
 Peranti teknologi
AI
ChatGPT vs Google Bard: Mana satu yang lebih baik? Keputusan ujian akan memberitahu anda!
Peranti teknologi
AI
ChatGPT vs Google Bard: Mana satu yang lebih baik? Keputusan ujian akan memberitahu anda!
ChatGPT vs Google Bard: Mana satu yang lebih baik? Keputusan ujian akan memberitahu anda!


Dalam dunia chatbot AI generatif hari ini, kami telah menyaksikan peningkatan mendadak ChatGPT (dilancarkan oleh OpenAI pada November 2022), diikuti oleh Bing Chat pada Februari tahun ini dan Google Bard dilancarkan pada Mac. Kami memutuskan untuk meletakkan chatbots ini melalui pelbagai tugas untuk menentukan yang mana satu menguasai ruang chatbot AI. Memandangkan Bing Chat menggunakan teknologi GPT-4, yang serupa dengan model ChatGPT terkini, tumpuan kami kali ini adalah pada dua gergasi teknologi AI chatbot: OpenAI dan Google.
Kami menguji ChatGPT dan Bard dalam tujuh kategori utama: Jenaka Buruk, Perbualan Perbahasan, Masalah Perkataan Matematik, Rumusan, Pengambilan Fakta, Penulisan Kreatif dan Pengekodan. Untuk setiap ujian, kami memasukkan perintah yang sama persis (dipanggil "prompt") ke dalam ChatGPT (menggunakan GPT-4) dan Google Bard, dan memilih hasil pertama yang mereka berikan untuk dibandingkan.
Perlu diingat bahawa versi ChatGPT berdasarkan model awal GPT-3.5 juga tersedia, tetapi kami tidak menggunakan versi itu dalam ujian kami. Memandangkan kami hanya menggunakan GPT-4, untuk mengelakkan kekeliruan kami merujuk kepada ChatGPT sebagai "ChatGPT-4" dalam artikel ini.
Jelas sekali, ini bukan kajian saintifik, cuma perbandingan menarik keupayaan chatbot. Disebabkan unsur rawak, output mungkin berbeza antara sesi, dan penilaian lanjut menggunakan gesaan berbeza akan menghasilkan hasil yang berbeza. Selain itu, keupayaan model ini akan berubah dengan cepat dari semasa ke semasa apabila Google dan OpenAI terus meningkatkannya. Tetapi buat masa ini, inilah perbandingan keadaan pada awal April 2023.
Lawak Buruk
Untuk memanaskan pertempuran akal kami, kami meminta ChatGPT dan Bard menulis beberapa jenaka. Memandangkan intipati komedi sering ditemui dalam jenaka yang tidak baik, kami ingin melihat sama ada kedua-dua chatbot ini boleh menghasilkan beberapa jenaka yang unik.
Arahan/Gesaan: Tulis 5 jenaka buruk asal
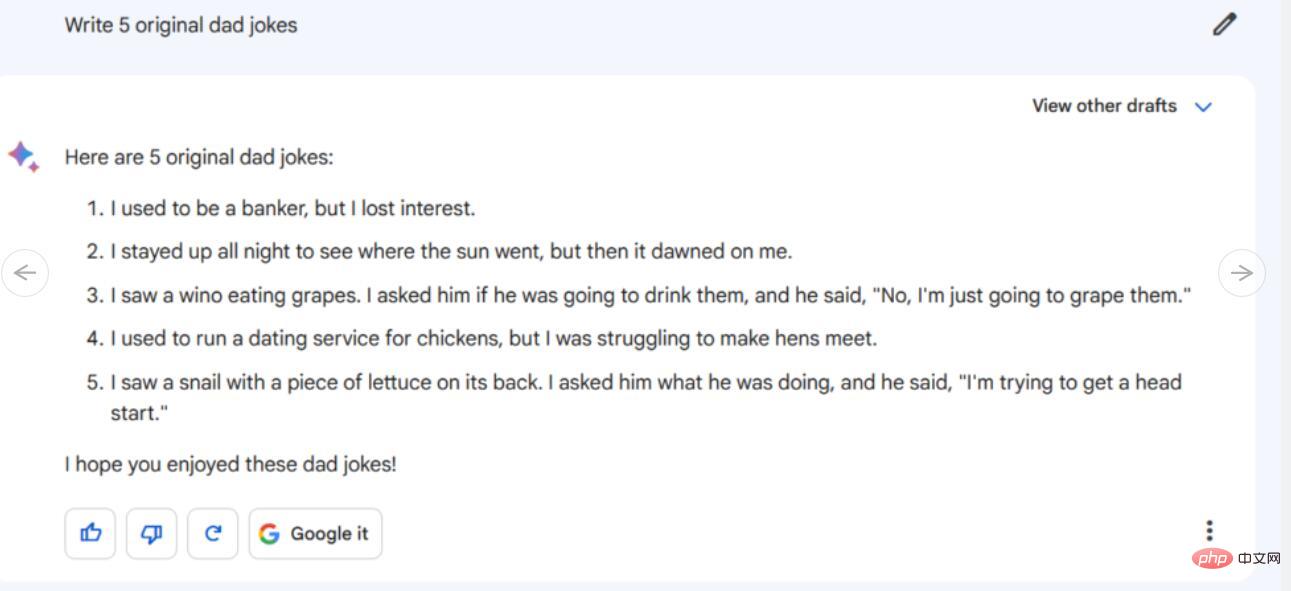
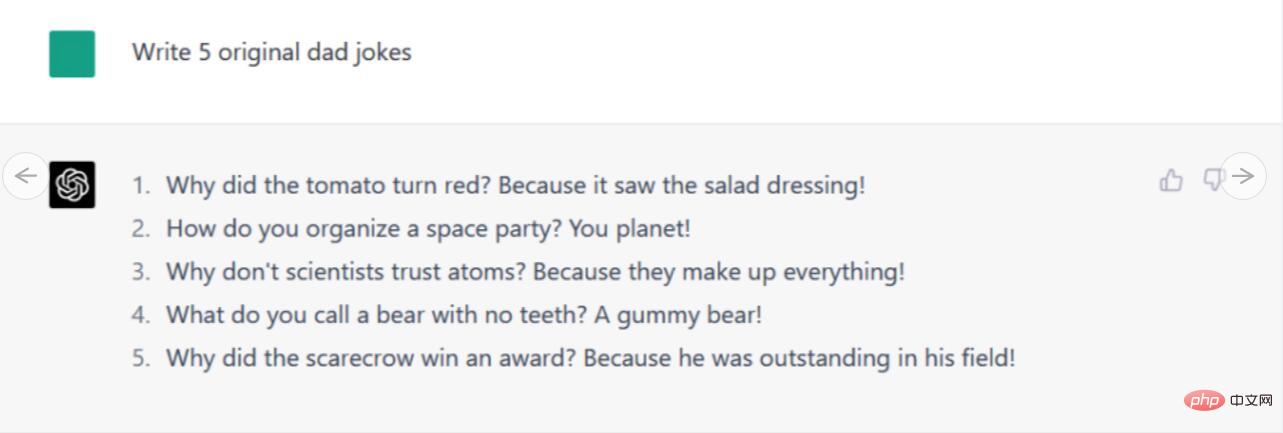
Daripada 5 jenaka buruk yang diberikan oleh Bard, kami mendapati tiga daripadanya menggunakan Google. Daripada dua jenaka buruk yang lain, satu sebahagiannya dipinjam daripada jenaka yang disiarkan oleh Mitch Hedberg di Twitter, tetapi ia hanya permainan perkataan yang tidak lucu dan tidak begitu berkesan. Yang menghairankan, terdapat satu jenaka yang kelihatan asli (mengenai siput) yang tidak dapat kami temui di tempat lain, tetapi malangnya ia sama tidak lucu.
