

Analisis ringkas tentang cara nod melaksanakan ocr

Bagaimana untuk melaksanakan OCR (pengecaman aksara optik)? Artikel berikut akan memperkenalkan kepada anda cara menggunakan nod untuk melaksanakan OCR. Saya harap ia akan membantu anda!

ocr ialah pengecaman aksara optik secara ringkas, ia adalah untuk mengecam teks pada gambar.
Malangnya, saya hanyalah seorang pengaturcara web peringkat rendah. Saya tidak tahu banyak tentang AI Jika saya ingin melaksanakan OCR, saya hanya boleh mencari perpustakaan pihak ketiga.
Terdapat banyak perpustakaan pihak ketiga untuk OCR dalam bahasa Python Saya telah lama mencari perpustakaan pihak ketiga untuk OCR dalam nodejs Akhirnya, saya mendapati bahawa perpustakaan tesseract.js boleh masih melaksanakan OCR dengan sangat mudah. [Cadangan tutorial berkaitan: tutorial video nodejs]
Paparan kesan
Contoh dalam talian: http://www.lolmbbs.com/tool/ ocr
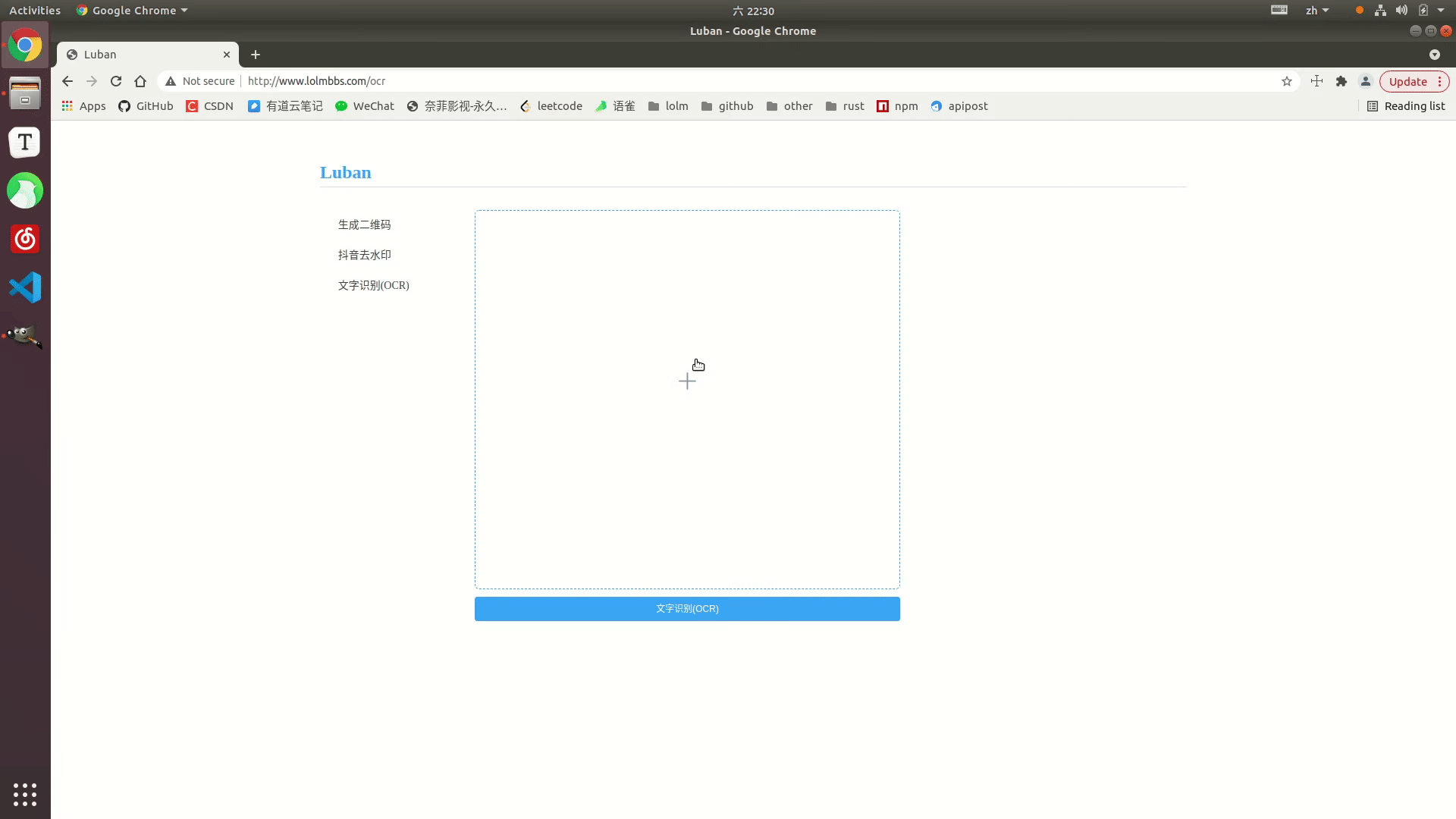