

Artikel ini terutamanya menganalisis daripada perspektif struktur storan data InnoDB dalam keadaan bagaimana kecekapan pertanyaan SQL akan dikurangkan. Saya sering melihat beberapa artikel mengadu mengenainya di Internet Apabila jumlah data adalah besar, kecekapan pertanyaan akan dikurangkan dengan banyak. Apabila terdapat banyak jadual yang berkaitan, kecekapan pertanyaan akan berkurangan. Jumlah data dalam satu jadual tidak boleh melebihi satu juta, dsb.

Versi pangkalan data: 8.0 Enjin: InnoDB Bahan rujukan: Buku kecil Nuggets "Memahami Mysql dari Roots". Jika anda mempunyai masa, saya cadangkan anda membacanya sendiri.
Contoh jadual:
CREATE TABLE `hospital_info` ( `pk_id` bigint unsigned NOT NULL AUTO_INCREMENT COMMENT '主键', `id` varchar(36) NOT NULL COMMENT '外键', `hospital_code` varchar(36) NOT NULL COMMENT '医院编码', `hospital_name` varchar(36) NOT NULL COMMENT '医院名称', `is_deleted` tinyint DEFAULT NULL COMMENT '是否删除 0否 1是', `gmt_created` datetime DEFAULT NULL COMMENT '创建时间', `gmt_modified` datetime DEFAULT NULL COMMENT 'gmt_modified', `gmt_deleted` datetime(3) DEFAULT '9999-12-31 23:59:59.000' COMMENT '删除时间', PRIMARY KEY (`pk_id`), KEY `hospital_code` (`hospital_code`) ) ENGINE=InnoDB AUTO_INCREMENT=2 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci COMMENT='医院信息';
Bermula daripada satu baris data, mari kita fahami format storan satu baris dahulu daripada data.
Pada masa ini terdapat 4 format baris, iaitu format baris Kompak, Lewah, Dinamik dan Mampat.
Secara umumnya tidak perlu menyatakannya dengan sengaja apabila membuat jadual Versi 5.7 dan ke atas akan lalai kepada Dinamik.
Setiap format baris adalah serupa Di sini kami mengambil Compact sebagai contoh untuk memahami secara ringkas cara setiap baris data direkodkan. 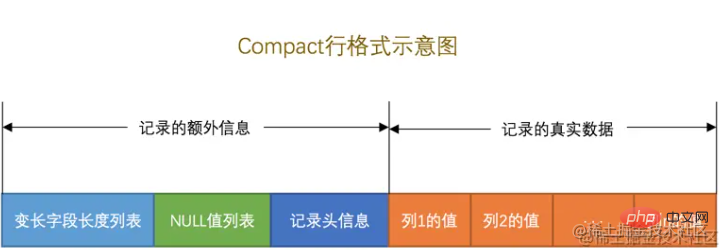
Seperti yang ditunjukkan dalam gambar di atas. Terbahagi kepada dua bahagian: "Maklumat tambahan" dan "Data sebenar".
Ini lebih menarik secara amnya, apabila mentakrifkan medan, anda perlu menentukan jenis dan . panjang,
Contohnya: takrifan medan kod_hospital dalam jadual sampel ialah VARCHAR(36). Dalam penggunaan sebenar, panjang medan hospital_code hanya menggunakan 32 bit.
Apakah yang akan berlaku kepada baki 4 aksara? Jika anda mengisi secara paksa aksara kosong, bukankah ia akan membazir 4 aksara memori. Jika ia tidak diisi, bagaimana untuk menentukan berapa banyak aksara yang disimpan dalam medan semasa? Berapa banyak memori yang diperlukan?
Pada masa ini, senarai medan panjang berubah akan berada dalam susunan terbalik mengikut medan , menggunakan 1~2 bait untuk merekodkan panjang sebenar setiap medan panjang berubah. Ini boleh menggunakan ruang memori dengan berkesan.
Medan yang serupa: VARBINAR, pelbagai jenis TEKS, pelbagai jenis BLOB.
Sejajar dengan itu, terdapat "medan panjang tetap", seperti: CHAR(10) Medan jenis ini akan menduduki ruang panjang aksara yang ditentukan secara lalai semasa pemulaan tidak mencukupi Kemudian isikan aksara kosong, jadi ia adalah satu pembaziran ruang Secara umumnya disyorkan untuk menetapkan panjang mengikut keperluan.
Sudah tentu, "senarai medan panjang boleh ubah" tidak semestinya wujud Jika jenis medan yang ditentukan tidak mempunyai "medan panjang boleh ubah", ia tidak akan wujud.
Sambungan: Untuk medan jenis TEKS atau BLOB, panjangnya mungkin tidak disimpan pada satu halaman Dalam kes ini, kebanyakan data akan direkodkan di halaman lain dan dikekalkan dalam arus rekod.
Apabila sebenarnya menyimpan data, sesetengah lajur mungkin menyimpan nilai NULL, jika nilai ini semua direkodkan dalam In real data, ruang simpanan akan terbuang. Dalam format Kompak, lajur dengan nilai NULL ini diurus secara seragam dan disimpan dalam senarai nilai NULL.
Jika tiada medan dalam satu baris data ialah NULL, lajur ini tidak akan dijana.
Kaedah penyimpanan juga agak menarik, ia adalah mod binari rakaman dalam susunan terbalik.
