
 Peranti teknologi
AI
bunyi bising! Adakah ChatGPT memahami bahasa tersebut? PNAS: Mari kita kaji dahulu apa itu 'pemahaman'.
Peranti teknologi
AI
bunyi bising! Adakah ChatGPT memahami bahasa tersebut? PNAS: Mari kita kaji dahulu apa itu 'pemahaman'.
bunyi bising! Adakah ChatGPT memahami bahasa tersebut? PNAS: Mari kita kaji dahulu apa itu 'pemahaman'.

Sama ada mesin boleh memikirkan soalan ini adalah seperti bertanya sama ada kapal selam boleh berenang. ——Dijkstra
Lama sebelum pelancaran ChatGPT, industri telah pun merasakan perubahan yang dibawa oleh model besar.
Pada 14 Oktober tahun lepas, profesor Melanie Mitchell dan David C. Krakauer dari Institut Santa Fe menerbitkan ulasan mengenai arXiv, menyiasat secara menyeluruh semua Perdebatan mengenai sama ada pra skala besar -model bahasa yang terlatih boleh memahami bahasa, artikel itu menerangkan hujah-hujah menyokong dan menentang, serta isu-isu utama dalam sains kecerdasan yang lebih luas yang diperoleh daripada hujah-hujah ini.

Pautan kertas: https://arxiv.org/pdf/2210.13966.pdf
Jurnal penerbitan: "Academy of the Akhbar" Akademi Sains Kebangsaan" (PNAS)
Terlalu panjang untuk dibaca versi:
Hujah utama yang memihak kepada "pemahaman" ialah bahawa model bahasa yang besar boleh menyelesaikan banyak tugas yang kelihatan memerlukan pemahaman sebelum ia dapat diselesaikan.
Hujah utama menentang "pemahaman" ialah dari perspektif manusia, pemahaman model bahasa yang besar adalah sangat rapuh, seperti tidak dapat memahami perubahan halus antara gesaan dan model bahasa tidak mempunyai dunia sebenar pengalaman hidup Untuk mengesahkan pengetahuan mereka, model bahasa multimodal boleh mengurangkan masalah ini.
Masalah yang paling kritikal ialah tiada siapa yang mempunyai definisi yang boleh dipercayai tentang "apa itu pemahaman" lagi, dan mereka tidak tahu bagaimana untuk menguji keupayaan pemahaman model bahasa untuk manusia. ujian tidak semestinya sesuai untuk menguji pemahaman model bahasa yang besar.
Ringkasnya, model bahasa yang besar boleh memahami bahasa, tetapi mungkin dengan cara yang berbeza daripada manusia.
Penyelidik percaya bahawa sains kecerdasan baharu boleh dibangunkan untuk mengkaji secara mendalam pelbagai jenis pemahaman, mengetahui kelebihan dan batasan mod pemahaman yang berbeza, dan pada masa yang sama mengintegrasikan hasilnya dihasilkan oleh bentuk pemahaman yang berbeza.

Melanie Mitchell, pengarang pertama kertas kerja, ialah seorang profesor di Institut Santa Fe She menerima Ph.D. pada tahun 1990 Lulus dari University of Michigan, mentornya ialah Hofstadter (pengarang "Gödel, Escher, Bach: A Collection of Different Masters") dan John Holland Arah penyelidikan utamanya ialah penaakulan analogi, sistem yang kompleks , algoritma genetik dan sel.
Apakah sebenarnya "pemahaman" itu?
"Apa itu pemahaman" sentiasa membingungkan ahli falsafah, saintis kognitif dan pendidik. Pengkaji sering menggunakan manusia atau haiwan lain sebagai rujukan untuk "kebolehan memahami".
Sehingga baru-baru ini, dengan kebangkitan sistem kecerdasan buatan berskala besar, terutamanya kemunculan model bahasa besar (LLM), perdebatan sengit telah dicetuskan dalam komuniti kecerdasan buatan, iaitu sekarang Bolehkah dikatakan bahawa mesin telah dapat memahami bahasa semula jadi dan seterusnya memahami situasi fizikal dan sosial yang digambarkan oleh bahasa.
