
 Peranti teknologi
AI
Laksanakan latihan kelebihan dengan memori kurang daripada 256KB dan kosnya kurang daripada seperseribu PyTorch
Peranti teknologi
AI
Laksanakan latihan kelebihan dengan memori kurang daripada 256KB dan kosnya kurang daripada seperseribu PyTorch
Laksanakan latihan kelebihan dengan memori kurang daripada 256KB dan kosnya kurang daripada seperseribu PyTorch

Mengenai latihan rangkaian saraf, tanggapan pertama semua orang ialah GPU + pelayan + platform awan. Disebabkan overhed memori yang besar, latihan tradisional sering dilakukan dalam awan dan platform tepi hanya bertanggungjawab untuk inferens. Walau bagaimanapun, reka bentuk sedemikian menyukarkan model AI untuk menyesuaikan diri dengan data baharu: lagipun, dunia sebenar adalah senario yang dinamik, berubah dan berkembang Bagaimana satu latihan boleh merangkumi semua senario?
Untuk membolehkan model terus menyesuaikan diri dengan data baharu, bolehkah kami melakukan latihan di tepi (latihan pada peranti) supaya peranti boleh terus belajar sendiri? Dalam kerja ini, kami melaksanakan latihan pada peranti menggunakan kurang daripada 256KB memori, dan overhed adalah kurang daripada 1/1000 PyTorch, dan pada masa yang sama, kami menunjukkan prestasi yang baik on the visual wake word task (VWW) Mencapai ketepatan latihan awan. Teknologi ini membolehkan model menyesuaikan diri dengan data sensor baharu. Pengguna boleh menikmati perkhidmatan tersuai tanpa memuat naik data ke awan, dengan itu melindungi privasi.

- Tapak web: https://tinytraining.mit.edu/
- Kertas: https://arxiv.org/abs/2206.15472
- Demo: https://www.bilibili.com/ video/BV1qv4y1d7MV
- Kod: https://github.com/mit-han-lab/tiny-training
Latar Belakang
Latihan pada peranti membolehkan model pra-latihan menyesuaikan diri dengan persekitaran baharu selepas penggunaan. Dengan melatih dan menyesuaikan diri secara tempatan pada mudah alih, model boleh terus meningkatkan keputusannya dan menyesuaikan model untuk pengguna. Contohnya, model bahasa penalaan halus membolehkan mereka belajar daripada sejarah input melaraskan model penglihatan membolehkan kamera pintar mengenali objek baharu secara berterusan. Dengan mendekatkan latihan kepada terminal dan bukannya awan, kami boleh meningkatkan kualiti model dengan berkesan sambil melindungi privasi pengguna, terutamanya apabila memproses maklumat peribadi seperti data perubatan dan sejarah input.
Walau bagaimanapun, latihan pada peranti IoT kecil pada asasnya berbeza daripada latihan awan dan sangat mencabar Pertama, saiz SRAM peranti AIoT (MCU) biasanya terhad (256KB). Tahap ingatan ini sangat sukar untuk membuat inferens, apatah lagi latihan. Tambahan pula, algoritma pembelajaran pemindahan kos rendah dan cekap sedia ada, seperti hanya melatih pengelas lapisan terakhir (FC terakhir) dan hanya mempelajari istilah bias, selalunya mempunyai ketepatan yang tidak memuaskan dan tidak boleh digunakan dalam amalan, apatah lagi dalam beberapa aplikasi moden rangka kerja pembelajaran mendalam tidak dapat menterjemahkan nombor teori algoritma ini kepada penjimatan yang diukur. Akhir sekali, rangka kerja latihan mendalam moden (PyTorch, TensorFlow) biasanya direka untuk pelayan awan dan melatih model kecil (MobileNetV2-w0.35) memerlukan jumlah memori yang besar walaupun saiz kelompok ditetapkan kepada 1. Oleh itu, kita perlu reka bentuk bersama algoritma dan sistem untuk mencapai latihan pada peranti terminal pintar.