Menggunakan jadual sampel untuk menganalisis, terdapat tiga medan dalam jadual: is_deleted, gmt_created dan gmt_modified, yang mungkin kosong . Dengan mengandaikan bahawa gmt_created dan gmt_modified kedua-duanya kosong dalam rekod, senarai nilai NULL yang sepadan sepatutnya kelihatan seperti berikut.
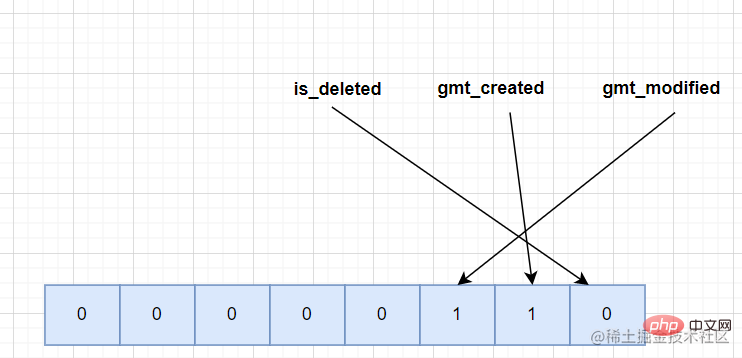
Peluasan: Mysql menyokong storan data binari, dan penggunaan penuh boleh mengurangkan sejumlah besar ruang storan.
Maklumat pengepala rekod terdiri daripada 5 aksara tetap, iaitu 40 bit perduaan panjangnya.
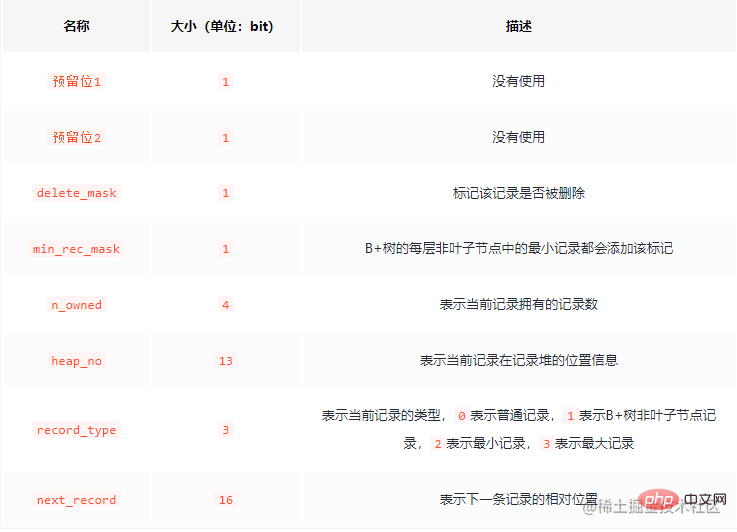
Pertama sekali, sebagai pemahaman, berikut adalah logo yang lebih menarik: delete_mask Sesiapa yang telah menggunakan redis tahu bahawa data yang dipadam dalam redis akan tidak Ia akan dikosongkan serta-merta. Perkara yang sama berlaku dalam mysql yang sama Data yang dipadam tidak akan dikosongkan serta-merta kerana proses pembersihan akan menyebabkan operasi IO, yang sangat menjejaskan kecekapan. Data yang dipadamkan akan membentuk senarai terpaut , yang boleh digunakan sebagai ruang boleh guna semula.
Sebenarnya tiada apa yang boleh dikatakan tentang perkara ini, ia adalah untuk merekodkan data bukan NULL sebenar.
Terdapat soalan yang sering dilihat dalam talian: Apakah yang berlaku jika kunci utama tidak ditetapkan?
Di bawah InnoDB, kunci utama ialah pengecam unik rekod Jika pengguna tidak menyatakannya, mysql akan memilih satu daripada kunci unik (unik) sebagai kunci utama tiada kunci Unik, Lajur tersembunyi bernama id_baris akan ditambahkan sebagai kunci utama.
Selain itu, dua lajur transaction_id (transaction ID) dan roll_pointer (rollback pointer) akan ditambahkan.
Format empat baris adalah serupa, jadi saya tidak akan memperkenalkannya satu demi satu. Mereka dibahagikan kepada dua bahagian: "maklumat tambahan" dan ". data sebenar". Perbezaannya adalah terutamanya dalam kandungan rekod "maklumat tambahan" dan penyimpanan medan panjang berubah-ubah.
