

Dalam MySQL, pengimbangan beban merujuk kepada membentuk berbilang pelayan MySQL ke dalam kelompok dan memperuntukkan permintaan pertanyaan pangkalan data untuk meningkatkan prestasi sistem pangkalan data. Pengimbangan beban MySQL adalah untuk menyelesaikan masalah kesesakan apabila pangkalan data tunggal mengendalikan sejumlah besar permintaan Ia mencapai tujuan untuk meningkatkan prestasi sistem pangkalan data dengan mengagihkan permintaan secara sama rata kepada berbilang pelayan Pada masa yang sama, pengimbangan beban juga boleh meningkatkan ketersediaan sistem pangkalan data Apabila salah satu pelayan gagal, pelayan lain boleh terus memproses permintaan, dengan itu memastikan kesinambungan perkhidmatan.

Persekitaran pengendalian tutorial ini: sistem windows7, versi mysql8, komputer Dell G3.
Apakah pengimbangan beban MySQL?
Pengimbangan beban MySQL merujuk kepada membentuk berbilang pelayan MySQL ke dalam kelompok dan memperuntukkan permintaan pertanyaan pangkalan data untuk meningkatkan prestasi sistem pangkalan data. Pengimbangan beban membolehkan ketersediaan tinggi, kebolehskalaan dan pengimbangan beban.
Idea asas pengimbangan beban adalah mudah: purata beban sebanyak mungkin dalam kelompok pelayan. Berdasarkan idea ini, pendekatan biasa kami ialah menyediakan pengimbang beban di hujung hadapan pelayan. Peranan pengimbang beban adalah untuk menghalakan sambungan yang diminta ke pelayan terbiar yang tersedia.
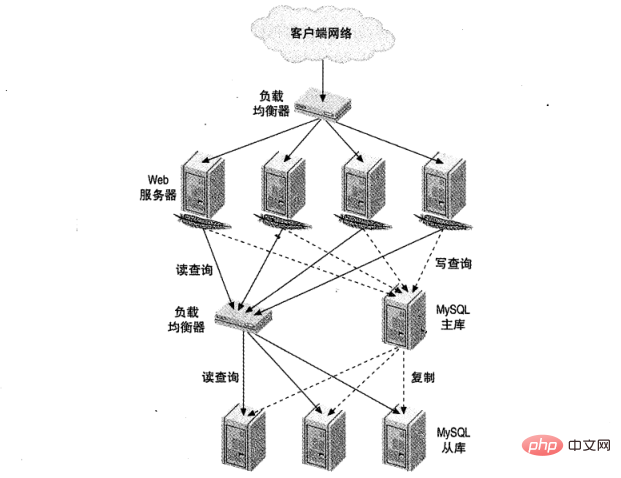
Rajah 1 menunjukkan persediaan pengimbangan beban tapak web yang besar. Satu bertanggungjawab untuk trafik HTTP dan satu lagi untuk akses MySQL.
Mengapakah pengimbangan beban MySQL diperlukan?
Pengimbangan beban MySQL adalah untuk menyelesaikan masalah kesesakan apabila pangkalan data tunggal mengendalikan sejumlah besar permintaan Dengan mengagihkan permintaan secara sama rata kepada berbilang pelayan, ia mencapai tujuan untuk meningkatkan prestasi sistem pangkalan data. Pada masa yang sama, pengimbangan beban juga boleh meningkatkan ketersediaan sistem pangkalan data Apabila salah satu pelayan gagal, pelayan lain boleh terus memproses permintaan, sekali gus memastikan kesinambungan perkhidmatan.
Pengimbangan beban mempunyai lima tujuan biasa:
Skalabiliti . Pengimbangan beban berguna untuk pengembangan tertentu, seperti membaca data daripada pangkalan data siap sedia apabila membaca dan menulis diasingkan.
Kecekapan. Pengimbangan beban membantu menggunakan sumber dengan lebih cekap dengan dapat mengawal ke mana permintaan dihalakan.
Ketersediaan. Penyelesaian pengimbangan beban yang fleksibel boleh meningkatkan ketersediaan perkhidmatan dengan ketara.
Ketelusan. Pelanggan tidak perlu mengetahui sama ada pengimbang beban wujud, dan ia juga tidak perlu mengetahui berapa banyak mesin berada di belakang pengimbang beban. Apa yang dibentangkan kepada pelanggan adalah pelayan yang telus.
