
 pembangunan bahagian belakang
Tutorial Python
Contoh Python penjelasan terperinci tentang pdfplumber membaca PDF dan menulis ke Excel
pembangunan bahagian belakang
Tutorial Python
Contoh Python penjelasan terperinci tentang pdfplumber membaca PDF dan menulis ke Excel
Contoh Python penjelasan terperinci tentang pdfplumber membaca PDF dan menulis ke Excel

Artikel ini membawa anda pengetahuan yang berkaitan tentang python, yang terutamanya memperkenalkan isu berkaitan tentang pdfplumber membaca PDF dan menulis ke Excel, termasuk pemasangan modul pdfplumber, memuatkan PDF, dan Mari lihat beberapa operasi praktikal dan sebagainya saya harap ia akan membantu semua orang.

Pembelajaran yang disyorkan: tutorial video python
1. Perbandingan 13 perpustakaan utama untuk mengendalikan PDF dalam Python
PDF ( Portable Document Format) ialah format dokumen mudah alih yang memudahkan penyebaran dokumen merentasi sistem pengendalian. Dokumen PDF mengikut format standard, jadi terdapat banyak alat yang boleh beroperasi pada dokumen PDF, dan Python tidak terkecuali.
Carta perbandingan modul PDF yang mengendalikan Python adalah seperti berikut:
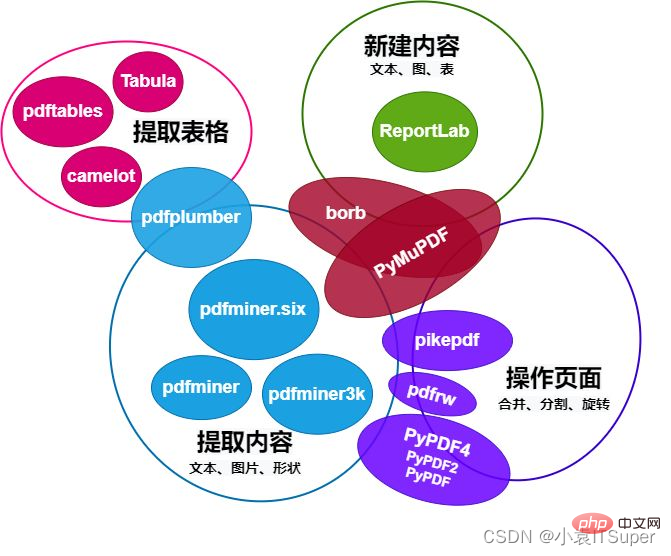
Artikel ini terutamanya memperkenalkan pdfplumber Fokus pada pengekstrakan kandungan PDF, seperti teks ( kedudukan, fon dan warna, dsb.) dan bentuk (segi empat tepat, garisan, lengkung), serta keupayaan untuk menghuraikan jadual.
2. modul pdfplumber
Beberapa perpustakaan Python lain membantu pengguna mengekstrak maklumat daripada PDF. Sebagai gambaran keseluruhan yang luas, pdfplumber membezakan dirinya daripada perpustakaan pemprosesan PDF lain dengan menggabungkan ciri berikut:
- Akses mudah kepada maklumat terperinci tentang setiap objek PDF
- untuk cara yang lebih tinggi dan boleh disesuaikan untuk mengekstrak teks dan jadual
- Penyahpepijatan visual bersepadu ketat
- Ciri utiliti berguna lain seperti menapis objek mengikut kotak pangkas
1 input konsol cmd:
Pakej panduan:pip install pdfplumber
import pdfplumber
 2 . Muatkan PDF
