

Berapa banyak data yang boleh disimpan oleh setiap jadual dalam MySQL? Dalam situasi sebenar, disebabkan medan berbeza dan ruang berbeza yang diduduki oleh setiap jadual, jumlah data yang boleh disimpan di bawah prestasi optimum juga berbeza, yang memerlukan pengiraan manual.
Berikut adalah rekod temuduga rakan saya:
Penemuduga: Beritahu saya sedikit Apa yang anda lakukan sebagai pelatih?
Rakan: Semasa latihan saya, saya membina fungsi untuk menyimpan rekod operasi pengguna Ia terutamanya mendapatkan maklumat operasi pengguna yang dihantar daripada perkhidmatan huluan daripada MQ, dan kemudian menyimpan maklumat ini dalam MySQL dan menyediakannya kepada gudang data. Digunakan oleh rakan sekerja.
Rakan: Oleh kerana jumlah data yang agak besar, terdapat kira-kira 40 hingga 50 juta item setiap hari, jadi saya juga melakukan operasi sub-jadual untuknya. Tiga jadual dijana secara tetap setiap hari, dan kemudian data dimodelkan dan disimpan dalam ketiga-tiga jadual ini masing-masing untuk mengelakkan data yang berlebihan dalam jadual daripada memperlahankan kelajuan pertanyaan.
Nampaknya tiada yang salah dengan ungkapan ini, kan? meja tidak akan berfungsi? Tidakkah empat meja berfungsi?
Rakan: Kerana setiap jadual MySQL tidak boleh melebihi 20 juta keping data, jika tidak, kelajuan pertanyaan akan dikurangkan dan prestasi akan terjejas. Data harian kami ialah kira-kira 50 juta keping, jadi lebih selamat untuk membahagikannya kepada tiga jadual. Penemuduga: Ada lagi? Rakan: Tiada lagi...Apa yang kamu buat, oops
Penemuduga: Kemudian balik dan tunggu pemberitahuan.
Telah selesai bercakap. Adakah anda rasa ada yang salah dengan jawapan rakan saya?
Kata Pengantar
Tetapi sebenarnya, 20 juta atau 5 juta ini hanyalah angka kasar dan tidak terpakai untuk semua senario Jika anda berfikir secara membuta tuli selagi data jadual tidak melebihi 20 juta, di sana tidak akan menjadi masalah. Ia berkemungkinan menyebabkan penurunan yang ketara dalam prestasi sistem.
Dalam situasi sebenar, setiap jadual mempunyai medan berbeza dan ruang berbeza yang diduduki oleh medan, jadi jumlah data yang boleh disimpan di bawah prestasi optimum juga berbeza.
Jadi, bagaimana untuk mengira jumlah data yang sesuai untuk setiap jadual? Jangan risau, lihat ke bawah perlahan-lahan.
Artikel ini sesuai untuk pembaca
Untuk membaca artikel ini, anda perlu mempunyai pengetahuan asas tertentu tentang MySQL, sebaik-baiknya pemahaman tertentu tentang InnoDB dan B-trees , anda mungkin perlu mempunyai lebih daripada satu tahun pengalaman pembelajaran MySQL (kira-kira satu tahun?), dan mengetahui pengetahuan teori bahawa "secara umumnya lebih baik untuk mengekalkan ketinggian B-tree dalam InnoDB dalam tempoh tiga peringkat." Artikel ini menerangkan topik "Berapa banyak data boleh disimpan dalam B-tree dengan ketinggian 3 dalam InnoDB?" Selain itu, pengiraan data dalam artikel ini agak ketat (sekurang-kurangnya lebih ketat daripada 95% catatan blog yang berkaitan di Internet Jika anda mengambil berat tentang butiran ini dan tidak jelas pada masa ini, sila teruskan membaca).
Anda akan mengambil masa kira-kira 10-20 minit untuk membaca artikel ini Jika anda menyemak data semasa membaca, ia mungkin mengambil masa kira-kira 30 minit.
