
 pangkalan data
tutorial mysql
Membawa anda memahami kumpulan penimbal pangkalan data (Kolam Penampan) dalam MySQL
pangkalan data
tutorial mysql
Membawa anda memahami kumpulan penimbal pangkalan data (Kolam Penampan) dalam MySQL
Membawa anda memahami kumpulan penimbal pangkalan data (Kolam Penampan) dalam MySQL


Untuk jadual yang menggunakan enjin storan InnoDB, ruang storan diuruskan dalam unit halaman sebagai butiran asas untuk menukar masuk dan keluar antara memori dan cakera. Apabila kita memuatkan halaman dari cakera ke dalam memori, cakera I/O akan dilakukan. Overhed cakera I/O sangat mempengaruhi prestasi keseluruhan Jika kita membaca halaman yang sepadan secara langsung dari memori, bukankah ia akan mengurangkan kehilangan prestasi yang disebabkan oleh cakera I/O dan kecekapan akan bertambah baik. Berdasarkan ini, Kolam Penampan (
Buffer Pool) muncul, jadi seterusnya, mari kita bincangkan tentang Kolam Penampan dalam InnoDB.
Kolam Penampan
Sesetengah orang mungkin berpendapat bahawa memandangkan kumpulan penimbal sangat bagus, mengapa tidak simpan sahaja semua data dalam kumpulan penimbal Tidak, tidak, tidak , Kolam penimbal ialah memori bersebelahan yang diperuntukkan oleh sistem pengendalian. Memori mempunyai kapasiti yang jauh lebih kecil daripada cakera dan mahal. Jadi berapa banyak memori yang akan diperuntukkan oleh sistem pengendalian kepada kumpulan penimbal?
- Secara lalai, saiz kumpulan penimbal ialah 128MB
Sudah tentu, jika mesin anda mempunyai kapasiti memori yang sangat besar, anda boleh mengkonfigurasi parameter pilihan permulaan; dalam fail konfigurasi innodb_buffer_pool_sizeUnit ialah bait, dan minimum tidak boleh kurang daripada 5MB.
Struktur dalaman kumpulan penimbal
Kolam penimbal membahagikan memori berterusan yang diperuntukkan oleh sistem pengendalian kepada beberapa halaman (halaman penimbal) dengan saiz lalai 16KB [Pada masa ini, terdapat is no actual Halaman cakera dicache dalam Buffer Pool]. Apabila kita menukar halaman dari cakera ke dalam buffer pool, bagaimana kita memperuntukkan lokasi? Oleh itu, beberapa maklumat kawalan diperlukan untuk mengenal pasti halaman penimbal dalam kumpulan penimbal ini Maklumat kawalan ini disimpan dalam kawasan memori yang dipanggil blok kawalan dan sepadan dengan halaman penimbal satu-satu. Saiz blok kawalan juga ditetapkan. Oleh itu, dalam ruang ingatan yang berterusan ini, pemecahan memori pasti akan berlaku. Secara ringkasnya, struktur dalaman kumpulan penimbal adalah seperti berikut:
- Halaman penimbal
- Blok kawalan: nombor halaman, alamat halaman penimbal dalam kumpulan penimbal, nod senarai terpaut maklumat, dsb.
- Pemecahan memori [Jika memori diperuntukkan dengan betul, pemecahan memori boleh diketepikan]
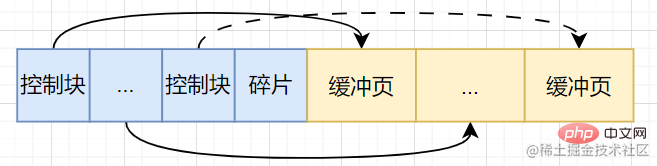
Pengurusan kolam penimbal
Di atas yang dipautkan maklumat nod senarai disebut dalam blok kawalan, jadi untuk apa nod senarai terpaut digunakan? Ia adalah untuk mengurus halaman dalam kumpulan penimbal dengan lebih baik. Senarai terpaut digunakan untuk memautkan blok kawalan, kerana terdapat surat-menyurat satu dengan satu antara blok kawalan dan halaman penimbal.
1) Senarai terpaut percuma
Memautkan blok kawalan yang sepadan dengan semua halaman penimbal percuma untuk membentuk senarai terpaut.
