

Kaedah pelaksanaan Java untuk menentukan pengekodan semasa membuat fail

Artikel ini membawakan anda pengetahuan yang berkaitan tentang java Ia terutamanya memperkenalkan kaedah pelaksanaan pengekodan Java apabila mencipta fail Artikel ini memperkenalkannya dengan terperinci melalui kod sampel, yang sangat berguna untuk semua orang . Ia mempunyai rujukan dan nilai pembelajaran tertentu semasa belajar atau bekerja.

Kajian yang disyorkan: "tutorial video java"
Kata Pengantar: Baru-baru ini, saya telah mempelajari pengetahuan yang berkaitan dengan aliran Java IO. Saya ingin Mengamalkan dan mengukuhkan pengetahuan yang telah anda pelajari dengan membaca dan menulis dokumen. Apabila menggunakan kelas Fail untuk mencipta fail, saya tiba-tiba terfikir, bagaimanakah saya harus menentukan pengekodan yang digunakan oleh fail tersebut? Kemudian saya fikir, bagaimana saya harus menyemak pengekodan fail?
1. Analisis Masalah
Mula-mula pergi ke Internet untuk mencari jawapannya adalah seperti berikut:
FileInputStream fis=new FileInputStream(“xxxx.txt”); OutputStreamWriter osw=new OutputStreamWriter(fis,“UTF-8”);
Kod di atas mungkin bermakna apabila menulis a. fail, Aksara dikodkan dalam UTF-8, yang berbeza daripada apa yang saya harapkan. Seperti yang berikut,
File myfile = new File("test.txt”, “UTF-8”);
if (!myfile.exists()) myfile.createNewFile();Jadi, saya menyemak dokumentasi Java API 8 rasmi tidak menyediakan pembina yang boleh menentukan pengekodan aksara.

Pada masa yang sama, ia tidak menyediakan kaedah lain untuk mengakses pengekodan aksara seperti set atau get, menunjukkan bahawa pengekodan aksara bukanlah atribut yang wujud bagi fail. Seperti masa penciptaan fail, masa pengubahsuaian fail, sama ada ia boleh dibaca, boleh ditulis dan boleh laku, ini adalah atribut yang wujud bagi fail, atau meta-maklumat, ia adalah sebahagian daripada fail.
2. Pengekodan aksara
Kami tahu bahawa sebarang maklumat yang disimpan dalam komputer ialah rentetan 01, dan teks tidak terkecuali.
Pemprosesan aksara termasuk dua proses: Pengekodan dan penyahkodan
Pengekodan: "petakan" aksara kepada rentetan 01
Penyahkodan: tukar 01 Rentetan "peta" kepada aksara
Pengekodan aksara yang berbeza, seperti GBK, UTF-8, menggunakan peraturan yang berbeza untuk pengekodan dan penyahkodan.
Untuk rentetan teks yang sama: "China", gunakan pengekodan UTF-8 untuk menyimpan, secara amnya menggunakan tiga bait untuk menyimpan aksara Cina (bentuk heksadesimal rentetan 01 yang mendasari).
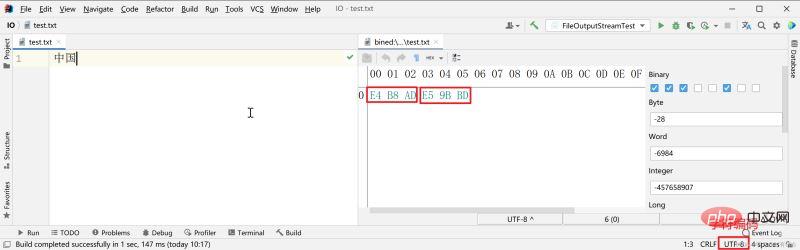
disimpan menggunakan pengekodan GBK, menggunakan dua bait untuk mewakili aksara Cina.