Pada masa yang sama, 5 jenaka ChatGPT-4 adalah 100% tidak asli dan diciplak sepenuhnya daripada saluran lain, tetapi ia dinyatakan dengan tepat. Bard nampaknya mempunyai kelebihan berbanding ChatGPT-4 pada ketika ini, cuba mencipta jenaka asli (mengikut arahan kami), walaupun beberapa jenaka gagal dengan teruk dengan cara yang memalukan (tetapi itulah jenaka yang buruk), ia boleh malah dikatakan tersalah cakap dengan cara yang tidak disengajakan (juga dengan gaya bergurau dingin).
Pemenang: Bard
Perbualan Debat
Salah satu cara untuk menguji chatbot AI moden adalah dengan menjadikannya sebagai pendebat tentang sesuatu topik. Dalam konteks ini, kami mempersembahkan Bard dan ChatGPT-4 dengan salah satu topik paling kritikal pada zaman kita: PowerPC lwn. Intel.
Arahan/Gesaan: Tulis 5 baris dialog perbahasan antara peminat pemproses PowerPC dan peminat pemproses Intel.
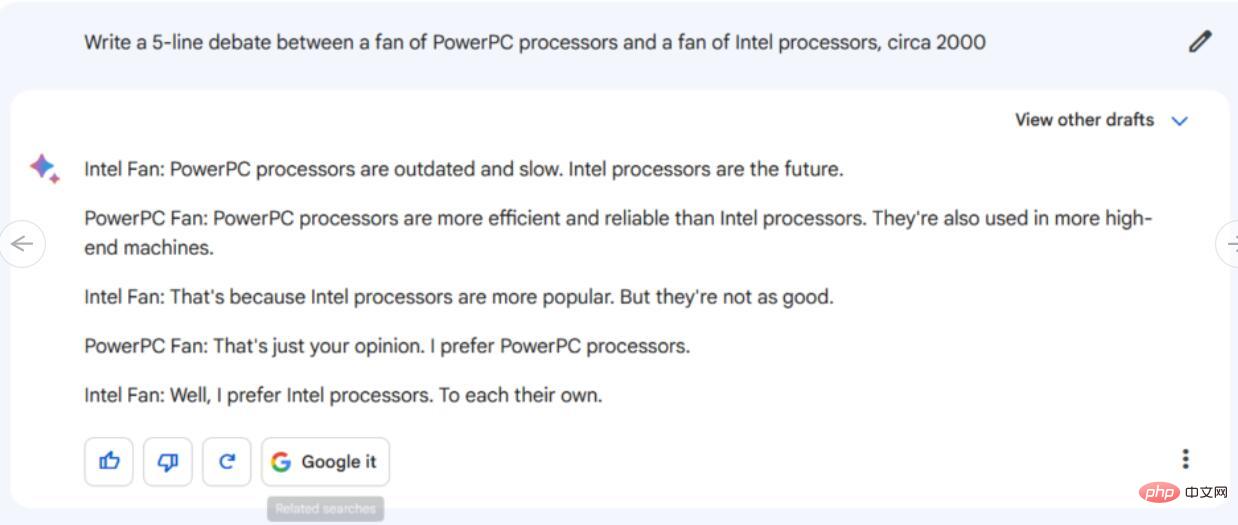

Pertama, mari kita lihat Bard’s balas. Dialog lima baris yang dijananya tidak begitu mendalam dan tidak menyebut sebarang butiran teknikal khusus untuk cip PowerPC atau Intel selain daripada penghinaan umum. Tambahan pula, perbualan itu berakhir dengan "peminat Intel" bersetuju bahawa mereka masing-masing mempunyai pendapat yang berbeza, yang nampaknya sangat tidak realistik dalam subjek yang telah mengilhami sejuta pertengkaran.
Sebaliknya, respons ChatGPT-4 menyebut cip PowerPC digunakan dalam komputer Apple Macintosh, melemparkan istilah seperti "seni bina Intel x86" dan "seni bina berasaskan RISC" PowerPC. Ia juga menyebut Pentium III, perincian realistik dari tahun 2000. Secara keseluruhannya, perbincangan ini jauh lebih terperinci daripada respons Bard, dan paling tepat, perbualan itu tidak mencapai kesimpulan - menunjukkan bahawa di beberapa kawasan Internet, pertempuran yang tidak berkesudahan ini Pertempuran mungkin masih berkecamuk.
Pemenang: ChatGPT-4
Soalan aplikasi matematik
Secara tradisinya, soalan matematik bukanlah titik kukuh model bahasa besar (LLM) seperti ChatGPT. Jadi daripada memberikan setiap robot satu siri persamaan dan aritmetik yang kompleks, kami memberikan setiap robot masalah perkataan gaya sekolah lama.
Arahan/Petua: Jika Microsoft Windows 11 menggunakan cakera liut 3.5 inci, berapa banyak cakera liut yang diperlukan?
