

Bagaimana untuk menyelesaikan masalah paging dalam mysql

Artikel ini membawa anda pengetahuan yang berkaitan tentang mysql Ia terutamanya memperkenalkan penyelesaian elegan kepada masalah paging dalam mysql Artikel ini akan membincangkan cara mengoptimumkan paging dalam apabila jadual mysql mempunyai jumlah data yang besar . Masalah penomboran, dan dilampirkan ialah kod pseudo bagi kes mengoptimumkan masalah SQL yang perlahan, saya harap ia akan membantu semua orang.

Pembelajaran yang disyorkan: tutorial video mysql
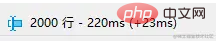
Dalam proses pembangunan permintaan harian, saya percaya semua orang akan biasa dengan had, tetapi menggunakan had, apabila offset (offset) sangat besar, anda akan mendapati kecekapan pertanyaan semakin perlahan dan perlahan. Apabila had ialah 2000 pada permulaan, ia mungkin mengambil masa 200ms untuk menanyakan data yang diperlukan Walau bagaimanapun, apabila had adalah 4000 mengimbangi 100000, anda akan mendapati bahawa kecekapan pertanyaannya sudah memerlukan kira-kira 1S lebih teruk dan lambat.
Ringkasan
Artikel ini akan membincangkan cara mengoptimumkan masalah paging dalam apabila jadual mysql mempunyai jumlah data yang besar, dan melampirkan pseudokod bagi kes terkini untuk mengoptimumkan masalah sql perlahan.
1. Hadkan huraian masalah paging dalam
Mari kita lihat struktur jadual dahulu (sekadar beri contoh, struktur jadual tidak lengkap dan medan yang tidak berguna tidak akan dipaparkan)
CREATE TABLE `p2p_detail_record` ( `id` varchar(32) COLLATE utf8mb4_bin NOT NULL DEFAULT '' COMMENT '主键', `batch_num` int NOT NULL DEFAULT '0' COMMENT '上报数量', `uptime` bigint NOT NULL DEFAULT '0' COMMENT '上报时间', `uuid` varchar(64) COLLATE utf8mb4_bin NOT NULL DEFAULT '' COMMENT '会议id', `start_time_stamp` bigint NOT NULL DEFAULT '0' COMMENT '开始时间', `answer_time_stamp` bigint NOT NULL DEFAULT '0' COMMENT '应答时间', `end_time_stamp` bigint NOT NULL DEFAULT '0' COMMENT '结束时间', `duration` int NOT NULL DEFAULT '0' COMMENT '持续时间', PRIMARY KEY (`id`), KEY `idx_uuid` (`uuid`), KEY `idx_start_time_stamp` (`start_time_stamp`) //索引, ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin COMMENT='p2p通话记录详情表';
Andaikan SQL paging dalam yang ingin kami tanyakan kelihatan seperti ini
select * from p2p_detail_record ppdr where ppdr .start_time_stamp >1656666798000 limit 0,2000

Kecekapan pertanyaan ialah 94ms. Bukankah ia pantas? Jadi jika kita mengehadkan 100000 atau 2000, kecekapan pertanyaan ialah 1.5S, yang sudah sangat perlahan Bagaimana jika ada lagi?