Konsep halaman data mungkin biasa kepada anda. Ia adalah unit asas untuk InnoDB untuk mengurus ruang storan Saiz satu halaman secara amnya 16KB. Pelbagai jenis halaman direka bentuk mengikut tujuan yang berbeza, seperti: halaman untuk menyimpan maklumat pengepala ruang jadual, halaman untuk menyimpan maklumat Sisipkan Penimbal, halaman untuk menyimpan maklumat INODE , halaman untuk menyimpan maklumat INODE, 🎜>buat asal
halaman maklumat log, dsb.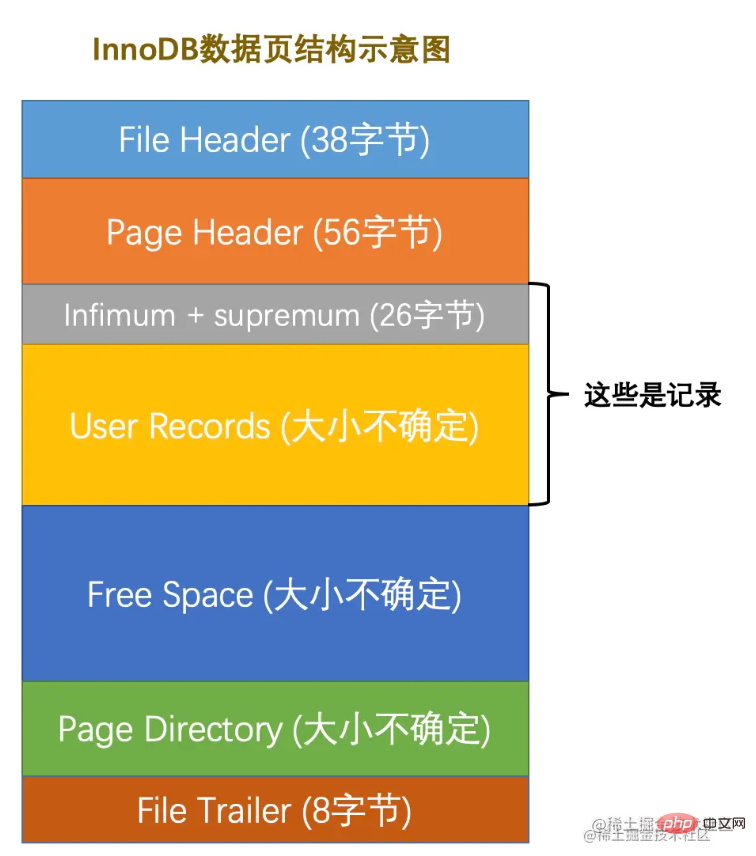 Ruang halaman dibahagikan seperti berikut:
Ruang halaman dibahagikan seperti berikut:
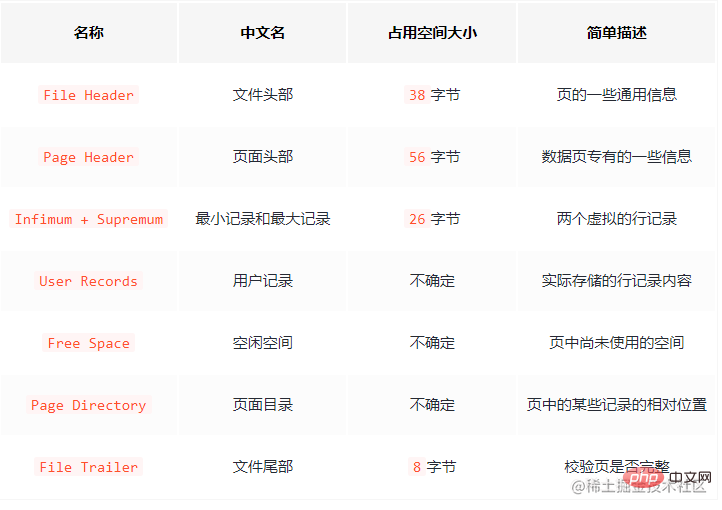
Terdapat banyak atribut dalam Pengepala fail dan Pengepala halaman Saya tidak akan memperkenalkannya satu per satu di sini asalkan anda tahu kedua-dua ini Rekod secara setempat beberapa atribut halaman , seperti: nombor halaman, nombor halaman halaman sebelumnya dan seterusnya, jenis halaman dan penggunaan memori halaman, dsb. Biar saya bercakap di sini, halaman disambungkan oleh senarai pautan berganda. Rekod data ialah jadual rantai tunggal
.Treler Fail
digunakan untuk mengesahkan integriti data halaman Apabila data halaman ditulis semula dari memori ke cakera, ia perlu disahkan untuk mengelakkan kerosakan halaman data.Fokus pada Rekod Pengguna (ruang terpakai) dan Ruang Bebas (ruang yang tinggal)
, berikut ialah rekod data sebenar yang disimpan.Selain itu, Infimum dan Supremum