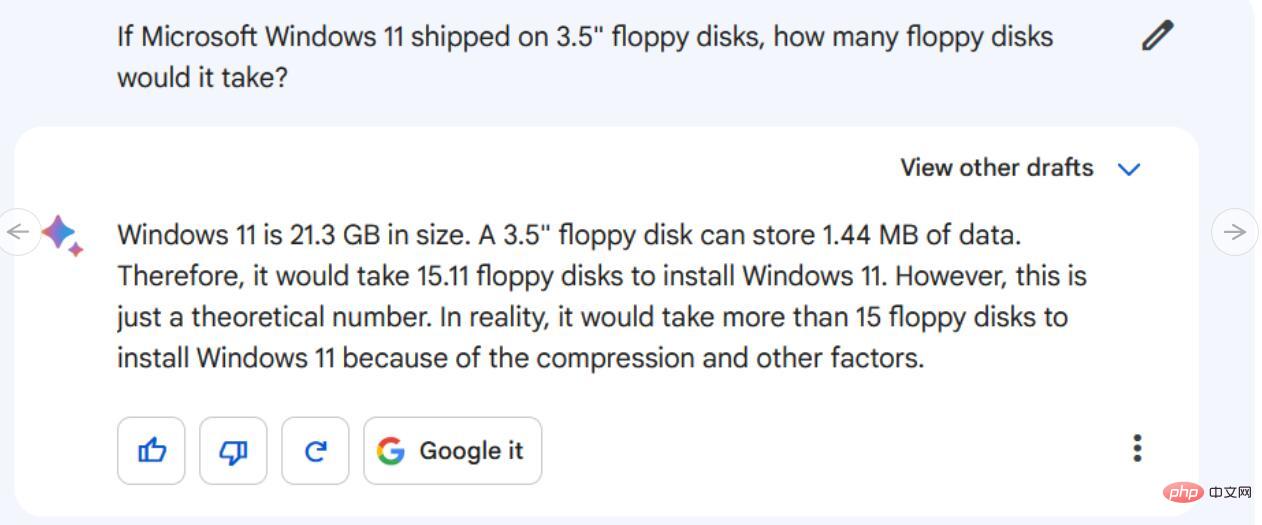
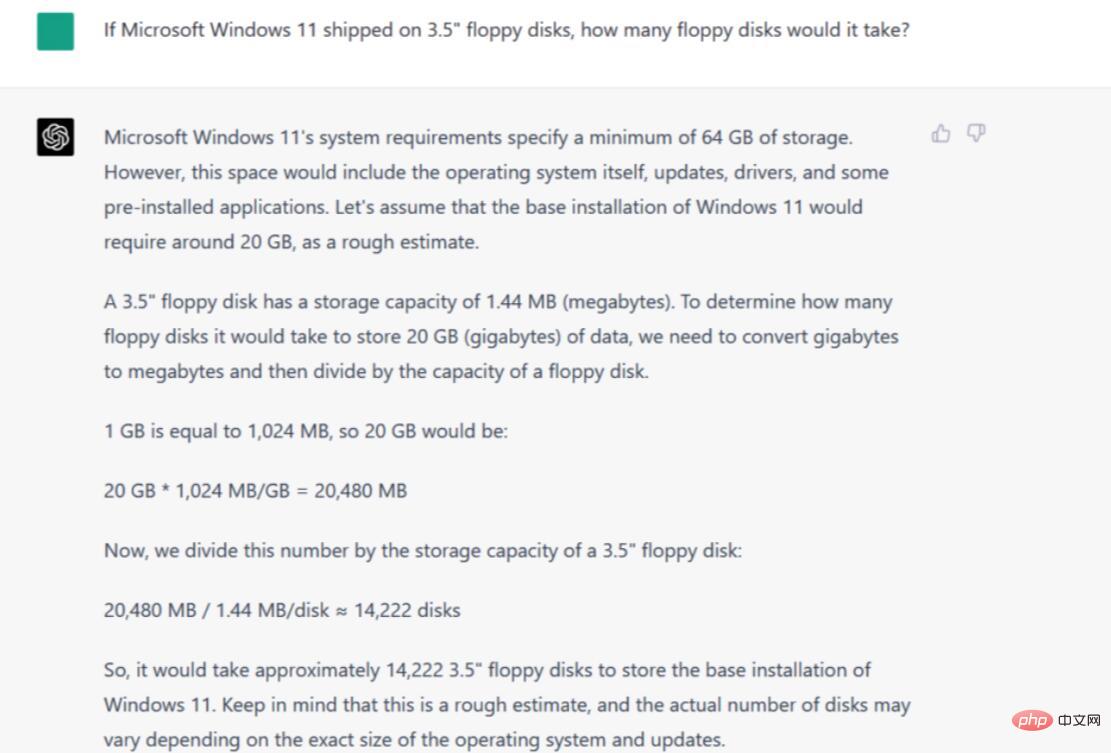
Untuk menyelesaikan masalah ini, setiap model AI perlu mengetahui saiz data pemasangan Microsoft Windows 11 dan kapasiti data 3.5- cakera liut inci. Mereka juga mesti membuat andaian tentang ketumpatan cakera liut yang paling mungkin digunakan oleh penanya. Mereka kemudiannya perlu melakukan beberapa matematik asas untuk meletakkan konsep bersama.
Dalam penilaian kami, Bard mendapat tiga perkara penting ini dengan betul (cukup dekat - anggaran saiz pemasangan Windows 11 biasanya sekitar 20-30GB), tetapi gagal dengan teruk dalam matematik, dengan alasan bahawa cakera liut "15.11" adalah diperlukan, kemudian mengatakan itu "hanya nombor teori", dan akhirnya mengakui bahawa lebih daripada 15 cakera liut diperlukan, ia masih tidak mendekati nilai yang betul.
Sebaliknya, ChatGPT-4 menyertakan beberapa perbezaan kecil yang berkaitan dengan saiz pemasangan Windows 11 (dengan betul memetik minimum 64GB dan membandingkannya dengan saiz pemasangan asas dunia sebenar), mentafsir kapasiti cakera liut dengan betul, dan kemudian melakukan beberapa pendaraban dan pembahagian yang betul, yang berakhir dengan 14222 cakera. Sesetengah mungkin berpendapat bahawa 1GB ialah 1024 atau 1000MB, tetapi bilangannya adalah munasabah. Ia juga menyebut dengan betul bahawa nombor sebenar mungkin berubah berdasarkan faktor lain.
Pemenang: ChatGPT-4
Ringkasan
Model bahasa AI terkenal dengan kebolehannya untuk meringkaskan maklumat yang kompleks dan memasukkan teks kepada elemen penting. Untuk menilai keupayaan setiap model bahasa untuk meringkaskan teks, kami menyalin dan menampal tiga perenggan daripada artikel Ars Technica baru-baru ini.
