

Bagaimana untuk mengoptimumkan pertanyaan paging mysql

Kaedah pengoptimuman untuk pertanyaan halaman: 1. Pengoptimuman subkueri, peningkatan prestasi boleh dicapai dengan menulis semula pernyataan SQL halaman ke dalam subkueri. 2. Pengoptimuman had ID, anda boleh mengira julat id yang ditanya berdasarkan bilangan halaman yang ditanya dan bilangan rekod yang ditanya, dan kemudian pertanyaan berdasarkan pernyataan "id antara dan". 3. Optimumkan berdasarkan penyusunan semula indeks, cari alamat data yang berkaitan melalui indeks dan elakkan imbasan jadual penuh. 4. Untuk pengoptimuman perkaitan yang tertunda, anda boleh menggunakan JOIN untuk melengkapkan operasi paging pada lajur indeks dahulu, dan kemudian kembali ke jadual untuk mendapatkan lajur yang diperlukan.

Persekitaran pengendalian tutorial ini: sistem windows7, versi mysql8, komputer Dell G3.
Kecekapan pertanyaan halaman adalah penting terutamanya apabila jumlah data adalah besar, menjejaskan respons bahagian hadapan dan pengalaman pengguna.
Kaedah pengoptimuman pertanyaan paging
1. Gunakan pengoptimuman subkueri
Ini kaedah mula-mula menempatkan id pada kedudukan mengimbangi dan kemudian bertanyakan kemudian Kaedah ini sesuai untuk kes di mana id semakin meningkat.
Prinsip pengoptimuman subkueri: https://www.jianshu.com/p/0768ebc4e28d
select * from sbtest1 where k=504878 limit 100000,5; proses pertanyaan:
terlebih dahulu akan menanyakan data nod daun indeks, dan kemudian tanya semua nilai medan yang diperlukan pada indeks berkelompok berdasarkan nilai kunci utama pada nod daun. Seperti yang ditunjukkan di sebelah kiri rajah di bawah, anda perlu menanyakan nod indeks 100005 kali, menanyakan data indeks berkelompok 100005 kali dan akhirnya menapis hasil daripada 100000 item pertama dan mengeluarkan 5 item terakhir. MySQL membelanjakan banyak data pertanyaan I/O rawak dalam indeks berkelompok, dan data yang ditanya oleh 100,000 I/O rawak tidak akan muncul dalam set hasil.
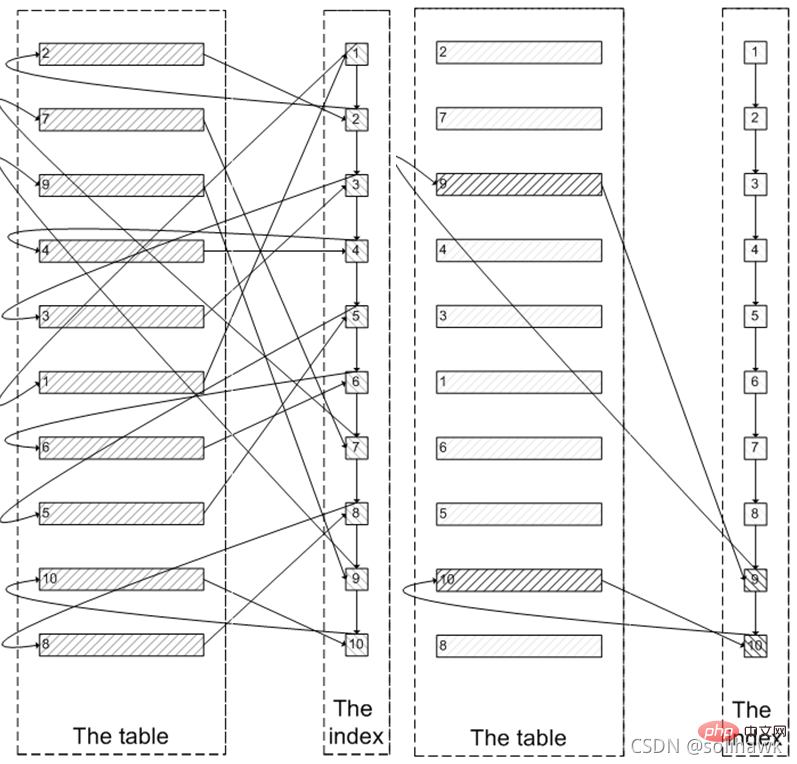
Memandangkan indeks digunakan pada mulanya, mengapa tidak bertanya dahulu di sepanjang nod daun indeks ke 5 nod terakhir yang diperlukan, dan kemudian menanyakan data sebenar dalam indeks berkelompok . Ini hanya memerlukan 5 I/O rawak, sama seperti proses di sebelah kanan gambar di atas. Ini ialah pengoptimuman subkueri dahulu. Seperti yang ditunjukkan di bawah:
mysql> select * from sbtest1 where k=5020952 limit 50,1; mysql> select id from sbtest1 where k=5020952 limit 50,1; mysql> select * from sbtest1 where k=5020952 and id>=( select id from sbtest1 where k=5020952 limit 50,1) limit 10; mysql> select * from sbtest1 where k=5020952 limit 50,10;
Dalam pengoptimuman subkueri, sama ada k dalam predikat mempunyai indeks mempunyai kesan yang besar terhadap kecekapan pertanyaan Pernyataan di atas tidak menggunakan indeks dan imbasan jadual penuh mengambil masa 24.2s. Tanpa indeks, ia mengambil masa 24.2 saat sahaja.