mengenal pasti rekod minimum dan maksimum masing-masing. Iaitu, apabila halaman dijana, ia akan mengandungi dua rekod ini secara lalai, tetapi jangan risau, kedua-dua rekod ini hanya digunakan sebagai kepala dan ekor senarai terpaut data dan tidak menjejaskan data sebenar. Ringkasnya, penyimpanan rekod dalam halaman adalah seperti berikut: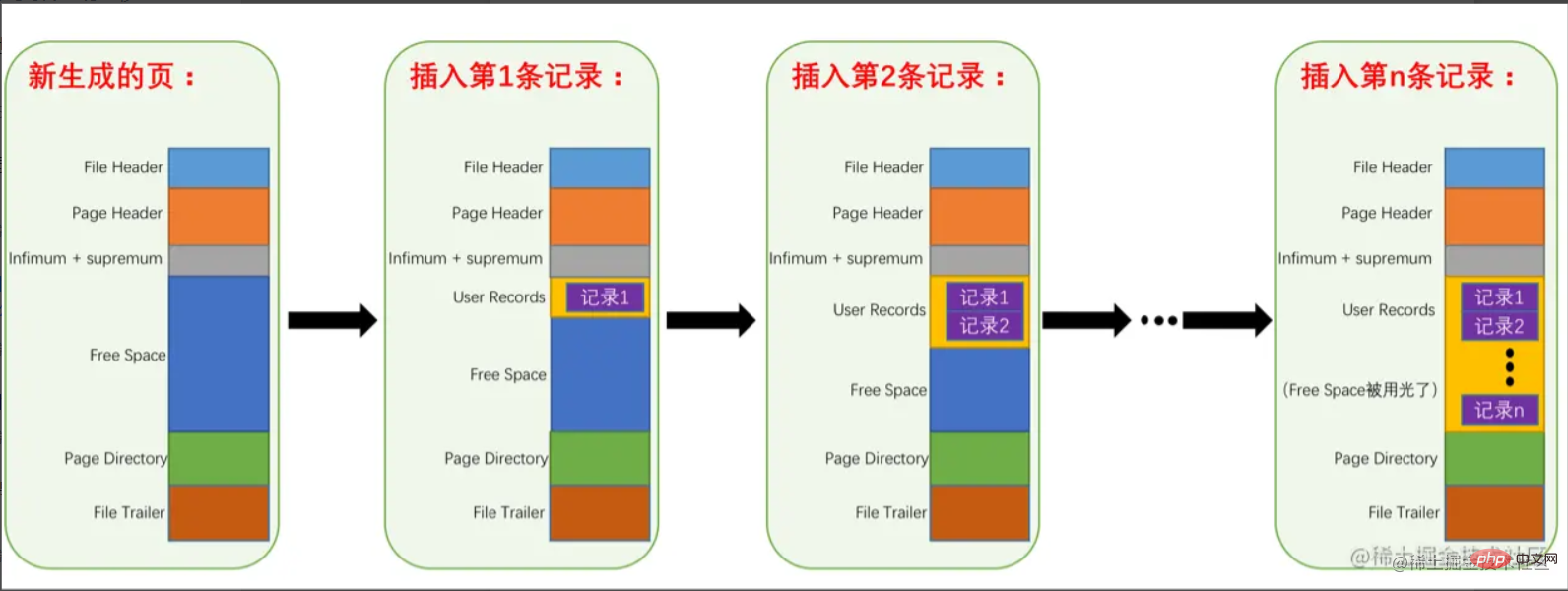 Ringkasnya, ia adalah penukaran
Ringkasnya, ia adalah penukaran
Pada ketika ini, data telah ditulis ke dalam halaman data. Bagaimana untuk mengeluarkannya? Kami tahu di atas bahawa rekod data terdiri daripada senarai pautan tunggal Adakah kita perlu bermula daripada rekod Infimum
(minimum) dan merentasi sepanjang senarai terpaut? Jelas sekali, bos pembangunan MySQL tidak boleh begitu bodoh, jika tidak, saya boleh melakukannya, haha.Di sini kami akan menyebut Direktori Halaman (direktori halaman). Dalam halaman, data dikumpulkan dan alamat mengimbangi rekod terakhir dalam setiap kumpulan diekstrak secara berasingan dan disimpan mengikut urutan dalam "direktori halaman" berhampiran penghujung halaman direktori halaman adalah Jumlah anjakan dipanggil "slot". Selain itu, pengepala rekod terakhir (n_owned
) juga menyimpan berapa banyak rekod yang terdapat dalam kumpulan.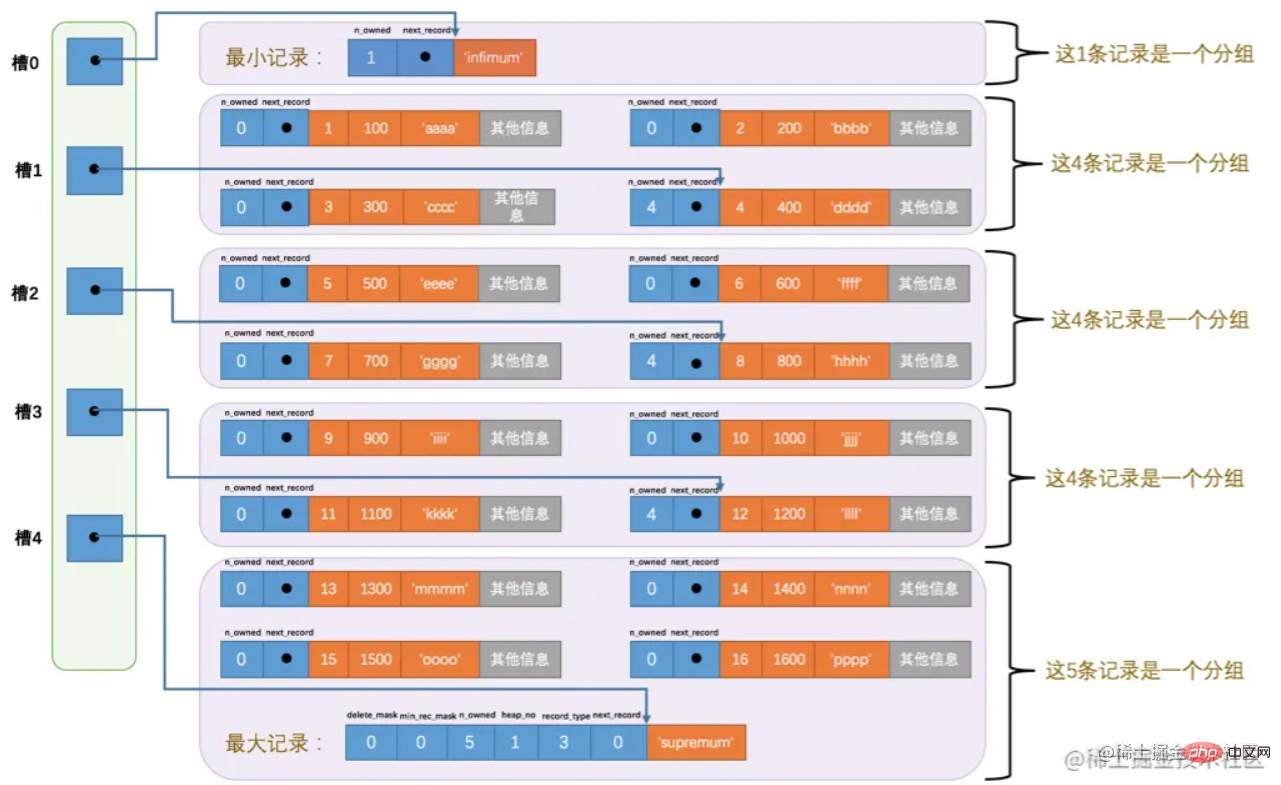 Direktori halaman terdiri daripada slot.
