
 Peranti teknologi
AI
Jika anda ingin mempelajari kecerdasan buatan, anda mesti menguasai set data ini Pengenalan dan penggunaan praktikal MNIST
Peranti teknologi
AI
Jika anda ingin mempelajari kecerdasan buatan, anda mesti menguasai set data ini Pengenalan dan penggunaan praktikal MNIST
Jika anda ingin mempelajari kecerdasan buatan, anda mesti menguasai set data ini Pengenalan dan penggunaan praktikal MNIST

Mempelajari kecerdasan buatan sudah semestinya memerlukan beberapa set data Contohnya, kecerdasan buatan untuk mengenal pasti pornografi memerlukan beberapa gambar yang serupa. Kecerdasan buatan untuk pengecaman pertuturan dan korpus amat diperlukan. Pelajar yang baru mengenali kecerdasan buatan sering bimbang tentang set data. Hari ini kami akan memperkenalkan set data yang sangat mudah, tetapi sangat berguna, iaitu MNIST. Set data ini sangat sesuai untuk kita belajar dan mengamalkan algoritma berkaitan kecerdasan buatan.
Dataset MNIST ialah set data yang sangat mudah yang dihasilkan oleh Institut Piawaian dan Teknologi Kebangsaan (NIST). Jadi apakah set data ini? Ia sebenarnya beberapa angka Arab tulisan tangan (sepuluh nombor dari 0 hingga 9).
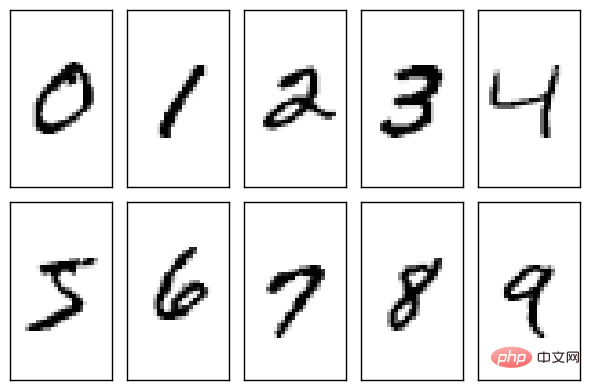
NIST masih sangat serius semasa menghasilkan set data. Set latihan dalam set data terdiri daripada digit tulisan tangan daripada 250 orang yang berbeza, 50% daripadanya adalah pelajar sekolah menengah dan 50% daripadanya adalah kakitangan dari Biro Banci. Set ujian juga adalah perkadaran yang sama bagi data digit tulisan tangan.
Cara memuat turun set data MNIST
Set data MNIST boleh dimuat turun dari laman web rasminya (http://yann.lecun.com/exdb/mnist/). laman web asing, muat turun mungkin sukar perlahan. Ia mengandungi empat bahagian:
- Imej set latihan: train-images-idx3-ubyte.gz (9.9 MB, 47 MB selepas penyahmampatan, mengandungi 60,000 sampel)
- Set Latihan label: train-labels-idx1-ubyte.gz (29 KB, 60 KB dinyahzip, mengandungi 60,000 label)
- Imej set ujian: t10k-images-idx3-ubyte.gz (1.6 MB, dibuka 7.8 MB selepas penyahmampatan, mengandungi 10,000 sampel)
- Label set ujian: t10k-labels-idx1-ubyte.gz (5KB, 10 KB selepas penyahmampatan, mengandungi 10,000 label)
Di atas mengandungi dua jenis kandungan, satu adalah gambar dan satu lagi adalah label Gambar dan label sesuai satu dengan satu. Tetapi gambar di sini bukanlah fail gambar yang biasa kita lihat, tetapi fail binari. Set data ini menyimpan 60,000 imej dalam format binari. Label adalah nombor sebenar yang sepadan dengan gambar.
Seperti yang ditunjukkan dalam rajah di bawah, artikel ini memuat turun set data secara setempat dan menyahmampat hasilnya. Untuk memudahkan perbandingan, pakej mampat asal dan fail nyahmampat disertakan.
Analisis ringkas tentang format set data
Semua orang telah mendapati bahawa selepas penyahmampatan, pakej yang dimampatkan bukanlah gambar, tetapi setiap pakej yang dimampatkan sepadan dengan soalan bebas. Dalam fail ini, maklumat tentang puluhan ribu gambar atau tag disimpan. Jadi bagaimana maklumat ini disimpan dalam fail ini?