Ini bukan perdebatan akademik semata-mata Tahap dan cara mesin memahami dunia akan memberi kesan kepada sejauh mana manusia boleh mempercayai AI untuk melaksanakan tugas seperti memandu kereta, mendiagnosis penyakit, menjaga. orang tua, dan mendidik kanak-kanak, supaya dalam diri manusia Mengambil tindakan yang kuat dan telus terhadap tugas yang berkaitan.
Perdebatan semasa menunjukkan bahawa terdapat beberapa perselisihan pendapat dalam cara komuniti akademik berfikir tentang pemahaman dalam sistem pintar, terutamanya dalam model mental yang bergantung pada "korelasi statistik" dan "mekanisme penyebab" ( model mental), perbezaannya lebih jelas.
Walau bagaimanapun, masih terdapat konsensus umum dalam komuniti penyelidikan kecerdasan buatan tentang pemahaman mesin, iaitu, walaupun sistem kecerdasan buatan mempamerkan tingkah laku yang kelihatan pintar dalam banyak tugas tertentu, mereka tidak Memahami data yang mereka proses seperti yang dilakukan oleh manusia.
Sebagai contoh, perisian pengecaman muka tidak memahami bahawa muka adalah sebahagian daripada badan, ia juga tidak memahami peranan ekspresi muka dalam interaksi sosial, dan ia juga tidak memahami cara manusia bertindak. dalam cara yang hampir tidak terhingga Untuk menggunakan konsep muka.
Begitu juga, program pertuturan ke teks dan penterjemahan mesin tidak memahami bahasa yang mereka proses, dan sistem pandu sendiri tidak memahami sentuhan mata atau bahasa badan yang halus yang digunakan oleh pemandu dan pejalan kaki untuk mengelakkan kemalangan.
Malah, kerapuhan sistem AI ini yang sering disebut, iaitu ralat yang tidak dapat diramalkan dan kekurangan generalisasi yang mantap, adalah penunjuk utama pemahaman AI.
Dalam beberapa tahun kebelakangan ini, penonton dan pengaruh model bahasa besar (LLM) dalam bidang kecerdasan buatan telah melonjak, yang juga telah mengubah pandangan sesetengah orang tentang prospek mesin pemahaman bahasa.
Model pra-latihan berskala besar, juga dipanggil Model Asas, ialah rangkaian saraf dalam dengan berbilion hingga trilion parameter (berat). selepas melakukan "pra-latihan" pada.
Tugas model semasa latihan adalah untuk meramal bahagian ayat input yang hilang, jadi kaedah ini juga dipanggil "pembelajaran penyeliaan kendiri", dan rangkaian yang terhasil adalah kompleks model statistik , anda boleh mendapatkan bagaimana perkataan dan frasa dalam data latihan berkaitan antara satu sama lain.
Model ini boleh digunakan untuk menjana bahasa semula jadi dan diperhalusi untuk tugasan bahasa semula jadi tertentu, atau dilatih lebih lanjut untuk memadankan "niat pengguna" dengan lebih baik, tetapi untuk bukan profesional Bagaimana sebenarnya bahasa model menyelesaikan tugas-tugas ini masih menjadi misteri kepada saintis.
Kerja dalaman rangkaian saraf sebahagian besarnya legap, malah penyelidik yang membina rangkaian ini mempunyai gerak hati yang terhad untuk sistem skala ini.

Saintis Neurosains Terrence Sejnowski menerangkan keupayaan kemunculan LLM seperti ini:
Selepas ambang tertentu melepasi, ia seperti makhluk asing tiba-tiba muncul dan boleh berkomunikasi dengan kita dengan cara manusia yang menakutkan. Hanya satu perkara yang jelas pada masa ini, model bahasa besar bukan manusia, beberapa aspek tingkah laku mereka kelihatan pintar, tetapi jika bukan kecerdasan manusia, apakah sifat kecerdasan mereka?
