Artikel ini membawakan anda pengetahuan yang berkaitan tentang Redis Terutamanya mengatur isu yang berkaitan dengan pengelompokan dan pengembangan Cara biasa untuk mencapai ketersediaan tinggi adalah dengan menyalin berbilang salinan pangkalan data untuk menggunakan pada pelayan yang berbeza , salah seorang daripada mereka boleh terus menyediakan perkhidmatan walaupun salah satu daripadanya gagal. Terdapat tiga mod penggunaan untuk mencapai ketersediaan tinggi: mod induk-hamba, mod sentinel dan mod kluster berguna kepada semua orang.

Pembelajaran yang disyorkan: Tutorial video Redis
Ketersediaan Redis yang tinggi
1 Mengapa ketersediaan tinggi
- Menghalang satu titik kegagalan daripada menjadikan keseluruhan kluster tidak tersedia
- Amalan biasa untuk mencapai ketersediaan tinggi Ia adalah untuk menyalin berbilang salinan pangkalan data dan menggunakannya pada pelayan yang berbeza Jika salah satu daripadanya gagal, ia boleh terus menyediakan perkhidmatan
- Redis mempunyai tiga mod penggunaan untuk mencapai ketersediaan tinggi: Master-slave. mod, mod sentinel, mod Kluster
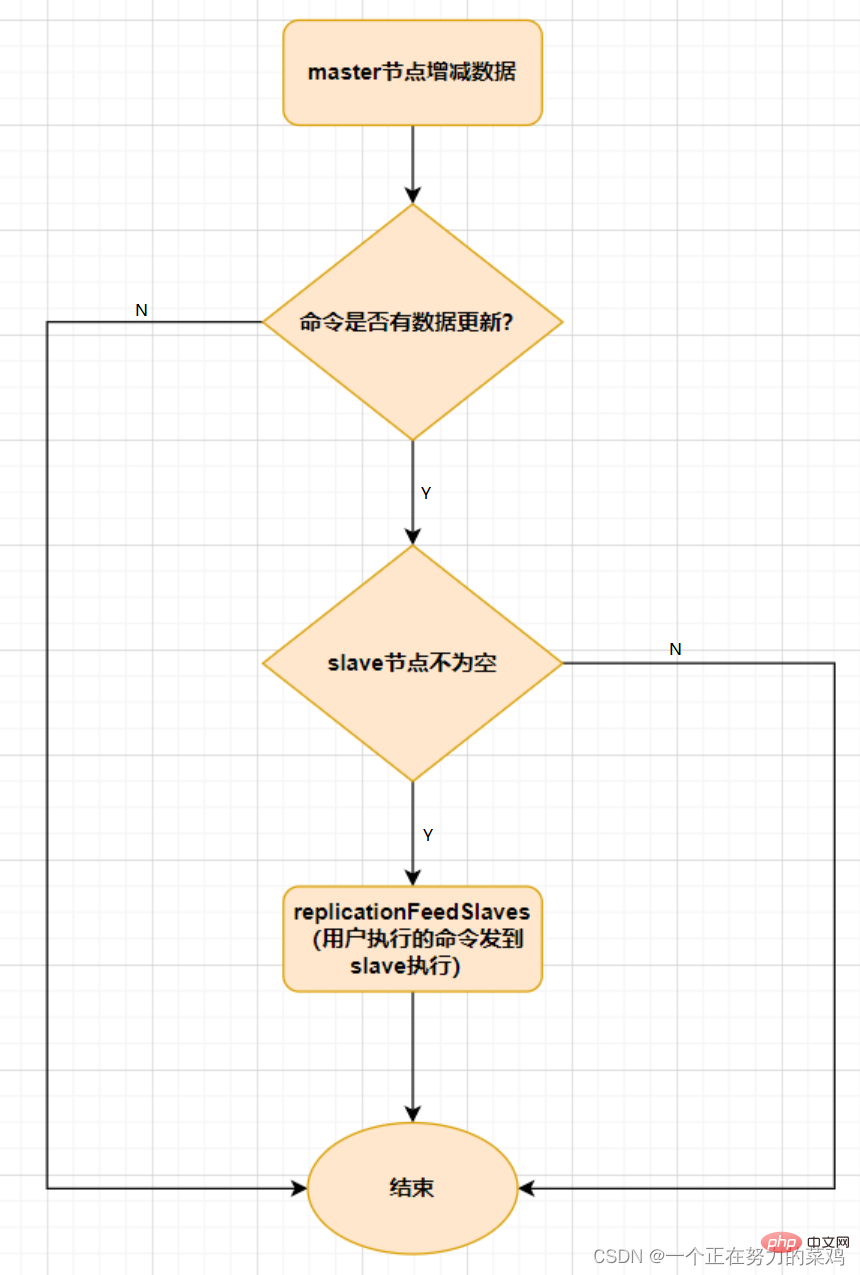
2. dan tulis
operasi
-
Nod hamba hanya bertanggungjawab untuk operasi baca
-
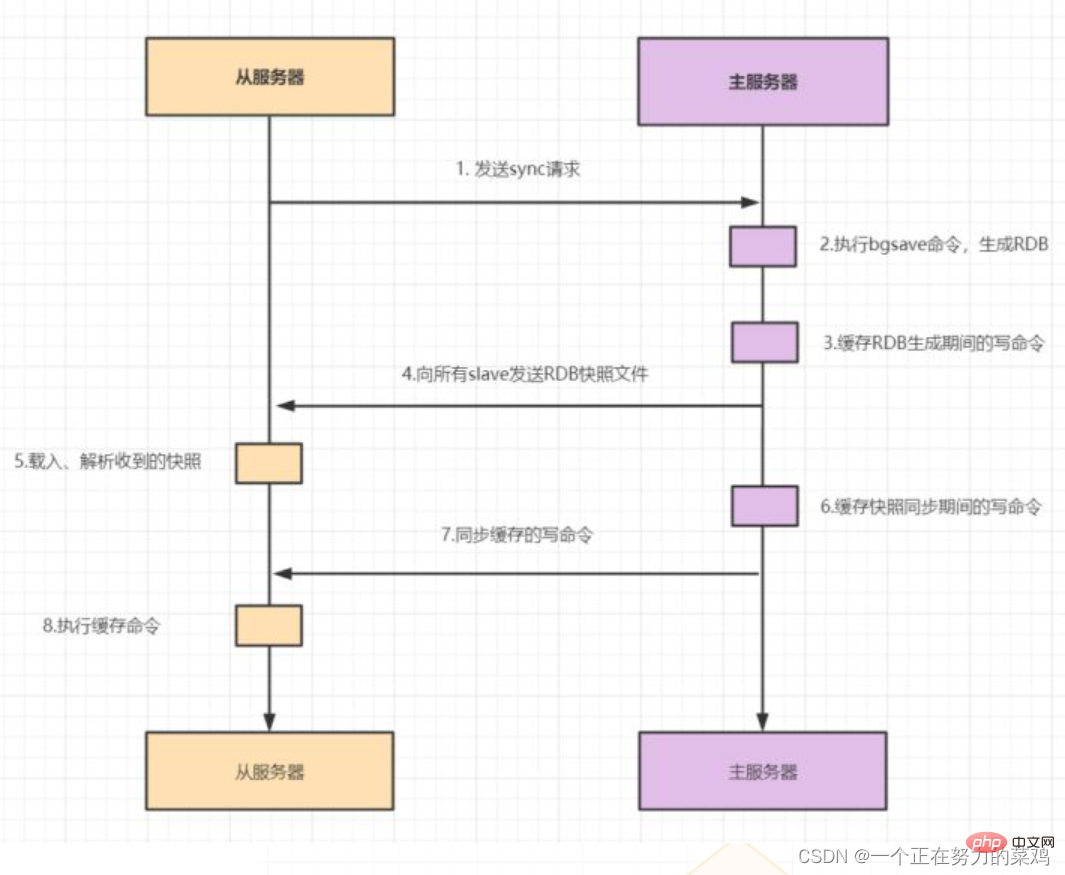
Data nod hamba datang daripada nod induk Prinsip pelaksanaan ialahmekanisme replikasi induk-hamba