Peta minda artikel ini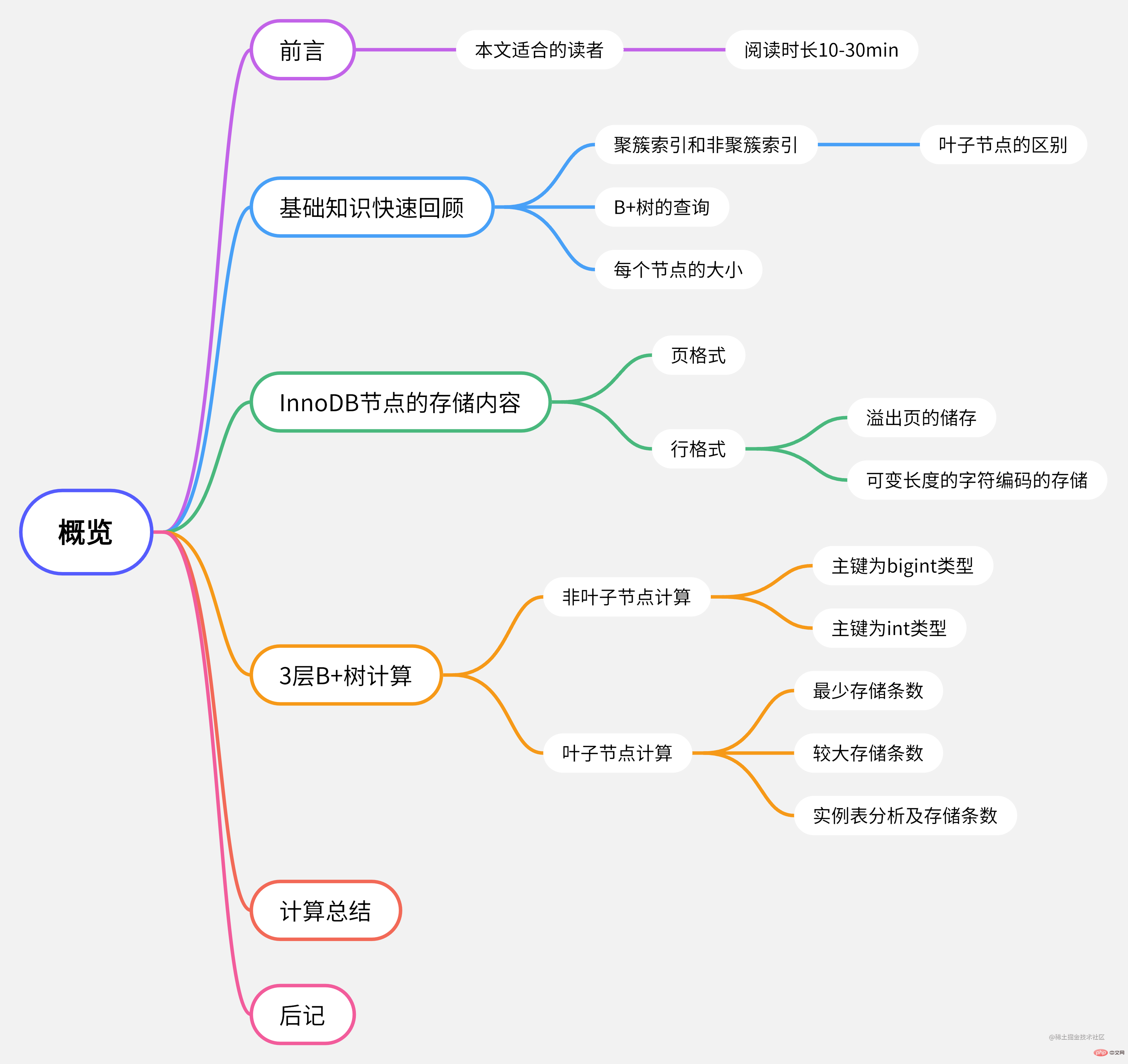 Semakan pantas pengetahuan asas
Semakan pantas pengetahuan asas
Nota: Kandungan berikut adalah intipatinya. Pelajar yang tidak boleh membaca atau memahaminya disyorkan untuk menyimpan artikel ini dahulu, dan kemudian kembali membacanya apabila anda mempunyai pangkalan pengetahuan
. ??
