
 pangkalan data
tutorial mysql
Mari kita bercakap tentang infrastruktur MySQL dan sistem pembalakan
pangkalan data
tutorial mysql
Mari kita bercakap tentang infrastruktur MySQL dan sistem pembalakan
Mari kita bercakap tentang infrastruktur MySQL dan sistem pembalakan

Artikel ini akan memberi anda sedikit pengetahuan tentang MySQL dan bercakap tentang infrastruktur MySQL dan sistem pengelogan secara mendalam. Saya harap ia akan membantu anda!

1. Infrastruktur MySQL
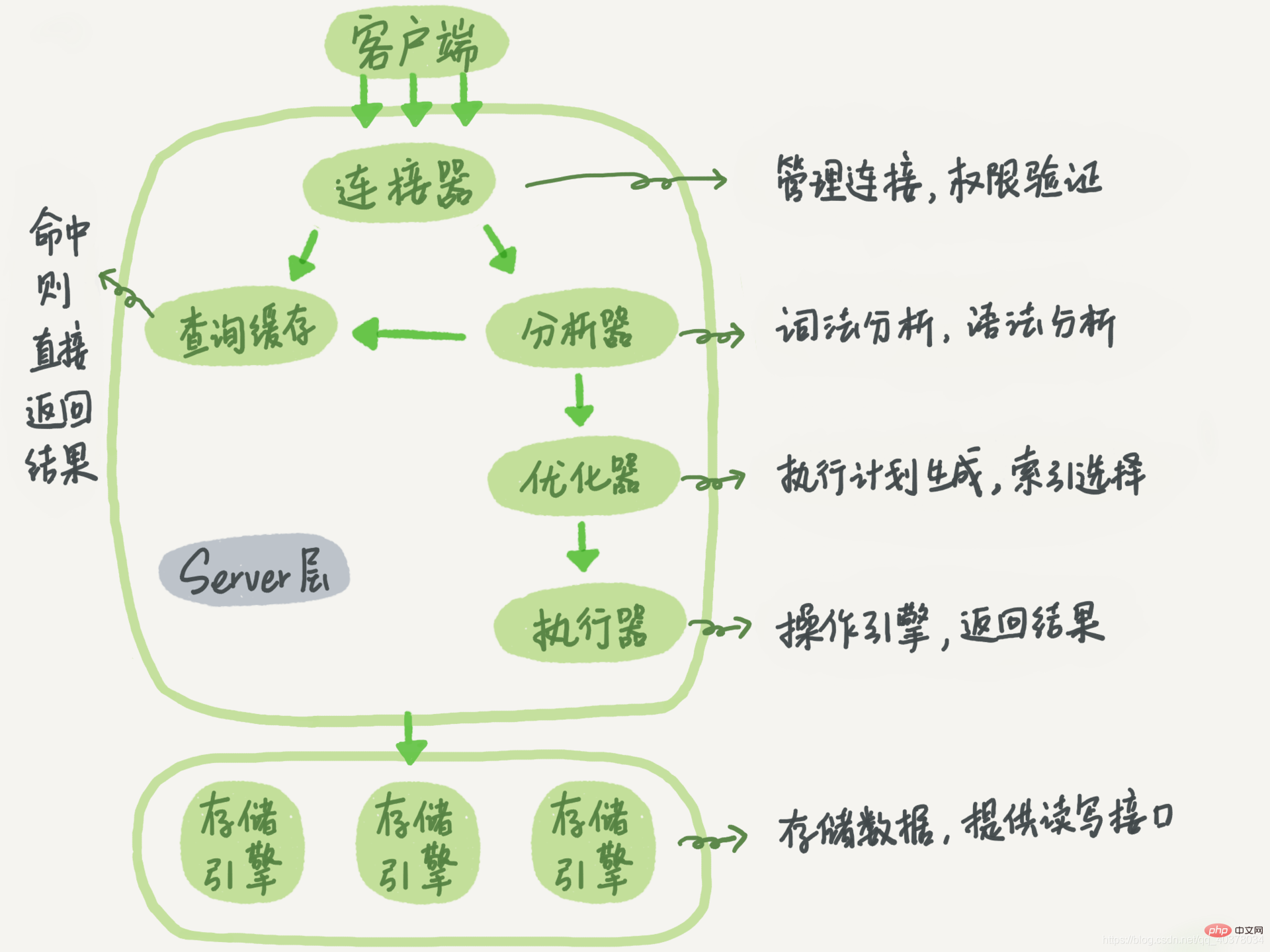
MySQL boleh dibahagikan kepada dua bahagian: Lapisan pelayan dan enjin storan lapisan
Lapisan Pelayan termasuk penyambung, cache pertanyaan, penganalisis, pengoptimum, pelaksana, dll., meliputi kebanyakan fungsi perkhidmatan teras MySQL, serta semua fungsi terbina dalam (seperti tarikh, masa, matematik dan fungsi penyulitan, dsb. ), semua fungsi enjin storan silang dilaksanakan dalam lapisan ini, seperti prosedur tersimpan, pencetus, paparan, dsb.
