

Cara menggunakan Node untuk pemampatan imej

Bagaimana untuk menggunakan Node untuk pemampatan imej? Artikel berikut menggunakan imej PNG sebagai contoh untuk memperkenalkan cara memampatkan imej saya harap ia akan membantu anda!

Baru-baru ini, saya ingin menyediakan perkhidmatan pemprosesan imej, salah satunya adalah untuk melaksanakan fungsi pemampatan imej. Pada masa lalu, semasa membangunkan bahagian hadapan, saya hanya boleh menggunakan API kanvas siap sedia untuk memprosesnya Bahagian belakang mungkin juga mempunyai API siap sedia, tetapi saya tidak tahu. Memikirkannya dengan teliti, saya tidak pernah memahami prinsip pemampatan imej secara terperinci, jadi saya hanya mengambil kesempatan ini untuk melakukan penyelidikan dan kajian, jadi saya menulis artikel ini untuk merakamnya. Seperti biasa, jika ada yang tidak kena, DDDD (bawa adik bersama).
Kami mula-mula memuat naik imej ke bahagian belakang dan melihat parameter apa yang diterima oleh bahagian belakang. Saya menggunakan Node.js (Nest) sebagai hujung belakang di sini dan saya menggunakan imej PNG sebagai contoh.
Antara muka dan parameter dicetak seperti berikut:
@Post('/compression')<br/>@UseInterceptors(FileInterceptor('file'))<br/>async imageCompression(@UploadedFile() file: Express.Multer.File) {<br/> <br/> return {<br/> file<br/> }<br/>}<br/>
Untuk melakukan pemampatan, kita perlu mendapatkan data imej. Seperti yang anda lihat, satu-satunya perkara yang boleh menyembunyikan data imej ialah rentetan penimbal ini. Jadi apakah rentetan penimbal ini anda perlu mengetahui terlebih dahulu apa itu PNG. [Cadangan tutorial berkaitan: tutorial video nodejs, Pengajaran pengaturcaraan]
PNG
Inilah PNG WIKIalamat.
Selepas membaca, saya mengetahui bahawa PNG terdiri daripada pengepala fail 8 bait serta berbilang ketulan. Gambarajah skematik adalah seperti berikut:
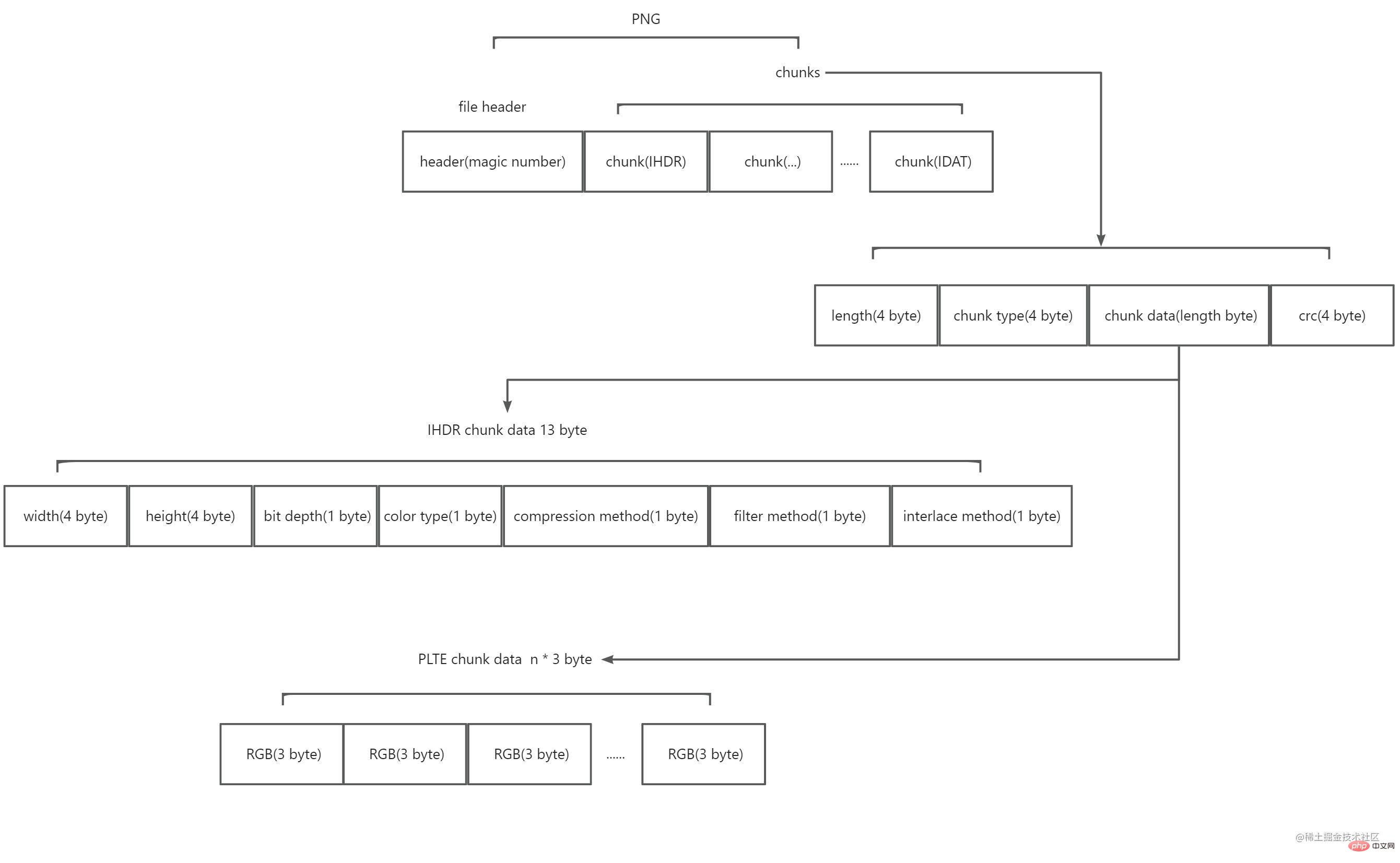
Antaranya:
Pengepala fail terdiri daripada apa yang dipanggil nombor ajaib. Nilainya ialah 89 50 4e 47 0d 0a 1a 0a (perenambelasan). Ia menandakan rentetan data ini sebagai format PNG.