Kaedah dan Keputusan
Kami mendapati bahawa latihan pada peranti mempunyai dua cabaran unik: (1) Model ini berada pada peranti tepi Ia adalah kuantitatif. Graf yang benar-benar terkuantisasi (seperti yang ditunjukkan di bawah) adalah sukar untuk dioptimumkan kerana tensor berketepatan rendah dan kekurangan lapisan normalisasi kelompok (2) sumber perkakasan yang terhad (memori dan pengiraan) perkakasan kecil tidak membenarkan perambatan balik penuh, yang Memori; penggunaan boleh dengan mudah melebihi had SRAM mikropengawal (dengan lebih daripada susunan magnitud), tetapi jika hanya lapisan terakhir dikemas kini, ketepatan akhir pasti akan menjadi tidak memuaskan.

Untuk mengatasi kesukaran pengoptimuman, kami mencadangkan Quantization-Aware Scaling (QAS) untuk menskalakan kecerunan tensor secara automatik dengan bit yang berbeza ketepatan (seperti berikut) ditunjukkan di sebelah kiri). QAS secara automatik boleh memadankan kecerunan dan skala parameter serta menstabilkan latihan tanpa memerlukan hiperparameter tambahan. Pada 8 set data, QAS boleh mencapai prestasi yang konsisten dengan latihan titik terapung (gambar kanan di bawah).

Untuk mengurangkan jejak memori yang diperlukan untuk perambatan belakang, kami mencadangkan Kemas Kini Jarang untuk melangkau pengiraan kecerunan lapisan dan subhelaian yang kurang penting. Kami membangunkan kaedah automatik berdasarkan analisis sumbangan untuk mencari skim kemas kini yang optimum. Berbanding dengan kemas kini lapisan k yang berat sebelah sahaja sebelum ini, skim kemas kini jarang yang kami cari mempunyai 4.5 kali hingga 7.5 kali penjimatan memori, dan purata ketepatan pada 8 set data hiliran adalah lebih tinggi.

Untuk menukar pengurangan teori dalam algoritma kepada nilai berangka sebenar, kami mereka bentuk Enjin Latihan Kecil (TTE): ia memindahkan kerja pembezaan automatik untuk menyusun masa, dan menggunakan codegen untuk mengurangkan overhed masa jalan. Ia juga menyokong pemangkasan graf dan penyusunan semula untuk penjimatan dan percepatan sebenar. Kemas Kini Jarang berkesan mengurangkan memori puncak sebanyak 7-9x berbanding Kemas Kini Penuh, dan boleh dipertingkatkan lagi kepada 20-21x jumlah penjimatan memori dengan penyusunan semula. Berbanding dengan TF-Lite, kernel yang dioptimumkan dan kemas kini jarang dalam TTE meningkatkan kelajuan latihan keseluruhan sebanyak 23-25 kali.


Kesimpulan
Dalam kertas kerja ini, kami telah mencadangkan pelaksanaan pertama pada mikropengawal Penyelesaian latihan (hanya menggunakan 256KB RAM dan 1MB Flash). Reka bentuk bersama sistem algoritma kami (Reka bentuk Bersama Sistem-Algoritma) sangat mengurangkan memori yang diperlukan untuk latihan (1000 kali berbanding PyTorch) dan masa latihan (20 kali ganda berbanding TF-Lite), dan mencapai ketepatan yang lebih tinggi pada kadar tugas hiliran. Latihan Kecil boleh memperkasakan banyak aplikasi menarik Contohnya, telefon mudah alih boleh menyesuaikan model bahasa berdasarkan e-mel/sejarah input pengguna, kamera pintar boleh terus mengenali wajah/objek baharu, dan beberapa senario AI yang tidak boleh disambungkan ke Internet juga boleh diteruskan. untuk belajar (seperti pertanian, marin, barisan pemasangan perindustrian). Melalui kerja kami, peranti hujung kecil boleh melakukan bukan sahaja inferens tetapi juga latihan. Dalam proses ini, data peribadi tidak akan dimuat naik ke awan, jadi tiada risiko privasi Pada masa yang sama, model AI boleh terus belajar sendiri untuk menyesuaikan diri dengan dunia yang berubah secara dinamik.