Enjin storan bertanggungjawab untuk penyimpanan dan pengambilan data. Model seni binanya adalah pemalam dan menyokong berbilang enjin storan seperti InnoDB, MyISAM dan Memory. Enjin storan yang paling biasa digunakan sekarang ialah InnoDB, yang telah menjadi enjin storan lalai sejak MySQL 5.5.5. Anda boleh menentukan penggunaan perlaksanaan enjin memori dengan menggunakan engin=memory dalam pernyataan SQL
Enjin storan yang berbeza berkongsi lapisan Pelayan
Penyambung
Penyambung bertanggungjawab untuk mewujudkan sambungan dengan pelanggan, mendapatkan kebenaran, mengekalkan dan mengurus sambungan. Perintah sambungan secara amnya:
mysql -h$ip -P$port -u$user -p
Mysql dalam arahan sambungan ialah alat klien yang digunakan untuk mewujudkan sambungan dengan pelayan. Selepas melengkapkan jabat tangan TCP, penyambung akan mula mengesahkan identiti
- Jika nama pengguna atau kata laluan tidak betul, ralat "Akses ditolak untuk pengguna" akan diterima, dan kemudian program klien akan tamat pelaksanaan
- Jika pengesahan nama pengguna dan kata laluan lulus, penyambung kembali ke jadual kebenaran untuk mengetahui kebenaran yang anda miliki. Selepas itu, logik penghakiman kebenaran dalam hubungan ini akan bergantung pada kebenaran yang dibaca pada masa ini
Ini bermakna selepas pengguna berjaya membuat sambungan, akaun pentadbir akan digunakan untuk mengakses kebenaran pengguna . Walaupun kebenaran diubah suai, ia tidak akan menjejaskan kebenaran sambungan sedia ada. Selepas pengubahsuaian selesai, hanya sambungan yang baru dibuat akan menggunakan tetapan kebenaran baharu
Selepas sambungan selesai, jika anda tidak mempunyai tindakan seterusnya, sambungan akan terbiar dan boleh dilihat dalam arahan show processlist

Arahan ialah Tidur, menunjukkan bahawa sambungan ini ialah sambungan melahu
Jika pelanggan tidak aktif terlalu lama, penyambung akan memutuskan sambungannya secara automatik. Masa ini dikawal oleh parameter wait_timeout. Nilai lalai ialah 8 jam
Jika pelanggan menghantar permintaan sekali lagi selepas sambungan diputuskan, ia akan menerima mesej ralat: Sambungan terputus ke pelayan MySQL semasa pertanyaan. Pada masa ini, anda perlu menyambung semula, dan kemudian melaksanakan permintaan
Dalam pangkalan data, sambungan yang panjang bermakna selepas sambungan berjaya, jika pelanggan terus membuat permintaan, sambungan yang sama akan sentiasa digunakan . Sambungan pendek merujuk kepada memutuskan sambungan selepas melaksanakan beberapa pertanyaan setiap kali, dan mewujudkan semula sambungan untuk pertanyaan seterusnya
Proses mewujudkan sambungan biasanya lebih rumit, jadi disyorkan untuk menggunakan sambungan yang panjang seboleh-bolehnya
Tetapi selepas semua sambungan yang panjang digunakan, kadangkala memori yang diduduki oleh MySQL meningkat dengan cepat Ini kerana memori yang digunakan buat sementara oleh MySQL semasa pelaksanaan diuruskan dalam objek sambungan. Sumber ini akan dikeluarkan apabila sambungan diputuskan. Oleh itu, jika sambungan panjang terkumpul, mereka mungkin menduduki terlalu banyak memori dan dibunuh secara paksa oleh sistem (OOM Berdasarkan fenomena, MySQL dimulakan semula secara tidak normal
Masalah ini boleh diselesaikan melalui dua penyelesaian berikut:
1. Putuskan sambungan yang panjang dengan kerap. Selepas menggunakannya untuk tempoh masa, atau selepas program menentukan bahawa pertanyaan besar yang menduduki memori telah dilaksanakan, putuskan sambungan, dan kemudian tanya dan sambung semula 2 Jika anda menggunakan MySQL 5.7 atau lebih baru versi, anda boleh Selepas melakukan operasi yang agak besar buat kali pertama, mulakan semula sumber sambungan dengan melaksanakan mysql_reset_connection. Proses ini tidak memerlukan penyambungan semula dan pengesahan kebenaran, tetapi sambungan akan dipulihkan kepada keadaan apabila ia baru dibuat2. Cache pertanyaan
