
 hujung hadapan web
tutorial js
Penjelasan grafik terperinci tentang memori dan GC enjin Node V8
hujung hadapan web
tutorial js
Penjelasan grafik terperinci tentang memori dan GC enjin Node V8
Penjelasan grafik terperinci tentang memori dan GC enjin Node V8

Artikel ini akan memberi anda pemahaman yang mendalam tentang memori dan pengumpul sampah (GC) enjin NodeJS V8 saya harap ia akan membantu anda!

1. Mengapa GC diperlukan
Aplikasi program perlu menggunakan memori untuk dijalankan, dan dua partition memori ialah apa kita sering membincangkan Konsep: kawasan timbunan dan kawasan timbunan.
Kawasan tindanan ialah baris gilir linear, yang dikeluarkan secara automatik apabila fungsi tamat, manakala kawasan timbunan ialah ruang memori dinamik bebas, dan memori timbunan diperuntukkan dan dikeluarkan secara manual atau program pengumpulan sampah (Kutipan Sampah (selepas ini dirujuk sebagai GC) secara automatik diperuntukkan dan dikeluarkan.
Pada hari-hari awal pembangunan perisian atau beberapa bahasa semuanya diperuntukkan dan dikeluarkan memori timbunan secara manual, seperti C, C++. Walaupun ia boleh mengendalikan memori dengan tepat dan mencapai penggunaan memori yang terbaik, kecekapan pembangunan adalah sangat rendah dan ia terdedah kepada operasi memori yang tidak betul. [Cadangan tutorial berkaitan: tutorial video nodejs, Pengajaran pengaturcaraan]
Dengan perkembangan teknologi, bahasa peringkat tinggi (seperti Java Nod ) tidak memerlukan pembangun untuk mengendalikan memori secara manual, dan bahasa pengaturcaraan akan memperuntukkan dan melepaskan ruang secara automatik. Pada masa yang sama, pemungut sampah GC (Kutipan Sampah) juga dilahirkan untuk membantu melepaskan dan menyusun ingatan. Dalam kebanyakan kes, pembangun tidak perlu mengambil berat tentang memori itu sendiri dan boleh memberi tumpuan kepada pembangunan perniagaan. Artikel berikut terutamanya membincangkan ingatan timbunan dan GC.
2. Pembangunan GC
Operasi GC akan menggunakan sumber CPU Proses operasi GC akan mencetuskan STW (stop-the-world) untuk menggantung urutan kod perniagaan. Kenapa pula dengan STW? Ini adalah untuk memastikan tiada konflik dengan objek yang baru dibuat semasa proses GC.
GC terutamanya berkembang dan berkembang dengan peningkatan saiz ingatan. Ia secara kasarnya dibahagikan kepada 3 peringkat perwakilan utama:
- Peringkat 1 GC benang tunggal (mewakili: bersiri)
GC benang tunggal, di mana sampah dilakukan Apabila mengumpul, anda mesti menggantung sepenuhnya semua rangkaian pekerja lain Ia adalah peringkat awal GC dan mempunyai prestasi yang paling teruk
- Fasa 2 selari berbilang benang. GC (mewakili : Parallel Scavenge, ParNew)
Gunakan berbilang benang GC untuk berjalan secara selari pada masa yang sama dalam persekitaran berbilang CPU, dengan itu mengurangkan masa pengumpulan sampah dan masa jeda benang pengguna . Algoritma ini juga Akan STW, Menggantung sepenuhnya semua rangkaian pekerja lain
- Fasa 3 berbilang benang serentak GC (wakil: CMS (Sapuan Tanda Serentak) G1)
Konkurensi di sini bermaksud: Pelaksanaan berbilang benang GC boleh dijalankan serentak dengan kod perniagaan.
Algoritma GC dalam dua peringkat pembangunan sebelumnya akan menjadi STW sepenuhnya, manakala dalam GC serentak, beberapa peringkat urutan GC boleh dijalankan serentak dengan kod perniagaan, memastikan masa STW yang lebih singkat. Walau bagaimanapun, akan terdapat ralat penandaan dalam mod ini, kerana objek baharu mungkin masuk semasa proses GC Sudah tentu, algoritma itu sendiri akan membetulkan dan menyelesaikan masalah ini
Tiga peringkat di atas tidak bermakna. GC itu mestilah seperti yang diterangkan di atas Satu daripada tiga jenis. GC dalam bahasa pengaturcaraan yang berbeza dilaksanakan menggunakan gabungan algoritma mengikut keperluan yang berbeza.
3. Pembahagian memori v8 dan GC
Reka bentuk memori timbunan dan reka bentuk GC berkait rapat. V8 membahagikan memori timbunan kepada beberapa kawasan utama dan menggunakan strategi generasi.
Gambar lanun:
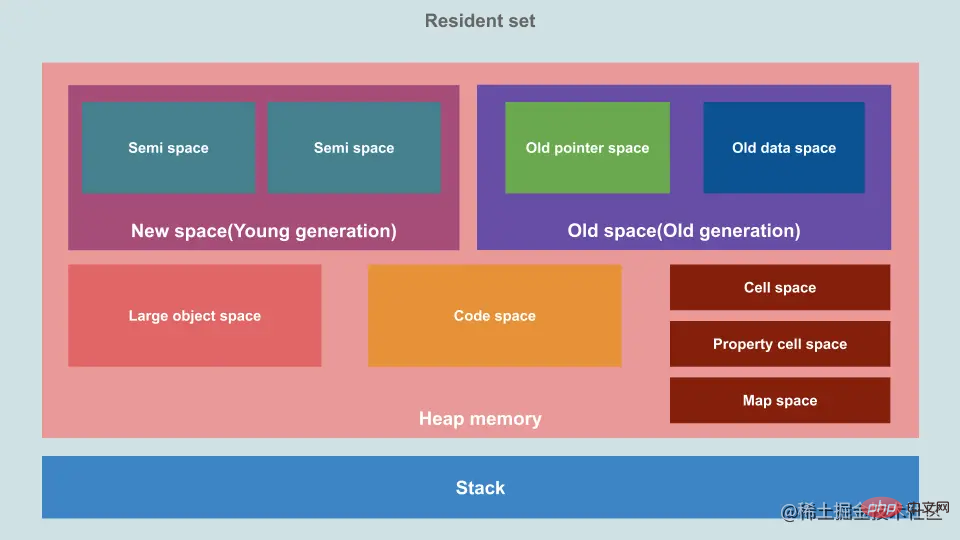
- Angkasa baharu atau generasi muda: : Ruangnya kecil dan terbahagi kepada Dua separuh ruang (semi-ruang), di mana data mempunyai jangka hayat yang singkat.