- Replikasi induk-hamba termasuk replikasi penuh dan replikasi tambahan
Apabila hamba mula menyambung kepada tuan buat kali pertama, atau ia dianggap sebagai replikasi Penuh pertama digunakan untuk setiap sambungan -
Selepas hamba disegerakkan sepenuhnya dengan induk, jika data pada induk dikemas kini semula, replikasi tambahan akan dicetuskan

-
mod Sentinel
Dalam mod induk-hamba, apabila nod induk tidak dapat menyediakan perkhidmatan kerana kegagalan, adalah perlu untuk mempromosikan secara manual nod hamba kepada nod induk , dan pada masa yang sama, bahagian aplikasi mesti dimaklumkan kepada kemas kini alamat nod induk. Jelas sekali, kebanyakan senario perniagaan tidak dapat menerima kaedah pengendalian kerosakan ini secara rasmi Redis telah menyediakan seni bina Redis Sentinel (Sentinel) untuk menyelesaikan masalah ini bermula dari 2.8
Mod Sentinel Ia adalah sistem Sentinel yang terdiri. daripada satu atau lebih kejadian Sentinel ia boleh
memantau semua nod induk Redis dan nod hamba
, dan secara automatik mengambil induk luar talian apabila nod induk
yang dipantau memasuki keadaan luar talian Nod hamba di bawah pelayan ditingkatkan kepada nod induk baharu -
- Walau bagaimanapun, jika proses sentinel memantau nod Redis, masalah (titik tunggal) mungkin berlaku, jadi berbilang sentinel boleh digunakan dipantau, dan setiap sentinel turut memantau Ringkasnya, mod sentinel mempunyai tiga fungsi