Selepas sambungan dibuat ditubuhkan , anda boleh melaksanakan penyataan pilih. Selepas MySQL mendapat permintaan pertanyaan, ia akan pergi ke cache pertanyaan terlebih dahulu untuk melihat sama ada pernyataan ini telah dilaksanakan sebelum ini. Pernyataan yang dilaksanakan sebelum ini dan keputusannya mungkin dicache terus dalam ingatan dalam bentuk pasangan nilai kunci. Kuncinya ialah pernyataan pertanyaan, dan nilainya ialah hasil pertanyaan. Jika pertanyaan boleh terus mencari kunci dalam cache ini, maka nilai akan dikembalikan terus kepada klienJika pernyataan itu tiada dalam cache pertanyaan, fasa pelaksanaan seterusnya akan diteruskan. Selepas pelaksanaan selesai, hasil pelaksanaan akan disimpan dalam cache pertanyaan. Jika pertanyaan mencecah cache, MySQL boleh terus mengembalikan hasil tanpa melakukan operasi kompleks seterusnya Ini sangat cekapTetapi dalam kebanyakan kes, ia tidak disyorkan untuk menggunakan cache pertanyaan kerana cache pertanyaan gagal dengan kerap. Untuk kemas kini pada jadual, semua cache pertanyaan pada jadual ini akan dikosongkan. Untuk pangkalan data dengan tekanan kemas kini yang berat, kadar hit bagi cache pertanyaan akan menjadi sangat rendah可以将参数query_cache_type设置成DEMAND,这样对于默认的SQL语句都不使用查询缓存。而对于确定要是查询缓存的语句,可以用SQL_CACHE显示指定,如下面这条语句一样:
select SQL_CACHE * from T where ID=10;
MySQL8.0版本直接将查询缓存的整块功能删掉了
3、分析器
如果没有命中查询缓存,就要开始真正执行语句了。MySQL首先要对SQL语句做解析
分析器会先做词法分析。输入的是由多个字符串和空格组成的一条SQL语句,MySQL需要识别出里面的字符串分别是什么,代表什么
select * from T where ID=10;
MySQL从输入的select这个关键字识别出来,这是一个查询语句。它也要把字符串T识别成表名T,把字符串ID识别成列ID
做完了这些识别以后,就要做语法分析。根据词法分析的结果,语法分析器会根据语法规则,判断这个SQL语句是否满足MySQL语法。如果语法不对,就会收到"You have an error in your SQL syntax"的错误提示
4、优化器
经过了分析器,在开始执行之前,还要先经过优化器的处理
优化器是在表里面有多个索引的时候,决定使用哪个索引;或者在一个语句有多表关联的时候,决定各个表的连接顺序
5、执行器
优化器阶段完成后,这个语句的执行方案就确定下来了,然后进入执行器阶段,开始执行语句
开始执行的时候,要先判断一下你对这个表T有没有执行查询的权限,如果没有,就会返回没有权限的错误,如下所示
mysql> select * from T where ID=10; ERROR 1142 (42000): SELECT command denied to user 'b'@'localhost' for table 'T'
如果有权限,就打开表继续执行。打开表的时候,执行器就会根据表的引擎定义,去使用这个引擎提供的接口
比如在表T中,ID字段没有索引,那么执行器的执行流程是这样的:
1.调用InnoDB引擎接口取这个表的第一行,判断ID值是不是10,如果不是则跳过,如果是则将这个行存在结果集中
2.调用引擎接口取下一行,重复相同的判断逻辑,直到取到这个表的最后一行
3.执行器将上述遍历过程中所有满足条件的行组成的记录集作为结果集返回给客户端
在数据库的慢查询日志中看到一个rows_examined的字段,表示这个语句执行过程扫描了多少行。这个值就是在执行器每次调用引擎获取数据行的时候累加的
在有些场景下,执行器调用一次,在引起内部则扫描了多行,因此引擎扫描行数跟rows_examined并不是完全相同的
二、日志系统
表T的创建语句如下,这个表有一个主键ID和一个整型字段c:
create table T(ID int primary key, c int);
如果要将ID=2这一行的值加1,SQL语句如下:
update T set c=c+1 where ID=2;
1、redo log(重做日志)
在MySQL中,如果每次的更新操作都需要写进磁盘,然后磁盘也要找到对应的那条记录,然后再更新,整个过程IO成本、查找成本都很高。MySQL里常说的WAL技术,全称是Write-Ahead Logging,它的关键点就是先写日志,再写磁盘
当有一条记录需要更新的时候,InnoDB引擎就会把记录写到redo log里面,并更新buffer pool的page,这个时候更新就算完成了
buffer pool是物理页的缓存,对InnoDB的任何修改操作都会首先在buffer pool的page上进行,然后这样的页面将被标记为脏页并被放到专门的flush list上,后续将由专门的刷脏线程阶段性的将这些页面写入磁盘
InnoDB的redo log是固定大小的,比如可以配置为一组4个文件,每个文件的大小是1GB,从头开始写,写到末尾就又回到开头循环写
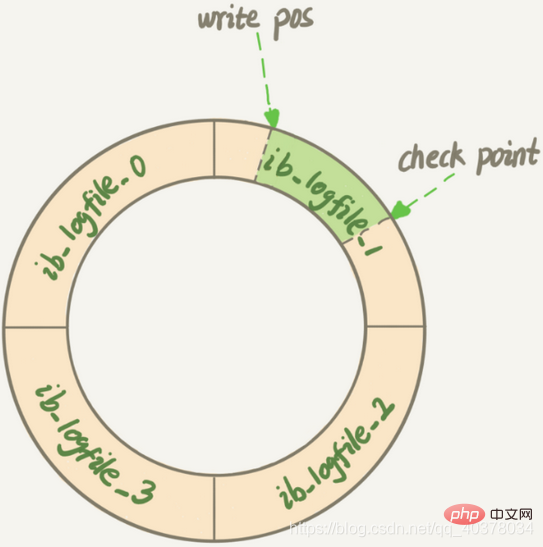
write pos是当前记录的位置,一边写一边后移,写到第3号文件末尾后就回到0号文件开头。check point是当前要擦除的位置,也是往后推移并且循环的,擦除记录前要把记录更新到数据文件
write pos和check point之间空着的部分,可以用来记录新的操作。如果write pos追上check point,这时候不能再执行新的更新,需要停下来擦掉一些记录,把check point推进一下
有了redo log,InnoDB就可以保证即使数据库发生异常重启,之前提交的记录都不会丢失,这个能力称为crash-safe
2、binlog(归档日志)
MySQL整体来看就有两块:一块是Server层,主要做的是MySQL功能层面的事情;还有一块是引擎层,负责存储相关的具体事宜。redo log是InnoDB引擎特有的日志,而Server层也有自己的日志,称为binlog
为什么会有两份日志?
Kerana tiada enjin InnoDB dalam MySQL pada mulanya. Enjin yang disertakan dengan MySQL ialah MyISAM, tetapi MyISAM tidak mempunyai keupayaan selamat ranap, dan log binlog hanya boleh digunakan untuk pengarkiban. InnoDB diperkenalkan ke dalam MySQL dalam bentuk pemalam Memandangkan hanya bergantung pada binlog tidak mempunyai keupayaan selamat ranap, InnoDB menggunakan log buat semula untuk mencapai keupayaan selamat ranap
format log binlog:
Terdapat tiga format binlog: STATEMENT, ROW, MIXED
1), mod STATEMENT
Teks asal SQL kenyataan direkodkan dalam binlog. Kelebihannya ialah tidak perlu merekod perubahan data dalam setiap baris, yang mengurangkan jumlah log binlog, menjimatkan IO dan meningkatkan prestasi. Kelemahannya ialah dalam beberapa kes ia akan menyebabkan ketidakkonsistenan data dalam master-slave (seperti fungsi sleep(), last_insert_id(), dan fungsi yang ditentukan pengguna (udf), dll.)