Sokong Golongan Pemahaman VS Lawan Golongan Pemahaman
Walaupun prestasi model bahasa besar mengejutkan, keadaan terkini -LLM seni masih terdedah kepada kerapuhan dan kesilapan bukan manusia.
Walau bagaimanapun, dapat diperhatikan bahawa prestasi rangkaian telah meningkat dengan ketara dengan pengembangan bilangan parameter dan saiz korpus latihan, yang juga telah mengetuai beberapa penyelidik dalam bidang ini untuk mendakwa bahawa selagi terdapat set data rangkaian dan latihan yang cukup besar, model bahasa (versi berbilang modal) dan mungkin versi berbilang modal - akan membawa kepada kecerdasan dan pemahaman peringkat manusia.
Slogan kecerdasan buatan baharu telah muncul: Skala adalah semua yang anda perlukan!
Pernyataan ini juga mencerminkan perdebatan tentang model bahasa berskala besar dalam komuniti penyelidikan kecerdasan buatan:
Satu kumpulan percaya bahawa model bahasa boleh benar-benar memahami bahasa, dan boleh menaakul secara umum (walaupun belum sampai ke peringkat manusia).
Sebagai contoh, sistem LaMDA Google telah dilatih terlebih dahulu pada teks dan kemudian diperhalusi pada tugas perbualan, membolehkannya mengadakan perbualan dengan pengguna dalam julat domain yang sangat luas.

Sekolah lain percaya bahawa model pra-latihan besar seperti GPT-3 atau LaMDA, tanpa mengira mereka Tidak kira seberapa fasih output bahasa, ia tidak dapat memiliki pemahaman kerana model ini tidak mempunyai pengalaman praktikal dan tidak mempunyai model mental dunia.
Model bahasa hanya dilatih untuk meramal perkataan dalam koleksi teks yang besar, membolehkan mereka mempelajari bentuk bahasa, jauh daripada mempelajari makna di sebalik bahasa.
Sistem yang dilatih semata-mata pada bahasa tidak akan pernah mendekati kecerdasan manusia, walaupun ia dilatih dari sekarang sehingga kematian alam semesta. Sudah jelas bahawa sistem ini ditakdirkan untuk hanya tahap pemahaman yang cetek dan tidak akan pernah mendekati pemikiran seluruh badan yang kita lihat pada manusia.
Seorang sarjana lain percaya bahawa apabila bercakap tentang sistem ini, pemahaman tentang kecerdasan, agen, dan lanjutan adalah salah, dan model bahasa sebenarnya adalah perpustakaan pengetahuan manusia yang dimampatkan, Lebih serupa dengan perpustakaan atau ensiklopedia daripada ejen.
Sebagai contoh, manusia tahu apa yang dimaksudkan dengan "gatal" untuk membuat kita ketawa, kerana kita mempunyai badan; model bahasa boleh menggunakan perkataan "gatal", tetapi jelas tidak mengalami perasaan ini, Memahami "gatal" memetakan satu perkataan kepada perasaan, bukan kepada perkataan lain.
Mereka di pihak "LLM tidak faham" berpendapat bahawa walaupun kefasihan model bahasa besar mengejutkan, kejutan kami mencerminkan kekurangan keyakinan kami terhadap korelasi statistik dalam model ini. adalah kekurangan intuisi tentang apa yang boleh dihasilkan pada skala.
Tinjauan 2022 terhadap penyelidik aktif dalam komuniti pemprosesan bahasa semula jadi menunjukkan pembahagian yang jelas dalam perbahasan ini.
Apabila 480 responden ditanya sama ada mereka bersetuju dengan kenyataan bahawa LLM pada dasarnya boleh memahami bahasa, iaitu, "model bahasa generatif yang dilatih hanya pada teks, asalkan cukup Dengan data dan sumber pengkomputeran, bahasa semula jadi boleh difahami dalam erti kata tertentu."
Hasil tinjauan dibahagikan sama rata, dengan separuh (51%) bersetuju dan separuh lagi (49%) tidak bersetuju .
