

Mentafsir CRISP-ML(Q): Proses Kitaran Hayat Pembelajaran Mesin

Penterjemah |. Bugatti
Penilai |. Sun Shujuan
Pada masa ini, tiada amalan standard untuk membina dan mengurus aplikasi pembelajaran mesin (ML). Projek pembelajaran mesin kurang teratur, kurang kebolehulangan dan cenderung gagal secara langsung dalam jangka masa panjang. Oleh itu, kami memerlukan proses untuk membantu kami mengekalkan kualiti, kemampanan, keteguhan dan pengurusan kos sepanjang kitaran hayat pembelajaran mesin.
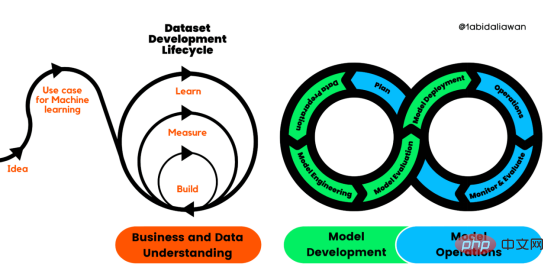
Rajah 1. Proses kitaran hayat pembangunan pembelajaran mesin
Proses standard merentas industri untuk membangunkan aplikasi pembelajaran mesin menggunakan kaedah jaminan kualiti (CRISP-ML(Q )) ialah versi CRISP-DM yang dinaik taraf untuk memastikan kualiti produk pembelajaran mesin.
CRISP-ML (Q) mempunyai enam peringkat berasingan:
1 Pemahaman perniagaan dan data
2 Penyediaan data
3 🎜>
4. Penilaian model 5. Penerapan model 6. Walaupun terdapat susunan dalam rangka kerja, output peringkat kemudian boleh menentukan sama ada kita perlu menyemak semula peringkat sebelumnya.Rajah 2. Jaminan kualiti pada setiap peringkat 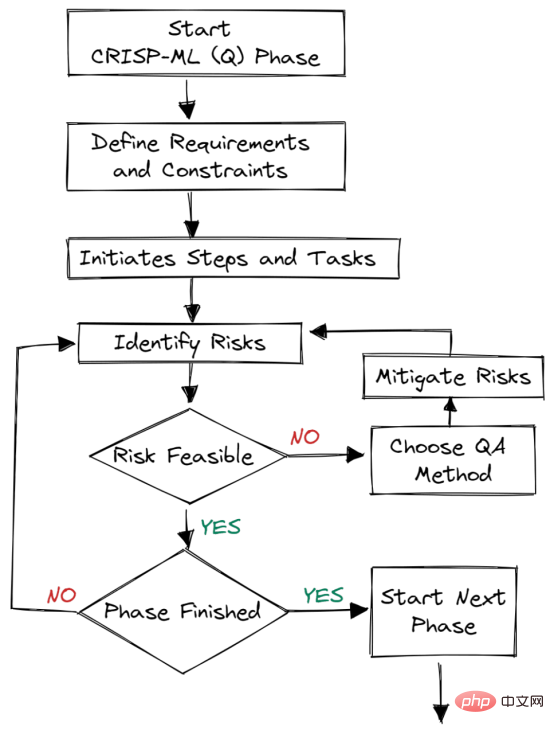
Skop:
Perkara yang kami harap dapat dicapai dengan menggunakan proses pembelajaran mesin. Adakah untuk mengekalkan pelanggan atau mengurangkan kos operasi melalui automasi?Kriteria Kejayaan:
Kita mesti mentakrifkan perniagaan yang jelas dan boleh diukur, pembelajaran mesin (metrik statistik) dan metrik kejayaan ekonomi (KPI).Kebolehlaksanaan:
Kami perlu memastikan ketersediaan data, kesesuaian untuk aplikasi pembelajaran mesin, kekangan undang-undang, keteguhan, kebolehskalaan, kebolehtafsiran dan keperluan sumber.Pengumpulan Data:
Dengan mengumpul data, menjadikannya versi untuk kebolehulangan dan memastikan aliran berterusan data sebenar dan terjana.Pengesahan Kualiti Data:
Pastikan kualiti dengan mengekalkan perihalan, keperluan dan pengesahan data.Untuk memastikan kualiti dan kebolehulangan, kami perlu merekodkan sifat statistik data dan proses penjanaan data.