- Generasi lama (angkasa lama atau generasi lama) : Ruang besar, boleh ditambah dan tempoh kemandirian data adalah panjang
- Ruang objek besar ( ruang-objek besar) : Objek melebihi 256K akan berada dalam ruang ini secara lalai, diterangkan di bawah
- Ruang kod (ruang-kod) : Just-in-time pengkompil (JIT) dalam Kod tersusun disimpan di sini
- Ruang sel : Ruang ini digunakan untuk menyimpan objek JavaScript bersaiz tetap kecil, seperti nombor dan nilai Boolean.
- Ruang sel sifat : Ruang ini digunakan untuk menyimpan objek JavaScript khas, seperti sifat pengakses dan objek dalaman tertentu.
- Ruang Peta: Ruang ini digunakan untuk menyimpan maklumat meta dan struktur data dalaman lain untuk objek JavaScript, seperti objek Peta dan Set.
3.1 Strategi generasi: generasi baharu dan generasi lama
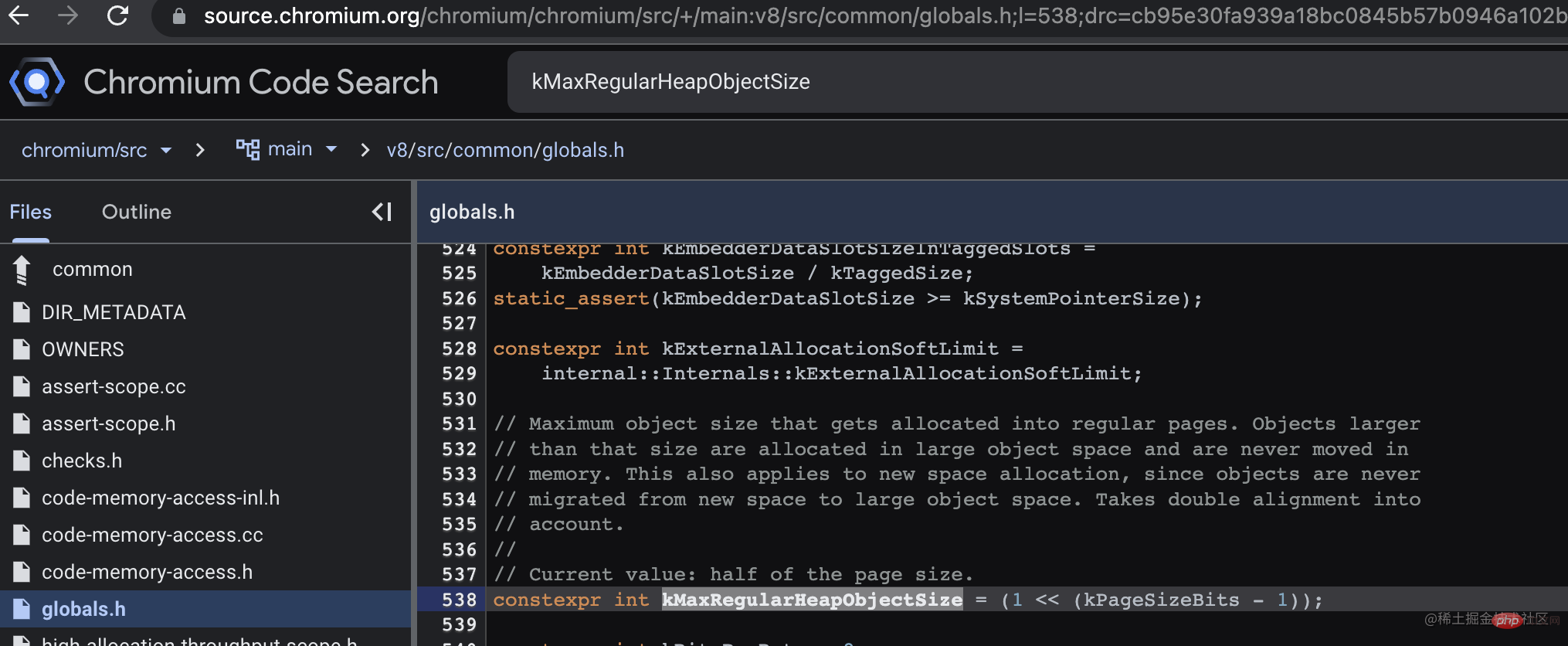
Dalam Node.js, GC mengamalkan generasi generasi Strategi dibahagikan kepada kawasan generasi baru dan lama, dan kebanyakan data memori berada dalam dua kawasan ini.
3.1.1 Generasi Baharu
Generasi baharu ialah kumpulan memori yang kecil dan pantas yang menyimpan objek muda dan dibahagikan kepada dua ruang separuh (separuh ruang). ruang adalah bebas (dipanggil ke angkasa), dan separuh lagi ruang menyimpan data (dipanggil dari angkasa).