2 ), mod ROW
tidak merekodkan maklumat kontekstual setiap pernyataan SQL, tetapi hanya merekodkan data yang telah diubah suai dan pengubahsuaian yang telah dilakukan. Dan tidak akan ada masalah bahawa panggilan dan pencetus prosedur atau fungsi atau pencetus yang disimpan tidak dapat disalin dengan betul dalam keadaan tertentu. Kelemahannya ialah sejumlah besar log akan dijana, terutamanya apabila mengubah jadual, log akan meroket
3), mod CAMPURAN
Penggunaan campuran di atas dua mod, secara amnya Untuk replikasi, gunakan mod STATEMENT untuk menyimpan binlog Untuk operasi yang tidak boleh disalin dalam mod STATEMENT, gunakan mod ROW untuk menyimpan binlog MySQL akan memilih kaedah menyimpan log mengikut penyata SQL yang dilaksanakan
3. Perbezaan antara log buat semula dan log binlog 1.log buat semula adalah unik untuk enjin InnoDB binlog dilaksanakan oleh lapisan Pelayan MySQL dan boleh digunakan oleh semua enjin 2.redo log ialah log fizikal, yang merekodkan Apakah pengubahsuaian yang telah dibuat pada data tertentu Binlog ialah log logik, yang merekodkan logik asal pernyataan ini daripada baris dengan ID=23. Log buat semula ditulis dalam gelung Ya, ruang itu pasti akan habis; beralih kepada yang seterusnya dan tidak akan menimpa log sebelumnya4. Penyerahan dua peringkat
Proses dalaman pelaksana dan enjin InnoDB apabila melaksanakan pernyataan kemas kini ini:
1 Pelaksana mula-mula mencari enjin dan mengambil ID baris=2. ID ialah kunci utama dan enjin terus menggunakan carian pokok untuk mencari baris ini. Jika data dalam baris dengan ID=2 sudah ada dalam ingatan, ia akan dikembalikan terus kepada pelaksana jika tidak, ia perlu dibaca ke dalam memori dari cakera terlebih dahulu, dan kemudian dikembalikan kepada 2. Pelaksana mendapat data baris enjin, tambah 1 pada nilai ini untuk mendapatkan baris data baharu, dan kemudian panggil antara muka enjin untuk menulis baris data baharu ini 3. Enjin mengemas kini baris baharu ini data ke dalam memori dan mengemas kini baris ini pada masa yang sama Operasi direkodkan dalam log buat semula, dan log buat semula berada dalam keadaan sediakan pada masa ini. Kemudian maklumkan kepada pelaksana bahawa pelaksanaan telah selesai dan anda boleh menyerahkan transaksi pada bila-bila masa 4. Pelaksana menjana binlog operasi ini dan menulis binlog ke cakera 5 pelaksana memanggil antara muka transaksi komit enjin , enjin menukar log buat semula yang baru ditulis kepada keadaan yang diserahkan, dan kemas kini selesai Carta alir pelaksanaan penyata kemas kini adalah seperti berikut angka menunjukkan bahawa ia dilaksanakan di dalam InnoDB, dan kotak gelap menunjukkan bahawa ia dilaksanakan dalam pelaksana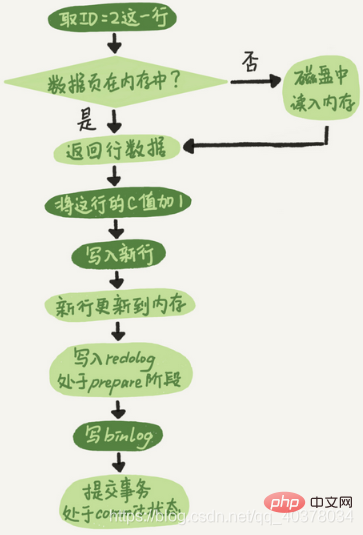
membahagikan tulisan log semula ke dalam dua langkah: sediakan dan komit, iaitu komit dua peringkat
Memandangkan log buat semula dan Binlog ialah dua logik bebas Jika penyerahan dua peringkat tidak diperlukan, sama ada tulis log buat semula dahulu dan kemudian tulis binlog, atau tulis binlog dahulu dan kemudian tulis semula log
1 Tulis semula log dahulu dan kemudian tulis binlog . Jika proses MySQL dimulakan semula secara tidak normal apabila log buat semula telah ditulis tetapi binlog belum lagi ditulis. Memandangkan selepas log buat semula ditulis, walaupun sistem ranap, data masih boleh dipulihkan, jadi nilai c dalam baris ini selepas pemulihan ialah 1. Walau bagaimanapun, kerana binlog ranap sebelum ia selesai, pernyataan ini tidak direkodkan dalam binlog pada masa ini Nilai c dalam baris ini yang direkodkan dalam binlog ialah 0
2. Tulis binlog dahulu dan kemudian. log buat semula. Jika berlaku ranap selepas binlog ditulis, memandangkan log buat semula belum ditulis lagi, transaksi akan menjadi tidak sah selepas pemulihan ranap, jadi nilai c dalam baris ini ialah 0. Tetapi binlog telah merekodkan log perubahan c dari 0 kepada 1. Oleh itu, apabila binlog dipulihkan kemudian, satu lagi transaksi akan keluar, dan nilai c dalam baris yang dipulihkan ialah 1
Jika komit dua fasa tidak digunakan, status pangkalan data mungkin berbeza daripada yang menggunakannya Status perpustakaan yang dipulihkan daripada log adalah tidak konsisten. Kedua-dua log buat semula dan binlog boleh digunakan untuk mewakili status komit transaksi, dan komit dua peringkat adalah untuk memastikan kedua-dua keadaan itu konsisten secara logik
log buat semula digunakan untuk memastikan keupayaan selamat ranap. Apabila parameter innodb_flush_log_at_trx_commit ditetapkan kepada 1, ini bermakna log buat semula setiap transaksi diteruskan terus ke cakera, yang memastikan bahawa data tidak akan hilang selepas MySQL dimulakan semula secara tidak normal hingga 1, ini bermakna setiap transaksi Binlog setiap transaksi dikekalkan ke cakera, yang memastikan binlog tidak akan hilang selepas MySQL dimulakan semula secara tidak normal
三、MySQL刷脏页
1、刷脏页的场景
当内存数据页跟磁盘数据页不一致的时候,我们称这个内存页为脏页。内存数据写入到磁盘后,内存和磁盘行的数据页的内容就一致了,称为干净页
第一种场景是,InnoDB的redo log写满了,这时候系统会停止所有更新操作,把checkpoint往前推进,redo log留出空间可以继续写

checkpoint位置从CP推进到CP’,就需要将两个点之间的日志对应的所有脏页都flush到磁盘上。之后,上图中从write pos到CP’之间就是可以再写入的redo log的区域第二种场景是,系统内存不足。当需要新的内存页,而内存不够用的时候,就要淘汰一些数据页,空出内存给别的数据页使用。如果淘汰的是脏页,就要先将脏页写到磁盘
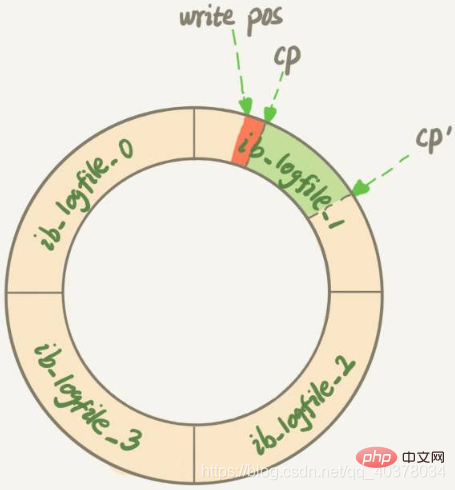
这时候不能直接把内存淘汰掉,下次需要请求的时候,从磁盘读入数据页,然后拿redo log出来应用不就行了?
