

Artikel ini membawakan anda pengetahuan yang berkaitan tentang Python terutamanya mengatur isu-isu berkaitan merangkak imej web Jika anda ingin mendapatkan data dengan cekap, perangkak sangat mudah digunakan juga sangat mudah dan mudah. Mari kita lihat proses asas menulis crawler melalui program crawler kecil yang ringkas Mari kita lihat bersama-sama.

[Cadangan berkaitan: Tutorial video Python3 ]
Dalam era ledakan maklumat ini, jika anda ingin mendapatkan data dengan cekap, Crawler sangat berguna. Menggunakan Python untuk membuat crawler juga sangat mudah dan mudah Mari kita lihat proses asas menulis crawler melalui program crawler kecil yang mudah:
Bahasa: python
IDE: pycharm
Pertama ialah pustaka yang akan digunakan, kerana ia adalah program yang paling mudah untuk bermula, terutamanya kami menggunakan dua yang berikut:
import requests //用于请求网页 import re //正则表达式,用于解析筛选网页中的信息
Antaranya, re datang dengan python, dan perpustakaan permintaan perlu dipasang sendiri. Cuma masukkan permintaan pemasangan pip pada baris arahan.
Kemudian cari tapak web rawak Berhati-hati agar tidak cuba merangkak maklumat sensitif privasi Berikut ialah tapak web emotikon:
Nota: Kandungan dalam tapak web emotikon di sini boleh dimuat turun secara percuma. . , jadi perangkak hanya memudahkan proses kami satu demi satu. Berhati-hati untuk tidak merangkak sumber berbayar.
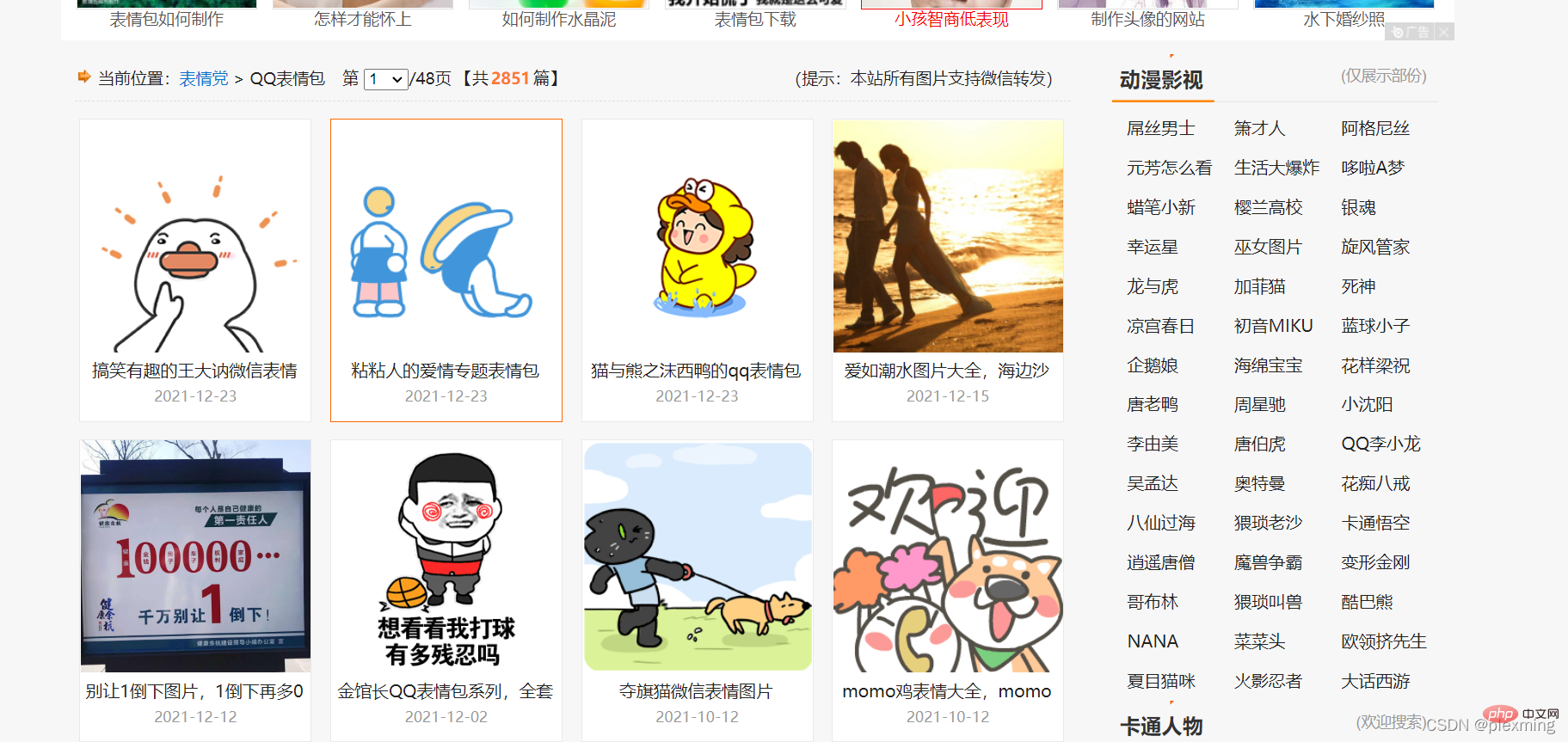
Apa yang perlu kami lakukan ialah memuat turun emotikon ini ke komputer kami melalui perangkak.
