

Mari kita bercakap tentang struktur indeks MySQL


Pembelajaran yang disyorkan: tutorial video mysql
Pengenalan
Selain data, sistem pangkalan data juga mengekalkan Struktur data yang memenuhi algoritma carian tertentu Struktur data ini merujuk (menunjukkan) data dalam beberapa cara supaya algoritma carian lanjutan boleh dilaksanakan pada struktur data ini. Struktur data ini ialah indeks.
Secara umumnya, indeks itu sendiri juga sangat besar dan tidak boleh disimpan sepenuhnya dalam ingatan, jadi indeks selalunya disimpan pada cakera dalam bentuk fail indeks.
Kelebihan:
1 Sama seperti membina indeks bibliografi di perpustakaan universiti, ia meningkatkan kecekapan pengambilan data dan mengurangkan kos IO pangkalan data.
2. Isih data melalui lajur indeks untuk mengurangkan kos pengisihan data dan mengurangkan penggunaan CPU.
Kelemahan:
1 Walaupun indeks sangat meningkatkan kelajuan pertanyaan, ia juga mengurangkan kelajuan mengemas kini jadual, seperti INSERT, UPDATE dan DELETE pada jadual. Kerana semasa mengemas kini jadual, MySQL bukan sahaja perlu menyimpan data, tetapi juga menyimpan fail indeks. Setiap kali medan yang menambah lajur indeks dikemas kini, maklumat indeks selepas perubahan nilai utama yang disebabkan oleh kemas kini akan dilaraskan.
2 Malah, indeks juga merupakan jadual yang menyimpan kunci utama dan medan indeks dan menunjuk ke rekod jadual entiti, jadi lajur indeks juga mengambil ruang
Contoh indeks: ( Gunakan struktur pokok sebagai indeks)
Sebelah kiri ialah jadual data, dengan jumlah dua lajur dan tujuh rekod yang paling kiri ialah alamat fizikal rekod data.
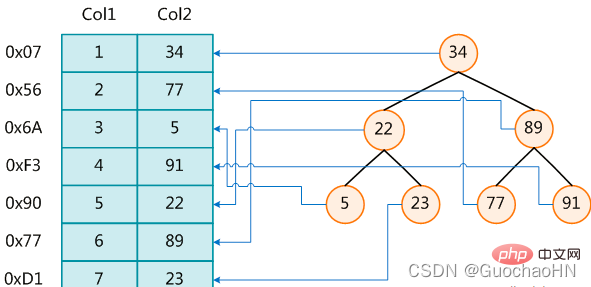
Untuk mempercepatkan carian Col2, anda boleh mengekalkan pepohon carian binari seperti yang ditunjukkan di sebelah kanan Setiap nod mengandungi nilai kunci indeks dan penunjuk ke alamat fizikal rekod data yang sepadan, supaya anda boleh menggunakan carian binari untuk mendapatkan data yang sepadan dalam kerumitan tertentu, dengan itu cepat mendapatkan semula rekod yang memenuhi syarat.
Struktur indeks (pokok)
Bagaimana untuk mempercepatkan kelajuan pertanyaan jadual pangkalan data melalui indeks? Untuk kemudahan penjelasan, kami mengehadkan jadual pangkalan data untuk hanya memasukkan dua keperluan pertanyaan berikut:
1 pilih* daripada pengguna di mana id=1234
2. pilih *daripada pengguna di mana id>1234 dan id<2345; (mengikut selang)
Mengapa menggunakan pokok dan bukannya jadual cincang
Ha Prestasi pertanyaan jadual Greek mengikut nilai adalah sangat baik, dan kerumitan masa ialah O(1), tetapi ia tidak dapat menyokong carian pantas data mengikut selang waktu, jadi ia tidak dapat memenuhi keperluan. Dengan cara yang sama, walaupun prestasi pertanyaan bagi pepohon carian binari seimbang adalah sangat tinggi, kerumitan masa adalah O(logn), dan traversal tertib pepohon boleh mengeluarkan urutan data yang tersusun, ia tidak dapat memenuhi keperluan untuk cepat mencari data mengikut selang .