这里是从性能考虑的。如果刷脏页一定会写盘,就保证了每个数据页有两种状态:一种是内存里存在,内存里就肯定是正确的结果,直接返回;另一种是内存里没有数据,就可以肯定数据文件上是正确的结果,读入内存后返回。这样的效率最高
- 第三种场景是,MySQL认为系统空闲的时候刷脏页,当然在系统忙的时候也要找时间刷一点脏页
- 第四种场景是,MySQL正常关闭的时候会把内存的脏页都flush到磁盘上,这样下次MySQL启动的时候,就可以直接从磁盘上读数据,启动速度会很快
redo log写满了,要flush脏页,出现这种情况的时候,整个系统就不能再接受更新了,所有的更新都必须堵住
内存不够用了,要先将脏页写到磁盘,这种情况是常态。InnoDB用缓冲池管理内存,缓冲池中的内存页有三种状态:
- 第一种是还没有使用的
- 第二种是使用了并且是干净页
- 第三种是使用了并且是脏页
InnoDB的策略是尽量使用内存,因此对于一个长时间运行的库来说,未被使用的页面很少
当要读入的数据页没有在内存的时候,就必须到缓冲池中申请一个数据页。这时候只能把最久不使用的数据页从内存中淘汰掉:如果要淘汰的是一个干净页,就直接释放出来复用;但如果是脏页,即必须将脏页先刷到磁盘,变成干净页后才能复用
刷页虽然是常态,但是出现以下两种情况,都是会明显影响性能的:
- 一个查询要淘汰的脏页个数太多,会导致查询的响应时间明显变长
- 日志写满,更新全部堵住,写性能跌为0,这种情况对敏感业务来说,是不能接受的
2、InnoDB刷脏页的控制策略
首先,要正确地告诉InnoDB所在主机的IO能力,这样InnoDB才能知道需要全力刷脏页的时候,可以刷多快。参数为innodb_io_capacity,建议设置成磁盘的IOPS
InnoDB的刷盘速度就是考虑脏页比例和redo log写盘速度。参数innodb_max_dirty_pages_pct是脏页比例上限,默认值是75%。脏页比例是通过Innodb_buffer_pool_pages_dirty/Innodb_buffer_pool_pages_total得到的,SQL语句如下:
mysql> select VARIABLE_VALUE into @a from performance_schema.global_status where VARIABLE_NAME = 'Innodb_buffer_pool_pages_dirty'; select VARIABLE_VALUE into @b from performance_schema.global_status where VARIABLE_NAME = 'Innodb_buffer_pool_pages_total'; select @a/@b;
四、日志相关问题
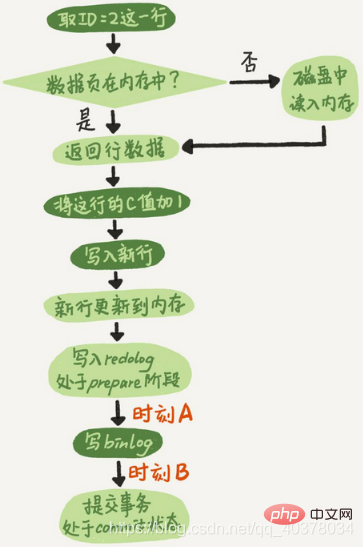
问题一:在两阶段提交的不同时刻,MySQL异常重启会出现什么现象
如果在图中时刻A的地方,也就是写入redo log处于prepare阶段之后、写binlog之前,发生了崩溃,由于此时binlog还没写,redo log也还没提交,所以崩溃恢复的时候,这个事务会回滚。这时候,binlog还没写,所以也不会传到备库
如果在图中时刻B的地方,也就是binlog写完,redo log还没commit前发生崩溃,那崩溃恢复的时候MySQL怎么处理?
崩溃恢复时的判断规则:
1)如果redo log里面的事务是完整的,也就是已经有了commit标识,则直接提交
2)如果redo log里面的事务只有完整的prepare,则判断对应的事务binlog是否存在并完整
a.如果完整,则提交事务
b.否则,回滚事务
时刻B发生崩溃对应的就是2(a)的情况,崩溃恢复过程中事务会被提交
问题二:MySQL怎么知道binlog是完整的?
一个事务的binlog是有完整格式的:
- statement格式的binlog,最后会有COMMIT
- row格式的binlog,最后会有一个XID event
问题三:redo log和binlog是怎么关联起来的?
它们有一个共同的数据字段,叫XID。崩溃恢复的时候,会按顺序扫描redo log:
- 如果碰到既有prepare、又有commit的redo log,就直接提交
- 如果碰到只有prepare、而没有commit的redo log,就拿着XID去binlog找对应的事务
问题四:redo log一般设置多大?
如果是现在常见的几个TB的磁盘的话,redo log设置为4个文件、每个文件1GB
问题五:正常运行中的实例,数据写入后的最终落盘,是从redo log更新过来的还是从buffer pool更新过来的呢?
redo log并没有记录数据页的完整数据,所以它并没有能力自己去更新磁盘数据页,也就不存在数据最终落盘是由redo log更新过去的情况
1.如果是正常运行的实例的话,数据页被修改以后,跟磁盘的数据页不一致,称为脏页。最终数据落盘,就是把内存中的数据页写盘。这个过程,甚至与redo log毫无关系
2.在崩溃恢复场景中,InnoDB如果判断到一个数据页可能在崩溃恢复的时候丢失了更新,就会将它对到内存,然后让redo log更新内存内容。更新完成后,内存页变成脏页,就回到了第一种情况的状态
问题六:redo log buffer是什么?是先修改内存,还是先写redo log文件?
在一个事务的更新过程中,日志是要写多次的。比如下面这个事务:
begin;insert into t1 ...insert into t2 ...commit;
这个事务要往两个表中插入记录,插入数据的过程中,生成的日志都得先保存起来,但又不能在还没commit的时候就直接写到redo log文件里
所以,redo log buffer就是一块内存,用来先存redo日志的。也就是说,在执行第一个insert的时候,数据的内存被修改了,redo log buffer也写入了日志。但是,真正把日志写到redo log文件,是在执行commit语句的时候做的
五、MySQL是怎么保证数据不丢的?