Pertama sekali, anda mesti mengakses laman web ini melalui python Kodnya adalah seperti berikut:
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:98.0) Gecko/20100101 Firefox/98.0'
}
response = requests.get('https://qq.yh31.com/zjbq/',headers=headers) //请求网页Sebab bahagian pengepala adalah. ditambah adalah kerana sesetengah halaman web akan mengenalinya Ternyata anda meminta melalui python dan kemudian menolak anda, jadi kami perlu menukar pengepala permintaan biasa. Anda boleh mencari satu secara rawak atau gunakan f12 untuk menyalin satu daripada maklumat rangkaian.
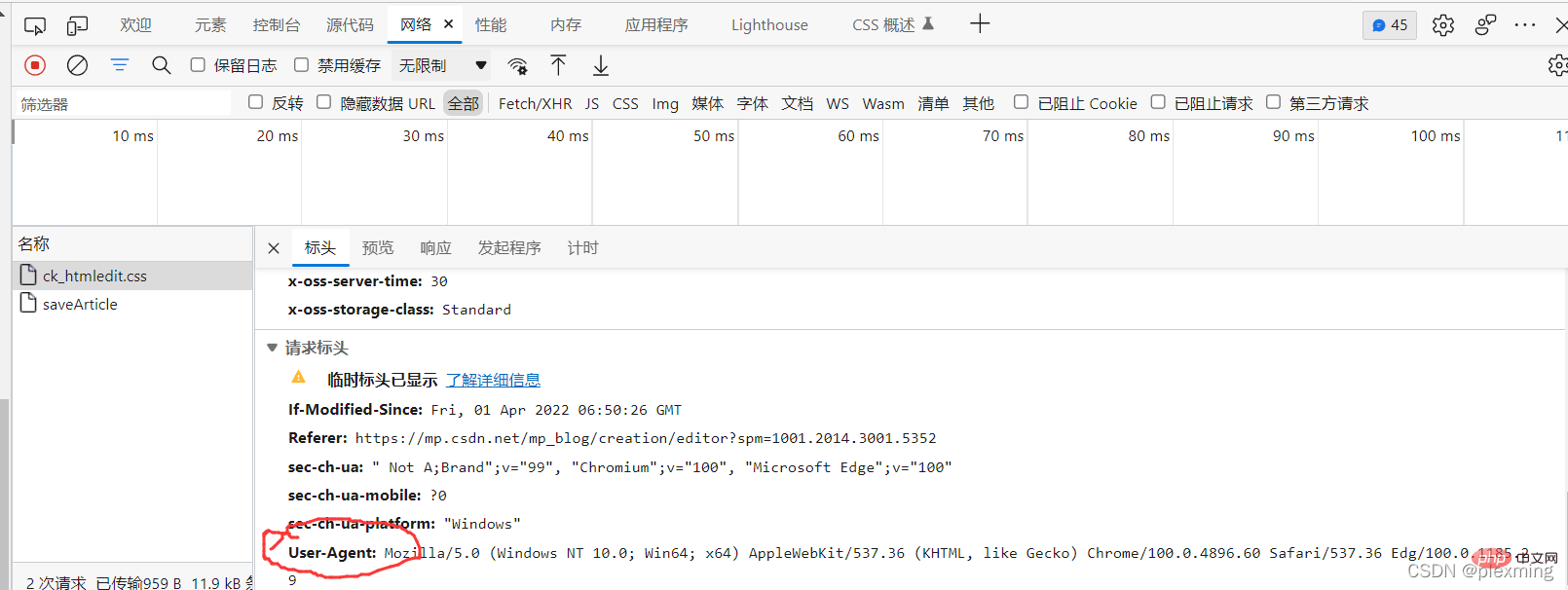
Kemudian kita perlu mencari lokasi imej yang ingin kita crawl dalam kod halaman web Semak kod sumber dengan f12 dan cari pakej emotikon seperti berikut:
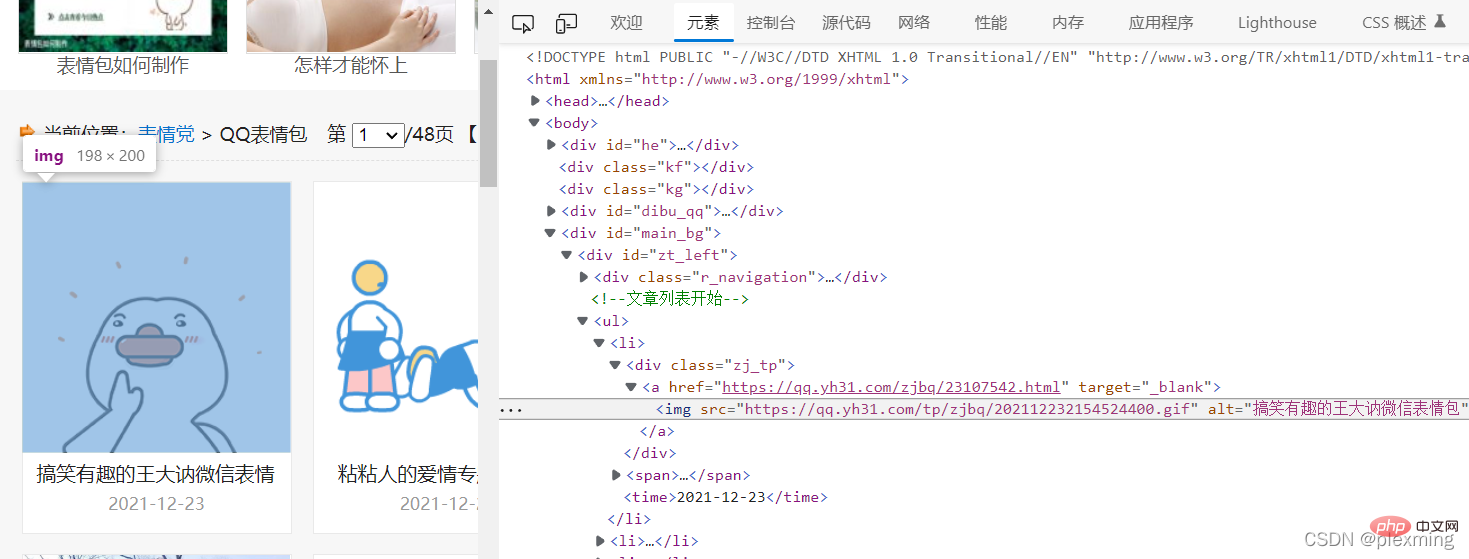
Kemudian buat peraturan padanan dan gantikan rentetan tengah dengan ungkapan biasa ialah .*?
t = '<img src="(.*?)" alt="(.*?)" width="160" height="120">'
seperti ini.
Kemudian anda boleh memanggil kaedah findall dalam pustaka semula untuk merangkak ke bawah kandungan yang berkaitan:
result = re.findall(t, response.text)
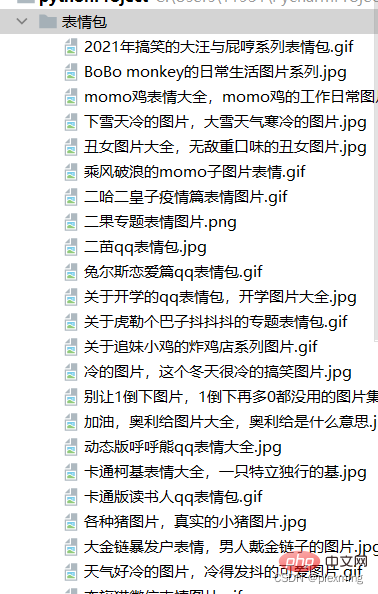
Kandungan yang dikembalikan ialah senarai yang terdiri daripada rentetan, dan akhirnya kami merangkak ke alamat Muat turun sahaja imej dan simpan ke folder melalui pernyataan python.
import requests
import re
import os
image = '表情包'
if not os.path.exists(image):
os.mkdir(image)
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:98.0) Gecko/20100101 Firefox/98.0'
}
response = requests.get('https://qq.yh31.com/zjbq/',headers=headers)
response.encoding = 'GBK'
response.encoding = 'utf-8'
print(response.request.headers)
print(response.status_code)
t = '<img src="(.*?)" alt="(.*?)" width="160" height="120">'
result = re.findall(t, response.text)
for img in result:
print(img)
res = requests.get(img[0])
print(res.status_code)
s = img[0].split('.')[-1] #截取图片后缀,得到表情包格式,如jpg ,gif
with open(image + '/' + img[1] + '.' + s, mode='wb') as file:
file.write(res.content)Keputusan akhir kelihatan seperti ini:
[Cadangan berkaitan: Tutorial video Python3 】
Atas ialah kandungan terperinci Bermula dengan perangkak Python: merangkak imej web. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

















![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