2 . Muatkan PDF
Baca kod PDF:
pdfplumber.open("路径/文件名.pdf", password = "test", laparams = { "line_overlap": 0.7 })Tafsiran parameter:
- : Untuk memuatkan PDF yang dilindungi kata laluan, lulus kata kunci kata laluan hujah
password: Untuk menetapkan parameter analisis reka letak kepada enjin susun atur pdfminer.six, lulus hujah kata kunci laparams -
laparamsKod kes:
import pdfplumberwith pdfplumber.open("./1.pdf") as pdf:
print(pdf)
print(type(pdf))<pdfplumber.pdf.pdf><class></class></pdfplumber.pdf.pdf>
pdfplumber.PDF
| 属性 | 说明 |
|---|---|
.metadata |
从PDF的Info中获取元数据键 /值对字典。 通常包括“ CreationDate”,“ ModDate”,“ Producer”等。 |
.pages |
返回一个包含pdfplumber.Page实例的列表,每一个实例代表PDF每一页的信息 |
) : .metadata
import pdfplumberwith pdfplumber.open("./1.pdf") as pdf:
print(pdf.metadata)
{'Author': 'wangwangyuqing', 'Comments': '', 'Company': '', 'CreationDate': "D:20220330113508+03'35'", 'Creator': 'WPS 文字', 'Keywords': '', 'ModDate': "D:20220330113508+03'35'", 'Producer': '', 'SourceModified': "D:20220330113508+03'35'", 'Subject': '', 'Title': '', 'Trapped': 'False'}Hasil berjalan:
import pdfplumberwith pdfplumber.open("./1.pdf") as pdf:
print(len(pdf.pages))2
pdfplumber.Page
| 属性 | 说明 |
|---|---|
.page_number |
顺序页码,从1第一页开始,从第二页开始2,依此类推。 |
.width |
页面的宽度。 |
.height |
页面的高度。 |
.objects/.chars/.lines/.rects/.curves/.figures/.images |
这些属性中的每一个都是一个列表,每个列表包含一个字典,用于嵌入页面上的每个此类对象。有关详细信息,请参阅下面的“对象”。 |
:
1. 读取第一页宽度、高度等信息
import pdfplumberwith pdfplumber.open("./1.pdf") as pdf:
first_page = pdf.pages[0] # pdfplumber.Page对象的第一页
# 查看页码
print('页码:', first_page.page_number)
# 查看页宽
print('页宽:', first_page.width)
# 查看页高
print('页高:', first_page.height)运行结果:
页码: 1页宽: 595.3页高: 841.9
2. 读取文本第一页
import pdfplumberwith pdfplumber.open("./1.pdf") as pdf:
first_page = pdf.pages[0] # pdfplumber.Page对象的第一页
text = first_page.extract_text()
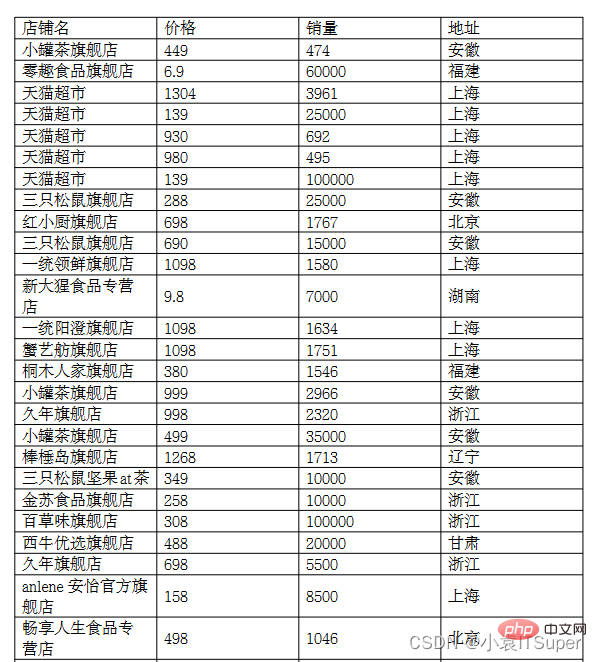
print(text)运行结果:
店铺名 价格 销量 地址 小罐茶旗舰店 449 474 安徽 零趣食品旗舰店 6.9 60000 福建 天猫超市 1304 3961 上海 天猫超市 139 25000 上海 天猫超市 930 692 上海 天猫超市 980 495 上海 天猫超市 139 100000 上海 三只松鼠旗舰店 288 25000 安徽 红小厨旗舰店 698 1767 北京 三只松鼠旗舰店 690 15000 安徽 一统领鲜旗舰店 1098 1580 上海 新大猩食品专营9.8 7000 湖南.......舰店 蟹纳旗舰店 498 1905 上海 三只松鼠坚果at茶 188 35000 安徽 嘉禹沪晓旗舰店 598 1517 上海
3. 读取表格第一页
import pdfplumberimport xlwtwith pdfplumber.open("1.pdf") as pdf:
page_one = pdf.pages[0] # PDF第一页
table_1 = page_one.extract_table() # 读取表格数据
# 1. 创建Excel表对象
workbook = xlwt.Workbook(encoding='utf8')
# 2. 新建sheet表
worksheet = workbook.add_sheet('Sheet1')
# 3. 自定义列名
col1 = table_1[0]
# print(col1)# ['店铺名', '价格', '销量', '地址']
# 4. 将列属性元组col写进sheet表单中第一行
for i in range(0, len(col1)):
worksheet.write(0, i, col1[i])
# 5. 将数据写进sheet表单中
for i in range(0, len(table_1[1:])):
data = table_1[1:][i]
for j in range(0, len(col1)):
worksheet.write(i + 1, j, data[j])
# 6. 保存文件分两种格式
workbook.save('test.xls')运行结果: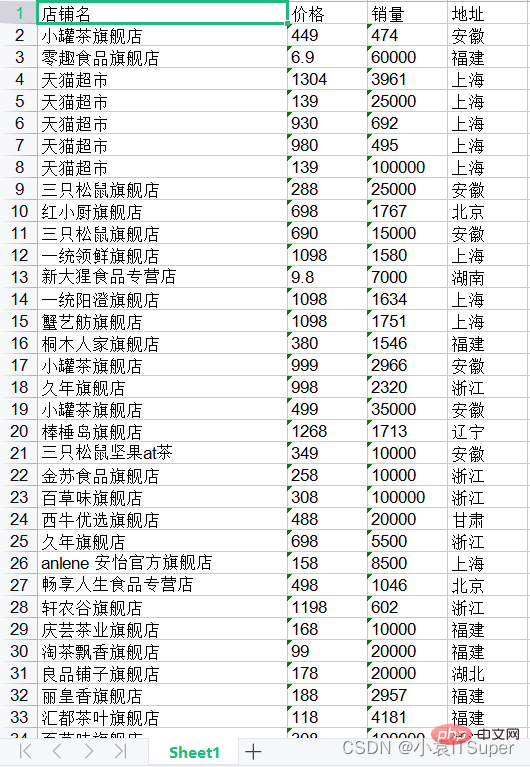
三、实战操作
1. 提取单个PDF全部页数
测试代码:
import pdfplumberimport xlwtwith pdfplumber.open("1.pdf") as pdf:
# 1. 把所有页的数据存在一个临时列表中
item = []
for page in pdf.pages:
text = page.extract_table()
for i in text:
item.append(i)
# 2. 创建Excel表对象
workbook = xlwt.Workbook(encoding='utf8')
# 3. 新建sheet表
worksheet = workbook.add_sheet('Sheet1')
# 4. 自定义列名
col1 = item[0]
# print(col1)# ['店铺名', '价格', '销量', '地址']
# 5. 将列属性元组col写进sheet表单中第一行
for i in range(0, len(col1)):
worksheet.write(0, i, col1[i])
# 6. 将数据写进sheet表单中
for i in range(0, len(item[1:])):
data = item[1:][i]
for j in range(0, len(col1)):
worksheet.write(i + 1, j, data[j])
# 7. 保存文件分两种格式
workbook.save('test.xls')运行结果(上面得没截全):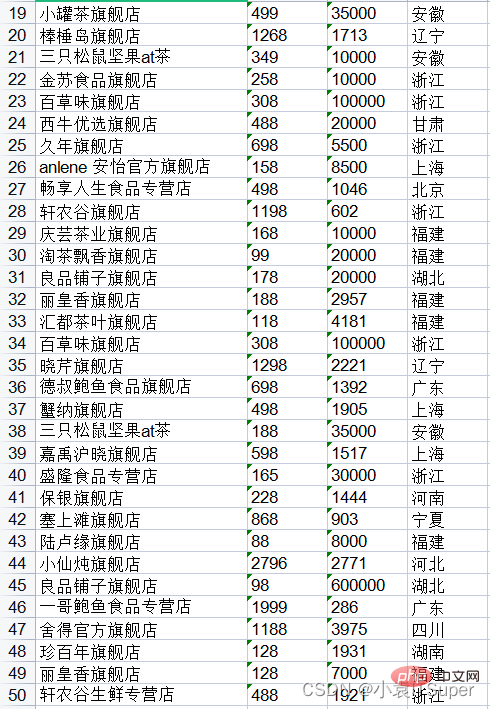
2. 批量提取多个PDF文件
测试代码:
import pdfplumber
import xlwt
import os
# 一、获取文件下所有pdf文件路径
file_dir = r'E:\Python学习\pdf文件'
file_list = []
for files in os.walk(file_dir):
# print(files)
# ('E:\\Python学习\\pdf文件', [],
# ['1.pdf', '1的副本.pdf', '1的副本10.pdf', '1的副本11.pdf', '1的副本2.pdf', '1的副本3.pdf', '1的副本4.pdf', '1的副本5.pdf', '1的副本6.pdf',
# '1的副本7.pdf', '1的副本8.pdf', '1的副本9.pdf'])
for file in files[2]:
# 以. 进行分割如果后缀为PDF或pdf就拼接地址存入file_list
if file.split(".")[1] == 'pdf' or file.split(".")[1] == 'PDF':