-
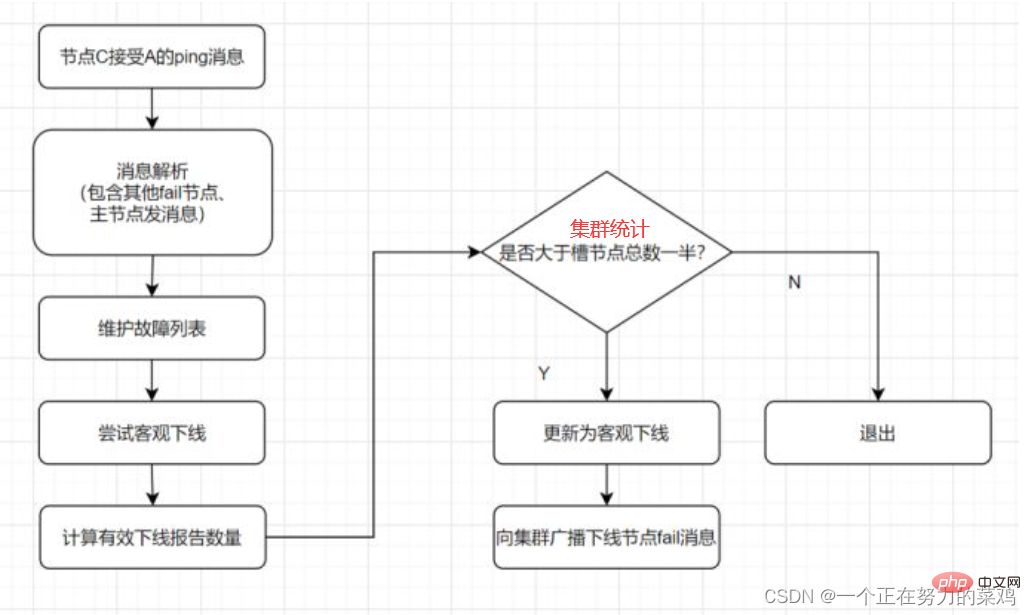
Proses failover adalah seperti berikut-
1 2 3 | 1.发送命令,等待Redis服务器(包括主服务器和从服务器)返回监控其运行状态
2.哨兵监测到主节点宕机会自动将从节点切换成主节点,然后通过发布订阅模式通知其他的从节点修改配置文件,让它们切换主机
3.哨兵之间还会相互监控,从而达到高可用
|
Salin selepas log masuk
1 2 3 4 | 假设主服务器宕机,哨兵1先检测到这个结果,系统并不会马上进行 failover 过程,仅仅是哨兵1主观的认为主服务器不可用,这个现象称为主观下线
当后面的哨兵也检测到主服务器不可用并且数量达到一定值时,那么哨兵之间就会进行一次投票,投票的结果由一个哨兵发起,进行failover操作
切换成功后通过发布订阅模式,让各个哨兵把自己监控的从服务器实现切换主机,这个过程称为客观下线
这样对于客户端而言,一切都是透明的
|
Salin selepas log masuk
4.Mod kelompok kluster
- Mod Sentinel adalah berdasarkan mod tuan-hamba , yang menyedari pemisahan membaca dan menulis, dan juga boleh bertukar secara automatik, menjadikan sistem lebih tersedia Walau bagaimanapun, data yang disimpan dalam setiap nod adalah sama, yang membazirkan memori dan tidak mudah untuk berkembang dalam talian wujud.
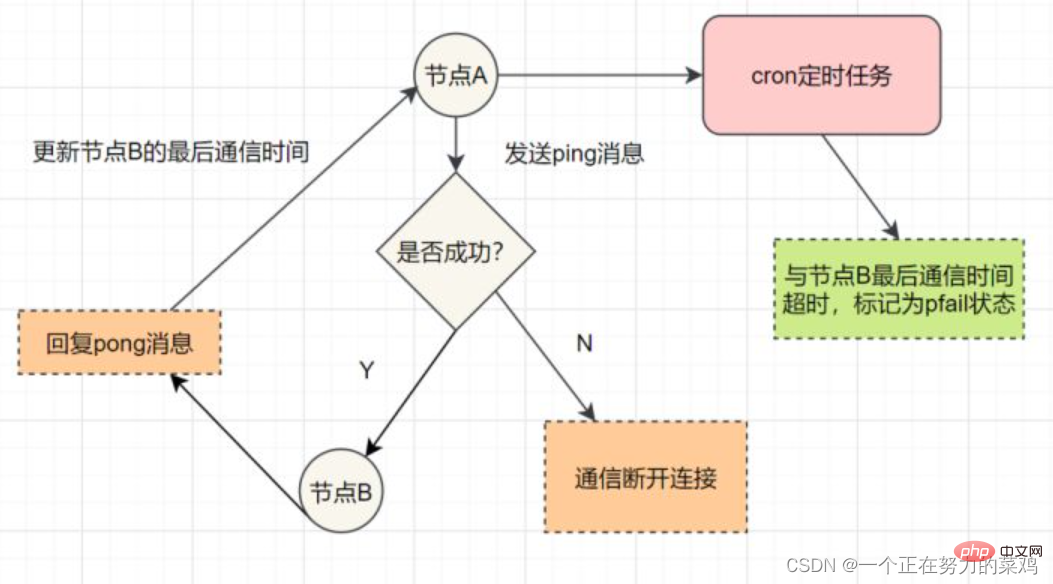
1 2 3 4 5 6 7 | 每个Sentinel以每秒钟一次的频率向它所知的Master,Slave以及其他Sentinel实例发送一个PING命令
如果实例距离最后一次有效回复PING命令的时间超过down-after-milliseconds选项所指定的值,则这个实例会被Sentinel标记为主观下线
如果一个Master被标记为主观下线,则正在监视这个Master的所有Sentinel要以每秒一次的频率确认Master的确进入了主观下线状态
当有足够数量的Sentinel(大于等于配置文件指定的值)在指定的时间范围内确认Master的确进入了主观下线状态,则Master会被标记为客观下线
一般情况下,每个Sentinel会以每10秒一次的频率向它已知的所有Master,Slave发送INFO命令
当Master被Sentinel标记为客观下线时,Sentinel向下线的Master的所有Slave发送INFO命令的频率会从10秒一次改为每秒一次