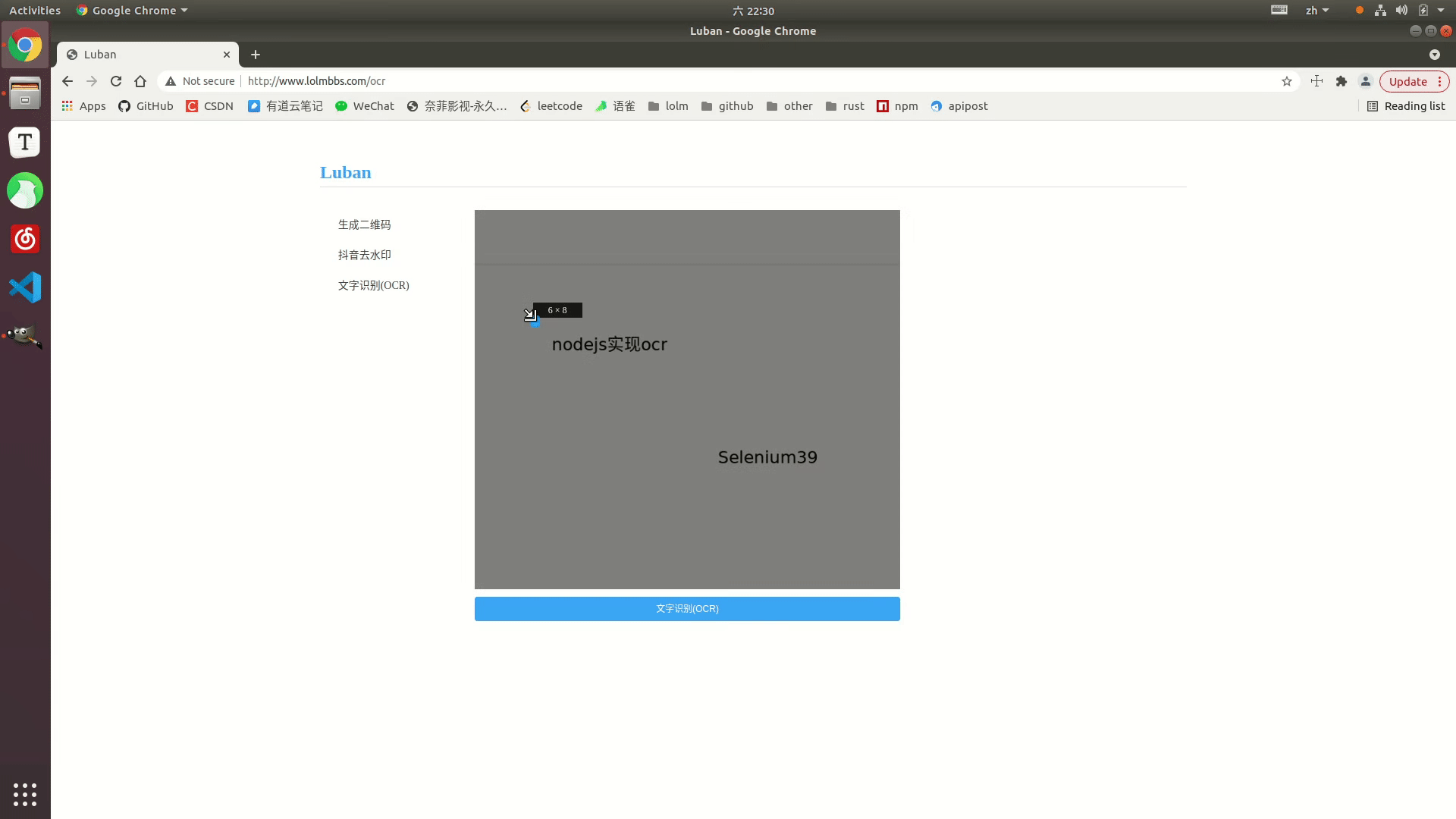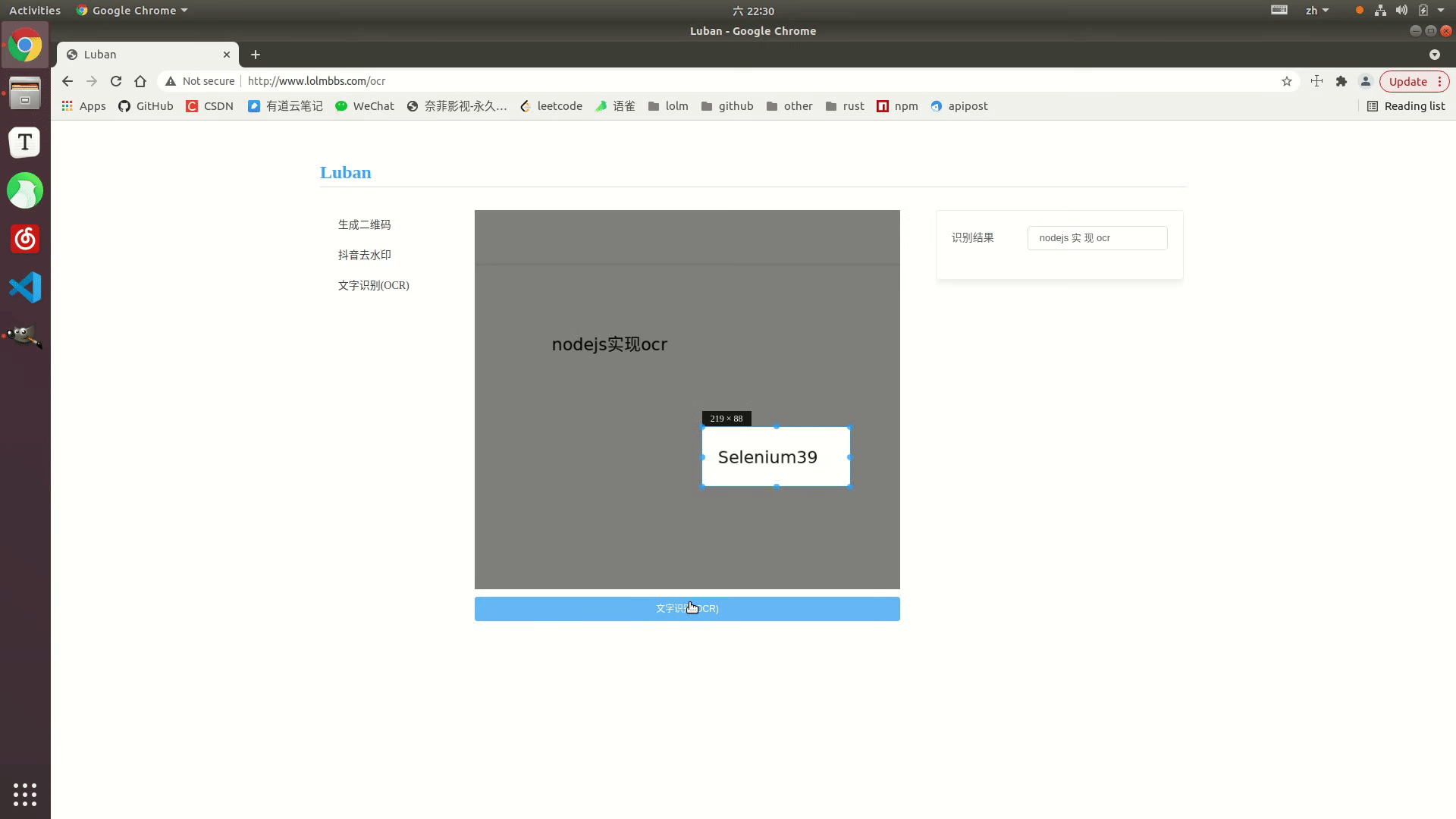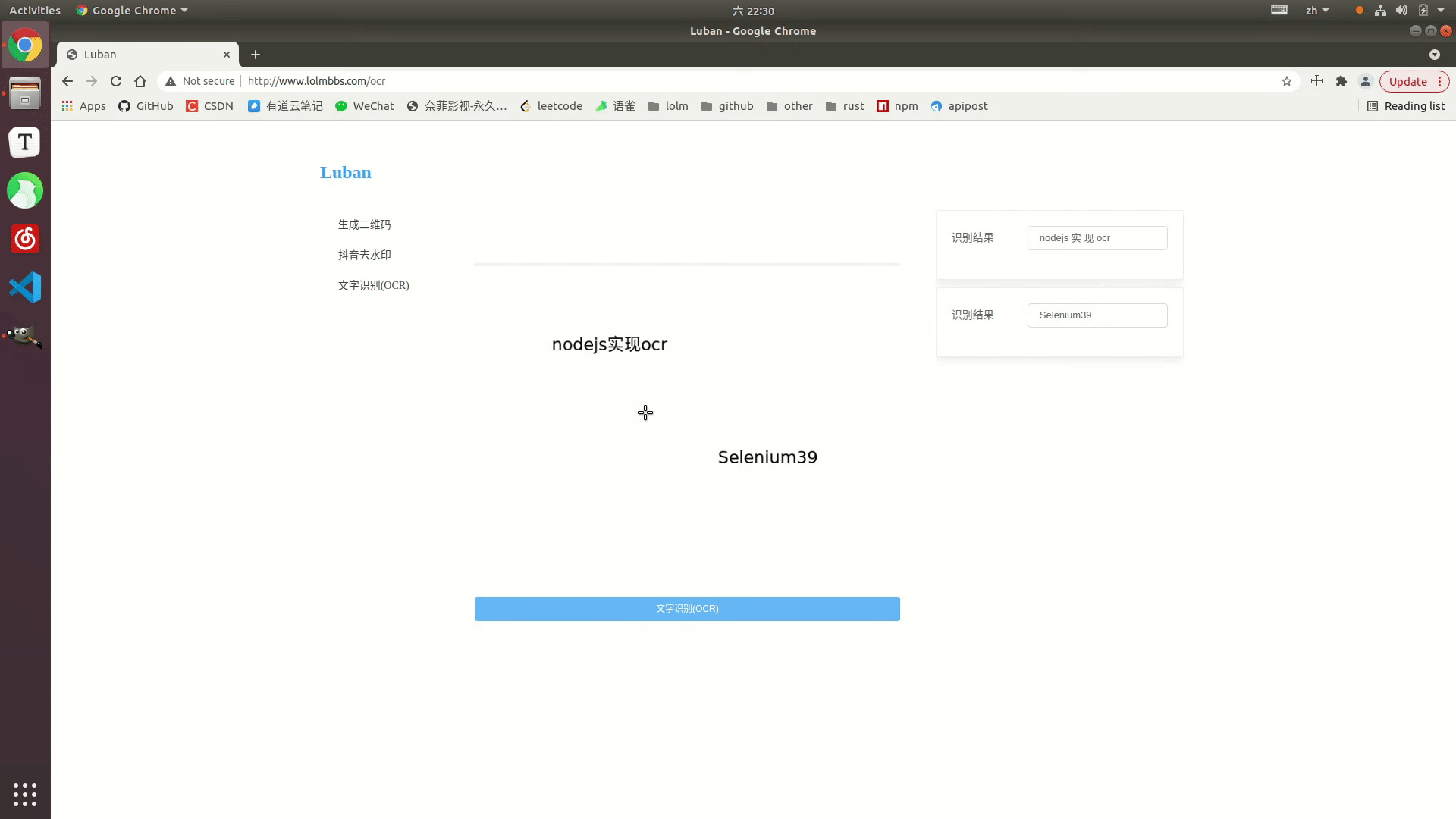
Kod terperinci
tesserract.js Pustaka ini menyediakan berbilang versi yang saya gunakan di sini adalah di luar talian. Versi tesseract.js-luar talian, lagipun, semua orang mengalami keadaan rangkaian yang buruk. 