mysql> explain select * from sbtest1 where k=5020952 and id>=( select id from sbtest1 where k=5020952 limit 50,1) limit 10; +----+-------------+---------+------------+-------------+---------------+------------+---------+-------+------+----------+------------------------------------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+---------+------------+-------------+---------------+------------+---------+-------+------+----------+------------------------------------------+ | 1 | PRIMARY | sbtest1 | NULL | index_merge | PRIMARY,c1 | c1,PRIMARY | 8,4 | NULL | 19 | 100.00 | Using intersect(c1,PRIMARY); Using where | | 2 | SUBQUERY | sbtest1 | NULL | ref | c1 | c1 | 4 | const | 88 | 100.00 | Using index | +----+-------------+---------+------------+-------------+---------------+------------+---------+-------+------+----------+------------------------------------------+ 2 rows in set, 1 warning (0.11 sec)
Walau bagaimanapun, kaedah pengoptimuman ini juga mempunyai had:
Cara penulisan ini memerlukan ID kunci utama mestilah berturut-turut
-
Klausa Where tidak membenarkan penambahan syarat lain
2 Gunakan pengoptimuman had id
Kaedah ini menganggap id daripada. jadual data terus meningkat, maka kita boleh mengira julat ID yang ditanya berdasarkan bilangan halaman yang ditanya dan bilangan rekod yang ditanya, dan boleh disoal menggunakan id antara dan.
Dengan mengandaikan bahawa id jadual dalam pangkalan data terus meningkat, julat id yang ditanya boleh dikira berdasarkan bilangan halaman yang ditanya dan bilangan rekod yang ditanya, dan kemudian disoal berdasarkan id antara dan pernyataan. Julat id boleh dikira melalui formula paging Contohnya, jika saiz halaman semasa ialah m dan nombor halaman semasa ialah no1, maka nilai maksimum halaman ialah max=(no1 1)m-1. , dan nilai minimum ialah min=no1m, pernyataan SQL boleh dinyatakan sebagai id antara min dan maks.
select * from sbtest1 where id between 1000000 and 1000100 limit 100;
Kaedah pertanyaan ini boleh mengoptimumkan kelajuan pertanyaan dengan baik dan pada asasnya boleh diselesaikan dalam masa berpuluh-puluh milisaat. Hadnya ialah anda perlu mengetahui id dengan jelas, tetapi secara amnya dalam jadual perniagaan pertanyaan paging, medan id asas akan ditambah, yang membawa banyak kemudahan kepada pertanyaan paging. Terdapat satu lagi cara untuk menulis SQL di atas:
select * from sbtest1 where id >= 1000001 limit 100;
Anda boleh melihat perbezaan dalam masa pelaksanaan:
mysql> show profiles; +----------+------------+--------------------------------------------------------------------------------------------------------------+ | Query_ID | Duration | Query | +----------+------------+--------------------------------------------------------------------------------------------------------------+ | 6 | 0.00085500 | select * from sbtest1 where id between 1000000 and 1000100 limit 100 | | 7 | 0.12927975 | select * from sbtest1 where id >= 1000001 limit 100 | +----------+------------+--------------------------------------------------------------------------------------------------------------+
Anda juga boleh menggunakan kaedah dalam untuk membuat pertanyaan, yang selalunya digunakan Digunakan untuk bertanya apabila berbilang jadual dikaitkan Gunakan set id pertanyaan jadual lain untuk membuat pertanyaan:
select * from sbtest1 where id in (select id from sbtest2 where k=504878) limit 100;
Apabila menggunakan dalam pertanyaan, sila ambil perhatian bahawa beberapa versi mysql tidak menyokong penggunaan dalam klausa. had.