Penyediaan data Peringkat kedua sangat mudah. Kami akan menyediakan data untuk fasa pemodelan. Ini termasuk pemilihan data, pembersihan data, kejuruteraan ciri, peningkatan data dan normalisasi. 1. Kami bermula dengan pemilihan ciri, pemilihan data dan pengendalian kelas yang tidak seimbang melalui pensampelan berlebihan atau pensampelan terkurang. 2. Kemudian, fokus pada mengurangkan hingar dan mengendalikan nilai yang hilang. Untuk tujuan jaminan kualiti, kami akan menambah ujian unit data untuk mengurangkan nilai yang salah. 3 Bergantung pada model, kami melakukan kejuruteraan ciri dan penambahan data seperti pengekodan dan pengelompokan satu-panas. 4. Ini mengurangkan risiko ciri berat sebelah. Untuk memastikan kebolehulangan, kami mencipta pemodelan data, transformasi dan saluran paip kejuruteraan ciri. Kejuruteraan ModelKekangan dan keperluan fasa pemahaman perniagaan dan data akan menentukan fasa pemodelan. Kita perlu memahami masalah perniagaan dan cara kita akan membangunkan model pembelajaran mesin untuk menyelesaikannya. Kami akan menumpukan pada pemilihan model, pengoptimuman dan latihan, memastikan metrik prestasi model, keteguhan, kebolehskalaan, kebolehtafsiran dan mengoptimumkan sumber storan dan pengkomputeran. 1. Penyelidikan tentang seni bina model dan masalah perniagaan yang serupa. 2. Tentukan penunjuk prestasi model. 3. 4. Fahami pengetahuan domain dengan mengintegrasikan pakar. 5. 6. Pemampatan dan penyepaduan model. Untuk memastikan kualiti dan kebolehulangan, kami akan menyimpan dan metadata model kawalan versi, seperti seni bina model, data latihan dan pengesahan, hiperparameter dan perihalan persekitaran. Akhir sekali, kami akan menjejaki percubaan ML dan membuat saluran paip ML untuk mencipta proses latihan yang boleh berulang. Penilaian ModelIni adalah peringkat di mana kami menguji dan memastikan model sedia untuk digunakan.
- Kami akan menguji prestasi model pada set data ujian.
- Nilai kekukuhan model dengan menyediakan data rawak atau palsu.
- Tingkatkan kebolehtafsiran model untuk memenuhi keperluan kawal selia.
- Bandingkan hasil dengan metrik kejayaan awal secara automatik atau dengan pakar domain.
Setiap langkah fasa penilaian didokumenkan untuk jaminan kualiti.
Pengedaran Model
Penyerahan model ialah peringkat di mana kami menyepadukan model pembelajaran mesin ke dalam sistem sedia ada. Model ini boleh digunakan pada pelayan, penyemak imbas, perisian dan peranti tepi. Ramalan daripada model tersedia dalam papan pemuka BI, API, aplikasi web dan pemalam.
Proses penggunaan model:
- Tentukan inferens perkakasan.
- Penilaian model dalam persekitaran pengeluaran.
- Pastikan penerimaan dan kebolehgunaan pengguna.
- Sediakan pelan sandaran untuk meminimumkan kerugian.
- Strategi penggunaan.
Pemantauan dan Penyelenggaraan
Model dalam persekitaran pengeluaran memerlukan pemantauan dan penyelenggaraan yang berterusan. Kami akan memantau ketepatan masa model, prestasi perkakasan dan prestasi perisian.
Pemantauan berterusan ialah bahagian pertama proses jika prestasi menurun di bawah ambang, keputusan dibuat secara automatik untuk melatih semula model pada data baharu. Tambahan pula, bahagian penyelenggaraan tidak terhad kepada latihan semula model. Ia memerlukan mekanisme membuat keputusan, memperoleh data baharu, mengemas kini perisian dan perkakasan serta menambah baik proses ML berdasarkan kes penggunaan perniagaan.
Ringkasnya, ia adalah penyepaduan berterusan, latihan dan penggunaan model ML.
Kesimpulan
Melatih dan mengesahkan model ialah sebahagian kecil daripada aplikasi ML. Mengubah idea awal menjadi realiti memerlukan beberapa proses. Dalam artikel ini kami memperkenalkan CRISP-ML(Q) dan cara ia memfokuskan pada penilaian risiko dan jaminan kualiti.
Kami mula-mula mentakrifkan matlamat perniagaan, mengumpul dan membersihkan data, membina model, mengesahkan model dengan set data ujian, dan kemudian menggunakannya ke persekitaran pengeluaran.
Satu komponen utama rangka kerja ini ialah pemantauan dan penyelenggaraan yang berterusan. Kami akan memantau data dan metrik perisian dan perkakasan untuk menentukan sama ada untuk melatih semula model atau menaik taraf sistem.
Jika anda baru dalam operasi pembelajaran mesin dan ingin mengetahui lebih lanjut, baca kursus MLOps percuma disemak oleh DataTalks.Club. Anda akan memperoleh pengalaman praktikal dalam kesemua enam fasa, memahami pelaksanaan praktikal CRISP-ML.