只要redo log和binlog保证持久化到磁盘,就能确保MySQL异常重启后,数据可以恢复
1、binlog的写入机制
事务执行过程中,先把日志写到binlog cache,事务提交的时候,再把binlog cache写到binlog文件中。一个事务的binlog是不能被拆开的,因此不论这个事务多大,也要确保一次性写入
系统给binlog cache分配了一片内存,每个线程一个,参数binlog_cache_size用于控制单个线程内binlog cache所占内存的大小。如果超过了这个参数规定的大小,就要暂存到磁盘
事务提交的时候,执行器把binlog cache里的完整事务写入到binlog中,并清空binlog cache
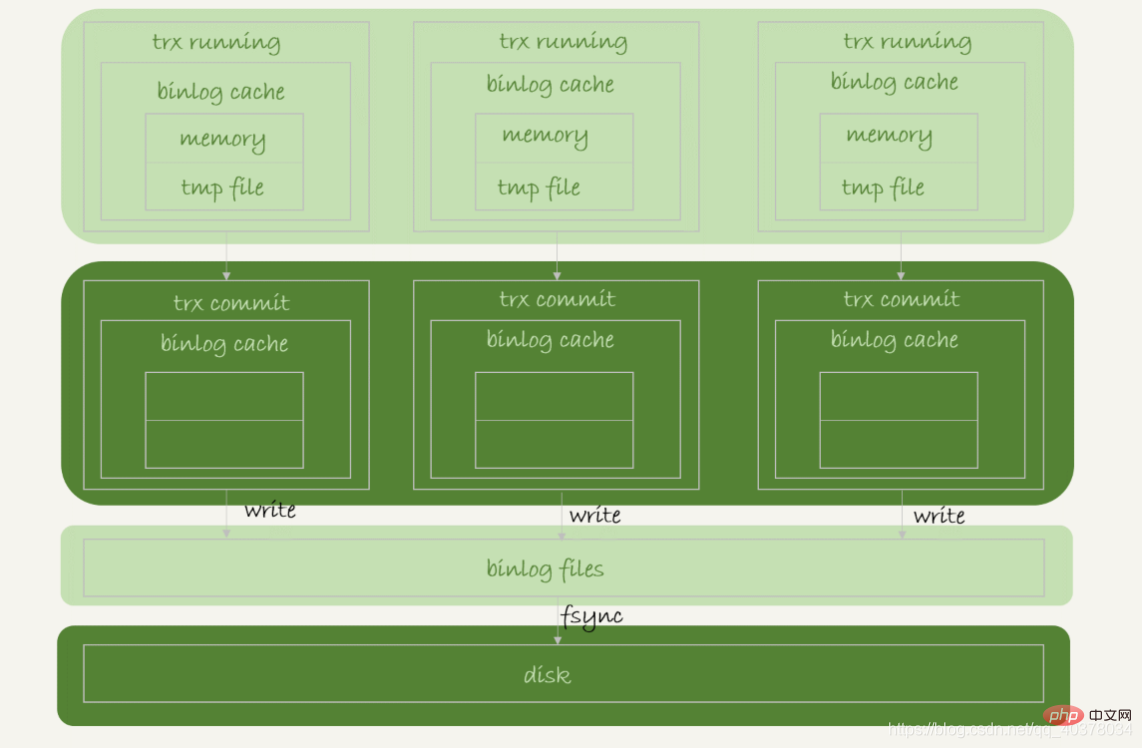
每个线程有自己binlog cache,但是共用一份binlog文件
- 图中的write,指的就是把日志写入到文件系统的page cache,并没有把数据持久化到磁盘,所以速度比较快
- 图中的fsync,才是将数据持久化到磁盘的操作。一般情况下认为fsync才占磁盘的IOPS
write和fsync的时机,是由参数sync_binlog控制的:
- sync_binlog=0的时候,表示每次提交事务都只write,不fsync
- sync_binlog=1的时候,表示每次提交事务都会执行fsync
- sync_binlog=N(N>1)的时候,表示每次提交事务都write,但累积N个事务后才fsync
因此,在出现IO瓶颈的场景中,将sync_binlog设置成一个比较大的值,可以提升性能,对应的风险是:如果主机发生异常重启,会丢失最近N个事务的binlog日志
2、redo log的写入机制
事务在执行过程中,生成的redo log是要先写到redo log buffer的。redo log buffer里面的内容不是每次生成后都要直接持久化到磁盘,也有可能在事务还没提交的时候,redo log buffer中的部分日志被持久化到磁盘
redo log可能存在三种状态,对应下图的三个颜色块
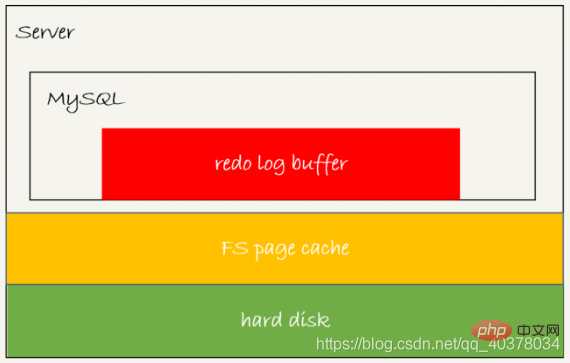
这三张状态分别是:
- wujud dalam penimbal semula log Ia secara fizikal dalam memori proses MySQL, iaitu bahagian merah dalam gambar
- ditulis ke cakera, tetapi ia tidak berterusan secara fizikal dalam halaman sistem fail di dalam cache, iaitu bahagian kuning
- dalam gambar dikekalkan ke cakera, yang sepadan dengan cakera keras, iaitu bahagian hijau dalam gambar.
Log ditulis ke penimbal log buat semula dan Menulis ke cache halaman adalah sangat pantas, tetapi berterusan ke cakera adalah lebih perlahan
Untuk mengawal penulisan log semula strategi, InnoDB menyediakan parameter innodb_flush_log_at_trx_commit, yang mempunyai tiga nilai yang mungkin:
- ditetapkan kepada 0, ini bermakna setiap kali transaksi diserahkan, log buat semula hanya ditinggalkan dalam penimbal log buat semula .
