
 pangkalan data
tutorial mysql
Mari kita bincangkan tentang cara mengoptimumkan perintah Mengikut pernyataan dalam SQL
pangkalan data
tutorial mysql
Mari kita bincangkan tentang cara mengoptimumkan perintah Mengikut pernyataan dalam SQL
Mari kita bincangkan tentang cara mengoptimumkan perintah Mengikut pernyataan dalam SQL

Bagaimana untuk mengoptimumkan pernyataan orderBy dalam sql? Artikel berikut akan memperkenalkan kepada anda kaedah mengoptimumkan pernyataan orderBy dalam SQL Ia mempunyai nilai rujukan yang baik dan saya harap ia akan membantu anda.

Apabila menggunakan pangkalan data untuk pertanyaan data, anda pasti akan menghadapi keperluan untuk mengisih set hasil pertanyaan berdasarkan medan tertentu. Dalam sql, pernyataan orderby biasanya digunakan untuk mencapai ini. Letakkan medan yang perlu diisih selepas kata kunci Jika terdapat berbilang medan, gunakan "," untuk memisahkannya.
select * from table t order by t.column1,t.column2;
Sql di atas menunjukkan pertanyaan data dalam jadual, dan kemudian mengisihnya mengikut lajur 1. Jika lajur 1 adalah sama, ia akan diisih mengikut lajur 2. Kaedah pengisihan lalai ialah tertib menurun . Sudah tentu, kaedah pengisihan juga boleh ditentukan. Tambahkan DESC dan ASE selepas medan diisih untuk menunjukkan susunan menurun dan menaik masing-masing.
Menggunakan orderby ini boleh melaksanakan operasi pengisihan harian dengan mudah. Saya telah banyak menggunakannya, dan saya tidak tahu sama ada anda pernah menghadapi senario ini: Kadang-kadang selepas menggunakan orderby, kecekapan pelaksanaan SQL adalah sangat perlahan, dan kadang-kadang ia lebih pantas Memandangkan saya taksub dengan dadih sepanjang hari, Saya tidak mempunyai masa untuk mengkajinya, saya hanya merasakan Ia menakjubkan. Sementara saya bebas hujung minggu ini, mari kita kaji bagaimana orderby dilaksanakan dalam mysql.
Untuk kemudahan penerangan, kami mula-mula membuat jadual data t1, seperti berikut:
CREATE TABLE `t1` ( `id` int(11) NOT NULL not null auto_increment, `a` int(11) DEFAULT NULL, `b` int(11) DEFAULT NULL, `c` int(11) DEFAULT NULL, PRIMARY KEY (`id`) , KEY `a` (`a`) USING BTREE ) ENGINE=InnoDB;
dan masukkan data:
insert into t1 (a,b,c) values (1,1,3); insert into t1 (a,b,c) values (1,4,5); insert into t1 (a,b,c) values (1,3,3); insert into t1 (a,b,c) values (1,3,4); insert into t1 (a,b,c) values (1,2,5); insert into t1 (a,b,c) values (1,3,6);
Untuk membuat indeks berkesan, masukkan 10,000 baris 7, 7, 7, data yang tidak berkaitan, apabila jumlah data adalah kecil, keseluruhan jadual akan diimbas terus
insert into t1 (a,b,c) values (7,7,7);
Kita kini perlu mencari semua rekod dengan a= 1, dan kemudian isikannya mengikut medan b.
Sql pertanyaan ialah
select a,b,c from t1 where a = 1 order by b limit 2;
Untuk mengelakkan imbasan jadual penuh semasa proses pertanyaan, kami menambah indeks pada medan a.
Mula-mula kita semak pelan pelaksanaan sql melalui pernyataan
explain select a,b,c from t1 where a = 1 order by b lmit 2;
, seperti yang ditunjukkan di bawah:

Selain itu kami boleh Anda lihat Menggunakan filesort Ini bermakna bahawa semasa pelaksanaan sql, operasi pengisihan diselesaikan dalam sort_buffer ialah penimbal memori yang diperuntukkan oleh mysql ini digunakan khas untuk menyelesaikan pengisihan saiz lalai ialah 1M, dan saiznya dikawal oleh pembolehubah sort_buffer_size.
Apabila mysql melaksanakan orderby, ia melaksanakan dua kaedah berbeza mengikut kandungan medan yang dimasukkan ke dalam sort_buffer: pengisihan medan penuh dan pengisihan rowid.