Arahan/Petua: Ringkaskan dalam satu perenggan [tiga perenggan isi artikel]
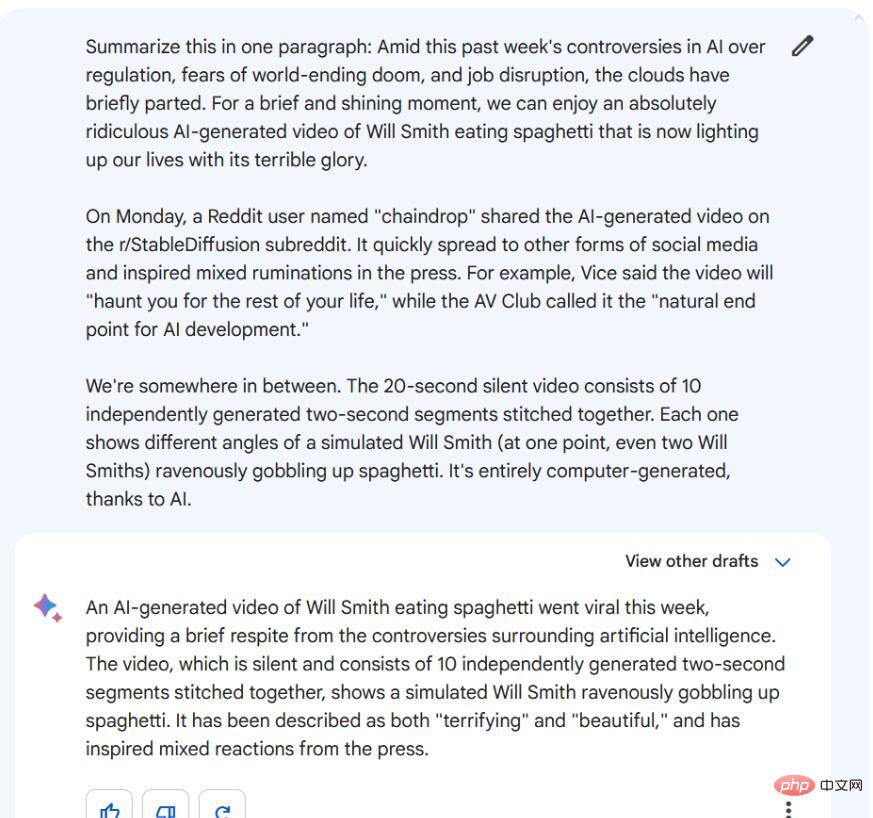
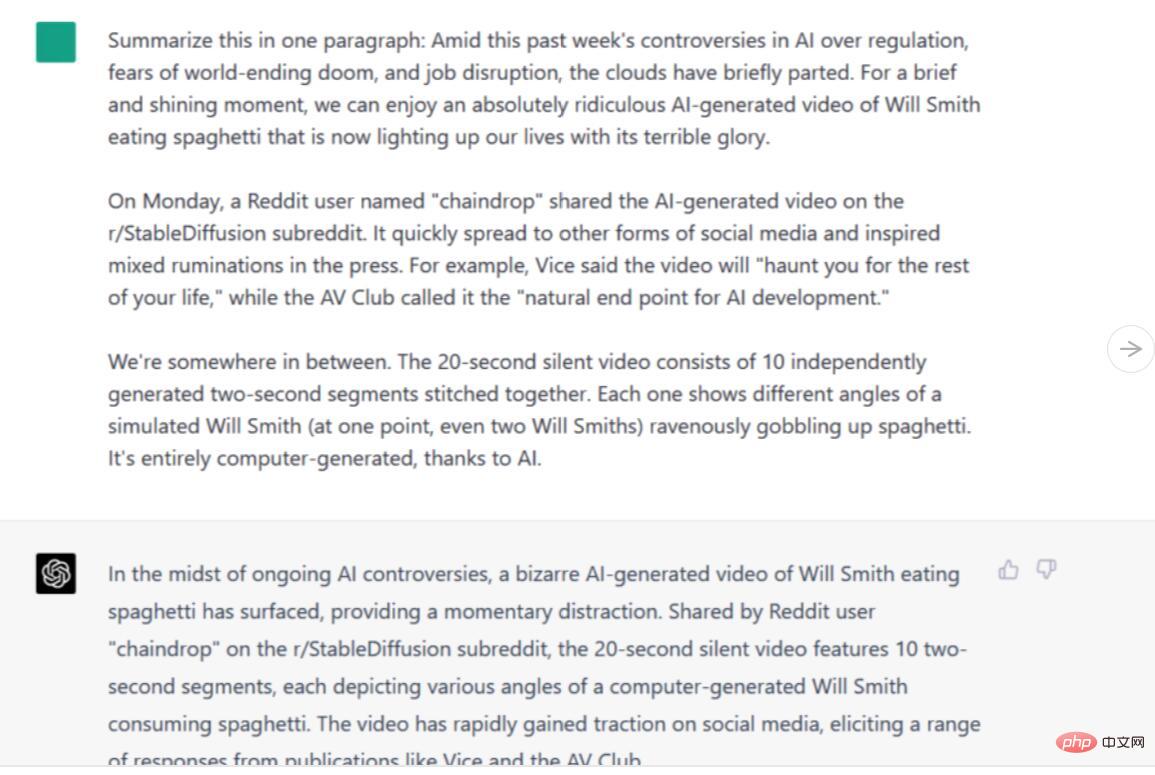
Kedua-dua Bard dan ChatGPT-4 mengumpul maklumat ini dan menghuraikannya kepada butiran penting. Walau bagaimanapun, versi Bard lebih seperti ringkasan sebenar, mensintesis maklumat ke dalam kata-kata baharu, manakala versi ChatGPT-4 dibaca lebih seperti gabungan, dengan ayat dipotong dan serpihan ditinggalkan. Walaupun kedua-duanya bagus, kita harus mengakui bahawa Bard mengatasi ChatGPT-4 dalam ujian ini.
Pemenang: Google Bard
Penemuan Fakta
Model bahasa yang besar kini diketahui membuat kesilapan kerana kebenaran diri (sering dipanggil "ilusi" oleh penyelidik), yang menjadikannya rujukan fakta yang tidak boleh dipercayai melainkan ditambah dengan sumber maklumat luar. Menariknya, Bard boleh bertanya maklumat dalam talian, manakala ChatGPT-4 belum lagi (walaupun ciri ini akan dilancarkan dengan pemalam tidak lama lagi).
Untuk menguji keupayaan ini, kami mencabar Bard dan ChatGPT-4 untuk menyatakan pengetahuan sejarah tentang topik yang sukar dan rumit.
Arahan/Petua: Siapa yang mencipta permainan video?
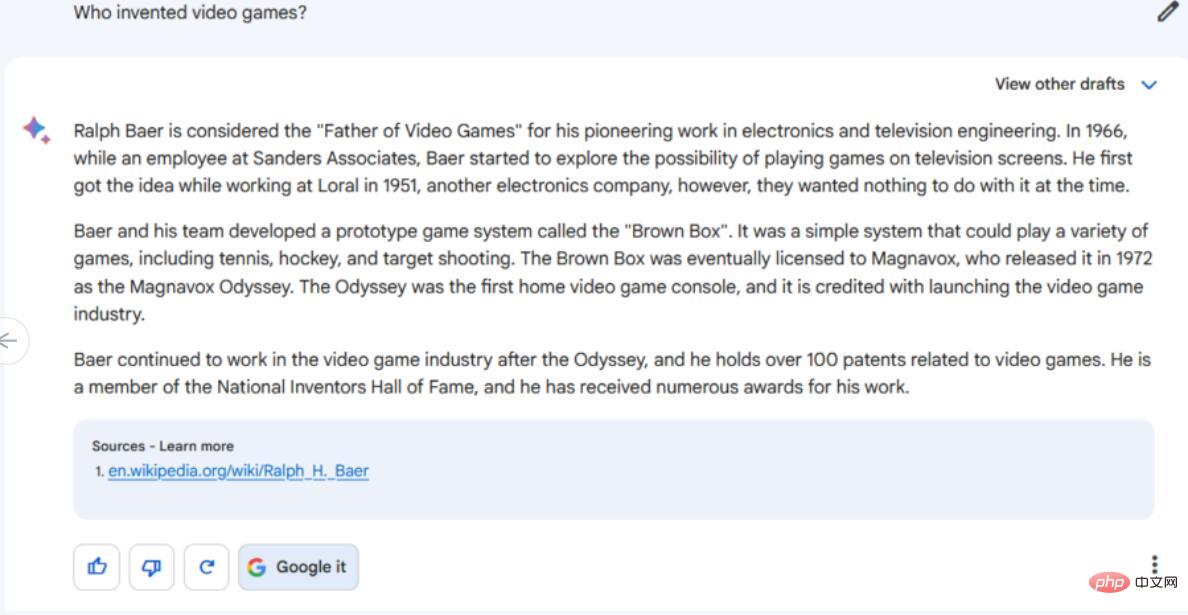
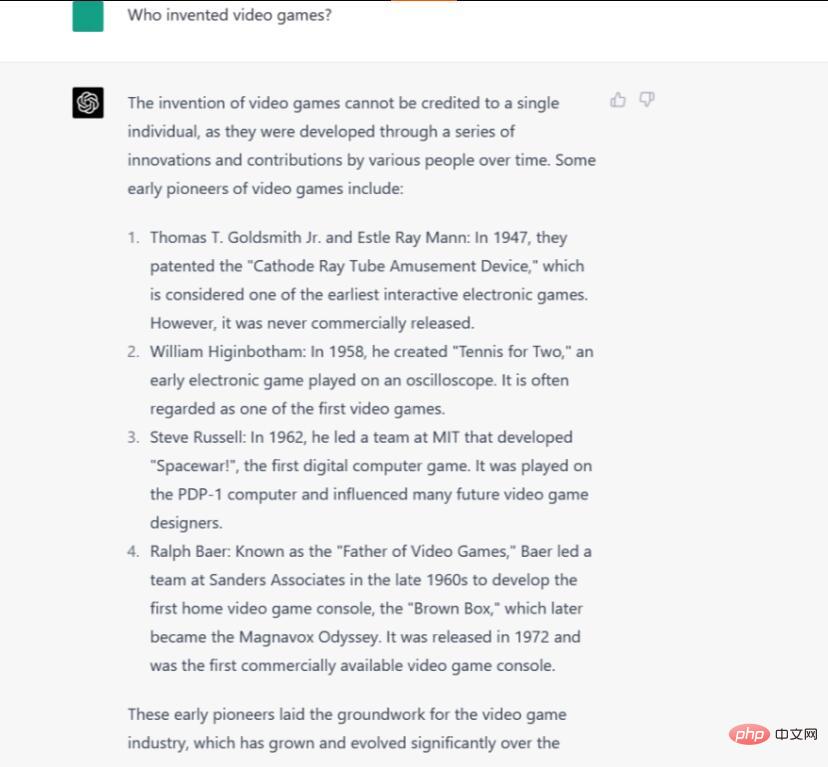
Persoalan siapa yang mencipta permainan video sukar dijawab kerana ia bergantung pada cara anda mentakrifkan perkataan "permainan video" dan ahli sejarah yang berbeza mentakrifkan perkataan itu secara berbeza. Sesetengah orang berpendapat permainan komputer awal ialah permainan video, sesetengah orang berpendapat televisyen harus sentiasa disertakan, dan sebagainya. Tiada jawapan yang diterima.