Gambar rajah struktur keseluruhan adalah seperti berikut:
Direktori halaman terdiri daripada slot.
Gambar rajah struktur keseluruhan adalah seperti berikut:
Selepas mempunyai direktori, pertanyaannya agak mudah. Anda boleh menggunakan kaedah dikotomi
untuk carian pantas. Dalam rajah di atas, kita tahu bahawa slot minimum ialah 0 dan maksimum ialah 4. Contohnya: Katakan anda ingin menanyakan data yang rekod kunci utamanya ialah 6. 1) Kira kedudukan slot tengah, iaitu (0+4)/2 = 2. Kunci utama rekod yang sepadan dengan slot yang diekstrak ialah 8, kerana 8>6. 2) Dengan cara yang sama, tetapkan slot terbesar kepada 2, iaitu, (0+2)/2 =1 Kunci utama yang sepadan dengan slot 1 ialah 4, kerana 4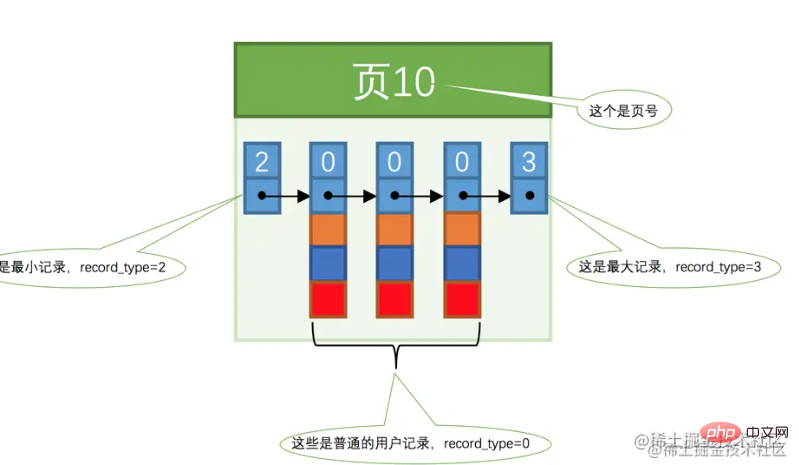 Untuk memudahkan penerangan seterusnya, borang data halaman dipermudahkan seperti yang ditunjukkan dalam rajah di bawah.
Untuk memudahkan penerangan seterusnya, borang data halaman dipermudahkan seperti yang ditunjukkan dalam rajah di bawah. 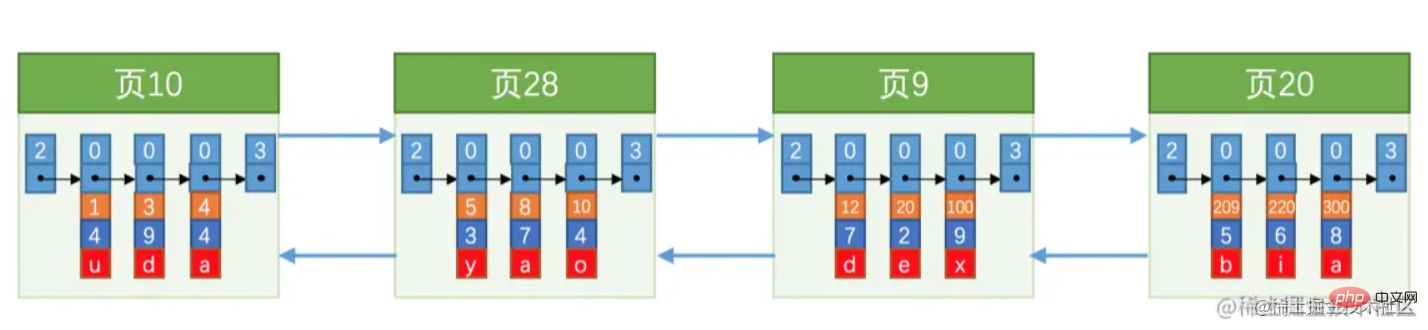 Anda juga boleh memikirkan tentang soalan, seperti yang dinyatakan sebelum ini. Halaman data dipautkan menggunakan senarai pautan berganda, kira-kira seperti yang ditunjukkan dalam rajah di bawah: Seperti yang dapat dilihat daripada rajah di atas, nombor halaman tidak berturut-turut dan tidak semestinya ruang ingatan yang berterusan (ingat ayat ini akan disebut kemudian)
Anda juga boleh memikirkan tentang soalan, seperti yang dinyatakan sebelum ini. Halaman data dipautkan menggunakan senarai pautan berganda, kira-kira seperti yang ditunjukkan dalam rajah di bawah: Seperti yang dapat dilihat daripada rajah di atas, nombor halaman tidak berturut-turut dan tidak semestinya ruang ingatan yang berterusan (ingat ayat ini akan disebut kemudian)
Dengan mengandaikan setiap halaman boleh menyimpan 3 rekod, dan kini terdapat 100,000 rekod yang perlu disimpan, lebih daripada 30,000 halaman data akan diperlukan Pada masa ini, kami akan menghadapi masalah pertanyaan yang sama seperti terlalu banyak data pada a satu halaman, dan kita tidak boleh melintasinya satu demi satu. Pada masa ini, direktori yang boleh ditanya dengan cepat juga diperlukan. Direktori ini ialah "Indeks".