Apabila objek pertama kali dicipta, ia diperuntukkan kepada generasi muda dari separuh ruang, yang mempunyai umur 1 tahun. Apabila dari tidak mencukupi atau melebihi saiz tertentu, GC Minor akan dicetuskan (menggunakan algoritma salin Scavenge Pada masa ini, GC akan menggantung pelaksanaan aplikasi (STW, stop-the-world), tandakan semua objek aktif dalam (dari ruang), dan kemudian susun dan alihkannya secara berterusan ke ruang kosong lain (ke angkasa) dalam generasi baharu. Akhirnya, semua memori dalam ruang dari asal akan dilepaskan dan menjadi ruang kosong Kedua-dua ruang itu akan melengkapkan pertukaran dari dan ke algoritma ialah Algoritma yang mengorbankan ruang untuk masa.
Ruang generasi baharu adalah lebih kecil, jadi ruang ini akan mencetuskan GC dengan lebih kerap. Pada masa yang sama, ruang yang diimbas lebih kecil, penggunaan prestasi GC juga lebih kecil, dan masa pelaksanaan GCnya juga lebih pendek.
Setiap kali GC Kecil selesai, umur objek yang masih hidup ialah +1 Objek yang telah bertahan berbilang GC Kecil (umur lebih besar daripada N) akan dialihkan ke kumpulan memori generasi lama.
3.1.2 Generasi Lama
Generasi lama ialah kolam memori besar yang digunakan untuk menyimpan objek tahan lama. Memori generasi lama menggunakan Mark-Sweep dan algoritma Mark-Compact . Salah satu pelaksanaannya dipanggil Datuk Bandar GC. Apabila objek dalam generasi lama mengisi bahagian tertentu, iaitu nisbah objek yang masih hidup kepada jumlah objek melebihi ambang tertentu, pembersihan tanda atau pemadatan penandaan akan dicetuskan .
Oleh kerana ruangnya lebih besar, masa pelaksanaan GCnya juga lebih lama dan kekerapannya lebih rendah daripada generasi baharu. Jika masih terdapat ruang yang tidak mencukupi selepas generasi lama melengkapkan kitar semula GC, V8 akan memohon lebih banyak memori daripada sistem.
Anda boleh melaksanakan kaedah global.gc() secara manual, menetapkan parameter berbeza dan mencetuskan GC secara aktif. Walau bagaimanapun, perlu diingat bahawa kaedah ini dilumpuhkan secara lalai dalam Node.js. Jika anda ingin mendayakannya, anda boleh mendayakannya dengan menambahkan parameter --expose-gc apabila memulakan aplikasi Node.js, contohnya:
node --expose-gc app.js
V8 digunakan terutamanya pada generasi lama kutipan sampah dilakukan dengan menggabungkan >Mark-Sweep dan Mark-Compact.
Mark-Sweep bermaksud sapuan tanda, yang dibahagikan kepada dua peringkat, tanda dan sapu. Mark-Sweep Dalam fasa penandaan, ia merentasi semua objek dalam timbunan dan menandakan objek hidup Dalam fasa pembersihan berikutnya, hanya objek yang tidak bertanda dibersihkan.
Mark-Sweep Masalah terbesar ialah selepas sapuan markah dilakukan, ruang memori akan menjadi tidak berterusan. Pemecahan memori seperti ini akan menyebabkan masalah untuk peruntukan memori seterusnya, kerana besar kemungkinan objek besar perlu diperuntukkan Pada masa ini, semua ruang yang berpecah tidak akan dapat menyelesaikan peruntukan, dan pengumpulan sampah akan dicetuskan. terlebih dahulu, dan kitar semula ini tidak diperlukan.
Untuk menyelesaikan masalah pemecahan memoriMark-Sweep, Mark-Compact telah dicadangkan. Mark-Compact bermaksud kompilasi markah, yang berdasarkan Mark-Sweep. Perbezaan di antara mereka ialah selepas objek ditandakan sebagai mati, semasa proses pembersihan, objek hidup dialihkan ke satu hujung Selepas pergerakan selesai, ingatan di luar sempadan terus dibersihkan. V8 juga akan mengeluarkan sejumlah memori percuma dan mengembalikannya kepada sistem berdasarkan logik tertentu.
3.2 Ruang objek besar Ruang objek besar
Objek besar akan dicipta terus dalam ruang objek besar dan tidak akan dialihkan ke ruang lain. Jadi berapa banyak objek yang akan dicipta terus dalam ruang objek besar dan bukannya dalam kawasandari generasi baharu? Selepas merujuk maklumat dan kod sumber, akhirnya saya menemui jawapannya. Secara lalai, ia adalah 256K V8 nampaknya tidak mendedahkan arahan pengubahsuaian v8_enable_hugepage konfigurasi dalam kod sumber harus ditetapkan semasa pembungkusan.
// There is a separate large object space for objects larger than // Page::kMaxRegularHeapObjectSize, so that they do not have to move during // collection. The large object space is paged. Pages in large object space // may be larger than the page size.