3. Pengoptimuman berdasarkan penyusunan semula indeks
Penyusunan semula berdasarkan indeks menggunakan algoritma pengoptimuman dalam pertanyaan indeks untuk mencari alamat data yang berkaitan melalui indeks untuk mengelakkan Jadual penuh imbasan, yang menjimatkan banyak masa. Selain itu, Mysql juga mempunyai cache indeks yang berkaitan, dan lebih baik menggunakan cache apabila konkurensi tinggi. Dalam MySQL, anda boleh menggunakan pernyataan berikut:
SELECT * FROM 表名称 WHERE id_pk > (pageNum*10) ORDER BY id_pk ASC LIMIT M
Kaedah ini sesuai untuk situasi di mana jumlah data adalah besar (berpuluh-puluh ribu tupel Sebaiknya objek lajur selepas ORDER BY). ialah kunci utama atau indeks unik, supaya operasi ORDER BY boleh dihapuskan menggunakan indeks tetapi set keputusan adalah stabil. Contohnya, dua pernyataan berikut:
mysql> show profiles; +----------+------------+--------------------------------------------------------------------------------------------------------------+ | Query_ID | Duration | Query | +----------+------------+--------------------------------------------------------------------------------------------------------------+ | 8 | 3.30585150 | select * from sbtest1 limit 1000000,10 | | 9 | 1.03224725 | select * from sbtest1 order by id limit 1000000,10 | +----------+------------+--------------------------------------------------------------------------------------------------------------+
Selepas menggunakan susunan demi pernyataan untuk id medan indeks, prestasi telah meningkat dengan ketara.
4 Gunakan perkaitan tertunda untuk mengoptimumkan
Sama seperti subkueri di atas, kita boleh menggunakan JOIN untuk melengkapkan operasi halaman pada lajur indeks dahulu, dan kemudian kembalikan Dapatkan lajur yang diperlukan daripada jadual.
select a.* from t5 a inner join (select id from t5 order by text limit 1000000, 10) b on a.id=b.id;

从实验中可以得出,在采用JOIN改写后,上面的两个局限性都已经解除了,而且SQL的执行效率也没有损失。
5、记录上次查询结束的位置
和上面使用的方法都不同,记录上次结束位置优化思路是使用某种变量记录上一次数据的位置,下次分页时直接从这个变量的位置开始扫描,从而避免MySQL扫描大量的数据再抛弃的操作。
select * from t5 where id>=1000000 limit 10;

6、使用临时表优化
使用临时存储的表来记录分页的id然后进行in查询
这种方式已经不属于查询优化,这儿附带提一下。
对于使用 id 限定优化中的问题,需要 id 是连续递增的,但是在一些场景下,比如使用历史表的时候,或者出现过数据缺失问题时,可以考虑使用临时存储的表来记录分页的id,使用分页的id来进行 in 查询。这样能够极大的提高传统的分页查询速度,尤其是数据量上千万的时候。
【相关推荐:mysql视频教程】
Atas ialah kandungan terperinci Bagaimana untuk mengoptimumkan pertanyaan paging mysql. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1378
1378
 52
52

 Mysql: Konsep mudah untuk pembelajaran mudah
Apr 10, 2025 am 09:29 AM
Mysql: Konsep mudah untuk pembelajaran mudah
Apr 10, 2025 am 09:29 AM
MySQL adalah sistem pengurusan pangkalan data sumber terbuka. 1) Buat Pangkalan Data dan Jadual: Gunakan perintah Createdatabase dan Createtable. 2) Operasi Asas: Masukkan, Kemas kini, Padam dan Pilih. 3) Operasi lanjutan: Sertai, subquery dan pemprosesan transaksi. 4) Kemahiran Debugging: Semak sintaks, jenis data dan keizinan. 5) Cadangan Pengoptimuman: Gunakan indeks, elakkan pilih* dan gunakan transaksi.
 Cara membuka phpmyadmin
Apr 10, 2025 pm 10:51 PM
Cara membuka phpmyadmin
Apr 10, 2025 pm 10:51 PM
Anda boleh membuka phpmyadmin melalui langkah -langkah berikut: 1. Log masuk ke panel kawalan laman web; 2. Cari dan klik ikon phpmyadmin; 3. Masukkan kelayakan MySQL; 4. Klik "Login".
 Cara Membuat Premium Navicat
Apr 09, 2025 am 07:09 AM
Cara Membuat Premium Navicat
Apr 09, 2025 am 07:09 AM
Buat pangkalan data menggunakan Navicat Premium: Sambungkan ke pelayan pangkalan data dan masukkan parameter sambungan. Klik kanan pada pelayan dan pilih Buat Pangkalan Data. Masukkan nama pangkalan data baru dan set aksara yang ditentukan dan pengumpulan. Sambung ke pangkalan data baru dan buat jadual dalam penyemak imbas objek. Klik kanan di atas meja dan pilih masukkan data untuk memasukkan data.