Berdasarkan halaman data yang ditunjukkan dalam rajah di atas, struktur indeks berikut boleh dibentuk: 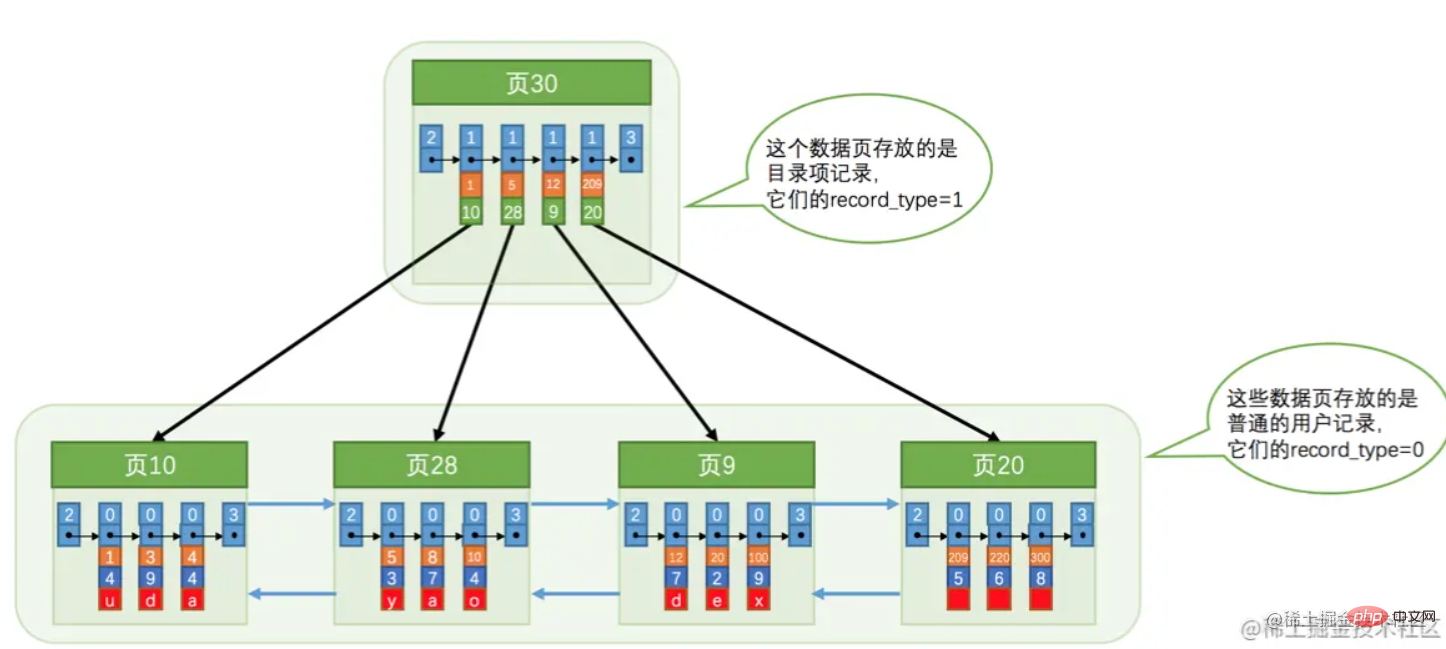 Inilah yang sering dipanggil indeks berkelompok , dan daun adalah data. Satu perkara yang perlu diperhatikan di sini ialah "Halaman 30" menyimpan kunci utama dan nombor halaman di mana ia berada.
Jika satu halaman indeks penuh, ia akan dipecahkan. Menghasilkan struktur pokok seperti yang ditunjukkan di bawah.
Inilah yang sering dipanggil indeks berkelompok , dan daun adalah data. Satu perkara yang perlu diperhatikan di sini ialah "Halaman 30" menyimpan kunci utama dan nombor halaman di mana ia berada.