ketulan terbahagi kepada dua jenis, satu dipanggil ketulan utama (Ketulan kritikal), dan satu lagi dipanggil ketulan tambahan (Ketulan sampingan). Blok kunci adalah penting Tanpa blok kunci, penyahkod tidak akan dapat mengenal pasti dan memaparkan gambar dengan betul. Blok tambahan adalah pilihan, dan sesetengah perisian mungkin membawa blok tambahan selepas memproses imej. Setiap blok terdiri daripada empat bahagian: 4 bait menerangkan berapa lama kandungan blok ini, 4 bait menerangkan jenis blok ini dan n bait menerangkan kandungan blok (n ialah saiz nilai 4 bait sebelumnya, iaitu, Panjang maksimum blok ialah 28*4), dan semakan CRC 4-bait menyemak data blok dan menandakan penghujung blok. Antaranya, nilai 4 bait jenis blok ialah 4 kod ACSII Huruf pertama dalam huruf besar menunjukkan bahawa ia adalah blok kunci , dan dalam huruf kecil menunjukkan bahawa ia adalah blok tambahan <. 🎜>; huruf kedua Huruf besar bermaksud awam , huruf kecil bermaksud peribadi ; huruf ketiga mestilah huruf besar untuk pengembangan PNG yang seterusnya; blok tidak dikenali , sama ada ia boleh disalin dengan selamat, huruf besar bermakna ia boleh disalin dengan selamat hanya apabila blok kunci belum diubah suai, huruf kecil bermakna ia boleh disalin dengan selamat. PNG secara rasmi menyediakan banyak jenis blok yang ditentukan Di sini anda hanya perlu mengetahui jenis blok utama, iaitu IHDR, PLTE, IDAT dan IEND.
IHDR
PNG memerlukanblok pertama mestilah IHDR. Kandungan blok IHDR ditetapkan pada 13 bait dan mengandungi maklumat imej berikut:
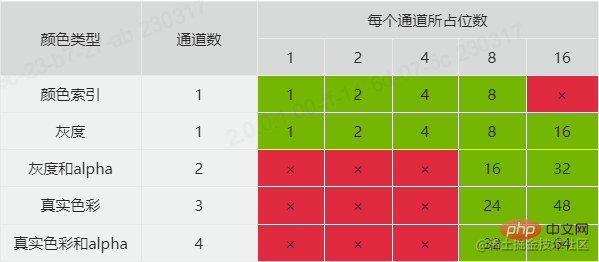
lebar (4 bait) & ketinggian (4 bait)kedalaman bit (1 bait, Nilai ialah 1, 2, 4, 8 atau 16) & jenis warna jenis warna (1 bait, nilainya ialah 0, 2, 3, 4 atau 6) kaedah mampatan kaedah mampatan (1 bait, nilainya ialah 0 ) & Kaedah penapis kaedah penapis (1 bait, nilainya 0)Kaedah jalinan kaedah jalinan (1 bait, nilainya 0 atau 1)Lebar dan tingginya mudah untuk faham, dan selebihnya Beberapa daripada mereka kelihatan tidak dikenali, jadi saya akan menerangkannya seterusnya. Sebelum menerangkan kedalaman bit, mari kita lihat dahulu jenis warna Jenis warna mempunyai 5 nilai:- 0 bermaksud skala kelabu, yang hanya mempunyai satu saluran ( saluran. ), jika dilihat sebagai rgb, anda boleh memahami bahawa nilai saluran tiga warnanya adalah sama, jadi tidak perlu lebih daripada dua saluran untuk mewakilinya.