Malah, laman web rasmi MNIST memberikan penerangan terperinci. Mengambil contoh fail imej set latihan, penerangan format fail yang diberikan oleh laman web rasmi adalah seperti berikut:
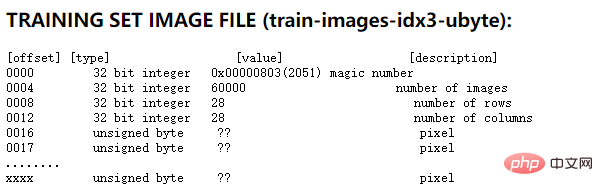
Seperti yang dapat dilihat dari gambar di atas, 4 nombor 32 digit pertama ialah maklumat penerangan set latihan. Yang pertama ialah nombor ajaib, iaitu nilai tetap 0x0803; yang kedua ialah bilangan gambar, 0xea60, iaitu 60000; . Berikut menerangkan setiap piksel dalam satu bait. Memandangkan satu bait digunakan untuk menerangkan piksel dalam fail ini, anda boleh mengetahui bahawa nilai piksel boleh dari 0 hingga 255. Di mana 0 bermaksud putih dan 255 bermaksud hitam.

Format fail tag adalah serupa dengan fail imej. Terdapat dua nombor 32 digit di hadapan, yang pertama ialah nombor ajaib, nilai tetap 0x0801; yang kedua digunakan untuk menerangkan bilangan tag. Data seterusnya ialah nilai setiap teg, diwakili oleh satu bait. Julat nilai yang diwakili di sini ialah

Data fail label yang sepadan dengan set latihan sebenar adalah seperti berikut. Ia dapat dilihat bahawa ia konsisten dengan penerangan format di atas. Di samping itu, kita dapat melihat bahawa sepadan dengan set label ini, nombor yang diwakili oleh gambar sebelumnya hendaklah masing-masing 5, 0, 4, 1, dsb. Ingat di sini, ia akan digunakan kemudian.

Kami tahu tentang format fail set data, mari lakukannya secara praktikal.
Pemprosesan visual set data
Setelah mengetahui format storan data di atas, kami boleh menghuraikan data. Sebagai contoh, artikel berikut melaksanakan program kecil untuk menghuraikan gambar dalam koleksi gambar dan mendapatkan hasil visual. Sudah tentu, kita sebenarnya boleh tahu apa gambar itu berdasarkan nilai set label Ini hanyalah percubaan. Hasil akhir disimpan dalam fail teks, menggunakan aksara "Y" untuk mewakili tulisan tangan dan aksara "0" untuk mewakili warna latar belakang. Kod program khusus adalah sangat mudah dan tidak akan diterangkan secara terperinci dalam artikel ini.
# -*- coding: UTF-8 -*-
def trans_to_txt(train_file, txt_file, index):
with open(train_file, 'rb') as sf:
with open(txt_file, "w") as wf:
offset = 16 + (28*28*index)
cur_pos = offset
count = 28*28
strlen = 1
out_count = 1
while cur_pos < offset+count:
sf.seek(cur_pos)
data = sf.read(strlen)
res = int(data[0])
#虽然在数据集中像素是1-255表示颜色,这里简化为Y
if res > 0 :
wf.write(" Y ")
else:
wf.write(" 0 ")
#由于图片是28列,因此在此进行换行
if out_count % 28 == 0 :
wf.write("n")
cur_pos += strlen
out_count += 1
trans_to_txt("../data/train-images.idx3-ubyte", "image.txt", 0)Apabila kita menjalankan kod di atas, kita boleh mendapatkan fail bernama image.txt. Anda boleh melihat kandungan fail seperti berikut. Nota merah telah ditambahkan kemudian, terutamanya untuk keterlihatan yang lebih baik. Seperti yang dapat dilihat dari kandungan dalam gambar, ini sebenarnya adalah "5" tulisan tangan.

Terdahulu kami menganalisis set data secara visual melalui antara muka Python asli. Python mempunyai banyak fungsi perpustakaan yang telah dilaksanakan, jadi kita boleh memudahkan fungsi di atas melalui fungsi perpustakaan.