若没有足够数量的Sentinel同意Master已经下线,Master的客观下线状态就会被移除;若Master重新向Sentinel的PING命令返回有效回复,Master 的主观下线状态就会被移除
|
Salin selepas log masuk
Kluster gugusan
yang ditambahkan pada Redis3.0 melaksanakan storan teragih Redis
dan memecah data, yang bermaksud
menyimpan kandungan yang berbeza pada setiap nod Redis- , untuk
menyelesaikan masalah pengembangan dalam talian- , dan ia juga menyediakan fungsi replikasi dan failoverKluster Redis berkomunikasi melalui protokol Gosip, nod bertukar maklumat secara berterusan termasuk kegagalan nod, sambungan nod baharu, maklumat pertukaran nod induk, maklumat slot, dsb. Mesej gosip biasa ialah ping, pong, meet, fail
-
Algoritma slot Hash
1 2 3 4 | ping消息:集群内交换最频繁的消息,集群内每个节点每秒向多个其他节点发送ping消息,用于检测节点是否在线和交换彼此状态信息
meet消息:通知新节点加入,消息发送者通知接收者加入到当前集群,meet消息通信正常完成后,接收节点会加入到集群中并进行周期性的ping、pong消息交换
pong消息:当接收到ping、meet消息时,作为响应消息回复给发送方确认消息正常通信;pong消息内部封装了自身状态数据,节点也可以向集群内广播自身的pong消息来通知整个集群对自身状态进行更新
fail消息:当节点判定集群内另一个节点下线时,会向集群内广播一个fail消息,其他节点接收到fail消息之后把对应节点更新为下线状态
|
Salin selepas log masuk
5 isu Failover selepas mencapai ketersediaan tinggi
Subjektif luar talian<.>: Nod berpendapat bahawa nod lain tidak tersedia, iaitu, keadaan luar talian ini bukan penentuan kesalahan terakhir, dan hanya boleh mewakili pendapat satu nod, dan mungkin terdapat salah penilaian
1 2 3 4 5 6 7 8 | 既然是分布式存储,Cluster集群使用的分布式算法是一致性Hash嘛?并不是,而是Hash Slot插槽算法
插槽算法把整个数据库被分为16384个slot(槽),每个进入Redis的键值对根据key进行散列,分配到这16384插槽中的一个