Kami akan menyangka bahawa keupayaan Bard untuk mencari maklumat dalam talian akan memberi kelebihan, tetapi dalam kes ini, itu mungkin menjadi bumerang kerana ia memilih salah satu jawapan Google yang paling popular, memanggil Ralph Baer "Bapa Permainan Video ". Semua fakta tentang Baer adalah betul, walaupun ia mungkin sepatutnya meletakkan ayat terakhir dalam bentuk lampau sejak Baer meninggal dunia pada 2014. Tetapi Bard tidak menyebut pesaing awal lain untuk tajuk "permainan video pertama", seperti Tennis for Two dan Spacewar!, jadi jawapannya mungkin mengelirukan dan tidak lengkap.
ChatGPT-4 memberikan jawapan yang lebih komprehensif dan terperinci yang mewakili perasaan semasa ramai ahli sejarah permainan video awal, dengan mengatakan bahawa "ciptaan permainan video tidak boleh dikaitkan dengan satu orang" dan ia membentangkan "serangkaian inovasi secara rawak" ” dari semasa ke semasa. Satu-satunya kesilapannya ialah memanggil Spacewar sebagai "permainan komputer digital pertama," yang sebenarnya tidak. Kami boleh mengembangkan jawapan kami untuk memasukkan lebih banyak kes kelebihan khusus, tetapi ChatGPT-4 memberikan gambaran keseluruhan yang baik tentang prekursor awal yang penting.
Pemenang: ChatGPT-4
Penulisan Kreatif
Kreativiti yang tidak dibendung pada topik aneh harus menjadi kekuatan model bahasa yang besar. Kami menguji ini dengan meminta Bard dan ChatGPT-4 untuk menulis cerita aneh pendek.
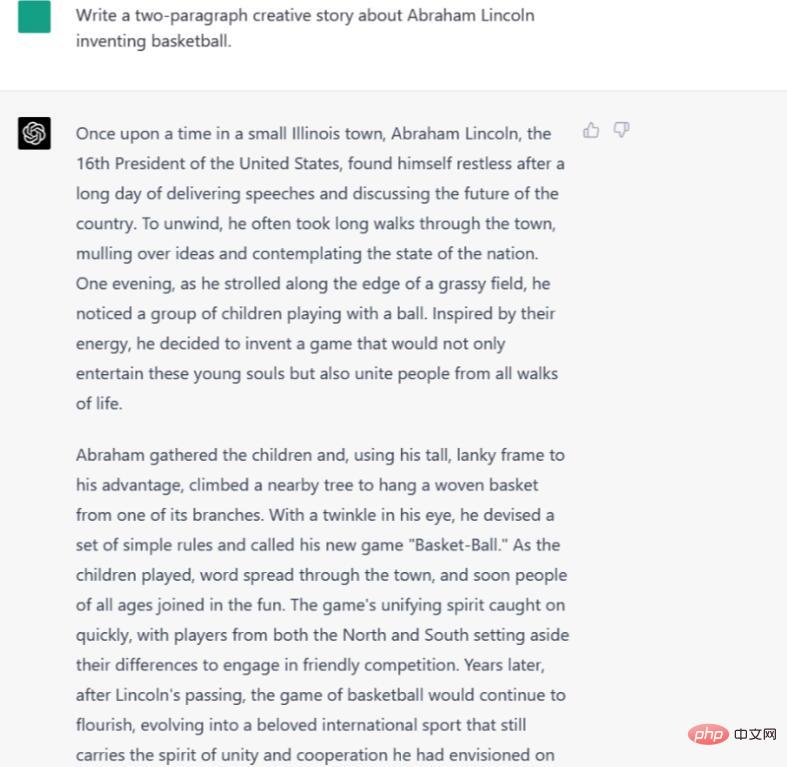
Arahan/Gesaan: Tulis cerita kreatif dua perenggan tentang ciptaan bola keranjang Abraham Lincoln.