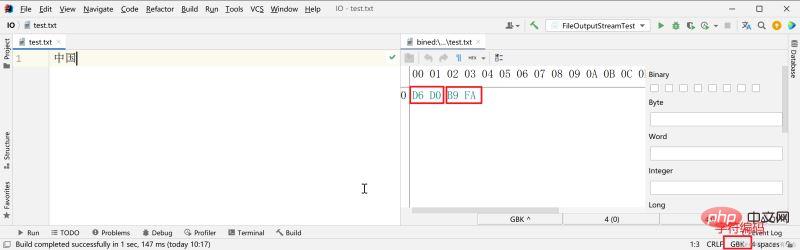
Apabila kami menulis teks dalam editor teks dan menyimpannya, editor akan "memetakan" teks ke dalam rentetan 01 mengikut jenis pengekodan aksara yang anda tetapkan.
Jenis aksara yang anda tetapkan hanyalah peraturan penukaran untuk editor mengekod teks ke dalam 10 rentetan dan bukan atribut teks.
Apabila editor membuka fail teks, apa yang dipaparkan bukanlah rentetan 01 asas, tetapi teks Ini kerana editor menggunakan pengekodan teks tertentu untuk menyahkod rentetan 01 kepada aksara. Jika, apabila penyahkodan, pengekodan aksara yang digunakan adalah konsisten atau serasi dengan pengekodan, teks boleh dipaparkan dengan betul. Jika pengekodan aksara yang digunakan semasa penyahkodan tidak konsisten atau tidak serasi dengan pengekodan, aksara akan menjadi kacau bilau.
Sebagai contoh, saya mempunyai fail teks menggunakan pengekodan GBK, kandungannya ialah "Bila bulan terang akan keluar",

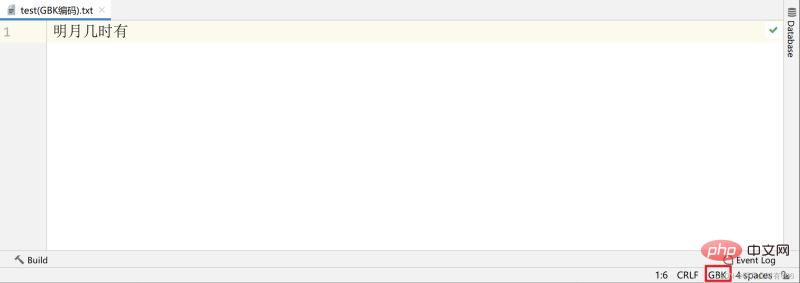
Saya menggunakan kod VS (editor teks yang sangat berguna daripada Microsoft) untuk membuka fail, yang secara istilah bermaksud menyahkod fail. Pengekodan teks lalai yang digunakan ialah UTF-8, dan penyahkodan adalah sama. Walau bagaimanapun, kerana lapisan bawah teks saya ialah rentetan 01 yang dikodkan GBK (dua bait dan satu aksara), menggunakan UTF-8 untuk menyahkod rentetan 01 sudah pasti akan membawa kepada aksara bercelaru disebabkan pengekodan dan penyahkodan yang tidak konsisten. Pada masa ini, selagi anda memilih pengekodan GBK yang sepadan secara manual, fail yang dinyahkod tidak akan bercelaru.