使用的哈希映射也比较简单,用CRC16算法计算出一个16位的值,再对16384取模,数据库中的每个键都属于这16384个槽的其中一个,集群中的每个节点都可以处理这16384个槽
集群中的每个节点负责一部分的hash槽,比如当前集群有A、B、C个节点,每个节点上的哈希槽数 =16384/3,那么就有:
节点A负责0~5460号哈希槽
节点B负责5461~10922号哈希槽
节点C负责10923~16383号哈希槽Redis Cluster集群中,需要确保16384个槽对应的node都正常工作,如果某个node出现故障,它负责的slot也会失效,整个集群将不能工作
为了保证高可用,Cluster集群引入了主从复制,一个主节点对应一个或者多个从节点,当其它主节点ping一个主节点A时,如果半数以上的主节点与 A通信超时,那么认为主节点A宕机,如果主节点宕机时,就会启用从节点Redis的每一个节点上都有两个玩意,一个是插槽slot(0~16383),另外一个是cluster,可以理解为一个集群管理的插件,当我们存取的key到达时,Redis会根据Hash Slot插槽算法取到编号在0~16383之间的哈希槽,通过这个值去找到对应的插槽所对应的节点,然后直接自动跳转到这个对应的节点上进行存取操作
|
Salin selepas log masuk
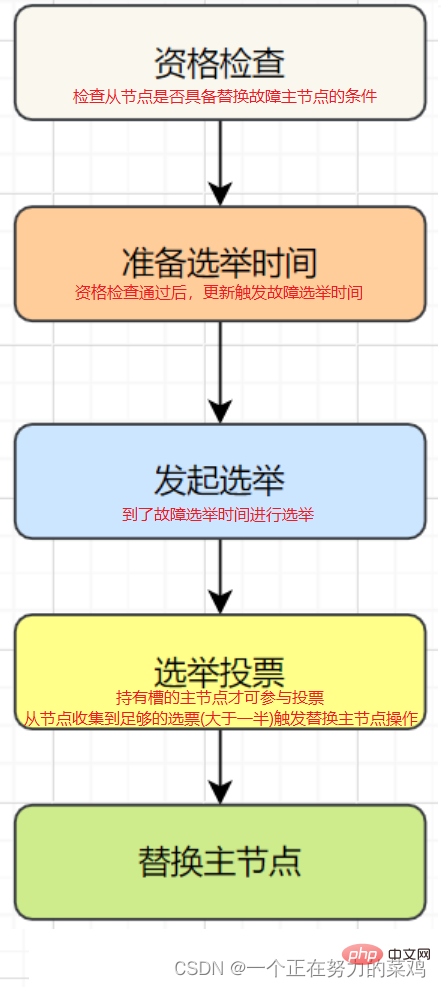
- Objektif luar talian : Tandakan nod sebagai benar-benar luar talian Berbilang nod dalam gugusan menganggap nod itu tidak tersedia dan mencapai hasil konsensus Jika Nod induk yang memegang slot gagal, dan failover perlu dilakukan untuk nod
- Pemulihan kegagalan: Selepas kesalahan ditemui, jika nod luar talian ialah nod induk, Anda perlu memilih satu nod hambanya untuk menggantikannya untuk memastikan ketersediaan tinggi kluster
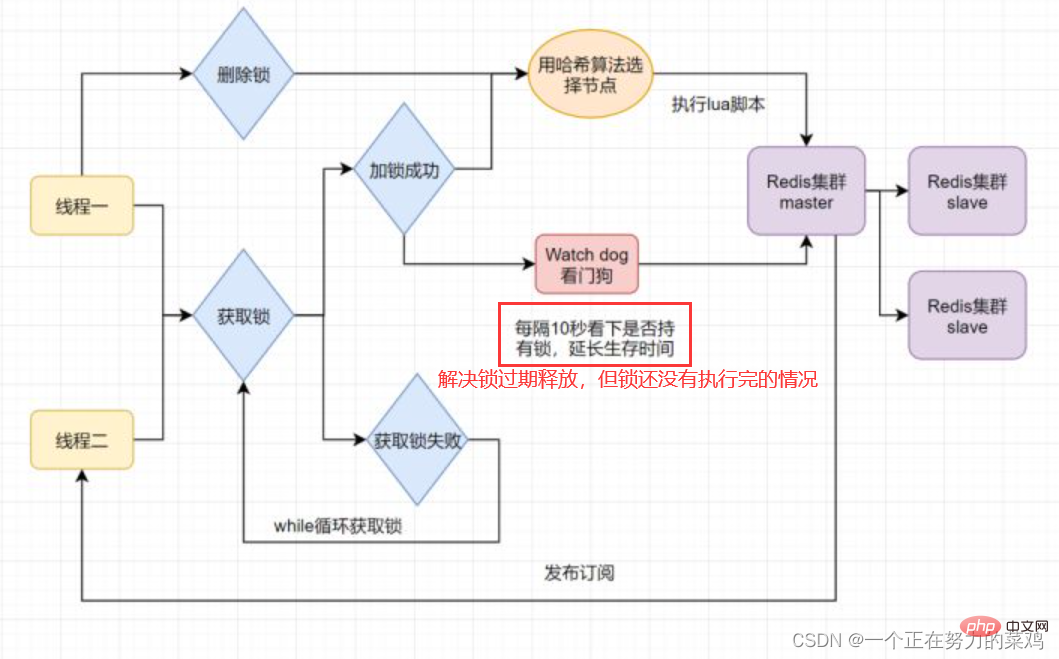
- Satu siri masalah dan penyelesaian yang disebabkan oleh kunci yang diedarkan Redis 1. Redisson
Kunci yang diedarkan mungkin mempunyai
tamat tempoh dan pelepasan kunci, tetapi perniagaan tidak selesai