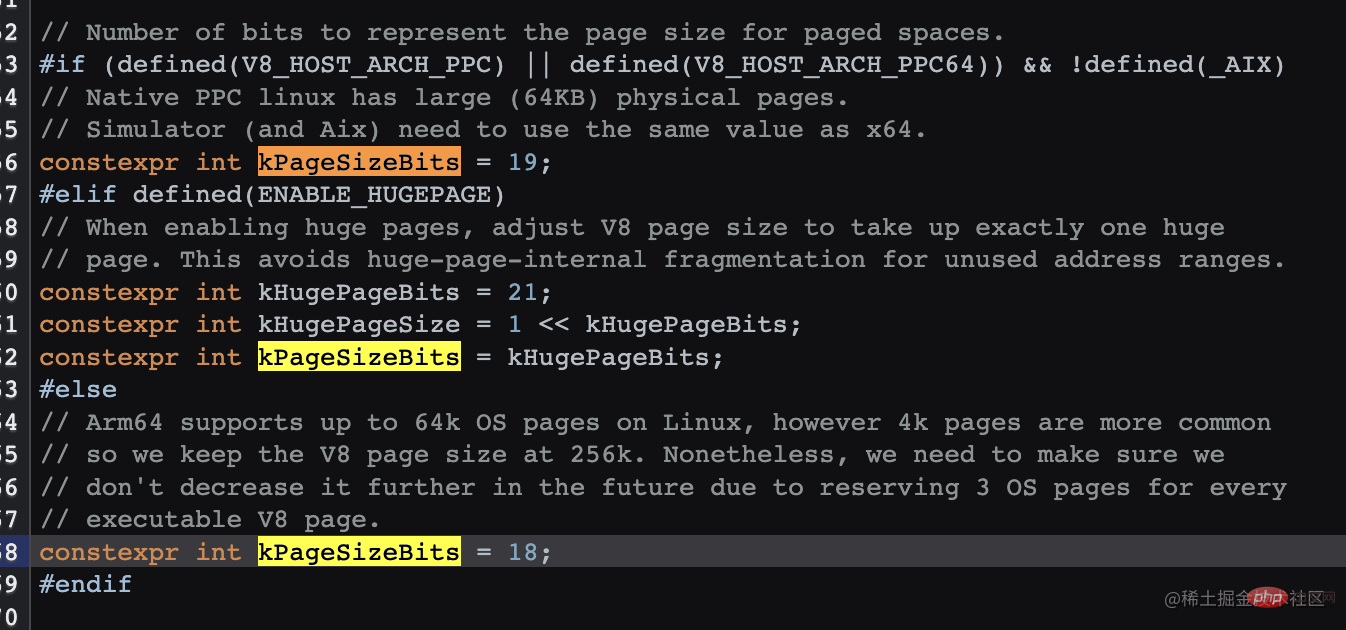
(1 << (18 - 1)) 的结果 256K (1 << (19 - 1)) 的结果 256K (1 << (21 - 1)) 的结果 1M(如果开启了hugPage)
四、V8 新老分区大小
4.1 老生代分区大小
在v12.x 之前:
为了保证 GC 的执行时间保持在一定范围内,V8 限制了最大内存空间,设置了一个默认老生代内存最大值,64位系统中为大约1.4G,32位为大约700M,超出会导致应用崩溃。
如果想加大内存,可以使用 --max-old-space-size 设置最大内存(单位:MB)
node --max_old_space_size=
在v12以后:
V8 将根据可用内存分配老生代大小,也可以说是堆内存大小,所以并没有限制堆内存大小。以前的限制逻辑,其实不合理,限制了 V8 的能力,总不能因为 GC 过程消耗的时间更长,就不让我继续运行程序吧,后续的版本也对 GC 做了更多优化,内存越来越大也是发展需要。
如果想要做限制,依然可以使用 --max-old-space-size 配置, v12 以后它的默认值是0,代表不限制。
参考文档:nodejs.medium.com/introducing…
4.2 新生代分区大小
新生代中的一个 semi-space 大小 64位系统的默认值是16M,32位系统是8M,因为有2个 semi-space,所以总大小是32M、16M。
--max-semi-space-size
--max-semi-space-size 设置新生代 semi-space 最大值,单位为MB。
此空间不是越大越好,空间越大扫描的时间就越长。这个分区大部分情况下是不需要做修改的,除非针对具体的业务场景做优化,谨慎使用。
--max-new-space-size
--max-new-space-size 设置新生代空间最大值,单位为KB(不存在)
有很多文章说到此功能,我翻了下 nodejs.org 网页中 v4 v6 v7 v8 v10的文档都没有看到有这个配置,使用 node --v8-options 也没有查到,也许以前的某些老版本有,而现在都应该使用 --max-semi-space-size。
五、 内存分析相关API
5.1 v8.getHeapStatistics()
执行 v8.getHeapStatistics(),查看 v8 堆内存信息,查询最大堆内存 heap_size_limit,当然这里包含了新、老生代、大对象空间等。我的电脑硬件内存是 8G,Node版本16x,查看到 heap_size_limit 是4G。
{
total_heap_size: 6799360,
total_heap_size_executable: 524288,
total_physical_size: 5523584,
total_available_size: 4340165392,
used_heap_size: 4877928,
heap_size_limit: 4345298944,
malloced_memory: 254120,
peak_malloced_memory: 585824,
does_zap_garbage: 0,
number_of_native_contexts: 2,
number_of_detached_contexts: 0
}到 k8s 容器中查询 NodeJs 应用,分别查看了v12 v14 v16版本,如下表。看起来是本身系统当前的最大内存的一半。128M 的时候,为啥是 256M,因为容器中还有交换内存,容器内存实际最大内存限制是内存限制值 x2,有同等的交换内存。
所以结论是大部分情况下 heap_size_limit 的默认值是系统内存的一半。但是如果超过这个值且系统空间足够,V8 还是会申请更多空间。当然这个结论也不是一个最准确的结论。而且随着内存使用的增多,如果系统内存还足够,这里的最大内存还会增长。
| 容器最大内存 | heap_size_limit |
|---|---|
| 4G | 2G |
| 2G | 1G |
| 1G | 0.5G |
| 1.5G | 0.7G |
| 256M | 256M |
| 128M | 256M |
5.2 process.memoryUsage
process.memoryUsage()
{
rss: 35438592,
heapTotal: 6799360,
heapUsed: 4892976,
external: 939130,
arrayBuffers: 11170
}通过它可以查看当前进程的内存占用和使用情况 heapTotal、heapUsed,可以定时获取此接口,然后绘画出折线图帮助分析内存占用情况。以下是 Easy-Monitor 提供的功能:
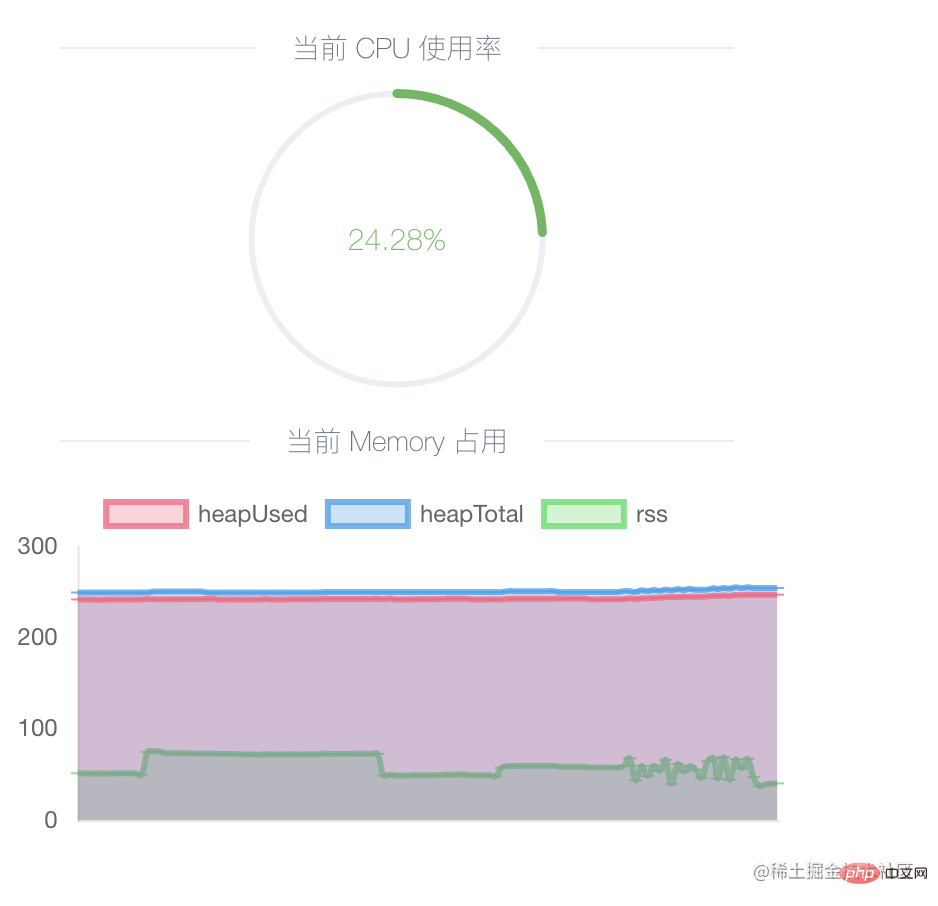
建议本地开发环境使用,开启后,尝试大量请求,会看到内存曲线增长,到请求结束之后,GC触发后会看到内存曲线下降,然后再尝试多次发送大量请求,这样往复下来,如果发现内存一直在增长低谷值越来越高,就可能是发生了内存泄漏。
5.3 开启打印GC事件
使用方法
node --trace_gc app.js // 或者 v8.setFlagsFromString('--trace_gc');
- --trace_gc
