

Menurut The Information, bekas penyelidik kecerdasan buatan Google Jacob Devlin baru-baru ini meninggalkan syarikat itu untuk menyertai OpenAI, tetapi sebelum itu, dia mendedahkan bahawa dia telah memberi amaran kepada Sundar Pichai, Ketua Pegawai Eksekutif syarikat induk Google Alphabet, bahawa Google The chatbot Bard mendapat data daripada ChatGPT secara tidak langsung.

Adakah anda masih ingat bahawa Baidu Wenxin disoal sebagai insiden "cangkang"? Baru-baru ini, media asing menyebarkan berita bahawa Google nampaknya melakukan perkara yang sama.
Menurut The Information, bekas penyelidik kecerdasan buatan Google Jacob Devlin baru-baru ini meninggalkan syarikat itu untuk menyertai OpenAI, tetapi sebelum itu, dia mendedahkan bahawa dia telah mendedahkan kepada Sundar Pichai, Ketua Pegawai Eksekutif syarikat induk Google Alphabet Warning, bot sembang Google Bard mendapat data daripada ChatGPT secara tidak langsung.
Menurut penerangan Devlin, pasukan pembangunan Bard melawat tapak web yang dipanggil ShareGPT, yang berkongsi dan menerbitkan sejumlah besar kandungan sembang yang diperoleh pengguna melalui ChatGPT. Ini bermakna Bard menggunakan data siap sedia ChatGPT untuk "mempersenjatai" dirinya sendiri, yang sama dengan mencuri keputusan awal ChatGPT.