Untuk menyokong carian pantas data mengikut selang waktu, kami mengubah pepohon carian binari dan merangkai nod daun pepohon carian perduaan dengan senarai terpaut Jika anda ingin mencari data dalam selang waktu tertentu, anda hanya perlu menggunakan selang Nilai permulaan dicari dalam pepohon Selepas mengesan nod dalam senarai terpaut tersusun, ia bermula dari nod ini dan merentasi sepanjang senarai terpaut tersusun sehingga nilai data nod dalam senarai terpaut tersusun lebih besar. daripada nilai akhir selang sehingga.
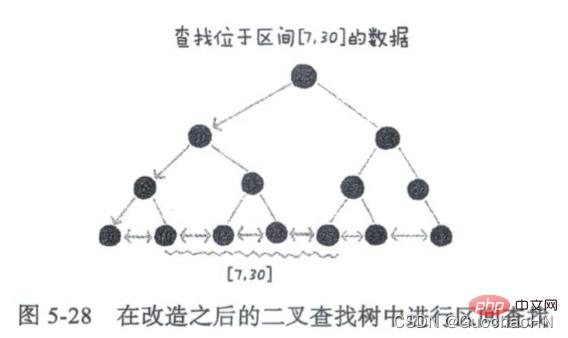
Dan kerana kerumitan masa banyak operasi pada pokok adalah berkadar dengan ketinggian pokok, mengurangkan ketinggian pokok boleh mengurangkan operasi cakera IO. Oleh itu, kami membina indeks menjadi pokok m-ary (m>2). Sila lihat artikel berikut untuk mendapatkan butiran.
Indeks BTree
Sebelum memperkenalkan B-tree, mari kita fahami B-tree dahulu.
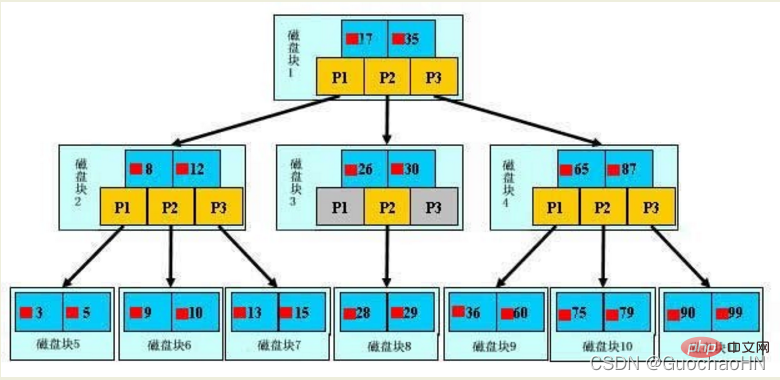
1. Pengenalan Permulaan
B-tree, blok biru muda dipanggil blok cakera, anda boleh melihat setiap blok cakera Mengandungi beberapa item data (ditunjukkan dalam warna biru tua) dan penunjuk (ditunjukkan dalam warna kuning Sebagai contoh, blok cakera 1 mengandungi item data 17 dan 35, dan mengandungi penunjuk P1, P2, dan P3. P1 mewakili blok cakera kurang daripada 17, P2 mewakili blok cakera antara 17 dan 35, dan P3 mewakili blok cakera lebih daripada 35.
Nota:
Data sebenar hanya wujud dalam nod daun iaitu 3, 5, 9, 10, 13, 15, 28, 29, 36, 60, 75, 79, 90, 99 . (Dan ia adalah selang data yang terdiri daripada berbilang keping data: 3~5,...,90~99)
Nod bukan daun tidak menyimpan data sebenar, tetapi hanya menyimpan item data yang membimbing arah carian, seperti 17, 35 sebenarnya tidak wujud dalam helaian data.
2. Proses carian
Jika anda ingin mencari item data 29, anda akan memuatkan blok cakera 1 dari cakera ke memori Pada masa ini, IO berlaku Gunakan carian binari dalam memori untuk menentukan bahawa 29 adalah antara 17 dan 35 , dan kunci P2 blok cakera 1. Penunjuk, masa ingatan boleh diabaikan kerana ia sangat singkat (berbanding cakera IO blok cakera 3 dimuatkan dari cakera ke memori melalui alamat cakera penunjuk P2 blok cakera). 1. IO kedua berlaku, 29 antara 26 dan 30. Dalam tempoh tersebut, penunjuk P2 blok cakera 3 dikunci, dan blok cakera 8 dimuatkan ke dalam memori melalui penunjuk IO ketiga berlaku. carian binari dilakukan dalam ingatan untuk mencari 29, dan pertanyaan ditamatkan sebanyak tiga IO.