Isih medan penuh
Pertama sekali, mari kita lihat proses pelaksanaan SQL secara keseluruhan melalui gambar:
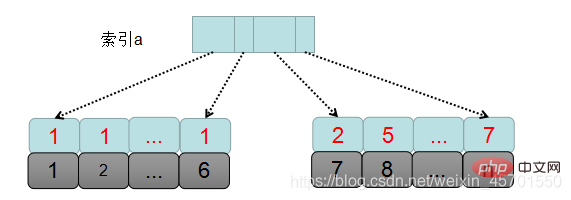
mysql pertama kali ditentukan berdasarkan syarat pertanyaan Set data yang perlu diisih ialah set data dengan a=1 dalam jadual, iaitu rekod dengan ID kunci utama dari 1 hingga 6.
Keseluruhan proses pelaksanaan SQL adalah seperti berikut:
1 Cipta dan mulakan sort_buffer, dan tentukan medan yang perlu diletakkan dalam penimbal, iaitu, a, b ,c ketiga-tiga medan ini.
2 Cari id kunci utama pertama yang memenuhi a=1 daripada pokok indeks a, iaitu, id=1.
3 Kembali ke jadual ke indeks id, keluarkan seluruh baris data, dan kemudian keluarkan nilai a, b, c daripada seluruh baris data dan letakkannya ke dalam sort_buffer.
4 Cari id kunci utama seterusnya bagi a=1 mengikut urutan daripada indeks a.
5 Ulang langkah 3 dan 4 sehingga rekod terakhir dengan a=1 diperolehi, iaitu kunci utama id=5.
6 Pada masa ini, medan a, b, dan c bagi semua rekod yang memenuhi syarat a=1 semuanya dibaca dan dimasukkan ke dalam sort_buffer Kemudian, data ini diisih mengikut nilai b Kaedah pengisihan ialah Isih Pantas. Ia adalah jenis cepat yang sering ditemui dalam temu bual, dan kerumitan masa isihan pantas ialah log2n.
7. Kemudian keluarkan 2 baris pertama data daripada set hasil yang diisih.
Di atas adalah proses pelaksanaan orderby dalam msql. Oleh kerana data yang dimasukkan ke dalam sort_buffer ialah semua medan yang perlu dikeluarkan, pengisihan ini dipanggil pengisihan penuh.
Saya tertanya-tanya adakah anda mempunyai sebarang soalan selepas melihat ini? Apakah yang perlu saya lakukan jika jumlah data yang perlu diisih adalah besar dan sort_buffer tidak dapat dimuatkan di dalamnya?
Sememangnya, jika terdapat banyak baris data dengan a=1, dan terdapat banyak medan yang perlu disimpan dalam sort_buffer, mungkin terdapat lebih daripada tiga medan a, b dan c mungkin perlu mengeluarkan lebih banyak medan. Kemudian sort_buffer dengan saiz lalai hanya 1M mungkin tidak dapat menampungnya.
Apabila sort_buffer tidak dapat menampungnya, mysql akan mencipta sekumpulan fail cakera sementara untuk membantu pengisihan. Secara lalai, 12 fail sementara akan dibuat, dan data yang akan diisih akan dibahagikan kepada 12 bahagian Setiap bahagian akan diisih secara berasingan untuk membentuk 12 fail yang dipesan data dalaman, dan kemudian 12 fail yang dipesan ini akan digabungkan menjadi fail yang dipesan. . Fail besar, dan akhirnya selesaikan pengisihan data.
Pengisihan berasaskan fail adalah kurang cekap daripada pengisihan berasaskan memori Untuk meningkatkan kecekapan pengisihan, pengisihan berasaskan fail harus dielakkan sebanyak mungkin. Untuk mengelakkan pengisihan berasaskan fail, anda perlu melakukannya sort_buffer Menampung jumlah data yang perlu diisih.
Jadi mysql telah dioptimumkan untuk situasi di mana sort_buffer tidak dapat menampungnya. Ia adalah untuk mengurangkan bilangan medan yang disimpan dalam sort_buffer semasa pengisihan.