Jika satu halaman indeks penuh, ia akan dipecahkan. Menghasilkan struktur pokok seperti yang ditunjukkan di bawah. 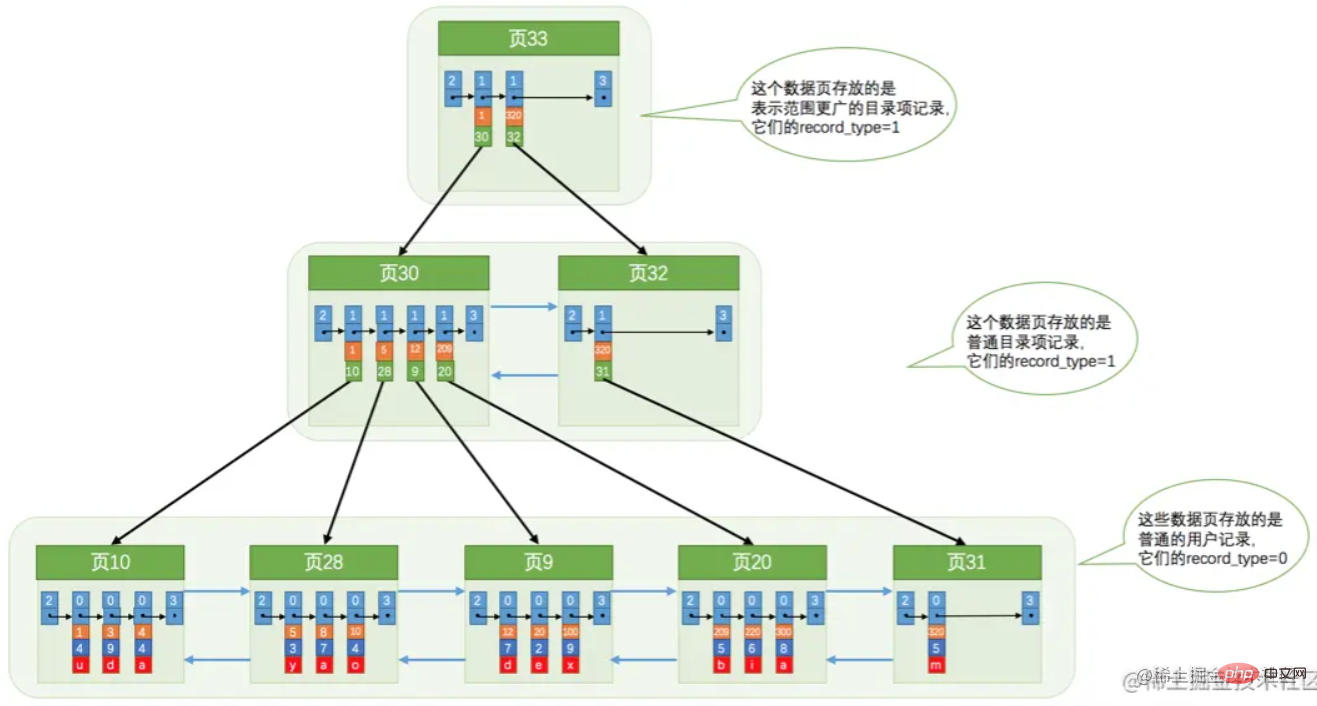 Namun, gambar di atas tidak tepat sepenuhnya untuk kemudahan pengenalan. Nod akar harus dijana terlebih dahulu, dan apabila nod akar penuh, ia akan berpecah. Nod akar merekodkan maklumat halaman indeks selepas pemisahan.
Namun, gambar di atas tidak tepat sepenuhnya untuk kemudahan pengenalan. Nod akar harus dijana terlebih dahulu, dan apabila nod akar penuh, ia akan berpecah. Nod akar merekodkan maklumat halaman indeks selepas pemisahan.
Ringkasnya, ia sama seperti pertumbuhan pokok, bermula dari akar dan kemudian ke batang, dahan, daun, dll.
Indeks sekunder mempunyai idea yang sama dengan indeks berkelompok Perbezaannya ialah nod daun indeks sekunder bukan data sebenar, tetapi kunci utama data. Anda perlu melakukan operasi return table untuk mendapatkan data sebenar.
Setakat ini, kami telah mengetahui struktur storan bagi sekeping data dan halaman unit data storan terkecil. Halaman data disambungkan melalui senarai pautan berganda, dan halaman data tidak semestinya berterusan.
Pada masa ini, masalah timbul Bagaimana jika halaman rekod dalam jadual yang sama berada terlalu jauh dalam alamat memori? Bayangkan bahawa untuk mencari tiga orang, mereka pergi ke Beijing, New York, dan London masing-masing. Anda perlu mencari mereka satu demi satu dan membuang banyak masa dalam perjalanan. Jika anda mengumpulkannya di negara atau bandar, ia akan menjadi lebih cepat.
Maka lahirlah konsep Daerah. Satu kawasan terdiri daripada 64 halaman berturut-turut Secara lalai, kawasan menduduki 1J memori. Apabila memohon memori, ia menduduki 1M ruang pada satu masa, dan halaman data bersebelahan, yang menyelesaikan masalah IO rawak pada tahap tertentu.
Berdasarkan zon, untuk meningkatkan kecekapan pertanyaan dengan lebih berkesan, nod daun dan nod bukan daun bagi pokok B+ direkodkan dalam zon berbeza Set zon ini dipanggil " segmen.)”. Di bawah konsep ini, untuk memasukkan rekod pertama, anda perlu memohon 2 ruang kawasan, nod akar indeks berkelompok dan halaman data Kali ini, anda perlu memohon 2M ruang! Saya tidak melakukan apa-apa, dan ruang 2M hilang Adakah ini munasabah? Jelas sekali, ini tidak munasabah.
Oleh itu, konsep "Kawasan Pecahan" telah dicipta. Kawasan berserpihan tergolong terus ke ruang meja dan tidak tergolong dalam mana-mana segmen. Proses memperuntukkan memori berubah kepada:
1) Apabila data pertama kali dimasukkan, ruang storan diperuntukkan sebagai satu halaman dari kawasan serpihan.