Indeks Pokok B
Pokok B serupa dengan pokok B dan pokok B ialah versi pokok B yang dipertingkatkan. Iaitu: pokok yang dibina oleh pokok carian m-fork dan senarai terpaut tersusun ialah B-tree, iaitu indeks pokok untuk disimpan
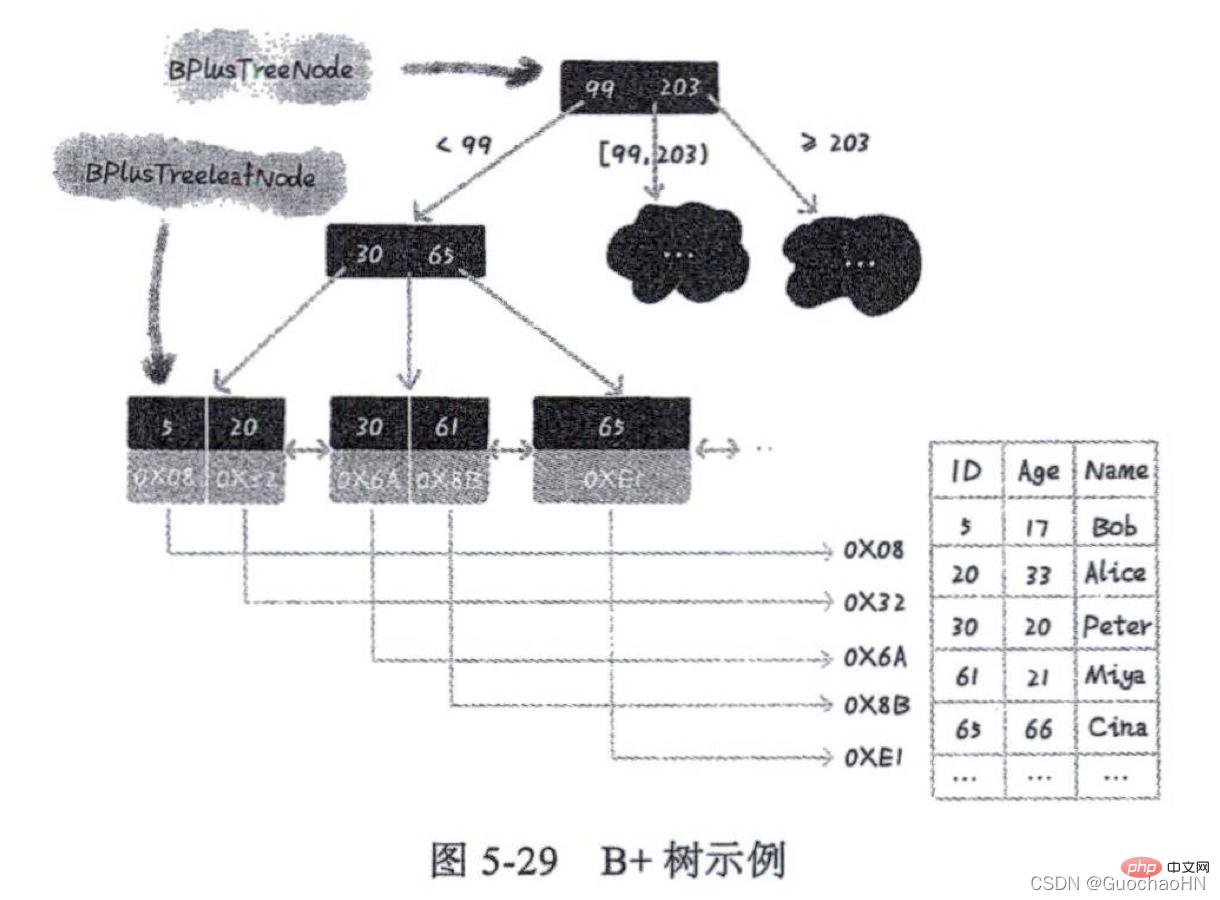
seperti yang ditunjukkan dalam rajah: B-tree dan ciri-ciri utama B-tree Perbezaannya adalah seperti berikut:
1. Nod daun bagi B-tree disambung secara bersiri menggunakan senarai terpaut. Untuk mencari data dalam selang tertentu, anda hanya perlu menggunakan nilai permulaan selang untuk mencari dalam pepohon Selepas mengesan nod dalam senarai terpaut tersusun, mulakan dari nod ini dan melintasi senarai terpaut tersusun ke belakang sehingga Sehingga nod. nilai data dalam senarai terpaut tersusun adalah lebih besar daripada nilai akhir selang.