- 2 mewakili warna sebenar (rgb) yang mempunyai tiga saluran iaitu R (merah), G (hijau), B (biru).
3 mewakili indeks warna (diindeks) Ia juga hanya mempunyai satu saluran, mewakili nilai indeks warna. Jenis ini selalunya dilengkapi dengan set senarai warna, dan warna tertentu diperoleh berdasarkan nilai indeks dan pertanyaan senarai warna.
4 mewakili skala kelabu dan alfa Ia mempunyai dua saluran Selain saluran skala kelabu, terdapat saluran alfa tambahan untuk mengawal ketelusan.
6 mewakili warna sebenar dan alfa yang mempunyai empat saluran.
Sebab kami bercakap tentang saluran adalah kerana ia berkaitan dengan kedalaman bit di sini. Nilai kedalaman bit mentakrifkan bilangan bit yang diduduki oleh setiap saluran. Dengan menggabungkan kedalaman bit dan jenis warna, anda boleh mengetahui jenis format warna imej dan saiz memori yang diduduki oleh setiap piksel. Gabungan yang disokong secara rasmi oleh PNG adalah seperti berikut:
Penapisan dan pemampatan adalah kerana PNG tidak menyimpan data asal imej, tetapi data yang diproses, itulah sebabnya imej PNG disebabkan oleh jejak ingatan yang lebih kecil. PNG menggunakan dua langkah untuk memampatkan dan menukar data imej.
Langkah pertama ialah menapis. Tujuan penapisan adalah untuk membolehkan data imej asal mencapai nisbah mampatan yang lebih besar selepas melepasi peraturan. Contohnya, jika terdapat gambar kecerunan, dari kiri ke kanan, warnanya ialah [#000000, #000001, #000002, ..., #ffffff], maka kita boleh bersetuju dengan peraturan bahawa piksel di sebelah kanan ialah sentiasa sama seperti Bandingkan dengan piksel kiri sebelumnya, kemudian data yang diproses menjadi [1, 1, 1, ..., 1], adakah ini akan membolehkan pemampatan yang lebih baik? PNG pada masa ini hanya mempunyai satu kaedah penapisan, yang berdasarkan piksel bersebelahan sebagai nilai ramalan dan menolak nilai ramalan daripada piksel semasa. Terdapat lima jenis penapisan, (buat masa ini saya tidak tahu di mana nilai jenis ini disimpan. Ia mungkin dalam IDAT. Setelah anda menemuinya, padamkan dalam kurungan ini. Ia disahkan bahawa nilai jenis ini disimpan dalam data IDAT) seperti yang ditunjukkan dalam jadual berikut:
| Type byte | Filter name | Predicted value |
|---|---|---|
| 0 | None | 不做任何处理 |
| 1 | Sub | 左侧相邻像素 |
| 2 | Up | 上方相邻像素 |
| 3 | Average | Math.floor((左侧相邻像素 + 上方相邻像素) / 2) |
| 4 | Paeth | 取(左侧相邻像素 + 上方相邻像素 - 左上方像素)最接近的值 |
第二步,压缩。PNG也只有一种压缩算法,使用的是DEFLATE算法。这里不细说,具体看下面的章节。
交错方式,有两种值。0表示不处理,1表示使用Adam7 算法进行处理。我没有去详细了解该算法,简单来说,当值为0时,图片需要所有数据都加载完毕时,图片才会显示。而值为1时,Adam7会把图片划分多个区域,每个区域逐级加载,显示效果会有所优化,但通常会降低压缩效率。加载过程可以看下面这张gif图。

PLTE
PLTE的块内容为一组颜色列表,当颜色类型为颜色索引时需要配置。值得注意的是,颜色列表中的颜色一定是每个通道8bit,每个像素24bit的真实色彩列表。列表的长度,可以比位深约定的少,但不能多。比如位深是2,那么22,最多4种颜色,列表长度可以为3,但不能为5。
IDAT
IDAT的块内容是图片原始数据经过PNG压缩转换后的数据,它可能有多个重复的块,但必须是连续的,并且只有当上一个块填充满时,才会有下一个块。
IEND
IEND的块内容为0 byte,它表示图片的结束。
阅读到这里,我们把上面的接口改造一下,解析这串buffer。
@Post('/compression')<br/>@UseInterceptors(FileInterceptor('file'))<br/>async imageCompression(@UploadedFile() file: Express.Multer.File) {<br/> const buffer = file.buffer;<br/><br/> const result = {<br/> header: buffer.subarray(0, 8).toString('hex'),<br/> chunks: [],<br/> size: file.size,<br/> };<br/><br/> let pointer = 8;<br/> while (pointer < buffer.length) {<br/> let chunk = {};<br/> const length = parseInt(buffer.subarray(pointer, pointer + 4).toString('hex'), 16);<br/> const chunkType = buffer.subarray(pointer + 4, pointer + 8).toString('ascii');<br/> const crc = buffer.subarray(pointer + length, pointer + length + 4).toString('hex');<br/> chunk = {<br/> ...chunk,<br/> length,<br/> chunkType,<br/> crc,<br/> };<br/><br/> switch (chunkType) {<br/> case 'IHDR':<br/> const width = parseInt(buffer.subarray(pointer + 8, pointer + 12).toString('hex'), 16);<br/> const height = parseInt(buffer.subarray(pointer + 12, pointer + 16).toString('hex'), 16);<br/> const bitDepth = parseInt(<br/> buffer.subarray(pointer + 16, pointer + 17).toString('hex'),<br/> 16,<br/> );<br/> const colorType = parseInt(<br/> buffer.subarray(pointer + 17, pointer + 18).toString('hex'),<br/> 16,<br/> );<br/> const compressionMethod = parseInt(<br/> buffer.subarray(pointer + 18, pointer + 19).toString('hex'),<br/> 16,<br/> );<br/> const filterMethod = parseInt(<br/> buffer.subarray(pointer + 19, pointer + 20).toString('hex'),<br/> 