Jadual data biasanya sepadan dengan penyimpanan satu atau lebih pokok Bilangan pokok adalah berkaitan dengan bilangan indeks Setiap indeks akan mempunyai pokok yang berasingan.
Indeks berkelompok dan indeks bukan berkelompok:
Contohnya, jika indeks ialah id, maka nod bukan daun menyimpan data id.
Perbezaan antara nod daun adalah seperti berikut:
select * from table where id = 1, kami sentiasa pergi ke nod daun untuk mendapatkan data.
Pertanyaan B-tree ditanya lapisan demi lapisan dari atas ke bawah Secara umumnya, kami berpendapat adalah lebih baik untuk mengekalkan ketinggian pokok B dalam 3 lapisan. Iaitu, dua lapisan atas adalah indeks, dan lapisan terakhir menyimpan data Dengan cara ini, apabila melihat jadual, hanya tiga IO cakera diperlukan (sebenarnya kurang satu kali, kerana nod akar akan bermastautin dalam ingatan). dan jumlah data yang boleh disimpan adalah Ia juga agak mengagumkan.
Jika jumlah data terlalu besar dan bilangan B menjadi 4, maka setiap pertanyaan memerlukan 4 IO cakera, yang akan merendahkan prestasi. Itulah sebabnya kami mengira bilangan maksimum kepingan data yang boleh disimpan oleh pokok B 3 lapisan InnoDB.
Saiz lalai setiap nod MySQL ialah 16KB, yang bermaksud setiap nod boleh menyimpan sehingga 16KB data, dengan maksimum 64KB dan a minimum 4KB.
Sambungan: Bagaimana jika data dalam baris tertentu sangat besar dan melebihi saiz nod?
Dokumentasi MySQL 5.7 menerangkan:
Untuk tetapan 4KB, 8KB, 16KB dan 32KB, panjang baris maksimum adalah kurang sedikit daripada separuh halaman pangkalan data. Sebagai contoh: untuk saiz halaman lalai 16KB, panjang baris maksimum adalah kurang sedikit daripada 8KB dan untuk saiz halaman lalai 32KB, panjang baris maksimum kurang sedikit daripada 16KB.
Dan untuk halaman 64KB, panjang baris maksimum kurang sedikit daripada 16KB.
Jika baris melebihi panjang baris maksimum, lajur panjang berubah-ubah disimpan dalam halaman luar sehingga baris memenuhi had panjang baris maksimum. Maksudnya, varchar dan teks dengan panjang berubah-ubah disimpan dalam halaman luaran untuk mengurangkan panjang data baris ini.

Alamat dokumen: MySQL :: Manual Rujukan MySQL 5.7 :: 14.12.2 Pengurusan Ruang Fail
Kelajuan pertanyaan MySQL terutamanya bergantung pada kelajuan baca dan tulis cakera, kerana MySQL hanya membaca satu nod ke dalam memori setiap kali semasa membuat pertanyaan, dan mencari sasaran seterusnya melalui data daripada nod ini Baca kedudukan nod, dan kemudian baca data nod seterusnya sehingga data yang diperlukan ditanya atau data tidak wujud.
Mesti ada yang bertanya, bukankah kita perlu menanyakan data dalam setiap nod? Mengapa masa yang diambil tidak dikira di sini?
Ini kerana selepas membaca keseluruhan data nod, ia akan disimpan dalam memori Menanyakan data nod dalam memori sebenarnya mengambil masa yang sangat singkat yang sama. gg
Dalam pokok B Innodb, nod yang sering kita rujuk dipanggil halaman ( halaman), setiap halaman menyimpan data pengguna, dan semua halaman bersama-sama membentuk pokok B (sudah tentu ia akan menjadi lebih rumit dalam amalan, tetapi kita hanya perlu mengira berapa banyak keping data yang boleh disimpan, jadi buat masa ni boleh jadi macam ni faham?).