默认示例代码
const { createWorker } = require('tesseract.js');
const path = require('path');
const worker = createWorker({
langPath: path.join(__dirname, '..', 'lang-data'),
logger: m => console.log(m),
});
(async () => {
await worker.load();
await worker.loadLanguage('eng');
await worker.initialize('eng');
const { data: { text } } = await worker.recognize(path.join(__dirname, '..', 'images', 'testocr.png'));
console.log(text);
await worker.terminate();
})();1. Menyokong pengecaman berbilang bahasa
tesseract.js versi kod sampel lalai hanya menyokong. pengiktirafan Dalam bahasa Inggeris, jika bahasa Cina diiktiraf, hasilnya akan menjadi tanda tanya. Tetapi mujurlah, anda boleh mengimport berbilang model bahasa terlatih untuk menyokong pengiktirafan berbilang bahasa.
Muat turun model bahasa yang sepadan yang anda perlukan dari https://github.com/naptha/tessdata/tree/gh-pages/4.0.0 dan letakkan dalam direktori akar
dalam direktori lang-data Di sini saya memilih tiga model bahasa Cina (chi_sim.traineddata.gz) Jepun (jpn.traineddata.gz) Inggeris (eng.traineddata.gz).Ubah suai konfigurasi item bahasa untuk memuatkan dan memulakan model dalam kod untuk menyokong bahasa Cina, Jepun dan Inggeris pada masa yang sama.
await worker.loadLanguage('chi_sim+jpn+eng'); await worker.initialize('chi_sim+jpn+eng');
Untuk memudahkan ujian semua orang, saya telah memasukkan model latihan dan kod contoh dalam bahasa Cina, Jepun dan Korea serta imej ujian dalam versi luar talian contoh.
https://github.com/Selenium39/tesseract.js-offline
2 Tingkatkan prestasi pengecaman
Jika anda menjalankan versi luar talian, anda Anda. akan mendapati bahawa pemuatan model dan pengecaman OCR agak perlahan. Ia boleh dioptimumkan melalui dua langkah ini.
Dalam projek web, anda boleh memuatkan model sebaik sahaja aplikasi bermula, supaya anda tidak perlu menunggu model dimuatkan apabila anda menerima permintaan OCR nanti .
Merujuk kepada blog Mengapa saya memfaktorkan semula tesseract.js v2?, anda boleh menambah berbilang urutan pekerja melalui kaedah
createScheduleruntuk memproses permintaan ocr secara serentak.
多线程并发处理ocr请求示例
const Koa = require('koa')
const Router = require('koa-router')
const router = new Router()
const app = new Koa()
const path = require('path')
const moment = require('moment')
const { createWorker, createScheduler } = require('tesseract.js')
;(async () => {
const scheduler = createScheduler()
for (let i = 0; i < 4; i++) {
const worker = createWorker({
langPath: path.join(__dirname, '.', 'lang-data'),
cachePath: path.join(__dirname, '.'),
logger: m => console.log(`${moment().format('YYYY-MM-DD HH:mm:ss')}-${JSON.stringify(m)}`)
})
await worker.load()
await worker.loadLanguage('chi_sim+jpn+eng')
await worker.initialize('chi_sim+jpn+eng')
scheduler.addWorker(worker)
}
app.context.scheduler = scheduler
})()
router.get('/test', async (ctx) => {
const { data: { text } } = await ctx.scheduler.addJob('recognize', path.join(__dirname, '.', 'images', 'chinese.png'))
// await ctx.scheduler.terminate()
ctx.body = text
})
app.use(router.routes(), router.allowedMethods())
app.listen(3002)Mulakan permintaan serentak dan anda boleh melihat berbilang pekerja melaksanakan tugas ocr serentak
ab -n 4 -c 4 localhost:3002/test
3. Kod bahagian hadapan
Kod bahagian hadapan dalam paparan kesan dilaksanakan terutamanya menggunakan komponen elementui dan vue -komponen pemangkas.