Bolehkah masa tamat tempoh kunci ditetapkan lebih lama untuk menyelesaikannya? masalah? Jelas sekali ia tidak bagus, masa pelaksanaan perniagaan tidak menentu
Redisson menyelesaikan masalah ini dengan membuka benang daemon bermasa untuk benang yang memperoleh kunci dan menyemak sama ada kunci itu wujud sekali-sekala, dan memanjangkan kunci jika wujud Masa tamat tempoh untuk mengelakkan kunci tamat tempoh dan pelepasan awal
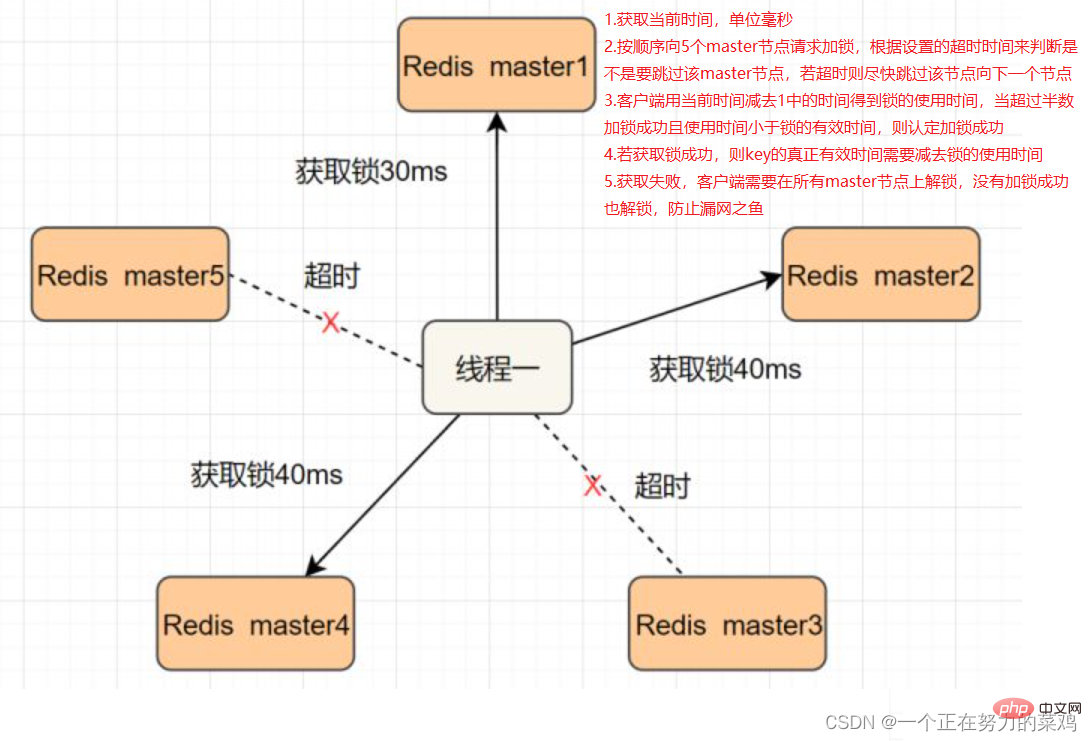
2. Algoritma Redlock
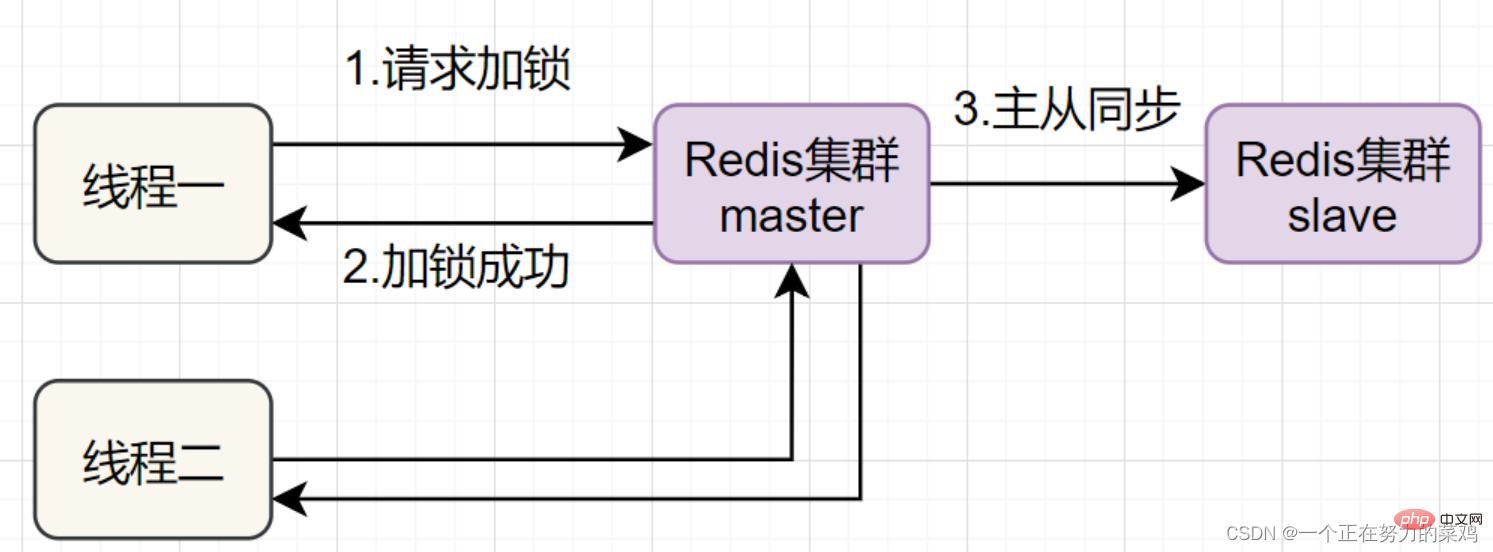
- Thread 1 mendapat kunci pada nod induk Redis, tetapi kunci yang dikunci belum lagi disegerakkan ke nod hamba. Pada masa ini, nod induk gagal, dan nod hamba akan dinaik taraf kepada nod induk Benang dua boleh mendapatkan kunci kunci yang sama, tetapi benang satu juga telah memperoleh kunci, dan keselamatan kunci hilang <.>
- Redlock menyelesaikan masalah ini dengan menggunakan berbilang induk Redis untuk memastikan ia tidak akan turun serentak dan nod induk ini bebas sepenuhnya daripada antara satu sama lain, Terdapat tiada penyegerakan data antara satu sama lain Langkah pelaksanaan adalah seperti berikut
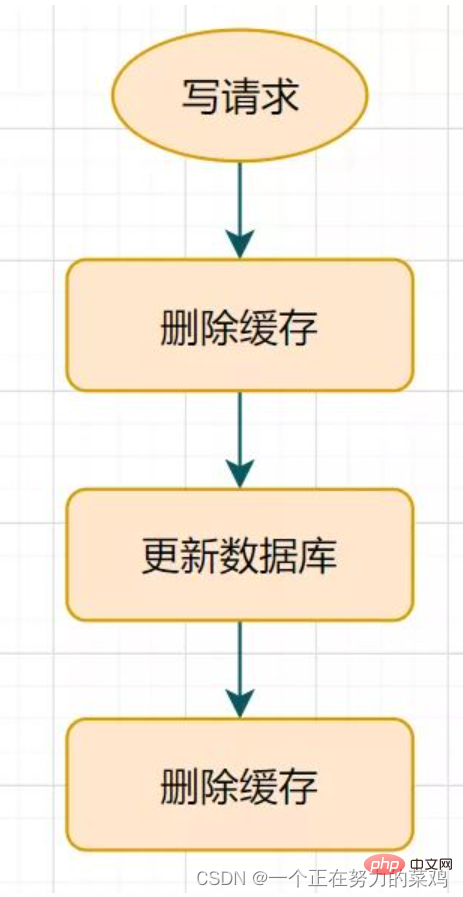
Cara memastikan konsistensi penulisan dua kali antara. MySQL dan Redis
1. Delay Double delete pada masa yang sama
Selepas mengemas kini pangkalan data, tangguhkan tidur seketika dan kemudian padamkan cache- Penyelesaian ini tidak mengapa. Hanya semasa tempoh tidur, mungkin terdapat data yang kotor, dan ia akan diterima oleh perniagaan umum