Halaman ialah unit cakera terkecil yang digunakan oleh enjin storan InnoDB untuk mengurus pangkalan data Kami sering mengatakan bahawa setiap nod ialah 16KB, yang sebenarnya bermaksud saiz setiap halaman ialah 16KB.
Ruang 16KB ini perlu menyimpan format halaman maklumat dan format baris maklumat format baris juga mengandungi beberapa metadata dan data pengguna. Oleh itu, apabila kita mengira, kita mesti memasukkan semua data ini.
Format halaman
Format asas setiap halaman, iaitu beberapa maklumat yang setiap halaman akan mengandungi Jadual ringkasan adalah seperti berikut :
| Nama | Ruang | Maksud dan fungsi , dsb. th> | ||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
Pengepala Fail |
Pengepala fail 38 bait td> | , digunakan untuk merekodkan beberapa maklumat pengepala halaman.
|
||||||||||||||||||||||||
Pengepala Halaman |
56 bait | Halaman pengepala, digunakan untuk merekod maklumat status halaman. Termasuk bilangan slot dalam direktori halaman, alamat ruang kosong, bilangan rekod pada halaman ini, bilangan bait yang diduduki oleh rekod yang dipadamkan, dsb. | ||||||||||||||||||||||||
Infimum & supremum |
26 bait | Nilai sempadan yang digunakan untuk mengehadkan rekod halaman semasa, termasuk nilai minimum dan nilai maksimum. | ||||||||||||||||||||||||
Rekod Pengguna |
Tidak tetap | Rekod Pengguna , data yang kami masukkan disimpan di sini. | ||||||||||||||||||||||||
Ruang Kosong |
Tidak tetap | Terbiar Ruang, apabila rekod pengguna ditambah, ruang diambil dari sini. | ||||||||||||||||||||||||
Pengarah Halaman |
Tidak tetap | Direktori halaman , digunakan untuk menyimpan maklumat lokasi data pengguna dalam halaman. Setiap slot akan memuatkan 4-8 keping data pengguna, dan setiap slot menduduki 1-2 bait Apabila satu slot melebihi 8 keping data, ia akan dibahagikan secara automatik kepada dua slot. | ||||||||||||||||||||||||
Treler Fail |
8 bait | maklumat akhir fail digunakan terutamanya untuk mengesahkan integriti halaman. |
Rajah skematik:
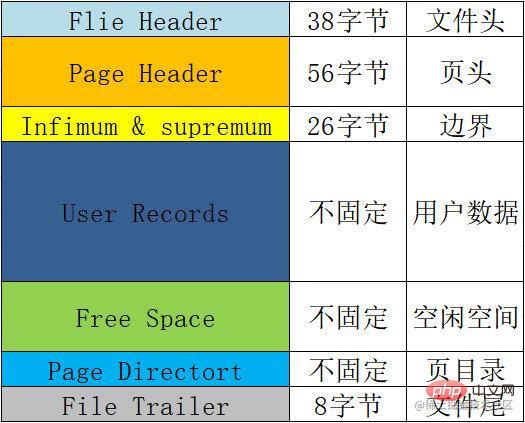
Saya melihat tapak web rasmi untuk masa yang lama dan tidak menemuinya? . . . Saya tidak tahu sama ada kerana saya tidak menulisnya atau kerana saya buta Jika sesiapa telah menemuinya, saya harap mereka boleh membantu saya menyiarkannya di ruang komen?
Jadi kandungan jadual dalam format halaman di atas adalah berdasarkan pembelajaran dan ringkasan daripada beberapa blog.
