

Algoritma diff ialah algoritma cekap yang membandingkan nod pokok pada tahap yang sama, mengelakkan keperluan untuk mencari dan melintasi pokok lapisan demi lapisan. Jadi berapa banyak yang anda tahu tentang algoritma diff? Artikel berikut akan memberi anda analisis mendalam tentang algoritma perbezaan vue2. Saya harap ia akan membantu anda!

Disebabkan saya sering bertanya tentang algoritma Diff semasa menonton temuduga secara langsung sebelum ini, dan penulis sendiri banyak menggunakan Vue2, jadi saya bercadang untuk mengkaji algoritma Diff Vue2 In Sebenarnya, saya telah lama ingin mempelajarinya Ya, tetapi mungkin kerana saya merasakan bahawa algoritma Diff adalah agak mendalam, saya telah menangguhkan mempelajarinya Tetapi baru-baru ini saya sedang bersiap untuk temu duga, jadi saya fikir saya akan melakukannya belajar cepat atau lambat Mengapa tidak mengambil peluang ini untuk memahami algoritma Diff. Selepas beberapa penyelidikan, saya mungkin tidak memahami intipati algoritma Diff.
? Ini sebenarnya adalah nota kajian penulis, dan tahap pengarang adalah terhad dan mereka akan terus diperbaiki Pada masa yang sama, artikel ini sangat panjang, jadi Pembaca, sila baca dengan sabar Selepas membaca ini, penulis percaya bahawa anda akan mempunyai pemahaman yang lebih mendalam tentang algoritma Diff. Saya rasa artikel ini lebih baik daripada kebanyakan artikel di Internet yang sedang menerangkan algoritma Diff, kerana artikel ini bermula dari masalah dan mengajar semua orang cara berfikir, dan bukannya bermula terus daripada jawapan, sama seperti membaca jawapan, yang terasa. Tidak bermakna. Artikel ini menerangkan langkah demi langkah Bimbing semua orang untuk merasai kehalusan algoritma Diff, dan akhirnya melakukan percubaan kecil untuk memberikan semua orang rasa yang lebih intuitif untuk algoritma Diff.
Kerana lapisan bawah Vue2 menggunakan DOM maya untuk mewakili halaman Structural, DOM maya sebenarnya adalah objek Jika anda ingin mengetahui cara menjananya, proses umum ialah:
.vue fail (ia mungkin menambah, memadam atau Kemas Kini) Ia hanya mengambil satu langkah, iaitu jumlah minimum kemas kini. Jadi bagaimana untuk mencapai jumlah kemas kini minimum? Kemudian kita perlu menggunakan algoritma Diff Jadi apakah sebenarnya yang dibandingkan dengan algoritma Diff? Mungkin ini adalah salah faham mudah tentang algoritma Diff apabila anda mula-mula mempelajarinya Malah, yang dibandingkan ialah DOM maya lama dan baharu, jadi algoritma Diff adalah untuk mencari perbezaan, mencari perbezaan antara. dua DOM maya, dan kemudian mencerminkan perbezaan ke Pada halaman, ini mencapai jumlah kemas kini terkecil Jika hanya tempat yang diubah dikemas kini, prestasi pasti akan menjadi lebih baik.
Object.defineProperty, jadi tanggungan dikumpulkan di sini, kemudian siapa yang mengumpul tanggungan? Ia adalah setiap komponen. Setiap komponen ialah Pemerhati, yang akan merekodkan semua pembolehubah get (iaitu, kebergantungan) sudah tentu, setiap kebergantungan (Dep) juga akan mengumpulnya lokasi sendiri.
Object.defineProperty akan dicetuskan dalam fungsi ini, data akan memberitahu setiap Pemerhati untuk mengemas kini halaman , dan kemudian setiap halaman akan Kaedah kemas kini akan dipanggil, kaedah ini set patch
sebenarnya, saya mengemas kini semasa mencari. memisahkan dua bahagian ini
Apabila ditanya dalam temu bual apakah algoritma Diff, semua orang pasti akan menyebut beberapa perkataan, seperti 头头、尾尾、尾头、头尾, 深度优先遍历(dfs), 同层比较 dan seumpamanya Walaupun perkataan ini boleh disebut dalam satu atau dua ayat, ia hanya dangkal.