Mesin memahami secara berbeza daripada manusia
Walaupun kedua-dua belah perbahasan "pemahaman LLM" mempunyai intuisi yang baik untuk menyokong pandangan masing-masing, pada masa ini terdapat alatan berasaskan sains kognitif yang tersedia untuk mendapatkan pemahaman yang lebih mendalam tentang pemahaman. kaedah tidak mencukupi untuk menjawab soalan tersebut tentang LLM.
Malah, sesetengah penyelidik telah menggunakan ujian psikologi (asalnya direka bentuk untuk menilai pemahaman manusia dan mekanisme penaakulan) kepada LLM dan mendapati bahawa dalam beberapa kes, LLM melakukan dalam teori pemikiran Menunjukkan manusia- seperti tindak balas dalam ujian dan kebolehan seperti manusia dan berat sebelah dalam penilaian penaakulan.
Walaupun ujian ini dianggap sebagai agen yang boleh dipercayai untuk menilai kebolehan generalisasi manusia, ini mungkin tidak berlaku untuk sistem kecerdasan buatan.
Model bahasa yang besar mempunyai keupayaan khas untuk mempelajari korelasi antara data latihan dan token dalam input, dan boleh menggunakan korelasi ini untuk menyelesaikan masalah, sebaliknya, manusia Gunakan konsep pekat yang mencerminkan pengalaman dunia sebenar mereka.
Apabila menggunakan ujian yang direka untuk manusia pada LLM, tafsiran keputusan mungkin bergantung pada andaian tentang kognisi manusia yang mungkin tidak benar untuk model ini.
Untuk membuat kemajuan, saintis perlu membangunkan penanda aras dan kaedah pengesanan baharu untuk memahami mekanisme pelbagai jenis kecerdasan dan pemahaman, termasuk bentuk baharu kecerdasan "pelik" yang kami cipta. , entiti seperti minda", dan beberapa kerja berkaitan telah pun dilakukan.
Apabila model menjadi lebih besar dan sistem yang lebih berkebolehan dibangunkan, perdebatan mengenai pemahaman dalam LLM menyerlahkan keperluan untuk "mengembangkan sains kecerdasan kita" , supaya "pemahaman" bermakna, sama ada untuk manusia atau mesin.
Ahli Neurosains Terrence Sejnowski menegaskan bahawa pendapat berbeza pakar tentang kecerdasan LLM menunjukkan bahawa idea lama kita berdasarkan kecerdasan semula jadi tidak mencukupi.
Jika LLM dan model yang berkaitan boleh berjaya dengan mengeksploitasi korelasi statistik pada skala yang belum pernah berlaku sebelum ini, mungkin ia boleh dianggap sebagai "bentuk pemahaman baharu", yang boleh mencapai bentuk ramalan manusia luar biasa yang luar biasa. keupayaan, seperti sistem AlphaZero dan AlphaFold DeepMind, yang masing-masing membawa bentuk gerak hati "eksotik" kepada bidang permainan catur dan ramalan struktur protein.
Jadi boleh dikatakan dalam beberapa tahun kebelakangan ini, bidang kecerdasan buatan telah mencipta mesin dengan mod pemahaman baharu, kemungkinan besar konsep baharu sepenuhnya, sambil kami mengejar kepintaran yang sukar difahami. Apabila kemajuan dicapai dalam aspek penting, konsep baharu ini akan terus diperkaya.
Masalah yang memerlukan pengetahuan pengekodan yang luas dan mempunyai keperluan prestasi tinggi akan terus menggalakkan pembangunan model statistik berskala besar, manakala mereka yang mempunyai pengetahuan terhad dan mekanisme penyebab yang kuat akan mempunyai Kondusif untuk memahami kecerdasan manusia.
Cabaran untuk masa depan adalah untuk membangunkan kaedah saintifik baharu untuk mendedahkan pemahaman terperinci tentang pelbagai bentuk kecerdasan, membezakan kekuatan dan batasan mereka, dan belajar cara mengintegrasikan model kognisi yang benar-benar berbeza ini .