Selain itu, apabila rekod baharu dimasukkan ke dalam indeks berkelompok InnoDB, InnoDB cuba membiarkan 1/16 halaman percuma untuk sisipan dan kemas kini rekod indeks pada masa hadapan. Jika rekod indeks disisipkan mengikut tertib (menaik atau menurun), halaman yang terhasil mempunyai kira-kira 15/16 daripada ruang yang tersedia. Jika rekod dimasukkan dalam susunan rawak, lebih kurang 1/2 hingga 15/16 ruang halaman tersedia. Dokumentasi rujukan: MySQL :: Manual Rujukan MySQL 5.7 :: 14.6.2.2 Struktur Fizikal Indeks InnoDB
Kecuali User Records dan Free Space memori yang diduduki ialah bait, setiap halaman hanya mempunyai ruang untuk data pengguna 1615×1024 −128=15232 bait (1/16 dikhaskan). Sudah tentu, ini adalah minimum kerana kami tidak mengambil kira direktori halaman. Direktori halaman dibiarkan untuk dipertimbangkan kemudian. Ini perlu dikira berdasarkan medan jadual. Format barisPertama sekali, saya rasa perlu untuk menyebut bahawa format baris lalai MySQL5.6 adalah COMPACT (compact ), 5.7 Format baris lalai dalam dan selepas ialah DYNAMIC (dinamik format baris yang berbeza disimpan dalam cara yang berbeza Terdapat dua format baris lain Kandungan artikel ini diterangkan terutamanya berdasarkan DINAMIK). Pautan dokumen rasmi: MySQL :: Manual Rujukan MySQL 5.7:: 14.11 Format baris InnoDB (kebanyakan kandungan format baris berikut boleh didapati di dalam)
Setiap baris rekod mengandungi maklumat berikut, kebanyakannya boleh didapati dalam dokumen rasmi. Apa yang saya tulis di sini tidak begitu terperinci Saya hanya menulis beberapa pengetahuan yang boleh membantu kami mengira ruang Untuk maklumat yang lebih terperinci, anda boleh mencari "Format baris MySQL" dalam talian. Rajah skematik: Terdapat juga beberapa perkara yang perlu diperhatikan: Nota: Ini adalah ciri DINAMIK. Apabila menggunakan DYNAMIC untuk mencipta jadual, InnoDB akan mengeluarkan nilai-nilai lajur pembolehubah panjang yang lebih panjang (seperti jenis VARCHAR, VARBINAR, BLOB dan TEKS) dan menyimpannya dalam halaman limpahan , hanya kekalkan penuding 20 bait yang menghala ke halaman limpahan pada lajur ini. Format baris COMPACT (format lalai MySQL5.6) menyimpan 768 bait pertama dan penuding 20-bait dalam rekod nod B-tree, dan selebihnya disimpan pada halaman limpahan . Sama ada lajur disimpan di luar halaman bergantung pada saiz halaman dan jumlah saiz baris. Apabila baris terlalu panjang, lajur terpanjang dipilih untuk storan luar halaman sehingga rekod indeks berkelompok muat pada halaman B-tree (dokumen tidak menyatakan bilangannya?). TEXT dan BLOB kurang daripada atau sama dengan 40 bait disimpan terus dalam baris dan tidak dimuka surat. Format baris DINAMIK mengelakkan masalah mengisi nod B-tree dengan jumlah data yang besar, mengakibatkan lajur yang panjang. Idea format baris DINAMIK ialah jika sebahagian daripada nilai data yang panjang disimpan di luar halaman, ia biasanya paling cekap untuk menyimpan keseluruhan nilai di luar halaman. Dengan format DINAMIK, lajur yang lebih pendek disimpan dalam nod B-tree jika boleh, meminimumkan bilangan halaman limpahan yang diperlukan untuk baris