2 Analisis punca slow sql
Mari kita lihat pelan pelaksanaan ini sql

juga telah mencapai indeks, jadi mengapa ia masih perlahan? Mari kita semak semula mata pengetahuan mysql yang berkaitan.
Indeks berkelompok dan indeks bukan berkelompok
Indeks berkelompok: Nod daun menyimpan seluruh baris data.
Indeks bukan berkelompok: Nod daun menyimpan nilai kunci utama yang sepadan dengan keseluruhan baris data.
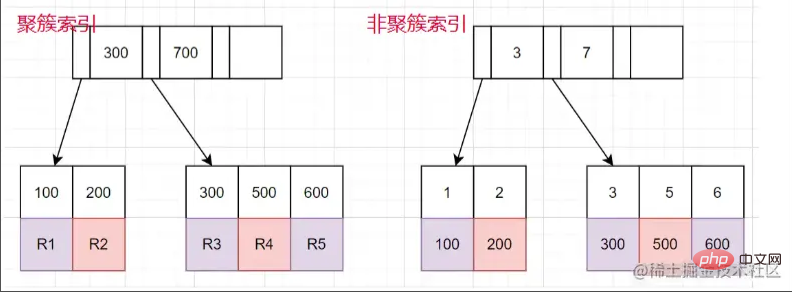
Proses menggunakan pertanyaan indeks bukan berkelompok
- Cari nod daun yang sepadan melalui indeks bukan berkelompok tree , dapatkan nilai kunci utama.
- kemudian mendapatkan semula nilai kunci utama dan kembali ke pokok indeks berkelompok untuk mencari keseluruhan baris data yang sepadan. (Keseluruhan proses dipanggil pulangan jadual)
Berbalik kepada persoalan mengapa SQL ini lambat, sebabnya adalah seperti berikut
1 pernyataan akan mengimbas n baris pertama offset, kemudian membuang baris offset pertama dan mengembalikan n baris data seterusnya. Dalam erti kata lain, limit 100000,10 akan mengimbas 100010 baris, manakala limit 0,10 hanya akan mengimbas 10 baris. Di sini kita perlu kembali ke jadual 100010 kali, dan banyak masa dihabiskan untuk mengembalikan jadual.
Idea teras penyelesaian: Bolehkah anda mengetahui terlebih dahulu ID kunci utama yang mana untuk dimulakan dan mengurangkan bilangan pemulangan jadual
Penyelesaian biasa
Melalui subqueries Optimize
select * from p2p_detail_record ppdr where id >= (select id from p2p_detail_record ppdr2 where ppdr2 .start_time_stamp >1656666798000 limit 100000,1) limit 2000
Hasil pertanyaan yang sama juga merupakan item ke-2000 bermula daripada 100,000 item Kecekapan pertanyaan ialah 200ms, yang jauh lebih pantas.
Kaedah rakaman tag
Kaedah rakaman tag: Sebenarnya, tandakan item mana yang anda semak kali terakhir, dan semak lagi lain kali Apabila tiba masanya, mulakan imbasan dari bar ini ke bawah. Serupa dengan penanda halaman
select * from p2p_detail_record ppdr where ppdr.id > 'bb9d67ee6eac4cab9909bad7c98f54d4' order by id limit 2000 备注:bb9d67ee6eac4cab9909bad7c98f54d4是上次查询结果的最后一条ID
Menggunakan kaedah rakaman tag, prestasi akan menjadi baik kerana indeks id dipukul. Tetapi pendekatan ini mempunyai beberapa kelemahan.
- 1. Anda hanya boleh membuat pertanyaan pada halaman berturut-turut, bukan merentasi halaman.
- 2. Medan serupa dengan yang secara berterusan meningkat diperlukan (orber mengikut id boleh digunakan).