file_list.append(file_dir + '\\' + file)
# 二、存入Excel
# 1. 把所有PDF文件的所有页的数据存在一个临时列表中
item = []
for file_path in file_list:
with pdfplumber.open(file_path) as pdf:
for page in pdf.pages:
text = page.extract_table()
for i in text:
item.append(i)
# 2. 创建Excel表对象
workbook = xlwt.Workbook(encoding='utf8')
# 3. 新建sheet表
worksheet = workbook.add_sheet('Sheet1')
# 4. 自定义列名
col1 = item[0]
# print(col1)# ['店铺名', '价格', '销量', '地址']
# 5. 将列属性元组col写进sheet表单中第一行
for i in range(0, len(col1)):
worksheet.write(0, i, col1[i])
# 6. 将数据写进sheet表单中
for i in range(0, len(item[1:])):
data = item[1:][i]
for j in range(0, len(col1)):
worksheet.write(i + 1, j, data[j])
# 7. 保存文件分两种格式
workbook.save('test.xls')运行结果(12个文件,一个文件50行总共600行):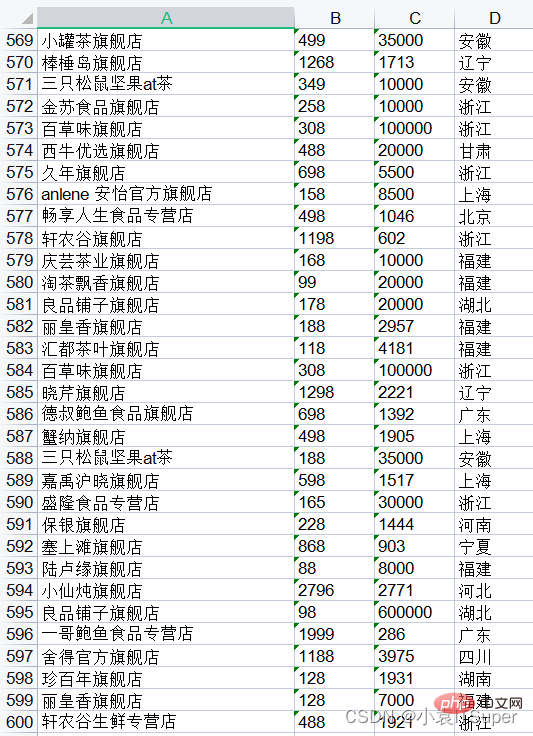
推荐学习:python视频教程
Atas ialah kandungan terperinci Contoh Python penjelasan terperinci tentang pdfplumber membaca PDF dan menulis ke Excel. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

Video Face Swap
Tukar muka dalam mana-mana video dengan mudah menggunakan alat tukar muka AI percuma kami!

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas



 PHP dan Python: Paradigma yang berbeza dijelaskan
Apr 18, 2025 am 12:26 AM
PHP dan Python: Paradigma yang berbeza dijelaskan
Apr 18, 2025 am 12:26 AM
PHP terutamanya pengaturcaraan prosedur, tetapi juga menyokong pengaturcaraan berorientasikan objek (OOP); Python menyokong pelbagai paradigma, termasuk pengaturcaraan OOP, fungsional dan prosedur. PHP sesuai untuk pembangunan web, dan Python sesuai untuk pelbagai aplikasi seperti analisis data dan pembelajaran mesin.
 Memilih antara php dan python: panduan
Apr 18, 2025 am 12:24 AM
Memilih antara php dan python: panduan
Apr 18, 2025 am 12:24 AM
PHP sesuai untuk pembangunan web dan prototaip pesat, dan Python sesuai untuk sains data dan pembelajaran mesin. 1.Php digunakan untuk pembangunan web dinamik, dengan sintaks mudah dan sesuai untuk pembangunan pesat. 2. Python mempunyai sintaks ringkas, sesuai untuk pelbagai bidang, dan mempunyai ekosistem perpustakaan yang kuat.