 MySQL dan SQL: Kemahiran Penting untuk Pemaju
Apr 10, 2025 am 09:30 AM
MySQL dan SQL: Kemahiran Penting untuk Pemaju
Apr 10, 2025 am 09:30 AM
MySQL dan SQL adalah kemahiran penting untuk pemaju. 1.MYSQL adalah sistem pengurusan pangkalan data sumber terbuka, dan SQL adalah bahasa standard yang digunakan untuk mengurus dan mengendalikan pangkalan data. 2.MYSQL menyokong pelbagai enjin penyimpanan melalui penyimpanan data yang cekap dan fungsi pengambilan semula, dan SQL melengkapkan operasi data yang kompleks melalui pernyataan mudah. 3. Contoh penggunaan termasuk pertanyaan asas dan pertanyaan lanjutan, seperti penapisan dan penyortiran mengikut keadaan. 4. Kesilapan umum termasuk kesilapan sintaks dan isu -isu prestasi, yang boleh dioptimumkan dengan memeriksa penyataan SQL dan menggunakan perintah menjelaskan. 5. Teknik pengoptimuman prestasi termasuk menggunakan indeks, mengelakkan pengimbasan jadual penuh, mengoptimumkan operasi menyertai dan meningkatkan kebolehbacaan kod.
 Cara Membuat Sambungan Baru ke MySQL di Navicat
Apr 09, 2025 am 07:21 AM
Cara Membuat Sambungan Baru ke MySQL di Navicat
Apr 09, 2025 am 07:21 AM
Anda boleh membuat sambungan MySQL baru di Navicat dengan mengikuti langkah -langkah: Buka aplikasi dan pilih Sambungan Baru (Ctrl N). Pilih "MySQL" sebagai jenis sambungan. Masukkan nama host/alamat IP, port, nama pengguna, dan kata laluan. (Pilihan) Konfigurasikan pilihan lanjutan. Simpan sambungan dan masukkan nama sambungan.
 Cara Memulihkan Data Selepas SQL Memadam Barisan
Apr 09, 2025 pm 12:21 PM
Cara Memulihkan Data Selepas SQL Memadam Barisan
Apr 09, 2025 pm 12:21 PM
Memulihkan baris yang dipadam secara langsung dari pangkalan data biasanya mustahil melainkan ada mekanisme sandaran atau transaksi. Titik Utama: Rollback Transaksi: Jalankan balik balik sebelum urus niaga komited untuk memulihkan data. Sandaran: Sandaran biasa pangkalan data boleh digunakan untuk memulihkan data dengan cepat. Snapshot Pangkalan Data: Anda boleh membuat salinan bacaan pangkalan data dan memulihkan data selepas data dipadam secara tidak sengaja. Gunakan Pernyataan Padam dengan berhati -hati: Periksa syarat -syarat dengan teliti untuk mengelakkan data yang tidak sengaja memadamkan. Gunakan klausa WHERE: Secara jelas menentukan data yang akan dipadam. Gunakan Persekitaran Ujian: Ujian Sebelum Melaksanakan Operasi Padam.
 Cara menggunakan redis berulir tunggal
Apr 10, 2025 pm 07:12 PM
Cara menggunakan redis berulir tunggal
Apr 10, 2025 pm 07:12 PM
Redis menggunakan satu seni bina berulir untuk memberikan prestasi tinggi, kesederhanaan, dan konsistensi. Ia menggunakan I/O multiplexing, gelung acara, I/O yang tidak menyekat, dan memori bersama untuk meningkatkan keserasian, tetapi dengan batasan batasan konkurensi, satu titik kegagalan, dan tidak sesuai untuk beban kerja yang berintensifkan.
 MySQL: Pengenalan kepada pangkalan data paling popular di dunia
Apr 12, 2025 am 12:18 AM
MySQL: Pengenalan kepada pangkalan data paling popular di dunia
Apr 12, 2025 am 12:18 AM
MySQL adalah sistem pengurusan pangkalan data relasi sumber terbuka, terutamanya digunakan untuk menyimpan dan mengambil data dengan cepat dan boleh dipercayai. Prinsip kerjanya termasuk permintaan pelanggan, resolusi pertanyaan, pelaksanaan pertanyaan dan hasil pulangan. Contoh penggunaan termasuk membuat jadual, memasukkan dan menanyakan data, dan ciri -ciri canggih seperti Operasi Join. Kesalahan umum melibatkan sintaks SQL, jenis data, dan keizinan, dan cadangan pengoptimuman termasuk penggunaan indeks, pertanyaan yang dioptimumkan, dan pembahagian jadual.