[40807:0x148008000] 235490 ms: Scavenge 247.5 (259.5) -> 244.7 (260.0) MB, 0.8 / 0.0 ms (average mu = 0.971, current mu = 0.908) task [40807:0x148008000] 235521 ms: Scavenge 248.2 (260.0) -> 245.2 (268.0) MB, 1.2 / 0.0 ms (average mu = 0.971, current mu = 0.908) allocation failure [40807:0x148008000] 235616 ms: Scavenge 251.5 (268.0) -> 245.9 (268.8) MB, 1.9 / 0.0 ms (average mu = 0.971, current mu = 0.908) task [40807:0x148008000] 235681 ms: Mark-sweep 249.7 (268.8) -> 232.4 (268.0) MB, 7.1 / 0.0 ms (+ 46.7 ms in 170 steps since start of marking, biggest step 4.2 ms, walltime since start of marking 159 ms) (average mu = 1.000, current mu = 1.000) finalize incremental marking via task GC in old space requested
GCType <heapUsed before> (<heapTotal before>) -> <heapUsed after> (<heapTotal after>) MB
上面的 Scavenge 和 Mark-sweep 代表GC类型,Scavenge 是新生代中的清除事件,Mark-sweep 是老生代中的标记清除事件。箭头符号前是事件发生前的实际使用内存大小,箭头符号后是事件结束后的实际使用内存大小,括号内是内存空间总值。可以看到新生代中事件发生的频率很高,而后触发的老生代事件会释放总内存空间。
- --trace_gc_verbose
展示堆空间的详细情况
v8.setFlagsFromString('--trace_gc_verbose'); [44729:0x130008000] Fast promotion mode: false survival rate: 19% [44729:0x130008000] 97120 ms: [HeapController] factor 1.1 based on mu=0.970, speed_ratio=1000 (gc=433889, mutator=434) [44729:0x130008000] 97120 ms: [HeapController] Limit: old size: 296701 KB, new limit: 342482 KB (1.1) [44729:0x130008000] 97120 ms: [GlobalMemoryController] Limit: old size: 296701 KB, new limit: 342482 KB (1.1) [44729:0x130008000] 97120 ms: Scavenge 302.3 (329.9) -> 290.2 (330.4) MB, 8.4 / 0.0 ms (average mu = 0.998, current mu = 0.999) task [44729:0x130008000] Memory allocator, used: 338288 KB, available: 3905168 KB [44729:0x130008000] Read-only space, used: 166 KB, available: 0 KB, committed: 176 KB [44729:0x130008000] New space, used: 444 KB, available: 15666 KB, committed: 32768 KB [44729:0x130008000] New large object space, used: 0 KB, available: 16110 KB, committed: 0 KB [44729:0x130008000] Old space, used: 253556 KB, available: 1129 KB, committed: 259232 KB [44729:0x130008000] Code space, used: 10376 KB, available: 119 KB, committed: 12944 KB [44729:0x130008000] Map space, used: 2780 KB, available: 0 KB, committed: 2832 KB [44729:0x130008000] Large object space, used: 29987 KB, available: 0 KB, committed: 30336 KB [44729:0x130008000] Code large object space, used: 0 KB, available: 0 KB, committed: 0 KB [44729:0x130008000] All spaces, used: 297312 KB, available: 3938193 KB, committed: 338288 KB [44729:0x130008000] Unmapper buffering 0 chunks of committed: 0 KB [44729:0x130008000] External memory reported: 20440 KB [44729:0x130008000] Backing store memory: 22084 KB [44729:0x130008000] External memory global 0 KB [44729:0x130008000] Total time spent in GC : 199.1 ms
- --trace_gc_nvp
每次GC事件的详细信息,GC类型,各种时间消耗,内存变化等