2. Mana-mana nod dalam B-tree tidak menyimpan data sebenar, tetapi hanya digunakan untuk pengindeksan. B-tree memperoleh data secara langsung melalui nod daun; dan setiap nod daun B-tree menyimpan nilai utama dan maklumat alamat baris data Apabila nod daun tertentu ditanya, maklumat data sebenar ditemui melalui alamat daun nod.
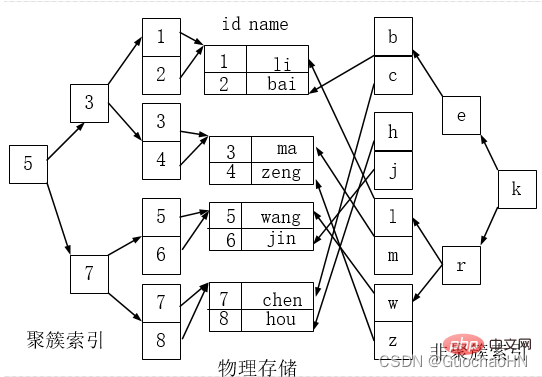
Indeks berkelompok dan indeks tidak berkelompok
Indeks berkelompok bukan jenis indeks yang berasingan, tetapi kaedah penyimpanan data. Istilah 'berkelompok' bermaksud bahawa baris data disimpan bersama dengan kelompok nilai kunci bersebelahan.
Faedah indeks berkelompok:
Mengikut susunan indeks berkelompok, apabila membuat pertanyaan untuk memaparkan julat data tertentu, kerana data bersambung rapat, pangkalan data tidak perlu mengekstrak daripada berbilang data menyekat data, jadi ia menjimatkan banyak operasi io.
Batasan indeks berkelompok:
1 Untuk pangkalan data mysql, pada masa ini hanya enjin data innodb menyokong indeks berkelompok, manakala Myisam tidak menyokong indeks berkelompok.
2. Memandangkan hanya terdapat satu kaedah pengisihan storan fizikal untuk data, setiap jadual Mysql hanya boleh mempunyai satu indeks berkelompok. Biasanya ia adalah kunci utama jadual.
3 Untuk menggunakan sepenuhnya ciri pengelompokan indeks berkelompok, lajur kunci utama jadual innodb harus cuba menggunakan ID urutan tersusun dan tidak disyorkan untuk menggunakan ID tidak tertib, seperti sebagai uuid.
Seperti yang ditunjukkan di bawah, indeks di sebelah kiri ialah indeks berkelompok, kerana susunan baris data pada cakera adalah konsisten dengan pengisihan indeks.
Klasifikasi indeks
Indeks nilai tunggal
Iaitu, indeks hanya mengandungi satu lajur dan jadual boleh mempunyai berbilang tunggal -indeks lajur
随表一起建索引: CREATE TABLE customer ( id INT(10) UNSIGNED AUTO_INCREMENT , customer_no VARCHAR(200), customer_name VARCHAR(200), PRIMARY KEY(id), KEY (customer_name) ); 单独建单值索引: CREATE INDEX idx_customer_name ON customer(customer_name); 删除索引: DROP INDEX idx_customer_name on customer;
Indeks unik
Nilai lajur indeks mestilah unik, tetapi nilai null dibenarkan
随表一起建索引: CREATE TABLE customer ( id INT(10) UNSIGNED AUTO_INCREMENT , customer_no VARCHAR(200), customer_name VARCHAR(200), PRIMARY KEY(id), KEY (customer_name), UNIQUE (customer_no) ); 单独建唯一索引: CREATE UNIQUE INDEX idx_customer_no ON customer(customer_no); 删除索引: DROP INDEX idx_customer_no on customer ;
Indeks kunci utama
Selepas menetapkan kunci utama kepada pangkalan data Indeks akan dibuat secara automatik Innodb ialah indeks berkelompok
随表一起建索引: CREATE TABLE customer ( id INT(10) UNSIGNED AUTO_INCREMENT , customer_no VARCHAR(200), customer_name VARCHAR(200), PRIMARY KEY(id) ); CREATE TABLE customer2 ( id INT(10) UNSIGNED , customer_no VARCHAR(200), customer_name VARCHAR(200), PRIMARY KEY(id) ); 单独建主键索引: ALTER TABLE customer add PRIMARY KEY customer(customer_no); 删除建主键索引: ALTER TABLE customer drop PRIMARY KEY ; 修改建主键索引: 必须先删除掉(drop)原索引,再新建(add)索引
