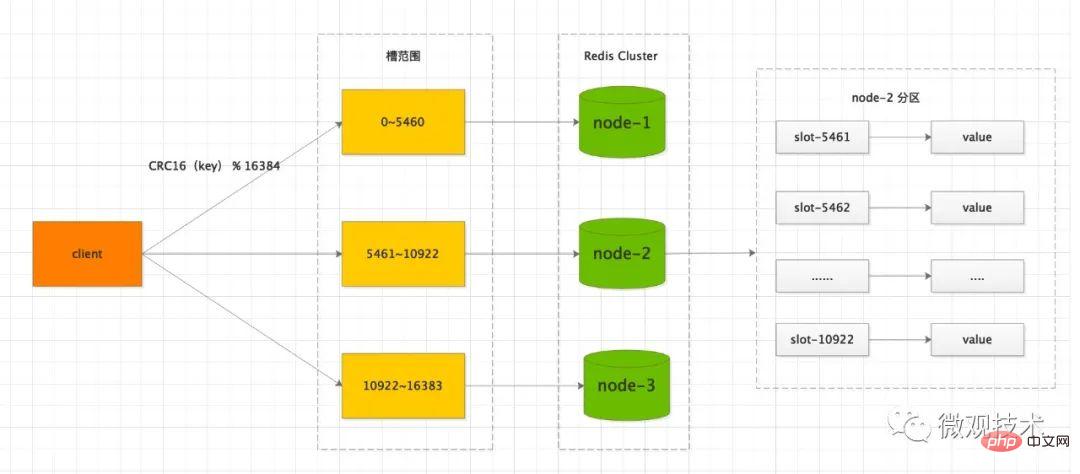
参考 Redis Cluster 模式, 集群网络拓扑通常是 3主 3从,主节点既负责写,也负责读。
通过水平分片,支持数据的横向扩展。由于每个节点都是独立的服务器,可以提高整体集群的吞吐量。
转换到数据库方面
常见的解决方式,是分库分表,每次读写都是操作主库的一个分表,从库只用来做数据备份。当主库发生故障时,主从切换,保证集群的高可用性。
推荐学习:mysql视频教程
Atas ialah kandungan terperinci Ringkasan penyelesaian kepada kelewatan tuan-hamba MySQL dan pemisahan baca-tulis. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1382
1382
 52
52

 Mysql: Konsep mudah untuk pembelajaran mudah
Apr 10, 2025 am 09:29 AM
Mysql: Konsep mudah untuk pembelajaran mudah
Apr 10, 2025 am 09:29 AM
MySQL adalah sistem pengurusan pangkalan data sumber terbuka. 1) Buat Pangkalan Data dan Jadual: Gunakan perintah Createdatabase dan Createtable. 2) Operasi Asas: Masukkan, Kemas kini, Padam dan Pilih. 3) Operasi lanjutan: Sertai, subquery dan pemprosesan transaksi. 4) Kemahiran Debugging: Semak sintaks, jenis data dan keizinan. 5) Cadangan Pengoptimuman: Gunakan indeks, elakkan pilih* dan gunakan transaksi.
 Cara membuka phpmyadmin
Apr 10, 2025 pm 10:51 PM
Cara membuka phpmyadmin
Apr 10, 2025 pm 10:51 PM
Anda boleh membuka phpmyadmin melalui langkah -langkah berikut: 1. Log masuk ke panel kawalan laman web; 2. Cari dan klik ikon phpmyadmin; 3. Masukkan kelayakan MySQL; 4. Klik "Login".
 MySQL: Pengenalan kepada pangkalan data paling popular di dunia
Apr 12, 2025 am 12:18 AM
MySQL: Pengenalan kepada pangkalan data paling popular di dunia
Apr 12, 2025 am 12:18 AM
MySQL adalah sistem pengurusan pangkalan data relasi sumber terbuka, terutamanya digunakan untuk menyimpan dan mengambil data dengan cepat dan boleh dipercayai. Prinsip kerjanya termasuk permintaan pelanggan, resolusi pertanyaan, pelaksanaan pertanyaan dan hasil pulangan. Contoh penggunaan termasuk membuat jadual, memasukkan dan menanyakan data, dan ciri -ciri canggih seperti Operasi Join. Kesalahan umum melibatkan sintaks SQL, jenis data, dan keizinan, dan cadangan pengoptimuman termasuk penggunaan indeks, pertanyaan yang dioptimumkan, dan pembahagian jadual.