16,<br/> );<br/> const interlaceMethod = parseInt(<br/> buffer.subarray(pointer + 20, pointer + 21).toString('hex'),<br/> 16,<br/> );<br/><br/> chunk = {<br/> ...chunk,<br/> width,<br/> height,<br/> bitDepth,<br/> colorType,<br/> compressionMethod,<br/> filterMethod,<br/> interlaceMethod,<br/> };<br/> break;<br/> case 'PLTE':<br/> const colorList = [];<br/> const colorListStr = buffer.subarray(pointer + 8, pointer + 8 + length).toString('hex');<br/> for (let i = 0; i < colorListStr.length; i += 6) {<br/> colorList.push(colorListStr.slice(i, i + 6));<br/> }<br/> chunk = {<br/> ...chunk,<br/> colorList,<br/> };<br/> break;<br/> default:<br/> break;<br/> }<br/> result.chunks.push(chunk);<br/> pointer = pointer + 4 + 4 + length + 4;<br/> }<br/><br/> return result;<br/>}<br/>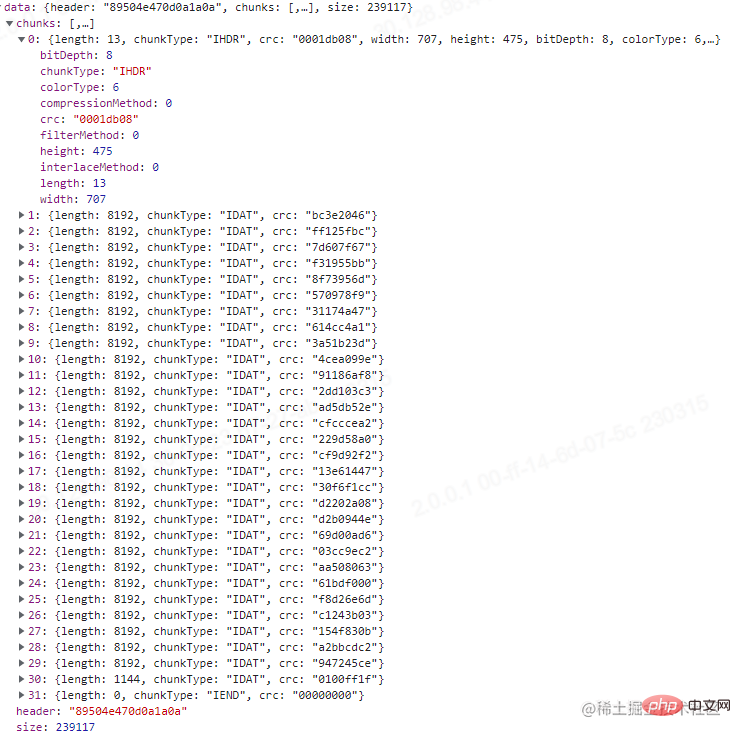
这里我测试用的图没有PLTE,刚好我去TinyPNG压缩我那张测试图之后进行上传,发现有PLTE块,可以看一下,结果如下图。
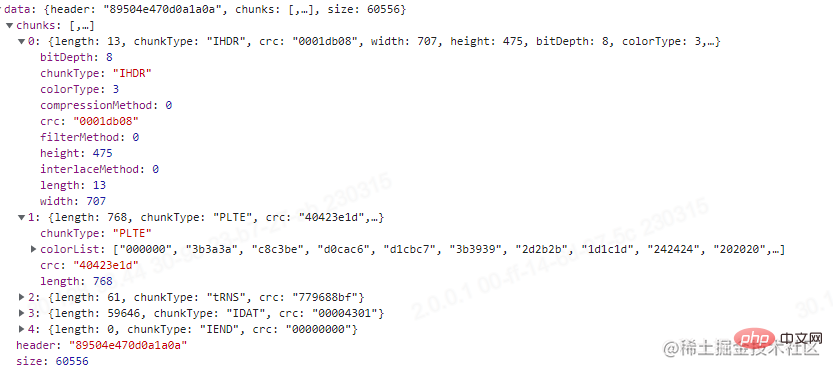
通过比对这两张图,压缩图片的方式我们也能窥探一二。
PNG的压缩
前面说过,PNG使用的是一种叫DEFLATE的无损压缩算法,它是Huffman Coding跟LZ77的结合。除了PNG,我们经常使用的压缩文件,.zip,.gzip也是使用的这种算法(7zip算法有更高的压缩比,也可以了解下)。要了解DEFLATE,我们首先要了解Huffman Coding和LZ77。
Huffman Coding
哈夫曼编码忘记在大学的哪门课接触过了,它是一种根据字符出现频率,用最少的字符替换出现频率最高的字符,最终降低平均字符长度的算法。
举个例子,有字符串"ABCBCABABADA",如果按照正常空间存储,所占内存大小为12 * 8bit = 96bit,现对它进行哈夫曼编码。
1.统计每个字符出现的频率,得到A 5次 B 4次 C 2次 D 1次
2.对字符按照频率从小到大排序,将得到一个队列D1,C2,B4,A5
3.按顺序构造哈夫曼树,先构造一个空节点,最小频率的字符分给该节点的左侧,倒数第二频率的字符分给右侧,然后将频率相加的值赋值给该节点。接着用赋值后节点的值和倒数第三频率的字符进行比较,较小的值总是分配在左侧,较大的值总是分配在右侧,依次类推,直到队列结束,最后把最大频率和前面的所有值相加赋值给根节点,得到一棵完整的哈夫曼树。
4.对每条路径进行赋值,左侧路径赋值为0,右侧路径赋值为1。从根节点到叶子节点,进行遍历,遍历的结果就是该字符编码后的二进制表示,得到:A(0)B(11)C(101)D(100)。
完整的哈夫曼树如下(忽略箭头,没找到连线- -!):
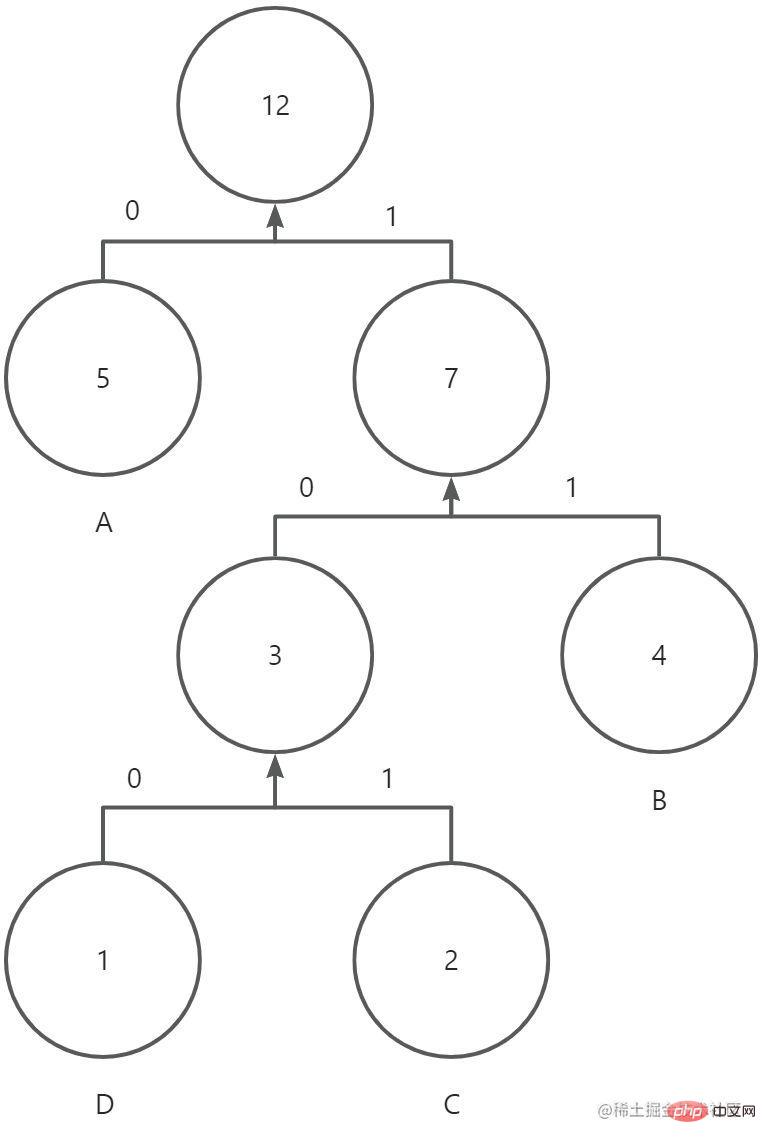
压缩后的字符串,所占内存大小为5 * 1bit + 4 * 2bit + 2 * 3bit + 1 * 3bit = 22bit。当然在实际传输过程中,还需要把编码表的信息(原始字符和出现频率)带上。因此最终占比大小为 4 * 8bit + 4 * 3bit(频率最大值为5,3bit可以表示)+ 22bit = 66bit(理想状态),小于原有的96bit。
LZ77
LZ77算法还是第一次知道,查了一下是一种基于字典和滑动窗的无所压缩算法。(题外话:因为Lempel和Ziv在1977年提出的算法,所以叫LZ77,哈哈哈?)
我们还是以上面这个字符串"ABCBCABABADA"为例,现假设有一个4 byte的动态窗口和一个2byte的预读缓冲区,然后对它进行LZ77算法压缩,过程顺序从上往下,示意图如下:

总结下来,就是预读缓冲区在动态窗口中找到最长相同项,然后用长度较短的标记来替代这个相同项,从而实现压缩。从上图也可以看出,压缩比跟动态窗口的大小,预读缓冲区的大小和被压缩数据的重复度有关。
DEFLATE