Masalah diselesaikan: Menukar halaman daripada cakera ke dalam kumpulan penimbal, bagaimana untuk membezakan halaman mana dalam kumpulan penimbal yang percuma? Dengan senarai pautan percuma, apabila halaman cakera ditukar ke dalam kumpulan penimbal, halaman penimbal percuma diperoleh terus daripada senarai pautan percuma, dan maklumat yang sepadan dalam halaman cakera diisi ke dalam blok kawalan yang sepadan dengan halaman penimbal, dan kemudian Hanya padamkan blok kawalan daripada senarai terpaut percuma.
2) Kemas kini senarai terpaut
Jika data halaman penimbal dalam kumpulan penimbal diubah suai, menyebabkan ia tidak konsisten dengan data pada cakera, halaman itu dipanggil kotor muka surat. Pautkan blok kawalan yang sepadan dengan semua halaman kotor untuk membentuk senarai terpaut kemas kini dan muat semula data halaman cache yang sepadan ke cakera pada masa tertentu pada masa hadapan berdasarkan senarai terpaut ini.
3) Senarai terpaut LRU
Saiz kumpulan penimbal adalah terhad Jika halaman cache melebihi saiz kumpulan penimbal, iaitu, tiada halaman penimbal percuma ialah halaman baharu yang akan ditambah Apabila memasuki kumpulan penimbal, strategi LRU digunakan untuk mengalih keluar halaman penimbal lama daripada kumpulan penimbal, dan kemudian menambah halaman baharu. Memandangkan senarai terpaut LRU melibatkan banyak kandungan, kami akan memperkenalkannya secara berasingan seterusnya.
"Falsafah" yang terkandung dalam senarai terpaut LRU
Biar saya nyatakan dahulu mekanisme prabacaan
Mekanisme pengoptimuman pada I/O, prabacaan, sebagai namanya, akan secara tidak segerak Halaman dimuatkan ke dalam kumpulan penimbal yang dijangka diperlukan tidak lama lagi, permintaan ini membawa masuk semua halaman dalam julat, dipanggil 局部性原理, untuk mengurangkan I/O cakera.
Sebelum memahami mekanisme baca ke hadapan, mari semak unit storan logik InnoDB: ruang meja → segmen → takat → halaman. Kawasan dinyatakan secara khusus, yang akan digunakan kemudian: kawasan adalah berterusan 64个页 dalam lokasi fizikal, iaitu saiz kawasan ialah 1MB
The mekanisme pra-bacaan boleh Ia dibahagikan kepada dua jenis berikut:
- Baca ke hadapan linear : Teknik yang meramalkan halaman mana yang mungkin diperlukan tidak lama lagi berdasarkan halaman yang diakses secara berurutan dalam kumpulan penimbal. Dengan mengkonfigurasi parameter innodb_read_ahead_threshold, jika halaman kawasan tertentu yang diakses secara berurutan melebihi nilai parameter ini, permintaan baca tak segerak akan dicetuskan untuk membaca semua halaman di kawasan seterusnya ke dalam kumpulan penimbal.
- Baca ke hadapan secara rawak : Boleh meramalkan bila halaman mungkin diperlukan berdasarkan halaman yang sudah ada dalam kumpulan penimbal, tanpa mengira susunan halaman tersebut dibaca. Jika 13 halaman berturut-turut pada tahap yang sama ditemui dalam kumpulan penimbal, InnoDB akan mengeluarkan permintaan secara tidak segerak untuk mengambil halaman yang selebihnya bagi tahap tersebut. Bacaan rawak dikawal dengan mengkonfigurasi pembolehubah innodb_random_read_ahead.
Bagaimanakah LRU tradisional mengurus halaman penimbal?
Gunakan algoritma LRU untuk mengurus halaman penimbal yang paling kurang digunakan baru-baru ini dan membentuk senarai terpaut yang sepadan untuk penyingkiran mudah.
Apabila halaman diakses [iaitu diakses baru-baru ini]
- Halaman itu berada dalam kumpulan penimbal, alihkan blok kawalan yang sepadan ke kepala senarai LRU
- Halaman itu tiada dalam kumpulan penimbal Dalam kumpulan penimbal, halaman yang paling kurang digunakan baru-baru ini pada penghujung dihapuskan, halaman dimuatkan daripada cakera dan diletakkan di kepala senarai terpaut LRU
Jadi mengapa InnoDB tidak menggunakan algoritma LRU yang intuitif? Sebabnya adalah seperti berikut:
-
Kegagalan baca ke hadapan
Halaman yang dibaca ke hadapan dalam kolam penimbal akan diletakkan di kepala senarai terpaut LRU, tetapi kebanyakannya Halaman mungkin tidak dibaca.