Atas ialah kandungan terperinci Laksanakan latihan kelebihan dengan memori kurang daripada 256KB dan kosnya kurang daripada seperseribu PyTorch. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas



 Pengoptimuman memori yang besar, apakah yang perlu saya lakukan jika komputer menaik taraf kepada kelajuan memori 16g/32g dan tiada perubahan?
Jun 18, 2024 pm 06:51 PM
Pengoptimuman memori yang besar, apakah yang perlu saya lakukan jika komputer menaik taraf kepada kelajuan memori 16g/32g dan tiada perubahan?
Jun 18, 2024 pm 06:51 PM
Untuk pemacu keras mekanikal atau pemacu keadaan pepejal SATA, anda akan merasakan peningkatan kelajuan berjalan perisian Jika ia adalah pemacu keras NVME, anda mungkin tidak merasakannya. 1. Import pendaftaran ke dalam desktop dan buat dokumen teks baharu, salin dan tampal kandungan berikut, simpannya sebagai 1.reg, kemudian klik kanan untuk menggabungkan dan memulakan semula komputer. WindowsRegistryEditorVersion5.00[HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Control\SessionManager\MemoryManagement]"DisablePagingExecutive"=d
 Sumber terbuka! Di luar ZoeDepth! DepthFM: Anggaran kedalaman monokular yang cepat dan tepat!
Apr 03, 2024 pm 12:04 PM
Sumber terbuka! Di luar ZoeDepth! DepthFM: Anggaran kedalaman monokular yang cepat dan tepat!
Apr 03, 2024 pm 12:04 PM
0. Apakah fungsi artikel ini? Kami mencadangkan DepthFM: model anggaran kedalaman monokular generatif yang serba boleh dan pantas. Sebagai tambahan kepada tugas anggaran kedalaman tradisional, DepthFM juga menunjukkan keupayaan terkini dalam tugas hiliran seperti mengecat kedalaman. DepthFM cekap dan boleh mensintesis peta kedalaman dalam beberapa langkah inferens. Mari kita baca karya ini bersama-sama ~ 1. Tajuk maklumat kertas: DepthFM: FastMonocularDepthEstimationwithFlowMatching Pengarang: MingGui, JohannesS.Fischer, UlrichPrestel, PingchuanMa, Dmytr
 Hello, Atlas elektrik! Robot Boston Dynamics hidup semula, gerakan pelik 180 darjah menakutkan Musk
Apr 18, 2024 pm 07:58 PM
Hello, Atlas elektrik! Robot Boston Dynamics hidup semula, gerakan pelik 180 darjah menakutkan Musk
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas secara rasmi memasuki era robot elektrik! Semalam, Atlas hidraulik hanya "menangis" menarik diri daripada peringkat sejarah Hari ini, Boston Dynamics mengumumkan bahawa Atlas elektrik sedang berfungsi. Nampaknya dalam bidang robot humanoid komersial, Boston Dynamics berazam untuk bersaing dengan Tesla. Selepas video baharu itu dikeluarkan, ia telah pun ditonton oleh lebih sejuta orang dalam masa sepuluh jam sahaja. Orang lama pergi dan peranan baru muncul. Ini adalah keperluan sejarah. Tidak dinafikan bahawa tahun ini adalah tahun letupan robot humanoid. Netizen mengulas: Kemajuan robot telah menjadikan majlis pembukaan tahun ini kelihatan seperti manusia, dan tahap kebebasan adalah jauh lebih besar daripada manusia Tetapi adakah ini benar-benar bukan filem seram? Pada permulaan video, Atlas berbaring dengan tenang di atas tanah, seolah-olah terlentang. Apa yang berikut adalah rahang-jatuh