Kaedah pengoptimuman khusus ialah pengisihan barisId berikut
RowId 排序
在全字段排序实现中,排序的过程中,要把需要输出的字段全部放到sort_buffer中,当输出的字段比较多的时候,可以放到sort_buffer中的数据行就会变少。也就增大了sort_buffer无法容纳数据的风险,直至出现基于文件的排序。
rowId排序对全字段排序的优化手段,主要是减少了放到sort_buffer中字段个数。
在rowId排序中,只会将需要排序的字段和主键Id放到sort_buffer中。
select a,b,c from t1 where a = 1 order by b limit 2;
在rowId的排序中的执行流程如下:
1.初始化并创建sort_buffer,并确认要放入的的字段,id和b。
2.从索引树a中找到第一个满足a=1的主键id,也就是id=1。
3.回表主键索引id,取出整行数据,从整行数据中取出id和b,存入sort_buffer中。
4.从索引a中取出下一条满足a=1的 记录的主键id。
5.重复步骤3和4,直到最后一个满足a=1的主键id,也就是a=6。
6.对sort_buffer中的数据,按照字段b排序。
7.从sort_buffer中的有序数据集中,取出前2个,因为此时取出的数据只有id和b,要想获取a和c字段,需要根据id字段,回表到主键索引中取出整行数据,从整行数据中获取需要的数据。
根据rowId排序的执行步骤,可以发现:相比全字段排序,rowId排序的实现方式,减少了存放到sort_buffer中的数据量,降低了基于文件的外部排序的可能性。
那rowid排序有不足的地方吗?肯定有的,要不然全字段排序就没有存在的意义了。rowid排序不足之处在于,在最后的步骤7中,增加了回表的次数,不过这个回表的次数,取决于limit后的值,如果返回的结果集比较小的话,回表的次数还是比较小的。
mysql是如何在全字段排序和rowId排序的呢?其实是根据存放的sort_buffer中每行字段的长度决定的,如果mysql认为每次放到sort_buffer中的数据量很大的话,那么就用rowId排序实现,否则使用全字段排序。那么多大算大呢?这个大小的阈值有一个变量的值来决定,这个变量就是 max_length_for_sort_data。如果每次放到sort_buffer中的数据大小大于该字段值的话,就使用rowId排序,否则使用全字段排序。
orderby的优化
上面讲述了orderby的两种排序的方式,以及一些优化策略,优化的目的主要就是避免基于磁盘文件的外部排序。因为基于磁盘文件的排序效率要远低于基于sort_buffer的内存排序。
但是当数据量比较大的时候,即使sort_buffer比较大,所有数据全部放在内存中排序,sql的整体执行效率也不高,因为排序这个操作,本身就是比较消耗性能的。
试想,如果基于索引a获取到所有a=1的数据,按照字段b,天然就是有序的,那么就不用执行排序操作,直接取出来的数据,就是符合结果的数据集,那么sql的执行效率就会大幅度增长。
其实要实现整个sql执行过程中,避免排序操作也不难,只需要创建一个a和b的联合索引即可。
alter table t1 add index a_b (a,b);
添加a和b的联合索引后,sql执行流程就变成了:
1.从索引树(a,b)中找到第一个满足a=1的主键id,也就是id=1。
2.回表到主键索引树,取出整行数据,并从中取出a,b,c,直接作为结果集的一部分返回。
3.从索引树(a,b)上取出下一个满足a=1的主键id。
4.重复步骤2和3,直到找到第二个满足a=1的主键id,并回表获取字段a,b,c。
此时我们可以通过查看sql的执行计划,来判断sql的执行过程中是否执行了排序操作。
explain select a,b from t1 where a = 1 order by b lmit 2;

通过查看执行计划,我们发现extra中已经没有了using filesort了,也就是没有执行排序操作了。
其实还可以通过覆盖索引,对该sql进一步优化,通过在索引中覆盖字段c,来避免回表的操作。
alter table t1 add index a_b_c (a,b,c);
添加索引a_b_c后,sql的执行过程如下:
1.从索引树(a,b,c)中找到第一个满足a=1的索引,从中取出a,b,c。直接作为结果集的一部分直接返回。
2.从索引(a,b,c)中取出下一个,满足a=1的记录作为结果集的一部分。
3.重复执行步骤2,直到查到第二个a=1或者不满足a=1的记录。
此时通过查看执行sql的的还行计划可以发现 extra中只有 Using index。
explain select a,b from t1 where a = 1 order by b lmit 2;

Ringkasan
Melalui pelbagai pengoptimuman sql ini, kecekapan pelaksanaan akhir sql pada asasnya adalah sama dengan kecekapan pertanyaan sql biasa tanpa pengisihan. Sebab mengapa operasi pengisihan tertib boleh dielakkan adalah untuk mengambil kesempatan daripada ciri-ciri tersusun secara semula jadi bagi indeks.