Malah, penulis membaca artikel mengenai algoritma Diff yang diterbitkan di CSDN, yang merupakan artikel yang sangat dibaca Penulis merasakan bahawa dia tidak memahaminya dengan jelas, atau dia memahaminya tetapi tidak menjelaskannya ia dengan jelas. Kemudian penulis akan menggunakan sendiri Biar saya berkongsi pandangan saya dengan anda.
Agar semua orang faham dengan jelas, berikut ialah proses panggilan fungsi:
Algoritma diff 前提 Ini sangat penting Anda mungkin bertanya apakah prasyaratnya? Bukankah hanya perbandingan yang disebutkan sebelum ini? Anda betul tetapi tidak betul, kerana premis langkah ini sebelum algoritma Diff mencapai 头头、尾尾、尾头、头尾 ialah nod yang dibandingkan dua kali ialah 相同的 Persamaan di sini tidak betul-betul sama seperti yang difikirkan oleh semua orang, tetapi ia adalah sama jika ia memenuhi syarat-syarat tertentu untuk memudahkan penerangan, artikel hanya mengambil kira tag yang hanya mengandungi key dan 标签名(tag), maka sama seperti yang dinyatakan sebelum ini ialah key 相同以及 tag 相同 untuk membuktikan bahawa kenyataan penulis itu agak betul, kod sumber juga disiarkan di sini:
// https://github.com/vuejs/vue/blob/main/src/core/vdom/patch.ts
// 36行
function sameVnode(a, b) {
return (
a.key === b.key &&
a.asyncFactory === b.asyncFactory &&
((a.tag === b.tag &&
a.isComment === b.isComment &&
isDef(a.data) === isDef(b.data) &&
sameInputType(a, b)) ||
(isTrue(a.isAsyncPlaceholder) && isUndef(b.asyncFactory.error)))
)
}Jika anda takut kekeliruan, anda boleh meninggalkan perkara berikut dan ia tidak akan menjejaskan pemahaman keseluruhan situasi: Jadi jika kedua-dua DOM maya tidak sama, tidak perlu terus membandingkan, dan jika mereka sama, tidak perlu membandingkan Persamaan di sini adalah betul-betul sama, iaitu, alamat kedua-duanya DOM maya adalah sama, jadi tampal juga kod sumber:
function patchVnode(......) {
if (oldVnode === vnode) {
return
}
......
}Setakat ini, semua orang mungkin keliru sekarang:
patch Jika ia tidak sama, gantikan sahaja jika ia sama, gunakan key 相同以及 tag 相同patchVnode Barulah algoritma Diff akan dipertimbangkan Jika tidak sepadan, padamkan sahaja yang asal satu dan gantikannya dengan DOM baharu. 相同的
kod sumber adalah dalam baris 638 hingga 655 daripadaMalah, pengenalan patchVnode semasa diperkenalkan secara langsung kepada kod sumber, tetapi anda mungkin tidak tahu mengapa ia diklasifikasikan dengan cara ini, jadi penulis di sini untuk memberitahu anda mengapa ia berlaku dikelaskan dengan cara ini. Pertama sekali, Berikut ialah kesimpulan:patch.ts.