v8.setFlagsFromString('--trace_gc_nvp'); [45469:0x150008000] 8918123 ms: pause=0.4 mutator=83.3 gc=s reduce_memory=0 time_to_safepoint=0.00 heap.prologue=0.00 heap.epilogue=0.00 heap.epilogue.reduce_new_space=0.00 heap.external.prologue=0.00 heap.external.epilogue=0.00 heap.external_weak_global_handles=0.00 fast_promote=0.00 complete.sweep_array_buffers=0.00 scavenge=0.38 scavenge.free_remembered_set=0.00 scavenge.roots=0.00 scavenge.weak=0.00 scavenge.weak_global_handles.identify=0.00 scavenge.weak_global_handles.process=0.00 scavenge.parallel=0.08 scavenge.update_refs=0.00 scavenge.sweep_array_buffers=0.00 background.scavenge.parallel=0.00 background.unmapper=0.04 unmapper=0.00 incremental.steps_count=0 incremental.steps_took=0.0 scavenge_throughput=1752382 total_size_before=261011920 total_size_after=260180920 holes_size_before=838480 holes_size_after=838480 allocated=831000 promoted=0 semi_space_copied=4136 nodes_died_in_new=0 nodes_copied_in_new=0 nodes_promoted=0 promotion_ratio=0.0% average_survival_ratio=0.5% promotion_rate=0.0% semi_space_copy_rate=0.5% new_space_allocation_throughput=887.4 unmapper_chunks=124 [45469:0x150008000] 8918234 ms: pause=0.6 mutator=110.9 gc=s reduce_memory=0 time_to_safepoint=0.00 heap.prologue=0.00 heap.epilogue=0.00 heap.epilogue.reduce_new_space=0.04 heap.external.prologue=0.00 heap.external.epilogue=0.00 heap.external_weak_global_handles=0.00 fast_promote=0.00 complete.sweep_array_buffers=0.00 scavenge=0.50 scavenge.free_remembered_set=0.00 scavenge.roots=0.08 scavenge.weak=0.00 scavenge.weak_global_handles.identify=0.00 scavenge.weak_global_handles.process=0.00 scavenge.parallel=0.08 scavenge.update_refs=0.00 scavenge.sweep_array_buffers=0.00 background.scavenge.parallel=0.00 background.unmapper=0.04 unmapper=0.00 incremental.steps_count=0 incremental.steps_took=0.0 scavenge_throughput=1766409 total_size_before=261207856 total_size_after=260209776 holes_size_before=838480 holes_size_after=838480 allocated=1026936 promoted=0 semi_space_copied=3008 nodes_died_in_new=0 nodes_copied_in_new=0 nodes_promoted=0 promotion_ratio=0.0% average_survival_ratio=0.5% promotion_rate=0.0% semi_space_copy_rate=0.3% new_space_allocation_throughput=888.1 unmapper_chunks=124
5.4 内存快照
const { writeHeapSnapshot } = require('node:v8');
v8.writeHeapSnapshot()打印快照,将会STW,服务停止响应,内存占用越大,时间越长。此方法本身就比较费时间,所以生成的过程预期不要太高,耐心等待。
注意:生成内存快照的过程,会STW(程序将暂停)几乎无任何响应,如果容器使用了健康检测,这时无法响应的话,容器可能被重启,导致无法获取快照,如果需要生成快照、建议先关闭健康检测。
兼容性问题:此 API arm64 架构不支持,执行就会卡住进程 生成空快照文件 再无响应, 如果使用库 heapdump,会直接报错:
(mach-o file, but is an incompatible architecture (have (arm64), need (x86_64))
此 API 会生成一个 .heapsnapshot 后缀快照文件,可以使用 Chrome 调试器的“内存”功能,导入快照文件,查看堆内存具体的对象数和大小,以及到GC根结点的距离等。也可以对比两个不同时间快照文件的区别,可以看到它们之间的数据量变化。
六、利用内存快照分析内存泄漏
一个 Node 应用因为内存超过容器限制经常发生重启,通过容器监控后台看到应用内存的曲线是一直上升的,那应该是发生了内存泄漏。
使用 Chrome 调试器对比了不同时间的快照。发现对象增量最多的是闭包函数,继而展开查看整个列表,发现数据量较多的是 mongo 文档对象,其实就是闭包函数内的数据没有被释放,再通过查看 Object 列表,发现同样很多对象,最外层的详情显示的是 Mongoose 的 Connection 对象。
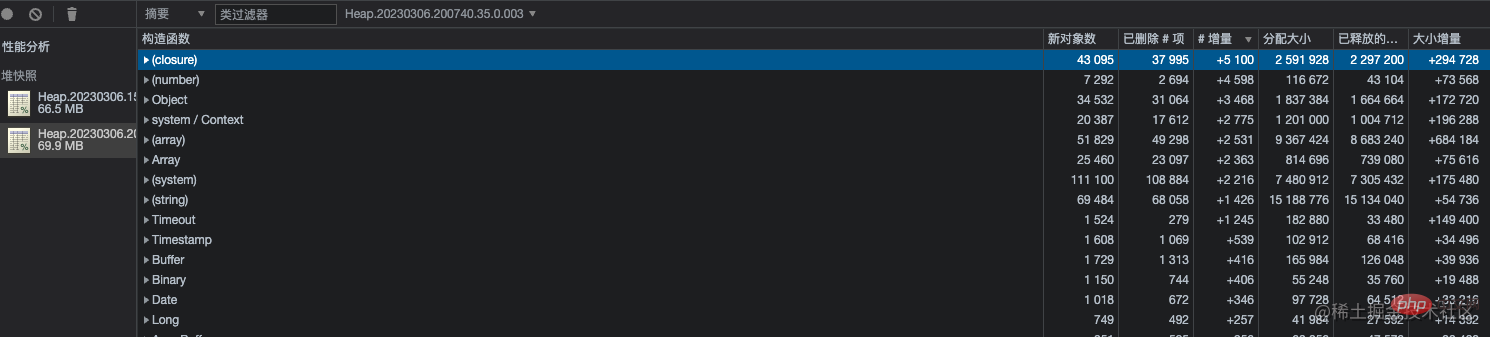
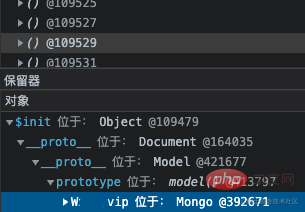
到此为止,已经大概定位到一个类的 mongo 数据存储逻辑附近有内存泄漏。
再看到 Timeout 对象也比较多,从 GC 根节点距离来看,这些对象距离非常深。点开详情,看到这一层层的嵌套就定位到了代码中准确的位置。因为那个类中有个定时任务使用 setInterval 定时器去分批处理一些不紧急任务,当一个 setInterval 把事情做完之后就会被 clearInterval 清除。
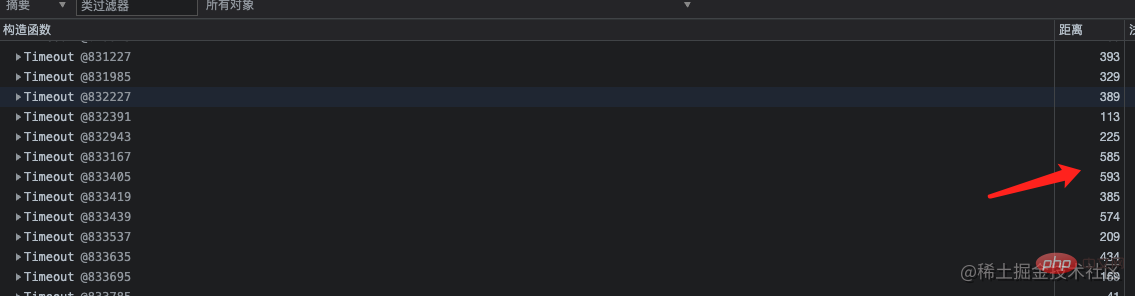
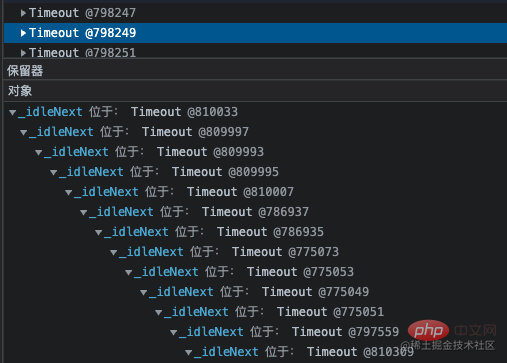
Penyelesaian dan pengoptimuman kebocoran
Melalui analisis logik kod, akhirnya kami menemui masalah itu ialah masalah dengan keadaan pencetus clearInterval, yang menyebabkan masalah. pemasa tidak perlu dikosongkan. Pemasa terus melaksanakan Kod ini dan data di dalamnya masih dalam penutupan dan tidak boleh dikitar semula oleh GC, jadi memori akan menjadi lebih besar dan lebih besar sehingga ia mencapai had atas dan ranap.
Cara menggunakan setInterval di sini adalah tidak munasabah, ia telah ditukar untuk menggunakan untuk menunggu baris gilir untuk melaksanakan secara berurutan, untuk mengelakkan bilangan yang besar. daripada concurrency pada masa yang sama Kod ini juga Jauh lebih jelas. Memandangkan sekeping kod ini agak lama, saya tidak akan mempertimbangkan mengapa setInterval digunakan pada mulanya.
Selepas lebih daripada sepuluh hari pemerhatian selepas versi baharu dikeluarkan, purata memori kekal pada hanya lebih 100M GC biasanya mengitar semula memori yang meningkat buat sementara waktu, menunjukkan lengkung beralun dan tiada lagi kebocoran berlaku.

Setakat ini, kebocoran memori telah dianalisis dan diselesaikan menggunakan syot kilat memori. Sudah tentu, analisis sebenar memerlukan sedikit liku-liku Kandungan gambar memori ini tidak mudah difahami dan tidak begitu mudah. Paparan data syot kilat ialah pengagregatan jenis Anda perlu melihat pembina yang berbeza dan butiran data dalaman, digabungkan dengan analisis komprehensif kod anda sendiri, untuk mencari beberapa petunjuk. Contohnya, daripada petikan memori yang saya dapat pada masa itu, terdapat banyak data termasuk penutupan, rentetan, kelas model mongo, Tamat Masa, Objek, dll. Malah, data tambahan ini semuanya datang daripada kod bermasalah , dan tidak boleh dikitar semula oleh GC.