Rujukan:
https://www.pnas.org/doi/10.1073/pnas.2215907120
Atas ialah kandungan terperinci bunyi bising! Adakah ChatGPT memahami bahasa tersebut? PNAS: Mari kita kaji dahulu apa itu 'pemahaman'.. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1378
1378
 52
52

 ChatGPT kini membenarkan pengguna percuma menjana imej dengan menggunakan DALL-E 3 dengan had harian
Aug 09, 2024 pm 09:37 PM
ChatGPT kini membenarkan pengguna percuma menjana imej dengan menggunakan DALL-E 3 dengan had harian
Aug 09, 2024 pm 09:37 PM
DALL-E 3 telah diperkenalkan secara rasmi pada September 2023 sebagai model yang jauh lebih baik daripada pendahulunya. Ia dianggap sebagai salah satu penjana imej AI terbaik setakat ini, mampu mencipta imej dengan perincian yang rumit. Walau bagaimanapun, semasa pelancaran, ia adalah tidak termasuk
 3 Cara Menukar Bahasa pada iPhone
Feb 02, 2024 pm 04:12 PM
3 Cara Menukar Bahasa pada iPhone
Feb 02, 2024 pm 04:12 PM
Bukan rahsia lagi bahawa iPhone adalah salah satu alat elektronik yang paling mesra pengguna, dan salah satu sebabnya ialah ia boleh diperibadikan dengan mudah mengikut keinginan anda. Dalam Pemperibadian, anda boleh menukar bahasa kepada bahasa yang berbeza daripada bahasa yang anda pilih semasa menyediakan iPhone anda. Jika anda biasa dengan berbilang bahasa, atau tetapan bahasa iPhone anda salah, anda boleh menukarnya seperti yang kami terangkan di bawah. Cara Menukar Bahasa iPhone [3 Kaedah] iOS membenarkan pengguna menukar bahasa pilihan pada iPhone secara bebas untuk menyesuaikan diri dengan keperluan yang berbeza. Anda boleh menukar bahasa interaksi dengan Siri untuk memudahkan komunikasi dengan pembantu suara. Pada masa yang sama, apabila menggunakan papan kekunci tempatan, anda boleh bertukar antara berbilang bahasa dengan mudah untuk meningkatkan kecekapan input.
 Bagaimana untuk memasang chatgpt pada telefon bimbit
Mar 05, 2024 pm 02:31 PM
Bagaimana untuk memasang chatgpt pada telefon bimbit
Mar 05, 2024 pm 02:31 PM
Langkah pemasangan: 1. Muat turun perisian ChatGTP dari laman web rasmi ChatGTP atau kedai mudah alih 2. Selepas membukanya, dalam antara muka tetapan, pilih bahasa sebagai bahasa Cina 3. Dalam antara muka permainan, pilih permainan mesin manusia dan tetapkan Spektrum bahasa Cina; 4 Selepas memulakan, masukkan arahan dalam tetingkap sembang untuk berinteraksi dengan perisian.
 Bagaimana untuk menetapkan bahasa komputer Win10 kepada bahasa Cina?
Jan 05, 2024 pm 06:51 PM
Bagaimana untuk menetapkan bahasa komputer Win10 kepada bahasa Cina?
Jan 05, 2024 pm 06:51 PM
Kadang-kadang kita hanya memasang sistem komputer dan mendapati bahawa sistem itu dalam bahasa Inggeris Dalam kes ini, kita perlu menukar bahasa komputer kepada bahasa Cina Jadi bagaimana untuk menukar bahasa komputer ke bahasa Cina dalam sistem win10 . Cara menukar bahasa komputer dalam win10 kepada bahasa Cina 1. Hidupkan komputer dan klik butang mula di sudut kiri bawah. 2. Klik pilihan tetapan di sebelah kiri. 3. Pilih "Masa dan Bahasa" pada halaman yang terbuka 4. Selepas membuka, klik "Bahasa" di sebelah kiri 5. Di sini anda boleh menetapkan bahasa komputer yang anda mahu.