- Tetapi bagaimana jika pemadaman cache gagal untuk kali kedua? Data dalam cache dan pangkalan data mungkin masih tidak konsisten
- Bagaimana pula dengan menetapkan masa tamat tempoh semula jadi untuk Kunci dan membiarkannya tamat tempoh secara automatik? Apakah yang perlu saya lakukan jika data yang diterima oleh perniagaan dalam masa tamat tempoh tidak konsisten? Masih terdapat penyelesaian lain yang lebih baik
-
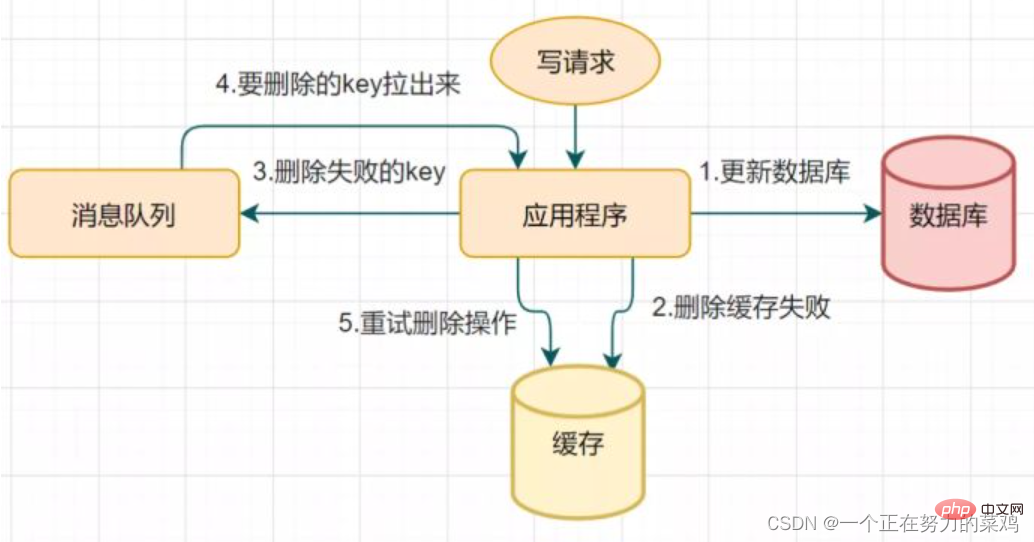
2. Padamkan mekanisme percubaan semula cache
Pemadaman dua kali tertunda mungkin mempunyai langkah kedua untuk memadamkan cache Kegagalan, mengakibatkan data tidak konsisten - Jika pemadaman gagal, padamkannya beberapa kali lagi untuk memastikan pemadaman cache berjaya, jadi anda boleh memperkenalkan
- mekanisme percubaan semula cache pemadaman
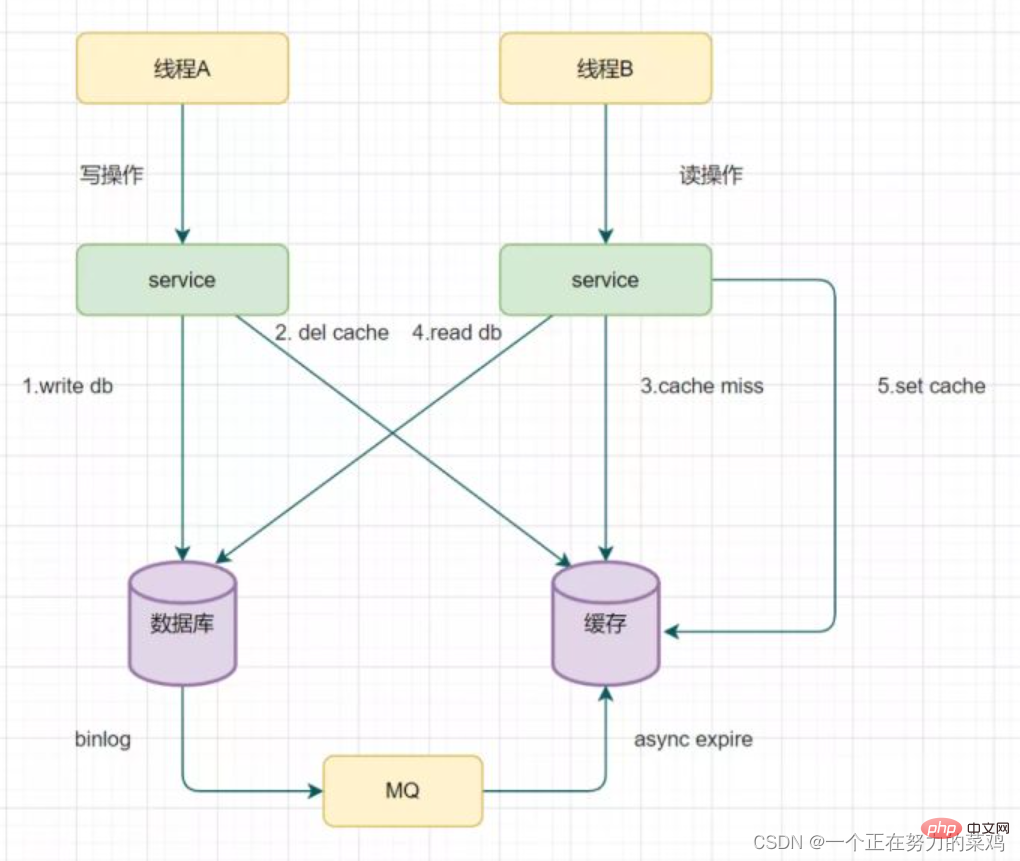
3. Baca biglog dan padamkan cache secara tak segerak
Cuba semula untuk memadam mekanisme cache akan menyebabkan banyak pencerobohan kod perniagaan, jadi membaca biglog dan memadam cache secara tidak segerak -
Pembelajaran yang disyorkan:
Tutorial video Redis
Atas ialah kandungan terperinci Penjelasan grafik terperinci tentang kelompok dan pengembangan Redis. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!