Menghuraikan data berdasarkan perpustakaan pihak ketiga
Ia agak rumit untuk dilaksanakan menggunakan antara muka Python asli. Kami tahu bahawa Python mempunyai banyak perpustakaan pihak ketiga, jadi kami boleh menggunakan perpustakaan pihak ketiga untuk menghuraikan dan memaparkan set data Kod khusus adalah seperti berikut.
# -*- coding: utf-8 -*-
import os
import struct
import numpy as np
# 读取数据集,以二维数组的方式返回图片信息和标签信息
def load_mnist(path, kind='train'):
# 从指定目录加载数据集
labels_path = os.path.join(path,
'%s-labels.idx1-ubyte'
% kind)
images_path = os.path.join(path,
'%s-images.idx3-ubyte'
% kind)
with open(labels_path, 'rb') as lbpath:
magic, n = struct.unpack('>II',
lbpath.read(8))
labels = np.fromfile(lbpath,
dtype=np.uint8)
with open(images_path, 'rb') as imgpath:
#解析图片信息,存储在images中
magic, num, rows, cols = struct.unpack('>IIII',
imgpath.read(16))
images = np.fromfile(imgpath,
dtype=np.uint8).reshape(len(labels), 784)
return images, labels
# 在终端打印某个图片的数据信息
def print_image(data, index):
idx = 0;
count = 0;
for item in data[index]:
if count % 28 == 0:
print("")
if item > 0:
print("33[7;31mY 33[0m", end="")
else:
print("0 ", end="")
count += 1
def main():
cur_path = os.getcwd()
cur_path = os.path.join(cur_path, "..data")
imgs, labels = load_mnist(cur_path)
print_image(imgs, 0)
if __name__ == "__main__":
main()Kod di atas dibahagikan kepada dua langkah Langkah pertama ialah menghuraikan set data ke dalam tatasusunan, dan langkah kedua ialah memaparkan gambar tertentu dalam tatasusunan. Paparan di sini juga melalui program teks, tetapi ia tidak disimpan dalam fail, tetapi dicetak pada terminal. Contohnya, jika kita masih mencetak gambar pertama, kesannya adalah seperti berikut:

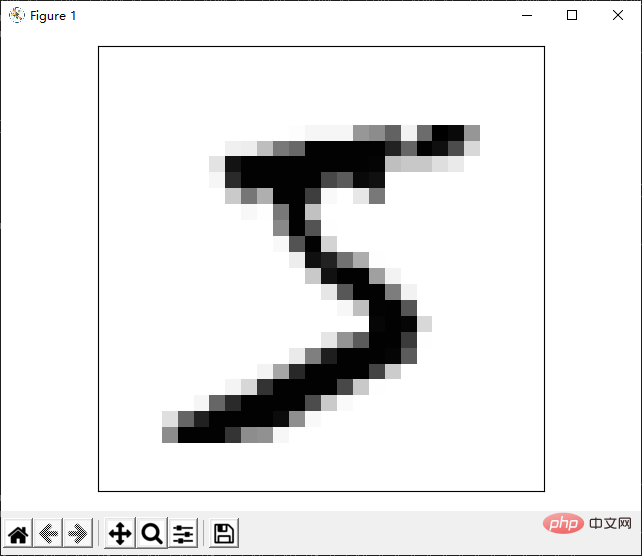
Pembentangan hasil di atas hanya mensimulasikan gambar melalui aksara. Malah, kita boleh menggunakan perpustakaan pihak ketiga untuk mencapai persembahan imej yang lebih sempurna. Seterusnya, kami memperkenalkan cara mempersembahkan gambar melalui perpustakaan matplotlib. Perpustakaan ini sangat berguna, dan saya akan berhubung dengan perpustakaan ini kemudian.
Kami melaksanakan
def show_image(data, index): fig, ax = plt.subplots(nrows=1, ncols=1, sharex=True, sharey=True, ) img = data[0].reshape(28, 28) ax.imshow(img, cmap='Greys', interpolation='nearest') ax.set_xticks([]) ax.set_yticks([]) plt.tight_layout() plt.show()
Pada masa ini anda dapat melihat bahawa
Sesetengah perpustakaan pihak ketiga mungkin hilang semasa melaksanakan fungsi di atas, seperti matplotlib, dsb. Pada masa ini, kita perlu memasangnya secara manual Kaedah khusus adalah seperti berikut:
pip install matplotlib -i http://pypi.douban.com/simple/ --trusted-host pypi.douban.com
Analisis data berdasarkan TensorFlow
MNIST sangat terkenal sehingga TensorFlow sudah menyokongnya. Oleh itu, kita boleh memuatkan dan menghuraikannya melalui TensorFlow. Di bawah ini kami memberikan kod yang dilaksanakan dengan TensorFlow.