Untuk kegunaan khusus komponen vue-cropper, sila rujuk pemangkasan imej vue blog saya: Menggunakan vue-cropper untuk pemangkasan imej
ps: Anda boleh lakukan ini apabila memuat naik imej Mula-mula muatkan base64 imej yang dimuat naik pada bahagian hadapan, lihat imej yang dimuat naik dahulu, dan kemudian minta bahagian belakang untuk memuat naik imej, yang lebih baik untuk pengalaman pengguna
Kod lengkap ialah seperti berikut
<template>
<div>
<div style="margin-top:30px;height:500px">
<div class="show">
<vueCropper
v-if="imgBase64"
ref="cropper"
:img="imgBase64"
:output-size="option.size"
:output-type="option.outputType"
:info="true"
:full="option.full"
:can-move="option.canMove"
:can-move-box="option.canMoveBox"
:original="option.original"
:auto-crop="option.autoCrop"
:fixed="option.fixed"
:fixed-number="option.fixedNumber"
:center-box="option.centerBox"
:info-true="option.infoTrue"
:fixed-box="option.fixedBox"
:max-img-size="option.maxImgSize"
style="background-image:none"
@mouseenter.native="enter"
@mouseleave.native="leave"
></vueCropper>
<el-upload
v-else
ref="uploader"
class="avatar-uploader"
drag
multiple
action=""
:show-file-list="false"
:limit="1"
:http-request="upload"
>
<i class="el-icon-plus avatar-uploader-icon"></i>
</el-upload>
</div>
<div
class="ocr"
@mouseleave="leaveCard"
>
<el-card
v-for="(item,index) in ocrResult"
:key="index"
class="card-box"
@mouseenter.native="enterCard(item)"
>
<el-form
size="small"
label-width="100px"
label-position="left"
>
<el-form-item label="识别结果">
<el-input v-model="item.text"></el-input>
</el-form-item>
</el-form>
</el-card>
</div>
</div>
<div style="margin-top:10px">
<el-button
size="small"
type="primary"
style="width:60%"
@click="doOcr"
>
文字识别(OCR)
</el-button>
</div>
</div>
</template>
<script>
import { uploadImage, ocr } from '../utils/api'
export default {
name: 'Ocr',
data () {
return {
imgSrc: '',
imgBase64: '',
option: {
info: true, // 裁剪框的大小信息
outputSize: 0.8, // 裁剪生成图片的质量
outputType: 'jpeg', // 裁剪生成图片的格式
canScale: false, // 图片是否允许滚轮缩放
autoCrop: true, // 是否默认生成截图框
fixedBox: false, // 固定截图框大小 不允许改变
fixed: false, // 是否开启截图框宽高固定比例
fixedNumber: [7, 5], // 截图框的宽高比例
full: true, // 是否输出原图比例的截图
canMove: false, // 时候可以移动原图
canMoveBox: true, // 截图框能否拖动
original: false, // 上传图片按照原始比例渲染
centerBox: true, // 截图框是否被限制在图片里面
infoTrue: true, // true 为展示真实输出图片宽高 false 展示看到的截图框宽高
maxImgSize: 10000
},
ocrResult: []
}
},
methods: {
upload (fileObj) {
const file = fileObj.file
const reader = new FileReader()
reader.readAsDataURL(file)
reader.onload = () => {
this.imgBase64 = reader.result
}
const formData = new FormData()
formData.append('image', file)
uploadImage(formData).then(res => {
this.imgUrl = res.imgUrl
})
},
doOcr () {
const cropAxis = this.$refs.cropper.getCropAxis()
const imgAxis = this.$refs.cropper.getImgAxis()
const cropWidth = this.$refs.cropper.cropW
const cropHeight = this.$refs.cropper.cropH
const position = [
(cropAxis.x1 - imgAxis.x1) / this.$refs.cropper.scale,