 Dalam mod induk-hamba, apabila nod induk tidak dapat menyediakan perkhidmatan kerana kegagalan, adalah perlu untuk mempromosikan secara manual nod hamba kepada nod induk , dan pada masa yang sama, bahagian aplikasi mesti dimaklumkan kepada kemas kini alamat nod induk. Jelas sekali, kebanyakan senario perniagaan tidak dapat menerima kaedah pengendalian kerosakan ini secara rasmi Redis telah menyediakan seni bina Redis Sentinel (Sentinel) untuk menyelesaikan masalah ini bermula dari 2.8
Dalam mod induk-hamba, apabila nod induk tidak dapat menyediakan perkhidmatan kerana kegagalan, adalah perlu untuk mempromosikan secara manual nod hamba kepada nod induk , dan pada masa yang sama, bahagian aplikasi mesti dimaklumkan kepada kemas kini alamat nod induk. Jelas sekali, kebanyakan senario perniagaan tidak dapat menerima kaedah pengendalian kerosakan ini secara rasmi Redis telah menyediakan seni bina Redis Sentinel (Sentinel) untuk menyelesaikan masalah ini bermula dari 2.8 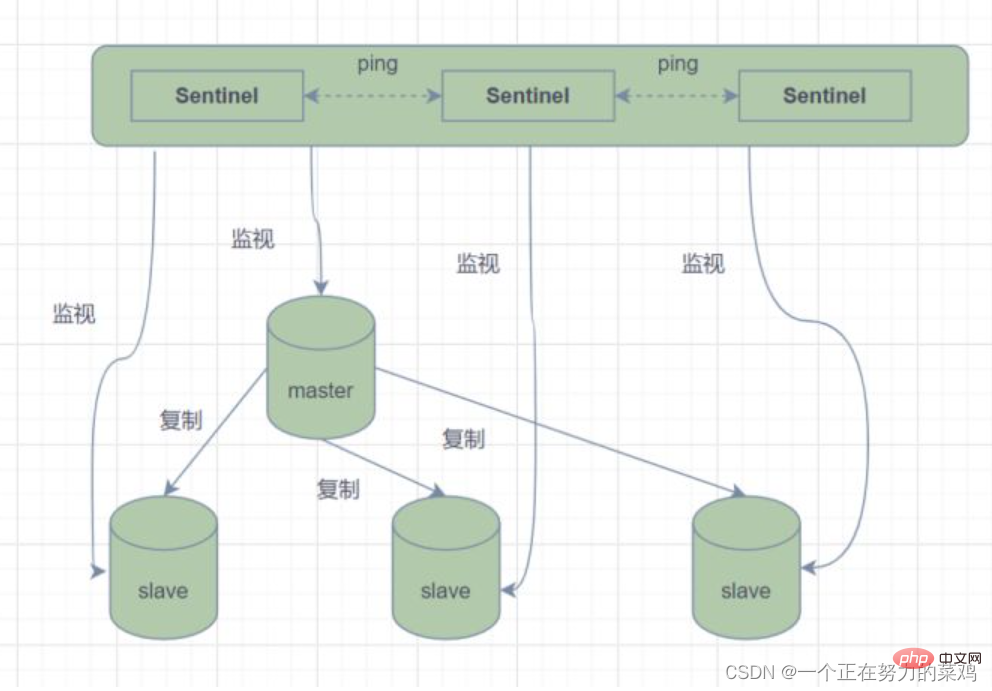
 Perisian pangkalan data yang biasa digunakan
Perisian pangkalan data yang biasa digunakan
 Apakah pangkalan data dalam memori?
Apakah pangkalan data dalam memori?
 Yang manakah mempunyai kelajuan bacaan yang lebih pantas, mongodb atau redis?
Yang manakah mempunyai kelajuan bacaan yang lebih pantas, mongodb atau redis?
 Cara menggunakan redis sebagai pelayan cache
Cara menggunakan redis sebagai pelayan cache
 Bagaimana redis menyelesaikan ketekalan data
Bagaimana redis menyelesaikan ketekalan data
 Bagaimanakah mysql dan redis memastikan konsistensi penulisan dua kali?
Bagaimanakah mysql dan redis memastikan konsistensi penulisan dua kali?
 Apakah data yang biasanya disimpan oleh redis cache?
Apakah data yang biasanya disimpan oleh redis cache?
 Apakah 8 jenis data redis
Apakah 8 jenis data redis










![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