Tajuk asal: Memahami CRISP-ML(Q): Proses Kitar Hayat Pembelajaran Mesin, Penulis: Abid Ali Awan
Atas ialah kandungan terperinci Mentafsir CRISP-ML(Q): Proses Kitaran Hayat Pembelajaran Mesin. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

Video Face Swap
Tukar muka dalam mana-mana video dengan mudah menggunakan alat tukar muka AI percuma kami!

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas



 Lima sekolah pembelajaran mesin yang anda tidak tahu
Jun 05, 2024 pm 08:51 PM
Lima sekolah pembelajaran mesin yang anda tidak tahu
Jun 05, 2024 pm 08:51 PM
Pembelajaran mesin ialah cabang penting kecerdasan buatan yang memberikan komputer keupayaan untuk belajar daripada data dan meningkatkan keupayaan mereka tanpa diprogramkan secara eksplisit. Pembelajaran mesin mempunyai pelbagai aplikasi dalam pelbagai bidang, daripada pengecaman imej dan pemprosesan bahasa semula jadi kepada sistem pengesyoran dan pengesanan penipuan, dan ia mengubah cara hidup kita. Terdapat banyak kaedah dan teori yang berbeza dalam bidang pembelajaran mesin, antaranya lima kaedah yang paling berpengaruh dipanggil "Lima Sekolah Pembelajaran Mesin". Lima sekolah utama ialah sekolah simbolik, sekolah sambungan, sekolah evolusi, sekolah Bayesian dan sekolah analogi. 1. Simbolisme, juga dikenali sebagai simbolisme, menekankan penggunaan simbol untuk penaakulan logik dan ekspresi pengetahuan. Aliran pemikiran ini percaya bahawa pembelajaran adalah proses penolakan terbalik, melalui sedia ada
 Pemula AI secara kolektif menukar pekerjaan kepada OpenAI, dan pasukan keselamatan berkumpul semula selepas Ilya pergi!
Jun 08, 2024 pm 01:00 PM
Pemula AI secara kolektif menukar pekerjaan kepada OpenAI, dan pasukan keselamatan berkumpul semula selepas Ilya pergi!
Jun 08, 2024 pm 01:00 PM
Minggu lalu, di tengah gelombang peletakan jawatan dalaman dan kritikan luar, OpenAI dibelenggu oleh masalah dalaman dan luaran: - Pelanggaran kakak balu itu mencetuskan perbincangan hangat global - Pekerja menandatangani "fasal tuan" didedahkan satu demi satu - Netizen menyenaraikan " Ultraman " tujuh dosa maut" ” Pembasmi khabar angin: Menurut maklumat dan dokumen bocor yang diperolehi oleh Vox, kepimpinan kanan OpenAI, termasuk Altman, sangat mengetahui peruntukan pemulihan ekuiti ini dan menandatanganinya. Di samping itu, terdapat isu serius dan mendesak yang dihadapi oleh OpenAI - keselamatan AI. Pemergian lima pekerja berkaitan keselamatan baru-baru ini, termasuk dua pekerjanya yang paling terkemuka, dan pembubaran pasukan "Penjajaran Super" sekali lagi meletakkan isu keselamatan OpenAI dalam perhatian. Majalah Fortune melaporkan bahawa OpenA
 Bagaimana untuk menilai keberkesanan kos sokongan komersial untuk rangka kerja Java
Jun 05, 2024 pm 05:25 PM
Bagaimana untuk menilai keberkesanan kos sokongan komersial untuk rangka kerja Java
Jun 05, 2024 pm 05:25 PM
Menilai kos/prestasi sokongan komersial untuk rangka kerja Java melibatkan langkah-langkah berikut: Tentukan tahap jaminan yang diperlukan dan jaminan perjanjian tahap perkhidmatan (SLA). Pengalaman dan kepakaran pasukan sokongan penyelidikan. Pertimbangkan perkhidmatan tambahan seperti peningkatan, penyelesaian masalah dan pengoptimuman prestasi. Timbang kos sokongan perniagaan terhadap pengurangan risiko dan peningkatan kecekapan.