DEFLATE【RFC 1951】是先使用LZ77编码,对编码后的结果在进行哈夫曼编码。我们这里不去讨论具体的实现方法,直接使用其推荐库Zlib,刚好Node.js内置了对Zlib的支持。接下来我们继续改造上面那个接口,如下:
import * as zlib from 'zlib';<br/><br/>@Post('/compression')<br/>@UseInterceptors(FileInterceptor('file'))<br/>async imageCompression(@UploadedFile() file: Express.Multer.File) {<br/> const buffer = file.buffer;<br/><br/> const result = {<br/> header: buffer.subarray(0, 8).toString('hex'),<br/> chunks: [],<br/> size: file.size,<br/> };<br/><br/> // 因为可能有多个IDAT的块 需要个数组缓存最后拼接起来<br/> const fileChunkDatas = [];<br/> let pointer = 8;<br/> while (pointer < buffer.length) {<br/> let chunk = {};<br/> const length = parseInt(buffer.subarray(pointer, pointer + 4).toString('hex'), 16);<br/> const chunkType = buffer.subarray(pointer + 4, pointer + 8).toString('ascii');<br/> const crc = buffer.subarray(pointer + length, pointer + length + 4).toString('hex');<br/> chunk = {<br/> ...chunk,<br/> length,<br/> chunkType,<br/> crc,<br/> };<br/><br/> switch (chunkType) {<br/> case 'IHDR':<br/> const width = parseInt(buffer.subarray(pointer + 8, pointer + 12).toString('hex'), 16);<br/> const height = parseInt(buffer.subarray(pointer + 12, pointer + 16).toString('hex'), 16);<br/> const bitDepth = parseInt(<br/> buffer.subarray(pointer + 16, pointer + 17).toString('hex'),<br/> 16,<br/> );<br/> const colorType = parseInt(<br/> buffer.subarray(pointer + 17, pointer + 18).toString('hex'),<br/> 16,<br/> );<br/> const compressionMethod = parseInt(<br/> buffer.subarray(pointer + 18, pointer + 19).toString('hex'),<br/> 16,<br/> );<br/> const filterMethod = parseInt(<br/> buffer.subarray(pointer + 19, pointer + 20).toString('hex'),<br/> 16,<br/> );<br/> const interlaceMethod = parseInt(<br/> buffer.subarray(pointer + 20, pointer + 21).toString('hex'),<br/> 16,<br/> );<br/><br/> chunk = {<br/> ...chunk,<br/> width,<br/> height,<br/> bitDepth,<br/> colorType,<br/> compressionMethod,<br/> filterMethod,<br/> interlaceMethod,<br/> };<br/> break;<br/> case 'PLTE':<br/> const colorList = [];<br/> const colorListStr = buffer.subarray(pointer + 8, pointer + 8 + length).toString('hex');<br/> for (let i = 0; i < colorListStr.length; i += 