tertentu. Char, varchar, teks, dsb. perlu menetapkan jenis pengekodan aksara Semasa mengira ruang yang diduduki, pengekodan yang berbeza perlu dilakukan ruang yang diduduki. varchar, teks dan jenis lain akan mempunyai senarai medan panjang untuk merekodkan panjang yang didudukinya, tetapi char ialah jenis panjang tetap, yang merupakan situasi khas. 10), maka terdapat Situasi berikut: Untuk pengekodan aksara panjang tetap (seperti kod ASCII), nama medan akan disimpan dalam format panjang tetap kod ASCII menduduki satu bait, jadi nama mengambil 10 bait. Untuk pengekodan aksara panjang berubah (seperti utf8mb4), sekurang-kurangnya 10 bait akan dikhaskan untuk nama. Jika boleh, InnoDB akan menyimpannya kepada 10 bait dengan memangkas ruang kosong mengekori. Jika ruang tidak boleh disimpan selepas memangkas, potong ruang mengekor kepada nilai minimum panjang bait nilai lajur (biasanya 1 bait). Panjang maksimum lajur ialah: diedit 4 >40 Sejujurnya saya tak berapa faham design char walaupun dah lama baca termasuk dokumen rasmi dan beberapa blog, harap pelajar yang faham boleh jelaskan keraguan mereka di kawasan ulasan: Untuk pengekodan aksara dengan panjang berubah-ubah, adakah char agak seperti jenis panjang berubah-ubah? utf8mb4 yang biasa digunakan menduduki 1 ~ 4 bait, jadi ruang yang diduduki oleh char(10) ialah 10 ~ 40 bait Perubahan ini agak besar, tetapi ia tidak meninggalkan ruang yang mencukupi untuknya, begitu juga Adakah ia istimewa untuk menggunakan a senarai medan panjang berubah-ubah untuk merekodkan penggunaan ruang medan aksara? Baiklah, kita sudah tahu apa yang disimpan dalam setiap halaman, dan kini kita mempunyai kuasa pengkomputeran. Memandangkan saya telah mengira baki ruang halaman dalam format halaman di atas, terdapat 15232 bait yang tersedia untuk setiap halaman Mari kita hitung baris secara langsung. Pengiraan nod bukan daun Halaman indeks ialah nod di mana indeks disimpan , iaitu, nod bukan daun. Setiap rekod indeks mengandungi nilai indeks semasa, maklumat penuding 6 bait dan pengepala baris 5 bait , digunakan sebagai penunjuk ke lapisan seterusnya halaman data. Saya tidak menemui ruang yang diduduki oleh penuding dalam rekod indeks dalam dokumen rasmi. Saya merujuk kepada catatan blog lain untuk 6 bait ini kod, tetapi khususnya dalam saya tidak tahu bahagian mana kod sumber?. Pelajar yang ingin tahu boleh menjawab soalan mereka di ruangan komen. Dengan mengandaikan bahawa id kunci utama kami adalah daripada jenis bigint, iaitu 8 bait, maka ruang yang diduduki oleh setiap baris data dalam halaman indeks adalah sama dengan bait. Setiap halaman boleh menyimpan data indeks. Termasuk jadual kandungan halaman, jika dikira berdasarkan purata 6 keping data setiap slot, akan ada sekurang-kurangnya slot, memerlukan 268 bait ruang. Jika ruang storan data diperuntukkan kepada slot, saya mengira bahawa kira-kira 787 data indeks boleh disimpan. Jika kunci utama adalah jenis int, ia boleh menyimpan lebih banyak, kira-kira 993 keping data indeks. Dalam pepohon B, apabila indeks nod direkodkan sebagai , ia akan mempunyai nod anak. Memandangkan dua peringkat pertama pokok