 Model 70B menjana 1,000 token dalam beberapa saat, penulisan semula kod mengatasi GPT-4o, daripada pasukan Kursor, artifak kod yang dilaburkan oleh OpenAI
Jun 13, 2024 pm 03:47 PM
Model 70B menjana 1,000 token dalam beberapa saat, penulisan semula kod mengatasi GPT-4o, daripada pasukan Kursor, artifak kod yang dilaburkan oleh OpenAI
Jun 13, 2024 pm 03:47 PM
Model 70B, 1000 token boleh dijana dalam beberapa saat, yang diterjemahkan kepada hampir 4000 aksara! Para penyelidik memperhalusi Llama3 dan memperkenalkan algoritma pecutan Berbanding dengan versi asli, kelajuannya adalah 13 kali lebih pantas! Bukan sahaja ia pantas, prestasinya pada tugas menulis semula kod malah mengatasi GPT-4o. Pencapaian ini datang dari mana-mana, pasukan di belakang Kursor artifak pengaturcaraan AI yang popular, dan OpenAI turut mengambil bahagian dalam pelaburan. Anda mesti tahu bahawa pada Groq, rangka kerja pecutan inferens pantas yang terkenal, kelajuan inferens 70BLlama3 hanyalah lebih daripada 300 token sesaat. Dengan kelajuan Kursor, boleh dikatakan bahawa ia mencapai penyuntingan fail kod lengkap hampir serta-merta. Sesetengah orang memanggilnya lelaki yang baik, jika anda meletakkan Curs
 Bagaimanakah keluk pembelajaran rangka kerja PHP berbanding rangka kerja bahasa lain?
Jun 06, 2024 pm 12:41 PM
Bagaimanakah keluk pembelajaran rangka kerja PHP berbanding rangka kerja bahasa lain?
Jun 06, 2024 pm 12:41 PM
Keluk pembelajaran rangka kerja PHP bergantung pada kecekapan bahasa, kerumitan rangka kerja, kualiti dokumentasi dan sokongan komuniti. Keluk pembelajaran rangka kerja PHP adalah lebih tinggi jika dibandingkan dengan rangka kerja Python dan lebih rendah jika dibandingkan dengan rangka kerja Ruby. Berbanding dengan rangka kerja Java, rangka kerja PHP mempunyai keluk pembelajaran yang sederhana tetapi masa yang lebih singkat untuk bermula.
 Bagaimanakah pilihan rangka kerja PHP yang ringan mempengaruhi prestasi aplikasi?
Jun 06, 2024 am 10:53 AM
Bagaimanakah pilihan rangka kerja PHP yang ringan mempengaruhi prestasi aplikasi?
Jun 06, 2024 am 10:53 AM
Rangka kerja PHP yang ringan meningkatkan prestasi aplikasi melalui saiz kecil dan penggunaan sumber yang rendah. Ciri-cirinya termasuk: saiz kecil, permulaan pantas, penggunaan memori yang rendah, kelajuan dan daya tindak balas yang dipertingkatkan, dan penggunaan sumber yang dikurangkan: SlimFramework mencipta API REST, hanya 500KB, responsif yang tinggi dan daya pemprosesan yang tinggi.
 Apakah aplikasi coroutine Go dalam kecerdasan buatan dan pembelajaran mesin?
Jun 05, 2024 pm 03:23 PM
Apakah aplikasi coroutine Go dalam kecerdasan buatan dan pembelajaran mesin?
Jun 05, 2024 pm 03:23 PM
Aplikasi coroutine Go dalam bidang kecerdasan buatan dan pembelajaran mesin termasuk: latihan dan ramalan masa nyata: tugas pemprosesan selari untuk meningkatkan prestasi. Pengoptimuman hiperparameter selari: Terokai tetapan berbeza serentak untuk mempercepatkan latihan. Pengkomputeran teragih: Agihkan tugas dengan mudah dan manfaatkan awan atau gugusan.
 China Mobile: Kemanusiaan memasuki revolusi perindustrian keempat dan secara rasmi mengumumkan 'tiga rancangan'
Jun 27, 2024 am 10:29 AM
China Mobile: Kemanusiaan memasuki revolusi perindustrian keempat dan secara rasmi mengumumkan 'tiga rancangan'
Jun 27, 2024 am 10:29 AM
Menurut berita pada 26 Jun, pada majlis perasmian Persidangan Komunikasi Mudah Alih Dunia 2024 Shanghai (MWC Shanghai), Pengerusi Mudah Alih China Yang Jie menyampaikan ucapan. Beliau berkata, pada masa ini, masyarakat manusia memasuki revolusi industri keempat, yang dikuasai oleh maklumat dan sangat bersepadu dengan maklumat dan tenaga, iaitu "revolusi kecerdasan digital", dan pembentukan kuasa produktif baru semakin pesat. Yang Jie percaya bahawa daripada "revolusi mekanisasi" yang digerakkan oleh enjin wap, kepada "revolusi elektrifikasi" yang didorong oleh elektrik dan enjin pembakaran dalaman, kepada "revolusi maklumat" yang didorong oleh komputer dan Internet, setiap pusingan revolusi perindustrian adalah berdasarkan "maklumat dan "Tenaga" adalah barisan utama, membawa pembangunan produktiviti