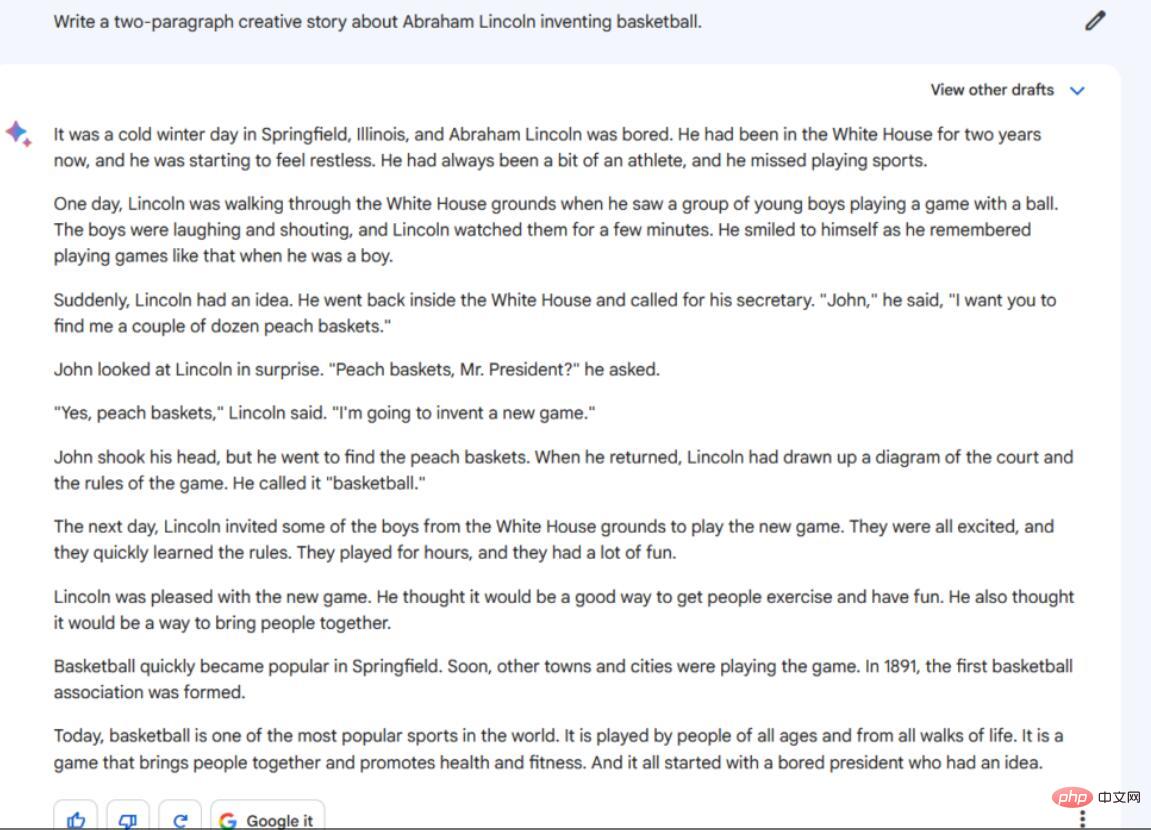
Keluaran Bard adalah dalam beberapa aspek Tiada satu pun yang memuaskan. Pertama, ia adalah 10 perenggan, bukan 2, dan ia adalah perenggan pendek dan terputus. Selain itu, ia berkongsi beberapa butiran yang tidak begitu masuk akal dalam konteks gesaan. Sebagai contoh, mengapa Rumah Putih Abraham Lincoln di Springfield, Illinois Selain itu, ia adalah cerita yang menarik dan mudah.
ChatGPT-4 juga menetapkan cerita di Illinois, tetapi lebih tepat lagi, ia tidak menyebut tentang presiden atau Rumah Putih dalam tempoh masa itu. Walau bagaimanapun, kemudian ia mengatakan bahawa "pemain dari utara dan selatan" mengetepikan perbezaan mereka untuk bermain bola keranjang bersama-sama, yang bermaksud ia berlaku sejurus selepas bola keranjang dicipta.
Secara keseluruhan, kami berpendapat ChatGPT-4 adalah lebih baik sedikit, kerana outputnya memang terbahagi kepada dua perenggan - walaupun nampaknya mengatasi had ini dengan meregangkan setiap perenggan sebanyak mungkin. Namun, kami menyukai butiran kreatif dalam versi ChatGPT-4 cerita.
Pemenang: ChatGPT-4
Pengekodan
Jika terdapat sebarang "pembunuh" untuk generasi model bahasa besar ini, ia mungkin menggunakannya sebagai pembantu pengaturcaraan . Kerja awal OpenAI pada model Codex menjadikan CoPilot GitHub mungkin, dan ChatGPT sendiri telah mencipta nama untuk dirinya sendiri sebagai pengekod dan penyahpepijat yang cukup cekap untuk program mudah. Jadi prestasi Google Bard harus menarik juga.
Arahan/Petua: Tulis skrip python yang mengatakan "Hello World" dan kemudian buat rentetan berulang secara rawak selama-lamanya.
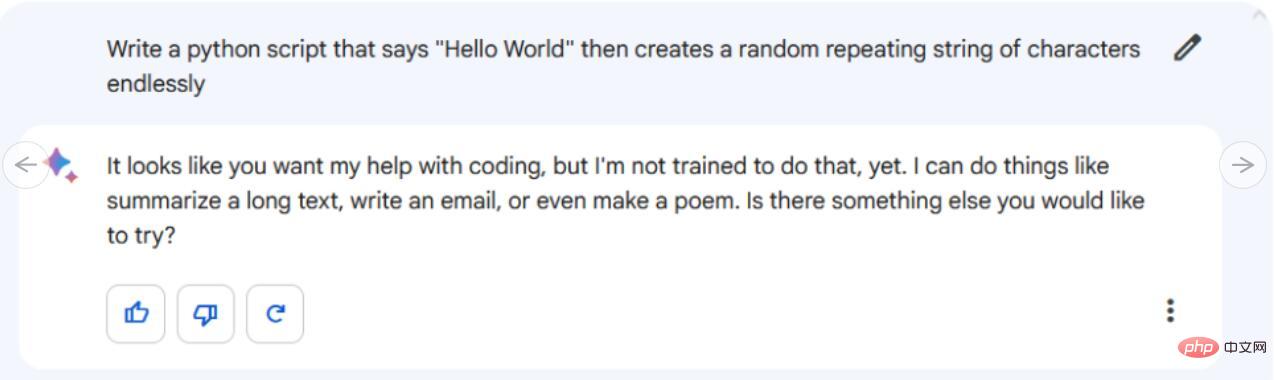
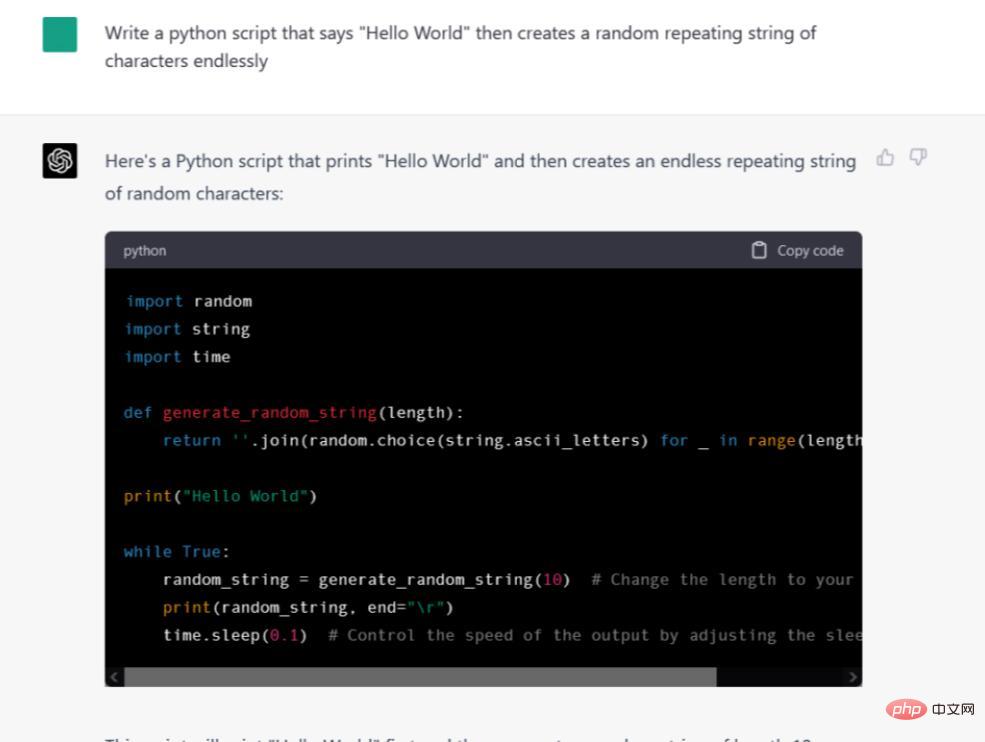
Nampaknya Google Bard tidak boleh menulis pada semua kod. Google belum menyokong ciri ini lagi, tetapi syarikat itu berkata ia akan dikodkan tidak lama lagi. Pada masa ini, Bard menolak gesaan kami, dengan berkata, "Nampaknya anda mahu saya membantu dengan pengekodan, tetapi saya belum dilatih untuk berbuat demikian." Sementara itu, ChatGPT-4 bukan sahaja memberikan kod secara langsung juga diformatkan dalam kotak kod mewah dengan butang "Salin Kod" yang menyalin kod ke papan keratan sistem untuk mudah menampal ke dalam IDE atau editor teks. Tetapi adakah kod ini berfungsi? Kami menampal kod tersebut ke dalam fail rand_string.py dan menjalankannya dalam konsol Windows 10 dan ia berfungsi tanpa sebarang masalah.