6) {<br/> colorList.push(colorListStr.slice(i, i + 6));<br/> }<br/> chunk = {<br/> ...chunk,<br/> colorList,<br/> };<br/> break;<br/> case 'IDAT':<br/> fileChunkDatas.push(buffer.subarray(pointer + 8, pointer + 8 + length));<br/> break;<br/> default:<br/> break;<br/> }<br/> result.chunks.push(chunk);<br/> pointer = pointer + 4 + 4 + length + 4;<br/> }<br/><br/> const originFileData = zlib.unzipSync(Buffer.concat(fileChunkDatas));<br/><br/> // 这里原图片数据太长了 我就只打印了长度<br/> return {<br/> ...result,<br/> originFileData: originFileData.length,<br/> };<br/>}<br/>
最终打印的结果,我们需要注意红框的那几个部分。可以看到上图,位深和颜色类型决定了每个像素由4 byte组成,然后由于过滤方式的存在,会在每行的第一个字节进行标记。因此该图的原始数据所占大小为:707 * 475 * 4 byte + 475 * 1 byte = 1343775 byte。正好是我们打印的结果。
我们也可以试试之前TinyPNG压缩后的图,如下:
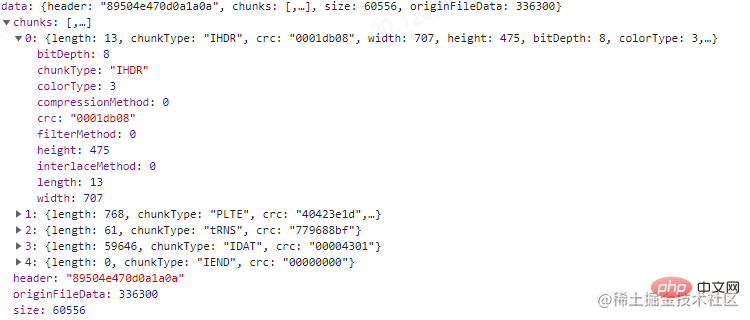
可以看到位深为8,索引颜色类型的图每像素占1 byte。计算得到:707 * 475 * 1 byte + 475 * 1 byte = 336300 byte。结果也正确。
总结
现在再看如何进行图片压缩,你可能很容易得到下面几个结论:
1.减少不必要的辅助块信息,因为辅助块对PNG图片而言并不是必须的。
2.减少IDAT的块数,因为每多一个IDAT的块,就多余了12 byte。
3.降低每个像素所占的内存大小,比如当前是4通道8位深的图片,可以统计整个图片色域,得到色阶表,设置索引颜色类型,降低通道从而降低每个像素的内存大小。
4.等等....
至于JPEG,WEBP等等格式图片,有机会再看。溜了溜了~(还是使用现成的库处理压缩吧)。
好久没写文章,写完才发现语雀不能免费共享,发在这里吧。
更多node相关知识,请访问:nodejs 教程!
Atas ialah kandungan terperinci Cara menggunakan Node untuk pemampatan imej. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1376
1376
 52
52

 Artikel tentang kawalan memori dalam Node
Apr 26, 2023 pm 05:37 PM
Artikel tentang kawalan memori dalam Node
Apr 26, 2023 pm 05:37 PM
Perkhidmatan Node yang dibina berdasarkan bukan sekatan dan dipacu peristiwa mempunyai kelebihan penggunaan memori yang rendah dan sangat sesuai untuk mengendalikan permintaan rangkaian besar-besaran. Di bawah premis permintaan besar-besaran, isu yang berkaitan dengan "kawalan memori" perlu dipertimbangkan. 1. Mekanisme kutipan sampah V8 dan had ingatan Js dikawal oleh mesin kutipan sampah
 Penjelasan grafik terperinci tentang memori dan GC enjin Node V8
Mar 29, 2023 pm 06:02 PM
Penjelasan grafik terperinci tentang memori dan GC enjin Node V8
Mar 29, 2023 pm 06:02 PM
Artikel ini akan memberi anda pemahaman yang mendalam tentang memori dan pengumpul sampah (GC) enjin NodeJS V8 saya harap ia akan membantu anda!