 Python vs JavaScript: Keluk Pembelajaran dan Kemudahan Penggunaan
Apr 16, 2025 am 12:12 AM
Python vs JavaScript: Keluk Pembelajaran dan Kemudahan Penggunaan
Apr 16, 2025 am 12:12 AM
Python lebih sesuai untuk pemula, dengan lengkung pembelajaran yang lancar dan sintaks ringkas; JavaScript sesuai untuk pembangunan front-end, dengan lengkung pembelajaran yang curam dan sintaks yang fleksibel. 1. Sintaks Python adalah intuitif dan sesuai untuk sains data dan pembangunan back-end. 2. JavaScript adalah fleksibel dan digunakan secara meluas dalam pengaturcaraan depan dan pelayan.
 Boleh kod vs dijalankan di Windows 8
Apr 15, 2025 pm 07:24 PM
Boleh kod vs dijalankan di Windows 8
Apr 15, 2025 pm 07:24 PM
Kod VS boleh dijalankan pada Windows 8, tetapi pengalaman mungkin tidak hebat. Mula -mula pastikan sistem telah dikemas kini ke patch terkini, kemudian muat turun pakej pemasangan kod VS yang sepadan dengan seni bina sistem dan pasangnya seperti yang diminta. Selepas pemasangan, sedar bahawa beberapa sambungan mungkin tidak sesuai dengan Windows 8 dan perlu mencari sambungan alternatif atau menggunakan sistem Windows yang lebih baru dalam mesin maya. Pasang sambungan yang diperlukan untuk memeriksa sama ada ia berfungsi dengan betul. Walaupun kod VS boleh dilaksanakan pada Windows 8, disyorkan untuk menaik taraf ke sistem Windows yang lebih baru untuk pengalaman dan keselamatan pembangunan yang lebih baik.
 PHP dan Python: menyelam mendalam ke dalam sejarah mereka
Apr 18, 2025 am 12:25 AM
PHP dan Python: menyelam mendalam ke dalam sejarah mereka
Apr 18, 2025 am 12:25 AM
PHP berasal pada tahun 1994 dan dibangunkan oleh Rasmuslerdorf. Ia pada asalnya digunakan untuk mengesan pelawat laman web dan secara beransur-ansur berkembang menjadi bahasa skrip sisi pelayan dan digunakan secara meluas dalam pembangunan web. Python telah dibangunkan oleh Guidovan Rossum pada akhir 1980 -an dan pertama kali dikeluarkan pada tahun 1991. Ia menekankan kebolehbacaan dan kesederhanaan kod, dan sesuai untuk pengkomputeran saintifik, analisis data dan bidang lain.
 Cara menjalankan program di terminal vscode
Apr 15, 2025 pm 06:42 PM
Cara menjalankan program di terminal vscode
Apr 15, 2025 pm 06:42 PM
Dalam kod VS, anda boleh menjalankan program di terminal melalui langkah -langkah berikut: Sediakan kod dan buka terminal bersepadu untuk memastikan bahawa direktori kod selaras dengan direktori kerja terminal. Pilih arahan Run mengikut bahasa pengaturcaraan (seperti python python your_file_name.py) untuk memeriksa sama ada ia berjalan dengan jayanya dan menyelesaikan kesilapan. Gunakan debugger untuk meningkatkan kecekapan debug.
 Adakah sambungan vscode berniat jahat?
Apr 15, 2025 pm 07:57 PM
Adakah sambungan vscode berniat jahat?
Apr 15, 2025 pm 07:57 PM
Sambungan kod VS menimbulkan risiko yang berniat jahat, seperti menyembunyikan kod jahat, mengeksploitasi kelemahan, dan melancap sebagai sambungan yang sah. Kaedah untuk mengenal pasti sambungan yang berniat jahat termasuk: memeriksa penerbit, membaca komen, memeriksa kod, dan memasang dengan berhati -hati. Langkah -langkah keselamatan juga termasuk: kesedaran keselamatan, tabiat yang baik, kemas kini tetap dan perisian antivirus.
 Bolehkah kod studio visual digunakan dalam python
Apr 15, 2025 pm 08:18 PM
Bolehkah kod studio visual digunakan dalam python
Apr 15, 2025 pm 08:18 PM
Kod VS boleh digunakan untuk menulis Python dan menyediakan banyak ciri yang menjadikannya alat yang ideal untuk membangunkan aplikasi python. Ia membolehkan pengguna untuk: memasang sambungan python untuk mendapatkan fungsi seperti penyempurnaan kod, penonjolan sintaks, dan debugging. Gunakan debugger untuk mengesan kod langkah demi langkah, cari dan selesaikan kesilapan. Mengintegrasikan Git untuk Kawalan Versi. Gunakan alat pemformatan kod untuk mengekalkan konsistensi kod. Gunakan alat linting untuk melihat masalah yang berpotensi lebih awal.