-
Pencemaran kolam penampan
Memuatkan banyak halaman yang kurang kerap digunakan ke dalam kumpulan penimbal akan mengalih keluar halaman yang lebih kerap digunakan daripada penimbal Dihapuskan daripada kolam . Contohnya, imbasan jadual penuh
Bagaimanakah LRU yang dioptimumkan mengurus halaman penimbal?
Berdasarkan kelemahan di atas, kaedah khusus yang dioptimumkan membahagikan senarai terpaut LRU tradisional kepada dua bahagian: kawasan data panas [kawasan muda] & kawasan data sejuk [kawasan lama]
- Kawasan data panas [Kawasan muda] : Halaman penimbal yang sangat digunakan
- Kawasan data sejuk [Kawasan lama] : Kawasan kurang digunakan
Rajah struktur yang dipermudahkan adalah seperti berikut:
Seperti yang ditunjukkan dalam rajah, kawasan data panas dan kawasan data sejuk masing-masing menduduki perkadaran yang berbeza, maka kita boleh mengawalnya melalui innodb_old_blocks_pct pilihan permulaanPerkadaran kawasan data sejuk.
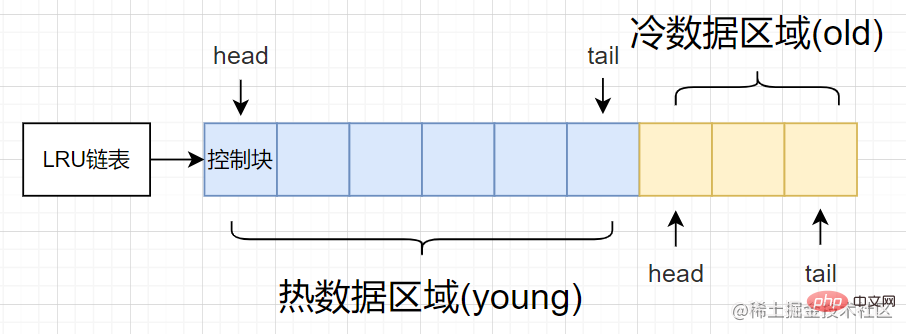
Bagaimanakah LRU yang dipertingkatkan boleh menyelesaikan masalah kegagalan baca-depan dengan lebih baik?
- Apabila halaman dimuatkan ke dalam kumpulan penimbal buat kali pertama, blok kawalan di hujung kawasan data sejuk terlebih dahulu dihapuskan (iaitu halaman yang sepadan dihapuskan) , dan kemudian blok kawalan yang sepadan dengan halaman baharu dihapuskan Blok akan diletakkan di kepala kawasan data sejuk terlebih dahulu.
- Jika halaman tidak diakses kemudiannya, ia akan dihapuskan secara perlahan daripada kawasan data sejuk Secara amnya, ia tidak akan menjejaskan halaman penimbal yang kerap diakses dalam kawasan data panas.
Bagaimanakah LRU yang dipertingkatkan boleh menyelesaikan masalah pencemaran kolam penampan dengan lebih baik?
Izinkan saya bercakap tentang kesimpulannya dahulu. Masalah ini tidak dioptimumkan dengan baik. halaman yang dilawati buat kali pertama juga akan diletakkan di kepala kawasan data sejuk, tetapi akses seterusnya akan meletakkannya di kepala kawasan data panas, yang juga akan menyesakkan halaman dengan kekerapan akses yang lebih tinggi.
- Jadi bagaimana untuk menyelesaikan masalah pencemaran kolam penampan?
Kolam penimbal memperkenalkan mekanisme tetingkap masa kawasan data sejuk, iaitu, hanya jika selang masa antara akses seterusnya ke halaman dan akses pertama ke halaman adalah lebih besar daripada nilai tetingkap yang ditentukan, halaman akan dialih keluar dari kawasan data sejuk Pindah ke kepala kawasan data panas. Jika nilai tetingkap kurang daripada nilai yang ditentukan, operasi bergerak tidak akan dilakukan.
- Begitu juga, nilai tetingkap boleh ditetapkan melalui parameter
- [unit ms]. Lalai ialah 1000ms, dan 1s akan menapis kebanyakan operasi seperti imbasan jadual penuh. Contohnya, semasa imbasan jadual penuh, selang masa antara berbilang akses ke halaman tidak akan melebihi 1 saat.