text ini memerlukan anda melihat pada bahagian kod sumber parsing template children dan text, maka akan terdapat sembilan situasi berikut children
按照上面的表格,因为如果新节点有文本节点,其实老节点不管是什么都会被替换掉,那么就可以按照 新节点 text 是否存在来分类,其实 Vue 源码也是这么来分类的:
if (isUndef(vnode.text)) {
// 新虚拟 DOM 有子节点
} else if (oldVnode.text !== vnode.text) {
// 如果新虚拟 DOM 是文本节点,直接用 textContent 替换掉
nodeOps.setTextContent(elm, vnode.text)
}那么如果有子节点的话,那应该怎么分类呢?我们可以按照每种情况需要做什么来进行分类,比如说:
textContent 设置为 ''textContent 设置为 ''textContent 设置为 '' 后再加入新的子节点那么通过以上六种情况 (新虚拟 DOM 不含有 text,也就是不是文本节点的情况),我们可以很容易地进行归类:
第二种情况 和 第三种情况。进行的是操作是:把原来 DOM 的 textContent 设置为 ''第四种情况 和 第六种情况。进行的是操作是:如果老虚拟 DOM 有 text,就置空,然后加入新的子节点第五种情况。进行的是操作是:需要进行精细比较,即对比新老子节点的不同其实源码也是这么来进行分类的,而且之前说的 同层比较 也就得出来了,因为每次比较都是比较的同一个父节点每一个子元素 (这里的子元素包括文本节点和子节点) 是否相同,而 深度优先遍历(dfs) 是因为每次比较中,如果该节点有子节点 (这里的子节点指的是有 children 属性,而不包括文本节点) 的话需要进行递归遍历,知道最后到文本节点结束。
⭕️ 这里需要搞清楚子节点和子元素的区别和联系
然后我们来看看源码是怎么写吧,只看新虚拟 DOM 不含有 text,也就是不是文本节点的情况:
if (isUndef(vnode.text)) {
if (isDef(oldCh) && isDef(ch)) {
if (oldCh !== ch)
// 递归处理,精细比较
// 对应分类 3️⃣
updateChildren(elm, oldCh, ch, insertedVnodeQueue, removeOnly)
} else if (isDef(ch)) {
if (__DEV__) {
checkDuplicateKeys(ch) // 可以忽略不看
}
// 对应分类 2️⃣
if (isDef(oldVnode.text)) nodeOps.setTextContent(elm, '')
addVnodes(elm, null, ch, 0, ch.length - 1, insertedVnodeQueue)
} else if (isDef(oldCh)) {
// 对应分类 1️⃣
removeVnodes(oldCh, 0, oldCh.length - 1)
} else if (isDef(oldVnode.text)) {
// 对应分类 1️⃣
nodeOps.setTextContent(elm, '')
}
}❓我们可以看到源码把分类 1️⃣ 拆开来了,这是因为如果老虚拟 DOM 有子节,那么可能绑定了一些函数,需要进行解绑等一系列操作,作者也没自信看,大致瞄了一眼,但是如果我们要求不高,如果只是想自己手动实现 Diff 算法,那么没有拆开的必要。
作者觉得这么讲可能比网上其他介绍 Diff 算法的要好,其他的可能直接给你说源码是怎么写的,可能没有说明白为啥这么写,但是通过之前这么分析讲解后可能你对为什么这么写会有更深的理解和帮助吧。
同层比较
因为当都含有子节点,即都包含 children 属性后,需要精细比较不同,不能像之前那些情况一样进行简单处理就可以了
那么这个函数中就会介绍大家经常说的 头头、尾尾、尾头、头尾 比较了,其实这不是 Vue 提出来的,是很早就提出来的算法,就一直沿用至今,大家可以参考【snabbdom 库】
? 在这之前我们要定义四个指针 newStartIdx、newEndIdx、oldStartIdx 和 oldEndIdx,分别指向 新头节点、新尾节点、旧头节点 与 旧尾节点
循环条件如下:
while(oldStartIdx <= oldEndIdx && newStartIdx <= newEndIdx) {
......