Perbandingan penyelesaian
- Menggunakan untuk mengoptimumkan melalui subqueries
Kelebihan: Anda boleh membuat pertanyaan merentasi halaman dan anda boleh menyemak data pada mana-mana halaman yang anda ingin semak.
Kelemahan: tidak secekap kaedah rakaman tag. Sebab: Contohnya, selepas anda perlu menyemak 100,000 keping data, anda juga perlu menanyakan sekeping data ke-1000 yang sepadan dengan indeks bukan berkelompok dahulu, dan kemudian dapatkan ID bermula dari ke-100,000 sekeping untuk pertanyaan.
- Menggunakan kaedah rakaman tag
Kelebihan: Kecekapan pertanyaan adalah sangat stabil dan sangat pantas.
Kelemahan:
- 不跨页查询,
- 需要一种类似连续自增的字段
关于第二点的说明: 该点一般都好解决,可使用任意不重复的字段进行排序即可。若使用可能重复的字段进行排序的字段,由于mysql对于相同值的字段排序是无序,导致如果正好在分页时,上下页中可能存在相同的数据。
实战案例
需求: 需要查询查询某一时间段的数据量,假设有几十万的数据量需要查询出来,进行某些操作。
需求分析 1、分批查询(分页查询),设计深分页问题,导致效率较慢。
CREATE TABLE `p2p_detail_record` ( `id` varchar(32) COLLATE utf8mb4_bin NOT NULL DEFAULT '' COMMENT '主键', `batch_num` int NOT NULL DEFAULT '0' COMMENT '上报数量', `uptime` bigint NOT NULL DEFAULT '0' COMMENT '上报时间', `uuid` varchar(64) COLLATE utf8mb4_bin NOT NULL DEFAULT '' COMMENT '会议id', `start_time_stamp` bigint NOT NULL DEFAULT '0' COMMENT '开始时间', `answer_time_stamp` bigint NOT NULL DEFAULT '0' COMMENT '应答时间', `end_time_stamp` bigint NOT NULL DEFAULT '0' COMMENT '结束时间', `duration` int NOT NULL DEFAULT '0' COMMENT '持续时间', PRIMARY KEY (`id`), KEY `idx_uuid` (`uuid`), KEY `idx_start_time_stamp` (`start_time_stamp`) //索引, ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin COMMENT='p2p通话记录详情表';
伪代码实现:
//最小ID
String lastId = null;
//一页的条数
Integer pageSize = 2000;
List<P2pRecordVo> list ;
do{
list = listP2pRecordByPage(lastId,pageSize); //标签记录法,记录上次查询过的Id
lastId = list.get(list.size()-1).getId(); //获取上一次查询数据最后的ID,用于记录
//对数据的操作逻辑
XXXXX();
}while(isNotEmpty(list));
<select id ="listP2pRecordByPage">
select *
from p2p_detail_record ppdr where 1=1
<if test = "lastId != null">
and ppdr.id > #{lastId}
</if>
order by id asc
limit #{pageSize}
</select>这里有个小优化点: 可能有的人会先对所有数据排序一遍,拿到最小ID,但是这样对所有数据排序,然后去min(id),耗时也蛮长的,其实第一次查询,可不带lastId进行查询,查询结果也是一样。速度更快。
总结
1、当业务需要从表中查出大数据量时,而又项目架构没上ES时,可考虑使用标签记录法的方式,对查询效率进行优化。
2、从需求上也应该尽可能避免,在大数据量的情况下,分页查询最后一页的功能。或者限制成只能一页一页往后划的场景。
推荐学习:mysql视频教程
Atas ialah kandungan terperinci Bagaimana untuk menyelesaikan masalah paging dalam mysql. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