6 Akhirnya
Bahasa yang berbeza mempunyai pelaksanaan GC yang berbeza, seperti Java dan Go:
Java: Fahami JVM (sepadan dengan Node V8 Java juga turut menggunakan strategi generasi eden dalam generasi baharunya . , objek baru dicipta di kawasan ini. V8 generasi baharu tidak mempunyai kawasan eden.
Go: Menggunakan penyingkiran tanda, algoritma penandaan tiga warna
Bahasa yang berbeza mempunyai pelaksanaan GC yang berbeza, tetapi pada asasnya semuanya dilaksanakan menggunakan gabungan algoritma yang berbeza. Dari segi prestasi, kombinasi berbeza membawa kecekapan prestasi yang berbeza dalam semua aspek, tetapi semuanya bertukar ganti dan hanya berat sebelah terhadap senario aplikasi yang berbeza.
Untuk lebih banyak pengetahuan berkaitan nod, sila lawati: tutorial nodejs!
Atas ialah kandungan terperinci Penjelasan grafik terperinci tentang memori dan GC enjin Node V8. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1377
1377
 52
52

 Artikel tentang kawalan memori dalam Node
Apr 26, 2023 pm 05:37 PM
Artikel tentang kawalan memori dalam Node
Apr 26, 2023 pm 05:37 PM
Perkhidmatan Node yang dibina berdasarkan bukan sekatan dan dipacu peristiwa mempunyai kelebihan penggunaan memori yang rendah dan sangat sesuai untuk mengendalikan permintaan rangkaian besar-besaran. Di bawah premis permintaan besar-besaran, isu yang berkaitan dengan "kawalan memori" perlu dipertimbangkan. 1. Mekanisme kutipan sampah V8 dan had ingatan Js dikawal oleh mesin kutipan sampah
 Penjelasan grafik terperinci tentang memori dan GC enjin Node V8
Mar 29, 2023 pm 06:02 PM
Penjelasan grafik terperinci tentang memori dan GC enjin Node V8
Mar 29, 2023 pm 06:02 PM
Artikel ini akan memberi anda pemahaman yang mendalam tentang memori dan pengumpul sampah (GC) enjin NodeJS V8 saya harap ia akan membantu anda!
 Mari bercakap secara mendalam tentang modul Fail dalam Node
Apr 24, 2023 pm 05:49 PM
Mari bercakap secara mendalam tentang modul Fail dalam Node
Apr 24, 2023 pm 05:49 PM
Modul fail ialah enkapsulasi operasi fail asas, seperti membaca/menulis/membuka/menutup/memadam fail, dsb. Ciri terbesar modul fail ialah semua kaedah menyediakan dua versi **segerak** dan ** asynchronous**, dengan Kaedah dengan akhiran penyegerakan adalah semua kaedah penyegerakan, dan kaedah yang tidak semuanya adalah kaedah heterogen.
 Pemahaman mendalam tentang generik dalam golang (Generik)
Apr 11, 2023 pm 07:20 PM
Pemahaman mendalam tentang generik dalam golang (Generik)
Apr 11, 2023 pm 07:20 PM
Perkara yang dibawa oleh artikel ini kepada anda ialah pemahaman mendalam tentang generik dalam golang? Bagaimana untuk menggunakan generik? Ia mempunyai nilai rujukan tertentu Rakan-rakan yang memerlukan boleh merujuk kepadanya.
 12 perkara yang perlu diberi perhatian apabila berkongsi dokumen reka bentuk antara muka
Apr 24, 2023 am 10:58 AM
12 perkara yang perlu diberi perhatian apabila berkongsi dokumen reka bentuk antara muka
Apr 24, 2023 am 10:58 AM
Apabila saya menyemak dokumen antara muka baru-baru ini, saya mendapati bahawa parameter yang ditakrifkan oleh rakan kongsi kecil ialah nilai penghitungan, tetapi dokumen antara muka tidak memberikan nilai penghitungan khusus yang sepadan. Sebenarnya, cara menulis dokumen antara muka dengan baik adalah sangat penting. Hari ini, Saudara Tianluo membawakan anda 12 mata untuk diberi perhatian dalam dokumen reka bentuk antara muka~
 Mari kita bincangkan tentang gelung acara dalam Node
Apr 11, 2023 pm 07:08 PM
Mari kita bincangkan tentang gelung acara dalam Node
Apr 11, 2023 pm 07:08 PM
Gelung peristiwa ialah bahagian asas Node.js dan mendayakan pengaturcaraan tak segerak dengan memastikan bahawa utas utama tidak disekat Memahami gelung peristiwa adalah penting untuk membina aplikasi yang cekap. Artikel berikut akan memberi anda pemahaman yang mendalam tentang gelung acara dalam Node.
 Ketahui tentang pakej tidak selamat di Golang
Apr 02, 2023 am 08:30 AM
Ketahui tentang pakej tidak selamat di Golang
Apr 02, 2023 am 08:30 AM
Dalam sesetengah perpustakaan peringkat rendah, anda sering melihat penggunaan pakej yang tidak selamat. Artikel ini akan membawa anda memahami pakej tidak selamat di Golang, memperkenalkan peranan pakej tidak selamat dan cara menggunakan Pointer saya harap ia akan membantu anda!
 Ketahui lebih lanjut tentang Penampan dalam Node
Apr 25, 2023 pm 07:49 PM
Ketahui lebih lanjut tentang Penampan dalam Node
Apr 25, 2023 pm 07:49 PM
Pada mulanya, JS hanya berjalan pada bahagian penyemak imbas Mudah untuk memproses rentetan berkod Unikod, tetapi sukar untuk memproses rentetan binari dan bukan berkod Unikod. Dan binari ialah format data peringkat terendah komputer, video/audio/program/pakej rangkaian