-
innodb_old_blocks_timeKolam penimbal VS cache pertanyaan
Adakah kumpulan penimbal dan cache pertanyaan adalah perkara yang sama? →Bukan
Kumpulan penimbal akan cuba menyimpan data yang kerap digunakan Apabila MySQL membaca halaman, ia akan terlebih dahulu menentukan sama ada halaman itu berada dalam kumpulan penimbal dibaca secara langsung, jika ia tidak wujud, halaman akan disimpan dalam kumpulan penimbal melalui memori atau cakera dan kemudian dibaca.
- Cache pertanyaan menyimpan hasil pertanyaan terlebih dahulu supaya anda boleh mendapatkan hasil secara langsung tanpa melaksanakannya pada masa akan datang. Perlu diingatkan bahawa cache pertanyaan dalam MySQL tidak menyimpan rancangan pertanyaan, tetapi hasil pertanyaan yang sepadan. Syarat hit adalah ketat, dan selagi jadual data berubah, cache pertanyaan akan menjadi tidak sah, jadi kadar hit adalah rendah.
- [Cadangan berkaitan: tutorial video mysql
Atas ialah kandungan terperinci Membawa anda memahami kumpulan penimbal pangkalan data (Kolam Penampan) dalam MySQL. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1371
1371
 52
52

 Tidak dapat log masuk ke mysql sebagai akar
Apr 08, 2025 pm 04:54 PM
Tidak dapat log masuk ke mysql sebagai akar
Apr 08, 2025 pm 04:54 PM
Sebab utama mengapa anda tidak boleh log masuk ke MySQL sebagai akar adalah masalah kebenaran, ralat fail konfigurasi, kata laluan tidak konsisten, masalah fail soket, atau pemintasan firewall. Penyelesaiannya termasuk: periksa sama ada parameter pengikat di dalam fail konfigurasi dikonfigurasi dengan betul. Semak sama ada kebenaran pengguna root telah diubahsuai atau dipadam dan ditetapkan semula. Sahkan bahawa kata laluan adalah tepat, termasuk kes dan aksara khas. Semak tetapan dan laluan kebenaran fail soket. Semak bahawa firewall menyekat sambungan ke pelayan MySQL.
 mysql sama ada untuk menukar jadual kunci meja
Apr 08, 2025 pm 05:06 PM
mysql sama ada untuk menukar jadual kunci meja
Apr 08, 2025 pm 05:06 PM
Apabila MySQL mengubahsuai struktur jadual, kunci metadata biasanya digunakan, yang boleh menyebabkan jadual dikunci. Untuk mengurangkan kesan kunci, langkah -langkah berikut boleh diambil: 1. Simpan jadual yang tersedia dengan DDL dalam talian; 2. Melakukan pengubahsuaian kompleks dalam kelompok; 3. Beroperasi semasa tempoh kecil atau luar puncak; 4. Gunakan alat PT-OSC untuk mencapai kawalan yang lebih baik.
 Integrasi RDS MySQL dengan Redshift Zero ETL
Apr 08, 2025 pm 07:06 PM
Integrasi RDS MySQL dengan Redshift Zero ETL
Apr 08, 2025 pm 07:06 PM
Penyederhanaan Integrasi Data: AmazonRDSMYSQL dan Integrasi Data Integrasi Zero ETL Redshift adalah di tengah-tengah organisasi yang didorong oleh data. Proses tradisional ETL (ekstrak, menukar, beban) adalah kompleks dan memakan masa, terutamanya apabila mengintegrasikan pangkalan data (seperti Amazonrdsmysql) dengan gudang data (seperti redshift). Walau bagaimanapun, AWS menyediakan penyelesaian integrasi ETL sifar yang telah mengubah keadaan ini sepenuhnya, menyediakan penyelesaian yang mudah, hampir-sebenar untuk penghijrahan data dari RDSMYSQL ke redshift. Artikel ini akan menyelam ke integrasi RDSMYSQL Zero ETL dengan redshift, menjelaskan bagaimana ia berfungsi dan kelebihan yang dibawa kepada jurutera dan pemaju data.
 Hubungan antara pengguna dan pangkalan data MySQL
Apr 08, 2025 pm 07:15 PM
Hubungan antara pengguna dan pangkalan data MySQL
Apr 08, 2025 pm 07:15 PM
Dalam pangkalan data MySQL, hubungan antara pengguna dan pangkalan data ditakrifkan oleh kebenaran dan jadual. Pengguna mempunyai nama pengguna dan kata laluan untuk mengakses pangkalan data. Kebenaran diberikan melalui perintah geran, sementara jadual dibuat oleh perintah membuat jadual. Untuk mewujudkan hubungan antara pengguna dan pangkalan data, anda perlu membuat pangkalan data, membuat pengguna, dan kemudian memberikan kebenaran.