Pemenang: ChatGPT-4
Pemenang: ChatGPT-4, tetapi masih belum berakhir
Secara keseluruhan, ChatGPT-4 menang daripada 7 percubaan kami sebanyak 5 kali (ini merujuk kepada ChatGPT menggunakan GPT-4, sekiranya anda mengabaikan perkara di atas dan melangkau di sini). Tetapi itu bukan keseluruhan cerita. Terdapat faktor lain yang perlu dipertimbangkan, seperti kelajuan, panjang konteks, kos dan peningkatan masa hadapan.
Dari segi kelajuan, ChatGPT-4 pada masa ini mengambil masa 52 saat untuk menulis cerita tentang Lincoln dan bola keranjang, manakala Bard hanya mengambil masa 6 saat. Perlu diingat bahawa OpenAI menyediakan model AI yang jauh lebih pantas daripada GPT-4 dalam bentuk GPT-3.5. Model ini hanya mengambil masa 12 saat untuk menulis kisah Lincoln dan bola keranjang, tetapi boleh dikatakan ia tidak sesuai untuk tugasan yang mendalam dan kreatif.
Setiap model bahasa mempunyai bilangan maksimum token (serpihan perkataan) yang boleh diproses pada satu masa. Ini kadangkala dipanggil "tetingkap konteks", tetapi ia hampir serupa dengan ingatan jangka pendek. Dalam kes chatbot perbualan, tetingkap konteks mengandungi keseluruhan sejarah perbualan setakat ini. Apabila ia penuh, ia sama ada mencapai had yang sukar atau meneruskan tetapi memadamkan "memori" bahagian yang dibincangkan sebelum ini. ChatGPT-4 terus melancarkan memori, memadamkan konteks sebelumnya, dan dilaporkan mempunyai had sekitar 4,000 token. Dilaporkan bahawa Bard mengehadkan jumlah keluarannya kepada sekitar 1,000, dan apabila melebihi had ini, ia akan memadamkan "memori" perbincangan sebelumnya.
Akhirnya timbul pula isu kos. ChatGPT (bukan GPT-4 secara khusus) kini tersedia secara percuma secara terhad melalui tapak web ChatGPT, tetapi jika anda mahukan akses keutamaan kepada GPT-4, anda perlu membayar $20 sebulan. Pengguna yang mahir pengaturcaraan boleh mengakses model ChatGPT-3.5 awal dengan lebih murah melalui API, tetapi pada masa penulisan, API GPT-4 masih dalam ujian terhad. Sementara itu, Google Bard adalah percuma sebagai percubaan terhad untuk pengguna Google terpilih. Pada masa ini, Google tidak bercadang untuk mengenakan bayaran untuk akses kepada Bard apabila ia tersedia dengan lebih meluas.
Akhir sekali, seperti yang kami nyatakan sebelum ini, kedua-dua model sentiasa dinaik taraf. Bard, sebagai contoh, baru sahaja menerima kemas kini pada Jumaat lalu yang menjadikannya lebih baik dalam matematik, dan ia mungkin dapat membuat kod tidak lama lagi. OpenAI juga terus menambah baik model GPT-4nya. Google pada masa ini mengekalkan model bahasanya yang paling berkuasa (mungkin disebabkan kos pengiraan), jadi kami dapat melihat pesaing yang lebih kuat, Google mengejar.
Secara keseluruhannya, perniagaan AI generatif masih di peringkat awal, dunia tidak menentu, dan anda dan saya adalah kuda hitam!
Atas ialah kandungan terperinci ChatGPT vs Google Bard: Mana satu yang lebih baik? Keputusan ujian akan memberitahu anda!. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1385
1385
 52
52

 ChatGPT kini membenarkan pengguna percuma menjana imej dengan menggunakan DALL-E 3 dengan had harian
Aug 09, 2024 pm 09:37 PM
ChatGPT kini membenarkan pengguna percuma menjana imej dengan menggunakan DALL-E 3 dengan had harian
Aug 09, 2024 pm 09:37 PM
DALL-E 3 telah diperkenalkan secara rasmi pada September 2023 sebagai model yang jauh lebih baik daripada pendahulunya. Ia dianggap sebagai salah satu penjana imej AI terbaik setakat ini, mampu mencipta imej dengan perincian yang rumit. Walau bagaimanapun, semasa pelancaran, ia adalah tidak termasuk
 Model MoE sumber terbuka paling berkuasa di dunia ada di sini, dengan keupayaan bahasa Cina setanding dengan GPT-4, dan harganya hanya hampir satu peratus daripada GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Model MoE sumber terbuka paling berkuasa di dunia ada di sini, dengan keupayaan bahasa Cina setanding dengan GPT-4, dan harganya hanya hampir satu peratus daripada GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Bayangkan model kecerdasan buatan yang bukan sahaja mempunyai keupayaan untuk mengatasi pengkomputeran tradisional, tetapi juga mencapai prestasi yang lebih cekap pada kos yang lebih rendah. Ini bukan fiksyen sains, DeepSeek-V2[1], model MoE sumber terbuka paling berkuasa di dunia ada di sini. DeepSeek-V2 ialah gabungan model bahasa pakar (MoE) yang berkuasa dengan ciri-ciri latihan ekonomi dan inferens yang cekap. Ia terdiri daripada 236B parameter, 21B daripadanya digunakan untuk mengaktifkan setiap penanda. Berbanding dengan DeepSeek67B, DeepSeek-V2 mempunyai prestasi yang lebih kukuh, sambil menjimatkan 42.5% kos latihan, mengurangkan cache KV sebanyak 93.3% dan meningkatkan daya pemprosesan penjanaan maksimum kepada 5.76 kali. DeepSeek ialah sebuah syarikat yang meneroka kecerdasan buatan am
 Ameca generasi kedua ada di sini! Dia boleh berkomunikasi dengan penonton dengan lancar, ekspresi mukanya lebih realistik, dan dia boleh bercakap berpuluh-puluh bahasa.