 Bagaimana untuk mengendalikan pemampatan imej semasa menyimpan imej jauh menggunakan PHP?
Jul 15, 2023 pm 03:57 PM
Bagaimana untuk mengendalikan pemampatan imej semasa menyimpan imej jauh menggunakan PHP?
Jul 15, 2023 pm 03:57 PM
Bagaimana untuk mengendalikan pemampatan imej semasa menyimpan imej jauh menggunakan PHP? Dalam pembangunan sebenar, kita selalunya perlu mendapatkan imej daripada rangkaian dan menyimpannya ke pelayan tempatan. Walau bagaimanapun, sesetengah imej jauh mungkin terlalu besar, yang memerlukan kami memampatkannya untuk mengurangkan ruang storan dan meningkatkan kelajuan pemuatan. PHP menyediakan beberapa sambungan berkuasa untuk mengendalikan pemampatan imej, yang paling biasa digunakan ialah perpustakaan GD dan perpustakaan Imagick. Pustaka GD ialah perpustakaan pemprosesan imej popular yang menyediakan banyak fungsi untuk mencipta, mengedit dan menyimpan imej. Berikut adalah kegunaan
 Mari bercakap secara mendalam tentang modul Fail dalam Node
Apr 24, 2023 pm 05:49 PM
Mari bercakap secara mendalam tentang modul Fail dalam Node
Apr 24, 2023 pm 05:49 PM
Modul fail ialah enkapsulasi operasi fail asas, seperti membaca/menulis/membuka/menutup/memadam fail, dsb. Ciri terbesar modul fail ialah semua kaedah menyediakan dua versi **segerak** dan ** asynchronous**, dengan Kaedah dengan akhiran penyegerakan adalah semua kaedah penyegerakan, dan kaedah yang tidak semuanya adalah kaedah heterogen.
 Mari kita bincangkan tentang cara memilih imej Node.js Docker terbaik?
Dec 13, 2022 pm 08:00 PM
Mari kita bincangkan tentang cara memilih imej Node.js Docker terbaik?
Dec 13, 2022 pm 08:00 PM
Memilih imej Docker untuk Node mungkin kelihatan seperti perkara remeh, tetapi saiz dan potensi kelemahan imej itu boleh memberi kesan yang ketara pada proses dan keselamatan CI/CD anda. Jadi bagaimana kita memilih imej Node.js Docker yang terbaik?
 Mari bercakap tentang mekanisme GC (pengumpulan sampah) dalam Node.js
Nov 29, 2022 pm 08:44 PM
Mari bercakap tentang mekanisme GC (pengumpulan sampah) dalam Node.js
Nov 29, 2022 pm 08:44 PM
Bagaimanakah Node.js melakukan GC (pengumpulan sampah)? Artikel berikut akan membawa anda melaluinya.
 Apakah yang perlu saya lakukan jika nod tidak boleh menggunakan arahan npm?
Feb 08, 2023 am 10:09 AM
Apakah yang perlu saya lakukan jika nod tidak boleh menggunakan arahan npm?
Feb 08, 2023 am 10:09 AM
Sebab mengapa nod tidak boleh menggunakan arahan npm adalah kerana pembolehubah persekitaran tidak dikonfigurasikan dengan betul Penyelesaiannya ialah: 1. Buka "Sistem Sifat"; 2. Cari "Pembolehubah Persekitaran" -> "Pembolehubah Sistem", dan kemudian edit persekitaran. pembolehubah; 3. Cari lokasi folder nodejs;
 Mari kita bincangkan tentang gelung acara dalam Node
Apr 11, 2023 pm 07:08 PM
Mari kita bincangkan tentang gelung acara dalam Node
Apr 11, 2023 pm 07:08 PM
Gelung peristiwa ialah bahagian asas Node.js dan mendayakan pengaturcaraan tak segerak dengan memastikan bahawa utas utama tidak disekat Memahami gelung peristiwa adalah penting untuk membina aplikasi yang cekap. Artikel berikut akan memberi anda pemahaman yang mendalam tentang gelung acara dalam Node.