}其实这个比较也就是按人类的习惯来进行比较的,比较顺序如下 :
新头节点与旧头节点:++newStartIdx 和 ++oldStartIdx新尾节点与旧尾节点:--newEndIdx 和 --oldEndIdx新尾节点与旧头节点:需要将 旧头节点 移动到 旧尾节点之前,为什么要这么做,讲起来比较复杂,记住就好,然后 --newEndIdx 和 ++oldStartIdx新头节点与旧尾节点:需要将 旧尾节点 移动到 旧头节点之前,为什么要这么做,讲起来比较复杂,记住就好,然后 ++newStartIdx 和 --oldEndIdx新头节点 在旧节点列表 (也就是 children 属性的值) 中进行查找,查找方式按照如下:key 就把 key 在 oldKeyToIdx 进行匹配,oldKeyToIdx 根据旧节点列表中元素的 key 生成对应的下标新头节点 添加到 旧头节点 之前即可旧头节点 之前undefined根据循环条件我们可以得到两种剩余情况,如下:
oldStartIdx > oldEndIdx 说明老节点先遍历完成,那么新节点比老节点多,就要把 newStartIdx 与 newEndIdx 之间的元素添加newStartIdx > newEndIdx 说明新节点先遍历完成,那么老节点比新节点多,就要把 oldStartIdx 与 oldEndIdx 之间的元素删除其实我们上面还没有考虑如果节点为 undefined 的情况,因为在上面也提到过,如果四种都不匹配后会将该节点置为 undefined,也只有旧节点列表中才有,因此要在开头考虑这两种情况:
oldStartVnode 为 undefined:++oldStartIdxoldEndVnode 为 undefined:--oldEndIdx那么我们来看源码怎么写的吧,其中用到的函数可以查看源码附录:
// https://github.com/vuejs/vue/blob/main/src/core/vdom/patch.ts
// 439 行至 556 行
while (oldStartIdx <= oldEndIdx && newStartIdx <= newEndIdx) {
if (isUndef(oldStartVnode)) {
// 情况 8️⃣
oldStartVnode = oldCh[++oldStartIdx] // Vnode has been moved left
} else if (isUndef(oldEndVnode)) {
// 情况 9️⃣
oldEndVnode = oldCh[--oldEndIdx]
} else if (sameVnode(oldStartVnode, newStartVnode)) {
// 情况 1️⃣
patchVnode(...)
oldStartVnode = oldCh[++oldStartIdx]
newStartVnode = newCh[++newStartIdx]
} else if (sameVnode(oldEndVnode, newEndVnode)) {
// 情况 2️⃣
patchVnode(...)
oldEndVnode = oldCh[--oldEndIdx]
newEndVnode = newCh[--newEndIdx]
} else if (sameVnode(oldStartVnode, newEndVnode)) {
// Vnode moved right
// 情况 3️⃣
patchVnode(...)
canMove &&
nodeOps.insertBefore(
parentElm,
oldStartVnode.elm,
nodeOps.nextSibling(oldEndVnode.elm)
)
oldStartVnode = oldCh[++oldStartIdx]
newEndVnode = newCh[--newEndIdx]
} else if (sameVnode(oldEndVnode, newStartVnode)) {
// Vnode moved left
// 情况 4️⃣
patchVnode(...)
canMove &&
nodeOps.insertBefore(parentElm, oldEndVnode.elm, oldStartVnode.elm)
oldEndVnode = oldCh[--oldEndIdx]
newStartVnode = newCh[++newStartIdx]
} else {
// 情况 5️⃣
if (isUndef(oldKeyToIdx)) // 创建 key -> index 的 Map
oldKeyToIdx = createKeyToOldIdx(oldCh, oldStartIdx, oldEndIdx)
// 找到 新头节点 的下标
idxInOld = isDef(newStartVnode.key)
? oldKeyToIdx[newStartVnode.key]
: findIdxInOld(newStartVnode, oldCh, oldStartIdx, oldEndIdx)
if (isUndef(idxInOld)) {
// New element
// 如果没找到
createElm(...)
} else {
// 如果找到了
vnodeToMove = oldCh[idxInOld]
if (sameVnode(vnodeToMove, newStartVnode)) {
patchVnode(...)
oldCh[idxInOld] = undefined
canMove &&
nodeOps.insertBefore(
parentElm,
vnodeToMove.elm,
oldStartVnode.elm
)
} else {
// same key but different element. treat as new element
createElm(...)
}
}
newStartVnode = newCh[++newStartIdx]
}
}
if (oldStartIdx > oldEndIdx) {
// 情况 6️⃣
refElm = isUndef(newCh[newEndIdx + 1]) ? null : newCh[newEndIdx + 1].elm
addVnodes(...)
} else if (newStartIdx > newEndIdx) {
// 情况 7️⃣
removeVnodes(...)