B 3 peringkat kami ialah rekod indeks, nod akar tahap pertama ialah rekod indeks, Kemudian lapisan kedua akan mempunyai nod, jenis data setiap nod adalah konsisten dengan nod akar, dan masih boleh diselamatkan rekod, bilangan nod dalam lapisan ketiga akan sama dengan . kemudian: Pengiraan OK selesai. Pengiraan bilangan rekod data Seperti yang kita yang dinyatakan sebelum ini, Panjang baris maksimum adalah kurang sedikit daripada separuh halaman pangkalan data Sebab mengapa ia kurang sedikit daripada separuh adalah kerana setiap halaman meninggalkan sedikit ruang untuk kandungan lain format halaman<.>, jadi kita boleh berfikir bahawa setiap halaman Setiap halaman boleh memuatkan sekurang-kurangnya dua keping data, setiap keping data kurang sedikit daripada 8KB. Jika panjang data baris melebihi nilai ini, InnoDB pasti akan membahagikan beberapa data kepada halaman limpahan, jadi kami tidak akan mempertimbangkannya. Jika setiap keping data ialah 8KB, setiap nod daun hanya boleh menyimpan 2 keping data, apabila kunci utama adalah besar, hanya boleh menyimpan Artikel Data adalah lebih daripada 1.2 juta keping Jumlah data ini tidak dijangka, bukan??. Mari kita menganalisis data baris jadual ini dahulu: tiada senarai nilai nol, tiada senarai medan panjang boleh ubah, ID transaksi dan medan penunjuk perlu dikira, pengepala rekod baris perlu dikira, kemudian setiap baris data menempati Ruang adalah Bait, setiap Nod daun boleh simpan data. 算上页目录的槽位所占空间,每个叶子节点可以存放 502 条数据,那么三层B+树可以存放的最大数据量就是 ,将近5亿条数据!没想到吧??。 大部分情况下我们的表字段都不是上面那样的,所以我选择了一场比较常规的表来进行分析,看看能存放多少数据。表情况如下:
名称
空间
含义和作用等
行记录头信息
5字节
行记录的标头信息
包含了一些标志位、数据类型等信息
如:删除标志、最小记录标志、排序记录、数据类型、
页中下一条记录的位置等
可变长度字段列表
不固定
来保存那些可变长度的字段占用的字节数,比如varchar、text、blob等。
若变长字段的长度小于 255字节,就用1字节表示;
若大于 255字节,用2字节表示。
表字段中有几个可变长字段该列表中就有几个值,如果没有就不存。
null值列表
不固定
用来存储可以为null的字段是否为null。
每个可为null的字段在这里占用一个bit,就是bitmap的思想。
该列表占用的空间是以字节为单位增长的,例如,如果有 9 到 16 个
可以为null的列,则使用两个字节,没有占用1.5字节这种情况。
事务ID和指针字段
6 7字节
了解MVCC的朋友应该都知道,数据行中包含了一个6字节的事务ID和
一个7字节的指针字段。
如果没有定义主键,则还会多一个6字节的行ID字段
当然我们都有主键,所以这个行ID我们不计算。
实际数据
不固定
这部分就是我们真实的数据了。

Penyimpanan halaman limpahan (halaman luar)
Kelebihan
Penyimpanan di bawah pengekodan aksara yang berbeza
Mulakan pengiraan
Pengiraan nod tunggal
Dua peringkat pertama pengiraan nod bukan daun
Bilangan minimum rekod yang disimpan
Sebilangan besar rekod yang disimpan
Andaikan jadual kami kelihatan seperti ini: -- 这是一张非常普通的课程安排表,除id外,仅包含了课程id和老师id两个字段
-- 且这几个字段均为 int 型(当然实际生产中不会这么设计表,这里只是举例)。
CREATE TABLE `course_schedule` (
`id` int NOT NULL,
`teacher_id` int NOT NULL,
`course_id` int NOT NULL,
PRIMARY KEY (`id`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
常规表的存放记录数
CREATE TABLE `blog` (
`id` bigint unsigned NOT NULL AUTO_INCREMENT COMMENT '博客id',
`author_id` bigint unsigned NOT NULL COMMENT '作者id',
`title` varchar(50) CHARACTER SET utf8mb4 NOT NULL COMMENT '标题',
`description` varchar(250) CHARACTER SET utf8mb4 NOT NULL COMMENT '描述',
`school_code` bigint unsigned DEFAULT NULL COMMENT '院校代码',
`cover_image` char(32) DEFAULT NULL COMMENT '封面图',
`create_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`release_time` datetime DEFAULT NULL COMMENT '首次发表时间',