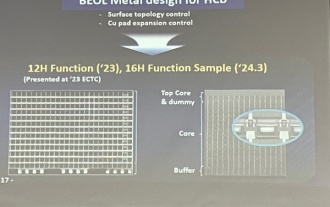 Samsung mengumumkan penyiapan pengesahan teknologi proses penyusunan ikatan hibrid 16 lapisan, yang dijangka digunakan secara meluas dalam memori HBM4
Apr 07, 2024 pm 09:19 PM
Samsung mengumumkan penyiapan pengesahan teknologi proses penyusunan ikatan hibrid 16 lapisan, yang dijangka digunakan secara meluas dalam memori HBM4
Apr 07, 2024 pm 09:19 PM
Menurut laporan itu, eksekutif Samsung Electronics Dae Woo Kim berkata bahawa pada Mesyuarat Tahunan Persatuan Mikroelektronik dan Pembungkusan Korea 2024, Samsung Electronics akan melengkapkan pengesahan teknologi memori HBM ikatan hibrid 16 lapisan. Dilaporkan bahawa teknologi ini telah lulus pengesahan teknikal. Laporan itu juga menyatakan bahawa pengesahan teknikal ini akan meletakkan asas untuk pembangunan pasaran memori dalam beberapa tahun akan datang. DaeWooKim berkata bahawa Samsung Electronics telah berjaya menghasilkan memori HBM3 bertindan 16 lapisan berdasarkan teknologi ikatan hibrid Sampel memori berfungsi seperti biasa Pada masa hadapan, teknologi ikatan hibrid bertindan 16 lapisan akan digunakan untuk pengeluaran besar-besaran memori HBM4. ▲Sumber imej TheElec, sama seperti di bawah Berbanding dengan proses ikatan sedia ada, ikatan hibrid tidak perlu menambah bonjolan antara lapisan memori DRAM, tetapi secara langsung menghubungkan lapisan atas dan bawah tembaga kepada kuprum.
 Daya hidup kecerdasan super membangkitkan! Tetapi dengan kedatangan AI yang mengemas kini sendiri, ibu tidak perlu lagi bimbang tentang kesesakan data
Apr 29, 2024 pm 06:55 PM
Daya hidup kecerdasan super membangkitkan! Tetapi dengan kedatangan AI yang mengemas kini sendiri, ibu tidak perlu lagi bimbang tentang kesesakan data
Apr 29, 2024 pm 06:55 PM
Saya menangis hingga mati. Dunia sedang membina model besar. Data di Internet tidak mencukupi. Model latihan kelihatan seperti "The Hunger Games", dan penyelidik AI di seluruh dunia bimbang tentang cara memberi makan data ini kepada pemakan yang rakus. Masalah ini amat ketara dalam tugas berbilang modal. Pada masa mereka mengalami kerugian, pasukan pemula dari Jabatan Universiti Renmin China menggunakan model baharu mereka sendiri untuk menjadi yang pertama di China untuk menjadikan "suapan data yang dijana model itu sendiri" menjadi kenyataan. Selain itu, ia merupakan pendekatan serampang dua mata dari segi pemahaman dan sisi penjanaan Kedua-dua pihak boleh menjana data baharu berbilang modal yang berkualiti tinggi dan memberikan maklum balas data kepada model itu sendiri. Apakah model? Awaker 1.0, model berbilang modal besar yang baru sahaja muncul di Forum Zhongguancun. Siapa pasukan itu? Enjin Sophon. Diasaskan oleh Gao Yizhao, pelajar kedoktoran di Sekolah Kecerdasan Buatan Hillhouse Universiti Renmin.