indeks kompaun
, iaitu indeks mengandungi berbilang. lajur
随表一起建索引: CREATE TABLE customer ( id INT(10) UNSIGNED AUTO_INCREMENT , customer_no VARCHAR(200), customer_name VARCHAR(200), PRIMARY KEY(id), KEY (customer_name), UNIQUE (customer_name), KEY (customer_no,customer_name) ); 单独建索引: CREATE INDEX idx_no_name ON customer(customer_no,customer_name); 删除索引: DROP INDEX idx_no_name on customer ;
analisis prestasi
Senario penciptaan indeks
Dalam kes yang mana adalah perlu untuk mencipta indeks
1 . Kunci utama secara automatik mencipta indeks unik
2 Medan yang kerap digunakan sebagai syarat pertanyaan harus dibuat Indeks
3 hubungan
4. Pilihan kunci tunggal/indeks gabungan, indeks gabungan lebih menjimatkan kos
5. Jika medan pengisihan diakses melalui indeks, kelajuan pengisihan akan dipertingkatkan dengan baik
6 Statistik atau medan kumpulan dalam pertanyaan
Dalam keadaan apa tidak mencipta indeks
1 >
2. Jadual atau medan yang kerap ditambah, dipadam atau diubah suai Sebab: Ia meningkatkan kelajuan pertanyaan, tetapi pada masa yang sama mengurangkan kelajuan mengemas kini jadual, seperti INSERT, UPDATE dan DELETE pada jadual. Kerana semasa mengemas kini jadual, MySQL bukan sahaja perlu menyimpan data, tetapi juga fail indeks 3. Tiada indeks akan dibuat untuk medan yang tidak digunakan dalam keadaan Where 4 . Prestasi penapisan tidak bagus Sesuai untuk pembinaan indeks Pembelajaran yang disyorkan:Atas ialah kandungan terperinci Mari kita bercakap tentang struktur indeks MySQL. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

Video Face Swap
Tukar muka dalam mana-mana video dengan mudah menggunakan alat tukar muka AI percuma kami!

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas



 Cara membuka phpmyadmin
Apr 10, 2025 pm 10:51 PM
Cara membuka phpmyadmin
Apr 10, 2025 pm 10:51 PM
Anda boleh membuka phpmyadmin melalui langkah -langkah berikut: 1. Log masuk ke panel kawalan laman web; 2. Cari dan klik ikon phpmyadmin; 3. Masukkan kelayakan MySQL; 4. Klik "Login".
 MySQL: Pengenalan kepada pangkalan data paling popular di dunia
Apr 12, 2025 am 12:18 AM
MySQL: Pengenalan kepada pangkalan data paling popular di dunia
Apr 12, 2025 am 12:18 AM
MySQL adalah sistem pengurusan pangkalan data relasi sumber terbuka, terutamanya digunakan untuk menyimpan dan mengambil data dengan cepat dan boleh dipercayai. Prinsip kerjanya termasuk permintaan pelanggan, resolusi pertanyaan, pelaksanaan pertanyaan dan hasil pulangan. Contoh penggunaan termasuk membuat jadual, memasukkan dan menanyakan data, dan ciri -ciri canggih seperti Operasi Join. Kesalahan umum melibatkan sintaks SQL, jenis data, dan keizinan, dan cadangan pengoptimuman termasuk penggunaan indeks, pertanyaan yang dioptimumkan, dan pembahagian jadual.