`modified_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '修改时间',
`status` tinyint unsigned NOT NULL COMMENT '发表状态',
`is_delete` tinyint unsigned NOT NULL DEFAULT 0,
PRIMARY KEY (`id`),
KEY `author_id` (`author_id`),
KEY `school_code` (`school_code`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8 COLLATE=utf8_general_mysql500_ci ROW_FORMAT=DYNAMIC;
这是我的开源项目“校园博客”(GitHub地址:github.com/stick-i/scb…) 中的博客表,用于存放博客的基本数据。
分析一下这张表的行记录:
行记录头信息:肯定得有,占用5字节。
可变长度字段列表:表中 title占用1字节,description占用2字节,共3字节。
null值列表:表中仅school_code、cover_image、release_time3个字段可为null,故仅占用1字节。
事务ID和指针字段:两个都得有,占用13字节。
字段内容信息:
id、author_id、school_code 均为bigint型,各占用8字节,共24字节。
create_time、release_time、modified_time 均为datetime类型,各占8字节,共24字节。
status、is_delete 为tinyint类型,各占用1字节,共2字节。
cover_image 为char(32),字符编码为表默认值utf8,由于该字段实际存的内容仅为英文字母(存url的),结合前面讲的字符编码不同情况下的存储 ,故仅占用32字节。
title、description masing-masing ialah varchar(50) dan varchar(250) Kedua-dua ini tidak seharusnya menghasilkan halaman limpahan (tidak pasti Pengekodan aksara ialah utf8mb4). Lebih daripada % disimpan dalam bahasa Cina (3 bait), 25% dalam bahasa Inggeris (1 bait) dan 5% ialah emotikon 4-bait?, apabila storan penuh, ia akan menduduki bait.
Menurut semua analisis di atas, sejumlah 869 bait telah diduduki, maka setiap nod daun boleh menyimpan item dengan mengira kandungan halaman, 17 item masih boleh diletakkan.
Maka jumlah maksimum data yang boleh disimpan oleh pokok B tiga lapisan ialah ,
Kira-kira 10 juta keping dataMenurut pengiraan dalam tiga situasi berbeza di atas, dapat dilihat bahawa julat storan data dalam kes InnoDB tiga lapisan B-tree Daripada lebih 1.2 juta entri kepada hampir 500 juta entri, rentang ini masih sangat besar Pada masa yang sama, kami juga mengira jadual maklumat blog yang boleh menyimpan
kira-kira Sepuluh juta keping
Jadi, apabila kita mempertimbangkan sub-jadual untuk projek, kita harus memberi lebih perhatian kepada situasi sebenar jadual, daripada berfikir secara membuta tuli bahawa 20 juta data adalah titik kritikal . Jika isu ini timbul semasa temu duga, saya rasa penemuduga tidak mahu mengetahui nombor itu, tetapi ingin melihat bagaimana anda menganalisis masalah dan bagaimana anda menghasilkan nombor itu proses.
 mysql mengubah suai nama jadual data
mysql mengubah suai nama jadual data
 MySQL mencipta prosedur tersimpan
MySQL mencipta prosedur tersimpan
 Pangkalan data tiga paradigma
Pangkalan data tiga paradigma
 Perbezaan antara mongodb dan mysql
Perbezaan antara mongodb dan mysql
 Bagaimana untuk menyemak sama ada kata laluan mysql terlupa
Bagaimana untuk menyemak sama ada kata laluan mysql terlupa
 mysql mencipta pangkalan data
mysql mencipta pangkalan data
 tahap pengasingan transaksi lalai mysql
tahap pengasingan transaksi lalai mysql
 Perbezaan antara sqlserver dan mysql
Perbezaan antara sqlserver dan mysql



![Penyelesaian pengoptimuman pertanyaan MySQL [diajar oleh arkitek daripada pengeluar utama] [Bermula dengan Penalaan MySQL |](https://img.php.cn/upload/course/000/000/068/6242a7d5be236814.png)







![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