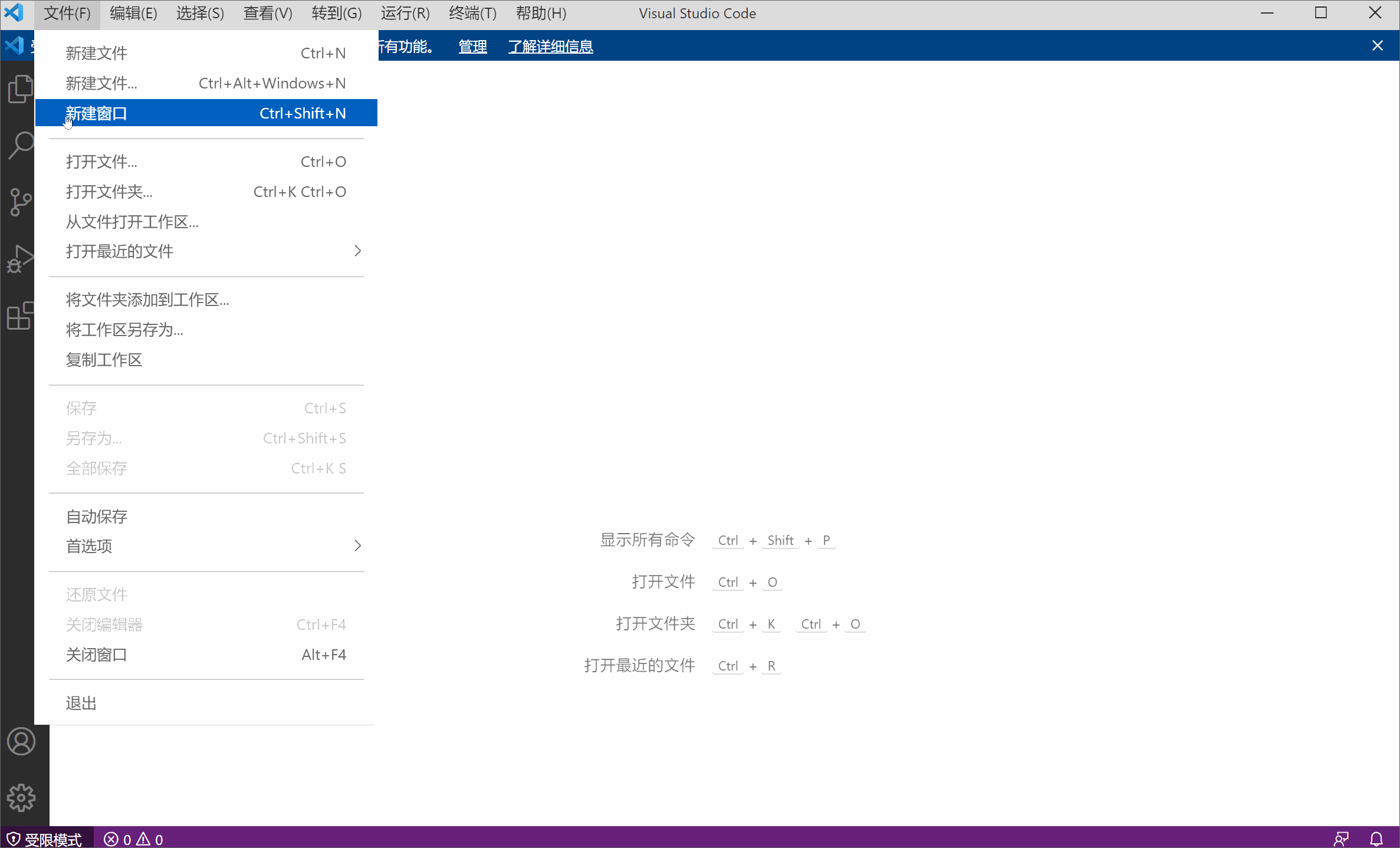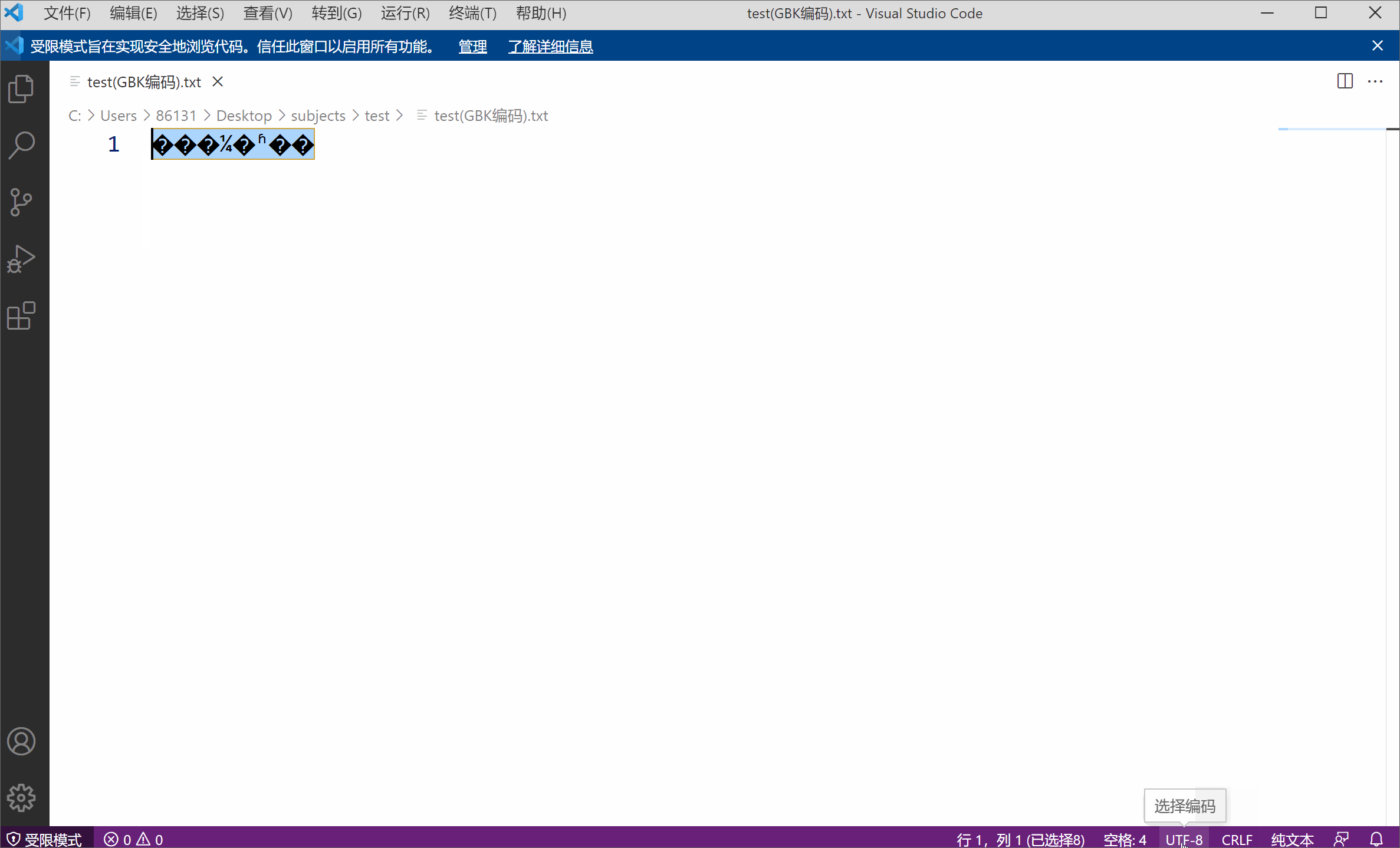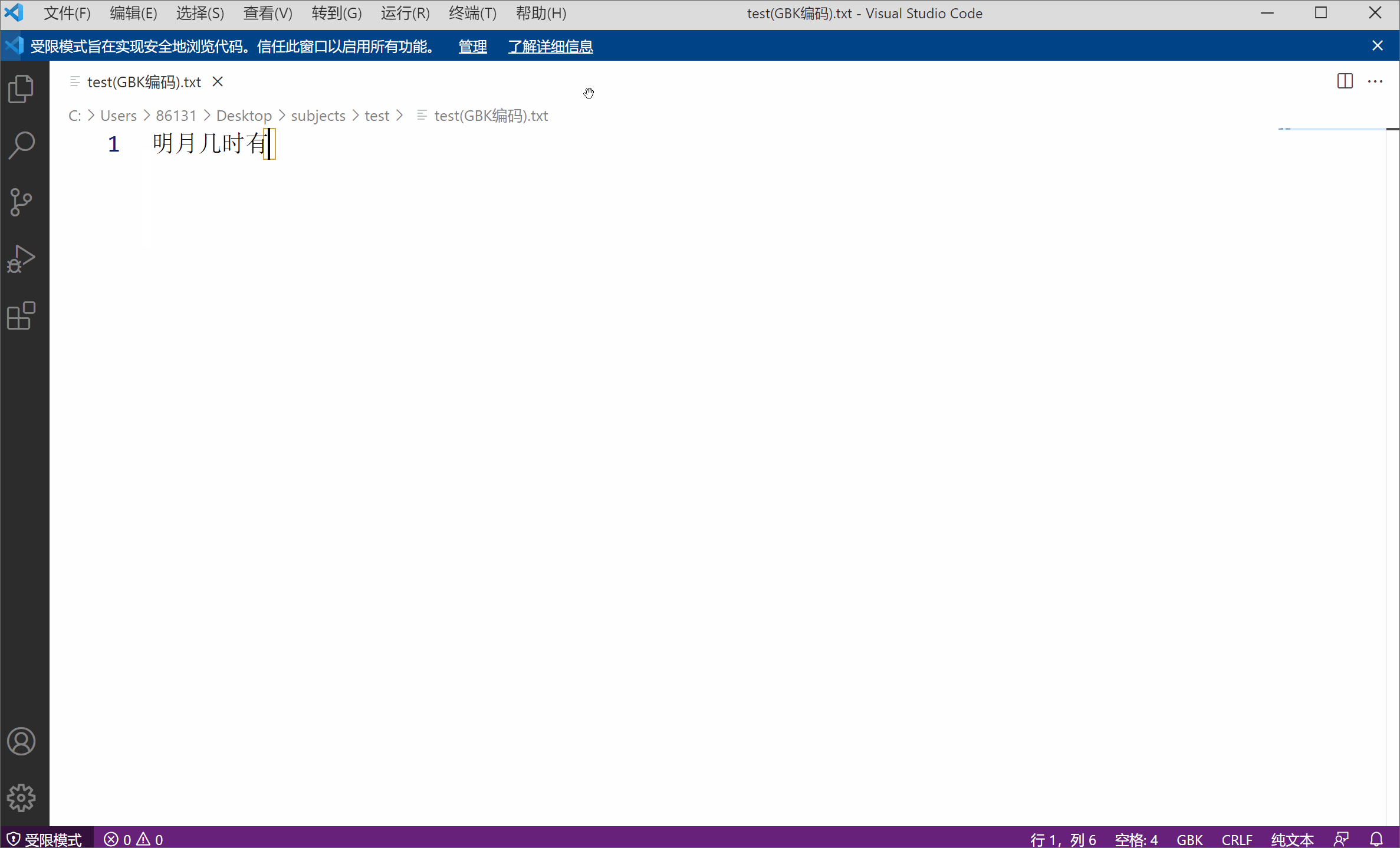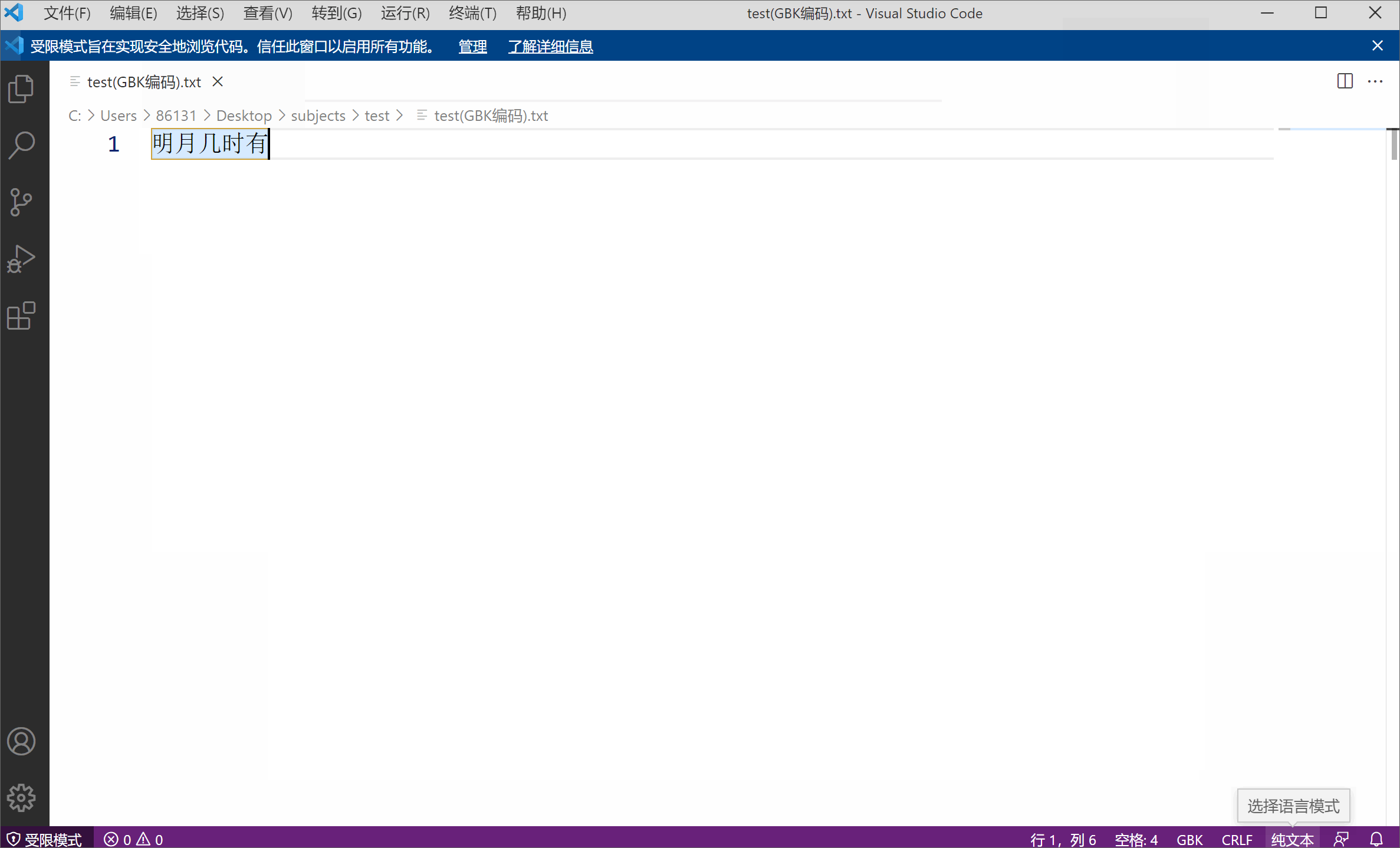
Watak yang bercelaru juga menggambarkan dari sisi bahawa pengekodan aksara bukanlah atribut yang wujud pada fail.
Saya telah banyak bercakap hanya untuk menggambarkan perkara ini: Pengekodan aksara ialah peraturan yang digunakan semasa penyahkodan dan pengekodan, bukan atribut yang wujud pada fail.