}如果问为什么这么比较,回答就是经过很多人很多年的讨论得出的,其实只要记住过程就行了,如果想要更深了解 Diff 算法,可以去 B 站看【尚硅谷】Vue源码解析之虚拟DOM和diff算法
这个问题面试很常见,但是可能大部分人也就只会背八股,没有完全理解,那么经过以上的介绍,我们可以得到自己的理解:
sameVnode 函数判断的,因此可能会有额外 DOM 操作为什么说可能有额外 DOM 操作呢?这个和插入的地方有关,之后会讨论,同理删除也一样
我们分为三个实验:没有 key、key 为 index、key 唯一,仅证明加了 key 可以进行最小化更新操作。
实验代码
有小伙伴评论说可以把代码贴上这样更好,那么作者就把代码附上 ?:
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
<script src="https://cdn.jsdelivr.net/npm/vue@2/dist/vue.js"></script>
<style>
.box {
display: flex;
flex-direction: row;
}
.item {
flex: 1;
}
</style>
</head>
<body>
<div id="app">
<div>
<div>
<h3>没有 key</h3>
<p v-for="(item, index) in list">{{ item }}</p>
</div>
<div>
<h3>key 为 index</h3>
<p v-for="(item, index) in list" :key="index">{{ item }}</p>
</div>
<div>
<h3>key 唯一</h3>
<p v-for="(item, index) in list" :key="item">{{ item }}</p>
</div>
</div>
<button @click="click1">push(4)</button>
<button @click="click2">splice(1, 0, 666)</button>
<button @click="click3">unshift(999)</button>
<br /><br />
<button @click="click4">pop()</button>
<button @click="click5">splice(1, 1)</button>
<button @click="click6">shift()</button>
</div>
<script>
var app = new Vue({
el: '#app',
data: {
show: false,
list: [1, 2, 3],
},
methods: {
click1() {
this.list.push(4);
},
click2() {
this.list.splice(1, 0, 666);
},
click3() {
this.list.unshift(999);
},
click4() {
this.list.pop();