Video Face Swap
Tukar muka dalam mana-mana video dengan mudah menggunakan alat tukar muka AI percuma kami!

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas



 Cara membuka phpmyadmin
Apr 10, 2025 pm 10:51 PM
Cara membuka phpmyadmin
Apr 10, 2025 pm 10:51 PM
Anda boleh membuka phpmyadmin melalui langkah -langkah berikut: 1. Log masuk ke panel kawalan laman web; 2. Cari dan klik ikon phpmyadmin; 3. Masukkan kelayakan MySQL; 4. Klik "Login".
 MySQL: Pengenalan kepada pangkalan data paling popular di dunia
Apr 12, 2025 am 12:18 AM
MySQL: Pengenalan kepada pangkalan data paling popular di dunia
Apr 12, 2025 am 12:18 AM
MySQL adalah sistem pengurusan pangkalan data relasi sumber terbuka, terutamanya digunakan untuk menyimpan dan mengambil data dengan cepat dan boleh dipercayai. Prinsip kerjanya termasuk permintaan pelanggan, resolusi pertanyaan, pelaksanaan pertanyaan dan hasil pulangan. Contoh penggunaan termasuk membuat jadual, memasukkan dan menanyakan data, dan ciri -ciri canggih seperti Operasi Join. Kesalahan umum melibatkan sintaks SQL, jenis data, dan keizinan, dan cadangan pengoptimuman termasuk penggunaan indeks, pertanyaan yang dioptimumkan, dan pembahagian jadual.
 Tempat Mysql: Pangkalan Data dan Pengaturcaraan
Apr 13, 2025 am 12:18 AM
Tempat Mysql: Pangkalan Data dan Pengaturcaraan
Apr 13, 2025 am 12:18 AM
Kedudukan MySQL dalam pangkalan data dan pengaturcaraan sangat penting. Ia adalah sistem pengurusan pangkalan data sumber terbuka yang digunakan secara meluas dalam pelbagai senario aplikasi. 1) MySQL menyediakan fungsi penyimpanan data, organisasi dan pengambilan data yang cekap, sistem sokongan web, mudah alih dan perusahaan. 2) Ia menggunakan seni bina pelanggan-pelayan, menyokong pelbagai enjin penyimpanan dan pengoptimuman indeks. 3) Penggunaan asas termasuk membuat jadual dan memasukkan data, dan penggunaan lanjutan melibatkan pelbagai meja dan pertanyaan kompleks. 4) Soalan -soalan yang sering ditanya seperti kesilapan sintaks SQL dan isu -isu prestasi boleh disahpepijat melalui arahan jelas dan log pertanyaan perlahan. 5) Kaedah pengoptimuman prestasi termasuk penggunaan indeks rasional, pertanyaan yang dioptimumkan dan penggunaan cache. Amalan terbaik termasuk menggunakan urus niaga dan preparedStatemen
 Mengapa menggunakan mysql? Faedah dan kelebihan
Apr 12, 2025 am 12:17 AM
Mengapa menggunakan mysql? Faedah dan kelebihan
Apr 12, 2025 am 12:17 AM
MySQL dipilih untuk prestasi, kebolehpercayaan, kemudahan penggunaan, dan sokongan komuniti. 1.MYSQL Menyediakan fungsi penyimpanan dan pengambilan data yang cekap, menyokong pelbagai jenis data dan operasi pertanyaan lanjutan. 2. Mengamalkan seni bina pelanggan-pelayan dan enjin penyimpanan berganda untuk menyokong urus niaga dan pengoptimuman pertanyaan. 3. Mudah digunakan, menyokong pelbagai sistem operasi dan bahasa pengaturcaraan. 4. Mempunyai sokongan komuniti yang kuat dan menyediakan sumber dan penyelesaian yang kaya.
 Cara menyambung ke pangkalan data Apache
Apr 13, 2025 pm 01:03 PM
Cara menyambung ke pangkalan data Apache
Apr 13, 2025 pm 01:03 PM
Apache menyambung ke pangkalan data memerlukan langkah -langkah berikut: Pasang pemacu pangkalan data. Konfigurasikan fail web.xml untuk membuat kolam sambungan. Buat sumber data JDBC dan tentukan tetapan sambungan. Gunakan API JDBC untuk mengakses pangkalan data dari kod Java, termasuk mendapatkan sambungan, membuat kenyataan, parameter mengikat, melaksanakan pertanyaan atau kemas kini, dan hasil pemprosesan.
 Cara Memulakan MySQL oleh Docker
Apr 15, 2025 pm 12:09 PM
Cara Memulakan MySQL oleh Docker
Apr 15, 2025 pm 12:09 PM
Proses memulakan MySQL di Docker terdiri daripada langkah -langkah berikut: Tarik imej MySQL untuk membuat dan memulakan bekas, tetapkan kata laluan pengguna root, dan memetakan sambungan pengesahan port Buat pangkalan data dan pengguna memberikan semua kebenaran ke pangkalan data
 Peranan MySQL: Pangkalan Data dalam Aplikasi Web
Apr 17, 2025 am 12:23 AM
Peranan MySQL: Pangkalan Data dalam Aplikasi Web
Apr 17, 2025 am 12:23 AM
Peranan utama MySQL dalam aplikasi web adalah untuk menyimpan dan mengurus data. 1.MYSQL dengan cekap memproses maklumat pengguna, katalog produk, rekod urus niaga dan data lain. 2. Melalui pertanyaan SQL, pemaju boleh mengekstrak maklumat dari pangkalan data untuk menghasilkan kandungan dinamik. 3.MYSQL berfungsi berdasarkan model klien-pelayan untuk memastikan kelajuan pertanyaan yang boleh diterima.
 CentOS memasang MySQL
Apr 14, 2025 pm 08:09 PM
CentOS memasang MySQL
Apr 14, 2025 pm 08:09 PM
Memasang MySQL pada CentOS melibatkan langkah -langkah berikut: Menambah sumber MySQL YUM yang sesuai. Jalankan YUM Pasang Perintah MySQL-Server untuk memasang pelayan MySQL. Gunakan perintah mysql_secure_installation untuk membuat tetapan keselamatan, seperti menetapkan kata laluan pengguna root. Sesuaikan fail konfigurasi MySQL seperti yang diperlukan. Tune parameter MySQL dan mengoptimumkan pangkalan data untuk prestasi.