Ketekalan. Jika aplikasi adalah stateful (urus niaga pangkalan data, sesi tapak web, dsb.), maka pengimbang beban boleh menunjukkan pertanyaan berkaitan ke pelayan yang sama untuk mengelakkan kehilangan keadaan.
Cara melaksanakan pengimbangan beban MySQL
Secara amnya terdapat dua cara untuk melaksanakan pengimbangan beban: Secara langsung sambungkan dan perkenalkan perisian tengah .
Sesetengah orang berpendapat bahawa pengimbangan beban adalah untuk mengkonfigurasi perkara secara langsung antara aplikasi dan pelayan MySQL, tetapi sebenarnya ini bukan satu-satunya pengimbangan beban kaedah. Seterusnya, kami akan membincangkan kaedah sambungan terus aplikasi biasa dan langkah berjaga-jaga yang berkaitan.
Dalam kaedah ini, salah satu masalah terbesar terdedah untuk berlaku: data kotor. Contoh biasa ialah apabila pengguna mengulas pada catatan blog dan kemudian memuat semula halaman tetapi tidak melihat ulasan baharu.
Sudah tentu, kita tidak boleh meninggalkan pemisahan baca-tulis hanya kerana masalah data yang kotor. Malah, untuk kebanyakan aplikasi, toleransi untuk data kotor mungkin agak tinggi, dan kaedah ini boleh diperkenalkan dengan berani pada masa ini.
Jadi untuk aplikasi yang mempunyai toleransi yang rendah untuk data kotor, bagaimana untuk memisahkan bacaan dan penulisan? Seterusnya, kami akan membezakan antara pemisahan membaca dan menulis. Saya percaya anda sentiasa boleh mencari strategi yang sesuai dengan anda.
1) Berdasarkan pemisahan pertanyaan
Jika aplikasi hanya mempunyai sejumlah kecil data yang tidak boleh bertolak ansur dengan data kotor, kami boleh memperuntukkan semua bacaan dan tulis yang tidak boleh bertolak ansur data kotor kepada tuan. Pertanyaan baca lain diperuntukkan pada hamba. Strategi ini mudah dilaksanakan, tetapi jika terdapat sedikit pertanyaan yang bertolak ansur dengan data kotor, kemungkinan pangkalan data siap sedia tidak dapat digunakan dengan berkesan.
2) Pemisahan berdasarkan data kotor
Ini adalah peningkatan kecil kepada strategi pemisahan berasaskan pertanyaan. Beberapa kerja tambahan diperlukan, seperti mempunyai kependaman replikasi semakan aplikasi untuk menentukan sama ada data siap sedia adalah terkini. Banyak aplikasi pelaporan boleh menggunakan strategi ini: mereka hanya perlu menyalin data yang dimuatkan pada waktu malam ke antara muka pangkalan data siap sedia, dan mereka tidak peduli sama ada ia telah terperangkap sepenuhnya dengan pangkalan data utama.
3) Pemisahan berasaskan sesi
Strategi ini lebih mendalam daripada strategi pemisahan data yang kotor. Ia menentukan sama ada pengguna telah mengubah suai data Pengguna tidak perlu melihat data terkini pengguna lain, hanya kemas kininya sendiri.
Secara khususnya, bit bendera boleh ditetapkan dalam lapisan sesi untuk menunjukkan sama ada pengguna telah membuat kemas kini Setelah pengguna membuat kemas kini, pertanyaan pengguna akan diarahkan ke pangkalan data utama untuk satu tempoh masa .
Strategi ini ialah kompromi yang baik antara kesederhanaan dan keberkesanan, dan merupakan strategi yang lebih disyorkan.
Sudah tentu, jika anda cukup bertimbang rasa, anda boleh menggabungkan strategi detasmen berasaskan sesi dengan strategi pemantauan kependaman replikasi. Jika pengguna mengemas kini data 10 saat yang lalu, dan semua kelewatan pangkalan data siap sedia adalah dalam masa 5 saat, anda boleh membaca data dari pangkalan data siap sedia dengan berani. Perlu diingat bahawa ingat untuk memilih pangkalan data siap sedia yang sama untuk keseluruhan sesi, jika tidak, apabila kelewatan beberapa pangkalan data siap sedia tidak konsisten, ia akan menyebabkan masalah kepada pengguna.