},
click5() {
this.list.splice(1, 1);
},
click6() {
this.list.shift();
}
},
})
</script>
</body>
</html>实验如下所示,我们首先更改原文字,然后点击按钮**「观察节点发生变化的个数」**:

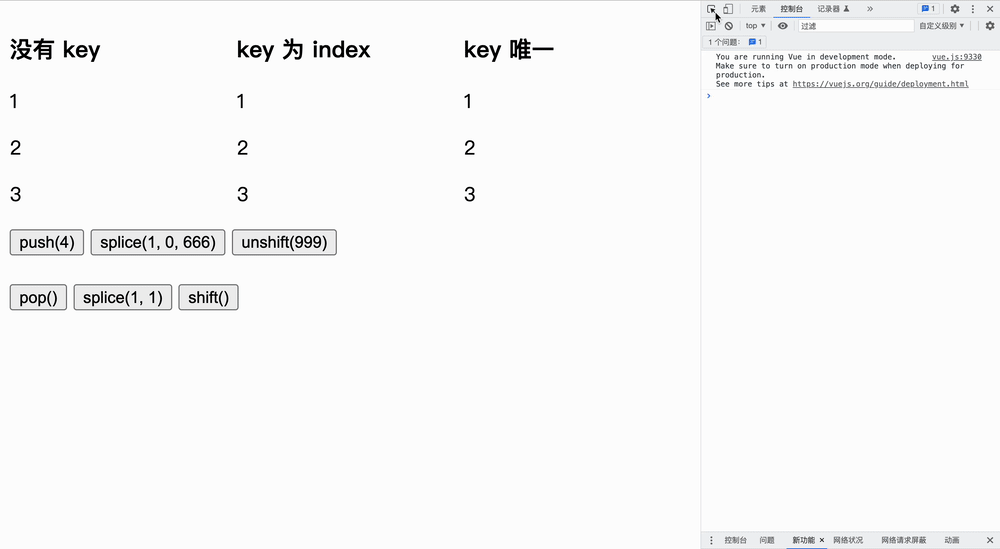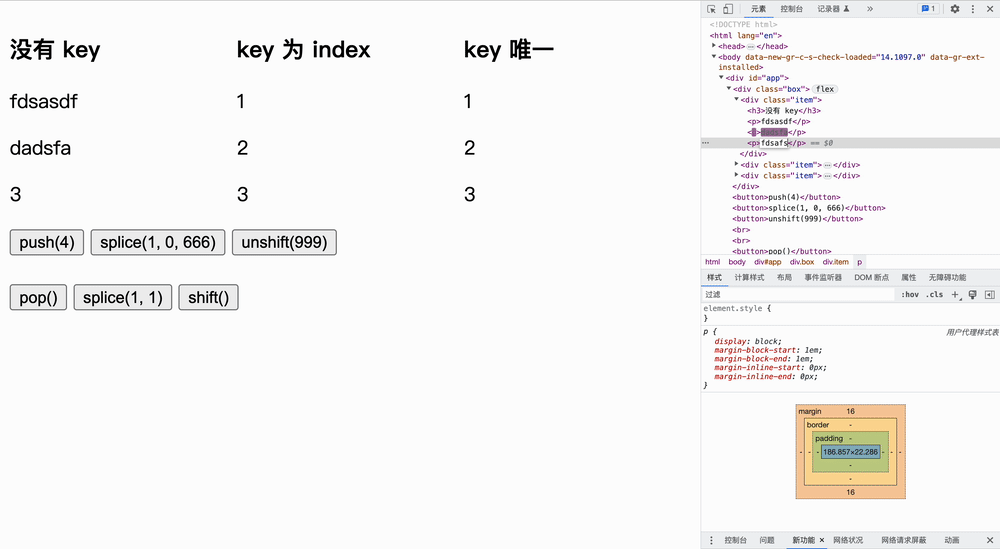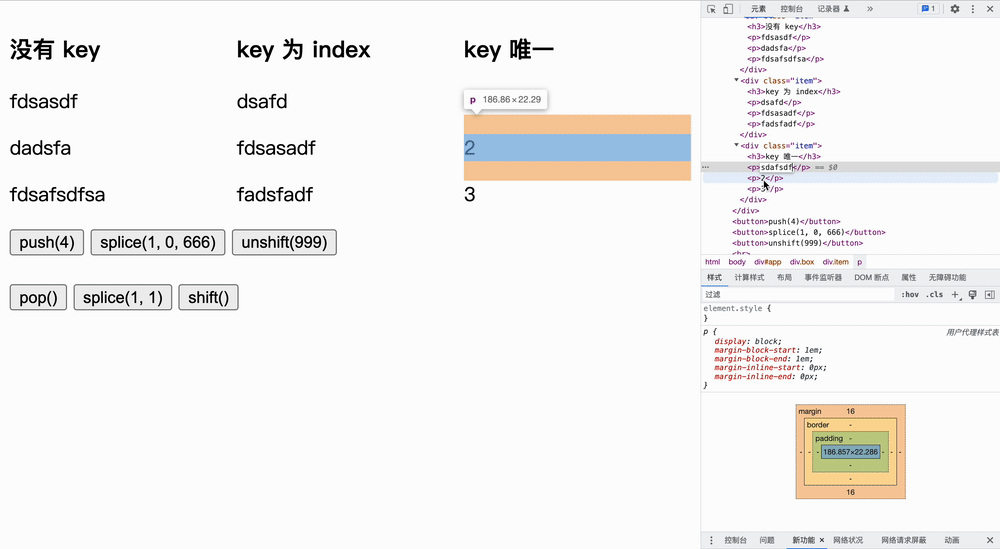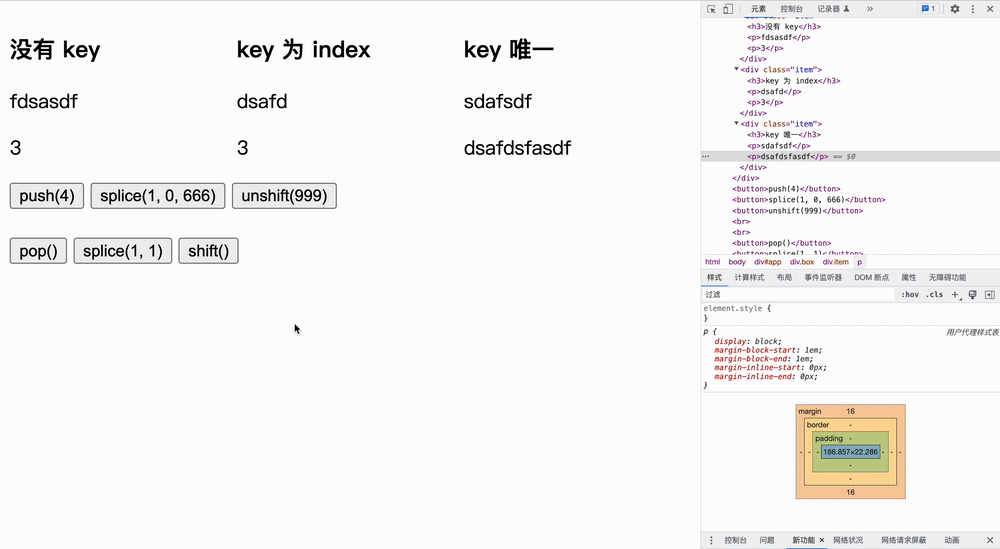
表格为每次实验中,每种情况的最小更新量,假设列表原来的长度为 n
| 实验 | 没有 key | key 为 index | key 唯一 |
|---|---|---|---|
| 在队尾增加 | 1 | 1 | 1 |
| 在队中增加 | n - i + 1 | n - i + 1 | 1 |
| 在队首增加 | n + 1 | n + 1 | 1 |
表格为每次实验中,每种情况的最小更新量,假设列表原来的长度为 n
| 实验 | 没有 key | key 为 index | key 唯一 |
|---|---|---|---|
| 在队尾删除 | 1 | 1 | 1 |
| 在队中删除 | n - i | n - i | 1 |
| 在队首删除 | n | n | 1 |
通过以上实验和表格可以得到加上 key 的性能和最小量更新的个数是最小的,虽然在 在队尾增加 和 在队尾删除 的最小更新量相同,但是之前也说了,如果没有 key 是要循环整个列表查找的,时间复杂度是 O(n),而加了 key 的查找时间复杂度为 O(1),因此总体来说加了 key 的性能要更好。
本文从源码和实验的角度介绍了 Diff 算法,相信大家对 Diff 算法有了更深的了解了,如果有问题可私信交流或者评论区交流,如果大家喜欢的话可以点赞 ➕ 收藏 ?
列举一些源码中出现的简单函数
setTextContent
function setTextContent(node: Node, text: string) {
node.textContent = text
}isUndef
function isUndef(v: any): v is undefined | null {
return v === undefined || v === null
}isDef
function isDef<T>(v: T): v is NonNullable<T> {
return v !== undefined && v !== null
}insertBefore
function insertBefore(
parentNode: Node,
newNode: Node,
referenceNode: Node
) {
parentNode.insertBefore(newNode, referenceNode)
}nextSibling