 Bagaimana untuk membangunkan chatbot pintar menggunakan ChatGPT dan Java
Oct 28, 2023 am 08:54 AM
Bagaimana untuk membangunkan chatbot pintar menggunakan ChatGPT dan Java
Oct 28, 2023 am 08:54 AM
Dalam artikel ini, kami akan memperkenalkan cara membangunkan chatbot pintar menggunakan ChatGPT dan Java, dan menyediakan beberapa contoh kod khusus. ChatGPT ialah versi terkini Generative Pre-training Transformer yang dibangunkan oleh OpenAI, teknologi kecerdasan buatan berasaskan rangkaian saraf yang boleh memahami bahasa semula jadi dan menjana teks seperti manusia. Menggunakan ChatGPT kami boleh membuat sembang adaptif dengan mudah
 Bolehkah chatgpt digunakan di China?
Mar 05, 2024 pm 03:05 PM
Bolehkah chatgpt digunakan di China?
Mar 05, 2024 pm 03:05 PM
chatgpt boleh digunakan di China, tetapi tidak boleh didaftarkan, begitu juga di Hong Kong dan Macao Jika pengguna ingin mendaftar, mereka boleh menggunakan nombor telefon mudah alih asing untuk mendaftar. Perhatikan bahawa semasa proses pendaftaran, persekitaran rangkaian mesti ditukar IP asing.
 Bagaimana untuk membina robot perkhidmatan pelanggan pintar menggunakan PHP ChatGPT
Oct 28, 2023 am 09:34 AM
Bagaimana untuk membina robot perkhidmatan pelanggan pintar menggunakan PHP ChatGPT
Oct 28, 2023 am 09:34 AM
Cara menggunakan ChatGPTPHP untuk membina robot perkhidmatan pelanggan yang pintar Pengenalan: Dengan perkembangan teknologi kecerdasan buatan, robot semakin digunakan dalam bidang perkhidmatan pelanggan. Menggunakan ChatGPTPHP untuk membina robot perkhidmatan pelanggan yang pintar boleh membantu syarikat menyediakan perkhidmatan pelanggan yang lebih cekap dan diperibadikan. Artikel ini akan memperkenalkan cara menggunakan ChatGPTPHP untuk membina robot perkhidmatan pelanggan yang pintar dan menyediakan contoh kod khusus. 1. Pasang ChatGPTPHP dan gunakan ChatGPTPHP untuk membina robot perkhidmatan pelanggan yang pintar.
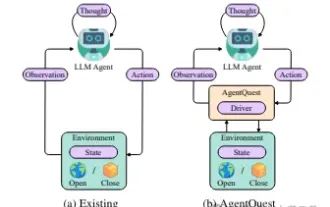 Meneroka sempadan ejen: AgentQuest, rangka kerja penanda aras modular untuk mengukur dan meningkatkan prestasi ejen model bahasa besar secara menyeluruh
Apr 11, 2024 pm 08:52 PM
Meneroka sempadan ejen: AgentQuest, rangka kerja penanda aras modular untuk mengukur dan meningkatkan prestasi ejen model bahasa besar secara menyeluruh
Apr 11, 2024 pm 08:52 PM
Berdasarkan pengoptimuman berterusan model besar, ejen LLM - entiti algoritma yang berkuasa ini telah menunjukkan potensi untuk menyelesaikan tugas penaakulan pelbagai langkah yang kompleks. Daripada pemprosesan bahasa semula jadi kepada pembelajaran mendalam, ejen LLM secara beransur-ansur menjadi tumpuan penyelidikan dan industri Mereka bukan sahaja dapat memahami dan menjana bahasa manusia, tetapi juga merumuskan strategi, melaksanakan tugas dalam persekitaran yang pelbagai, dan juga menggunakan panggilan API dan pengekodan untuk Membina. penyelesaian. Dalam konteks ini, pengenalan rangka kerja AgentQuest merupakan satu peristiwa penting Ia bukan sahaja menyediakan platform penanda aras modular untuk penilaian dan kemajuan ejen LLM, tetapi juga menyediakan penyelidik dengan alat yang Berkuasa untuk menjejak dan meningkatkan prestasi ejen ini pada masa yang tertentu. tahap yang lebih berbutir