Sebagai tindak balas, jurucakap Google Chris Pappas dengan cepat mengeluarkan kenyataan kepada media, dengan tegas dan jelas menyatakan, "Bard tidak menggunakan sebarang data ShareGPT atau ChatGPT untuk latihan. ( " Bard tidak dilatih tentang mana-mana data daripada ShareGPT atau ChatGPT.")"
Apabila ditanya oleh media sama ada Google Bard pernah menggunakan data ChatGPT sebelum ini, Pappas enggan menjawab, menegaskan bahawa apa yang dia boleh katakan adalah perkara di atas kenyataan.
Insiden ini tidak dapat membantu tetapi mengingatkan orang ramai tentang keraguan serupa yang dihadapi oleh Baidu Wenxinyiyan baru-baru ini.
Pada penghujung bulan Mac, seorang netizen menyiarkan soalan yang mempersoalkan lukisan Yiyan Baidu Wenxin, yang pada asasnya bermaksud “mesin menterjemah ayat bahasa Cina ke dalam perkataan Inggeris, menggunakan kecerdasan buatan Stable Diffusion yang baru sahaja dibuka sumbernya di luar negara untuk menghasilkan gambar. , dan kemudian mengembalikannya ke bahasa Inggeris, saya katakan saya melukisnya sendiri.”
Contoh yang diberikan oleh netizen pada masa itu termasuk Wen Xinyiyan memasukkan arahan dan memintanya melukis "tikus dan bas", dan gambar yang Wenxinyiyan buat ialah “mouse” dan bas”, kerana bahasa Inggeris untuk “mouse” dan “bas” ialah “mouse” dan “bus”.
Baidu juga bertindak balas dengan segera. Pada 23 Mac, Baidu mengeluarkan kenyataan yang menyatakan bahawa Wenxin Yiyan sepenuhnya merupakan model bahasa besar yang dibangunkan oleh Baidu, dan keupayaan graf Wenxin berasal daripada model besar rentas mod Wenxin ERNIE-ViLG. Dalam latihan model besar, Baidu menggunakan data awam Internet global, yang selaras dengan amalan industri. Pada masa yang sama, beliau berkata bahawa Wen Xinyiyan sentiasa belajar dan berkembang semasa proses penggunaan, dan berharap semua orang akan mempunyai sedikit keyakinan dalam teknologi dan produk yang dibangunkan sendiri.
Seterusnya, Baidu membetulkan masalah yang sama dan pengguna tidak lama kemudian mendapati bahawa masalah yang berkaitan tidak lagi wujud, menunjukkan bahawa situasi yang sama sedang diperbetulkan berdasarkan maklum balas pengguna.
Mengenai soalan Baidu Wen Xinyiyan, pakar industri juga berkata bahawa penggunaan data awam dalam talian adalah operasi industri asas. Terdapat beberapa penyedia perkhidmatan perantaraan dalam industri ini yang pakar dalam melatih data untuk aplikasi AI. Set data AI yang mereka latih berdasarkan anotasi data awam sememangnya digunakan oleh berbilang aplikasi AI pada masa yang sama.
Walau bagaimanapun, operasi asas dalam industri mungkin tidak mendapat pemahaman dan pengiktirafan yang sama di peringkat pengguna Kali ini, Google Bard didedahkan menggunakan data ChatGPT untuk latihan, yang turut mencetuskan kekecohan di luar negara menuduh Google mencuri keputusan OpenAI.
Data awam di Internet, termasuk maklumat laman web, mudah ditangkap dengan cara teknikal, yang merupakan kek untuk Google, yang merupakan enjin carian. Di samping itu, pendedahan sedemikian datang daripada pekerja Google yang baru meletak jawatan, jadi kredibiliti secara semula jadi telah bertambah baik.
Walau bagaimanapun, sesetengah netizen menyatakan bahawa Devlin menyertai pesaing OpenAI selepas meninggalkan pasukan Google AI sudah pastinya melibatkan kepentingan komersial, dan kesahihannya perlu disahkan lagi.
Walau bagaimanapun, menurut Geek.com, tidak kira betapa benar kejadian seperti itu, ia sepenuhnya menunjukkan "peraturan besi": bidang model AI yang besar benar-benar ketinggalan selangkah demi selangkah, dan mereka yang lewat mahu mengejar penggerak pertama Ia adalah tahap, ia tidak mudah.
Terdapat banyak faktor yang mempengaruhi di sebalik ini, termasuk algoritma, kuasa pengkomputeran dan kualiti data latihan. Apa yang lebih penting ialah selepas model AI besar pertama mencapai kejayaan, ia akan terus berlatih dan berkembang, dan tidak akan berhenti dan menunggu pengejar.
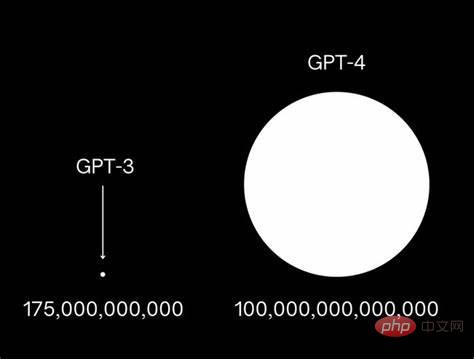
Oleh sebab itu, GPT OpenAI telah dinaik taraf dengan pantas daripada GPT-3 kepada era GPT-4 Ini juga telah mencetuskan beberapa selebriti, termasuk Musk, untuk bersama-sama mengeluarkan surat terbuka menyeru syarikat besar untuk. menangguhkan operasi berskala besar pembangunan model untuk mengelakkan mengancam manusia.
Robin Li juga berkata dalam wawancara dengan media sebelum ini bahawa walaupun dia menunjukkan prestasi yang lebih baik di beberapa kawasan, secara keseluruhan Baidu Wenxinyiyan dan OpenAI ChatGPT masih ada jurang satu atau dua bulan antara tahap. Beliau juga menegaskan bahawa apabila ChatGPT mula-mula dilancarkan, maklum balas luaran adalah lebih teruk daripada Wen Xinyiyan.
Satu lagi berita buruk untuk Google Bard ialah pasukan kecerdasan buatan Otak Google dikhabarkan akan bekerjasama dengan DeepMind, sebuah lagi syarikat kecerdasan buatan yang bergabung dengan Alphabet, dalam projek baharu yang diberi nama kod Gemini, dengan matlamat untuk membangunkan Dapatkan produk yang boleh bersaing dengan GPT OpenAI. Ini seolah-olah membayangkan bahawa Google tidak yakin dengan Bard dan berharap untuk membangunkan model besar AI yang lebih maju dan mencipta robot sembang AI yang lebih maju.
Atas ialah kandungan terperinci Google juga melakukannya? Bard didedahkan menggunakan data ChatGPT untuk latihan Model besar itu benar-benar ketinggalan langkah demi langkah.. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 Pendaftaran ChatGPT
Pendaftaran ChatGPT
 Ensiklopedia ChatGPT percuma domestik
Ensiklopedia ChatGPT percuma domestik
 Bagaimana untuk memasang chatgpt pada telefon bimbit
Bagaimana untuk memasang chatgpt pada telefon bimbit
 Bolehkah chatgpt digunakan di China?
Bolehkah chatgpt digunakan di China?
 Mana yang lebih baik untuk belajar dahulu, bahasa c atau c++?
Mana yang lebih baik untuk belajar dahulu, bahasa c atau c++?
 windows tidak boleh membuka add printer
windows tidak boleh membuka add printer
 Penggunaan penyentuh AC
Penggunaan penyentuh AC
 Peranan fungsi float() dalam python
Peranan fungsi float() dalam python








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