function nextSibling(node: Node) {
return node.nextSibling
}createKeyToOldIdx
function createKeyToOldIdx(children, beginIdx, endIdx) {
let i, key
const map = {}
for (i = beginIdx; i <= endIdx; ++i) {
key = children[i].key
if (isDef(key)) map[key] = i
}
return map
}Atas ialah kandungan terperinci Analisis mendalam tentang algoritma Diff dalam Vue2. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 Adakah python bahagian hadapan atau belakang?
Adakah python bahagian hadapan atau belakang?
 Cara melaksanakan pemesejan segera pada bahagian hadapan
Cara melaksanakan pemesejan segera pada bahagian hadapan
 Mengapakah vue.js melaporkan ralat?
Mengapakah vue.js melaporkan ralat?
 Apakah kegunaan slot vue.js?
Apakah kegunaan slot vue.js?
 Cara melompat dengan parameter dalam vue.js
Cara melompat dengan parameter dalam vue.js
 Perbezaan antara front-end dan back-end
Perbezaan antara front-end dan back-end
 Pengenalan kepada hubungan antara php dan front-end
Pengenalan kepada hubungan antara php dan front-end
 Mengapa webstorm tidak boleh menjalankan fail
Mengapa webstorm tidak boleh menjalankan fail
 apa maksud bbs
apa maksud bbs

![Pertempuran sebenar Vue3 bahagian hadapan [projek vue tulisan tangan]](https://img.php.cn/upload/course/000/000/068/639b12e98e0b5441.png)









![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