2) Apabila segmen telah menduduki 32 halaman kawasan serpihan, ruang akan diperuntukkan sebagai kawasan yang lengkap.
ruang jadual juga dibahagikan kepada: ruang jadual sistem dan ruang meja bebas , sebagai tambahan kepada struktur data XDES Entry zon. Kandungannya terlalu banyak dan rumit Jika anda perlu tahu lebih lanjut, anda boleh membaca buku asal.
1) Adakah lebih banyak indeks lebih baik? Apakah kesan yang akan ada jika lebih banyak?
Semakin banyak, semakin baik Seperti yang anda boleh lihat daripada di atas, rekod indeks juga memerlukan penggunaan memori. Setiap indeks sepadan dengan pokok B+, dan setiap pokok memerlukan dua segmen untuk merekodkan nod daun dan nod bukan daun masing-masing. Ini akan menyebabkan banyak pembaziran ingatan. Ini tidak boleh diterima Lagipun, maksud indeks itu sendiri adalah untuk menukar ruang untuk masa. Tetapi kita perlu tahu bahawa penambahan, pemadaman dan pengubahsuaian data akan membawa kepada perubahan dalam indeks, yang memerlukan indeks untuk mengagihkan semula nod dan kitar semula dan peruntukan memori halaman. Ini semua adalah operasi IO Jika terdapat terlalu banyak indeks, ia pasti akan membawa kepada penurunan prestasi.
Oleh itu, penggunaan indeks bersama yang munasabah boleh menyelesaikan masalah indeks tunggal yang terlalu banyak. Selain itu, indeks mempunyai had panjang dan medan yang terlalu panjang tidak sesuai untuk pengindeksan.
2) Mengapakah kecekapan pertanyaan indeks begitu tinggi?
Ini sebenarnya adalah masalah algoritma Ambil indeks berkelompok sebagai contoh Andaikan bahawa halaman indeks nod bukan daun setiap satu boleh merekodkan 1000 keping data, dan setiap nod daun boleh merekodkan 500 keping. data. A 3 Pokok B+ lapisan (tidak mengira nod akar) boleh menyimpan 10001000500 rekod. Indeks dengan struktur tiga lapisan boleh menyimpan begitu banyak rekod. Ia hanya memerlukan beberapa pertanyaan untuk mencari data setiap kali, jadi kecekapan adalah tinggi secara semula jadi.
Malah, data yang boleh direkodkan pada satu halaman indeks adalah jauh lebih besar daripada ini.
Begitu juga, anda boleh memikirkan masalah di sini Jika sekeping data dalam nod daun sangat besar, begitu besar sehingga halaman data hanya boleh menyimpan 3 rekod, maka kedalaman pepohon B+ akan. meningkat, jadi ia boleh dikurangkan dengan munasabah Saiz rekod tunggal dalam jadual juga merupakan pengoptimuman.
3) Jika jumlah data adalah besar, adakah SQL akan dilaksanakan dengan perlahan?
Sebenarnya, saya sangat ingin mengadu tentang isu ini Kecekapan pertanyaan berjuta-juta data ialah xx saat, yang terlalu perlahan. Tidak dapat dinafikan bahawa prestasi mysql sememangnya lebih lemah daripada beberapa pangkalan data, tetapi ia akan menjadi perlahan dengan berjuta-juta data Fikirkan sama ada reka bentuk struktur SQL dan jadual anda adalah munasabah. Belum lagi berjuta-juta tahap, malah berpuluh-puluh juta tahap boleh mencapai pertanyaan peringkat milisaat. Hanya bercakap tentang kuantiti adalah karut Anda perlu melihat saiz memori yang diduduki oleh kunci Jika terdapat beratus-ratus medan dalam jadual anda, atau terdapat medan dengan aksara yang sangat panjang. Kemudian tuhan pun tidak dapat menyelamatkan kamu.
Artikel ini terutamanya memperkenalkan konsep struktur data MySql, dan kebanyakan kandungan datang daripada buku "Memahami Mysql daripada Akar". Banyak penyederhanaan telah dibuat, yang boleh menjadi asas untuk memahami beberapa konsep.
Sekiranya terdapat sebarang kesilapan atau ketinggalan, terima kasih kerana membetulkannya.
[Cadangan berkaitan: tutorial video mysql]
Atas ialah kandungan terperinci Analisis ringkas tentang struktur penyimpanan data dalam MySQL. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 mysql mengubah suai nama jadual data
mysql mengubah suai nama jadual data
 MySQL mencipta prosedur tersimpan
MySQL mencipta prosedur tersimpan
 Pangkalan data tiga paradigma
Pangkalan data tiga paradigma
 Perbezaan antara mongodb dan mysql
Perbezaan antara mongodb dan mysql
 Bagaimana untuk menyemak sama ada kata laluan mysql terlupa
Bagaimana untuk menyemak sama ada kata laluan mysql terlupa
 mysql mencipta pangkalan data
mysql mencipta pangkalan data
 tahap pengasingan transaksi lalai mysql
tahap pengasingan transaksi lalai mysql
 Perbezaan antara sqlserver dan mysql
Perbezaan antara sqlserver dan mysql


![Penyelesaian pengoptimuman pertanyaan MySQL [diajar oleh arkitek daripada pengeluar utama] [Bermula dengan Penalaan MySQL |](https://img.php.cn/upload/course/000/000/068/6242a7d5be236814.png)








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