Tetapi kita semua tahu bahawa indeks boleh mempercepatkan kecekapan pertanyaan, tetapi kos penyelenggaraan indeks agak tinggi. Menambah dan mengubah suai data dalam jadual data akan melibatkan perubahan dalam indeks, jadi lebih banyak indeks, lebih baik. Kadangkala, menambah terlalu banyak indeks disebabkan oleh beberapa pertanyaan yang tidak biasa dan pengisihan tidak berbaloi.
[Cadangan berkaitan: tutorial video mysql]
Atas ialah kandungan terperinci Mari kita bincangkan tentang cara mengoptimumkan perintah Mengikut pernyataan dalam SQL. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1378
1378
 52
52

 Apakah perbezaan antara HQL dan SQL dalam rangka kerja Hibernate?
Apr 17, 2024 pm 02:57 PM
Apakah perbezaan antara HQL dan SQL dalam rangka kerja Hibernate?
Apr 17, 2024 pm 02:57 PM
HQL dan SQL dibandingkan dalam rangka kerja Hibernate: HQL (1. Sintaks berorientasikan objek, 2. Pertanyaan bebas pangkalan data, 3. Keselamatan jenis), manakala SQL mengendalikan pangkalan data secara langsung (1. Piawaian bebas pangkalan data, 2. Boleh laku kompleks pertanyaan dan manipulasi data).
 Penggunaan operasi bahagian dalam Oracle SQL
Mar 10, 2024 pm 03:06 PM
Penggunaan operasi bahagian dalam Oracle SQL
Mar 10, 2024 pm 03:06 PM
"Penggunaan Operasi Bahagian dalam OracleSQL" Dalam OracleSQL, operasi bahagi ialah salah satu operasi matematik yang biasa. Semasa pertanyaan dan pemprosesan data, operasi pembahagian boleh membantu kami mengira nisbah antara medan atau memperoleh hubungan logik antara nilai tertentu. Artikel ini akan memperkenalkan penggunaan operasi pembahagian dalam OracleSQL dan memberikan contoh kod khusus. 1. Dua cara operasi bahagi dalam OracleSQL Dalam OracleSQL, operasi bahagi boleh dilakukan dalam dua cara berbeza.
 Perbandingan dan perbezaan sintaks SQL antara Oracle dan DB2
Mar 11, 2024 pm 12:09 PM
Perbandingan dan perbezaan sintaks SQL antara Oracle dan DB2
Mar 11, 2024 pm 12:09 PM
Oracle dan DB2 ialah dua sistem pengurusan pangkalan data hubungan yang biasa digunakan, setiap satunya mempunyai sintaks dan ciri SQL tersendiri. Artikel ini akan membandingkan dan membezakan antara sintaks SQL Oracle dan DB2, dan memberikan contoh kod khusus. Sambungan pangkalan data Dalam Oracle, gunakan pernyataan berikut untuk menyambung ke pangkalan data: CONNECTusername/password@database Dalam DB2, pernyataan untuk menyambung ke pangkalan data adalah seperti berikut: CONNECTTOdataba
 Penjelasan terperinci tentang fungsi Set tag dalam teg SQL dinamik MyBatis
Feb 26, 2024 pm 07:48 PM
Penjelasan terperinci tentang fungsi Set tag dalam teg SQL dinamik MyBatis
Feb 26, 2024 pm 07:48 PM
Tafsiran teg SQL dinamik MyBatis: Penjelasan terperinci tentang penggunaan teg Set MyBatis ialah rangka kerja lapisan kegigihan yang sangat baik Ia menyediakan banyak teg SQL dinamik dan boleh membina pernyataan operasi pangkalan data secara fleksibel. Antaranya, tag Set ialah tag yang digunakan untuk menjana klausa SET dalam kenyataan UPDATE, yang sangat biasa digunakan dalam operasi kemas kini. Artikel ini akan menerangkan secara terperinci penggunaan teg Set dalam MyBatis dan menunjukkan kefungsiannya melalui contoh kod tertentu. Apakah itu Set tag Set tag digunakan dalam MyBati
 Apakah yang dimaksudkan dengan atribut identiti dalam SQL?