Saya tidak dapat membantu tetapi tertanya-tanya, mengapa pengekodan aksara tidak ditetapkan sebagai sebahagian daripada sifat fail?
Andaikan ia boleh ditetapkan dan ditetapkan kepada GBK, maka sistem pengendalian perlu mengekalkan fungsi tersebut. Sama seperti fail tidak boleh ditulis, jika program cuba menulis ke fail, sistem pengendalian akan menolak untuk menulis bait yang mesti ditulis oleh sistem pengendalian mesti memenuhi keperluan pengekodan GBK keperluan sistem pengendalian Memeriksa kesahihan bait memerlukan banyak overhed prestasi, malah mustahil untuk dilaksanakan, kerana sesetengah bait khas boleh mewakili sama ada GBK atau UTF-8, yang tidak jelas. Sekarang, apa gunanya melakukan ini? Adakah ia supaya editor boleh memilih pengekodan yang betul berdasarkan sifat pengekodan semasa membuka fail? Tidak perlu seorang editor pintar boleh membuat kesimpulan tentang pengekodan rentetan 01 anda berdasarkan beberapa bait pertama kandungan. Selain itu, anda juga boleh menetapkan pengekodan aksara yang digunakan untuk penyahkodan secara manual.
3. Penyelesaian Masalah
Apabila mencipta fail, pengekodan fail tidak boleh ditentukan. Apabila menulis teks pada fail (seperti Ctrl S menyimpan dalam editor teks, yang pada asasnya menjalankan operasi menulis), anda boleh memilih untuk menukar teks kepada peraturan pengekodan rentetan 01.