4) Berdasarkan versi global/pemisahan sesi
Sahkan sama ada pangkalan data siap sedia telah mengemas kini data dengan merekodkan koordinat log pangkalan data utama dan membandingkannya dengan yang disalin koordinat pangkalan data siap sedia. Apabila aplikasi menunjuk kepada operasi tulis, selepas melakukan transaksi, lakukan operasi SHOW MASTER STATUS, dan kemudian simpan koordinat log induk dalam cache sebagai nombor versi objek atau sesi yang diubah suai. Apabila aplikasi bersambung ke pangkalan data siap sedia, laksanakan SHOW SLAVE STATUS dan bandingkan koordinat pada pangkalan data siap sedia dengan nombor versi dalam cache. Jika pangkalan data siap sedia adalah lebih baharu daripada titik rekod pangkalan data utama, ini bermakna pangkalan data siap sedia telah mengemas kini data yang sepadan dan boleh digunakan dengan yakin.
Malah, banyak strategi pemisahan baca-tulis memerlukan pemantauan kependaman replikasi untuk menentukan peruntukan pertanyaan baca. Walau bagaimanapun, perlu diambil perhatian bahawa nilai lajur Seconds_behind_master yang diperolehi oleh SHOW SLAVE STATUS tidak mewakili kelewatan dengan tepat. Kita boleh menggunakan alat pt-degupan jantung dalam Percona Toolkit untuk memantau kependaman dengan lebih baik.
Untuk beberapa aplikasi yang lebih mudah, DNS boleh dibuat untuk tujuan yang berbeza. Kaedah paling mudah ialah mempunyai satu nama DNS untuk pelayan baca sahaja (read.mysql-db.com) dan nama DNS lain untuk pelayan yang bertanggungjawab untuk operasi tulis (write.mysql-db.com). Jika pangkalan data siap sedia boleh bersaing dengan pangkalan data utama, halakan nama DNS baca sahaja ke pangkalan data siap sedia, jika tidak, tuding ke pangkalan data utama.
Strategi ini sangat mudah untuk dilaksanakan, tetapi terdapat masalah besar: ia tidak dapat mengawal DNS sepenuhnya.
Strategi ini lebih berbahaya Walaupun masalah DNS yang tidak dapat dikawal sepenuhnya boleh dielakkan dengan mengubah suai fail /etc/hosts, ia masih merupakan strategi yang ideal.
Mencapai pengimbangan beban dengan memindahkan alamat maya antara pelayan. Adakah ia berasa serupa dengan mengubah suai DNS? Tetapi sebenarnya mereka adalah perkara yang sama sekali berbeza. Memindahkan alamat IP membolehkan nama DNS kekal tidak berubah Kami boleh memaksa perubahan alamat IP dimaklumkan dengan cepat dan secara atom kepada rangkaian tempatan melalui arahan ARP (tidak tahu tentang ARP, lihat di sini).
Teknik yang mudah ialah memberikan alamat IP tetap kepada setiap pelayan fizikal. Alamat IP ini ditetapkan pada pelayan dan tidak berubah. Anda kemudiannya boleh menggunakan alamat IP maya untuk setiap "perkhidmatan" logik (yang boleh difahami sebagai bekas).
Dengan cara ini, IP boleh dipindahkan dengan mudah antara pelayan tanpa mengkonfigurasi semula aplikasi dan pelaksanaannya lebih mudah.
Strategi di atas mengandaikan bahawa aplikasi disambungkan ke pelayan MySQL, tetapi banyak pengimbangan beban akan memperkenalkan middleware sebagai agen Komunikasi rangkaian. Ia menerima semua komunikasi di satu pihak, mengedarkan permintaan ini kepada pelayan yang ditetapkan di sisi lain, dan menghantar hasil pelaksanaan kembali ke mesin yang meminta. Rajah 2 menggambarkan seni bina ini. 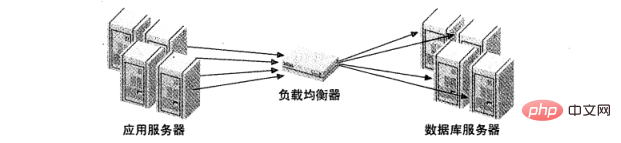
Terdapat banyak perkakasan dan perisian pengimbangan beban di luar sana, tetapi hanya sedikit yang direka khusus untuk pelayan MySQL. Pelayan web secara amnya lebih seimbang beban, jadi banyak peranti pengimbangan beban tujuan umum akan menyokong HTTP dan hanya mempunyai beberapa ciri asas untuk kegunaan lain.