(cropAxis.y1 - imgAxis.y1) / this.$refs.cropper.scale,
cropWidth / this.$refs.cropper.scale,
cropHeight / this.$refs.cropper.scale
]
const rectangle = {
top: position[1],
left: position[0],
width: position[2],
height: position[3]
}
if (this.imgUrl) {
ocr({ imgUrl: this.imgUrl, rectangle }).then(res => {
this.ocrResult.push(
{
text: res.text,
cropInfo: { //截图框显示的大小
width: cropWidth,
height: cropHeight,
left: cropAxis.x1,
top: cropAxis.y1
},
realInfo: rectangle //截图框在图片上真正的大小
})
})
}
},
enterCard (item) {
this.$refs.cropper.goAutoCrop()// 重新生成自动裁剪框
this.$nextTick(() => {
// if cropped and has position message, update crop box
// 设置自动裁剪框的宽高和位置
this.$refs.cropper.cropOffsertX = item.cropInfo.left
this.$refs.cropper.cropOffsertY = item.cropInfo.top
this.$refs.cropper.cropW = item.cropInfo.width
this.$refs.cropper.cropH = item.cropInfo.height
})
},
leaveCard () {
this.$refs.cropper.clearCrop()
},
enter () {
if (this.imgBase64 === '') {
return
}
this.$refs.cropper.startCrop() // 开始裁剪
},
leave () {
this.$refs.cropper.stopCrop()// 停止裁剪
}
}
}
</script>Lebih banyak nod Untuk pengetahuan berkaitan, sila lawati: tutorial nodejs!
Atas ialah kandungan terperinci Analisis ringkas tentang cara nod melaksanakan ocr. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

Video Face Swap
Tukar muka dalam mana-mana video dengan mudah menggunakan alat tukar muka AI percuma kami!

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1393
1393
 52
1205
24
52
1205
24

 Adakah nodejs rangka kerja bahagian belakang?
Apr 21, 2024 am 05:09 AM
Adakah nodejs rangka kerja bahagian belakang?
Apr 21, 2024 am 05:09 AM
Node.js boleh digunakan sebagai rangka kerja bahagian belakang kerana ia menawarkan ciri seperti prestasi tinggi, kebolehskalaan, sokongan merentas platform, ekosistem yang kaya dan kemudahan pembangunan.
 Bagaimana untuk menyambungkan nodejs ke pangkalan data mysql
Apr 21, 2024 am 06:13 AM
Bagaimana untuk menyambungkan nodejs ke pangkalan data mysql
Apr 21, 2024 am 06:13 AM
Untuk menyambung ke pangkalan data MySQL, anda perlu mengikuti langkah berikut: Pasang pemacu mysql2. Gunakan mysql2.createConnection() untuk mencipta objek sambungan yang mengandungi alamat hos, port, nama pengguna, kata laluan dan nama pangkalan data. Gunakan connection.query() untuk melaksanakan pertanyaan. Akhir sekali gunakan connection.end() untuk menamatkan sambungan.
 Apakah pembolehubah global dalam nodejs
Apr 21, 2024 am 04:54 AM
Apakah pembolehubah global dalam nodejs
Apr 21, 2024 am 04:54 AM
Pembolehubah global berikut wujud dalam Node.js: Objek global: modul Teras global: proses, konsol, memerlukan pembolehubah persekitaran Runtime: __dirname, __filename, __line, __column Constants: undefined, null, NaN, Infinity, -Infinity
 Apakah perbezaan antara fail npm dan npm.cmd dalam direktori pemasangan nodejs?
Apr 21, 2024 am 05:18 AM
Apakah perbezaan antara fail npm dan npm.cmd dalam direktori pemasangan nodejs?