 Versi Kuaishou Sora 'Ke Ling' dibuka untuk ujian: menghasilkan video lebih 120-an, memahami fizik dengan lebih baik dan boleh memodelkan pergerakan kompleks dengan tepat
Jun 11, 2024 am 09:51 AM
Versi Kuaishou Sora 'Ke Ling' dibuka untuk ujian: menghasilkan video lebih 120-an, memahami fizik dengan lebih baik dan boleh memodelkan pergerakan kompleks dengan tepat
Jun 11, 2024 am 09:51 AM
Apa? Adakah Zootopia dibawa menjadi realiti oleh AI domestik? Didedahkan bersama-sama dengan video itu ialah model penjanaan video domestik berskala besar baharu yang dipanggil "Keling". Sora menggunakan laluan teknikal yang serupa dan menggabungkan beberapa inovasi teknologi yang dibangunkan sendiri untuk menghasilkan video yang bukan sahaja mempunyai pergerakan yang besar dan munasabah, tetapi juga mensimulasikan ciri-ciri dunia fizikal dan mempunyai keupayaan gabungan konsep dan imaginasi yang kuat. Mengikut data, Keling menyokong penjanaan video ultra panjang sehingga 2 minit pada 30fps, dengan resolusi sehingga 1080p dan menyokong berbilang nisbah aspek. Satu lagi perkara penting ialah Keling bukanlah demo atau demonstrasi hasil video yang dikeluarkan oleh makmal, tetapi aplikasi peringkat produk yang dilancarkan oleh Kuaishou, pemain terkemuka dalam bidang video pendek. Selain itu, tumpuan utama adalah untuk menjadi pragmatik, bukan untuk menulis cek kosong, dan pergi ke dalam talian sebaik sahaja ia dikeluarkan Model besar Ke Ling telah pun dikeluarkan di Kuaiying.
 Tentera Udara A.S. mempamerkan jet pejuang AI pertamanya dengan profil tinggi! Menteri secara peribadi menjalankan pandu uji tanpa campur tangan semasa keseluruhan proses, dan 100,000 baris kod telah diuji selama 21 kali.
May 07, 2024 pm 05:00 PM
Tentera Udara A.S. mempamerkan jet pejuang AI pertamanya dengan profil tinggi! Menteri secara peribadi menjalankan pandu uji tanpa campur tangan semasa keseluruhan proses, dan 100,000 baris kod telah diuji selama 21 kali.
May 07, 2024 pm 05:00 PM
Baru-baru ini, bulatan tentera telah terharu dengan berita: jet pejuang tentera AS kini boleh melengkapkan pertempuran udara automatik sepenuhnya menggunakan AI. Ya, baru-baru ini, jet pejuang AI tentera AS telah didedahkan buat pertama kali, mendedahkan misterinya. Nama penuh pesawat pejuang ini ialah Variable Stability Simulator Test Aircraft (VISTA). Ia diterbangkan sendiri oleh Setiausaha Tentera Udara AS untuk mensimulasikan pertempuran udara satu lawan satu. Pada 2 Mei, Setiausaha Tentera Udara A.S. Frank Kendall berlepas menggunakan X-62AVISTA di Pangkalan Tentera Udara Edwards Ambil perhatian bahawa semasa penerbangan selama satu jam, semua tindakan penerbangan telah diselesaikan secara autonomi oleh AI! Kendall berkata - "Sejak beberapa dekad yang lalu, kami telah memikirkan tentang potensi tanpa had pertempuran udara-ke-udara autonomi, tetapi ia sentiasa kelihatan di luar jangkauan." Namun kini,
 Sumber mengatakan Samsung Electronics dan SK Hynix akan mengkomersialkan memori mudah alih bertindan selepas 2026
Sep 03, 2024 pm 02:15 PM
Sumber mengatakan Samsung Electronics dan SK Hynix akan mengkomersialkan memori mudah alih bertindan selepas 2026
Sep 03, 2024 pm 02:15 PM
Menurut berita dari laman web ini pada 3 September, media Korea etnews melaporkan semalam (waktu tempatan) bahawa produk memori mudah alih berstruktur "seperti HBM" SK Hynix akan dikomersialkan selepas 2026. Sumber berkata bahawa kedua-dua gergasi memori Korea menganggap memori mudah alih bertindan sebagai sumber penting hasil masa hadapan dan merancang untuk mengembangkan "memori seperti HBM" kepada telefon pintar, tablet dan komputer riba untuk membekalkan kuasa untuk AI bahagian hujung. Menurut laporan sebelumnya di laman web ini, produk Samsung Electronics dipanggil memori LPWide I/O, dan SK Hynix memanggil teknologi ini VFO. Kedua-dua syarikat telah menggunakan laluan teknikal yang hampir sama, iaitu menggabungkan pembungkusan kipas dan saluran menegak. Memori LPWide I/O Samsung Electronics mempunyai sedikit lebar 512