Untuk program Java, kodnya adalah seperti berikut, iaitu kod yang disebut pada permulaan artikel:
FileInputStream fis=new FileInputStream(“xxxx.txt”); OutputStreamWriter osw=new OutputStreamWriter(fis,“UTF-8”);
Pembelajaran yang disyorkan: "tutorial video java "
Atas ialah kandungan terperinci Kaedah pelaksanaan Java untuk menentukan pengekodan semasa membuat fail. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1376
1376
 52
52

 Akar Kuasa Dua di Jawa
Aug 30, 2024 pm 04:26 PM
Akar Kuasa Dua di Jawa
Aug 30, 2024 pm 04:26 PM
Panduan untuk Square Root di Java. Di sini kita membincangkan cara Square Root berfungsi di Java dengan contoh dan pelaksanaan kodnya masing-masing.
 Nombor Sempurna di Jawa
Aug 30, 2024 pm 04:28 PM
Nombor Sempurna di Jawa
Aug 30, 2024 pm 04:28 PM
Panduan Nombor Sempurna di Jawa. Di sini kita membincangkan Definisi, Bagaimana untuk menyemak nombor Perfect dalam Java?, contoh dengan pelaksanaan kod.
 Penjana Nombor Rawak di Jawa
Aug 30, 2024 pm 04:27 PM
Penjana Nombor Rawak di Jawa
Aug 30, 2024 pm 04:27 PM
Panduan untuk Penjana Nombor Rawak di Jawa. Di sini kita membincangkan Fungsi dalam Java dengan contoh dan dua Penjana berbeza dengan contoh lain.
 Weka di Jawa
Aug 30, 2024 pm 04:28 PM
Weka di Jawa
Aug 30, 2024 pm 04:28 PM
Panduan untuk Weka di Jawa. Di sini kita membincangkan Pengenalan, cara menggunakan weka java, jenis platform, dan kelebihan dengan contoh.
 Nombor Smith di Jawa
Aug 30, 2024 pm 04:28 PM
Nombor Smith di Jawa
Aug 30, 2024 pm 04:28 PM
Panduan untuk Nombor Smith di Jawa. Di sini kita membincangkan Definisi, Bagaimana untuk menyemak nombor smith di Jawa? contoh dengan pelaksanaan kod.
 Soalan Temuduga Java Spring
Aug 30, 2024 pm 04:29 PM
Soalan Temuduga Java Spring
Aug 30, 2024 pm 04:29 PM
Dalam artikel ini, kami telah menyimpan Soalan Temuduga Spring Java yang paling banyak ditanya dengan jawapan terperinci mereka. Supaya anda boleh memecahkan temuduga.
 Cuti atau kembali dari Java 8 Stream Foreach?
Feb 07, 2025 pm 12:09 PM
Cuti atau kembali dari Java 8 Stream Foreach?
Feb 07, 2025 pm 12:09 PM
Java 8 memperkenalkan API Stream, menyediakan cara yang kuat dan ekspresif untuk memproses koleksi data. Walau bagaimanapun, soalan biasa apabila menggunakan aliran adalah: bagaimana untuk memecahkan atau kembali dari operasi foreach? Gelung tradisional membolehkan gangguan awal atau pulangan, tetapi kaedah Foreach Stream tidak menyokong secara langsung kaedah ini. Artikel ini akan menerangkan sebab -sebab dan meneroka kaedah alternatif untuk melaksanakan penamatan pramatang dalam sistem pemprosesan aliran. Bacaan Lanjut: Penambahbaikan API Java Stream Memahami aliran aliran Kaedah Foreach adalah operasi terminal yang melakukan satu operasi pada setiap elemen dalam aliran. Niat reka bentuknya adalah
 TimeStamp to Date in Java
Aug 30, 2024 pm 04:28 PM
TimeStamp to Date in Java
Aug 30, 2024 pm 04:28 PM
Panduan untuk TimeStamp to Date di Java. Di sini kita juga membincangkan pengenalan dan cara menukar cap waktu kepada tarikh dalam java bersama-sama dengan contoh.