# -*- coding: utf-8 -*-
from tensorflow.examples.tutorials.mnist import input_data
import pylab
def show_mnist():
# 通过TensorFlow库解析数据
mnist = input_data.read_data_sets("../data", one_hot=True)
im = mnist.train.images[0]
im = im.reshape(28 ,28)
# 进行绘图
pylab.imshow(im, cmap='Greys', interpolation='nearest')
pylab.show()
if __name__ == "__main__":
show_mnist()Kesan akhir yang dicapai oleh kod ini adalah sama seperti contoh sebelumnya, jadi saya tidak akan menerangkan butiran di sini.
Atas ialah kandungan terperinci Jika anda ingin mempelajari kecerdasan buatan, anda mesti menguasai set data ini Pengenalan dan penggunaan praktikal MNIST. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1377
1377
 52
52

 Bytedance Cutting melancarkan keahlian super SVIP: 499 yuan untuk langganan tahunan berterusan, menyediakan pelbagai fungsi AI
Jun 28, 2024 am 03:51 AM
Bytedance Cutting melancarkan keahlian super SVIP: 499 yuan untuk langganan tahunan berterusan, menyediakan pelbagai fungsi AI
Jun 28, 2024 am 03:51 AM
Laman web ini melaporkan pada 27 Jun bahawa Jianying ialah perisian penyuntingan video yang dibangunkan oleh FaceMeng Technology, anak syarikat ByteDance Ia bergantung pada platform Douyin dan pada asasnya menghasilkan kandungan video pendek untuk pengguna platform tersebut Windows , MacOS dan sistem pengendalian lain. Jianying secara rasmi mengumumkan peningkatan sistem keahliannya dan melancarkan SVIP baharu, yang merangkumi pelbagai teknologi hitam AI, seperti terjemahan pintar, penonjolan pintar, pembungkusan pintar, sintesis manusia digital, dsb. Dari segi harga, yuran bulanan untuk keratan SVIP ialah 79 yuan, yuran tahunan ialah 599 yuan (nota di laman web ini: bersamaan dengan 49.9 yuan sebulan), langganan bulanan berterusan ialah 59 yuan sebulan, dan langganan tahunan berterusan ialah 499 yuan setahun (bersamaan dengan 41.6 yuan sebulan) . Di samping itu, pegawai yang dipotong juga menyatakan bahawa untuk meningkatkan pengalaman pengguna, mereka yang telah melanggan VIP asal
 Pembantu pengekodan AI yang ditambah konteks menggunakan Rag dan Sem-Rag
Jun 10, 2024 am 11:08 AM
Pembantu pengekodan AI yang ditambah konteks menggunakan Rag dan Sem-Rag
Jun 10, 2024 am 11:08 AM
Tingkatkan produktiviti, kecekapan dan ketepatan pembangun dengan menggabungkan penjanaan dipertingkatkan semula dan memori semantik ke dalam pembantu pengekodan AI. Diterjemah daripada EnhancingAICodingAssistantswithContextUsingRAGandSEM-RAG, pengarang JanakiramMSV. Walaupun pembantu pengaturcaraan AI asas secara semulajadi membantu, mereka sering gagal memberikan cadangan kod yang paling relevan dan betul kerana mereka bergantung pada pemahaman umum bahasa perisian dan corak penulisan perisian yang paling biasa. Kod yang dijana oleh pembantu pengekodan ini sesuai untuk menyelesaikan masalah yang mereka bertanggungjawab untuk menyelesaikannya, tetapi selalunya tidak mematuhi piawaian pengekodan, konvensyen dan gaya pasukan individu. Ini selalunya menghasilkan cadangan yang perlu diubah suai atau diperhalusi agar kod itu diterima ke dalam aplikasi
 Bolehkah penalaan halus benar-benar membolehkan LLM mempelajari perkara baharu: memperkenalkan pengetahuan baharu boleh menjadikan model menghasilkan lebih banyak halusinasi
Jun 11, 2024 pm 03:57 PM
Bolehkah penalaan halus benar-benar membolehkan LLM mempelajari perkara baharu: memperkenalkan pengetahuan baharu boleh menjadikan model menghasilkan lebih banyak halusinasi