 Mengapa menggunakan mysql? Faedah dan kelebihan
Apr 12, 2025 am 12:17 AM
Mengapa menggunakan mysql? Faedah dan kelebihan
Apr 12, 2025 am 12:17 AM
MySQL dipilih untuk prestasi, kebolehpercayaan, kemudahan penggunaan, dan sokongan komuniti. 1.MYSQL Menyediakan fungsi penyimpanan dan pengambilan data yang cekap, menyokong pelbagai jenis data dan operasi pertanyaan lanjutan. 2. Mengamalkan seni bina pelanggan-pelayan dan enjin penyimpanan berganda untuk menyokong urus niaga dan pengoptimuman pertanyaan. 3. Mudah digunakan, menyokong pelbagai sistem operasi dan bahasa pengaturcaraan. 4. Mempunyai sokongan komuniti yang kuat dan menyediakan sumber dan penyelesaian yang kaya.
 Cara menggunakan redis berulir tunggal
Apr 10, 2025 pm 07:12 PM
Cara menggunakan redis berulir tunggal
Apr 10, 2025 pm 07:12 PM
Redis menggunakan satu seni bina berulir untuk memberikan prestasi tinggi, kesederhanaan, dan konsistensi. Ia menggunakan I/O multiplexing, gelung acara, I/O yang tidak menyekat, dan memori bersama untuk meningkatkan keserasian, tetapi dengan batasan batasan konkurensi, satu titik kegagalan, dan tidak sesuai untuk beban kerja yang berintensifkan.
 Tempat Mysql: Pangkalan Data dan Pengaturcaraan
Apr 13, 2025 am 12:18 AM
Tempat Mysql: Pangkalan Data dan Pengaturcaraan
Apr 13, 2025 am 12:18 AM
Kedudukan MySQL dalam pangkalan data dan pengaturcaraan sangat penting. Ia adalah sistem pengurusan pangkalan data sumber terbuka yang digunakan secara meluas dalam pelbagai senario aplikasi. 1) MySQL menyediakan fungsi penyimpanan data, organisasi dan pengambilan data yang cekap, sistem sokongan web, mudah alih dan perusahaan. 2) Ia menggunakan seni bina pelanggan-pelayan, menyokong pelbagai enjin penyimpanan dan pengoptimuman indeks. 3) Penggunaan asas termasuk membuat jadual dan memasukkan data, dan penggunaan lanjutan melibatkan pelbagai meja dan pertanyaan kompleks. 4) Soalan -soalan yang sering ditanya seperti kesilapan sintaks SQL dan isu -isu prestasi boleh disahpepijat melalui arahan jelas dan log pertanyaan perlahan. 5) Kaedah pengoptimuman prestasi termasuk penggunaan indeks rasional, pertanyaan yang dioptimumkan dan penggunaan cache. Amalan terbaik termasuk menggunakan urus niaga dan preparedStatemen
 MySQL dan SQL: Kemahiran Penting untuk Pemaju
Apr 10, 2025 am 09:30 AM
MySQL dan SQL: Kemahiran Penting untuk Pemaju
Apr 10, 2025 am 09:30 AM
MySQL dan SQL adalah kemahiran penting untuk pemaju. 1.MYSQL adalah sistem pengurusan pangkalan data sumber terbuka, dan SQL adalah bahasa standard yang digunakan untuk mengurus dan mengendalikan pangkalan data. 2.MYSQL menyokong pelbagai enjin penyimpanan melalui penyimpanan data yang cekap dan fungsi pengambilan semula, dan SQL melengkapkan operasi data yang kompleks melalui pernyataan mudah. 3. Contoh penggunaan termasuk pertanyaan asas dan pertanyaan lanjutan, seperti penapisan dan penyortiran mengikut keadaan. 4. Kesilapan umum termasuk kesilapan sintaks dan isu -isu prestasi, yang boleh dioptimumkan dengan memeriksa penyataan SQL dan menggunakan perintah menjelaskan. 5. Teknik pengoptimuman prestasi termasuk menggunakan indeks, mengelakkan pengimbasan jadual penuh, mengoptimumkan operasi menyertai dan meningkatkan kebolehbacaan kod.
 Cara Membina Pangkalan Data SQL
Apr 09, 2025 pm 04:24 PM
Cara Membina Pangkalan Data SQL
Apr 09, 2025 pm 04:24 PM
Membina pangkalan data SQL melibatkan 10 langkah: memilih DBMS; memasang DBMS; mewujudkan pangkalan data; mewujudkan jadual; memasukkan data; mengambil data; mengemas kini data; memadam data; menguruskan pengguna; Menyandarkan pangkalan data.