 Adakah Mysql perlu membayar
Apr 08, 2025 pm 05:36 PM
Adakah Mysql perlu membayar
Apr 08, 2025 pm 05:36 PM
MySQL mempunyai versi komuniti percuma dan versi perusahaan berbayar. Versi komuniti boleh digunakan dan diubahsuai secara percuma, tetapi sokongannya terhad dan sesuai untuk aplikasi dengan keperluan kestabilan yang rendah dan keupayaan teknikal yang kuat. Edisi Enterprise menyediakan sokongan komersil yang komprehensif untuk aplikasi yang memerlukan pangkalan data yang stabil, boleh dipercayai, berprestasi tinggi dan bersedia membayar sokongan. Faktor yang dipertimbangkan apabila memilih versi termasuk kritikal aplikasi, belanjawan, dan kemahiran teknikal. Tidak ada pilihan yang sempurna, hanya pilihan yang paling sesuai, dan anda perlu memilih dengan teliti mengikut keadaan tertentu.
 Pengoptimuman pertanyaan di MySQL adalah penting untuk meningkatkan prestasi pangkalan data, terutama ketika berurusan dengan set data yang besar
Apr 08, 2025 pm 07:12 PM
Pengoptimuman pertanyaan di MySQL adalah penting untuk meningkatkan prestasi pangkalan data, terutama ketika berurusan dengan set data yang besar
Apr 08, 2025 pm 07:12 PM
1. Gunakan indeks yang betul untuk mempercepatkan pengambilan data dengan mengurangkan jumlah data yang diimbas memilih*frommployeesWherElast_name = 'Smith'; Jika anda melihat lajur jadual beberapa kali, buat indeks untuk lajur tersebut. Jika anda atau aplikasi anda memerlukan data dari pelbagai lajur mengikut kriteria, buat indeks komposit 2. Elakkan pilih * Hanya lajur yang diperlukan, jika anda memilih semua lajur yang tidak diingini, ini hanya akan memakan lebih banyak pelayan dan menyebabkan pelayan melambatkan pada masa yang tinggi atau kekerapan misalnya, jadual anda
 Bagaimana untuk mengoptimumkan prestasi MySQL untuk aplikasi beban tinggi?
Apr 08, 2025 pm 06:03 PM
Bagaimana untuk mengoptimumkan prestasi MySQL untuk aplikasi beban tinggi?
Apr 08, 2025 pm 06:03 PM
Panduan Pengoptimuman Prestasi Pangkalan Data MySQL Dalam aplikasi yang berintensifkan sumber, pangkalan data MySQL memainkan peranan penting dan bertanggungjawab untuk menguruskan urus niaga besar-besaran. Walau bagaimanapun, apabila skala aplikasi berkembang, kemunculan prestasi pangkalan data sering menjadi kekangan. Artikel ini akan meneroka satu siri strategi pengoptimuman prestasi MySQL yang berkesan untuk memastikan aplikasi anda tetap cekap dan responsif di bawah beban tinggi. Kami akan menggabungkan kes-kes sebenar untuk menerangkan teknologi utama yang mendalam seperti pengindeksan, pengoptimuman pertanyaan, reka bentuk pangkalan data dan caching. 1. Reka bentuk seni bina pangkalan data dan seni bina pangkalan data yang dioptimumkan adalah asas pengoptimuman prestasi MySQL. Berikut adalah beberapa prinsip teras: Memilih jenis data yang betul dan memilih jenis data terkecil yang memenuhi keperluan bukan sahaja dapat menjimatkan ruang penyimpanan, tetapi juga meningkatkan kelajuan pemprosesan data.
 Bolehkah mysql berjalan di Android
Apr 08, 2025 pm 05:03 PM
Bolehkah mysql berjalan di Android
Apr 08, 2025 pm 05:03 PM
MySQL tidak boleh berjalan secara langsung di Android, tetapi ia boleh dilaksanakan secara tidak langsung dengan menggunakan kaedah berikut: menggunakan pangkalan data ringan SQLite, yang dibina di atas sistem Android, tidak memerlukan pelayan yang berasingan, dan mempunyai penggunaan sumber kecil, yang sangat sesuai untuk aplikasi peranti mudah alih. Sambungkan jauh ke pelayan MySQL dan sambungkan ke pangkalan data MySQL pada pelayan jauh melalui rangkaian untuk membaca dan menulis data, tetapi terdapat kelemahan seperti kebergantungan rangkaian yang kuat, isu keselamatan dan kos pelayan.