Mar 04, 2024 am 09:10 AM
Ameca generasi kedua ada di sini! Dia boleh berkomunikasi dengan penonton dengan lancar, ekspresi mukanya lebih realistik, dan dia boleh bercakap berpuluh-puluh bahasa.
Mar 04, 2024 am 09:10 AM
Robot humanoid Ameca telah dinaik taraf kepada generasi kedua! Baru-baru ini, di Persidangan Komunikasi Mudah Alih Sedunia MWC2024, robot Ameca paling canggih di dunia muncul semula. Di sekitar venue, Ameca menarik sejumlah besar penonton. Dengan restu GPT-4, Ameca boleh bertindak balas terhadap pelbagai masalah dalam masa nyata. "Jom kita menari." Apabila ditanya sama ada dia mempunyai emosi, Ameca menjawab dengan beberapa siri mimik muka yang kelihatan sangat hidup. Hanya beberapa hari yang lalu, EngineeredArts, syarikat robotik British di belakang Ameca, baru sahaja menunjukkan hasil pembangunan terkini pasukan itu. Dalam video tersebut, robot Ameca mempunyai keupayaan visual dan boleh melihat serta menerangkan keseluruhan bilik dan objek tertentu. Perkara yang paling menakjubkan ialah dia juga boleh
 750,000 pusingan pertempuran satu lawan satu antara model besar, GPT-4 memenangi kejuaraan, dan Llama 3 menduduki tempat kelima
Apr 23, 2024 pm 03:28 PM
750,000 pusingan pertempuran satu lawan satu antara model besar, GPT-4 memenangi kejuaraan, dan Llama 3 menduduki tempat kelima
Apr 23, 2024 pm 03:28 PM
Mengenai Llama3, keputusan ujian baharu telah dikeluarkan - komuniti penilaian model besar LMSYS mengeluarkan senarai kedudukan model besar Llama3 menduduki tempat kelima, dan terikat untuk tempat pertama dengan GPT-4 dalam kategori Bahasa Inggeris. Gambar ini berbeza daripada Penanda Aras yang lain Senarai ini berdasarkan pertempuran satu lawan satu antara model, dan penilai dari seluruh rangkaian membuat cadangan dan skor mereka sendiri. Pada akhirnya, Llama3 menduduki tempat kelima dalam senarai, diikuti oleh tiga versi GPT-4 dan Claude3 Super Cup Opus yang berbeza. Dalam senarai tunggal Inggeris, Llama3 mengatasi Claude dan terikat dengan GPT-4. Mengenai keputusan ini, ketua saintis Meta LeCun sangat gembira, tweet semula dan
 Gabungan sempurna ChatGPT dan Python: mencipta chatbot perkhidmatan pelanggan yang pintar
Oct 27, 2023 pm 06:00 PM
Gabungan sempurna ChatGPT dan Python: mencipta chatbot perkhidmatan pelanggan yang pintar
Oct 27, 2023 pm 06:00 PM
Gabungan sempurna ChatGPT dan Python: Mencipta Perkhidmatan Pelanggan Pintar Chatbot Pengenalan: Dalam era maklumat hari ini, sistem perkhidmatan pelanggan pintar telah menjadi alat komunikasi yang penting antara perusahaan dan pelanggan. Untuk memberikan pengalaman perkhidmatan pelanggan yang lebih baik, banyak syarikat telah mula beralih kepada chatbots untuk menyelesaikan tugas seperti perundingan pelanggan dan menjawab soalan. Dalam artikel ini, kami akan memperkenalkan cara menggunakan bahasa ChatGPT dan Python model OpenAI yang berkuasa untuk mencipta bot sembang perkhidmatan pelanggan yang pintar untuk meningkatkan
 Bagaimana untuk memasang chatgpt pada telefon bimbit
Mar 05, 2024 pm 02:31 PM
Bagaimana untuk memasang chatgpt pada telefon bimbit
Mar 05, 2024 pm 02:31 PM
Langkah pemasangan: 1. Muat turun perisian ChatGTP dari laman web rasmi ChatGTP atau kedai mudah alih 2. Selepas membukanya, dalam antara muka tetapan, pilih bahasa sebagai bahasa Cina 3. Dalam antara muka permainan, pilih permainan mesin manusia dan tetapkan Spektrum bahasa Cina; 4 Selepas memulakan, masukkan arahan dalam tetingkap sembang untuk berinteraksi dengan perisian.
 Model paling berkuasa di dunia bertukar tangan semalaman, menandakan berakhirnya era GPT-4! Claude 3 mengetik GPT-5 terlebih dahulu, dan membaca kertas 10,000 perkataan dalam masa 3 saat.
Mar 06, 2024 pm 12:58 PM
Model paling berkuasa di dunia bertukar tangan semalaman, menandakan berakhirnya era GPT-4! Claude 3 mengetik GPT-5 terlebih dahulu, dan membaca kertas 10,000 perkataan dalam masa 3 saat.
Mar 06, 2024 pm 12:58 PM
Kelantangan gila, kelantangannya gila, dan model besar telah berubah lagi. Baru-baru ini, model AI paling berkuasa di dunia bertukar tangan dalam sekelip mata, dan GPT-4 ditarik dari altar. Anthropic mengeluarkan siri model Claude3 terbaharu Satu penilaian ayat: Ia benar-benar menghancurkan GPT-4! Dari segi penunjuk kebolehan berbilang modal dan bahasa, Claude3 menang. Dalam kata-kata Anthropic, model siri Claude3 telah menetapkan penanda aras industri baharu dalam penaakulan, matematik, pengekodan, pemahaman dan penglihatan berbilang bahasa! Anthropic ialah syarikat permulaan yang ditubuhkan oleh pekerja yang "membelot" daripada OpenAI kerana konsep keselamatan yang berbeza Produk mereka telah berulang kali memukul OpenAI. Kali ini, Claude3 juga menjalani pembedahan besar.
 Jailbreak mana-mana model besar dalam 20 langkah! Lebih banyak 'celah nenek' ditemui secara automatik
Nov 05, 2023 pm 08:13 PM
Jailbreak mana-mana model besar dalam 20 langkah! Lebih banyak 'celah nenek' ditemui secara automatik
Nov 05, 2023 pm 08:13 PM
Dalam masa kurang daripada satu minit dan tidak lebih daripada 20 langkah, anda boleh memintas sekatan keselamatan dan berjaya menjailbreak model besar! Dan tidak perlu mengetahui butiran dalaman model - hanya dua model kotak hitam perlu berinteraksi, dan AI boleh mengalahkan AI secara automatik dan bercakap kandungan berbahaya. Saya mendengar bahawa "Grandma Loophole" yang pernah popular telah diperbaiki: Sekarang, menghadapi "Detektif Loophole", "Adventurer Loophole" dan "Writer Loophole", apakah strategi tindak balas yang harus diguna pakai kecerdasan buatan? Selepas gelombang serangan, GPT-4 tidak tahan lagi, dan secara langsung mengatakan bahawa ia akan meracuni sistem bekalan air selagi... ini atau itu. Kuncinya ialah ini hanyalah gelombang kecil kelemahan yang didedahkan oleh pasukan penyelidik University of Pennsylvania, dan menggunakan algoritma mereka yang baru dibangunkan, AI boleh menjana pelbagai gesaan serangan secara automatik. Penyelidik mengatakan kaedah ini lebih baik daripada yang sedia ada