Apr 21, 2024 am 05:18 AM
Terdapat dua fail berkaitan npm dalam direktori pemasangan Node.js: npm dan npm.cmd Perbezaannya adalah seperti berikut: sambungan berbeza: npm ialah fail boleh laku dan npm.cmd ialah pintasan tetingkap arahan. Pengguna Windows: npm.cmd boleh digunakan daripada command prompt, npm hanya boleh dijalankan dari baris arahan. Keserasian: npm.cmd adalah khusus untuk sistem Windows, npm tersedia merentas platform. Cadangan penggunaan: Pengguna Windows menggunakan npm.cmd, sistem pengendalian lain menggunakan npm.
 PI Node Teaching: Apakah nod pi? Bagaimana cara memasang dan menyediakan nod pi?
Mar 05, 2025 pm 05:57 PM
PI Node Teaching: Apakah nod pi? Bagaimana cara memasang dan menyediakan nod pi?
Mar 05, 2025 pm 05:57 PM
Penjelasan dan Panduan Pemasangan Terperinci untuk Pinetwork Nodes Artikel ini akan memperkenalkan ekosistem pinetwork secara terperinci - nod pi, peranan utama dalam ekosistem pinetwork, dan menyediakan langkah -langkah lengkap untuk pemasangan dan konfigurasi. Selepas pelancaran Rangkaian Ujian Blockchain Pinetwork, nod PI telah menjadi bahagian penting dari banyak perintis yang aktif mengambil bahagian dalam ujian, bersiap sedia untuk pelepasan rangkaian utama yang akan datang. Jika anda tidak tahu kerja pinet, sila rujuk apa itu picoin? Berapakah harga untuk penyenaraian? Penggunaan PI, perlombongan dan analisis keselamatan. Apa itu Pinetwork? Projek Pinetwork bermula pada tahun 2019 dan memiliki syiling pi cryptocurrency eksklusifnya. Projek ini bertujuan untuk mewujudkan satu yang semua orang boleh mengambil bahagian
 Adakah terdapat perbezaan besar antara nodejs dan java?
Apr 21, 2024 am 06:12 AM
Adakah terdapat perbezaan besar antara nodejs dan java?
Apr 21, 2024 am 06:12 AM
Perbezaan utama antara Node.js dan Java ialah reka bentuk dan ciri: Didorong peristiwa vs. didorong benang: Node.js dipacu peristiwa dan Java dipacu benang. Satu-benang vs. berbilang benang: Node.js menggunakan gelung acara satu-benang dan Java menggunakan seni bina berbilang benang. Persekitaran masa jalan: Node.js berjalan pada enjin JavaScript V8, manakala Java berjalan pada JVM. Sintaks: Node.js menggunakan sintaks JavaScript, manakala Java menggunakan sintaks Java. Tujuan: Node.js sesuai untuk tugas intensif I/O, manakala Java sesuai untuk aplikasi perusahaan besar.
 Adakah nodejs bahasa pembangunan bahagian belakang?
Apr 21, 2024 am 05:09 AM
Adakah nodejs bahasa pembangunan bahagian belakang?
Apr 21, 2024 am 05:09 AM
Ya, Node.js ialah bahasa pembangunan bahagian belakang. Ia digunakan untuk pembangunan bahagian belakang, termasuk mengendalikan logik perniagaan sebelah pelayan, mengurus sambungan pangkalan data dan menyediakan API.
 Bagaimana untuk menggunakan projek nodejs ke pelayan
Apr 21, 2024 am 04:40 AM
Bagaimana untuk menggunakan projek nodejs ke pelayan
Apr 21, 2024 am 04:40 AM
Langkah-langkah penggunaan pelayan untuk projek Node.js: Sediakan persekitaran penggunaan: dapatkan akses pelayan, pasang Node.js, sediakan repositori Git. Bina aplikasi: Gunakan npm run build untuk menjana kod dan kebergantungan yang boleh digunakan. Muat naik kod ke pelayan: melalui Git atau Protokol Pemindahan Fail. Pasang kebergantungan: SSH ke dalam pelayan dan gunakan pemasangan npm untuk memasang kebergantungan aplikasi. Mulakan aplikasi: Gunakan arahan seperti node index.js untuk memulakan aplikasi, atau gunakan pengurus proses seperti pm2. Konfigurasikan proksi terbalik (pilihan): Gunakan proksi terbalik seperti Nginx atau Apache untuk menghalakan trafik ke aplikasi anda