Jun 11, 2024 pm 03:57 PM
Model Bahasa Besar (LLM) dilatih pada pangkalan data teks yang besar, di mana mereka memperoleh sejumlah besar pengetahuan dunia sebenar. Pengetahuan ini dibenamkan ke dalam parameter mereka dan kemudiannya boleh digunakan apabila diperlukan. Pengetahuan tentang model ini "diperbaharui" pada akhir latihan. Pada akhir pra-latihan, model sebenarnya berhenti belajar. Selaraskan atau perhalusi model untuk mempelajari cara memanfaatkan pengetahuan ini dan bertindak balas dengan lebih semula jadi kepada soalan pengguna. Tetapi kadangkala pengetahuan model tidak mencukupi, dan walaupun model boleh mengakses kandungan luaran melalui RAG, ia dianggap berfaedah untuk menyesuaikan model kepada domain baharu melalui penalaan halus. Penalaan halus ini dilakukan menggunakan input daripada anotasi manusia atau ciptaan LLM lain, di mana model menemui pengetahuan dunia sebenar tambahan dan menyepadukannya
 Tujuh Soalan Temuduga Teknikal GenAI & LLM yang Cool
Jun 07, 2024 am 10:06 AM
Tujuh Soalan Temuduga Teknikal GenAI & LLM yang Cool
Jun 07, 2024 am 10:06 AM
Untuk mengetahui lebih lanjut tentang AIGC, sila layari: 51CTOAI.x Komuniti https://www.51cto.com/aigc/Translator|Jingyan Reviewer|Chonglou berbeza daripada bank soalan tradisional yang boleh dilihat di mana-mana sahaja di Internet memerlukan pemikiran di luar kotak. Model Bahasa Besar (LLM) semakin penting dalam bidang sains data, kecerdasan buatan generatif (GenAI) dan kecerdasan buatan. Algoritma kompleks ini meningkatkan kemahiran manusia dan memacu kecekapan dan inovasi dalam banyak industri, menjadi kunci kepada syarikat untuk kekal berdaya saing. LLM mempunyai pelbagai aplikasi Ia boleh digunakan dalam bidang seperti pemprosesan bahasa semula jadi, penjanaan teks, pengecaman pertuturan dan sistem pengesyoran. Dengan belajar daripada sejumlah besar data, LLM dapat menjana teks
 Untuk menyediakan tanda aras dan sistem penilaian menjawab soalan saintifik dan kompleks baharu untuk model besar, UNSW, Argonne, University of Chicago dan institusi lain bersama-sama melancarkan rangka kerja SciQAG
Jul 25, 2024 am 06:42 AM
Untuk menyediakan tanda aras dan sistem penilaian menjawab soalan saintifik dan kompleks baharu untuk model besar, UNSW, Argonne, University of Chicago dan institusi lain bersama-sama melancarkan rangka kerja SciQAG
Jul 25, 2024 am 06:42 AM
Editor |ScienceAI Question Answering (QA) set data memainkan peranan penting dalam mempromosikan penyelidikan pemprosesan bahasa semula jadi (NLP). Set data QA berkualiti tinggi bukan sahaja boleh digunakan untuk memperhalusi model, tetapi juga menilai dengan berkesan keupayaan model bahasa besar (LLM), terutamanya keupayaan untuk memahami dan menaakul tentang pengetahuan saintifik. Walaupun pada masa ini terdapat banyak set data QA saintifik yang meliputi bidang perubatan, kimia, biologi dan bidang lain, set data ini masih mempunyai beberapa kekurangan. Pertama, borang data adalah agak mudah, kebanyakannya adalah soalan aneka pilihan. Ia mudah dinilai, tetapi mengehadkan julat pemilihan jawapan model dan tidak dapat menguji sepenuhnya keupayaan model untuk menjawab soalan saintifik. Sebaliknya, Soal Jawab terbuka
 Lima sekolah pembelajaran mesin yang anda tidak tahu
Jun 05, 2024 pm 08:51 PM
Lima sekolah pembelajaran mesin yang anda tidak tahu