 Tempat Mysql: Pangkalan Data dan Pengaturcaraan
Apr 13, 2025 am 12:18 AM
Tempat Mysql: Pangkalan Data dan Pengaturcaraan
Apr 13, 2025 am 12:18 AM
Kedudukan MySQL dalam pangkalan data dan pengaturcaraan sangat penting. Ia adalah sistem pengurusan pangkalan data sumber terbuka yang digunakan secara meluas dalam pelbagai senario aplikasi. 1) MySQL menyediakan fungsi penyimpanan data, organisasi dan pengambilan data yang cekap, sistem sokongan web, mudah alih dan perusahaan. 2) Ia menggunakan seni bina pelanggan-pelayan, menyokong pelbagai enjin penyimpanan dan pengoptimuman indeks. 3) Penggunaan asas termasuk membuat jadual dan memasukkan data, dan penggunaan lanjutan melibatkan pelbagai meja dan pertanyaan kompleks. 4) Soalan -soalan yang sering ditanya seperti kesilapan sintaks SQL dan isu -isu prestasi boleh disahpepijat melalui arahan jelas dan log pertanyaan perlahan. 5) Kaedah pengoptimuman prestasi termasuk penggunaan indeks rasional, pertanyaan yang dioptimumkan dan penggunaan cache. Amalan terbaik termasuk menggunakan urus niaga dan preparedStatemen
 Mengapa menggunakan mysql? Faedah dan kelebihan
Apr 12, 2025 am 12:17 AM
Mengapa menggunakan mysql? Faedah dan kelebihan
Apr 12, 2025 am 12:17 AM
MySQL dipilih untuk prestasi, kebolehpercayaan, kemudahan penggunaan, dan sokongan komuniti. 1.MYSQL Menyediakan fungsi penyimpanan dan pengambilan data yang cekap, menyokong pelbagai jenis data dan operasi pertanyaan lanjutan. 2. Mengamalkan seni bina pelanggan-pelayan dan enjin penyimpanan berganda untuk menyokong urus niaga dan pengoptimuman pertanyaan. 3. Mudah digunakan, menyokong pelbagai sistem operasi dan bahasa pengaturcaraan. 4. Mempunyai sokongan komuniti yang kuat dan menyediakan sumber dan penyelesaian yang kaya.
 Cara menyambung ke pangkalan data Apache
Apr 13, 2025 pm 01:03 PM
Cara menyambung ke pangkalan data Apache
Apr 13, 2025 pm 01:03 PM
Apache menyambung ke pangkalan data memerlukan langkah -langkah berikut: Pasang pemacu pangkalan data. Konfigurasikan fail web.xml untuk membuat kolam sambungan. Buat sumber data JDBC dan tentukan tetapan sambungan. Gunakan API JDBC untuk mengakses pangkalan data dari kod Java, termasuk mendapatkan sambungan, membuat kenyataan, parameter mengikat, melaksanakan pertanyaan atau kemas kini, dan hasil pemprosesan.
 Cara Memulakan MySQL oleh Docker
Apr 15, 2025 pm 12:09 PM
Cara Memulakan MySQL oleh Docker
Apr 15, 2025 pm 12:09 PM
Proses memulakan MySQL di Docker terdiri daripada langkah -langkah berikut: Tarik imej MySQL untuk membuat dan memulakan bekas, tetapkan kata laluan pengguna root, dan memetakan sambungan pengesahan port Buat pangkalan data dan pengguna memberikan semua kebenaran ke pangkalan data
 Peranan MySQL: Pangkalan Data dalam Aplikasi Web
Apr 17, 2025 am 12:23 AM
Peranan MySQL: Pangkalan Data dalam Aplikasi Web
Apr 17, 2025 am 12:23 AM
Peranan utama MySQL dalam aplikasi web adalah untuk menyimpan dan mengurus data. 1.MYSQL dengan cekap memproses maklumat pengguna, katalog produk, rekod urus niaga dan data lain. 2. Melalui pertanyaan SQL, pemaju boleh mengekstrak maklumat dari pangkalan data untuk menghasilkan kandungan dinamik. 3.MYSQL berfungsi berdasarkan model klien-pelayan untuk memastikan kelajuan pertanyaan yang boleh diterima.
 CentOS memasang MySQL
Apr 14, 2025 pm 08:09 PM
CentOS memasang MySQL
Apr 14, 2025 pm 08:09 PM
Memasang MySQL pada CentOS melibatkan langkah -langkah berikut: Menambah sumber MySQL YUM yang sesuai. Jalankan YUM Pasang Perintah MySQL-Server untuk memasang pelayan MySQL. Gunakan perintah mysql_secure_installation untuk membuat tetapan keselamatan, seperti menetapkan kata laluan pengguna root. Sesuaikan fail konfigurasi MySQL seperti yang diperlukan. Tune parameter MySQL dan mengoptimumkan pangkalan data untuk prestasi.