- Apabila ia ditetapkan kepada 1, ini bermakna setiap kali transaksi diserahkan, Apabila meneruskan log buat semula terus ke cakera
- ditetapkan kepada 2, ia bermakna setiap kali transaksi diserahkan, log buat semula hanya ditulis pada cache halaman
3 mekanisme penyerahan kumpulan
Nombor urutan logik log LSN meningkat secara monotonik dan digunakan untuk sesuai dengan titik tulis log redo. . LSN juga akan ditulis ke halaman data InnoDB untuk memastikan halaman data tidak akan dilaksanakan beberapa kali log buat semula berulang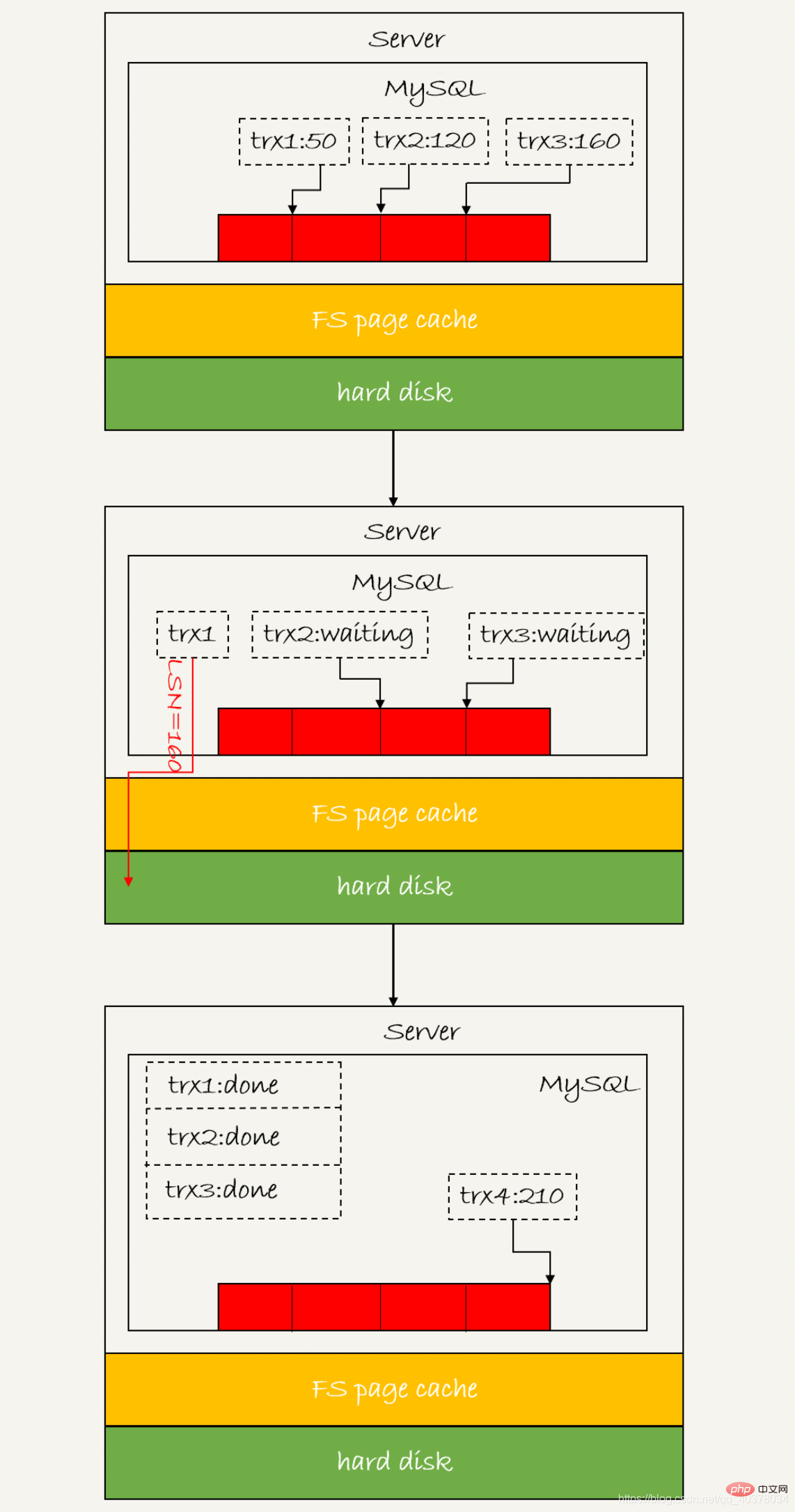 Gambar di atas menunjukkan tiga transaksi serentak dalam fasa penyediaan, semua ditulis Selepas menyelesaikan proses buat semula log penimbal dan berterusan ke cakera, LSN yang sepadan ialah 50, 120 dan 160 masing-masing
Gambar di atas menunjukkan tiga transaksi serentak dalam fasa penyediaan, semua ditulis Selepas menyelesaikan proses buat semula log penimbal dan berterusan ke cakera, LSN yang sepadan ialah 50, 120 dan 160 masing-masing

dua syarat dipenuhi, fsync
Mekanisme WAL terutamanya mendapat manfaat daripada Kedua-dua aspek:
- Kedua-dua log buat semula dan binlog ditulis secara berurutan, dan penulisan berurutan ke cakera adalah lebih pantas daripada penulisan rawak
- Mekanisme penyerahan kumpulan boleh mengurangkan penggunaan IOPS pesanan cakera dengan ketara
4. Jika MySQL kini mempunyai kesesakan prestasi, dan kesesakan berada pada IO, apakah kaedah yang boleh digunakan untuk meningkatkan prestasi
1. dan parameter binlog_group_commit_sync_no_delay_count (berapa kali terkumpul sebelum memanggil fsync) untuk mengurangkan bilangan penulisan binlog ke cakera. Kaedah ini dilaksanakan berdasarkan menunggu tambahan yang disengajakan, jadi ia boleh meningkatkan masa tindak balas penyata, tetapi tiada risiko kehilangan data
2. Tetapkan sync_binlog kepada nilai yang lebih besar daripada 1 (tulis setiap kali a transaksi dilakukan) , tetapi fsync hanya selepas N transaksi terkumpul). Risiko melakukan ini ialah log binlog akan hilang apabila hos dimatikan
3. Tetapkan innodb_flush_log_at_trx_commit kepada 2 (hanya log buat semula ditulis pada cache halaman setiap kali transaksi dilakukan). Risiko melakukan ini ialah data akan hilang apabila hos kehilangan kuasa
[Cadangan berkaitan: tutorial video mysql]
Atas ialah kandungan terperinci Mari kita bercakap tentang infrastruktur MySQL dan sistem pembalakan. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

Video Face Swap
Tukar muka dalam mana-mana video dengan mudah menggunakan alat tukar muka AI percuma kami!