Jun 05, 2024 pm 08:51 PM
Pembelajaran mesin ialah cabang penting kecerdasan buatan yang memberikan komputer keupayaan untuk belajar daripada data dan meningkatkan keupayaan mereka tanpa diprogramkan secara eksplisit. Pembelajaran mesin mempunyai pelbagai aplikasi dalam pelbagai bidang, daripada pengecaman imej dan pemprosesan bahasa semula jadi kepada sistem pengesyoran dan pengesanan penipuan, dan ia mengubah cara hidup kita. Terdapat banyak kaedah dan teori yang berbeza dalam bidang pembelajaran mesin, antaranya lima kaedah yang paling berpengaruh dipanggil "Lima Sekolah Pembelajaran Mesin". Lima sekolah utama ialah sekolah simbolik, sekolah sambungan, sekolah evolusi, sekolah Bayesian dan sekolah analogi. 1. Simbolisme, juga dikenali sebagai simbolisme, menekankan penggunaan simbol untuk penaakulan logik dan ekspresi pengetahuan. Aliran pemikiran ini percaya bahawa pembelajaran adalah proses penolakan terbalik, melalui sedia ada
 Prestasi SOTA, kaedah AI ramalan pertalian protein-ligan pelbagai mod Xiamen, menggabungkan maklumat permukaan molekul buat kali pertama
Jul 17, 2024 pm 06:37 PM
Prestasi SOTA, kaedah AI ramalan pertalian protein-ligan pelbagai mod Xiamen, menggabungkan maklumat permukaan molekul buat kali pertama
Jul 17, 2024 pm 06:37 PM
Editor |. KX Dalam bidang penyelidikan dan pembangunan ubat, meramalkan pertalian pengikatan protein dan ligan dengan tepat dan berkesan adalah penting untuk pemeriksaan dan pengoptimuman ubat. Walau bagaimanapun, kajian semasa tidak mengambil kira peranan penting maklumat permukaan molekul dalam interaksi protein-ligan. Berdasarkan ini, penyelidik dari Universiti Xiamen mencadangkan rangka kerja pengekstrakan ciri berbilang mod (MFE) novel, yang buat pertama kalinya menggabungkan maklumat mengenai permukaan protein, struktur dan jujukan 3D, dan menggunakan mekanisme perhatian silang untuk membandingkan ciri modaliti yang berbeza penjajaran. Keputusan eksperimen menunjukkan bahawa kaedah ini mencapai prestasi terkini dalam meramalkan pertalian mengikat protein-ligan. Tambahan pula, kajian ablasi menunjukkan keberkesanan dan keperluan maklumat permukaan protein dan penjajaran ciri multimodal dalam rangka kerja ini. Penyelidikan berkaitan bermula dengan "S
 Meletakkan pasaran seperti AI, GlobalFoundries memperoleh teknologi gallium nitrida Tagore Technology dan pasukan berkaitan
Jul 15, 2024 pm 12:21 PM
Meletakkan pasaran seperti AI, GlobalFoundries memperoleh teknologi gallium nitrida Tagore Technology dan pasukan berkaitan
Jul 15, 2024 pm 12:21 PM
Menurut berita dari laman web ini pada 5 Julai, GlobalFoundries mengeluarkan kenyataan akhbar pada 1 Julai tahun ini, mengumumkan pemerolehan teknologi power gallium nitride (GaN) Tagore Technology dan portfolio harta intelek, dengan harapan dapat mengembangkan bahagian pasarannya dalam kereta dan Internet of Things dan kawasan aplikasi pusat data kecerdasan buatan untuk meneroka kecekapan yang lebih tinggi dan prestasi yang lebih baik. Memandangkan teknologi seperti AI generatif terus berkembang dalam dunia digital, galium nitrida (GaN) telah menjadi penyelesaian utama untuk pengurusan kuasa yang mampan dan cekap, terutamanya dalam pusat data. Laman web ini memetik pengumuman rasmi bahawa semasa pengambilalihan ini, pasukan kejuruteraan Tagore Technology akan menyertai GLOBALFOUNDRIES untuk membangunkan lagi teknologi gallium nitride. G