Sambungan MySQL hanyalah sambungan TCP/IP biasa, jadi anda boleh menggunakan pengimbang beban pelbagai guna pada MySQL. Walau bagaimanapun, disebabkan kekurangan ciri khusus MySQL, akan ada beberapa lagi sekatan:
Terdapat banyak algoritma yang digunakan untuk memutuskan pelayan yang menerima sambungan seterusnya. Setiap pengeluar mempunyai algoritma sendiri yang berbeza, dan kaedah biasa berikut ialah:
Peruntukan rawak. Pelayan dipilih secara rawak daripada kumpulan pelayan yang tersedia untuk mengendalikan permintaan.
Undian. Hantar permintaan kepada pelayan dalam susunan round-robin, contohnya: A, B, C, A, B, C.
Hash. Alamat IP sumber sambungan dicincang dan dipetakan ke pelayan yang sama dalam kumpulan.
Respon terpantas. Berikan sambungan kepada pelayan yang boleh mengendalikan permintaan dengan paling cepat.
Bilangan minimum sambungan . Berikan sambungan kepada pelayan dengan sambungan aktif paling sedikit.
Berat. Mengikut prestasi mesin dan keadaan lain, berat yang berbeza dikonfigurasikan untuk mesin yang berbeza supaya mesin berprestasi tinggi boleh mengendalikan lebih banyak sambungan.
Tiada kaedah terbaik antara kaedah di atas, hanya yang paling sesuai, bergantung pada beban kerja tertentu.
Selain itu, kami hanya menerangkan algoritma untuk pemprosesan segera. Tetapi kadangkala mungkin lebih cekap menggunakan algoritma beratur. Sebagai contoh, algoritma mungkin hanya mengekalkan konkurensi pelayan pangkalan data tertentu, membenarkan tidak lebih daripada N transaksi aktif pada satu masa. Jika terdapat terlalu banyak transaksi aktif, permintaan baharu dimasukkan ke dalam baris gilir dan biarkan senarai pelayan yang tersedia mengendalikannya.
Struktur replikasi yang paling biasa ialah satu pangkalan data utama serta berbilang pangkalan data siap sedia. Seni bina ini mempunyai kebolehskalaan yang lemah, tetapi kita boleh mencapai hasil yang lebih baik dengan menggabungkannya dengan pengimbangan beban melalui beberapa kaedah.
Kita tidak boleh dan tidak sepatutnya berfikir tentang membuat seni bina seperti Alibaba dari awal aplikasi. Cara terbaik ialah melaksanakan apa yang diperlukan oleh aplikasi anda hari ini dan merancang lebih awal untuk kemungkinan pertumbuhan pesat.
Selain itu, masuk akal untuk mempunyai matlamat angka untuk kebolehskalaan, sama seperti kita mempunyai matlamat yang tepat untuk prestasi, memenuhi 10K atau 100K serentak. Ini boleh mengelakkan isu overhed seperti penyirian atau kebolehoperasian daripada dibawa ke dalam aplikasi kami melalui teori yang berkaitan.
Dari segi strategi pengembangan MySQL, apabila aplikasi biasa berkembang kepada saiz yang sangat besar, ia biasanya mula-mula bergerak dari satu pelayan kepada seni bina skala dengan pangkalan data siap sedia, dan kemudian ke pembahagian data atau pembahagian berfungsi . Perlu diingatkan di sini bahawa kami tidak menganjurkan nasihat seperti "shard as early as possible, shard as much as possible". Sebenarnya, sharding adalah kompleks dan mahal, dan yang paling penting, banyak aplikasi mungkin tidak memerlukannya sama sekali. Daripada menghabiskan banyak wang untuk sharding, adalah lebih baik untuk melihat perubahan dalam perkakasan baharu dan versi baharu MySQL Mungkin perubahan baharu ini akan mengejutkan anda.
Ringkasan
ialah penunjuk kuantitatif skalabiliti.
[Cadangan berkaitan: tutorial video mysql]
Atas ialah kandungan terperinci Apakah pengimbangan beban dalam mysql. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!









![Penyelesaian pengoptimuman pertanyaan MySQL [diajar oleh arkitek daripada pengeluar utama] [Bermula dengan Penalaan MySQL |](https://img.php.cn/upload/course/000/000/068/6242a7d5be236814.png)









![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