Feb 19, 2024 am 11:24 AM
Apakah yang dimaksudkan dengan atribut identiti dalam SQL?
Feb 19, 2024 am 11:24 AM
Apakah Identity dalam SQL? Contoh kod khusus diperlukan Dalam SQL, Identity ialah jenis data khas yang digunakan untuk menjana nombor penambahan automatik. Ia sering digunakan untuk mengenal pasti setiap baris data dalam jadual. Lajur Identiti sering digunakan bersama dengan lajur kunci utama untuk memastikan setiap rekod mempunyai pengecam unik. Artikel ini akan memperincikan cara menggunakan Identiti dan beberapa contoh kod praktikal. Cara asas untuk menggunakan Identity ialah menggunakan Identit semasa membuat jadual.
 Bagaimana untuk melaksanakan Springboot+Mybatis-plus tanpa menggunakan pernyataan SQL untuk menambah berbilang jadual
Jun 02, 2023 am 11:07 AM
Bagaimana untuk melaksanakan Springboot+Mybatis-plus tanpa menggunakan pernyataan SQL untuk menambah berbilang jadual
Jun 02, 2023 am 11:07 AM
Apabila Springboot+Mybatis-plus tidak menggunakan pernyataan SQL untuk melaksanakan operasi penambahan berbilang jadual, masalah yang saya hadapi akan terurai dengan mensimulasikan pemikiran dalam persekitaran ujian: Cipta objek BrandDTO dengan parameter untuk mensimulasikan parameter yang dihantar ke latar belakang bahawa adalah amat sukar untuk melaksanakan operasi berbilang jadual dalam Mybatis-plus Jika anda tidak menggunakan alatan seperti Mybatis-plus-join, anda hanya boleh mengkonfigurasi fail Mapper.xml yang sepadan dan mengkonfigurasi ResultMap yang berbau dan kemudian. tulis pernyataan sql yang sepadan Walaupun kaedah ini kelihatan menyusahkan, ia sangat fleksibel dan membolehkan kita
 Bagaimana untuk menyelesaikan ralat 5120 dalam SQL
Mar 06, 2024 pm 04:33 PM
Bagaimana untuk menyelesaikan ralat 5120 dalam SQL
Mar 06, 2024 pm 04:33 PM
Penyelesaian: 1. Semak sama ada pengguna log masuk mempunyai kebenaran yang mencukupi untuk mengakses atau mengendalikan pangkalan data, dan pastikan pengguna mempunyai kebenaran yang betul 2. Semak sama ada akaun perkhidmatan SQL Server mempunyai kebenaran untuk mengakses fail yang ditentukan atau folder, dan pastikan akaun Mempunyai kebenaran yang mencukupi untuk membaca dan menulis fail atau folder 3. Semak sama ada fail pangkalan data yang ditentukan telah dibuka atau dikunci oleh proses lain, cuba tutup atau lepaskan fail, dan jalankan semula pertanyaan 4 . Cuba sebagai pentadbir Jalankan Studio Pengurusan seperti dsb.
 Bagaimana untuk menggunakan pernyataan SQL untuk pengagregatan data dan statistik dalam MySQL?
Dec 17, 2023 am 08:41 AM
Bagaimana untuk menggunakan pernyataan SQL untuk pengagregatan data dan statistik dalam MySQL?
Dec 17, 2023 am 08:41 AM
Bagaimana untuk menggunakan pernyataan SQL untuk pengagregatan data dan statistik dalam MySQL? Pengumpulan data dan statistik merupakan langkah yang sangat penting semasa melakukan analisis dan statistik data. Sebagai sistem pengurusan pangkalan data perhubungan yang berkuasa, MySQL menyediakan pelbagai fungsi pengagregatan dan statistik, yang boleh melaksanakan pengagregatan data dan operasi statistik dengan mudah. Artikel ini akan memperkenalkan kaedah menggunakan pernyataan SQL untuk melaksanakan pengagregatan data dan statistik dalam MySQL, dan menyediakan contoh kod khusus. 1. Gunakan fungsi COUNT untuk mengira Fungsi COUNT adalah yang paling biasa digunakan