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1393
1393
 52
1209
24
52
1209
24

 Cara membuka phpmyadmin
Apr 10, 2025 pm 10:51 PM
Cara membuka phpmyadmin
Apr 10, 2025 pm 10:51 PM
Anda boleh membuka phpmyadmin melalui langkah -langkah berikut: 1. Log masuk ke panel kawalan laman web; 2. Cari dan klik ikon phpmyadmin; 3. Masukkan kelayakan MySQL; 4. Klik "Login".
 MySQL: Pengenalan kepada pangkalan data paling popular di dunia
Apr 12, 2025 am 12:18 AM
MySQL: Pengenalan kepada pangkalan data paling popular di dunia
Apr 12, 2025 am 12:18 AM
MySQL adalah sistem pengurusan pangkalan data relasi sumber terbuka, terutamanya digunakan untuk menyimpan dan mengambil data dengan cepat dan boleh dipercayai. Prinsip kerjanya termasuk permintaan pelanggan, resolusi pertanyaan, pelaksanaan pertanyaan dan hasil pulangan. Contoh penggunaan termasuk membuat jadual, memasukkan dan menanyakan data, dan ciri -ciri canggih seperti Operasi Join. Kesalahan umum melibatkan sintaks SQL, jenis data, dan keizinan, dan cadangan pengoptimuman termasuk penggunaan indeks, pertanyaan yang dioptimumkan, dan pembahagian jadual.
 Tempat Mysql: Pangkalan Data dan Pengaturcaraan
Apr 13, 2025 am 12:18 AM
Tempat Mysql: Pangkalan Data dan Pengaturcaraan
Apr 13, 2025 am 12:18 AM
Kedudukan MySQL dalam pangkalan data dan pengaturcaraan sangat penting. Ia adalah sistem pengurusan pangkalan data sumber terbuka yang digunakan secara meluas dalam pelbagai senario aplikasi. 1) MySQL menyediakan fungsi penyimpanan data, organisasi dan pengambilan data yang cekap, sistem sokongan web, mudah alih dan perusahaan. 2) Ia menggunakan seni bina pelanggan-pelayan, menyokong pelbagai enjin penyimpanan dan pengoptimuman indeks. 3) Penggunaan asas termasuk membuat jadual dan memasukkan data, dan penggunaan lanjutan melibatkan pelbagai meja dan pertanyaan kompleks. 4) Soalan -soalan yang sering ditanya seperti kesilapan sintaks SQL dan isu -isu prestasi boleh disahpepijat melalui arahan jelas dan log pertanyaan perlahan. 5) Kaedah pengoptimuman prestasi termasuk penggunaan indeks rasional, pertanyaan yang dioptimumkan dan penggunaan cache. Amalan terbaik termasuk menggunakan urus niaga dan preparedStatemen
 Mengapa menggunakan mysql? Faedah dan kelebihan
Apr 12, 2025 am 12:17 AM
Mengapa menggunakan mysql? Faedah dan kelebihan
Apr 12, 2025 am 12:17 AM
MySQL dipilih untuk prestasi, kebolehpercayaan, kemudahan penggunaan, dan sokongan komuniti. 1.MYSQL Menyediakan fungsi penyimpanan dan pengambilan data yang cekap, menyokong pelbagai jenis data dan operasi pertanyaan lanjutan. 2. Mengamalkan seni bina pelanggan-pelayan dan enjin penyimpanan berganda untuk menyokong urus niaga dan pengoptimuman pertanyaan. 3. Mudah digunakan, menyokong pelbagai sistem operasi dan bahasa pengaturcaraan. 4. Mempunyai sokongan komuniti yang kuat dan menyediakan sumber dan penyelesaian yang kaya.
 Cara menyambung ke pangkalan data Apache
Apr 13, 2025 pm 01:03 PM
Cara menyambung ke pangkalan data Apache
Apr 13, 2025 pm 01:03 PM
Apache menyambung ke pangkalan data memerlukan langkah -langkah berikut: Pasang pemacu pangkalan data. Konfigurasikan fail web.xml untuk membuat kolam sambungan. Buat sumber data JDBC dan tentukan tetapan sambungan. Gunakan API JDBC untuk mengakses pangkalan data dari kod Java, termasuk mendapatkan sambungan, membuat kenyataan, parameter mengikat, melaksanakan pertanyaan atau kemas kini, dan hasil pemprosesan.
 Cara Memulakan MySQL oleh Docker
Apr 15, 2025 pm 12:09 PM
Cara Memulakan MySQL oleh Docker
Apr 15, 2025 pm 12:09 PM
Proses memulakan MySQL di Docker terdiri daripada langkah -langkah berikut: Tarik imej MySQL untuk membuat dan memulakan bekas, tetapkan kata laluan pengguna root, dan memetakan sambungan pengesahan port Buat pangkalan data dan pengguna memberikan semua kebenaran ke pangkalan data
 CentOS memasang MySQL
Apr 14, 2025 pm 08:09 PM
CentOS memasang MySQL
Apr 14, 2025 pm 08:09 PM
Memasang MySQL pada CentOS melibatkan langkah -langkah berikut: Menambah sumber MySQL YUM yang sesuai. Jalankan YUM Pasang Perintah MySQL-Server untuk memasang pelayan MySQL. Gunakan perintah mysql_secure_installation untuk membuat tetapan keselamatan, seperti menetapkan kata laluan pengguna root. Sesuaikan fail konfigurasi MySQL seperti yang diperlukan. Tune parameter MySQL dan mengoptimumkan pangkalan data untuk prestasi.
 Peranan MySQL: Pangkalan Data dalam Aplikasi Web
Apr 17, 2025 am 12:23 AM
Peranan MySQL: Pangkalan Data dalam Aplikasi Web
Apr 17, 2025 am 12:23 AM
Peranan utama MySQL dalam aplikasi web adalah untuk menyimpan dan mengurus data. 1.MYSQL dengan cekap memproses maklumat pengguna, katalog produk, rekod urus niaga dan data lain. 2. Melalui pertanyaan SQL, pemaju boleh mengekstrak maklumat dari pangkalan data untuk menghasilkan kandungan dinamik. 3.MYSQL berfungsi berdasarkan model klien-pelayan untuk memastikan kelajuan pertanyaan yang boleh diterima.
